DeekSeek-v2-简述
1. DeepSeek-V2是什么?
DeepSeek-V2是一个基于混合专家(Mixture-of-Experts,简称MoE)架构的语言模型。它是一种新型的人工智能模型,专门用于处理自然语言处理(NLP)任务,比如文本生成、翻译、问答等。与传统的语言模型相比,DeepSeek-V2在训练成本和推理效率上有显著的提升。
2. 模型的规模和效率
-
参数规模:DeepSeek-V2拥有2360亿个参数,这是一个非常庞大的数字,表明模型具有很强的学习能力。
-
激活参数:在处理每个token(比如一个单词或字符)时,DeepSeek-V2只激活210亿个参数。这种稀疏激活的设计使得模型在推理时更加高效,不会因为过高的计算负载而变得缓慢。
-
上下文长度:模型支持长达128K(128,000)个token的上下文长度。这意味着它可以处理非常长的文本输入,比如长篇文章或复杂的对话,而不会丢失上下文信息。
3. 创新的架构
DeepSeek-V2采用了两种创新的架构设计:
-
多头潜在注意力(MLA):
-
传统的注意力机制(如Transformer架构)需要存储大量的键值对(KV缓存),这会占用大量内存。
-
MLA通过将KV缓存压缩成一个潜在向量,显著减少了内存占用,从而提高了推理效率。
-
-
DeepSeekMoE架构:
-
这是一种高效的MoE架构,通过稀疏计算(只激活部分参数)来训练强大的模型。
-
它使得模型在保持高性能的同时,大幅降低了训练成本。
-
4. 性能提升
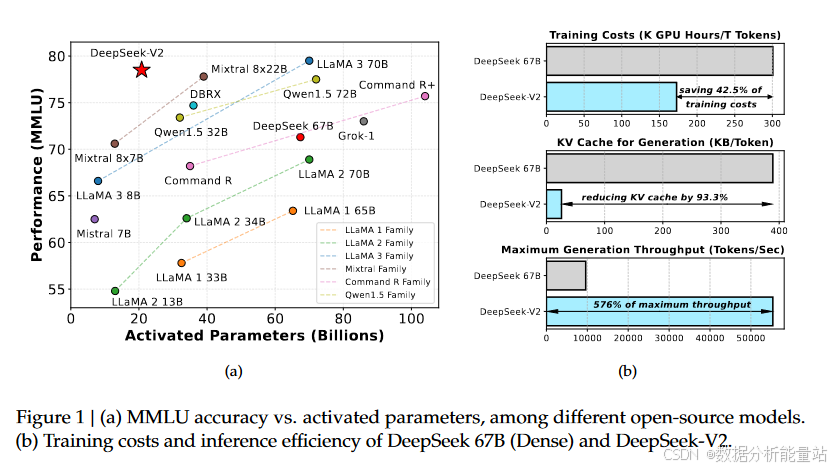
与DeepSeek 67B(一个较早的版本)相比,DeepSeek-V2在多个方面取得了显著的改进:
-
性能更强:在各种基准测试中,DeepSeek-V2的表现优于或接近其他大型语言模型。
-
训练成本更低:节省了42.5%的训练成本。
-
KV缓存减少:通过MLA设计,KV缓存减少了93.3%。
-
生成吞吐量更高:最大生成吞吐量提高了5.76倍,这意味着模型可以更快地生成文本。
5. 训练和微调
-
预训练:DeepSeek-V2在包含8.1万亿个token的高质量、多源语料库上进行了预训练。这意味着它学习了大量不同类型的文本数据,从而具备了广泛的知识。
-
微调:预训练之后,模型还经过了监督微调(SFT)和强化学习(RL),进一步优化了其性能。这些步骤帮助模型更好地适应特定的任务和场景。
6. 性能表现
-
基准测试:在各种标准基准测试中,DeepSeek-V2即使只激活210亿个参数,也达到了顶尖的性能水平。
-
聊天版本:DeepSeek-V2的聊天版本在对话生成任务中表现出色,能够生成高质量的文本。
7. 模型的可用性
-
开源:DeepSeek-V2的模型检查点已经开源,可以在GitHub上找到。
-
推理方式:用户可以通过多种方式运行模型,比如使用Hugging Face的Transformers库、SGLang框架或vLLM框架。
8. 总结
DeepSeek-V2是一个强大的语言模型,它通过创新的架构设计,在保持高性能的同时,大幅降低了训练和推理的成本。它不仅适用于学术研究,还可以在实际应用中高效地处理各种自然语言任务。
1 Introduction
在过去的几年中,大型语言模型(LLMs)取得了飞速发展,展示了接近人工通用智能(AGI)的潜力。这些模型的智能水平通常随着参数数量的增加而提升,但同时也带来了两个主要问题:
-
更高的训练成本:参数越多,训练所需的计算资源就越多。
-
推理效率降低:模型越大,生成文本的速度可能越慢。
这些问题限制了大型语言模型的广泛应用。为了解决这些问题,DeepSeek团队推出了DeepSeek-V2,这是一个开源的混合专家(MoE)语言模型,通过创新的架构设计实现了高效的训练和推理。
DeepSeek-V2的核心技术
DeepSeek-V2的核心在于其创新的架构设计,主要体现在两个方面:
多头潜在注意力(MLA)
-
问题:传统的多头注意力(MHA)机制在推理时需要存储大量的键值对(KV缓存),这会占用大量内存,导致推理效率低下。
-
解决方案:DeepSeek-V2引入了MLA机制,通过低秩压缩将KV缓存压缩成一个更小的潜在向量。
-
优势:MLA在保持性能的同时,显著减少了KV缓存的大小,从而提高了推理效率。
DeepSeekMoE架构
-
问题:传统的MoE架构(如GShard)虽然可以训练大型模型,但成本较高,且专家之间的通信开销较大。
-
解决方案:DeepSeek-V2采用了DeepSeekMoE架构,通过细粒度的专家分割和共享专家隔离,提高了专家的专业化能力。
-
优势:这种架构使得模型可以在较低成本下训练出更强大的性能,并通过专家并行化减少了通信开销。
模型性能和效率
DeepSeek-V2通过结合MLA和DeepSeekMoE,实现了以下优势:
-
强大的性能:即使只激活210亿个参数(总参数2360亿),DeepSeek-V2在各种基准测试中仍然表现出色,成为最强的开源MoE语言模型。
-
经济的训练成本:与DeepSeek 67B相比,DeepSeek-V2节省了42.5%的训练成本。
-
高效的推理吞吐量:KV缓存减少了93.3%,最大生成吞吐量提高了5.76倍。
预训练和微调
为了充分发挥DeepSeek-V2的潜力,团队进行了以下步骤:
-
预训练:使用一个包含8.1万亿个token的高质量、多源语料库进行预训练,数据量和质量都比之前的DeepSeek 67B有显著提升。
-
监督微调(SFT):收集了150万次对话会话,涵盖多个领域(如数学、代码、写作等),对DeepSeek-V2 Chat进行微调。
-
强化学习(RL):进一步通过分组相对策略优化(GRPO)使模型更好地符合人类偏好。
评估结果
DeepSeek-V2在多个基准测试中表现出色:
-
在英语和中文的基准测试中,DeepSeek-V2的性能优于其他开源模型。
-
在开放式对话生成任务中,DeepSeek-V2 Chat(RL)在AlpacaEval 2.0、MT-Bench和AlignBench等基准测试中取得了顶尖成绩。
-
在中文对话生成任务中,DeepSeek-V2 Chat(RL)甚至超越了大多数闭源模型。
开源社区的支持
为了促进研究和开发,DeepSeek团队还发布了DeepSeek-V2-Lite,这是一个较小的模型(总参数157亿,每个token激活24亿),同样采用了MLA和DeepSeekMoE架构,适合开源社区使用。
DeepSeek-V2通过创新的架构设计和优化,解决了大型语言模型在训练成本和推理效率上的瓶颈问题。它在保持强大性能的同时,显著降低了训练成本,并提高了推理效率。此外,通过高质量的预训练和微调,DeepSeek-V2在多种任务中表现出色,成为开源MoE语言模型中的佼佼者。
2 Architecture
总的来说,DeepSeek-V2仍然基于Transformer架构(Vaswani等人,2017),其中每个Transformer模块由一个注意力模块和一个前馈网络(FFN)组成。然而,对于注意力模块和FFN,我们都设计并采用了创新的架构。在注意力机制方面,我们设计了MLA(多头潜在注意力),它通过低秩键值联合压缩消除了推理时键值缓存的瓶颈,从而支持高效的推理。在前馈网络方面,我们采用了DeepSeekMoE架构(Dai等人,2024),这是一种高性能的混合专家(MoE)架构,能够在较低成本下训练出强大的模型。DeepSeek-V2的架构示意图如图2所示,我们将在本节详细介绍MLA和DeepSeekMoE。对于其他细节(例如层归一化和FFN中的激活函数),除非特别说明,DeepSeek-V2遵循DeepSeek 67B的设置(DeepSeek-AI,2024)。
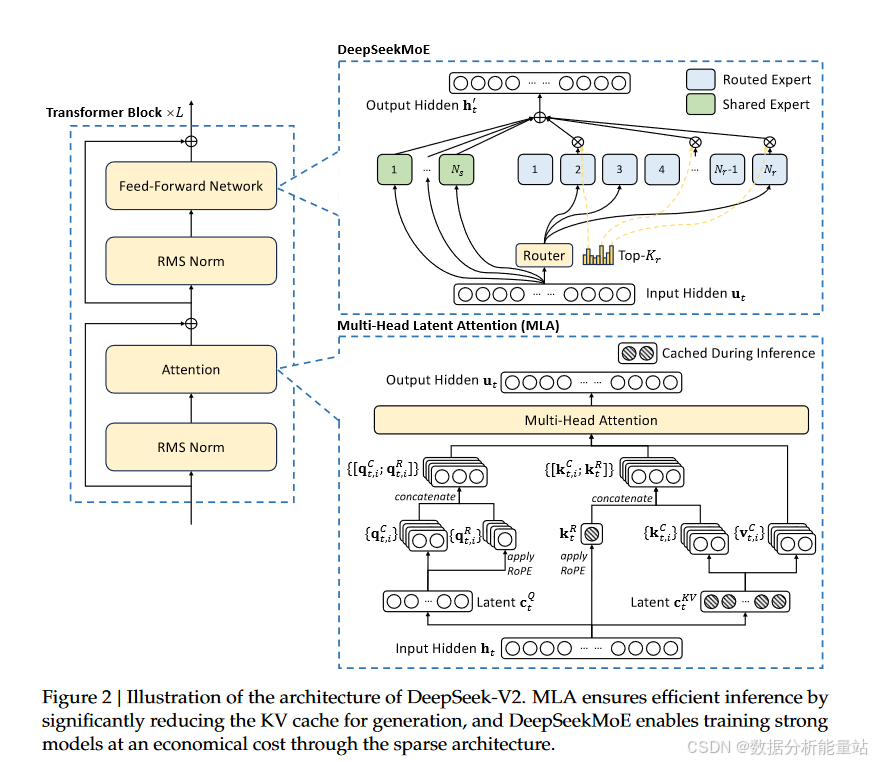
2.1 Multi-Head Latent Attention: Boosting Inference Efficiency
传统的Transformer模型通常采用多头注意力(MHA)(Vaswani等人,2017),但在生成任务中,其庞大的键值(KV)缓存会成为限制推理效率的瓶颈。为了减少KV缓存,提出了多查询注意力(MQA)(Shazeer, 2019)和分组查询注意力(GQA)(Ainslie等人,2023)。这些方法所需的KV缓存规模较小,但它们的性能无法与MHA相媲美(我们在附录D.1中提供了MHA、GQA和MQA的消融实验)。
对于DeepSeek-V2,我们设计了一种创新的注意力机制,称为多头潜在注意力(MLA)。MLA通过低秩键值联合压缩,在性能上优于MHA,但所需的KV缓存量显著减少。我们在接下来介绍其架构,并在附录D.2中提供了MLA与MHA的对比。
Preliminaries: Standard Multi-Head Attention
1 标准多头注意力(MHA)机制的背景和原理
基本概念
-
嵌入维度(d):每个token(比如单词或字符)在模型中被表示为一个向量,其维度是 d。
-
注意力头数量(nh):多头注意力的核心思想是将注意力机制分解为多个“头”,每个头负责处理一部分信息,从而提高模型的表达能力。
-
每个头的维度(dh):每个注意力头处理的向量维度是 dh。通常,d=nh×dh,即嵌入维度等于头的数量乘以每个头的维度。
-
输入向量(ht):第 t 个token的输入向量,维度为 d。
2 MHA的计算过程
-
生成查询(Query)、键(Key)和值(Value)
-
通过三个线性变换矩阵 WQ、WK 和 WV,将输入向量 ht 分别转换为查询向量 qt、键向量 kt 和值向量 vt。
-
这三个矩阵的维度是 dh×nh×d,输出的 qt、kt 和 vt 的维度是 dh×nh。
-
公式(1)、(2)和(3)描述了这一过程。
-
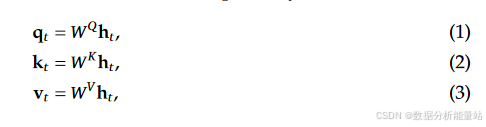
-
将向量划分为多个头
-
将 qt、kt 和 vt 划分为 nh 个头,每个头的维度是 dh。
-
公式(4)、(5)和(6)表示这一划分过程。
-

-
计算注意力输出
-
对于每个头 i,计算当前token t 的输出 ot,i:
-
首先,计算当前token的查询向量 qt,i 与之前所有token的键向量 kj,i 的点积(公式7中的 qt,iTkj,i)。
-
然后,通过Softmax函数对点积结果进行归一化,得到注意力权重。
-
最后,将注意力权重与对应的值向量 vj,i 相乘并求和,得到当前头的输出 ot,i。
-
-
将所有头的输出拼接起来,再通过一个输出投影矩阵 WO 转换为最终的输出 ut(公式8)。
3 MHA在推理中的问题
KV缓存的瓶颈
-
在推理过程中,为了加速计算,模型需要缓存之前所有token的键(Key)和值(Value)。
-
对于每个token,需要缓存的KV元素数量为 2×nh×dh×l,其中 l 是序列长度。
-
这种庞大的缓存需求会显著增加内存占用,限制了模型在实际部署中的最大批量大小和序列长度。
总结
标准多头注意力(MHA)是Transformer架构的核心,它通过多个注意力头并行计算,能够捕捉复杂的模式和关系。然而,MHA在推理时需要缓存大量的键值对(KV缓存),这会导致内存占用过高,成为模型部署中的一个主要瓶颈。为了解决这一问题,研究人员提出了多种改进方法,比如多查询注意力(MQA)和分组查询注意力(GQA),但这些方法在减少缓存的同时可能会牺牲一些性能。DeepSeek-V2则通过引入多头潜在注意力(MLA)机制,既减少了KV缓存,又保持了高性能。
Low-Rank Key-Value Joint Compression
1 低秩键值联合压缩(Low-Rank Key-Value Joint Compression)
在传统的多头注意力(MHA)中,每个token的键(Key)和值(Value)需要被缓存,以便在推理时快速计算注意力权重。然而,键和值的缓存会占用大量内存,尤其是在处理长序列时,这成为推理效率的一个瓶颈。
为了解决这个问题,MLA引入了低秩键值联合压缩技术,通过减少需要缓存的数据量来提高推理效率。
2 压缩过程
-
压缩键和值
-
对于每个token t,首先通过一个降维投影矩阵 WDKV 将输入向量 ht 压缩为一个低维的潜在向量 cKV,t:
-
cKV,t=WDKVht
-
这里的 cKV,t 是压缩后的键和值的联合表示,其维度为 dc,远小于传统的 dh×nh(即每个头的维度乘以头的数量)。
-
-
恢复键和值
-
接下来,通过两个升维投影矩阵 WUK 和 WUV,分别将 cKV,t 恢复为键 kC,t 和值 vC,t:
-
kC,t=WUKcKV,tvC,t=WUVcKV,t
-
这样,键和值的维度被恢复为 dh×nh,与传统MHA的输出维度一致。
-
推理时的优势
-
在推理过程中,MLA只需要缓存压缩后的潜在向量 cKV,t,而不是完整的键和值。
-
因此,KV缓存的大小从 2×dh×nh×l 降低到 dc×l,其中 l 是序列长度。
-
由于 dc 远小于 dh×nh,这大大减少了内存占用。
进一步优化
-
在推理时,矩阵 WUK 和 WUV 可以分别被吸收进 WQ 和 WO 中,这意味着在实际计算中,我们甚至不需要显式地计算键和值,进一步减少了计算量。
3 低秩查询压缩(Low-Rank Query Compression)
除了键和值的缓存问题,查询(Query)的计算也会占用大量内存,尤其是在训练过程中。为了减少查询的激活内存,MLA还引入了低秩查询压缩。
压缩过程
-
压缩查询
-
对于每个token t,通过一个降维投影矩阵 WDQ 将输入向量 ht 压缩为一个低维的潜在向量 cQ,t:
-
cQ,t=WDQht
-
这里的 cQ,t 是压缩后的查询表示,其维度为 dc′,远小于 dh×nh。
-
-
恢复查询
-
接下来,通过一个升维投影矩阵 WUQ,将 cQ,t 恢复为查询 qC,t:
-
qC,t=WUQcQ,t
-
这样,查询的维度被恢复为 dh×nh,与传统MHA的输出维度一致。
-
作用
-
低秩查询压缩的主要目的是减少训练过程中的激活内存,而不是减少KV缓存。
-
通过这种方式,模型可以在训练时更高效地利用内存,从而支持更大的模型和更长的序列。
MLA通过低秩键值联合压缩和低秩查询压缩,显著减少了推理和训练过程中的内存占用:
-
低秩键值联合压缩:通过将键和值压缩为低维的潜在向量,减少了KV缓存的大小,从而提高了推理效率。
-
低秩查询压缩:通过将查询压缩为低维的潜在向量,减少了训练过程中的激活内存,提高了训练效率。
这种设计不仅优化了模型的推理性能,还保持了与传统多头注意力相当的性能,是DeepSeek-V2高效推理的关键技术之一。
Decoupled Rotary Position Embedding
1 问题背景:RoPE与低秩压缩的冲突
RoPE的作用
RoPE(旋转位置嵌入)是一种用于处理位置信息的方法,它通过将位置信息嵌入到键(Key)和查询(Query)中,使得模型能够更好地捕捉长距离依赖关系。RoPE的一个关键特性是位置敏感性,即每个位置的键和查询都会根据其位置信息进行调整。
低秩压缩的限制
在MLA中,为了减少KV缓存的大小,键和值被压缩为低秩的潜在向量(cKV,t)。在推理时,通过升维投影矩阵(如 WUK)将这些潜在向量恢复为完整的键和值。然而,这种压缩和恢复的过程有一个重要的假设:升维矩阵(如 WUK)可以被吸收进其他矩阵(如 WQ)中,从而避免显式计算键和值。
冲突点
如果将RoPE应用于键(kC,t),RoPE矩阵会与升维矩阵 WUK 耦合。由于RoPE矩阵是位置敏感的,它会根据当前生成的token动态变化。这导致 WUK 无法再被吸收进 WQ,因为矩阵乘法不满足交换律(即 A×B=B×A)。因此,模型在推理时需要重新计算所有前缀token的键,这会显著降低推理效率。
2 解决方案:分离式RoPE策略
为了解决上述冲突,MLA引入了一种新的策略——分离式RoPE(Decoupled RoPE)。其核心思想是将RoPE的作用与低秩压缩的键值分离,从而避免耦合问题。
分离式RoPE的设计
-
额外的查询和共享键
-
引入一组额外的多头查询 qR,t,i 和一个共享键 kR,t,专门用于承载RoPE的位置信息。
-
这些额外的查询和共享键的维度为 dRh,表示每个头的分离维度。
-
-
计算过程
-
额外的查询 qR,t 通过矩阵 WQR 生成,并应用RoPE:
-
qR,t=RoPE(WQRcQ,t)
-
共享键 kR,t 通过矩阵 WKR 生成,并应用RoPE:
-
kR,t=RoPE(WKRht)
-
-
拼接操作
-
将低秩压缩的查询 qC,t,i 和额外的查询 qR,t,i 拼接起来,形成完整的查询:
-
qt,i=[qC,t,i;qR,t,i]
-



















