📃博客主页: 小镇敲码人
💚代码仓库,欢迎访问
🚀 欢迎关注:👍点赞 👂🏽留言 😍收藏
🌏 任尔江湖满血骨,我自踏雪寻梅香。 万千浮云遮碧月,独傲天下百坚强。 男儿应有龙腾志,盖世一意转洪荒。 莫使此生无痕度,终归人间一捧黄。🍎🍎🍎
❤️ 什么?你问我答案,少年你看,下一个十年又来了 💞 💞 💞

【深入浅出】之Linux进程(二)
- 父进程与子进程
- 使用系统调用函数fork给当前进程创建一个子进程
- fork函数的使用
- fork函数的原理
- demo代码:一次创建多个进程
- 进程的状态介绍
- 关于进程排队
- 模拟上述计算过程
- 进程的几种状态
- 僵尸进程
- 孤儿进程
父进程与子进程
刚刚介绍
PCB的常见属性,我们已经介绍了,pid,每一个进程都有唯一的一个pid,普通的进程一般都有自己的父进程。
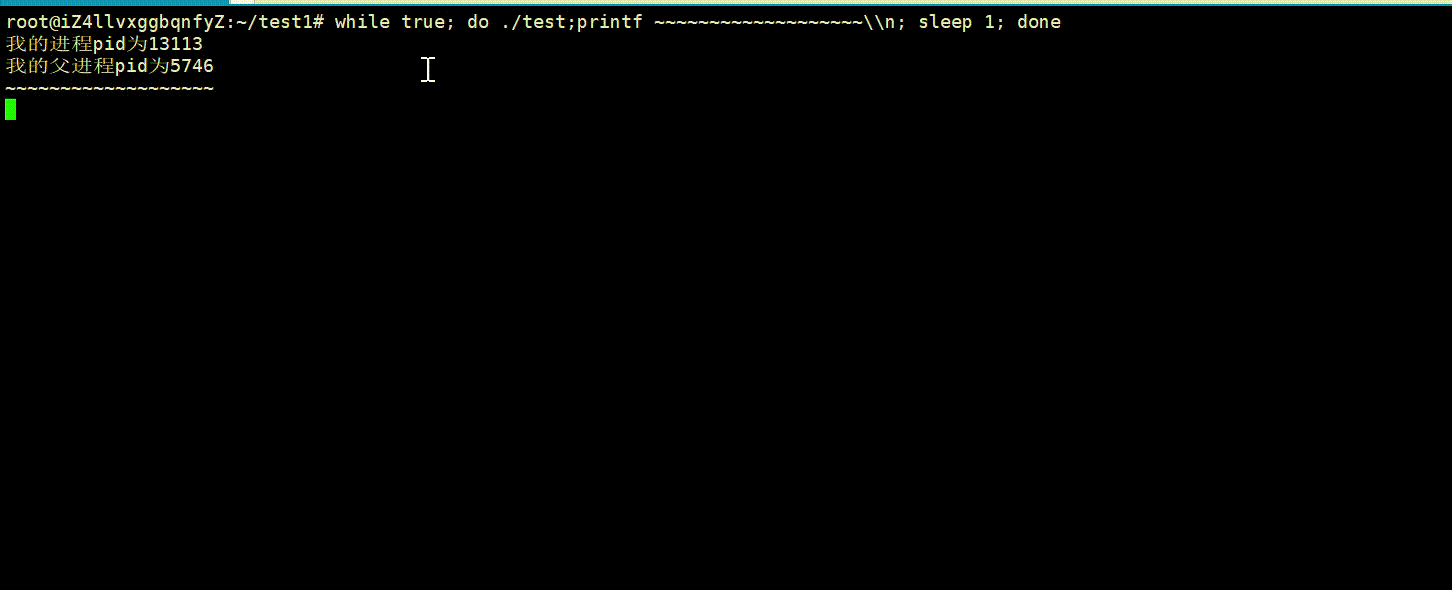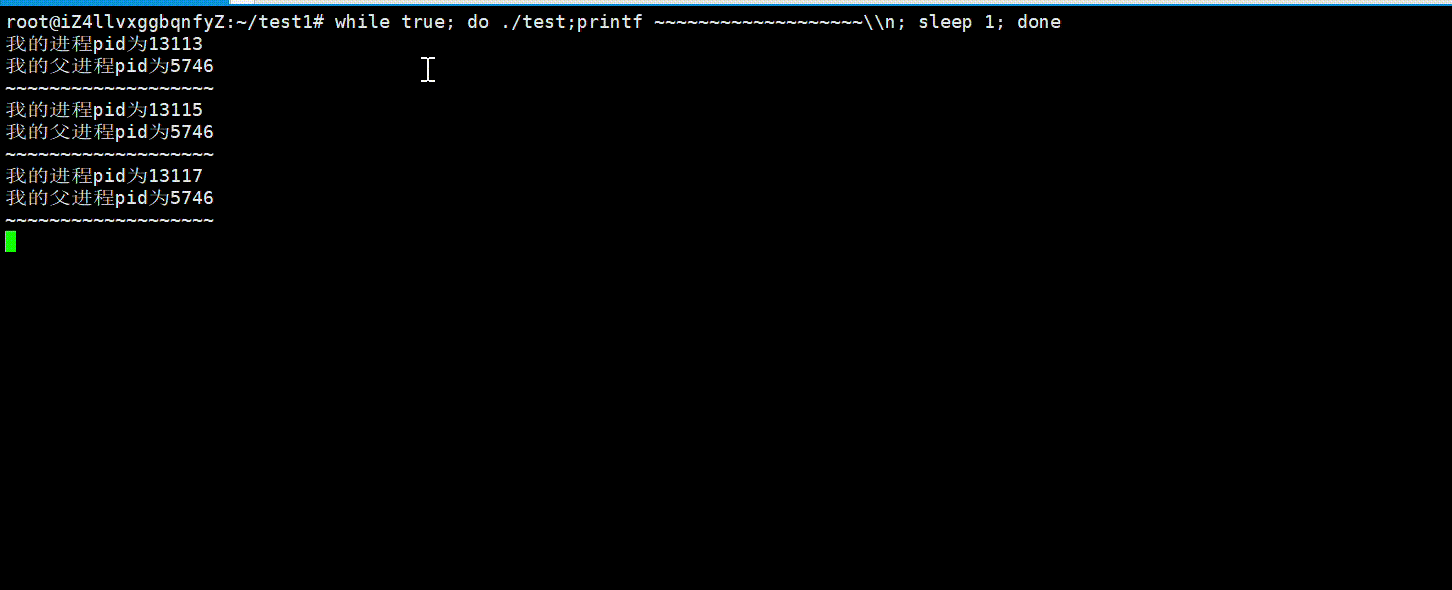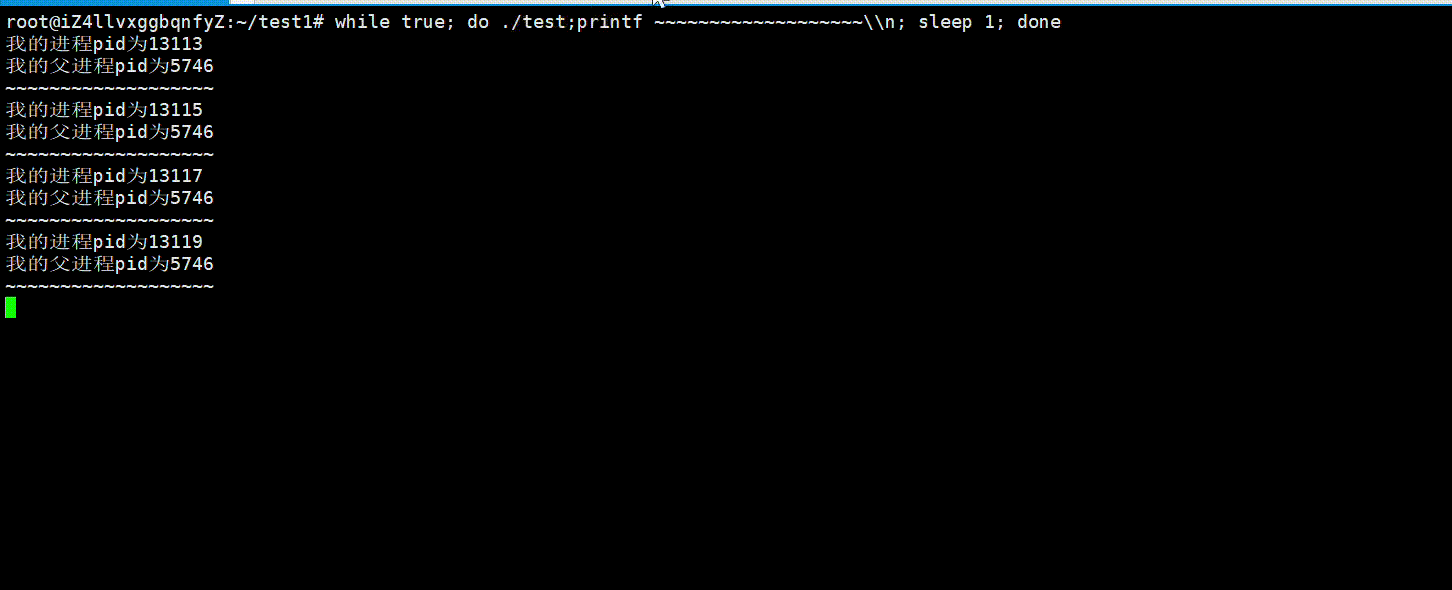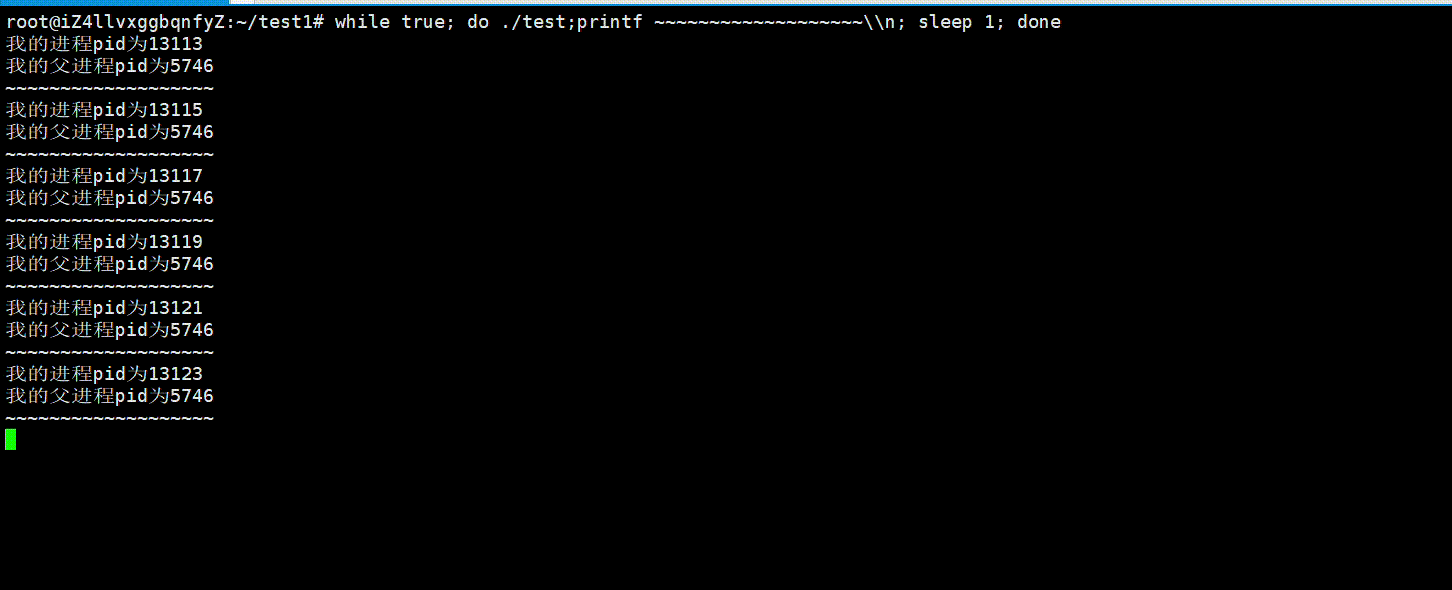
即使我们不同时间执行相同的可执行程序,它的进程pid都会变化,因为每一次它都是一个新的进程,操作系统会在内存中给它重新创建PCB对象,多说无益,我们可以用下面代码验证一下:
#include<stdio.h>
#include <unistd.h>
int main()
{
int i = 0;
printf("我的进程pid为%d\n",getpid());
printf("我的父进程pid为%d\n",getppid());
return 0;
}
运行结果:
使用系统调用函数fork给当前进程创建一个子进程
fork系统调用函数:
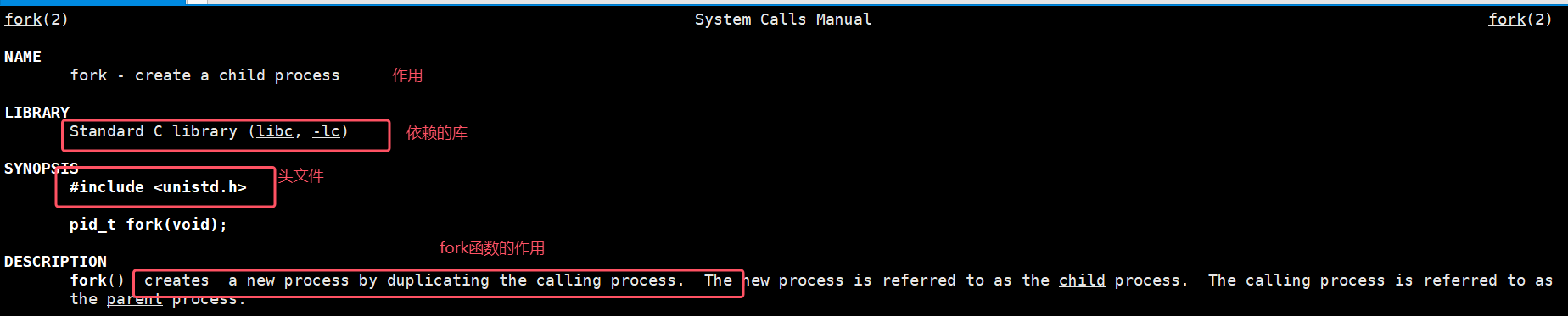
返回值:

- 如果成功子进程的
PID将被返回给父进程,0会被返回给子进程。如果失败,-1将会被返回给父进程,没有子进程被创建,errno将被设置。
fork函数的使用
先试着使用fork函数:
#include<stdio.h>
#include <unistd.h>
int main()
{
printf("before fork,I am a process,my pid is %d,my ppid is %d\n",getpid(),getppid());
sleep(5);
printf("开始创建进程了!!!\n");
sleep(1);
pid_t id = fork();
if(id < 0) return 1;
else if(id == 0)
{
//子进程
while(1)
{
printf("after fork:我是子进程:my pid is %d,my ppid is %d,my return id is %d\n",getpid(),getppid(),id);
sleep(1);
}
}
else
{
//父进程
while(1)
{
printf("after fork:我是父进程:my pid is %d,my ppid is %d,my return id is %d\n",getpid(),getppid(),id);
sleep(1);
}
}
return 0;
}
运行结果:

- 返回值符合预期,下面我们来研究以下
fork函数的工作原理。
fork函数的原理
关于fork函数还有如下问题,需要我们解决:
-
返回值
id为什么要给父进程返回子进程的pid,而给子进程返回0呢?这样设计可以区分子进程和父进程。给父进程返回子进程的
pid,可以便于父进程通过pid管理子进程。父进程对应自己的子进程,是一对多的关系。 -
fork进程为什么会返回两次?fork函数之所以会返回两次,是因为它创建了一个新的进程,这个新进程是原进程(父进程)的一个完全复制。这个复制过程导致了fork函数在两个进程中分别返回,每个进程的返回值不同,从而区分父进程和子进程。 -
id作为一个变量,为什么会同时既大于0,又等于0。子进程的
id变量和父进程的id变量的值是不同的,因为fork返回的时候就不同,return的本质是写入,而子进程和父进程是独立的,id变量的实际地址是不同的,即使你可能会发现它们打印出来的虚拟地址是相同的。- 子进程和父进程是独立的,有不同的内存空间
- 子进程是父进程的拷贝,它的很多东西都会进程父进程,比如进程的工作目录
cwd,但是它是写时拷贝的,就是同一个变量,当子进程中发生拷贝,系统就会给子进程重新开一块实际的内存空间,以此做到内存之间是独立的。

-
写时拷贝:写时拷贝是一种优化技术,旨在减少内存的使用和提高进程创建的效率。当创建一个新的进程,操作系统并不会立马为新进程开辟一块新的内存页面,而是父进程和子进程共享一块内存页面,这个页面被标记为可读。如果一旦有某个进程试图修改共享内存页面的数据,操作系统就会为这个想要修改数据的进程,重新开辟一块新的物理内存页面,并把原先的可读数据复制一份,把新数据修改到新的页面,原页面不变,继续被另一个进程使用。只会拷贝部分内存页面,因为还有一些内存页面是没有被修改的!!!,按需复制
-
某一个进程崩溃了,不会影响其它进程,因为有写时拷贝技术的存在,而且它们的数据的物理内存不同。父子进程共享代码但是写操作发生后不再共享物理内存,所以代码中的某个变量可能有不同的物理内存,但是它们的虚拟内存可能一样。
demo代码:一次创建多个进程
#include<stdio.h>
#include<stdbool.h>
#include <unistd.h>
#include <stdlib.h>
const int num = 10;
void Worker()
{
int cnt = 12;
while(cnt--)
{
printf("child process %d is running!!!cnt %d \n",getpid(),cnt);
sleep(1);
cnt--;
}
}
int main()
{
for(int i = 0;i < num;++i)
{
pid_t id = fork();
if(id < 0) return 1;
else if(id == 0)
{
Worker();
exit(0);//子进程执行完任务直接退出了
}
printf("chilid process created sucess!!!,child pid is %d\n",getpid());
sleep(1);
}
sleep(5);//只有父进程可以执行到这
printf("执行完成!!!\n");
return 0;
}
运行结果:

可以看到,我们一个创建了5个子进程,它们在完成任务之后,就退出了。但是状态变成了
Z,也就是僵尸进程,因为父进程没有读取。
进程的状态介绍
关于进程排队
进程不是一直在运行的,因为有时间片的存在,每个进程都只运行固定的时间,然后保存好上下文数据,切换为其它的进程,这就涉及到调度算法。
另外,即使进程放在了CPU上也不一定一直会运行,因为它可能会在等待某种硬件资源,比如C语言中,我们在使用
scanf的时候,如果一直键盘没有输入相应的数据,进程就不会往下执行,停顿在了那个位置,没有继续运行。
Linux中如何进行进程排队呢?
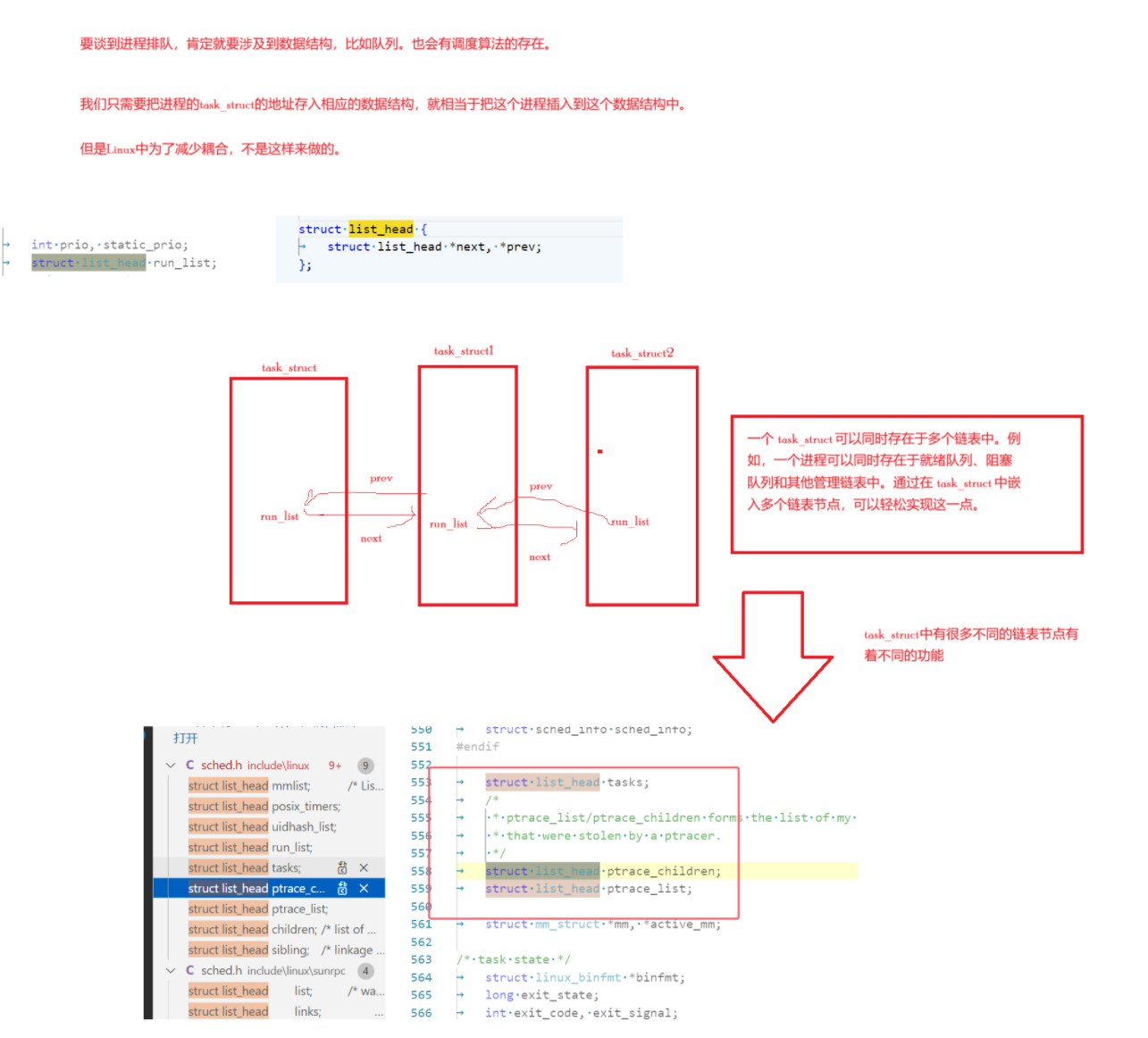

- 我们上面只是简单的写一下只给结构体某个成员的地址,如何得到结构体对象地址的思考,用C语言来写要考虑到指针加减的不同类型问题。
- 上面的做法解耦了数据结构和链表管理:
- 数据结构独立:
task_struct结构体可以独立于具体的链表管理逻辑。这样,task_struct的定义可以更加专注于进程本身的属性和状态,而不必关心如何被组织到链表中。 - 链表节点独立:通过在
task_struct中嵌入链表节点(例如struct list_head),内核可以灵活地将task_struct插入到不同的链表中,而不需要修改task_struct的核心定义。
- 数据结构独立:
模拟上述计算过程
只给结构体中某个成员的地址,得到结构体对象地址,并访问它的成员。
#include<stdio.h>
typedef struct Student
{
char name[20];
char sex[10];
int age;
}Stu;
int main()
{
Stu a = {"xiaoming","男",18};
int* pf = &a.age;
Stu* b = (Stu*)((char*)pf - (char*)(&((Stu*)0)->age));
printf("%s\n", b->name);
printf("%s\n", b->sex);
printf("%d\n", b->age);
return 0;
}
运行结果:
Linux平台(gcc):

Windows平台(vs2019):


- 只有都换成
char*才能满足我们的要求。
进程的几种状态
教材上关于进程状态的表述:运行、就绪、阻塞。

实际上在Linux内核中,状态就是一个整型变量:

Linux中进程的状态绝对了进程的后续动作:Linux中同时存在多个进程都要根据它的状态执行后续动作。

当进程在等待某种资源时,会被操作系统挂为阻塞状态,它的PCB对象会被放到该硬件资源的等待队列中:

挂起状态:当计算机资源很吃紧时,进程会被设置为挂起状态。

Linux中定义的进程状态:

- 下面我们在
ubuntu24.04下寻找一下上述进程状态的身影:
-
正在运行的进程:

R+:R表示正在运行,+表示是前台进程。
-
S:状态表示进程正在休眠:
-
s:小写s表示进程是一个会话leader,因为它管理着多个子进程,每个子进程处理一个单独的客户端连接。
-
t:进程正在被调试:
-
进程被系统管理员使用
kill命令中断(T):
-
模拟长时间的 I/O,让我们的程序读取一个很大的文件,磁盘 I/O 操作:创建一个文件并进行大量的读写操作,可以让进程进入
D状态。这样可以保证读取的完整性,而且硬件交互很特殊,不仅时间长,而且中间状态难以恢复,所以要将进程设置为不可中断睡眠:
-
僵尸状态(Z):

-
X状态(dead):进程已经变成死亡状态,这种状态一般不会显示到进程状态列表中。
僵尸进程
上述什么是僵尸状态我们已经介绍过了,处于僵尸状态的进程就是僵尸进程,这是因为子进程退出了,而父进程没有退出,在父进程没有读取子进程的结果前,子进程会一直处于僵尸进程,我们可以调用系统调用函数来解决这个问题。
-
wait函数解决僵尸进程的问题。今天我们只简单的使用一下,
wait函数,更多细节在进程地址空间的时候再谈。
- 这个函数的参数是一个指针,这个指针是什么,我们今天也不谈,直接给它传NULL,快速使用一下:
#include <unistd.h> #include<stdio.h> #include<sys/wait.h> int main() { printf("开始创建进程了!!!!我的pid is %d,我的ppid is %d\n",getpid(),getppid()); pid_t id = fork(); if(id < 0) return 1; else if(id == 0) { printf("hello !!!\n"); printf("开始创建进程了!!!!我的pid is %d,我的ppid is %d\n",getpid(),getppid()); exit(0); } else//父进程 { printf("我是父进程\n"); sleep(10); printf("开始回收子进程了!!!\n"); wait(NULL); printf("回收完成!!!\n"); } return 0; }运行结果:

sleep10秒后,主进程调用wait系统调用函数等待子进程,子进程资源被回收,僵尸状态变成死亡状态。
孤儿进程
当父进程比子进程提前结束,子进程就会变成孤儿进程,因为它没有父进程了,父进程已经变成死亡状态,如果子进程不被等待就会变成僵尸进程,导致资源泄漏,所以当这种情况发生时,系统会给子进程分配一个父进程。
看下面代码,子进程会变成孤儿进程:
#include <unistd.h>
#include<stdio.h>
#include<sys/wait.h>
int main()
{
printf("开始创建进程了!!!!我的pid is %d,我的ppid is %d\n",getpid(),getppid());
pid_t id = fork();
if(id < 0) return 1;
else if(id == 0)
{
printf("hello !!!\n");
printf("开始创建进程了!!!!我的pid is %d,我的ppid is %d\n",getpid(),getppid());
while(1)
{
printf("Running!!!!\n");
}
}
else//父进程
{
sleep(10);
printf("我要退出了!!!!\n");
exit(0);//父进程退出
}
}
运行结果:

-
当父进程退出后,子进程被
pid为1的init进程接管,它负责清理子进程的资源。
- 本人知识、能力有限,若有错漏,烦请指正,非常非常感谢!!!
- 转发或者引用需标明来源。






![[Python学习日记-63] 继承与派生](https://i-blog.csdnimg.cn/direct/dc4f30b642844d749b26aac5381591ea.png)