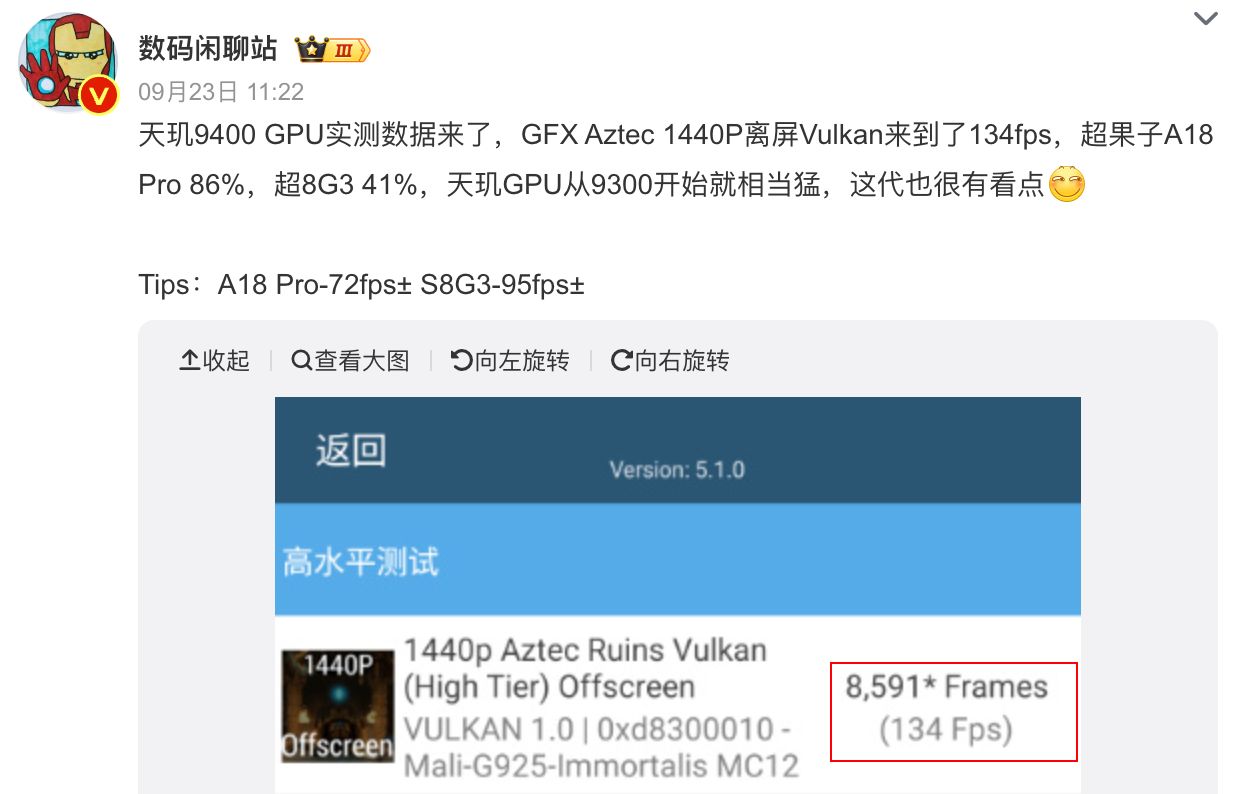
文章目录
- 前言
- 一、RNN介绍
- 1.基本结构
- 2.隐藏态特点
- 3.输出计算
- 二、RNN循环由来与局限
- 三、RNN延申
前言
- 因为传统神经网络无法训练出具有顺序的数据且模型搭建时没有考虑数据上下之间的关系。所以我们提出了循环神经网络。
一、RNN介绍
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络架构。与传统神经网络(Feedforward Neural Network, FNN)不同,RNN能够在处理序列输入时具有记忆性,可以保留之前输入的信息并继续作为后续输入的一部分进行计算。

1.基本结构
RNN 的基本结构包含以下几个部分:
- 输入层(Input Layer):接收序列中的当前输入。
- 隐藏层(Hidden Layer):包含循环连接,能够接收来自上一时间步的隐藏状态。
- 输出层(Output Layer):基于隐藏层的当前状态生成输出。
RNN 的隐藏层在每一个时间步都会更新其状态,这个状态不仅取决于当前的输入,还取决于上一个时间步的隐藏状态。这使得 RNN 能够捕捉序列数据中的时间依赖性。
2.隐藏态特点
特点:引入了隐状态h(hidden state)的概念,隐状态h可以对序列形的数据提取特征,接着再转换为输出。

如上图,最开始我们输入
x
1
x_1
x1,导入最初的隐藏态
h
0
h_0
h0,
通过RNN计算公式:
h
n
=
f
(
U
x
n
+
W
h
n
−
1
+
b
)
h_n=f(Ux_n+Wh_{n-1}+b)
hn=f(Uxn+Whn−1+b)
我们可以得出后续的
h
1
=
f
(
U
x
1
+
W
h
0
+
b
)
h_1=f(Ux_1+Wh_{0}+b)
h1=f(Ux1+Wh0+b),
h
2
=
f
(
U
x
2
+
W
h
1
+
b
)
h_2=f(Ux_2+Wh_{1}+b)
h2=f(Ux2+Wh1+b)等等。
注意: 1、W是隐藏状态到隐藏状态的权重矩阵,U是输入到隐藏状态的权重矩阵,b是隐藏层的偏置向量,f 是激活函数(如 tanh 或 ReLU)。在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点;
2、LSTM和GRU中的权值则不共享。
3.输出计算

RNN结构中输入是
x
1
x_1
x1,
x
2
x_2
x2, …
x
n
x_n
xn,输出为
y
1
y_1
y1,
y
2
y_2
y2, …
y
n
y_n
yn,也就是说,输入和输出序列必须要是等长的。
根据输出结果的计算公式:
y
n
=
g
(
V
h
n
+
c
)
y_n=g(Vh_n+c )
yn=g(Vhn+c)
可以得出
y
1
=
S
o
f
t
m
a
x
(
V
h
1
+
c
)
y_1=Softmax(Vh_1+c)
y1=Softmax(Vh1+c)。
V是隐藏状态到输出的权重矩阵,c是输出的偏置向量,g 是输出层的激活函数(如 softmax 等)。
二、RNN循环由来与局限
循环由来:

上图中可以看出,RNN的网络结构中包含了一个环路,这个环路使得数据可以在网络中不断循环。是RNN的核心特征,也是其被称为“循环”神经网络的关键所在。通过这个环路,RNN可以一边记住过去的数据,一边更新到最新的数据,从而实现对序列数据的处理。
局限性:
当我们所需要的相关信息和当前预测位置之间的间隔较远时,可能会影响学习效率。这是因为梯度会随着时间的推移不断下降减少,而当梯度值变得非常小时,就不会继续学习。
三、RNN延申
尽管 RNN 能够处理序列数据,但在处理长期依赖关系时存在梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)问题。为了解决这个问题,RNN 进行了延申,包括:
长短期记忆网络(Long Short-Term Memory, LSTM):
- LSTM 通过引入三个门(遗忘门、输入门和输出门)以及一个细胞状态(Cell State)来捕获长期依赖关系。
门控循环单元(Gated Recurrent Unit, GRU):
- GRU 是 LSTM 的简化版本,通过将 LSTM 中的遗忘门和输入门合并成一个更新门,以及将细胞状态和隐藏状态合并,简化了模型结构。