点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
A Bayesian Approach to Harnessing the Power of LLMs in Authorship Attribution
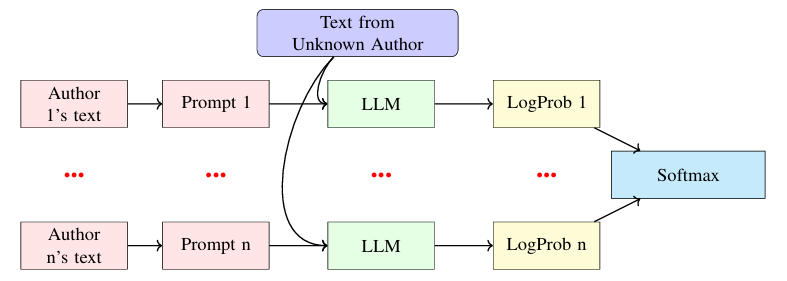
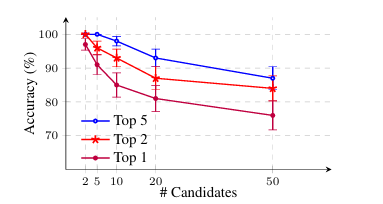
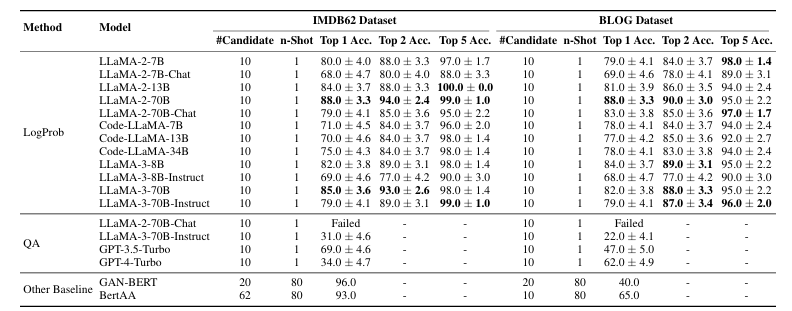
传统方法严重依赖手动特征,无法捕捉长距离相关性,限制了其有效性。最近的研究利用预训练语言模型的文本嵌入,但需要在标记数据上进行大量微调,这带来了数据依赖和可解释性有限的挑战。大型语言模型(LLMs)凭借其深度推理能力和保持长距离文本关联的能力,提供了一种有前景的替代方案。本研究探索了预训练LLMs在单次作者归属中的潜力,特别是利用贝叶斯方法和LLMs的概率输出。该方法计算文本蕴含作者以往作品的概率,反映了对作者身份更细致的理解。仅使用预训练模型如Llama-3-70B,本研究在IMDb和博客数据集上的结果显示,在十位作者的单次作者分类中达到了85%的准确率。这些发现为使用LLMs进行单次作者分析设定了新的基准,并扩大了这些模型在法医语言学中的应用范围。本研究还包括广泛的消融研究来验证该方法。


文章链接:
https://arxiv.org/pdf/2410.21716
02
FALCON: Feedback-driven Adaptive Long/short-term memory reinforced Coding Optimization system
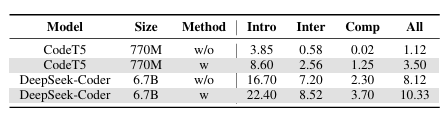
最近,大型语言模型(LLMs)在自动化代码生成方面取得了显著进展。尽管这些模型具有强大的指令遵循能力,但在编码场景中常常难以与用户意图保持一致。特别是由于数据集缺乏多样性,未能涵盖专业任务或边缘情况,导致模型在生成精准且符合人类意图的代码时遇到困难。此外,监督式微调(SFT)和基于人类反馈的强化学习(RLHF)中的挑战,也使得生成的代码无法精准对齐人类意图。为应对这些挑战并提升自动化编程系统的代码生成性能,本文提出了反馈驱动的自适应长短时记忆强化编码优化方法(即FALCON)。FALCON分为两个层级结构,从全局层面来看,长期记忆通过保留和应用已学知识来提升代码质量;从局部层面来看,短期记忆则允许将编译器和人工智能系统的即时反馈纳入其中。此外,本文引入了带有反馈奖励的元强化学习来解决全局 - 局部双层优化问题,增强模型在多样化代码生成任务中的适应性。本研究进行了大量实验,结果表明该技术达到了最先进的性能,在MBPP基准测试中比其他强化学习方法高出4.5个百分点,在Humaneval基准测试中高出6.1个百分点。
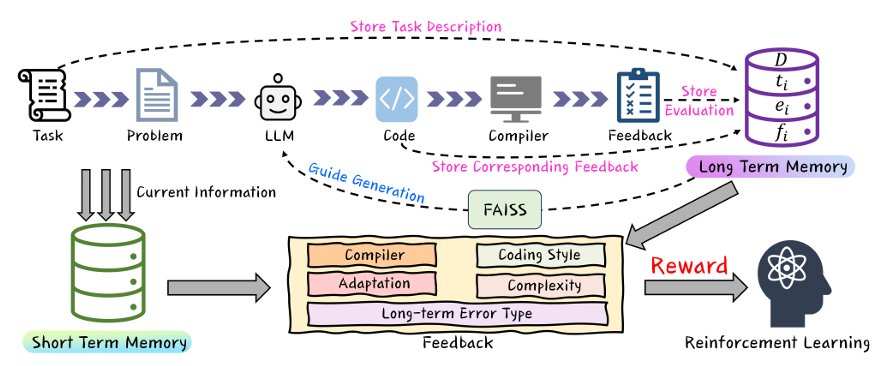
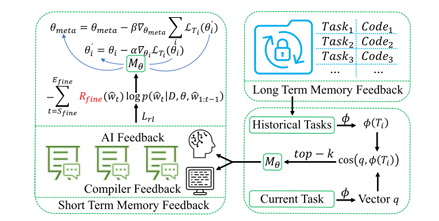
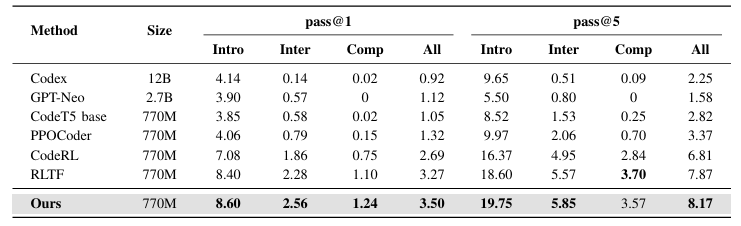
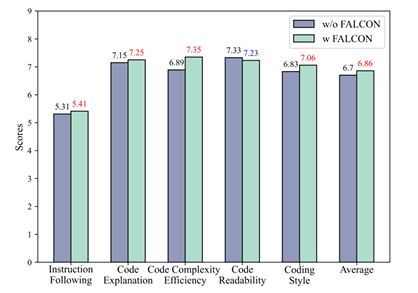
文章链接:
https://arxiv.org/pdf/2410.21349
03
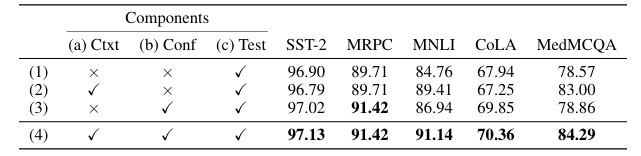
Improving In-Context Learning with Small Language Model Ensembles
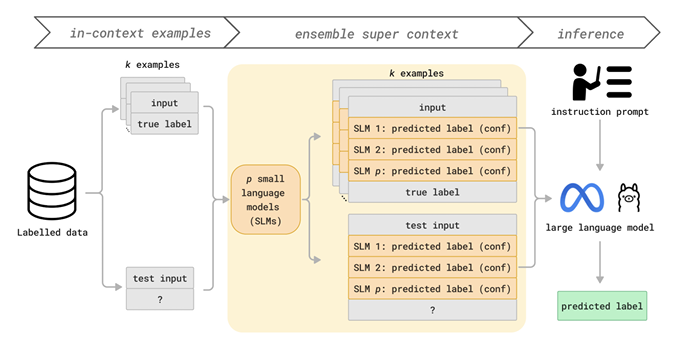
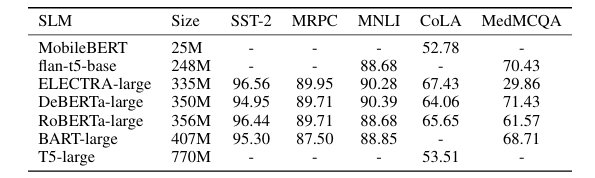
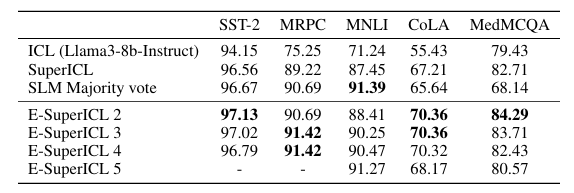
大型语言模型(LLMs)在各种任务中都展现出了令人印象深刻的性能,但在特定领域的任务上表现仍然有限。虽然检索增强生成和微调等方法可以帮助解决这一问题,但它们需要大量资源。在上下文学习(ICL)是一种廉价且高效的选择,但无法与先进方法的准确性相匹敌。本文提出了Ensemble SuperICL,这是一种新颖的方法,通过利用多个经过微调的小型语言模型(SLMs)的专业知识来增强ICL。Ensemble SuperICL在几个自然语言理解基准测试中取得了最先进的(SoTA)结果。此外,作者还在一个医学领域的标注任务上对其进行了测试,并通过使用在一般语言任务上微调的现成SLMs,展示了其实用性,在大规模数据标注中比所有基线方法都取得了更高的准确性。最后,作者进行了消融研究和敏感性分析,以阐明Ensemble SuperICL的潜在机制。本研究为LLMs中日益增长的高效领域专业化方法的需求做出了贡献,为从业者提供了一种廉价且有效的方法。
文章链接:
https://arxiv.org/pdf/2410.21868
04
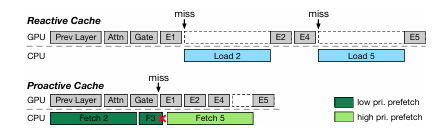
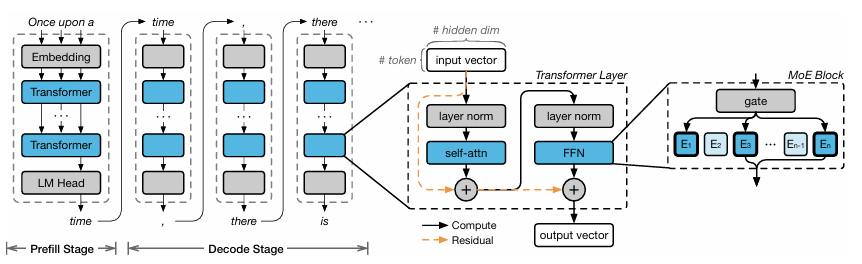
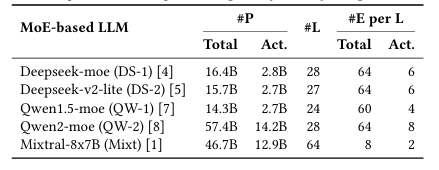
ProMoE: Fast MoE-based LLM Serving using Proactive Caching
大型语言模型的有前景的应用常常受到边缘设备上有限的GPU内存容量的限制。混合专家(MoE)模型通过在计算过程中仅激活模型参数的一个子集来缓解这一问题,允许未使用的参数被卸载到主机内存中,从而降低整体GPU内存需求。然而,现有的基于缓存的卸载解决方案是被动处理缓存未命中,并且显著影响系统性能。本文提出了PRoMoE,这是一种新颖的主动缓存系统,它利用中间模型结果来预测后续参数的使用情况。通过提前主动获取专家,PRoMoE将加载时间从关键路径中移除,并减少了卸载的性能开销。评估结果表明,与现有卸载解决方案相比,PRoMoE在预填充阶段和解码阶段分别实现了平均2.13倍和2.84倍的速度提升。
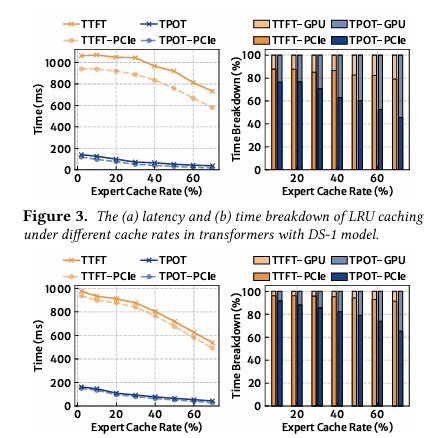
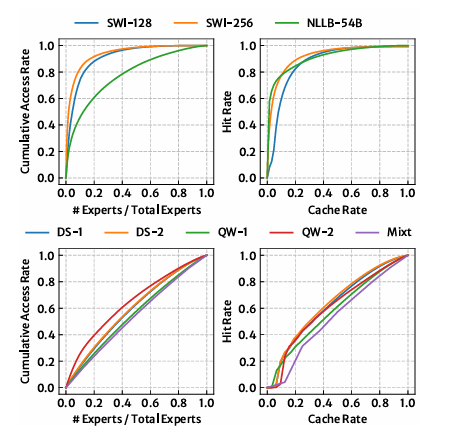
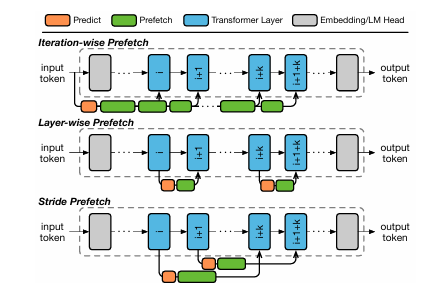
文章链接:
https://arxiv.org/pdf/2410.22134
05
Not All Languages are Equal: Insights into Multilingual Retrieval-Augmented Generation
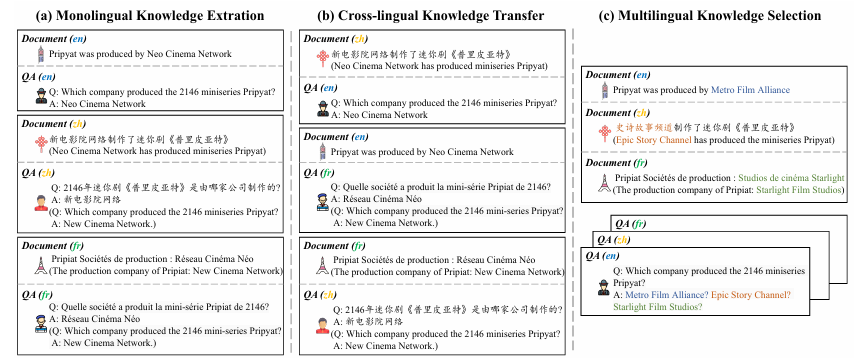
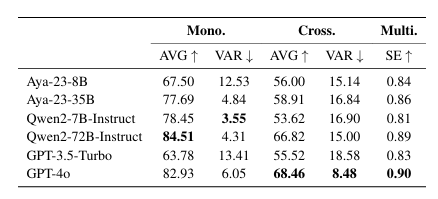
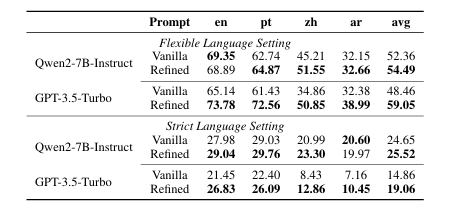
检索增强语言模型(RALMs)通过整合外部文本资源来拓展其知识范围。然而,全球知识的多语言特性要求RALMs能够处理多种语言,这一主题目前研究较少。本研究提出了Futurepedia,这是一个精心设计的基准测试,包含八种代表性语言的平行文本。作者使用该基准测试评估了六种多语言RALMs,以探索多语言RALMs面临的挑战。实验结果揭示了语言不平等现象:1)高资源语言在单语知识提取方面表现突出;2)印欧语系语言促使RALMs直接从文档中提供答案,缓解了跨语言表达答案的挑战;3)英语受益于RALMs的选择偏差,在多语言知识选择中更具影响力。基于这些发现,作者为改进多语言检索增强生成提供了建议。对于单语知识提取,必须谨慎关注将低资源语言翻译成高资源语言时的级联错误。在跨语言知识传递中,鼓励RALMs在不同语言的文档中提供答案可以提高传递性能。对于多语言知识选择,纳入更多非英语文档并重新定位英语文档有助于减轻RALMs的选择偏差。通过全面的实验,本研究强调了多语言RALMs所固有的复杂性,并为未来研究提供了有价值的见解。

文章链接:
https://arxiv.org/pdf/2410.21970
06
On Memorization of Large Language Models in Logical Reasoning
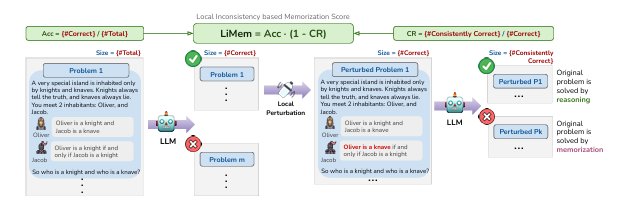
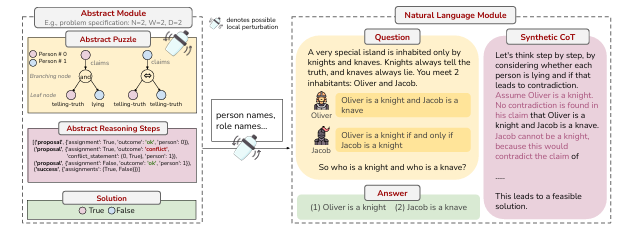
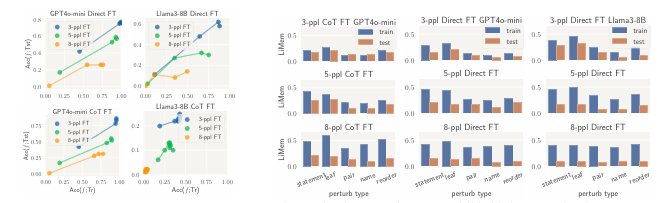
大型语言模型(LLMs)在具有挑战性的推理基准测试中表现出色,但也可能会犯一些基本的推理错误。这种矛盾的行为在理解LLMs推理能力背后的机制时令人困惑。一种假设是,LLMs在常见推理基准测试中日益提高且几乎饱和的性能可能是由于对类似问题的记忆。本文通过使用基于“骑士与无赖”(Knights and Knaves,简称K&K)谜题的动态生成逻辑推理基准测试,对这一假设进行了系统的定量记忆测量研究。研究发现,经过微调后,LLMs能够内插训练谜题(几乎达到完美准确率),但当这些谜题稍作扰动时,模型就会失败,这表明模型在解决这些训练谜题时严重依赖记忆。另一方面,研究表明,尽管微调导致了大量记忆,但也始终提高了泛化性能。通过扰动测试、跨难度级别的可转移性分析、探测模型内部结构以及使用错误答案进行微调等深入分析表明,尽管存在训练数据记忆,LLMs仍然学会了对K&K谜题进行推理。这一现象表明,LLMs在记忆和真正的推理能力之间表现出复杂的相互作用。最后,基于每个样本的记忆分数的分析揭示了LLMs在解决逻辑谜题时如何在推理和记忆之间切换。

文章链接:
https://arxiv.org/pdf/2410.23123
07
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
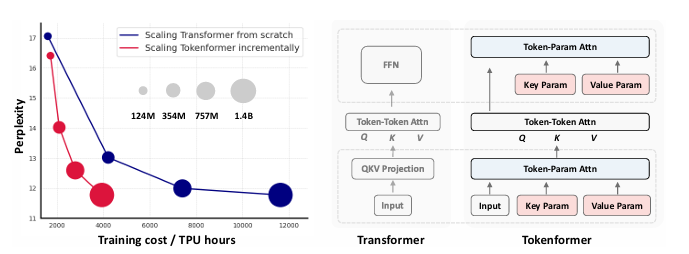
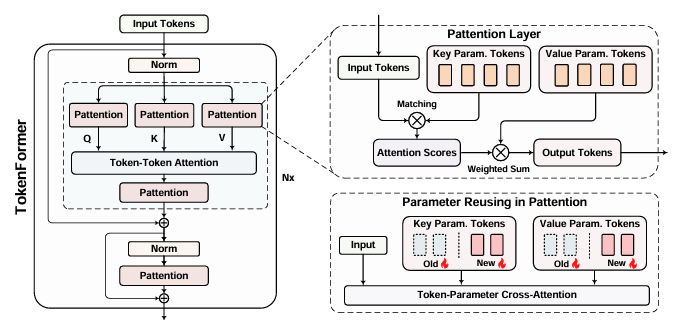
Transformer已成为基础模型中的主导架构,因其在各个领域的出色表现。然而,扩展这些模型的巨大成本仍然是一个重大问题。这一问题主要源于其对线性投影中固定参数数量的依赖。当引入架构修改(例如,通道维度)时,通常需要从头开始重新训练整个模型。随着模型规模的持续增长,这种策略导致计算成本越来越高,变得不可持续。为了解决这一问题,本文介绍了Tokenformer,这是一种原生可扩展的架构,它不仅利用注意力机制进行输入标记之间的计算,还用于标记与模型参数之间的交互,从而增强了架构的灵活性。通过将模型参数视为标记,本文用token-parameter注意力层替换了Transformer中的所有线性投影,其中输入标记作为查询,模型参数作为键和值。这种重新表述允许逐步且高效地扩展,而无需从头开始重新训练。该模型通过逐步添加新的键值参数对,从1.24亿参数扩展到14亿参数,实现了与从头开始训练的Transformer相当的性能,同时大大降低了训练成本。
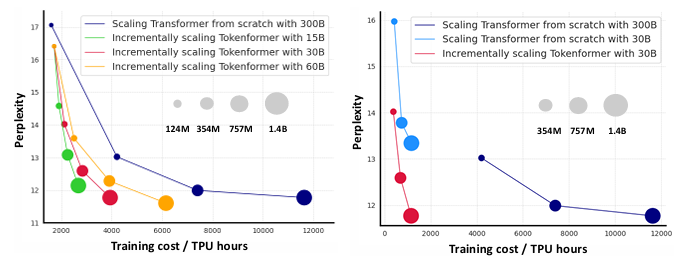
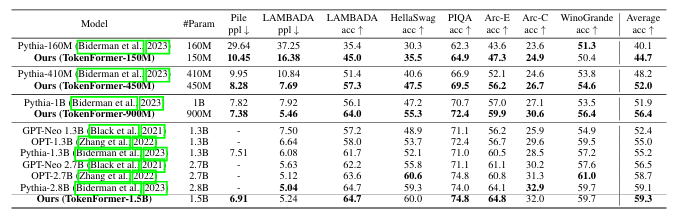
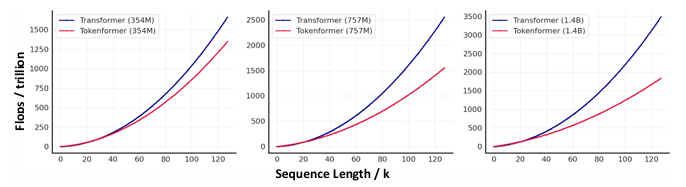
文章链接:
https://arxiv.org/pdf/2410.23168
本期文章由陈研整理
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!