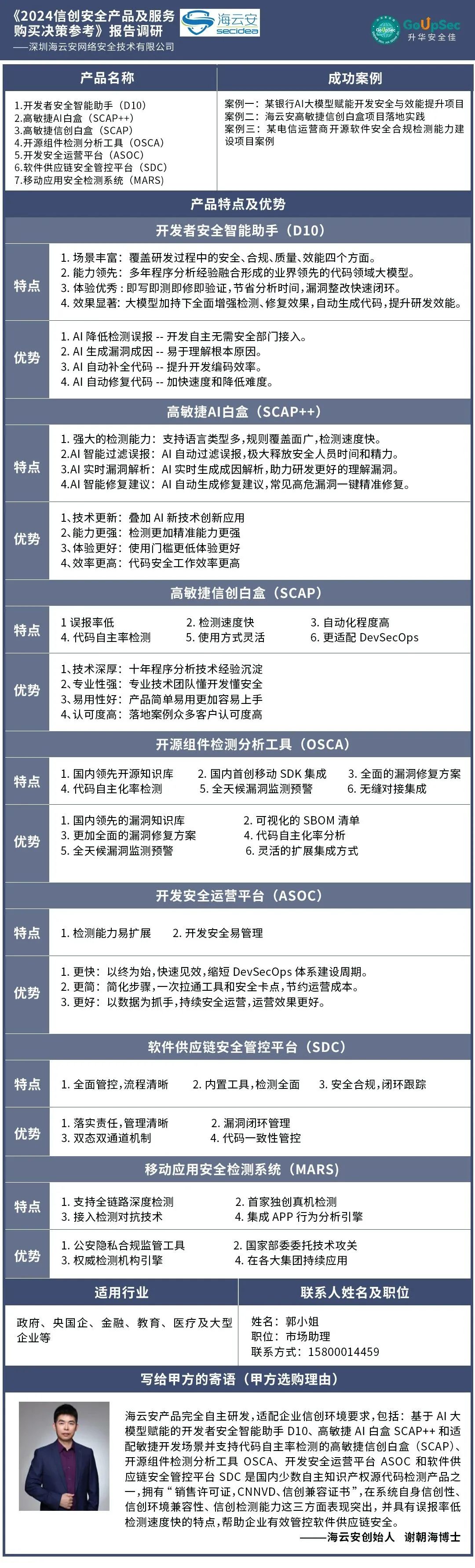
一、文字表示方法
在自然语言处理中,如何用数据表示文字是基础问题。独热编码(One-hot Encoding )是一种简单的方法,例如对于 “我”“你”“他”“猫”“狗” 等字,会将其编码为如 “我 = [1 0 0 0 0 ……]”“你 = [0 1 0 0 0 ……]” 的形式。这种编码方式存在明显缺陷,一方面,其维度取决于汉字个数,通常会很长;另一方面,它无法体现出字词之间的语义关系。
Word Embedding 则是让模型自己学习文字的向量表示。通过训练,每个字或词都能得到一个相对低维且能在一定程度上反映其语义特征的向量,相比 One-hot Encoding 更具优势。

二、常见输出
在自然语言处理任务中,常见的输出有以下几种情况:
① 词性识别任务(每个词都输出一个值):针对输入文本中的每个词,模型输出其对应的词性。例如对于句子 “我 爱 你”,模型会分别输出 “代词”“动词”“代词” 等词性标签。这里每个词都有对应的输出值,且输出的词性标签数量与输入词的数量相同。

② 情感分类(所有词输出一个值):模型对输入的文本进行情感判断,输出为正向或负向等情感类别。例如对于句子 “你做的不错”,模型可能输出正向情感;而对于 “唉,又又又 emo 了”,则可能输出负向情感。在这种任务中,通常是对整个文本进行分析后得出一个单一的情感类别作为输出。

③ 翻译任务(输出长度不对应):输入一种语言的文本,模型输出另一种语言的翻译结果。如输入 “我爱中国”,输出 “I love China”。在这类任务中,输出的文本长度通常与输入文本长度没有固定的对应关系,模型需要根据对源语言文本的理解生成符合目标语言语法和语义的翻译文本。

三、传统模型局限及自注意力机制引入
(一)RNN 和 LSTM
1、循环神经网络(RNN)
在 RNN 运行过程中,其隐藏状态会在不同时间步之间传递信息,就像在传递一个家族的 “传家宝”(可以理解为向量、记忆单元) 一样,不断积累和更新与序列相关的信息。它帮助模型记住之前的输入内容,以便更好地处理当前输入并预测后续输出。

但是,当句子中的无效信息太多的时候,或者是处理长序列的时候,RNN会出现信息混乱或者丢失的情况,于是我们便引入了长短期记忆(LSTM)。

2、长短期记忆(LSTM)
在长短期记忆网络(LSTM)里,有几个重要的 “门” 来帮助它处理信息:
-
遗忘门:
- 想象你在学习一个故事,这个门就像是一个过滤器,它会根据当前读到的新信息和你之前记住的一些信息,来决定你要忘记之前记住的部分内容。它会根据一些计算(利用当前输入和你之前的记忆状态),给出一个 0 到 1 的数字。如果是 0,就表示完全忘记之前的某个信息;如果是 1,就表示完全保留之前的信息。例如,你之前记住了一些情节,但随着故事发展,有些旧的情节可能变得不重要了,遗忘门就会帮助你慢慢忘记它们。
-
输入门:
- 这扇门负责决定你要记住哪些新信息。当你读新的内容时,输入门会先根据当前的信息和你之前的记忆,判断哪些新信息是重要的,哪些不重要。它会先计算出一个重要性的权重,然后根据这个权重把重要的新信息存储起来。就像你在听故事时,会根据新的情节和你之前的理解,决定哪些新情节需要重点记住,哪些可以忽略。
-
记忆门(输出门):
- 这个门决定你要把记住的哪些信息展示出来,也就是要输出的信息。它根据当前的信息和你之前的记忆状态进行计算,然后从你记住的所有信息中挑选一部分展示出来。这部分信息会被传递给下一个时刻,让你可以继续根据这些信息来理解后面的故事。比如说,你听完一段故事后,会根据你记住的信息和新的信息,选择一部分来表达你对当前故事的理解,这就是输出门的作用。
这些门共同协作,让 LSTM 可以更好地处理像故事、句子等一系列顺序信息,避免出现信息混乱或者丢失的情况,特别是对于较长的序列,它们能帮助 LSTM 更聪明地记住重要的信息,忘记无关的信息。这样就可以让 LSTM 在处理长序列数据时,比普通的神经网络表现得更好,更准确地预测或处理信息啦 。

虽然在处理文本序列时,循环神经网络(RNN)和长短期记忆网络(LSTM)是常用的方法。然而,它们存在严重的效率问题,因为在处理过程中只能一个词一个词地依次处理,无法同时对整个文本进行分析。例如在词性识别任务中,对于 “我 爱 你” 这样的句子,需要按照顺序逐个分析每个词的词性,这就导致处理速度很慢,并且在长文本处理时,这种劣势更加明显。
(二)自注意力机制(Self-attention)
为了解决上述问题,自注意力机制应运而生。它能够一次性处理所有字词的特征提取,无需等待前一个字词处理完毕,实现了完全并行的计算。
1、什么是注意力?
通俗一点来讲,我应该给A、B、C、D分配多少的精力,我的注意力分成四份 ,A分0.1份,B分0.2份,C分0.5份,D分0.2份,给谁分的多给谁分的少取决于A、B、C、D是否值得我们注意,这就叫做注意力,即输出是综合了每一个,给每一个分配不同权重相加而来。

2、自注意力机制
2.1、基础计算思路
对于b1、b2、b3、b4来说,我们可以用刚刚的思路,给a1、a2、a3、a4每一个设置一个注意力,即所占权重,然后用最简单的点乘,如对a1,2来说,我们可以用a1、a2点乘,假设两个都是768的向量,点乘出来一个值0.2,那么我们认为0.2就是1和2之间的注意力,b1也就是a1,1、a1,2、a1,3、a1,4相加出来的结果。但这种直接点乘的方式存在固定字乘出固定值的弊端,如“吃苹果”、“用苹果”,这里的苹果显然不是一个东西,用这种方式便不能正确分类。

2.2、改进计算思路
现在我们不用他们原来的值进行点乘,我们先对a1、a2做一步变换,对a1我们乘以一个矩阵Wq,对a2我们乘以一个矩阵Wk,得到一个q和k。我们知道乘以一个矩阵相当于做一个全连接,我们再对q和k进行点乘得到a1,2,这里的q我们称之为query(询问)、k我们称之为key(键值)。我们可以理解为q是一个扫码器,k是一个二维码,扫码过后我们就知道应该分配多少注意力。
 一般来讲,我们对每一个a也会乘以一个Wk,作为a1,1的二维码。最后我们一般要求分配的注意力和为1,所以在最后我们会进行一个Soft-max操作,使得四个注意力之和为1。
一般来讲,我们对每一个a也会乘以一个Wk,作为a1,1的二维码。最后我们一般要求分配的注意力和为1,所以在最后我们会进行一个Soft-max操作,使得四个注意力之和为1。
2.3、进一步改进计算思路
在注意力机制中,我们一般使用(值向量)而不是原始的(输入向量)乘以注意力权重,因为:
① 原始输入向量的局限性:原始输入向量包含了所有的原始信息,但这些信息可能较为繁杂,没有经过特定的转换和提炼。直接使用乘以注意力权重,不能很好地突出对当前任务或上下文真正重要的信息。
② 值向量的作用:通过计算得到的值向量 v ,是对原始输入向量 a 进行了一种线性变换和特征提取。这个变换过程可以将原始信息映射到一个更适合进行注意力加权的空间,使得不同维度的信息能够更好地被区分和利用。经过这样的转换后,再用注意力权重对进行加权求和,能够更有效地整合和突出与当前上下文相关的重要特征,从而更好地完成各种下游任务,如文本分类、机器翻译等。


因此,每一个字的特征提取都可以同时进行,因为它不需要等待前一个完成,实现完全并行!
2.4、维度计算和公式解释

① 我们用a1点乘Wq得到了一个q1,这里的Wq就相当于是一个全连接(768,768),这里的a1我们可以认为是(1,768 ),和线性代数不一样,我们用竖起来的表示a1,并且是一维的,所以这里得到的q1也是(1,768)。我们可以把(a1,a2,a3,a4)当成是一个输入矩阵 I ,经过一个全连接输出Q矩阵(q1,q2,q3,q4)。
② 同理可得 k 矩阵和 v 矩阵也是这么计算而来。

③ 对于注意力 a1,1、a1,2、a1,3、a1,4 来说,是由 q1 分别与k1、k2、k3、k4做点乘而来,也就是一个(1,768)点乘一个(768,1),得到一个数字,也就是一个值。如图,这里的 k1、k2、k3、k4 相当于就是(768,4)的一个矩阵,相乘得到的 a1,1、a1,2、a1,3、a1,4 就是一个(1,4)矩阵。

④ 在计算得到所有注意力之后,我们进行一个softmax操作,这里的softmax操作是在每一行进行的,也就是每一行最后相加为1。

⑤ 最后我们用每一个的注意力乘以对应的 v 得到 b ,如图所示,我认为这里的 v1、v2、v3、v4 竖着写更容易理解一点,相当于是(4,4)的矩阵与(4,768)的矩阵相乘,得到的依旧是一个(4,768)的矩阵。

从这个过程中我们也可以看到,实际上只有 q、k、v 是需要学习的,剩余的全是数据。
2.4、输入优化
我们根据上面所说的考虑一个问题,文本具有天然的顺序性,词语在句子中的位置会影响其语义和语法功能。自注意力机制本身在计算过程中并不区分字词的位置信息。例如在句子 “我 爱 你” 和 “你 爱 我” 中,如果没有位置编码,模型可能无法区分这两个句子的差异,因为仅从词向量本身来看,“我”“你”“爱” 的语义编码是固定的,但加上位置编码后,模型就能知道每个词在句子中的具体位置,从而更好地理解句子的语义和语法结构,像 “我” 在句首和句尾所表达的语义角色是不同的,位置编码有助于捕捉这种区别。所以我们引入一种改进方法:用汉字的编码和位置的编码直接相加作为模型输入。
举个例子,在这个过程中,如果没有额外的位置信息,它仅仅是基于词本身的语义编码(通过 Word Embedding 等方式得到)来进行计算。例如 “我” 这个词的向量表示可能是 [0.1, 0.2, 0.3] ,“爱” 是 [0.4, 0.5, 0.6] ,“你” 是 [0.7, 0.8, 0.9] ,在计算注意力时只关注这些向量的数值关系。
所以对于 “你 爱 我” 这个句子,虽然词语顺序变了,但如果没有位置编码,从自注意力机制的基本计算来看,它得到的结果可能和 “我 爱 你” 非常相似,因为词向量本身没有改变。
但实际上这两个句子的语义完全不同。而位置编码就是为了解决这个问题。位置编码会给每个位置赋予一个独特的向量表示。比如在一个简单的设定中,位置 1 对应的向量是 [0, 0, 1] ,位置 2 是 [0, 1, 0] ,位置 3 是 [1, 0, 0] 。
那么对于 “我 爱 你”,“我” 的输入向量就变成了 [0.1, 0.2, 0.3] + [0, 0, 1] ,“爱” 变成 [0.4, 0.5, 0.6] + [0, 1, 0] ,“你” 变成 [0.7, 0.8, 0.9] + [1, 0, 0] 。
对于 “你 爱 我”,“你” 的输入向量是 [0.7, 0.8, 0.9] + [0, 0, 1] ,“爱” 是 [0.4, 0.5, 0.6] + [0, 1, 0] ,“我” 是 [0.1, 0.2, 0.3] + [1, 0, 0] 。
这样,通过位置编码的加入,即使词向量本身相同,由于位置向量的不同,模型在计算注意力和提取特征时就能区分出两个句子中词语的不同位置和语义角色,从而准确理解句子的含义。

首先,每个词语(“我”“有”“一只”“猫”)都有其对应的词向量。然后,为每个词语的位置生成位置向量,将词向量和位置向量相加,得到 Transformer 的输入表示x。这些输入表示会通过后续的 Transformer 架构进行处理,以完成各种自然语言处理任务,如文本分类、机器翻译等。

Linear (21128, 768) 和 Linear (512, 768):这两个线性层是用于对词向量和位置向量进行某种变换或映射。例如,可能是将原始的高维词向量(维度为 21128)和位置向量(维度为 512)通过线性变换映射到 Transformer 模型所需要的维度(这里是 768)。
四、多头自注意力机制
为了进一步提升模型的性能和表达能力,可以采用多头自注意力机制。例如设置 4 个头的情况,即同时进行 4 组不同的自注意力计算。通过这种方式,模型能够从多个角度捕捉文本中的信息,就像对同一段文本,不同的头可以关注到不同层面的语义关系或语法结构等,然后将这些结果进行整合,从而更全面地理解文本。
五、Bert 模型
模型概述:
BERT 是一个强大的特征提取器,在自然语言处理中应用广泛。其预训练任务主要包括掩码语言模型(Masked Language Model)和下一句预测(Next Sentence Prediction)。
预训练任务细节:
① 在掩码语言模型(Masked Language Model)中,一般会对百分之十五的内容进行掩码,其中,如对于 “my dog is hairy”,有 80% 的概率将 “hairy” 替换为 [MASK],10% 替换为其他随机词如 “apple”,10% 保持不变。
② 在下一句预测任务(Next Sentence Prediction)则是给定两个句子,判断它们是否是前后相邻的句子,如 “[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]” 与 “[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flightless birds [SEP]”,分别标记为 “IsNext” 和 “NotNext”,通过大量此类数据训练,使 Bert 学习到丰富的语言特征和语义关系。

模型结构:
BERT 主要由三部分组成。首先是嵌入层(embedding layer),负责将输入文本转换为包含词嵌入和位置嵌入的向量表示;其次是多个多头注意力层(Multi - Head Attention),通过自注意力机制让特征充分交互,捕捉文本中的语义信息;最后是池化层(pooler output),在进行分类等下游任务时,通常只关注 [CLS] 标记对应的输出,可采用平均池化、最大池化等方法将其转换为最终的特征表示,用于后续任务如情感分类、命名实体识别等,在不同自然语言处理任务中发挥关键作用,显著提升了模型性能和效果。

Embedding嵌入:
① 词汇嵌入(Token Embeddings):输入句子中的每个单词或子词都会被转换成一个词汇嵌入,这个嵌入是一个高维向量,用于表示该词的语义。例如,"my"、"dog"、"is"等词会分别被转换为各自的词汇嵌入。
② 位置嵌入(Position Embeddings):位置嵌入用于表示token在句子中的位置。因为Transformer模型不像RNN那样处理序列数据,所以需要通过位置嵌入来告知模型各个词在句子中的位置。
③ 句子段落嵌入(Segment Embeddings):这个嵌入用于区分句子对。例如,在问答任务中,BERT通常需要区分问题句和答案句。通过句子段落嵌入,BERT能够辨别两个不同的部分。
图中举了一个例子:“my dog is cute”,BERT会为句子中的每个token生成三种嵌入:词汇嵌入、位置嵌入和句子段落嵌入。然后,这些嵌入会相加,得到一个综合表示,再输入Transformer层进行进一步的处理。

Pooler output池化输出:
① 仅输出CLS:在BERT的输入中,CLS(Classification)标记被放置在句子的开头,并通常作为整个句子的表示,特别是在分类任务中。图中提到,BERT可以只输出CLS标记作为最终结果。
在 BERT 模型中,[CLS] 标记是一个特殊的标记。
原理
- 句子表示:当输入一段文本到 BERT 时,会在文本开头添加 [CLS] 标记。在 BERT 的多层 Transformer 结构中,这个 [CLS] 标记会不断地与其他词的信息进行交互和融合,从而逐渐 “吸收” 整个句子的语义信息。
- 分类任务的应用:在进行分类任务(如情感分类、文本分类等)时,由于 [CLS] 标记已经综合了整个句子的信息,所以可以直接取 [CLS] 标记对应的输出向量作为整个句子的表示向量,然后将这个向量输入到后续的分类层(如全连接层和 Softmax 层)中进行分类预测。
示例
比如有一个句子 “这部电影很精彩”,输入到 BERT 后,经过多层计算,[CLS] 标记的输出向量就包含了 “这部电影很精彩” 这个句子的整体语义特征,然后就可以用这个向量来判断该句子的情感是积极的、消极的还是中性的等。
优点
这样做的好处是简化了模型的输出,不需要对句子中的每个词的输出都进行处理,只关注 [CLS] 标记的输出即可,同时也能取得较好的分类效果。
② 池化方法:
平均池化:此方法计算所有token嵌入的平均值,即对每个token的表示取平均,得到一个全局的表示。
最大池化:此方法选取所有token嵌入的最大值,即在每个维度上取最大值。
其他池化:这里可能指的是根据不同任务需求,使用的其他池化方法。