文章目录
- 前言
- 安装ollama
- 启动ollama
- 运行llama3模型
- 查看ollama列表
- 删除模型
- 通过代码进行调用
- REST API
前言
在拥有了一条4090显卡后,那冗余的性能让你不得不去想着办法整花活,于是就想着部署个llama3,于是发现了ollama这个新大陆,废话不多说,直接上操作,对于系统的安装和4090驱动的安装可以查看简易教程:
linux系统安装:U盘安装Ubuntu24.04,乌邦图,UltralISO
linux驱动显卡:linux系统,ubuntu安装英伟达NVIDIA4090显卡驱动
对于llama3的说明可以查看官方:https://ai.meta.com/blog/meta-llama-3-1
- 有何疑问欢迎加好友咨询

安装ollama
curl -fsSL https://ollama.com/install.sh | sh
- 直接一步到位安装完成

启动ollama
ollama serve
运行llama3模型
- 8B 版本最低仅需 4GB 显存即可运行,这也是我们主要选择的
- 70B 一条4090支撑,跑起来的模型回答问题会很慢
- 405B 商用级别的,不是业余爱好者能应用的
- 模型如果不存在,会自行进行拉取
ollama run llama3.1:8b
- 出现以下画面。即表示模型已运行,并且可以直接进行提问

- 退出:ctrl + d
查看ollama列表
ollama list

删除模型
仅作指令展示,别刚安装完就删除了
ollama rm llama3.1:8b
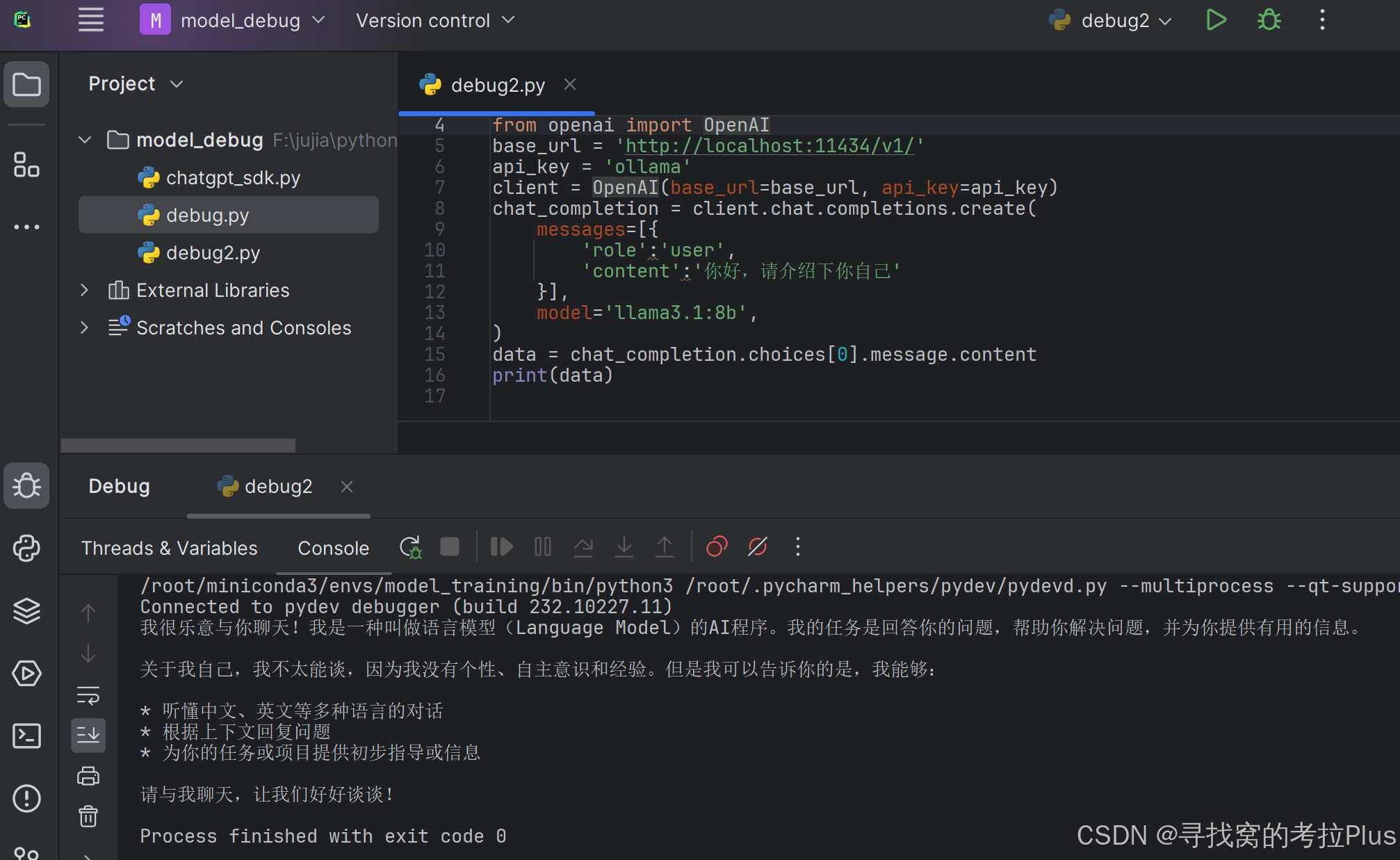
通过代码进行调用
from openai import OpenAI
base_url = 'http://localhost:11434/v1/'
api_key = 'ollama'
client = OpenAI(base_url=base_url, api_key=api_key)
chat_completion = client.chat.completions.create(
messages=[{
'role':'user',
'content':'你好,请介绍下你自己'
}],
model='llama3.1:8b',
)
data = chat_completion.choices[0].message.content
print(data)
- 执行效果不错
REST API
Ollama 提供了用于运行和管理模型的 REST API。
- 生成响应
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1:8b",
"prompt":"Why is the sky blue?"
}'
- 与模型交流
curl http://localhost:11434/api/chat -d '{
"model": "llama3.1:8b",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'