Mysql高级篇(下)——数据库设计范式
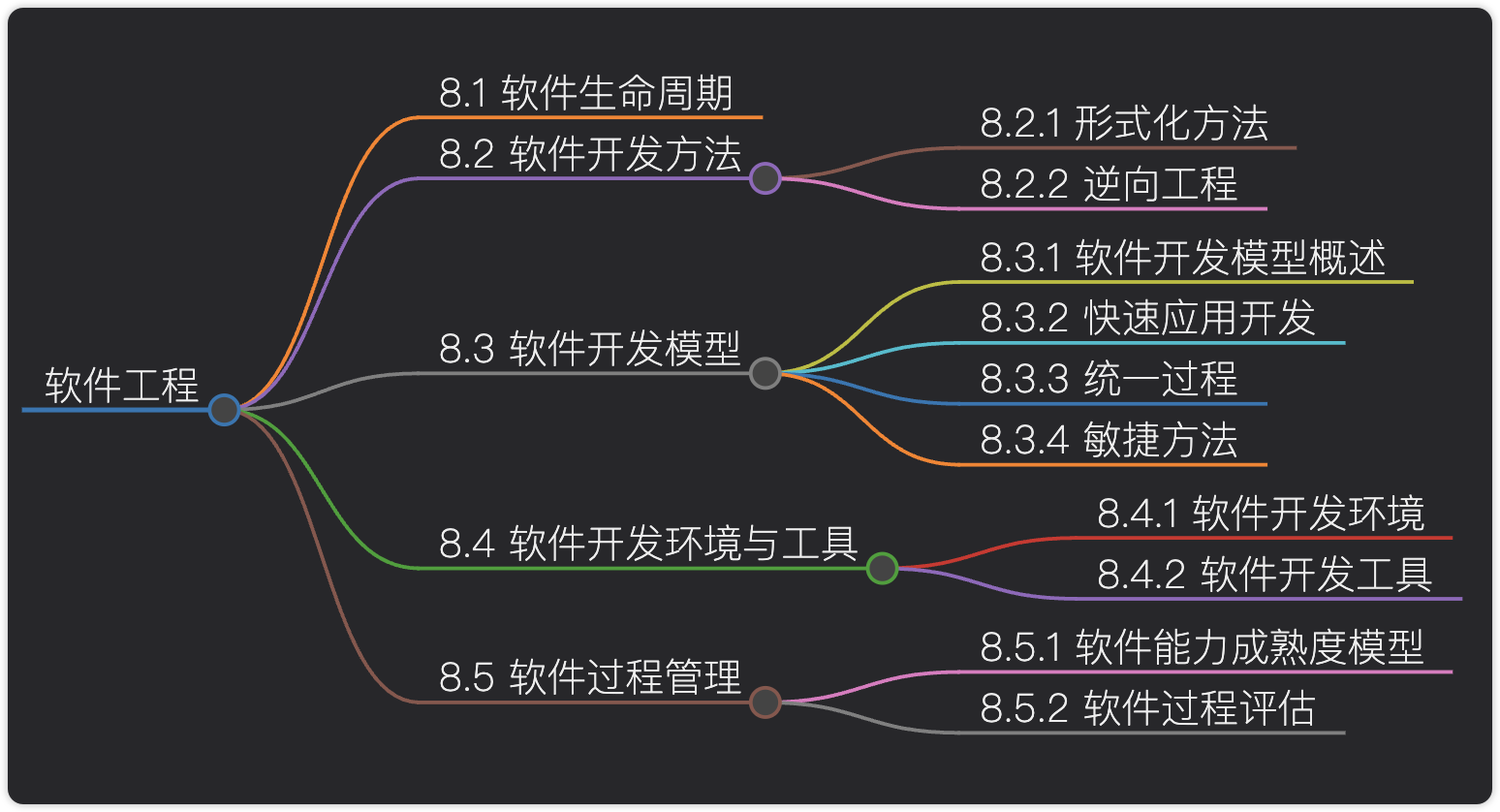
- 一、键和相关属性概念
- 二、关系型数据库中常见的六种设计范式
- 1. 第一范式(1NF)- 消除重复列,保证每列都是原子值
- 2. 第二范式(2NF)- 消除部分依赖
- 3. 第三范式(3NF) - 消除传递依赖
- 4. BCNF(巴斯-科德范式)- 消除候选键的部分依赖
- 5. 第四范式 (4NF) - 消除多值依赖
- 6. 第五范式 (5NF) - 消除连接依赖
- 🎈 总结:
- 三、反范式化(Denormalization)
- 1. 概述
- 2. 示例
- 3. 反范式化的优缺点:
- 🎈总结:
- 四、范式设计案例
- 案例实战
- 🎈总结:
一、键和相关属性概念
球员表 (player):
- 包含字段:
球员编号、姓名、身份证号、年龄、球队编号。这些字段记录了关于每个球员的详细信息。 - 其中,"
球员编号"是每个球员的唯一标识,用来区分不同球员。
球队表 (team):
- 包含字段:
球队编号、主教练、球队所在地。这些字段记录了每个球队的信息。 - "
球队编号"是球队表的主键,用来唯一标识球队。

二、关系型数据库中常见的六种设计范式
数据库设计中的六种范式(
1NF到5NF及BCNF)是逐步递进的,每个范式都基于前一个范式的基础,进一步提高了数据库设计的规范化程度。它们的关系可以理解为一种渐进式的约束机制,每一层范式都解决了上一层没有处理好的数据冗余或异常问题。
1. 第一范式(1NF)- 消除重复列,保证每列都是原子值
要求数据库中的所有字段都是原子值,即数据不可再分。每个字段都只包含单一的值,不能是 集合、列表兄弟值。
示例:
违反1NF的情况:
学生表 (Student)
-----------------------------
学生编号 | 姓名 | 电话号码
-----------------------------
101 | 张三 | 123456, 789012
102 | 李四 | 345678
-----------------------------
这里的“`电话号码`”字段包含了多个值(即`数组`或`集合`),违反了`1NF`。
符合1NF的表:
学生表 (Student)
-----------------------
学生编号 | 姓名 | 电话号码
-----------------------
101 | 张三 | 123456
101 | 张三 | 789012
102 | 李四 | 345678
-----------------------
通过将电话号码分成多行,每行只包含一个号码,表就符合1NF。
2. 第二范式(2NF)- 消除部分依赖
- 在满足
1NF的基础上,还 要求表中的每个非主键属性完全依赖于主键。即消除部分依赖(部分依赖是指某些属性只依赖于主键的一部分,而不是整个主键)。
示例:
违反2NF的情况:
选课表 (Student_Course)
----------------------------------------------
学生编号 | 学生姓名 | 课程编号 | 课程名称 | 成绩
----------------------------------------------
101 | 张三 | 201 | 数学 | 90
101 | 张三 | 202 | 物理 | 85
102 | 李四 | 201 | 数学 | 88
102 | 李四 | 203 | 化学 | 92
----------------------------------------------
这里的 复合主键 是 学生编号 + 课程编号
,但 学生姓名 依赖于 学生编号,而与 课程编号 无关;
同理 课程名称 依赖于 课程编号,而与 学生编号 无关;
这种部分依赖违反了2NF。
符合2NF的表:
学生表 (Student)
-----------------------
学生编号 | 学生姓名
-----------------------
101 | 张三
102 | 李四
-----------------------
选课表 (Student_Course)
------------------------------
学生编号 | 课程编号 | 成绩
------------------------------
101 | 201 | 90
101 | 202 | 85
102 | 201 | 88
102 | 203 | 92
------------------------------
课程表 (Course)
------------------------
课程编号 | 课程名称
------------------------
201 | 数学
202 | 物理
203 | 化学
------------------------
通过将学生信息和课程信息拆分为独立的表,消除了部分依赖,符合2NF。
3. 第三范式(3NF) - 消除传递依赖
- 满足2NF的基础上,要求消除供应依赖。即非主键属性不能依赖于其他非主键属性,必须直接依赖于主键。
示例:
违反3NF的情况:
雇员表 (Employee)
---------------------------
雇员编号 | 雇员姓名 | 部门编号 | 部门名称
---------------------------
001 | 张三 | 101 | 销售部
002 | 李四 | 102 | 财务部
003 | 王五 | 101 | 销售部
---------------------------
这里,部门名称 依赖于 部门编号,
而 部门编号 又依赖于 雇员编号(主键),
这属于传递依赖,违反了3NF。
符合3NF的表:
雇员表 (Employee)
------------------------
雇员编号 | 雇员姓名 | 部门编号
------------------------
001 | 张三 | 101
002 | 李四 | 102
003 | 王五 | 101
------------------------
部门表 (Department)
-----------------------
部门编号 | 部门名称
-----------------------
101 | 销售部
102 | 财务部
-----------------------
通过将部门信息拆分为单独的表,消除了传递依赖,符合3NF。
4. BCNF(巴斯-科德范式)- 消除候选键的部分依赖
BCNF是对第三范式的加强,它消除了在某些情况下主属性与主键之间的异常依赖。BCNF要求:
- 表中的每个决定因素(
determining factor)都必须是候选键。
BCNF的主要目的是避免在某些特殊情况下(如复合键或冗余的候选键)出现的依赖关系问题,即使表满足第三范式,也有可能会因为复杂的依赖关系而导致冗余。
示例:
违反BCNF的情况:
课程分配表 (Course_Assignment)
---------------------------------------
课程编号 | 教师编号 | 教室编号
---------------------------------------
201 | 001 | Room 101
202 | 002 | Room 102
201 | 001 | Room 101
---------------------------------------
在这个表中,教师编号 决定 教室编号(即 教师编号 → 教室编号),
但 教师编号 不是超键,因为它不能唯一标识整个表的记录。
这违反了BCNF。
符合BCNF的表:
课程表 (Course)
------------------------
课程编号 | 教师编号
------------------------
201 | 001
202 | 002
------------------------
教师教室表 (Teacher_Room)
------------------------
教师编号 | 教室编号
------------------------
001 | Room 101
002 | Room 102
------------------------
通过分解表结构,消除了不符合BCNF的依赖。
5. 第四范式 (4NF) - 消除多值依赖
在满足BCNF的基础上,消除多值依赖。即 表中不能存在一个属性依赖于多个不相关的属性。
示例:
违反4NF的情况:
学生活动表 (Student_Activity)
---------------------------
学生编号 | 活动 | 语言
---------------------------
101 | 篮球 | 英语
101 | 篮球 | 中文
101 | 音乐 | 英语
101 | 音乐 | 中文
---------------------------
这里,活动 和 语言 是彼此独立的多值依赖,导致数据冗余,违反了4NF。
符合4NF的表:
学生活动表 (Student_Activity)
---------------------------
学生编号 | 活动
---------------------------
101 | 篮球
101 | 音乐
---------------------------
学生语言表 (Student_Language)
---------------------------
学生编号 | 语言
---------------------------
101 | 英语
101 | 中文
---------------------------
通过将活动和语言分开存储,消除了多值依赖,符合4NF。
6. 第五范式 (5NF) - 消除连接依赖
在满足4NF的基础上,确保表的任何信息都不能通过自然连接来重构,即消除连接依赖。
示例:
违反5NF的情况:
供应商零件项目表 (Supplier_Part_Project)
--------------------------------------------
供应商 | 零件 | 项目
--------------------------------------------
A | P1 | J1
A | P2 | J1
B | P1 | J2
B | P2 | J2
--------------------------------------------
这里可能存在一种情况,即 供应商、零件 和 项目 之间的关系
可以通过自然连接拆分重构,这违反了5NF。
符合5NF的表:
供应商项目表 (Supplier_Project)
-------------------------------
供应商 | 项目
-------------------------------
A | J1
B | J2
-------------------------------
供应商零件表 (Supplier_Part)
-----------------------------
供应商 | 零件
-----------------------------
A | P1
A | P2
B | P1
B | P2
-----------------------------
零件项目表 (Part_Project)
-------------------------
零件 | 项目
-------------------------
P1 | J1
P2 | J1
P1 | J2
P2 | J2
-------------------------
通过将关系拆分为多个表,消除了连接依赖,符合5NF。
🎈 总结:
1NF:确保每列都是原子值。2NF:消除部分依赖。3NF:消除传递依赖。BCNF:每个决定因素都是超键。4NF:消除多值依赖。5NF:消除连接依赖。
三、反范式化(Denormalization)
1. 概述
反范式化(Denormalization)是 指在数据库设计中,故意违反范式规则,来提升查询性能或满足实际应用的需求。虽然范式化可以减少数据冗余、提高数据一致性,但高度规范化的表结构可能会导致较多的表连接操作,从而影响查询效率。在一些实际应用中,为了避免复杂的表连接查询,数据库设计者可能会选择反范式化,以提高读取性能,尤其是在查询频繁且读取效率比写入要求更高的场景。
2. 示例
假设在球员表(player)和球队表(team)的设计中,有这样一种需求: 我们需要频繁查询球员的详细信息,包括球员所属球队的主教练和球队所在地。
在范式化设计中,球员表和球队表是分开的,查询球员的详细信息时,需要对两个表进行连接操作,如下所示:
SELECT player.球员编号, player.姓名, player.年龄, team.主教练, team.球队所在地
FROM player
JOIN team ON player.球队编号 = team.球队编号;
这种设计遵循第三范式 (3NF),避免了冗余。但是,随着数据量增大,频繁的表连接可能会导致查询性能下降。
反范式化的方式:
为了提高查询性能,我们可以选择将球队的"主教练"和"球队所在地"直接存储在球员表中,而不是通过球队表来查找。这就引入了冗余数据,但可以减少表连接的次数,提升查询速度。新的球员表可能设计如下:
反范式化后的球员表:
球员编号 | 姓名 | 年龄 | 身份证号 | 球队编号 | 主教练 | 球队所在地 |
|---|---|---|---|---|---|---|
| 001 | 张三 | 25 | 123456 | 001 | 李教练 | 北京 |
| 002 | 李四 | 22 | 654321 | 002 | 王教练 | 上海 |
在这种设计下,查询球员及其所属球队的相关信息时,不需要连接球队表,直接从球员表中就可以获取到所有需要的数据:
SELECT 球员编号, 姓名, 年龄, 主教练, 球队所在地
FROM player;
3. 反范式化的优缺点:
-
优点:反范式化减少了查询时的表连接,提升了查询性能,尤其是在查询频繁的情况下效果明显。
-
缺点:反范式化引入了数据冗余,比如如果某个球队更换了主教练或所在地,所有球员表中的相关记录都需要更新,增加了数据维护的成本和一致性风险。
🎈总结:
反范式化是一种为了实际查询性能而做出的折中方案,它通过引入冗余数据来减少表连接操作。尽管这会违反范式化设计的规范,但在查询频率较高、性能要求较高的场景中,反范式化是一种常用的优化手段。使用时应结合实际需求,平衡性能提升与数据冗余、维护成本之间的关系。
四、范式设计案例
案例实战
在
MySQL中,范式的设计主要是为了减少数据一致性,保证数据一致性。下面是一个三级范式(3NF)设计的实际例子,展示如何从非范式到第三范式逐步优化数据库结构。
场景描述:
- 你在设计一个简单的
在线购物系统,初始设计中只有一个表Orders,存储订单信息。初始设计如下:
非范式设计:
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_address VARCHAR(200),
product_name VARCHAR(100),
product_price DECIMAL(10, 2),
order_date DATE
);
在这种设计中,存在重复数据,比如每次下一个订单时都需要存储customer_name和customer_address,还可能重复存储相同的product_name和product_price。
1NF (第一范式):
为了满足第一范式,每个字段都应该是原子性字段,不能包含多个值。上述表已经满足第一范式,因为每个字段都只包含一个值。
2NF (第二范式):
customer_name要达到第二式,消除必须部分依赖。具体来说,所有非主键字段必须完全依赖于主键。在上述设计中,customer_address只依赖于order_id,但并不属于订单信息,应该分离到一个单独的客户表中。
优化后期的设计(达到 2NF):
CREATE TABLE Customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
customer_address VARCHAR(200)
);
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES Customers(customer_id)
);
现在Orders表只包含与订单直接相关的信息,customer_name并且customer_address依赖于customer_id,而不是order_id。
3NF (第三范式):
第三式要求消除供给依赖,即非主键字段不能依赖于其他非主键字段。在Orders表中,product_name和product_price各处之间是相关的,不应该存在于同一个表中。你可以将产品信息分离到一个单独的字段的Products表中。
优化后期的设计(达到3NF):
CREATE TABLE Products (
product_id INT PRIMARY KEY,
product_name VARCHAR(100),
product_price DECIMAL(10, 2)
);
CREATE TABLE Orders (
order_id INT PRIMARY KEY,
customer_id INT,
product_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES Customers(customer_id),
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
🎈总结:
通过将Orders表串联为Customers、Orders和Products三个表,去掉了数据并提高了数据的一致性。这种设计不仅符合第三范式,还简化了更新操作。如果某些产品的价格变化,只需要更新Products表在一条记录中,不是所有包含该产品的订单。
这样,你的数据库就遵循了三级范式,避免了数据出现和异常问题。