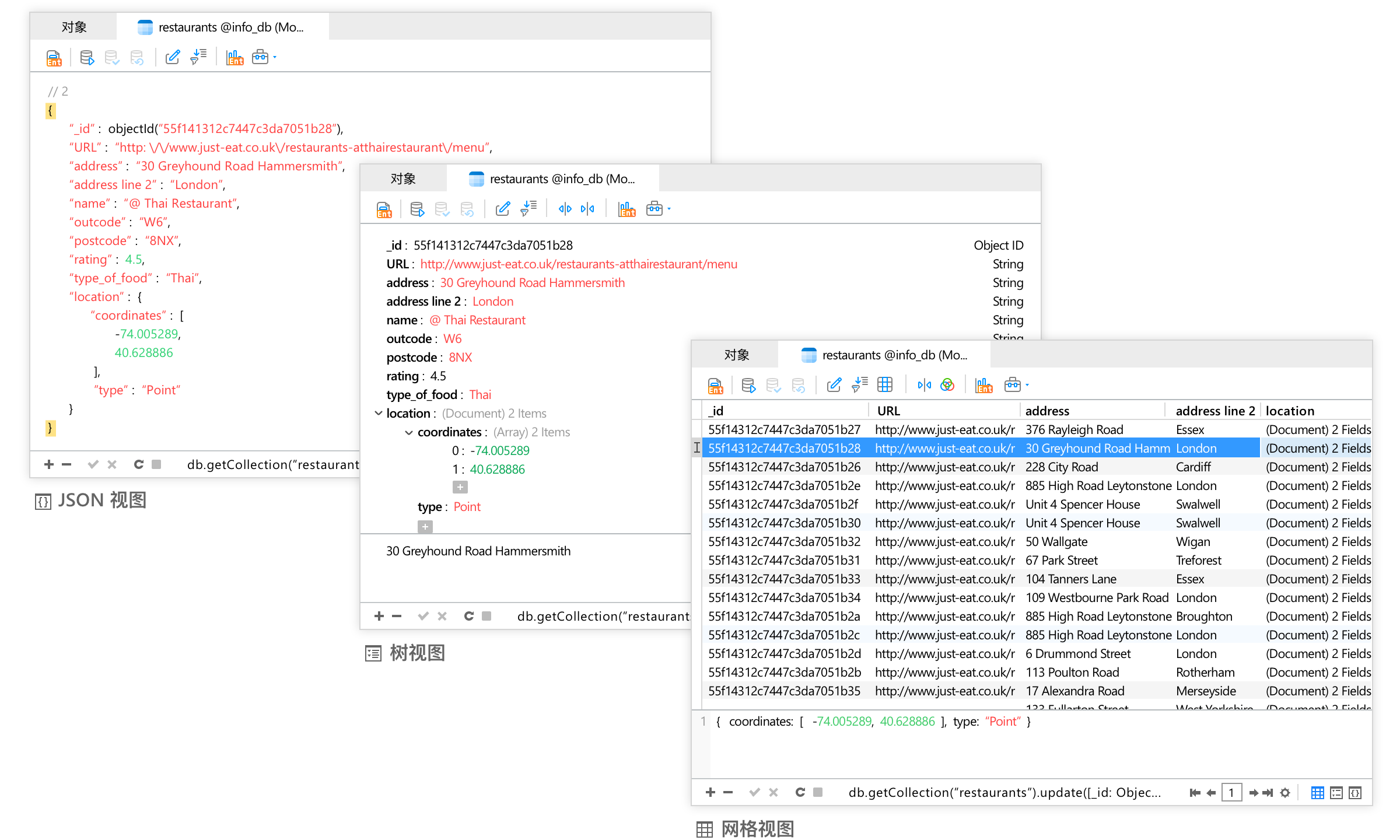
文章目录
- 极短临界区互斥锁的短板
- 原子操作类 atomic
- atomic 原子操作原理 CAS
- CAS 操作解决多线程创建链表的节点丢失问题
- 多线程下的 shared_ptr 智能指针
- 最简单的单例模式
极短临界区互斥锁的短板
![]()
如果两个线程同时对一个共享资源变量x进行自增操作将会出现线程安全问题,这个线程安全问题主要是两个线程同时对同一个变量进行控制,而自增操作不是原子操作,将会导致数据不一致问题;
原子操作是指在多线程或并发环境下,某个操作能够保证不会被中断,即这个操作一旦开始就会运行到结束,中见不会由任何原因被其他线程干扰,这意味着从外部观察到的这些操作只有两种状态;
- 未开始
- 已结束
原子操作不存在中间状态;
int x = 0;
class Func
{
public:
void operator()()
{
for (int i = 0; i < 10000; ++i)
{
++x;
}
}
};
int main()
{
Func func;
thread t1(func);
thread t2(func);
t1.join();
t2.join();
cout << x << endl;
return 0;
}
在这个例子中定义了一个Func类作为仿函数,定义了一个全局变量x并初始化为0,在仿函数中对全局变量x自增10000次,创建两个线程都调用这个仿函数函数对象;
运行结果为:
$ ./mytest
18797
$ ./mytest
18475
$ ./mytest
13067
每次的调用结果都不同但是每次的结果都不会是预期结果20000,因为自增操作不是原子操作;
一个自增操作,如++x将会有三个步骤;
mov eax, DWORD PTR [rip+x] ; 从全局变量 `x` 加载值到寄存器 `eax`
inc eax ; 增加寄存器 `eax` 的值
mov DWORD PTR [rip+x], eax ; 将增加后的值存回全局变量 `x`
三条指令代表线程不会被一直调度,而是存在一个时间片,当时间片到了之后就要调度其他的线程进行执行,而线程的调度不仅仅是直接切换,它需要保存当前线程执行的上下文;
假设t1和t2两个线程,t1线程将全局变量x加载值到寄存器eax中,加载过后增加eax的值,此时t1的时间片到了,t2被调度,在t2被调度之前t1将需要保存当前上下文,即当前eax寄存器中保存的值,此时内存中全局变量的值仍为0,即t1线程中eax寄存器中被自增后的值并未写回内存中;
当t2被调度后同样的执行了与t1相同的步骤,但t2将数据加载进寄存器,进行自增,写回内存并没有被中断,写回内存后当前的全局变量x即为1;
t2调度完毕后切换t1进行调度,t1首先加载上下文,即将之前保存的上下文eax中的值加载回eax寄存器中,而后进行最后一步,即把eax中的值写回内存中,当写回内存后x仍为1,这就是进程安全导致的数据不一致问题;

只有单条指令的操作是具有原子性的,凡是具有多条指令的操作都为非原子性的;
这种情况可以通过加锁来解决问题,使用mutex互斥锁;
int x = 0;
class Func
{
public:
void operator()(mutex &mtx)
{
for (int i = 0; i < 10000; ++i)
{
unique_lock<mutex> lock(mtx);
++x;
}
}
};
int main()
{
Func func;
mutex mtx;
thread t1(func, ref(mtx));
thread t2(func, ref(mtx));
t1.join();
t2.join();
cout << x << endl;
return 0;
}
/*
运行结果:
$ ./mytest
20000
*/
但是这里的互斥锁有一个问题,由于临界资源很短,且对临界资源的操作是非常小的操作,使用互斥锁反而有种"杀鸡焉用牛刀"的感觉;
这里还有一种加锁方式是不直接lock进行锁定而是反复循环try_lock尝试加锁,当互斥锁未被占用时这个线程将会获得这个锁资源,若是被占用则直接返回,不进行等待;
-
mutex::try_lockstd::mutex::try_lock bool try_lock();返回值为一个
bool值,当try_lock成功锁定互斥锁对象时返回true,否则返回false;
这种思路是由于使用lock和unlock需要使另一个进程进入等待队列,而等待和唤醒是需要开销的,如果是使获取锁的线程不进入等待队列而是循环询问,即循环尝试获取锁获取会减少这个等待和唤醒的时间,但实际上使用try_lock的方式会变得更慢,因为循环使用try_lock代表需要大量占用CPU资源;
int x1 = 0; // 用于 try_lock 的变量
int x2 = 0; // 用于 lock 的变量
class Func1 {
public:
void operator()(mutex &mtx) {
for (int i = 0; i < 10000000; ++i) {
while (!mtx.try_lock()); // 使用 try_lock 忙等待
++x1;
mtx.unlock();
}
}
};
class Func2 {
public:
void operator()(mutex &mtx) {
for (int i = 0; i < 10000000; ++i) {
mtx.lock(); // 使用 lock 获取锁
++x2;
mtx.unlock();
}
}
};
int main() {
mutex mtx1, mtx2;
// 创建并启动线程来测试 try_lock
Func1 func1;
auto start_try_lock = chrono::high_resolution_clock::now();
thread t1(func1, ref(mtx1));
thread t2(func1, ref(mtx1));
t1.join();
t2.join();
auto end_try_lock = chrono::high_resolution_clock::now();
chrono::duration<double> diff_try_lock = end_try_lock - start_try_lock;
// 创建并启动线程来测试 lock
Func2 func2;
auto start_lock = chrono::high_resolution_clock::now();
thread t3(func2, ref(mtx2));
thread t4(func2, ref(mtx2));
t3.join();
t4.join();
auto end_lock = chrono::high_resolution_clock::now();
chrono::duration<double> diff_lock = end_lock - start_lock;
// 输出结果
cout << "x1 (try_lock): " << x1 << endl;
cout << "Time taken with try_lock: " << diff_try_lock.count() << " s" << endl;
cout << "x2 (lock): " << x2 << endl;
cout << "Time taken with lock: " << diff_lock.count() << " s" << endl;
return 0;
}
/*
运行结果:
$ ./mytest
x1 (try_lock): 20000000
Time taken with try_lock: 3.49147 s
x2 (lock): 20000000
Time taken with lock: 1.10093 s
*/
这里定义了两个全局变量为x1和x2分别用来测试直接使用lock和循环使用try_lock进行测试,定义了两个仿函数分别作为两组多线程的入口点,一个仿函数直接使用lock,一个仿函数循环使用try_lock,并且调用了high_resolution_clock来计算两次的时间并进行计算,这里为了测试结果更加明显使用了一个较大的数值进行自增(10000000);
测试结果表明直接使用lock反而要远远快于循环使用try_lock;
当然这种场景下使用自旋锁的效率要远远高于直接使用lock,循环使用try_lock虽然也是一种自旋动作,但循环调用try_lock将会大大占用CPU资源,因为try_lock的上层开销要更大,这意味着CPU需要处理的指令要更多,但C++标准并未提供自旋锁;
原子操作类 atomic
![]()
atomic是C++封装的一个类,这个类专门用来处理较短临界区的操作,如自增自减,赋值等操作;
这个类中提供了原生的相关操作CAS,即比较并交换(compare and swap),而这些操作本质上是封装了来自不同平台下的操作,层与层之间之间解耦合使得使用atomic能使用相同的原子操作;
template <class T> struct atomic;
这个类提供了一系列的成员函数,包括重载了自增,自减,赋值等操作;

使用这个类模板对较短的临界区临界资源进行封装时使得在对这个临界资源进行操作时进行的都是原子操作;
class Func1
{
public:
void operator()(atomic<int> &x)
{
for (int i = 0; i < 10000; ++i)
{
++x; // 自增
}
}
};
int main()
{
Func1 func;
atomic<int> x; // 使用 atomic 封装临界资源 x
x = 0;
thread t1(func, ref(x)); // 引用传递 x
thread t2(func, ref(x));
t1.join(); // 线程等待
t2.join();
cout << x << endl; // 打印 x 最终值
return 0;
}
/*
运行结果:
$ ./mytest
20000
*/
运行结果表明由于两个线程进行的都是原子操作,最终结果与预期相同;
atomic不仅支持内置类型也支持自定义类型,但前提是所给予的自定义类型需要根据需求重载一些运算符,如自增自减赋值等,但使用自定义类型的时候需要考虑该自定义类型内容是否复杂,如果复杂的话说明临界区较大,在临界区较大的情况下使用互斥锁反而更适合场景;
atomic 原子操作原理 CAS
![]()
atomoic类的原理是CAS操作,这种操作是一种无所操作,即无锁编程;
CAS全称为compare and swap,这个操作涉及到两个步骤:
-
compare比较 -
swap交换
这个操作是由CPU支持的,即硬件支持的操作从而实现操作的原子性;
CPU会提供一系列的指令以及对应接口使得上层能够使用这些接口进行一些原子操作;
- x86 架构使用
CMPXCHG指令 - ARM 架构使用
LDREX和STREX指令
int compare_and_swap (int *reg, int oldval, int newval){
int old_reg_val = *reg;
if(old_reg_val == oldval){
*reg = newval;
}
return old_reg_val;
}
这个代码并不是atomic的实现,而是CAS操作的类似原理的代码,用来模拟CAS操作;
以对一个全局的临界资源int x自增为例,默认情况下对这个临界资源自增时使用的是三条指令:
mov eax, DWORD PTR [rip+x] ; 从全局变量 `x` 加载值到寄存器 `eax`
inc eax ; 增加寄存器 `eax` 的值
mov DWORD PTR [rip+x], eax ; 将增加后的值存回全局变量 `x`
将全局变量x从内存中加载到寄存器eax中,增加eax的值,最后将eax的值写回内存中;
而对于CAS操作而言,CAS操作多了一个最重要的步骤,即判断当前内存中的值是否与加载进寄存器中的最初值相同,如果当前内存中的值与加载进寄存器中的最初值相同则表示内存中的这个值并没有被修改,可以把在寄存器中计算(自增)的值重新写回内存中,表示一次CAS操作成功;
但如果在最后的比较中,当前内存中的值与最初加载进寄存器中的值不同则表示这个值已经被其他线程修改过了,如果再把当前寄存器的值写回内存中则是一个无用功,会导致数据不一致问题,那么这次的CAS操作则是失败,此时需要重新将内存中的值加载进寄存器中并再次进行上述操作,当比较时当前内存中的值与原来加载进寄存器的值相同时才能把在寄存器中计算后的值写回内存中,才算一次CAS操作成功;

class Func
{
public:
void operator()(atomic<int> &x)
{
for (int i = 0; i < 10000; ++i)
{
int old = 0, newval = 0;
do
{
old = x.load(); // 获取旧值
newval = old + 1; // 计算新值
} while (!atomic_compare_exchange_weak<int>(&x, &old, newval)); // 比较并交换
}
}
};
int main()
{
Func func; // 实例化函数对象
atomic<int> x(0); // 实例化一个 atomic 类对象
thread t1(func, ref(x)); // 创建线程
thread t2(func, ref(x));
t1.join();
t2.join();
cout << x << endl; // 打印最终结果
return 0;
}
这段代码为即为CAS操作的具体实现,通过每次循环读取x的值(old)并计算新值newval,尝试通过CAS操作将新值newval写回x;
如果在这个过程中x已经被修改,则CAS操作失败,并重新尝试,直到成功为止;
CAS 操作解决多线程创建链表的节点丢失问题
![]()

这是一个单链表结构,当需要为这个链表插入节点时需要先创建一个节点,而后将这个节点的地址赋值给链表中尾节点的next指针;
但若是出现多个线程同时对同一个链表进行节点插入则可能会出现节点丢失从而导致内存泄漏;

在这张图中线程t1创建了一个Node4节点,线程t2创建了一个Node5节点,节点创建时两个线程之间互不干扰,当节点创建完毕后不论先后一定会存在一个线程创建的节点先链接在链表尾节点的next处成为新的尾节点,但后来的线程所创建的节点再次对同一个节点的next进行链接时就会导致上一个节点丢失,在这个例子中t1创建的节点Node4率先被链接在链表尾节点的位置成为新的尾节点,而t2创建的Node5节点对同一个位置进行链接,导致Node4节点丢失,从而导致内存泄漏问题;
但如果使用了CAS操作则可以避免这种情况的发生,假设两个线程都各创建了一个节点并准备进行插入,t1所创建的节点在进行链接时判断当前插入的链表尾节点的next是否为nullptr空,若是为空则表示该位置可以进行插入,当前检查为空,进行插入,CAS操作成功;
当t2准备对该节点进行链接时首先会检查要插入的位置的next是否为空从而决定这个位置是否可以插入,检查不为空说明无法进行插入,当前CAS操作失败,但CAS操作必须要成功不能一直失败,所以将会取到当前节点的next节点作为插入位置,同样检查该节点的next是否为空,此处不为空则表示可以插入并进行插入,t2线程插入链表节点的CAS操作成功;

由于CAS操作是原子的,即一个线程在对链表进行新节点的插入时不会因为另一个线程的调度而导致节点丢失等问题;
多线程下的 shared_ptr 智能指针
![]()
标准库中的std::shared_ptr是具有一定的线程安全的,但他的线程安全的保证和限制为:
-
安全的引用计数
当多个线程同时持有指向同意对象的
std::shared_ptr时,对象的引用计数增减操作是原子的,因此创建,复制或销毁shared_ptr实例不会导致数据竞争; -
独立的
shared_ptr是线程安全的每个线程可以独立创建,复制和销毁自己的
shared_ptr实例,这些操作之间不会相互干扰;
但shared_ptr智能指针对共享对象本身的访问不是线程安全的,换句话来说shared_ptr只需要保证自身是线程安全的,对于用户所使用的共享对象是不具责任的;
同时当多个线程同时读写同一个shared_ptr实例,如通过赋值操作则可能会导致数据竞争,因此需要使用同步语句来保护这些操作;
int main()
{
shared_ptr<int> nptr(new int(0));
int n = 100000;
thread t1([=]
{
for(int i = 0;i<n;++i){
++(*nptr);
} });
thread t2([=]
{
for(int i = 0;i<n;++i){
++(*nptr);
} });
t1.join();
t2.join();
cout << *nptr << endl;
return 0;
}
/*
运行结果:
$ ./mytest
138056
*/
在这段代码中两个线程同时对一个shared_ptr智能指针所管理的对象进行自增操作10000次,运行结果为明显与预期不符,因为智能指针只会保证自身的线程安全不会保证智能指针所维护生命周期的变量的线程安全,所以需要加锁;
最简单的单例模式
![]()
class SingleLazy
{
public:
static SingleLazy &GetInstance()
{
static SingleLazy inst;
return inst;
}
private:
// 私有化构造
SingleLazy() {
std::cout << "SingleLazy()" << std::endl;
};
// 防拷贝
SingleLazy(const SingleLazy &) = delete;
SingleLazy &operator=(const SingleLazy &) = delete;
};
这是一个最简单的单例模式,并且这是一个懒汉模式,懒汉模式为只有第一次调用的时候才会实例化单例实例,饿汉模式为在主线程进入main函数前就将单例实例资源准备就绪,这里的单例只有调用GetInstance()函数才能获取单例;
int main()
{
sleep(3);
std::cout << "------------" << std::endl;
SingleLazy::GetInstance();
return 0;
}
/*
运行结果:
$ ./mytest
------------
SingleLazy()
*/
这里的单例模式的创建将会打印他的构造函数;
主函数在调用单例模式前首先调用sleep(3)使进程sleep三秒钟,随后打印------------,如果是饿汉模式,这个打印操作和sleep将会在单例模式的构造函数之后,而这里的运行结果明显为先进行了sleep和打印操作才调用单例,所以这是一个懒汉模式,因为局部的静态对象是在第一次调用时初始化;
在C++11之前这个最简单的懒汉模式单例不是线程安全的,而C++11之后引入了可以保证局部静态初始化是线程安全的,因此这个单例模式是线程安全的(C++11之后),能够保证只初始化一次;
也可以理解为在C++11之后,局部静态对象的初始化是原子操作;