知识图谱生成
llm-graph-builder(以下简称 LGB)也使用了最新的 graph + RAG 的思路,使用知识图谱来加持RAG,提供更加准确和丰富的知识问答。知识图谱的生成上,利用大模型的泛化能力来自动生成和构建知识图谱,包括实体、关系和属性等。其相较于微软开源的 GraphRAG(以下简称 MS-GRAG)有很多相似和同源之处,但也有很多的不同。
| 模块 | 能力 | llm-graph-builder | GraphRAG |
|---|---|---|---|
| 知识抽取 | 使用大模型抽取 | 支持 | 支持 |
| 支持适配多种大模型 | 支持 | 支持 | |
| 本体(schema)配置 | 部分支持(可选系统已配好的schema) 有一套比较完整的配置策略 | 支持 相对简单,只有简单枚举 | |
| prompt调整 | 不支持 | 不支持 | |
| promt形式 | zero-shot(效果一般,实体质量不高) | few-shot(效果更好) | |
| 知识分层 | 无 | 有分层社区,并提供社区级别的摘要 | |
| 知识存储 | 图数据库 | neo4j(查询较快) | 文件存储(效率低) |
| 知识召回 | 召回模式 | vector, graph + vector | graph + vector |
| 问答素材 | 基于召回的文本片段 | 基于召回的实体,或社区摘要 | |
| 问答效率 | 高 | 低 | |
| 交互 | 界面UI | 支持 | 不支持(命令行操作生成和问答) |
| 实体展示 | 支持 | 不支持 | |
| 文档级操作 | 支持文件级的生成、查看和召回 支持增量的生成 | 不支持 有文件更新时,需要重新构建知识图谱 |
知识抽取
LGB的prompt相较于微软MS-GRAG来说,简单许多。
微软的prompt无论是在结构上,还是组织形式上,都更加完善。而最终体现的效果也是相差较多。
知识存储
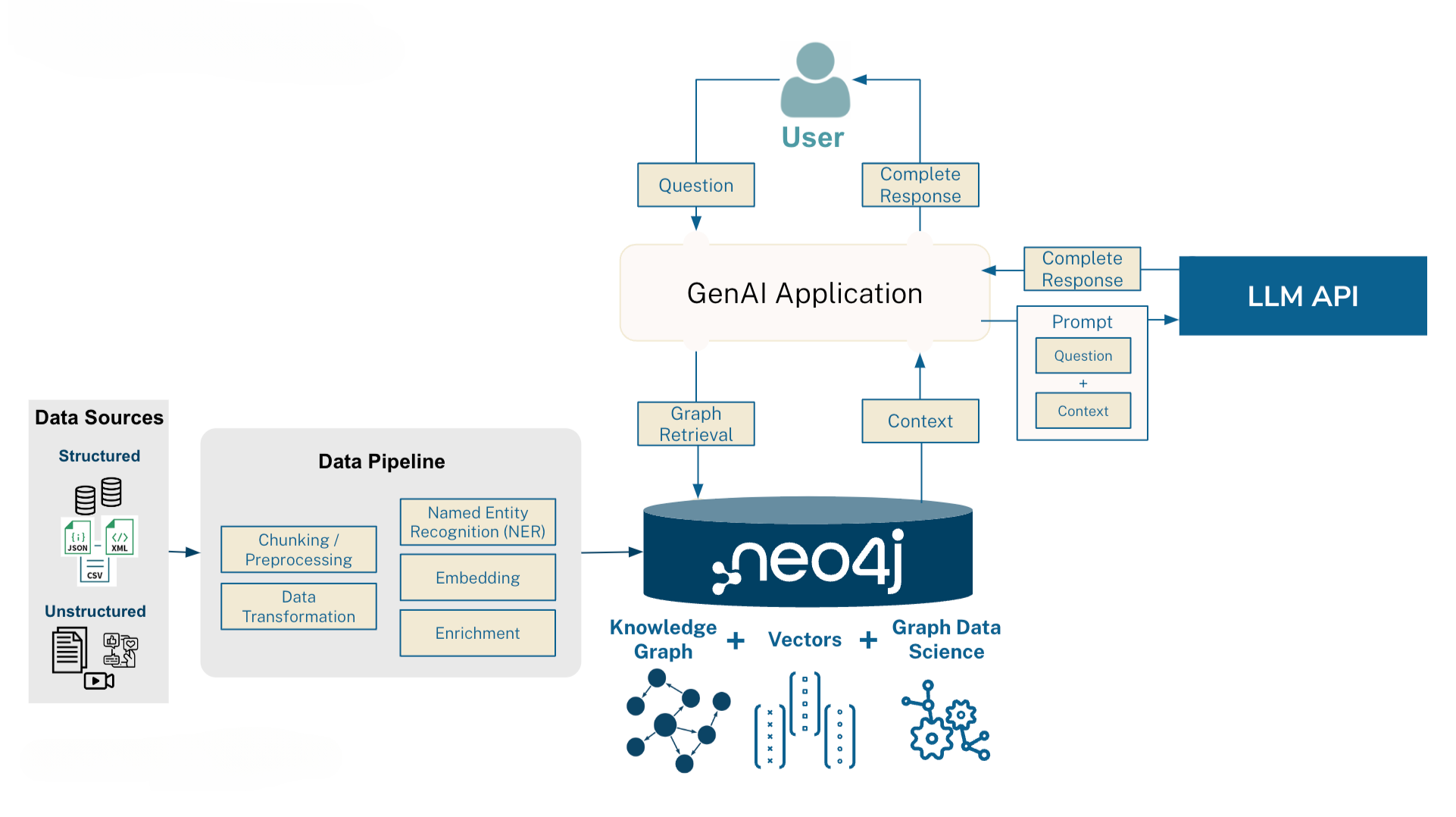
LGB 依托于 Neo4j 图数据库,包括文档管理,实体、关系管理等,都是基于Neo4j图数据来做的。在召回性能上,相较于 MS-GRAG 要快。
知识召回
在召回策略上,两个产品使用了不同的方案。
- LGB
利用图数据库提供的快速检索能力,支持了向量 + 图检索的召回模式,也支持单纯的向量召回(传统的RAG模式)。
无论是向量 + 图检索的模式,还是单纯向量模式,召回的内容都是文档片段(chunk);使用图模式时,会将关联的实体数量,作为rerank的依据。
最终将召回的内容,加上prompt,调用大模型来总结答案。
- MS-GRAG
微软的做法是,将所有提取的实体,作为叶子节点,同时自动对这些实体进行聚类。相关的实体节点聚成一类,称之为社区(community)。而多个社区,还可以继续形成新的社区。每个社区都有自己的摘要和总结。
召回时,根据用户问题的embedding,在以下5个场景中检索素材,并最终将召回的素材和历史对话一起传给大模型,生成答案。