- 课本内容
- 14.1 引言
- 概要
- 从数据中探究、研发预测模型、机器学习模型、规范性模型和分析方法并将研发结果进行部署供相关方分析的人,被称为数据科学家
- 业务驱动
- 期望抓住从多种流程生成的数据集中发现的商机,是提升一个组织大数据和数据科学能力的最大业务驱动力。
- 语境图
- 大数据和数据科学
- 图14-2 语境关系图:大数据和数据科学

- 图14-2 语境关系图:大数据和数据科学
- 大数据和数据科学
- 原则
- 与大数据管理相关的原则尚未完全形成,但有一点非常明确:组织应仔细管理与大数据源相关的元数据,以便对数据文件及其来源和价值进行准确的清单管理
- 基本理念
- 数据科学
- 数据科学将数据挖掘、统计分析和机器学习与数 据集成整合,结合数据建模能力,去构建预测模型、探索数据内容模 式
- 数据科学依赖于
- 丰富的数据源
- 信息组织和分析
- 信息交付
- 展示发现和数据洞察
- 分析对比
- 表14-1 分析对比

- 表14-1 分析对比
- 分析对比
- 数据科学的过程
- 数据科学的过程阶段
- 1)定义大数据战略和业务需求。定义一些可衡量的、能够产生实际收益的需求。
- 2)选择数据源。在当前的数据资产库中识别短板并找到数据源以弥补短板。
- 3)采集和提取数据资料。收集数据并加载使用它们。
- 4)设定数据假设和方法。通过对数据进行剖析、可视化和挖掘来探索数据源。定义模型算法的输入、种类或者模型假设和分析方法(换句话说,通过聚类对数据进行分组等)。
- 5)集成和调整数据进行分析。模型的可行性部分取决于源数据的质量
- 6)使用模型探索数据。对集成的数据应用统计分析和机器学习算法进行验证、训练,并随着时间的推移演化模型。
- 7)部署和监控。可以将产生有用信息的那些模型部署到生产环境中,以持续监控它们的价值和有效性。
- 数据科学的过程阶段
- 大数据
- 多V
- 数据量大
- 大于100TB,在1PB~1EB之间
- 数据更新快
- 数据种类多
- 数据黏度大
- 数据波动性大
- 数据准确度低
- 数据量大
- 多V
- 大数据架构组件
- 在传统的数据仓库中,ETL;在大数据环境中,ELT。
- DW/BI和大数据概念架构
- 图14-5 DW/BI和大数据概念架构

- 图14-5 DW/BI和大数据概念架构
- 大数据来源
- 数据湖
- 数据湖是一种可以提取、存储、评估和分析不同类型和结构海量数 据的环境,可供多种场景使用
- 为了建立数据湖中的内容清单,在数据被摄取时对元数据 进行管理至关重要
- 基于服务的架构
- SBA架构包括三个主要的组件,分别是批处理层、加速层和服务层
- 1)批处理层(Batch Layer)。数据湖作为批处理层提供服务,包括近期的和历史的数据。2)加速层(Speed Layer)。只包括实时数据。3)服务层(Serving Layer)。提供连接批处理和加速层数据的接口。
- SBA架构包括三个主要的组件,分别是批处理层、加速层和服务层
- 机器学习
- 监督学习
- 基于通用规则(如将SPAM邮件与非SPAM邮件分开)
- 无监督学习
- 基于找到的那些隐藏的规律(数据挖掘)
- 强化学习
- 基于目标的实现(如在国际象棋中击败对手)。
- 监督学习
- 语义分析
- 数据和文本挖掘
- 数据和文本挖掘使用了一系列的技术
- 剖析
- 剖析尝试描述个人、群体或人群的典型行为,用于建立异常检测应用程序的行为规范,如欺诈检测和计算机系统入侵监控
- 数据缩减
- 数据缩减是采用较小的数据集来替换大数据集,较小数据集中包含了较大数据集中的大部分重要信息
- 关联
- 关联是一种无监督的学习过程,根据交易涉及的元素进行研究,找到它们之间的关联
- 聚类
- 基于数据元素的共享特征,将它们聚合为不同的簇。客户细分是聚类的一个示例。
- 自组织映射
- 自组织映射是聚类分析的神经网络方法,有时被称为Kohonen网络或拓扑有序网络,旨在减少评估空间中的维度,同时尽可能地保留距离和邻近关系,类似于多维度缩放。
- 剖析
- 数据和文本挖掘使用了一系列的技术
- 预测分析
- 预测分析( Predictive Analytics)是有监督学习的子领域,用户尝试 对数据元素进行建模,并通过评估概率估算来预测未来结果
- 规范分析
- 规范分析(Prescriptive Analytics)比预测分析更进一步,它对将会影响结果的动作进行定义,而不仅仅是根据已发生的动作预测结果。规范分析预计将会发生什么,何时会发生,并暗示它将会发生的原因。
- 非结构化数据分析
- 非结构化数据分析(Unstructured Data Analytics)结合了文本挖掘、关联分析、聚类分析和其他无监督学习技术来处理大型数据集
- 运营分析
- 运营分析(Operational Analytics),也称为运营BI或流式分析,其 概念是从运营过程与实时分析的整合中产生的
- 数据可视化
- 可视化(Visualization)是通过使用图片或图形表示来解释概念、想法和事实的过程。数据可视化通过视觉概览(如图表或图形)来帮助理解基础数据。
- 数据混搭
- 数据混搭(Data Mashups)将数据和服务结合在一起,以可视化的方式展示见解或分析结果。
- 数据科学
- 概要
- 14.2 活动
- 定义大数据战略和业务需求
- 包括以下评估标准
- 1)组织试图解决什么问题,需要分析什么。
- 2)要使用或获取的数据源是什么。
- 3)提供数据的及时性和范围。
- 4)对其他数据结构的影响以及与其他数据结构的相关性。
- 5)对现有建模数据的影响。包括扩展对客户、产品和营销方法的知识。
- 包括以下评估标准
- 选择数据源
- 大数据环境可以快速获取大量数据,但随着时间的推移需要进行持续管理,需要了解以下基本事实
- 1)数据源头。2)数据格式。3)数据元素代表什么。4)如何连接其他数据。5)数据的更新频率。
- 大数据环境可以快速获取大量数据,但随着时间的推移需要进行持续管理,需要了解以下基本事实
- 获得和接收数据源
- 一旦确定好数据资料,就需要找到它们,有时候还需要购买它们, 并将它们提取(加载)到大数据环境中
- 制定数据假设和方法
- 集成和调整数据进行分析
- 准备用于分析的数据包括了解数据中的内容、查找各种来源的数据间的链接以及调整常用数据以供使用。
- 使用模型探索数据
- 填充预测模型
- 需要使用历史信息预先填充配置预测模型,这些信息涉及模型中的客户、市场、产品或模型触发因素之外的其他因素。
- 训练模型
- 需要通过数据模型进行训练。训练包括基于数据重复运行模型以验证假设,将导致模型更改。训练需要平衡,通过针对有限数据文件夹的训练避免过度拟合。
- 评估模型
- 针对训练集进行模型构建、评估和验证。此时,需要对业务需求进行完善,早期的可行性指标可以指导进一步处理或废弃需求的管理工作。
- 创建数据可视化
- 模型的数据可视化必须满足与模型目的相关的特定需求,每个可视化应该能够回答一个问题或提供一个见解。设定可视化的目的和参数:时间点状态、趋势与异常、移动部分之间的关系、地理差异及其他。
- 填充预测模型
- 部署和监控
- 满足业务需求的模型,必须以可行的方式部署到生产中,以获得持续监控。这些模型需要被改进和维护,有几种建模技术可供实施。
- 定义大数据战略和业务需求
- 14.3 工具
- MPP无共享技术和架构
- 大规模并行处理(MPP)的无共享数据库技术,已成为面向数据科 学的大数据集分析标准平台
- 基于分布式文件的数据库
- 分布式文件的解决方案技术,如开源的Hadoop,是以不同格式存储巨量数据的廉价方式。
- MapReduce模型有三个主要步骤:
- 映射
- 识别和获取需要分析的数据
- 洗牌
- 依据所需的分析模式组合数据
- 归并
- 删除重复或执行聚合,以便将结果数据集的大小减少到需要的规模
- 映射
- MapReduce模型有三个主要步骤:
- 分布式文件的解决方案技术,如开源的Hadoop,是以不同格式存储巨量数据的廉价方式。
- 数据库内算法
- 数据库内算法(In-database algorithm)使用类似MPP的原则。MPP无共享架构中的每个处理器可以独立运行查询,因此可在计算节点级别实现新形式的分析处理,提供数学和统计功能,提供可扩展数据库内算法的开源库,用于机器学习、统计和其他分析任务。
- 大数据云解决方案
- 有些供应商为大数据提供包括分析功能的云存储和集成整合能力。
- 统计计算和图形语言
- R语言是用于统计计算和图形的开源脚本语言和环境。
- 数据可视化工具集
- 与传统的可视化工具相比,这些工具具有以下优势:
- 1)复杂的分析和可视化类型,如格子图、火花线、热图、直方图、瀑布图和子弹图。2)内置可视化最佳实践。3)交互性,实现视觉发现。
- 与传统的可视化工具相比,这些工具具有以下优势:
- MPP无共享技术和架构
- 14.4 方法
- 解析建模
- 解析模型与不同的分析深度相关联
- 描述性建模以紧凑的方式汇总或表示数据结构。
- 解释性建模是数据统计模型的应用,主要是验证关于理论构造的因果假设。
- 将数据集随机分为三个部分:训练集、测试集和校验集。训练集用于拟合模型,测试集用于评估最终模型的泛化误差,校验集用于预测选择的误差。
- 解析模型与不同的分析深度相关联
- 大数据建模
- 解析建模
- 14.5 实施指南
- 战略一致性
- 战略交付成果应考虑以下因素
- 1)信息生命周期。2)元数据。3)数据质量。4)数据采集。5)数据访问和安全性。6)数据治理。7)数据隐私。8)学习和采用。9)运营。
- 战略交付成果应考虑以下因素
- 就绪评估/风险评估
- 业务相关性
- 业务准备情况
- 经济可行性
- 原型
- 可能最具挑战性的决策将围绕数据采购、平台开发和资源配置进行。
- 数字资料存储有许多来源,并非所有来源都需要内部拥有和运营。有些可以买,其他的可以租赁。
- 市场上有多种工具和技术,满足一般需求将是一个挑战。
- 及时保护具有专业技能的员工,并在实施过程中留住顶尖人才,可能需要考虑替代方案,包括专业服务、云采购或合作
- 培养内部人才的时间可能会超过交付窗口的时间
- 组织和文化变迁
- 与DW/BI一样,大数据实施将汇集许多关键的跨职能角色,包括:
- 1)大数据平台架构师。硬件、操作系统、文件系统和服务。2)数据摄取架构师。数据分析、系统记录、数据建模和数据映射。提供或支持将源映射到Hadoop集群以进行查询和分析。3)元数据专家。元数据接口、元数据架构和内容。4)分析设计主管。最终用户分析设计、最佳实践依靠相关工具集指导实施,以及最终用户结果集简化。5)数据科学家。提供基于统计和可计算性的理论知识,交付适当的工具和技术,应用到功能需求的架构和模型设计咨询。
- 与DW/BI一样,大数据实施将汇集许多关键的跨职能角色,包括:
- 战略一致性
- 14.6 大数据和数据科学治理
- 可视化渠道管理
- 数据科学和可视化标准
- 数据安全
- 元数据
- 数据质量
- 大多数高级数据质量工具集都提供了一些功能,使组织能够测试假设,并构建有关其数据的知识。例如:
- 1)发现。信息驻留在数据集中的位置。2)分类。基于标准化模式存在哪些类型的信息。3)分析。如何填充和构建数据。4)映射。可以将哪些其他数据集与这些值匹配。
- 大多数高级数据质量工具集都提供了一些功能,使组织能够测试假设,并构建有关其数据的知识。例如:
- 度量指标
- 技术使用指标
- 加载和扫描指标
- 加载和扫描指标定义了提取率以及与用户社区的交互。
- 学习和故事场景
- 指标可以包括效益的量化、成本预防或避免,以及启动和实现效益之间的时间长度
- 常用的测量方法包括:
- 1)已开发模型的数量和准确性。2)已识别的机会中实现的收入。3)避免已识别的威胁所降低的成本。
- 14.1 引言
- 考察分值&知识点
- 考察分值
- 4分
- 知识点
- 考察分值
DAMA数据管理知识体系(第14章 大数据和数据科学)
news2026/4/3 8:47:55
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2201286.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

论文阅读(十二):Attention is All You Need
文章目录 一、循环神经网络1.1RNN模型1.1.1RNN模型简介1.1.2RNN基本结构1.1.3权重共享机制1.1.4RNN局限性:长期依赖问题与梯度消失 1.2LSTM模型1.2.1LSTM核心思想1.2.2遗忘门1.2.3输入门1.2.4更新细胞状态1.2.5输出门1.2.6参数更新 二、Seq2Seq机制2.1RNN结构的局限…

react 知识点汇总(非常全面)
React 是一个用于构建用户界面的 JavaScript 库,由 Facebook 开发并维护。它的核心理念是“组件化”,即将用户界面拆分为可重用的组件。
React 的组件通常使用 JSX(JavaScript XML)。JSX 是一种 JavaScript 语法扩展,…
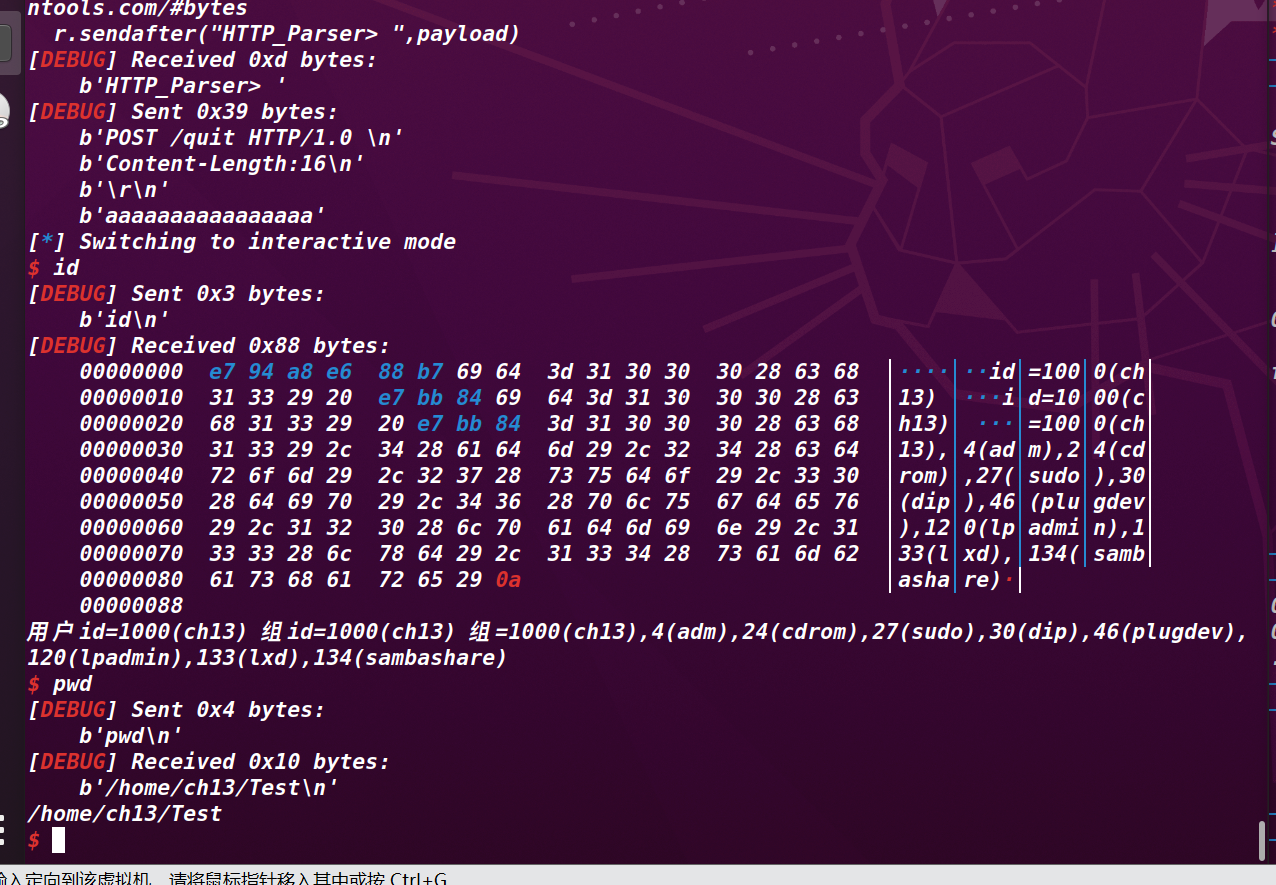
house_of_muney
house_of_muney
首先介绍一下house of muney 这个利用原理:
在了解过_dl_runtime_resolve的前提下,当程序保护开了延迟绑定的时候,程序第一次调用相关函数的时候会执行下面的命令
push n
push ModuleID
jmp _dl_runtime_resolve
这里的n…
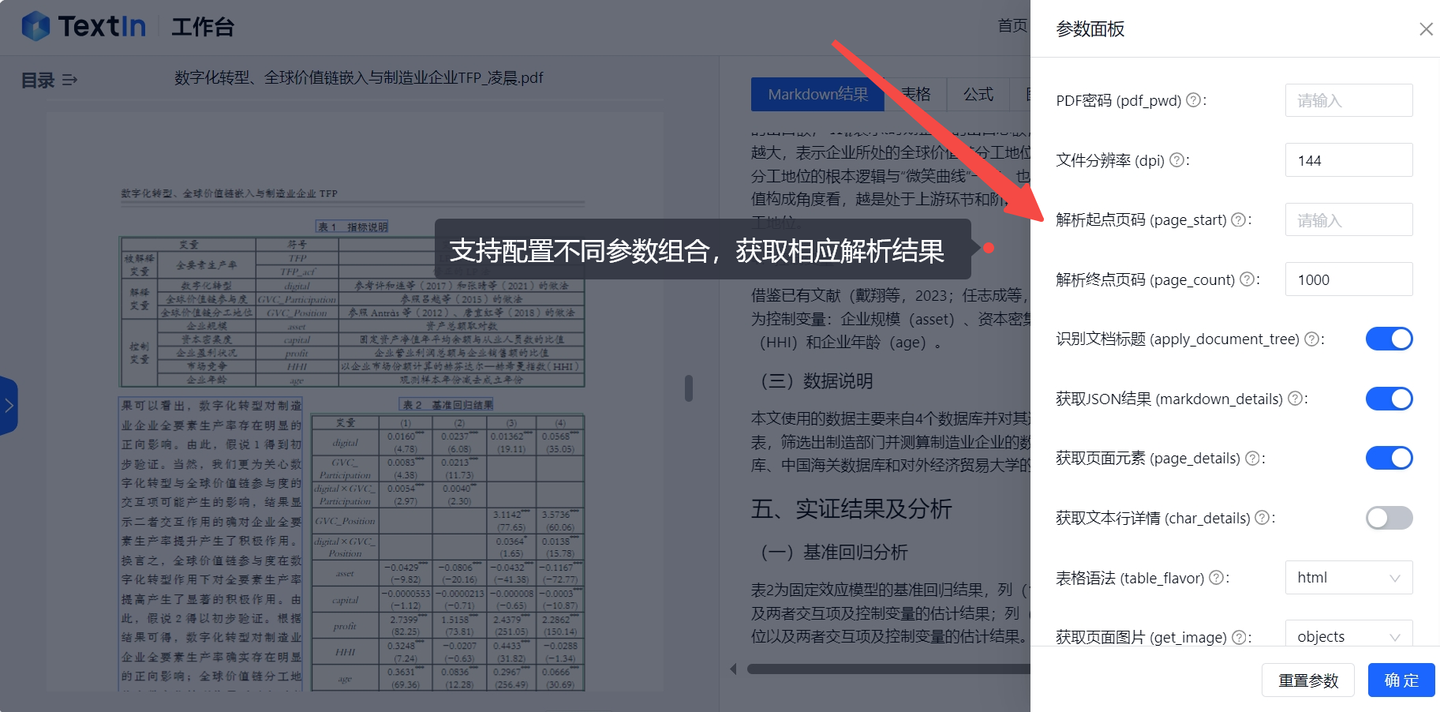
OCR+PDF解析配套前端工具开源详解!
目录 一、项目简介
TextIn为相关领域的前端开发提供了优秀的范本。
目前项目已在Github上开源!
二、性能特色
三、安装使用
安装依赖启动项目脚本命令项目结构
四、效果展示 面对日常生活和工作中常见的OCR识别、PDF解析、翻译、校对等场景,配套的…


打造直播美颜平台的关键技术:视频美颜SDK的深度解析
本篇文章,小编将深入解析视频美颜SDK的关键技术,探讨其在打造直播美颜平台中的作用。
一、视频美颜SDK的定义与功能
视频美颜SDK是一套专门为实时视频处理而设计的软件开发工具包。其主要功能包括人脸检测、肤色美化、瑕疵修复、虚化背景、实时滤镜等。…

Python对PDF文件的合并操作
在处理 PDF 文件时,合并多个 PDF 文件为一个单一文件或者将某个单一文件插入某个PDF文件是一个常见的需求。Python 提供了多种库来实现这一功能,其中 PyPDF2 是一个非常流行的选择。该库提供了简单易用的接口,包括 merge() 方法,可…

CRE6281B1 (宽VCC:8-45V PWM电源芯片)
CRE6281B1 是一款外驱功率管的高度集成的电流型PWM 控制 IC,为高性能、低待机功率、低成本、高效率的隔离型反激式开关电源控制器。在满载时,CRE6281B1工作在固定频率(65kHz)模式。在负载较低时,采用节能模式,实现较高的功率转换效…

关于Allegro导出Gerber时的槽孔问题
注意点一:
如果设计的板子中有 槽孔和通孔(俗称圆孔),不仅要NC Drill, 还要 NC Route allegro导出的槽孔文件后缀是 .rou 圆型孔后缀 是 .drl ,出gerber时需要看下是否有该文件。
注意点二:
导出钻孔文件时,设置参…

Hi3061M开发板——系统时钟频率
这里写目录标题 前言MCU时钟介绍PLLCRG_ConfigPLL时钟配置另附完整系统时钟结构图 前言
Hi3061M使用过程中,AD和APT输出,都需要考虑到时钟频率,特别是APT,关系到PWM的输出频率。于是就研究了下相关的时钟。
MCU时钟介绍
MCU共有…

22.1 K8S之KubeSphere实现中间件高可用集群
22.1 K8S之KubeSphere实现中间件高可用集群 一. 章节概述二. WordPress1. WordPress 简介---------------------------------------------------------------------------------------------------一. 章节概述 二. WordPress
1. WordPress 简介
创建并部署 WordPress

MySQL 数据库的性能优化方法方法有哪些?
MySQL 数据库的性能优化方法方法有哪些?
从开发角度来看,一般可以从 SQL 和库表设计两部分优化性能。
SQL 优化
根据慢sql日志,找出需要优化的一些sql语句。
常见优化方向:
避免select *,只查询必要的字段&#x…


sass学习笔记(1.0)
1.使用变量
sass可以像声明变量那样进行使用,这样同样的样式,就可以使用相同的变量来提高复用。
语法为:$ 变量名 在界面中也可以正常的显示 当然了,变量之间也可以相互引用,比如下面
div{$_color: #d45387;$BgColo…

kibana 删除es指定数据,不是删除索引
1 查询条件查询出满足条件的数据
GET /order_header_idx_202410/_search {"from":0,"size":10,"query":{"bool":{"filter":[{"term":{"oh_tenantId":{"value":"0211000001",&…

NeuVector部署、使用与原理分析
文章目录 前言1、概述2、安装与使用2.1、安装方法2.1.1、部署NeuVector前的准备工作2.1.1.1 扩容系统交换空间2.1.1.2 Kubernetes单机部署2.1.1.2.1 部署Docker2.1.1.2.2 部署Kubectl2.1.1.2.3 部署Minikube 2.1.1.3 Helm部署 2.1.2、使用Helm部署NeuVector 2.2、使用方法2.2.1…
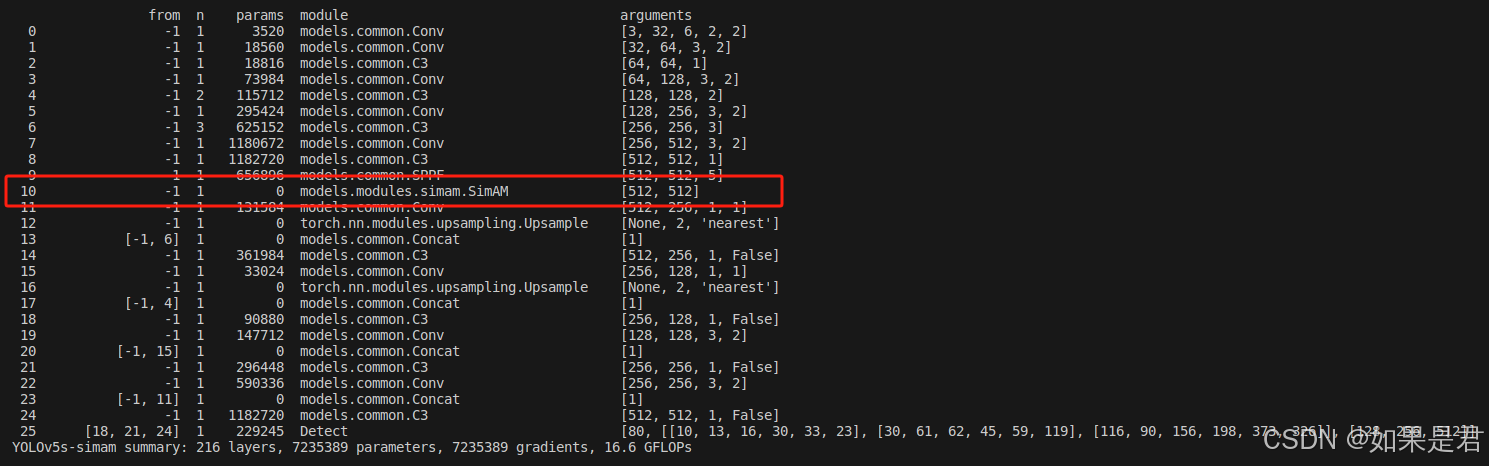
YOLOv5改进——添加SimAM注意力机制
目录
一、SimAM注意力机制核心代码
二、修改common.py
三、修改yolo.py
三、建立yaml文件
四、验证 一、SimAM注意力机制核心代码
在models文件夹下新建modules文件夹,在modules文件夹下新建一个py文件。这里为simam.py。复制以下代码到文件里面。
import…
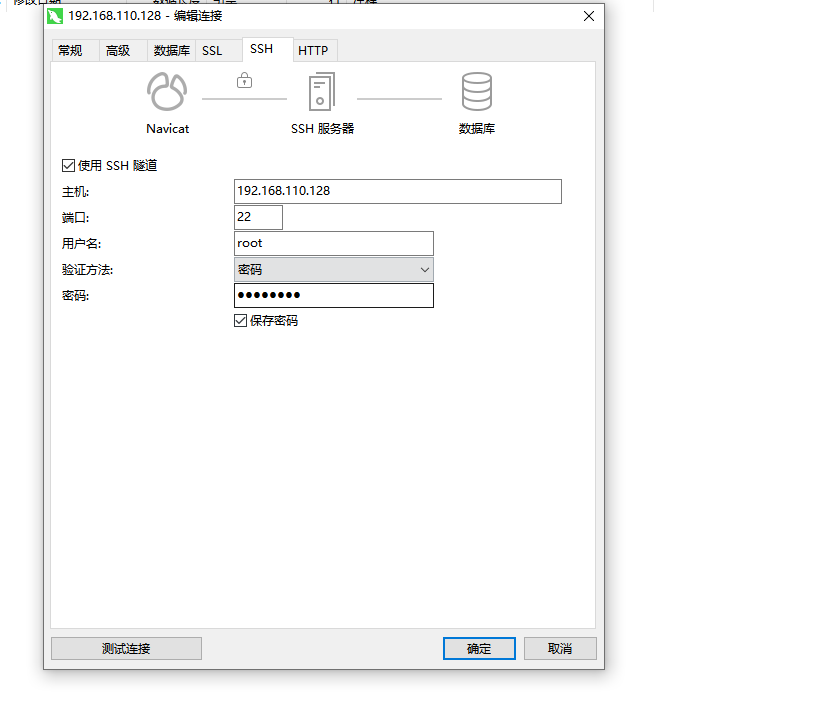
Mysql中创建用户并设置任何主机连接
Mysql中创建用户并设置任何主机连接 文章目录 Mysql中创建用户并设置任何主机连接背景解决方式 背景
在linux上安装mysql,默认用户是root,但是用navicat连接不了,必须要用ssh隧道连接,现在想用任何主机只要输入账号密码之后就可以连接
解决方式 #创建一个指定用户和IP链接的用…

Java:数据结构-ArrayList和顺序表(2)
一 ArrayList的使用
1.ArrayList的构造方法
第一种(指定容量的构造方法)
创建一个空的ArrayList,指定容量为initialCapacity。
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData new Object[init…

鸿蒙微内核IPC数据结构
鸿蒙内核IPC数据结构
内核为任务之间的通信提供了多种机制,包含队列、事件、互斥锁、信号量等,其中还有Futex(用户态快速锁),rwLock(读写锁),signal(信号)。
队列
队列又称为消息队列,是一种常用于任务间通信的数据…