目录
摘要
Abstract
DeepPose
算法框架
损失函数
创新点
局限性
训练过程
代码
总结
摘要
DeepPose是首个将CNN应用于姿态估计任务的模型。该模型在传统姿态估计方法的基础上,通过端到端的方式直接从图像中回归出人体关键点的二维坐标,避免了复杂的特征工程。DeepPose将姿态估计问题建模为一个回归问题,利用CNN提取图像特征,并通过全连接层直接预测关键点坐标。模型还引入了级联回归策略,通过多阶段优化逐步细化关键点位置,显著提高了预测精度。DeepPose在LSP和FLIC数据集上取得了当时最优的性能,为后续基于深度学习的人体姿态估计方法奠定了基础。尽管其在处理遮挡和复杂背景时存在一定局限性,但其端到端回归的思想和级联回归的策略对后续研究产生了深远影响,推动了人体姿态估计领域的发展。
Abstract
DeepPose is the first model to apply CNNs to the task of pose estimation. Building on traditional pose estimation methods, the model directly regresses the 2D coordinates of human keypoints from images in an end-to-end manner, avoiding complex feature engineering. DeepPose formulates pose estimation as a regression problem, leveraging CNNs to extract image features and using fully connected layers to directly predict keypoint coordinates. The model also introduces a cascaded regression strategy, refining keypoint locations through multi-stage optimization, which significantly improves prediction accuracy. DeepPose achieved state-of-the-art performance on the LSP and FLIC datasets at the time, laying the foundation for subsequent deep learning-based human pose estimation methods. Although it has certain limitations in handling occlusions and complex backgrounds, its end-to-end regression approach and cascaded regression strategy have had a profound impact on follow-up research, driving advancements in the field of human pose estimation.
DeepPose
论文地址:[1312.4659] DeepPose: Human Pose Estimation via Deep Neural Networks

DeepPose是由Google在2014年提出的一种基于深度学习的人体姿态估计算法,是首个将CNN应用于姿态估计任务的工作。该算法通过端到端的方式直接从图像中回归出人体关键点的二维坐标,避免了传统方法中复杂的特征工程和模型设计。
姿态估计的目标是从输入图像中检测出人体的关键点,如:关节点的位置,并将其表示为二维坐标。DeepPose将这一问题建模为一个回归问题,即通过神经网络直接从图像中回归出关键点的坐标。
算法框架
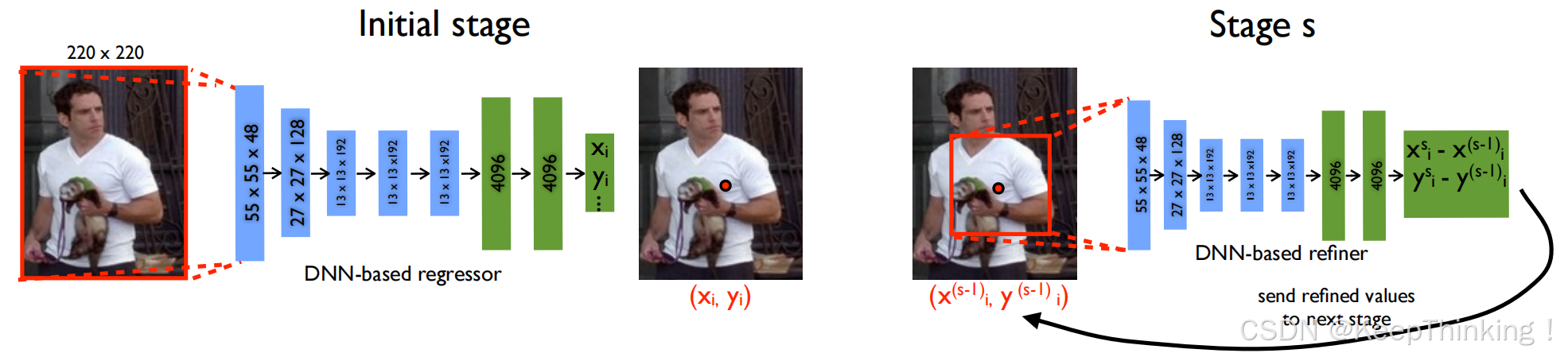
DeepPose的整体框架基于卷积神经网络,其核心思想是通过CNN提取图像特征,然后通过全连接层直接回归出关键点的坐标。
(1) 输入
输入为RGB图像,通常会被缩放到固定大小,如上图 220 x 220 。图像中通常包含一个人体实例。
(2) 特征提取(Backbone)
DeepPose使用AlexNet作为特征提取器:
首先,通过卷积层提取图像的局部特征;再经过池化层降低特征图的空间维度;最后,通过激活函数引入非线性。通过多层卷积和池化操作,模型逐渐提取出高层次的语义特征。
(3) 全局特征表示
经过卷积和池化后,特征图被展平为固定长度一维向量,作为全局特征表示。
(4) 关键点回归
在全局特征的基础上,DeepPose使用全连接层直接回归出关键点的坐标。假设需要预测的关键点数量为K,则全连接层的输出维度为2K,即每个关键点对应一个二维坐标。
使用L2损失函数最小化预测坐标与真实坐标之间的误差。
(5) 输出
模型的输出是一个长度为2K的向量,表示K个关键点的坐标。例如,对于人体姿态估计,K可以是14,如:头、肩、肘、腕等关键点。
参数传递过程:
Name Filter Size(WHC)/Stride Input Shape(WHC) Output Conv 11x11x96/4 224x224x3 55x55x96 LRN None 55x55x96 55x55x96 MaxP 2x2/2 55x55x96 27x27x96 Conv 5x5x256/1 27x27x96 27x27x256 LRN None 27x27x256 27x27x256 MaxP 2x2/2 27x27x256 13x13x256 Conv 3x3x384/1 13x13x256 13x13x384 Conv 3x3x384/1 13x13x384 13x13x384 Conv 3x3x256/1 13x13x384 13x13x256 MaxP 2x2/2 13x13x256 6x6x256 Flatten \ 6x6x256 4096x1 \ \ 4096x1 4096x1 \ \ 4096x1 4096x1 \ \ 4096x1 2xk
损失函数
DeepPose使用L2损失函数来衡量预测坐标与真实坐标之间的差异:
是第 i 个关键点的真实坐标;
是第 i 个关键点的预测坐标。
创新点
首次将CNN引入姿态估计:DeepPose是第一个将深度卷积神经网络应用于姿态估计任务的工作,开创了基于深度学习的人体姿态估计方法;
端到端回归:直接回归关键点坐标,避免了传统方法中复杂的特征工程和模型设计;
级联回归:通过多阶段回归逐步优化关键点的位置,提高了预测精度。
局限性
对遮挡和复杂背景的鲁棒性较差:由于直接回归坐标,模型在处理遮挡或复杂背景时表现不佳;
计算复杂度较高:全连接层的参数量较大,导致模型的计算复杂度较高;
依赖大规模标注数据:模型的性能高度依赖于大量精确标注的训练数据。
训练过程
数据增强:为了提高模型的鲁棒性,训练时会对输入图像进行数据增强,如:旋转、缩放、翻转等;
端到端训练:模型通过反向传播算法进行端到端训练,优化CNN和全连接层的参数;
多阶段训练:DeepPose还提出了一种级联回归的方法,即通过多个阶段的回归逐步细化关键点的位置。
代码
- 模型构建
DeepPose的模型结构包括一个CNN特征提取器和一个全连接回归器。以下是PyTorch的实现代码:
import torch
import torch.nn as nn
import torchvision.models as models
class DeepPose(nn.Module):
def __init__(self, num_keypoints):
super(DeepPose, self).__init__()
# 使用预训练的AlexNet作为特征提取器
self.backbone = models.alexnet(pretrained=True)
# 替换最后的分类层为回归层
self.backbone.classifier = nn.Sequential(
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_keypoints * 2) # 输出关键点的坐标 (x, y)
)
def forward(self, x):
return self.backbone(x)Backbone:使用预训练的AlexNet作为特征提取器,移除最后的分类层;
回归层:将AlexNet的全连接层替换为回归层,输出维度为num_keypoints * 2,表示每个关键点的(x, y)坐标;
前向传播:输入图像通过CNN提取特征,最终输出关键点坐标。
- 数据预处理
DeepPose的输入是图像和对应的关键点坐标标签。需要对数据进行预处理,包括图像缩放、归一化和数据增强。
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import cv2
import numpy as np
class PoseDataset(Dataset):
def __init__(self, image_paths, keypoints, transform=None):
self.image_paths = image_paths
self.keypoints = keypoints
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = cv2.imread(self.image_paths[idx])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
keypoints = self.keypoints[idx]
if self.transform:
image = self.transform(image)
return image, torch.tensor(keypoints, dtype=torch.float32)
# 数据预处理
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 示例数据
image_paths = ["image1.jpg", "image2.jpg"]
keypoints = [[[x1, y1], [x2, y2], ...], [[x1, y1], [x2, y2], ...]] # 关键点坐标
dataset = PoseDataset(image_paths, keypoints, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)PoseDataset:自定义数据集类,加载图像和关键点坐标;
数据增强:使用transforms对图像进行缩放、归一化等操作;
DataLoader:将数据集封装为批量数据,用于训练。
- 训练过程
训练过程包括定义损失函数、优化器和训练循环。
# 初始化模型
model = DeepPose(num_keypoints=14) # 假设预测14个关键点
criterion = nn.MSELoss() # 使用均方误差损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for images, targets in dataloader:
# 前向传播
outputs = model(images)
loss = criterion(outputs, targets.view(-1, 14 * 2)) # 计算损失
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")损失函数:使用MSE衡量预测坐标与真实坐标的差异;
优化器:使用Adam优化器更新模型参数;
训练循环:逐批次训练模型,输出每个epoch的损失。
- 推理过程
训练完成后,可以使用模型对新的图像进行关键点预测。
# 加载训练好的模型
model.load_state_dict(torch.load("deep_pose_model.pth"))
model.eval()
# 推理
with torch.no_grad():
test_image = cv2.imread("test_image.jpg")
test_image = transform(test_image).unsqueeze(0) # 预处理并增加batch维度
predicted_keypoints = model(test_image)
print("Predicted Keypoints:", predicted_keypoints)加载模型:加载训练好的模型权重;
推理:对输入图像进行预处理,并通过模型预测关键点坐标。
输入图像:

测试结果:

总结
DeepPose是首个将CNN应用于人体姿态估计任务的模型,标志着深度学习在该领域的突破性应用。其核心贡献在于将姿态估计问题建模为端到端的回归任务,通过CNN提取特征并直接预测关键点坐标,避免了传统方法中复杂的特征工程。DeepPose还引入了级联回归策略,通过多阶段优化逐步提升关键点定位精度。在LSP和FLIC等标准数据集上,DeepPose取得了当时最优的性能,为后续研究奠定了基础。尽管在处理遮挡和复杂背景时存在局限性,但其端到端回归思想和级联优化策略对后续工作产生了深远影响,推动了基于深度学习的人体姿态估计方法,如:热图回归、图模型和Transformer等的快速发展。
![[HarmonyOS]鸿蒙(添加服务卡片)推荐商品 修改卡片UI(内容)](https://i-blog.csdnimg.cn/direct/c539a3c420ee4ea3a72013376e8b48ed.png)











![[Spring Boot] Expense API 实现](https://i-blog.csdnimg.cn/direct/dbd245745f474e819b3206713fa7a83f.png)






