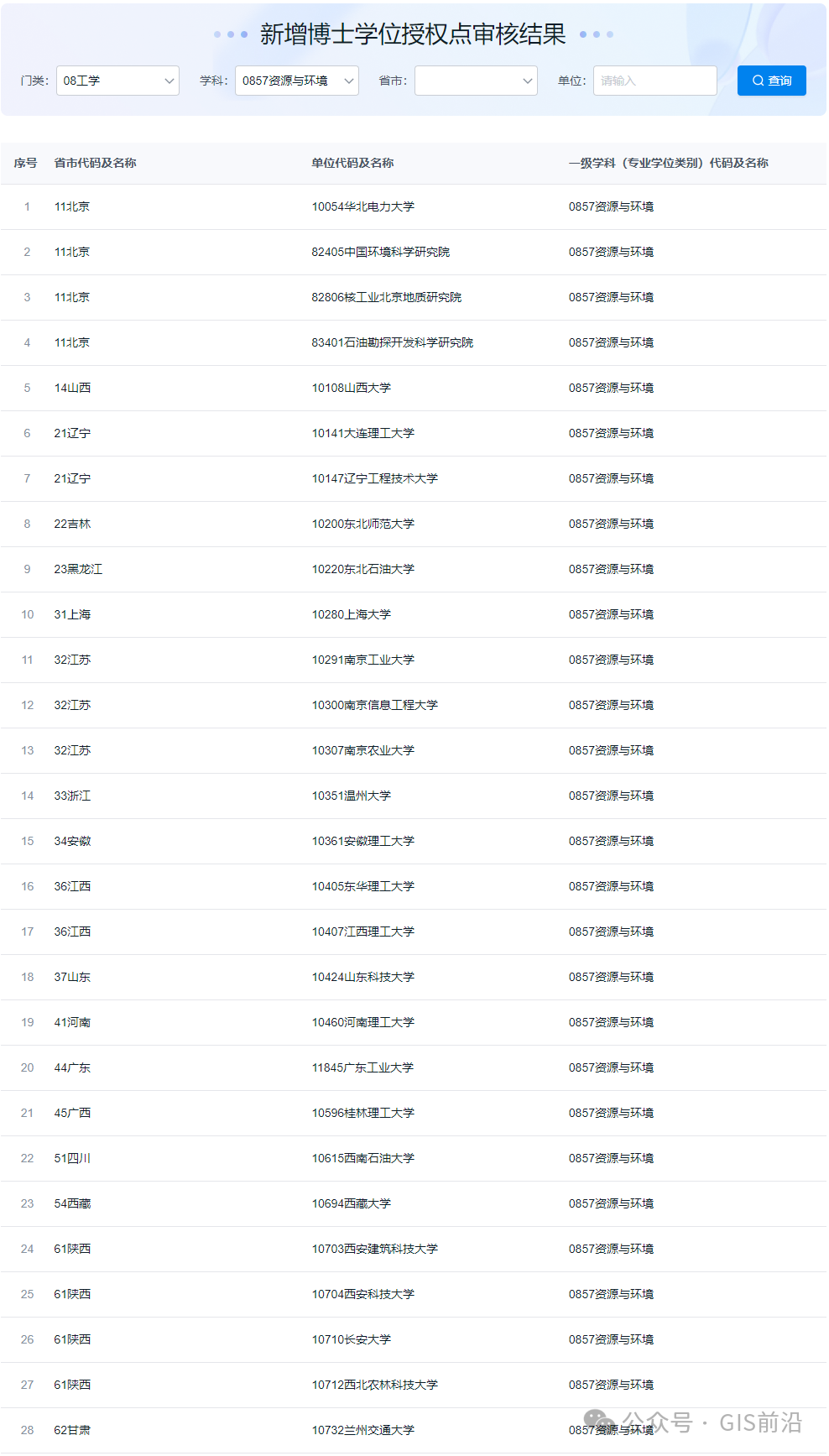
都说python做爬虫比较好,于是我跟着大家的脚步学习python进行爬虫,但是调试了半天,出现各种各样的问题,最终都得到实现了,下面我们来看具体的代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
# 如果你没有安装ChromeDriver,需要先下载并配置到环境变量
#driver_path = 'C://chromedriver127.exe'
driver_path = 'C://drivers/chromedriver.exe' ## 驱动路径
print(webdriver.__version__) ## 打印selenium的版本
service = Service(driver_path) ## 创建Serice
# 创建一个 Chrome 浏览器实例
#driver = webdriver.Chrome(executable_path=driver_path)
chrome_options = Options() ## 定义浏览器选项
chrome_options.add_argument("--headless") # 无界面模式
driver = webdriver.Chrome(service=service,options=chrome_options) ## 实现驱动
url = "https://www.read8686.com"
driver.get(url) ##开始爬虫获取
content = driver.page_source # 获取渲染后的HTML内容
# 做你需要的操作,例如解析HTML内容
print(content)
driver.quit() # 关闭浏览器执行结果:

希望对你有所帮助







![[uni-app]小兔鲜-02项目首页](https://img-blog.csdnimg.cn/img_convert/76ac29ad7495165212f0eb20b78e3949.png)







![[数据集][目标检测]手机识别检测数据集VOC+YOLO格式9997张1类别](https://i-blog.csdnimg.cn/direct/64685cdaf4b34c31838a52310e11cb9f.png)