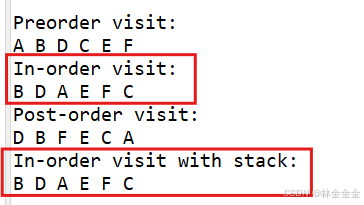
scrapy框架
加代理
付费代理IP池
middlewares.py
# 代理IP池
class ProxyMiddleware(object):
proxypool_url = 'http://127.0.0.1:5555/random'
logger = logging.getLogger('middlewares.proxy')
async def process_request(self, request, spider):
async with aiohttp.ClientSession() as client:
response = await client.get(self.proxypool_url)
if not response.status == 200:
return
proxy = await response.text()
self.logger.debug(f'set proxy {proxy}')
request.meta['proxy'] = f'http://{proxy}'
settings.py
DOWNLOADER_MIDDLEWARES = {
"demo.middlewares.DemoDownloaderMiddleware": 543,
"demo.middlewares.ProxyMiddleware": 544
}
隧道代理
import base64
proxyUser = "1140169503666491392"
proxyPass = "7RmCwS8r"
proxyHost = "http-short.xiaoxiangdaili.com"
proxyPort = "10010"
proxyServer = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
"user": proxyUser,
"pass": proxyPass
}
proxyAuth = "Basic " + base64.urlsafe_b64encode(bytes((proxyUser + ":" + proxyPass), "ascii")).decode("utf8")
# 隧道代理
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta["proxy"] = proxyServer
request.headers["Connection"] = "close"
request.headers["Proxy-Authorization"] = proxyAuth
# 60秒一切 变为 10秒一切
request.headers["Proxy-Switch-Ip"] = True
重试机制
settings.py
# Retry settings
RETRY_ENABLED = False
RETRY_TIMES = 5 # 想重试几次就写几
# 下面这行可要可不要
# RETRY_HTTP_CODES = [500, 502, 503, 504, 408]
重写已有重试中间件
midderwares.py
from scrapy.downloadermiddlewares.retry import RetryMiddleware
retry.py
def _retry(self, request, reason, spider):
max_retry_times = request.meta.get("max_retry_times", self.max_retry_times)
priority_adjust = request.meta.get("priority_adjust", self.priority_adjust)
# 重试更换代理IP
proxypool_url = 'http://127.0.0.1:5555/random'
logger = logging.getLogger('middlewares.proxy')
async def process_request(self, request, spider):
async with aiohttp.ClientSession() as client:
response = await client.get(self.proxypool_url)
if not response.status == 200:
return
proxy = await response.text()
self.logger.debug(f'set proxy {proxy}')
request.meta['proxy'] = f'http://{proxy}'
request.headers['Proxy-Authorization'] = "proxyauth"
return get_retry_request(
request,
reason=reason,
spider=spider,
max_retry_times=max_retry_times,
priority_adjust=priority_adjust,
)
零碎知识点
scrapy两种请求方式
-
GET请求
import scrapy yield scrapy.Request(begin_url,self.first) -
POST请求
from scrapy import FormRequest ##Scrapy中用作登录使用的一个包 formdata = { 'username': 'wangshang', 'password': 'a706486'} yield scrapy.FormRequest( url='http://172.16.10.119:8080/bwie/login.do', formdata=formdata, callback=self.after_login, )应用场景:POST请求并且携带加密token,我们需要伪造POST请求并且解密token
scrapy个性化配置
settings.py
custom_settings_for_centoschina_cn = {
'DOWNLOADER_MIDDLEWARES' : {
'questions.middlewares.QuestionsDownloaderMiddleware': 543,
},
'ITEM_PIPELINES': {
'questions.pipelines.QuestionsPipeline': 300,
},
'MYSQL_URI' : '124.221.206.17',
# 'MYSQL_URI' : '43.143.155.25',
'MYSQL_DB' : 'mydb',
'MYSQL_USER':'root',
'MYSQL_PASSWORD':'123456',
}
爬虫部分
import scrapy
from questions.settings import custom_settings_for_centoschina_cn
from questions.items import QuestionsItem
from lxml import etree
class CentoschinaCnSpider(scrapy.Spider):
name = 'centoschina.cn'
# allowed_domains = ['centoschina.cn']
custom_settings = custom_settings_for_centoschina_cn
3种方式加headers
-
settings.py的默认headers
# Override the default request headers: DEFAULT_REQUEST_HEADERS = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "en", } -
每个请求加headers
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0' } def start_requests(self): start_url = "https://2024.ip138.com/" for n in range(5): # dont_filter=True, 去掉框架自带相同链接去重机制 yield scrapy.Request(start_url, self.get_info, dont_filter=True, headers=A2024Ip138Spider.headers) -
下载器中间件加headers
def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # 加header request.headers[ 'user-agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0' # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None
优先级:3 > 2 > 1
request携带参数, response获取参数
def start_requests(self):
start_url = "https://2024.ip138.com/"
for n in range(5):
# dont_filter=True, 去掉框架自带相同链接去重机制
yield scrapy.Request(start_url, self.get_info, dont_filter=True, headers=A2024Ip138Spider.headers,
meta={'page': 1})
def get_info(self, response):
# print(response.text)
print(response.meta['page'])
ip = response.xpath('/html/body/p[1]/a[1]/text()').extract_first()
print(ip)
链家(scrapy项目)
项目介绍:不封IP
核心代码
import scrapy
class TjLianjiaSpider(scrapy.Spider):
name = "tj_lianjia"
# allowed_domains = ["ffffffffff"]
# start_urls = ["https://ffffffffff"]
def __init__(self):
self.page = 1
def start_requests(self):
start_url = 'https://tj.lianjia.com/ershoufang/pg{}/'.format(self.page)
yield scrapy.Request(start_url, self.get_info)
def get_info(self, response):
lis = response.xpath('//li[@class="clear LOGVIEWDATA LOGCLICKDATA"]')
for li in lis:
title = li.xpath('div[1]/div[@class="title"]/a/text()').extract_first()
totalprice = ''.join(li.xpath('div[1]/div[@class="priceInfo"]/div[1]//text()').extract())
print(title, totalprice)
self.page += 1
next_href = 'https://tj.lianjia.com/ershoufang/pg{}/'.format(self.page)
yield scrapy.Request(next_href, self.get_info)
更多精致内容