2024年“羊城杯”粤港澳大湾区网络安全大赛 AI部分
Author:Ns100kUp
From:极安云科-服务中心
Data:2024/08/27
Copyright:本内容版权归属极安云科,未经授权不得以任何形式复制、转载、摘编和使用。
培训、环境、资料、考证
公众号:Geek极安云科
网络安全群:624032112
网络系统管理群:223627079
网络建设与运维群:870959784
极安云科专注于技能提升,赋能
2024年广东省高校的技能提升,受赋能的客户院校均获奖!
2024年江苏省赛一二等奖前13名中,我们赋能客户占五支队伍!
2024年湖南省赛赋能三所院校均获奖!
2024年山东省赛赋能两所院校均获奖!
2024年湖北省赛赋能参赛院校九支队伍,共计斩获一等奖2项、三等奖7项!
1.NLP_Model_Attack
根据题目要求:要求进行 NLP 对抗,第一反应是操作 unicode 坏字符以及相似字符,让 GPT 写了如下代码,但仅达到 %38
import pandas as pd
import random
import textattack
from textattack.augmentation import WordNetAugmenter
# Unicode 坏字符(零宽度字符)
unicode_bad_chars = ['\u200B', '\u200C', '\u200D', '\uFEFF'] # 常见的零宽度字符
def add_unicode_bad_chars(text, num_chars=1):
"""在文本中随机位置插入 Unicode 坏字符"""
text_list = list(text)
for _ in range(num_chars):
position = random.randint(0, len(text_list) - 1)
bad_char = random.choice(unicode_bad_chars)
text_list.insert(position, bad_char)
return ''.join(text_list)
# 读取 CSV 文件
csv_file_path = '/Users/leadlife/Downloads/tempdir/AI附件/附件/original_text.csv' # 替换为你的 CSV 文件路径
df = pd.read_csv(csv_file_path)
# 使用 TextAttack 的扰动方法创建攻击
attack = WordNetAugmenter()
# 定义列表来存储攻击文本
attacked_texts = []
# 对每一行应用攻击
for index, row in df.iterrows():
text = row['text'] # 替换为 CSV 文件中包含文本的列名
augmented_texts = attack.augment(text)
# 添加 Unicode 坏字符并保存所有变体
all_attacked_texts = [add_unicode_bad_chars(t, num_chars=2) for t in augmented_texts] # 可以调整 num_chars 以增加坏字符的数量
attacked_texts.append('\n'.join(all_attacked_texts))
# 创建一个新的 DataFrame 存储攻击文本
attacked_df = pd.DataFrame({
'original_text': df['text'], # 保留原始文本
'attacked_text': attacked_texts # 攻击文本
})
# 输出到新的 CSV 文件
output_csv_file_path = 'attacked_texts_with_unicode.csv' # 替换为输出的 CSV 文件路径
attacked_df.to_csv(output_csv_file_path, index=False)
print(f"攻击文本已保存到 {output_csv_file_path}")
参考 nlp 攻击文章:
1.https://www.cnblogs.com/zzk0/p/16993693.html
2.https://medium.com/besedo-engineering/nlp-attacks-part-1-why-you-shouldnt-trust-your-text-classification-models-37947853b1a5
3.https://rexarski.com/posts/2023/01/adversarial-attacks-with-textattack/
其中使用 textattack 这个操作,但环境一直报错,根据对抗思路,可替换相似干扰字符,以及添加干扰词汇从而达到目的,进而使用 GPT 辅助编写出如下代码:
import pandas as pd
import random
# Load the original data
df = pd.read_csv('/Users/leadlife/Downloads/tempdir/AI附件/附件/original_text.csv')
# Define the perturbation function
def perturb_text(text):
# Define a similar character mapping
char_map = {
'a': ['@', '4'],
'e': ['3', 'ë'],
'i': ['1', 'î'],
'o': ['0', 'ο'],
's': ['$'],
'l': ['1', '|'],
't': ['7'],
'g': ['9'],
'b': ['8'],
'c': ['(', '<'],
'u': ['µ'],
'd': ['|)'],
'p': ['ρ']
}
# Define perturbation methods
perturbations = [
lambda x: x.replace(' ', ''), # Remove all spaces
lambda x: x + random.choice(['!', '.', '!!', '...']), # Add random punctuation
lambda x: x[::-1], # Reverse the text
lambda x: x.upper(), # Convert to uppercase
lambda x: x.lower(), # Convert to lowercase
lambda x: ''.join(random.choice([c.upper(), c.lower()]) for c in x), # Random capitalization
lambda x: ''.join(random.choice(char_map.get(c.lower(), [c])) for c in x), # Replace with similar chars
lambda x: x.replace(' ', '·'), # Replace spaces with middle dot
lambda x: x.replace(' ', '_'), # Replace spaces with underscore
lambda x: x.title(), # Capitalize each word
lambda x: ''.join(random.choice([c, random.choice(char_map.get(c.lower(), [c]))]) for c in x), # Randomly replace some chars
lambda x: ' '.join(random.sample(x.split(), len(x.split()))) # Shuffle words in the sentence
]
# Generate a unique set of perturbations
applied_perturbations = set()
while len(applied_perturbations) < 20:
perturbation = random.choice(perturbations)
perturbed_text = perturbation(text)
if perturbed_text != text: # Avoid adding unchanged text
applied_perturbations.add(perturbed_text)
return list(applied_perturbations)
# Generate adversarial text examples
attacked_texts = []
for _, row in df.iterrows():
original_text = row['text']
perturbed_texts = perturb_text(original_text)
for perturbed_text in perturbed_texts:
attacked_texts.append({
'id': row['id'],
'text': original_text,
'original_class': row.get('original_class'),
'original_label': row.get('original_label'),
'attacked_text': perturbed_text
})
# Save the perturbed texts to a CSV file
attacked_df = pd.DataFrame(attacked_texts)
attacked_df.to_csv('attacked_texts_use.csv', index=False)
print("Perturbation completed and saved to 'attacked_texts.csv'.")
得到数据集:
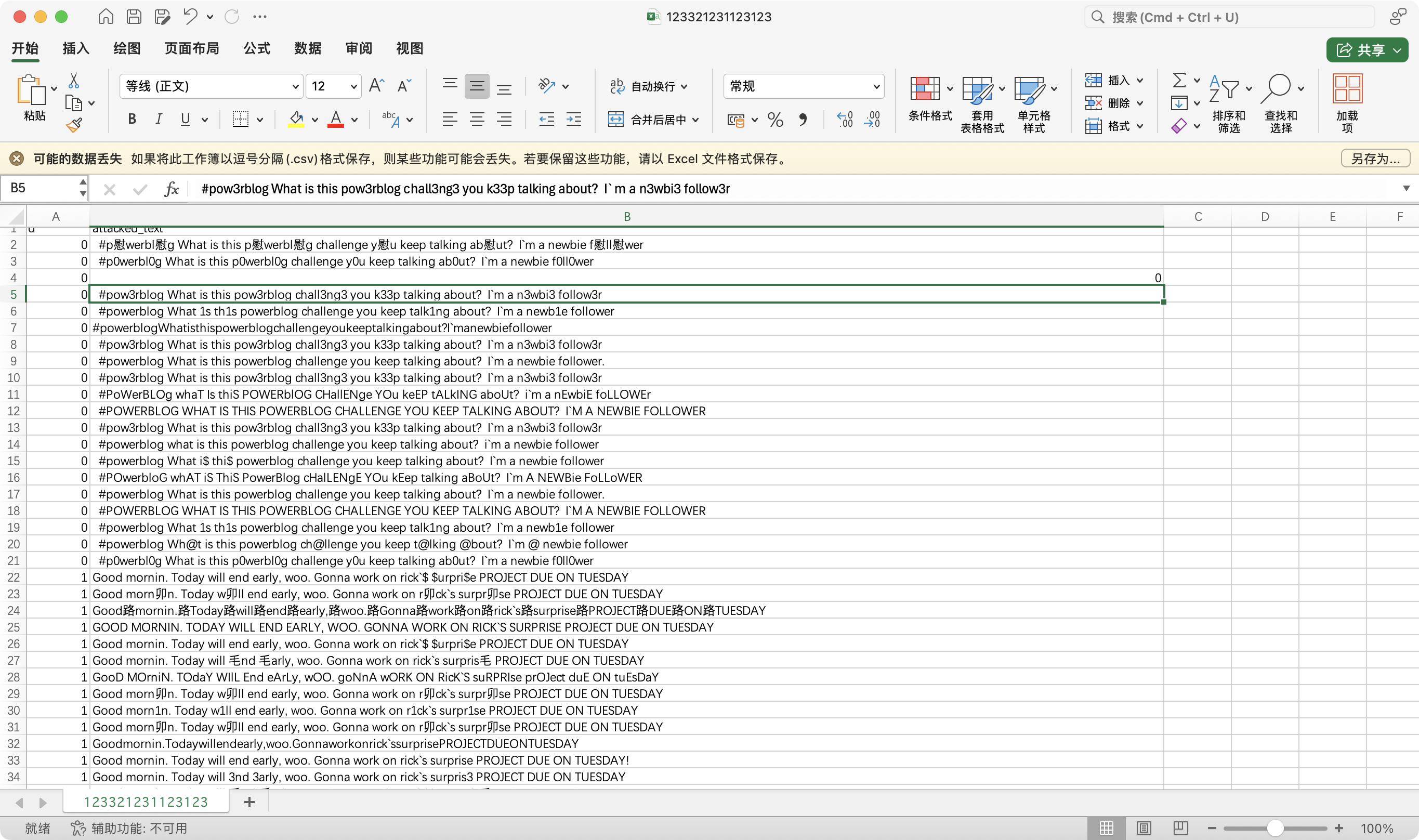
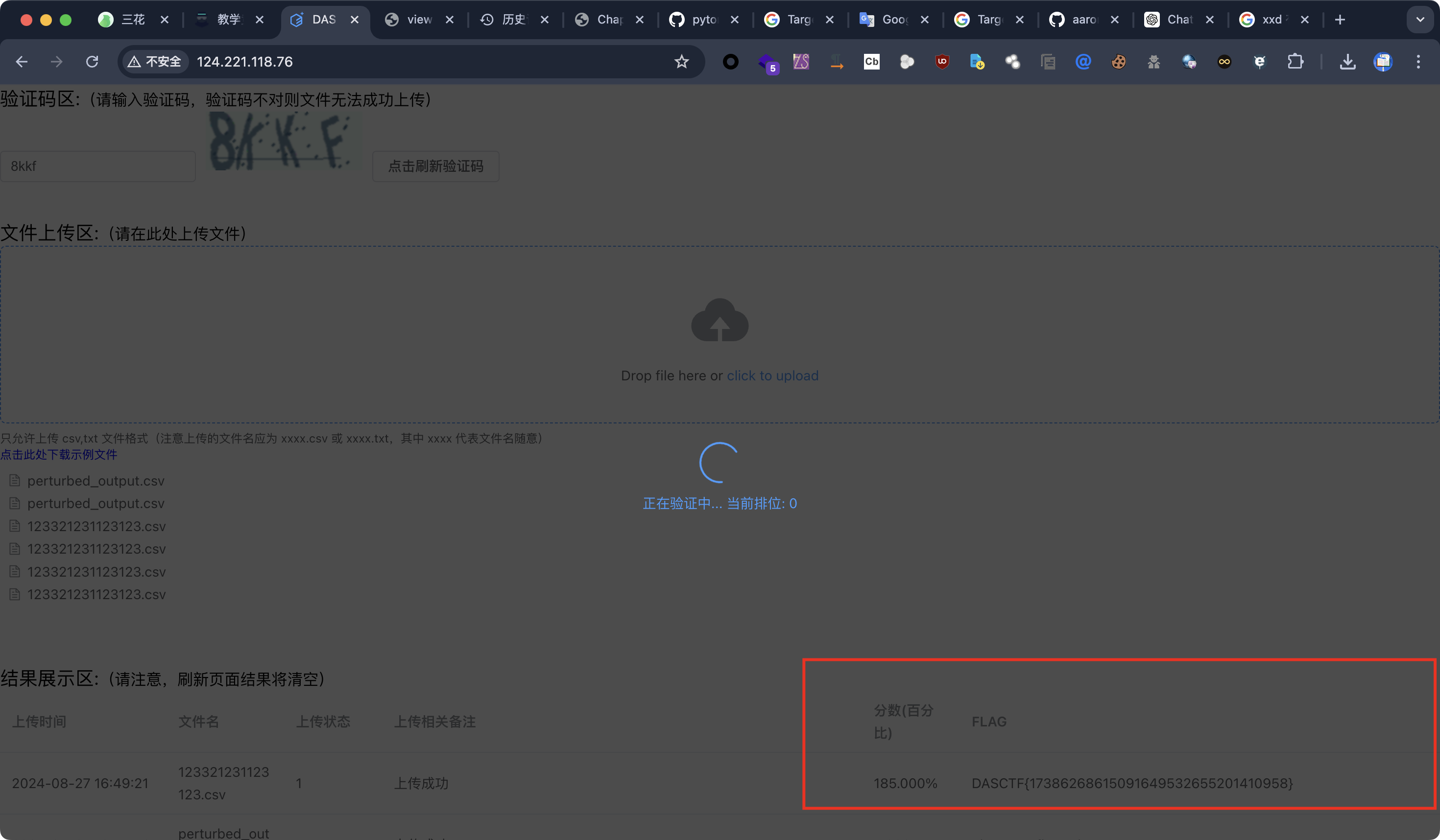
提交,成功获得 flag
![[QCTF2018]X-man-A face1](https://i-blog.csdnimg.cn/direct/71ca48d7bdfe4adda43a573906f1425a.png)


















