前面内容:pandas(10 日期和Timedelta)
目录
一、Python Pandas 分类数据
1.1 pd.Categorical()
1.2 describe()
1.3 获取类别的属性
1.4 分类操作
1.5 分类数据的比较
二、Python Pandas 数据可视化
2.1 基础绘图:plot
2.2 条形图
2.3 直方图
2.4 箱线图
2.5 面积图
2.6 散点图
2.7 饼图
一、Python Pandas 分类数据
在 pandas 中,分类数据(Categorical data) 是一种特殊的数据类型,它通过将数据分为不同的类别来有效地减少内存使用并提高性能。它在处理具有有限数量的可能值(如性别、状态、等级等)的列时非常有用。
对象创建
分类对象可以通过多种方式创建。以下是不同的方式描述:
分类
在Pandas对象创建时,将dtype指定为”category”。
例1:
import pandas as pd
s = pd.Series(["a","b","c","a"], dtype="category")
print(s)运行结果:

传递给系列对象的元素数量是四个,但类别只有三个。观察输出的类别。
创建分类数据
你可以使用 pandas.Categorical 或 Series.astype('category') 方法将数据转换为分类类型。
1.1 pd.Categorical()
pd.Categorical() 是 pandas 库中的一个功能强大的函数,用于将数据转换为分类类型。
pd.Categorical()语法
pd.Categorical(values, categories=None, ordered=False, dtype=None)参数:
- values: 要转换为分类类型的数据,可以是列表、numpy 数组或者 pandas Series。
- categories: 一个列表,指定分类的取值。如果没有提供,pandas 会自动推断这些类别。
- ordered: 布尔值(默认为
False)。如果设置为True,表示类别之间有顺序(可以进行大于、小于等比较操作)。 - dtype: 可选的,指定分类的类型,例如
category。
例1.2:pd.Categorical()
import pandas as pd
cat = pd.Categorical(['a', 'b', 'c', 'a', 'b', 'c'])
print cat运行结果:
![]()
例1.2 :
import pandas as pd
cat = cat=pd.Categorical(['a','b','c','a','b','c','d'], ['c', 'b', 'a'])
print(cat)运行结果:
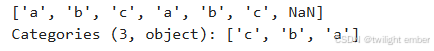
例1.3: ordered = True
import pandas as pd
cat = cat=pd.Categorical(['a','b','c','a','b','c','d'], ['c', 'b', 'a'],ordered=True)
print(cat)运行结果:
![]()
1.2 describe()
在分类数据上使用 .describe() 命令,我们得到与 Series 或 DataFrame 类型的字符串相似的输出。
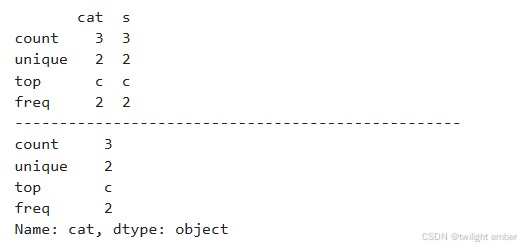
例1.4: df.describe()
import pandas as pd
import numpy as np
cat = pd.Categorical(["a", "c", "c", np.nan], categories=["b", "a", "c"])
df = pd.DataFrame({"cat":cat, "s":["a", "c", "c", np.nan]})
print(df.describe())
print('-'*50)
print(df["cat"].describe())运行结果:
1.3 获取类别的属性
obj.cat.categories 命令用于获取对象的 类别 。
例1.5:返回分类数据的类别列表
import pandas as pd
import numpy as np
s = pd.Categorical(["a", "c", "c", np.nan], categories=["b", "a", "c"])
print(s.categories)运行结果:
![]()
例1.6: 否有顺序
import pandas as pd
import numpy as np
cat = pd.Categorical(["a", "c", "c", np.nan], categories=["b", "a", "c"])
print(cat.ordered)运行结果:
![]()
1.4 分类操作
通过为 series.cat.categories 属性赋新值来重命名分类。
例1.7: 重命名分类
import pandas as pd
# 创建一个包含分类数据的 Series
s = pd.Series(["a", "b", "c", "a"], dtype="category")
# 获取当前类别,并修改它
new_categories = ["Group %s" % g for g in s.cat.categories]
# 使用新的类别创建一个新的 Categorical 类型
s = pd.Series(s.cat.codes, dtype=pd.CategoricalDtype(categories=new_categories, ordered=False))
# 打印更新后的类别
print(s.cat.categories)
运行结果:
![]()
例1.8:添加新类别
import pandas as pd
s = pd.Series(["a","b","c","a"], dtype="category")
s = s.cat.add_categories([4])
print(s.cat.categories)运行结果:
![]()
例1.9 :移除分类
使用 Categorical.remove_categories() 方法,可以移除不需要的分类。
import pandas as pd
s = pd.Series(["a","b","c","a"], dtype="category")
print(s)
print('-'*50)
print(s.cat.remove_categories("a"))运行结果:
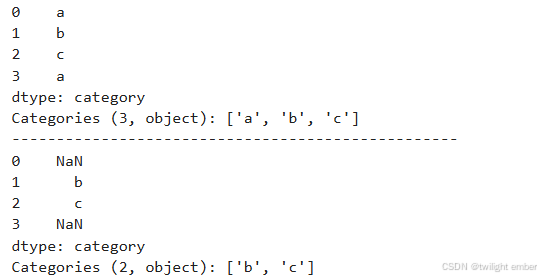
1.5 分类数据的比较
在 pandas 中,分类数据(Categorical 类型)支持比较操作,特别是当你使用有序类别(ordered=True)时,能够进行基于顺序的比较,例如 <、>、== 等。分类数据通常用于具有有限、固定类别的数据,并且在处理时可以提高性能,特别是当类别数据具有某种顺序时。
分类数据比较的基本操作
-
无序类别比较(
ordered=False): 如果分类数据是无序的,不能进行大小比较,但可以检查是否相等。 -
有序类别比较(
ordered=True): 如果分类数据是有序的(即ordered=True),则可以执行基于顺序的比较。
例1.10:
import pandas as pd
# 创建 Categorical 类型的 dtype,并指定类别和顺序
cat_dtype = pd.CategoricalDtype(categories=[1, 2, 3], ordered=True)
# 创建第一个 Series
cat = pd.Series([1, 2, 3]).astype(cat_dtype)
# 创建第二个 Series
cat1 = pd.Series([2, 2, 2]).astype(cat_dtype)
# 进行比较
print(cat > cat1)运行结果:

二、Python Pandas 数据可视化
2.1 基础绘图:plot
这个功能在Series和DataFrame上只是一个对matplotlib库plot()方法的简单封装。
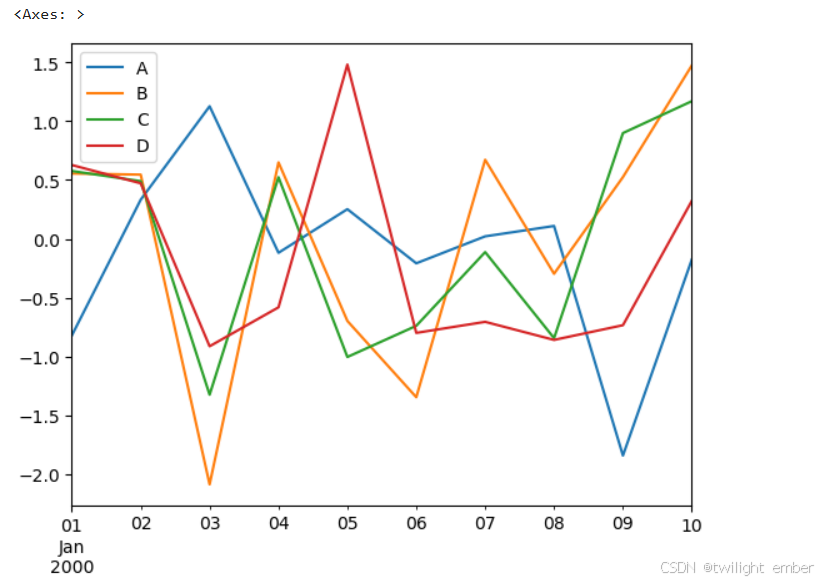
例1:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10,4),index=pd.date_range('1/1/2000',
periods=10), columns=list('ABCD'))
df.plot()运行结果:
2.2 条形图
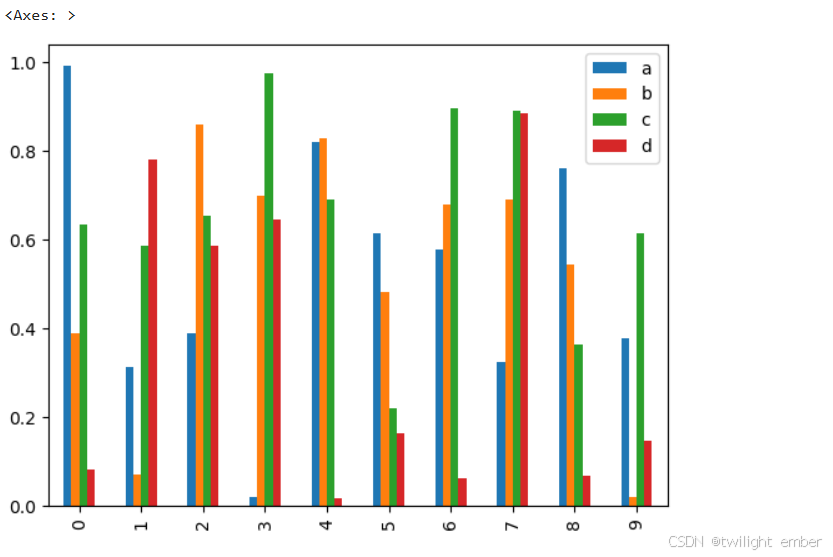
例2:条形图(.bar)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d'])
df.plot.bar()运行结果:
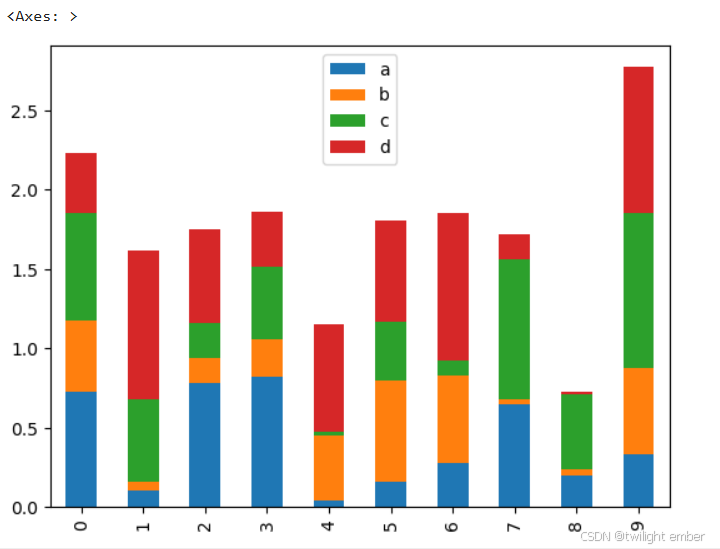
例3:可堆叠 (stacked=True)
df.plot.bar(stacked=True)运行结果:
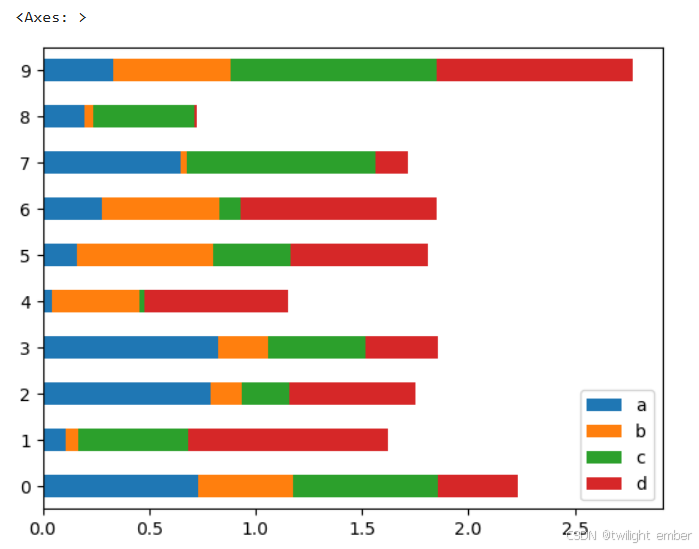
例4:横向(barh)
df.plot.barh(stacked=True)运行结果:
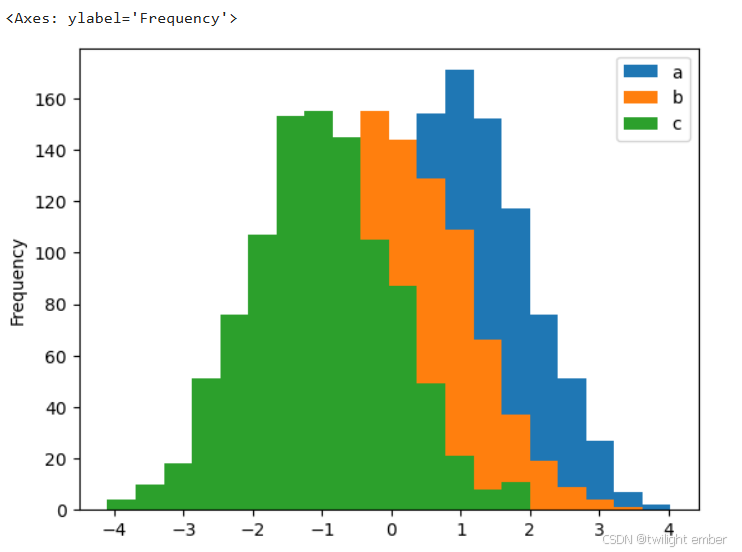
2.3 直方图
可以使用 plot.hist() 方法绘制直方图。我们可以指定条柱的数量。
例5: 直方图(hist )
import pandas as pd
import numpy as np
df = pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),'c':
np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df.plot.hist(bins=20)运行结果:
要为每列绘制不同的直方图,请使用以下代码−
例6:(.diff.hist)
import pandas as pd
import numpy as np
df=pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),'c':
np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df.diff().hist(bins=20)运行结果:
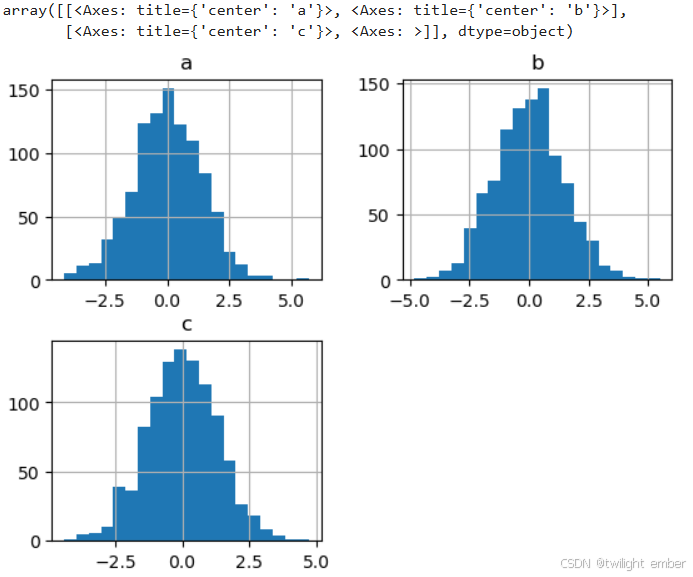
2.4 箱线图
可调用 Series.box.plot() 和 DataFrame.box.plot() ,或 DataFrame.boxplot() 来可视化每列数值的分布。
例7: 箱线图(box)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(10, 5), columns=['A', 'B', 'C', 'D', 'E'])
df.plot.box()运行结果:
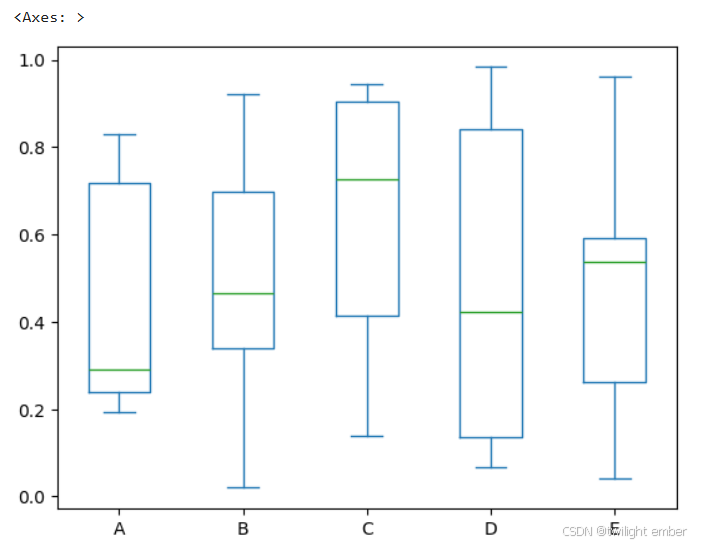
2.5 面积图
可以使用 Series.plot.area() 或 DataFrame.plot.area() 方法创建面积图。
例8:面积图(area)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df.plot.area()运行结果:
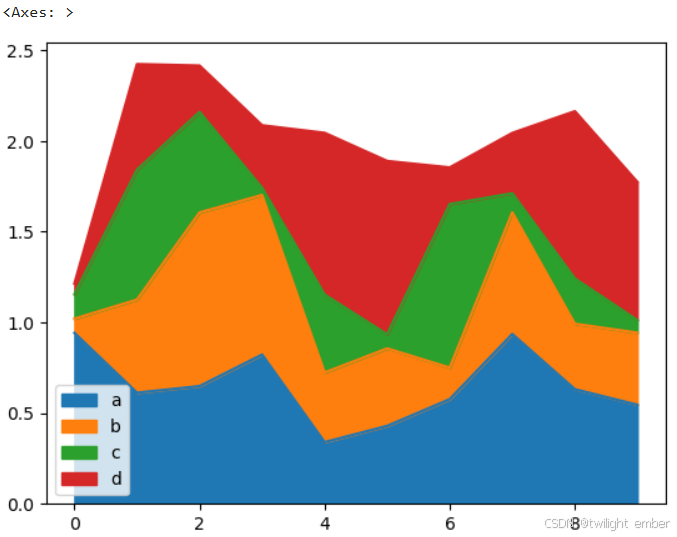
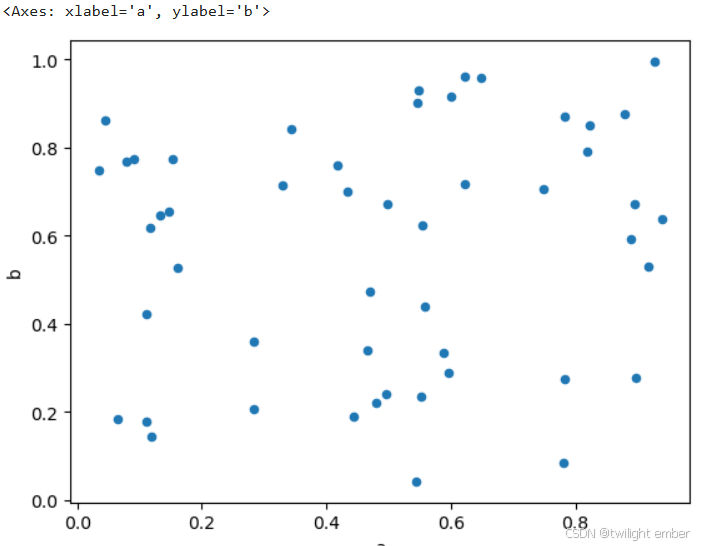
2.6 散点图
可以使用 DataFrame.plot.scatter() 方法来创建散点图。
例9:散点图(scatter)
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot.scatter(x='a', y='b')运行结果:
2.7 饼图
例10:饼图(pie)
import pandas as pd
import numpy as np
df = pd.DataFrame(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], columns=['x'])
df.plot.pie(subplots=True)subplots=True 参数用于在绘制多个图形时将每一列或每一行的图形绘制到不同的子图(subplot)中。这样可以帮助你在同一画布上并排展示多个图形。
此外,饼图必须 subplots=True
运行结果:




















