简介
Apache Paimon 是一种数据湖的格式,支持使用 Flink 和 Spark 构建实时湖仓架构,用于流式和批处理操作。Paimon 创新性地结合了数据湖格式和LSM结构,将实时流式更新引入数据湖架构。
Paimon 提供以下核心功能:
● 实时更新:
○ 主键表支持大规模更新的写入,具有非常高的实时性,通常通过Flink Streaming进行。
○ 支持合并引擎,支持按规则更新记录。规则:删除重复项以保留最后一行、部分更新、聚合记录或保留第一行等
○ 支持定义changelog-producer,为合并引擎的更新生成正确、完整的changelog。
● 大量附加数据处理:
○ 附加表(无主键)提供大规模批处理和流处理能力,自动小文件合并。
○ 支持通过 z-order 排序进行数据压缩以优化文件布局,并使用 minmax 等索引提供基于数据跳过的快速查询。
● 数据湖功能:
○ 可扩展的元数据:支持存储Petabyte大规模数据集,支持存储大量分区。
○ 支持 ACID 事务、时间旅行和模式演变。
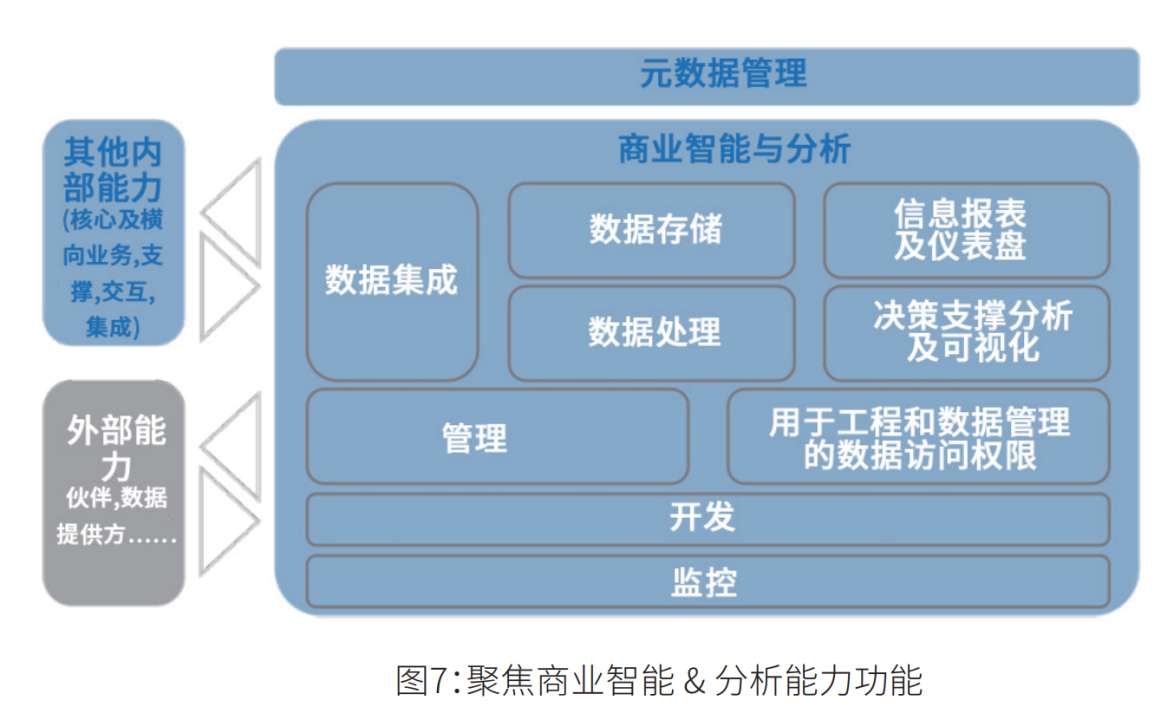
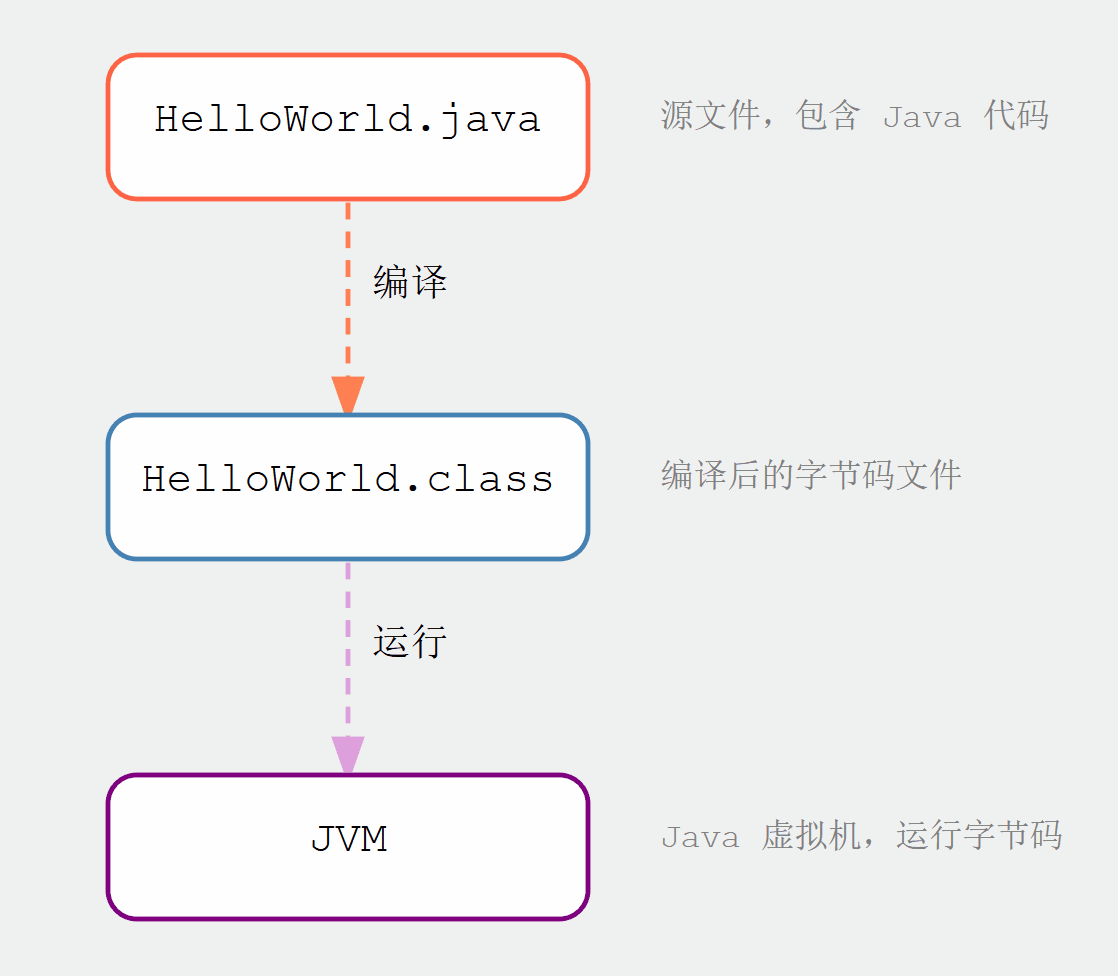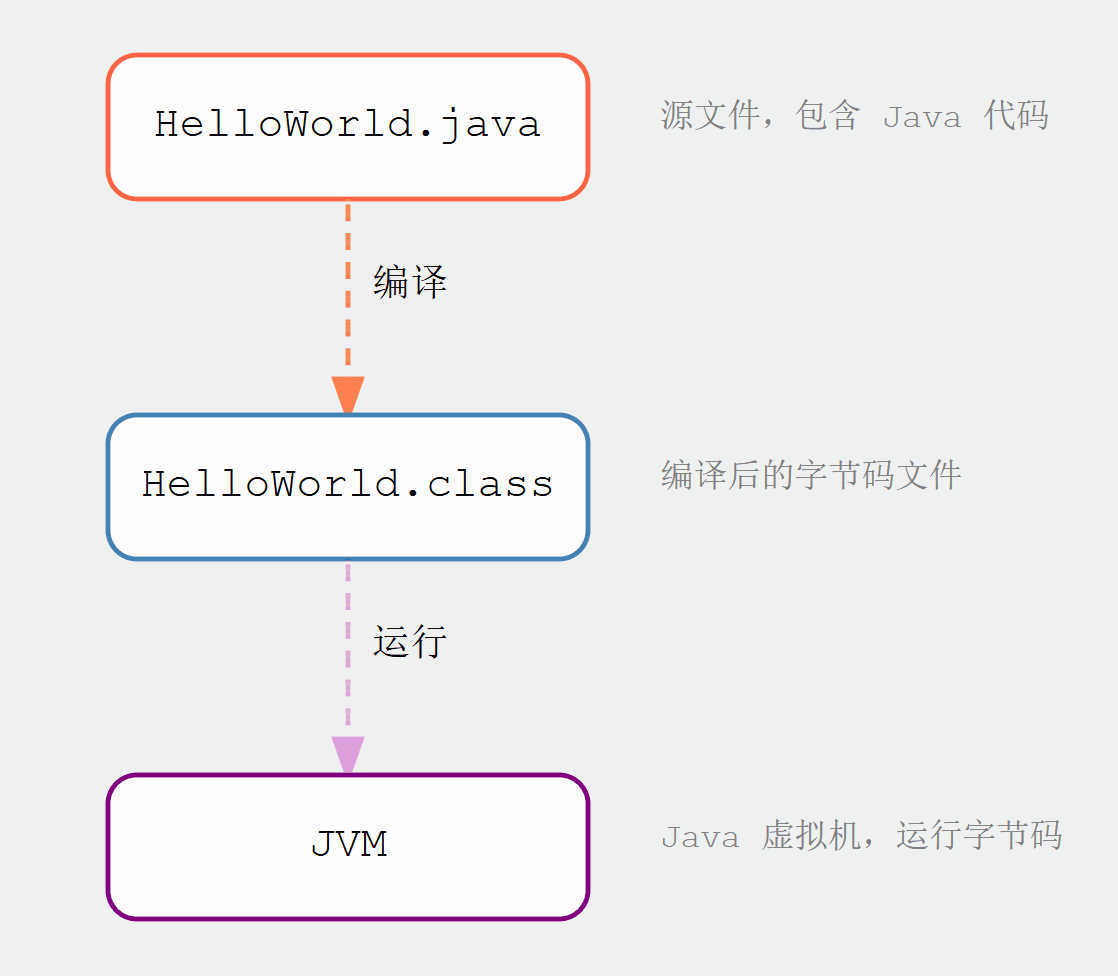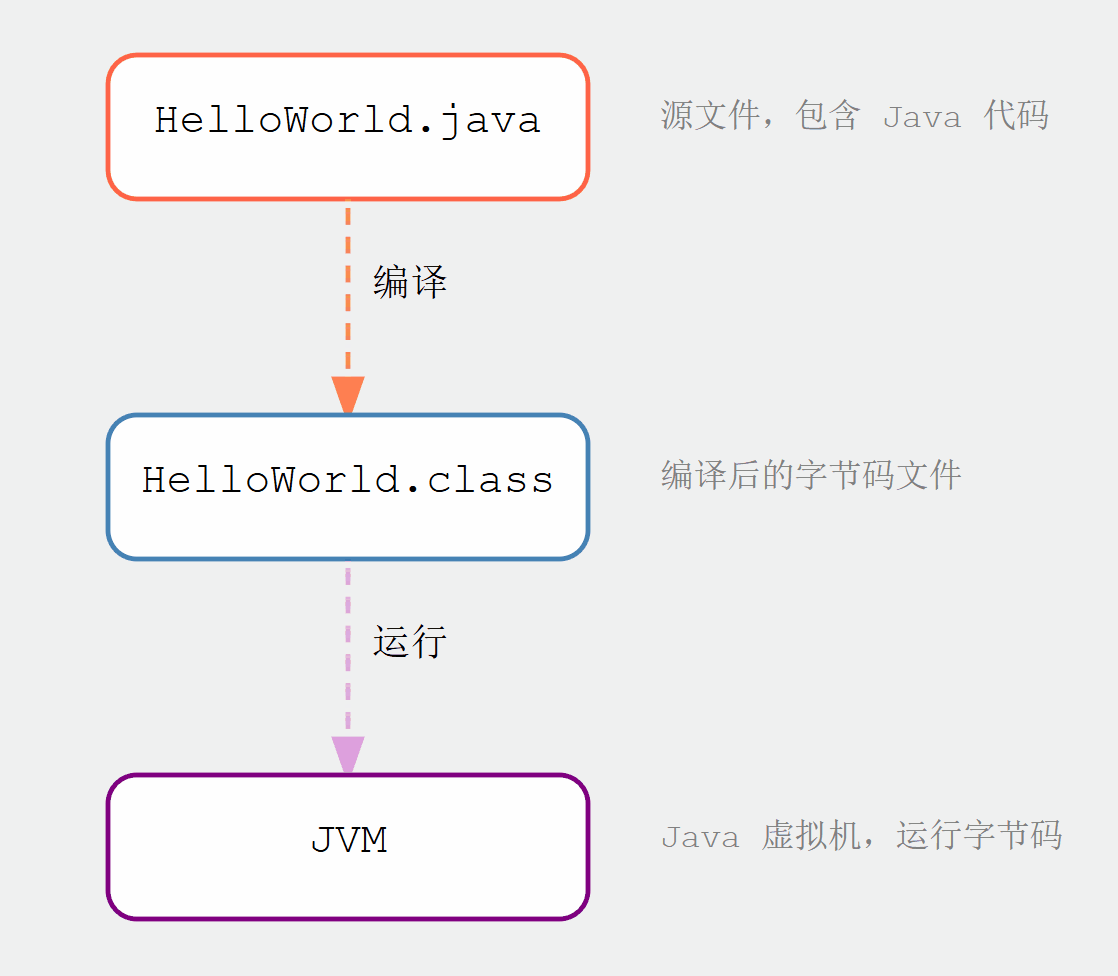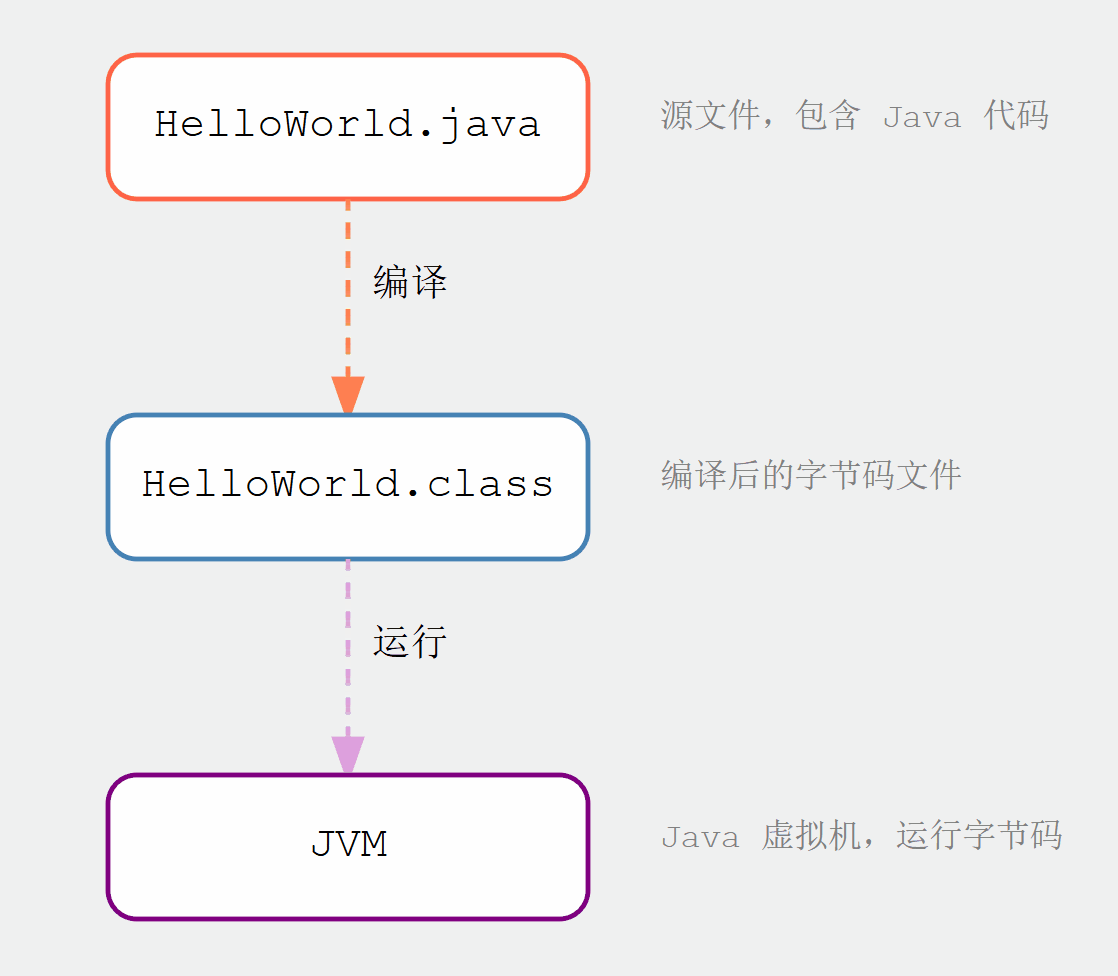
Apache Paimon 的架构

如上架构图所示:
读/写: Paimon 支持多种方式来读取/写入数据和执行 OLAP 查询。
● 对于读取,它支持消费数据
○ 从历史快照(批处理模式)
○ 从最新偏移量(在流模式下)
○ 以混合方式读取增量快照。
● 对于写入,它支持
○ 来自数据库变更日志的流式同步(CDC)
○ 从离线数据批量插入/覆盖。
生态系统:除了 Apache Flink,Paimon 还支持其他计算引擎的读取,例如 Apache Hive、Apache Spark 和 Trino。
内部的:
● 在底层,Paimon 将列式文件存储在文件系统/对象存储中
● 文件的元数据保存在manifest文件中,提供大规模存储和数据跳过。
● 对于主键表,采用LSM树结构,支持大量数据更新和高性能查询。








![[Postman]接口自动化测试入门](https://i-blog.csdnimg.cn/direct/5b5c708fe10749c2927f7325c9214f57.png)