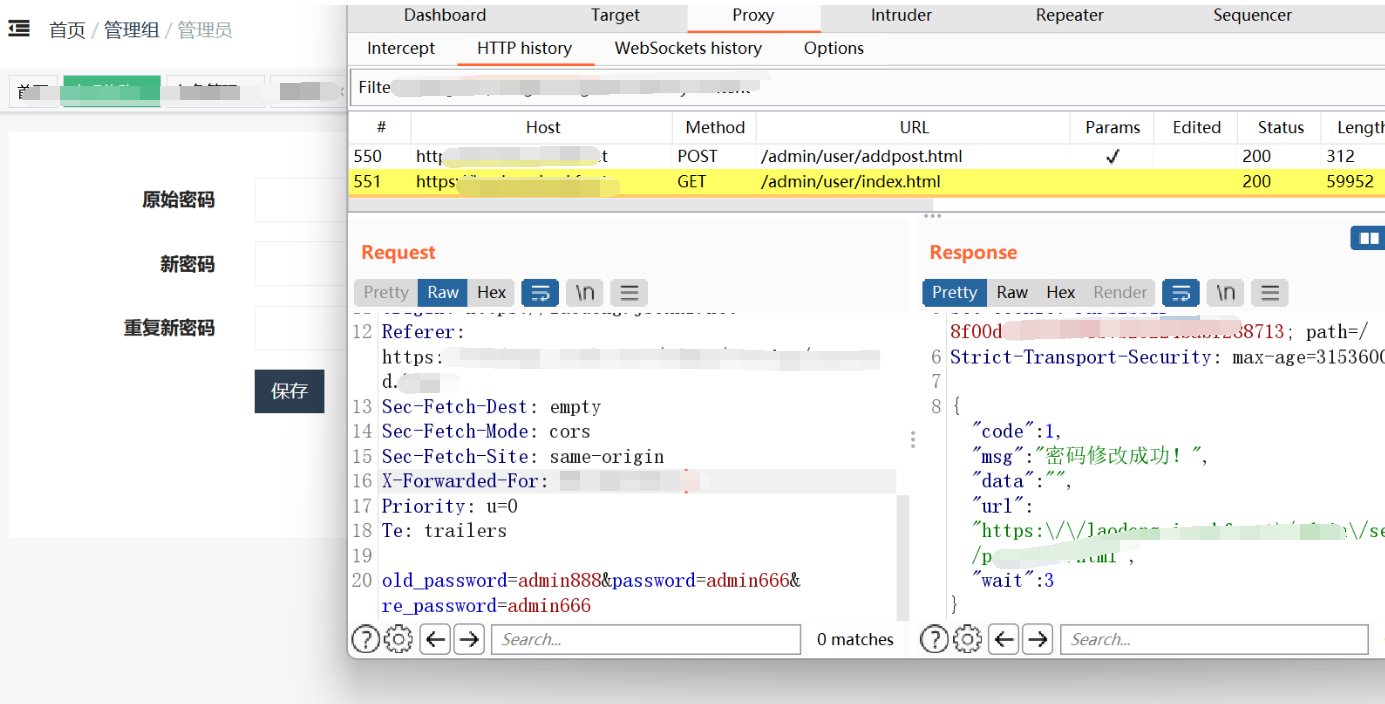
定义
- 本质上是做了意图的识别
判断两个内容的含义(包括相似、矛盾、支持度等) - 侠义
- 给定一组文本,判断语义是否相似
- Yi 分值形式给出相似度
- 广义
- 给定一组文本,计算某种自定义的关联度
- Text Entailment
判断文本是否能支持或反驳这个假设 - 主题判断
神经网络方法
- 表示型文本匹配
- 特点
- 只需要对用户新输入的问题送入模型,运行一次
实际查找中,对输入文本做一次向量化 - 运行结果与知识库中的标准问向量分别计算 loss
- 最后排序,找到最 match 的结果
- 更适用智能问答
- 用于需要分别看到两句话的场景
计算两句话相似性 - 类似于二分类任务
- 只需要对用户新输入的问题送入模型,运行一次
- 方式
- 共享encoder 参数
- 即孪生网络
- encoder 层
两句话分别输入encoder(LSTM、CNN+pool、bert) 得到句向量 - matching layer 层
- 对两个句向量进行预期分值计算
相同文本用相同参数,余弦值夹角为0,值为1,欧式距离为0 - 可以完全没有可训练参数
在评估阶段进行 cosine loss 或 欧式距离等向量分值计算
- 对两个句向量进行预期分值计算
- triplet loss

- 目标
- 使具有相同标签的样本在 embedding 空间尽量接近
- 使具有不同标签的样本在 embedding 空间尽量远离
- 方式
三元组<a, p, n>
- a 原点
- p 与a 同一类别的样本
- n 与a 不同类别的样本 - 在cv也用于人脸识别模型训练
- 目标
- 共享encoder 参数
- 特点
- 交互型文本匹配
- 特点
- 用户输入新问题,与知识库中的n 个标准问分别拼接送入模型,计算 n 次
对比把握句子重点 - 更适合问题与答案的匹配场景
因为答案长度与问题长度差异,答案与问题是两个概念的东西,共用 encoder 参数就不合适,可能需要补太多 padding - 用于需要同时看到两句话的场景
用于计算两句话相关性
- 用户输入新问题,与知识库中的n 个标准问分别拼接送入模型,计算 n 次
- 方式
- 每次计算需要两个输入
- 将两个句子拼接成长文本
在模型中判断两句话关联性,输出关联性得分
- 特点
非神经网络算法
-
Jaccard 相似度
核心逻辑:文本中元素的交集/文本中元素的并集

-
word2vec
核心逻辑:从词向量相似度得到句子相似度,将文本中所有的词的词向量相加取平均- 获取句子向量之间 余弦值
- 两个句子的相似度,等同于两个向量的余弦距离

-
BM25算法
对 TF-IDF 的改进

-
编辑距离
动态规划算法
def edit_distance(s1, s2):
m, n = len(s1), len(s2)
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
if s1[i - 1] == s2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1
return dp[m][n]
- 优点
- 可解释性强
- 跨语种
- 不需要训练模型
- 缺点
- 字符之间没有语义相似度
- 受无关词、停用词影响大
- 受语义影响大
- 文本长度对速度影响很搭
- 由一个字符串转成量一个所需的最少编辑操作次数
核心是比较两个序列相似性
应用
- 应用方向
- 短文本 vs 短文本
- 知识库问答
- 不使用文本分类的原因
- 拓展性不强
新增问题时需要重新训模型 - 相同问题的有效性
会出现无法命中相同问题的情况
- 拓展性不强
- 可以使用GPT模型
RAG 思路:检索增强
- 不使用文本分类的原因
- 聊天机器人
- 知识库问答
- 短文本 vs 长文本
- 文章检索
- 广告推荐
- 长文本 vs 长文本
新闻、文章的关联推荐
- 短文本 vs 短文本
- 实际应用
- 信息检索
搜索引擎 - nlp 最成熟的落地任务:智能问答
- 落地形式
- 人机对话
- 智能客服
- 智能音箱
- 聊天机器人
- 车载导航
- 手机助手
- 基础资源
- faq 库
- 多个问答对组成的集合
一个标准问对应一个标准审核好的标准答案 - 运行逻辑
- 用户提问
- 提问内容预处理
根据算法决定处理方式 - 找到最相似的问题
- 输出答案
- 核心
- 进行语义相似度计算
即 文本匹配
- 进行语义相似度计算
- 多个问答对组成的集合
- 书籍文档
- 网页
- 知识图谱
- 表格
- 特定领域知识
- 人工规则
- faq 库
- 答案产出方式
- 检索式
- 生成式
- 检索+生成
- 相关技术划分
- 单轮问答
- 多轮问答
- 多语种问答
- 事实性问答
- 开方性问答
- 多模态问答
问题是文字答案是语音或视频 - 选择性问答
- 抽取式问答
- 生成式问答
…
- 落地形式
- 信息检索
- 落地应用
- 信息检索
- 知识库问答
Faq 知识库



![[Python学习日记-29] 开发基础练习2——三级菜单与用户登录](https://i-blog.csdnimg.cn/direct/ca69ae135d174c47bb3c9284b5c40c9f.png)