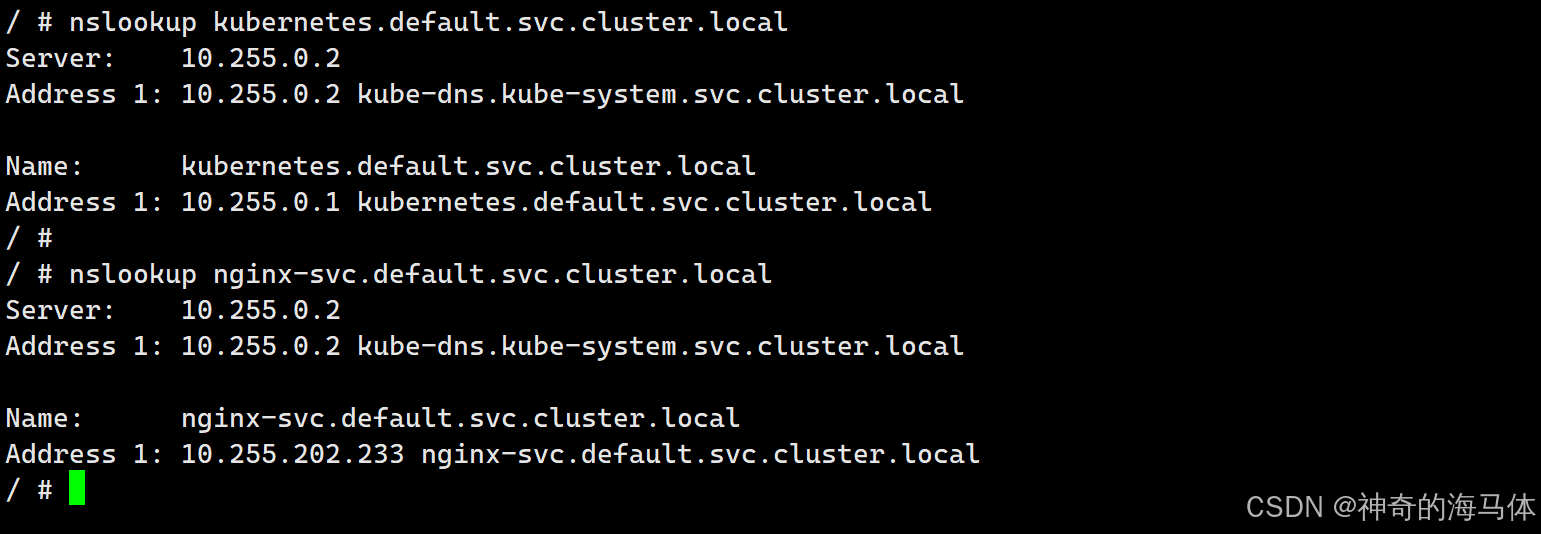
数组
- 前言
- 一、数据理论基础
- 二、数组常用操作
- 2.1 初始化数组
- 2.2 访问数组中的元素
- 2.3 插入元素
- 2.4 删除元素
- 三、数组扩展
- 3.1 遍历数组
- 3.2 数组扩容
- 总结
- 1、数组的优点
- 2、数组的不足
前言
- 在数据结构中,数组可以算得上最基本的数据结构。
- 数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。(后续我们再讲)
一、数据理论基础
- 学习数组之前我们首先要了解数组在内存中的存储方式,这样才能真正理解数组的相关操作
数组是储存在连续内存空间的相同类型的数据的集合,举一个字符数组的例子,如下图所示

- 观察上图,我们发现数组首个元素的索引为 0,这似乎有些反直觉,因为从 1 开始计数会更自然。那是因为,索引本质上是内存地址的偏移量。首个元素的地址偏移量是 0,因此它的索引为 0 是合理的。
二、数组常用操作
2.1 初始化数组
- 我们可以根据需求选用数组的两种初始化方式:无初始值、给定初始值。在未指定初始值的情况下,大多数编程语言会将数组元素初始化为 0
代码如下(示例):
# 初始化数组
arr: list[int] = [0] * 5 # [ 0, 0, 0, 0, 0 ]
nums: list[int] = [1, 3, 2, 5, 4] # [1, 3, 2, 5, 4]
2.2 访问数组中的元素
- 数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。

- 从上图中我们知道,我们只要知道数组第一位元素地址跟某元素的索引就可以轻松的算出来该元素的地址。
-
计算公式
- 元素内存地址 = 数组内存地址(即第一位元素的地址) + 元素长度(因为存的都是相同类型的元素,所以长度一样) x 元素索引 譬如求数组中 E 的元素的内存地址
- 16 = 00 + 4 x 4
代码如下(示例):
# 导包
import random
# 定义数组列表
list1: list[int] = [1, 3, 2, 5, 4]
def random_access(list1: list[int]) -> int:
"""
随机访问数组中的元素演示
:param list1: 接受 数组
:return: 返回数组中的随机一个元素
"""
# 在区间 [0, len(nums)-1] 中随机抽取一个数字
random_index = random.randint(0, len(list1) - 1)
# 获取并返回随机元素
random_num = list1[random_index]
return random_num
if __name__ == '__main__':
res = random_access(list1)
print(res)
数组中访问元素非常高效,我们可以在 O(1) 时间内访问数组中的任意一个元素
2.3 插入元素
- 因为数组中的元素在内存中是连续存在的,所以插入元素的时候,需要将插入位置后的所有元素都往后移动一位,之后再将元素赋值给该索引,如下图所示:

因为数组的长度是固定的,因此插入元素的时候,必定导致尾部元素丢失,这个我们在列表中在进行讨论。
代码如下(示例):
def insert(nums, num, index):
"""
在数组的索引 index 处插入元素 num
:param nums: 接受的数组
:param num: 要插入的元素
:param index: 要插入的位置(索引)
:return: 无返回值
"""
"""在数组的索引 index 处插入元素 num"""
# 把索引 index 以及之后的所有元素向后移动一位
for i in range(len(nums) - 1, index, -1):
nums[i] = nums[i - 1]
# 将 num 赋给 index 处的元素
nums[index] = num
if __name__ == '__main__':
nums = ['A', 'B', 'C', 'D', '']
print(f'插入前的数组为{nums}') # ['A', 'B', 'C', 'D', '']
insert(nums, 'E', 1)
print(f'插入前的数组为{nums}') # ['A', 'E', 'B', 'C', 'D']
2.4 删除元素
- 跟插入元素相同,删除元素也需要移动元素
- 数组中元素不能删除,只能覆盖
- 若删除索引 1 处的元素,就要将索引 1 之后的元素都往前移动一位,如下图所示:

删除 E 后, 你会发现数组中最后有两个 D ,这个我们之后在讨论
代码如下(示例):
def remove(nums, index):
"""
删除索引 index 处的元素
:param nums: 传入的数组
:param index: 要删除的元素的索引
:return: 无
"""
# 把索引 index 之后的所有元素向前移动一位
for i in range(index, len(nums) - 1, 1):
nums[i] = nums[i + 1]
if __name__ == '__main__':
nums = ['A', 'E', 'B', 'C', 'D']
print(f'删除前的数组为{nums}') # ['A', 'E', 'B', 'C', 'D']
remove(nums, 1)
print(f'删除后的数组为{nums}') # ['A', 'B', 'C', 'D', 'D']
三、数组扩展
3.1 遍历数组
- 我们既可以通过索引遍历数组,也可以直接遍历获取数组中的每个元素
代码如下(示例):
def traverse1(nums):
"""遍历数组"""
count = 0
# 通过索引遍历数组
for i in range(len(nums)):
print(nums[i])
count += 1
def traverse2(nums):
# 直接遍历数组元素
for num in nums:
print(num)
def traverse3(nums):
# 同时遍历数据索引和元素
# enumerate()函数会返回一个枚举对象,这个对象包含了列表中每个元素的索引和值。
# enumerate函数默认从0开始计数索引,如果你需要从其他的数字开始,可以通过传递一个可选的起始参数来实现。
for i, num in enumerate(nums):
print(f'索引是{i},对应的元素是{num}')
if __name__ == '__main__':
nums = ['A', 'B', 'C', 'D', 'E']
traverse1(nums) # A B C D E
traverse2(nums) # A B C D E
traverse3(nums) # A B C D E
3.2 数组扩容
- 在Python中数组的长度是不可变的,因为程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。
- 如果我们想要扩容数组的话,只能重新建立一个新数组,然后将原数组的元素依次复制到新数组,这是一个时间复杂度为 O ( n ) O(n) O(n)的操作,当数组很大的时候,很消耗时间。
代码如下(示例):
def extend(nums, enlarge):
"""
扩展数组长度
:param nums: 原数组
:param enlarge: 要扩多大的空间
:return: 返回扩容后的新数组
"""
# 初始化一个扩展长度后的数组
res = [0] * (len(nums) + enlarge)
# 将原数组中的所有元素复制到新数组
for i in range(len(nums)):
res[i] = nums[i]
# 返回扩展后的新数组
return res
if __name__ == '__main__':
nums = ['A', 'B', 'C', 'D', 'E']
print(f'扩容前的数组为{nums}') # ['A', 'B', 'C', 'D', 'E']
res = extend(nums, 3)
print(f'扩容后的数组为{res}') # ['A', 'B', 'C', 'D', 'E', 0, 0, 0]
总结
1、数组的优点
- 空间效率高:数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问:数组允许在 O ( 1 ) O(1) O(1) 时间内访问任何元素。
- 缓存局部性:当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度
2、数组的不足
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变:数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费:如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。