wx 搜索 gzh 司南锤,回复 子豪兄231笔记 可获取笔记文件(pdf+doc)
文章目录
- 学习链接:
- - 斯坦福大学公开课
- - 计算机视觉发展历史
- - 图像分类算法
- - 线性分类、损失函数与梯度下降
- - 神经网络与反向传播
- - 卷积神经网络
- - 可视化卷积神经网络
- - 训练神经网络 (一)
- - 激活函数
- - 权重初始化
- - Batch Normalization (批归一化)
- - 总结
- - 训练神经网络 (二)
- - 优化器
- -- SGD
- -- SGD + 动量 【Momentum】
- -- Nesterov Momentum 【NAG】
- -- AdaGrad
- -- RMSProp (Leakly AdaGrad)
- -- Adam( almost)
- -- Adam (full form)
- - 学习率
- -- 二阶优化法(牛顿法)
- - 防止过拟合
- - 模型集成
- - 正则化
- -- Dropout
- - 数据增强 (data augement)
- -- drop connect
- -- Fractional Max Pooling
- -- Stochastic Depth
- -- Cutout
- - 超参数选择
- - 总结
- - 卷积神经网络工程实践技巧
- -- 卷积
- -- imcol
- -- FFT
- - 迁移学习与fine tuning
- - 迁移学习
- - 卷积神经网络结构案例分析
- . LeNet-5
- . AlexNet
- . ZFNet (可视化理解反卷积)
- .VGG
- .GoogleNet
- .ResNet
- .NetWork in NetWork
- - 残差块的质量大于数量的重要性
- - 分形网络
- - 全附庸模型
- - 可部署移动设备
- - 元学习 (AI自己训练网络)
- - 总结
- - 深度学习硬件算力基础 (GPU & TPU)
- -- 加速推断的算法
- -- SqueezenNet
- - 深度学习软件编程框架
- - Pytorch
- - TensorFlow
- - Keras (对小白用户最友好,简单易上手)
- - 建议
- - 循环神经网络
- -- 编码器 & 解码器
- -- RNN梯度消失与梯度爆炸
- - LSTM
- -Transformer
- - 总结
学习链接:
【子豪兄】精讲CS231N斯坦福计算机视觉公开课(2020最新)_哔哩哔哩_bilibili
- 斯坦福大学公开课

- 计算机视觉发展历史
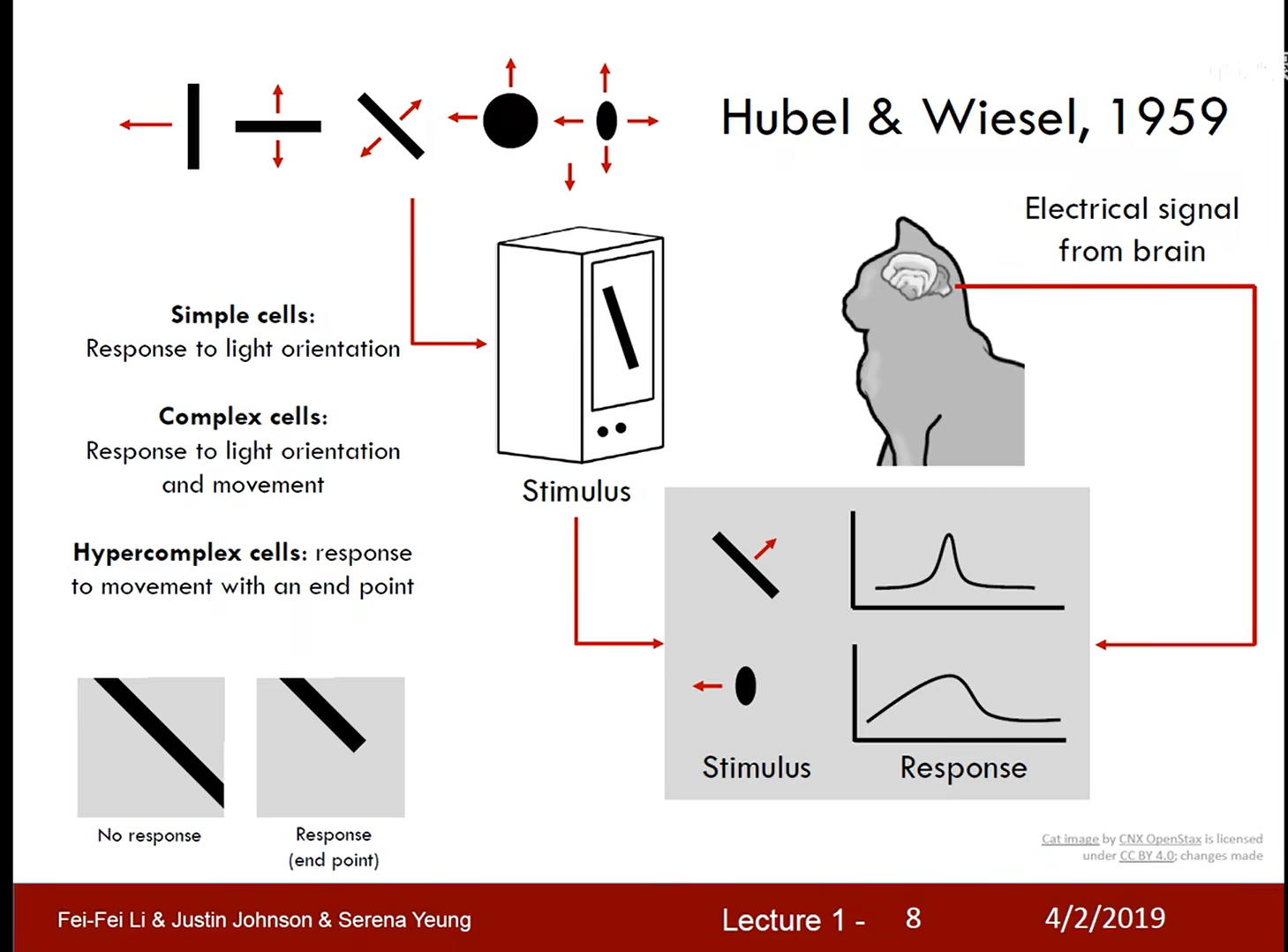
猫对边缘视觉敏感的研究:
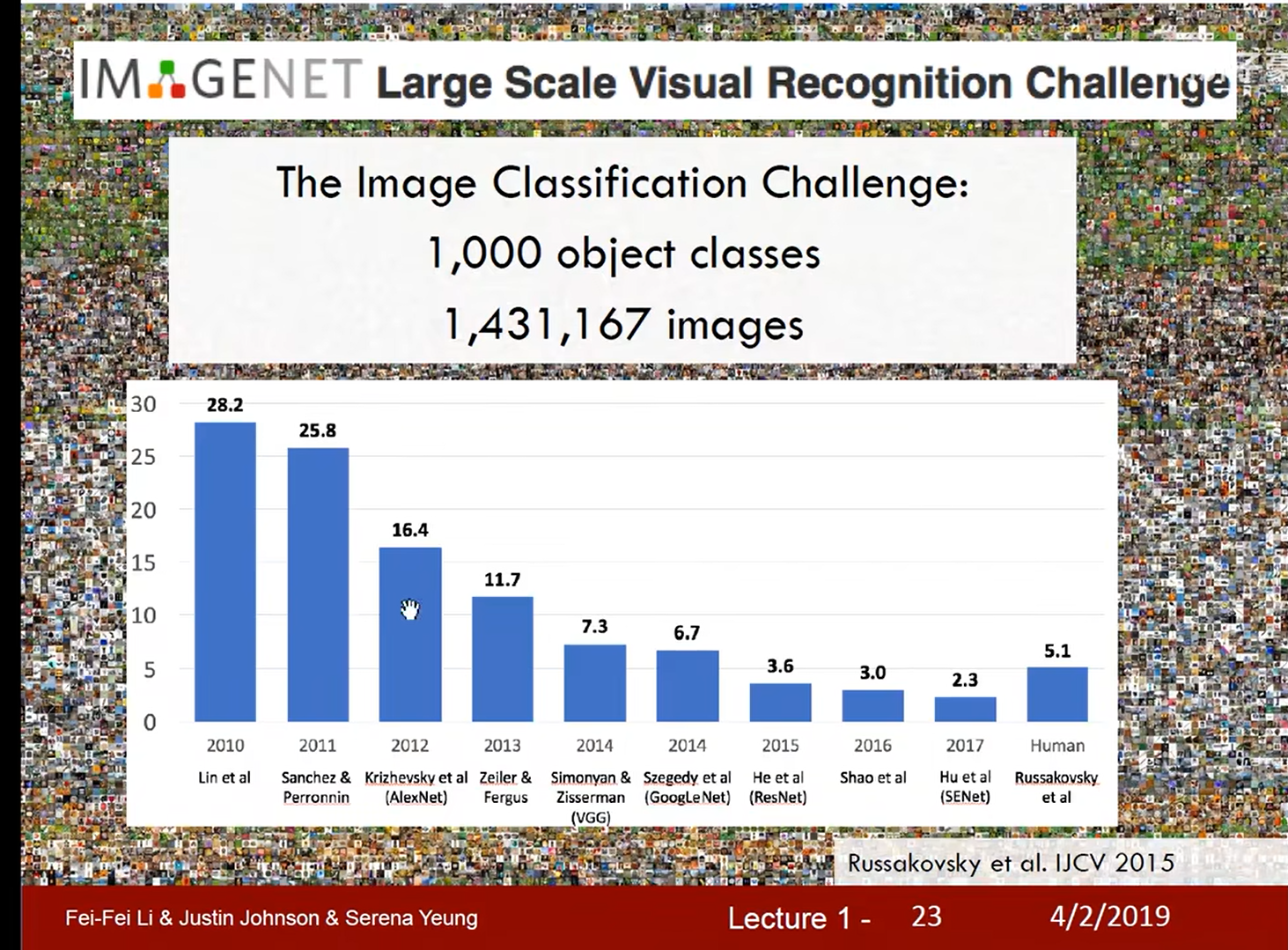
ImageNet:
前置知识:

- 图像分类算法
CIFAR10数据集:

L1距离:
将两个位置对应的地方直接相减 (曼哈顿距离)
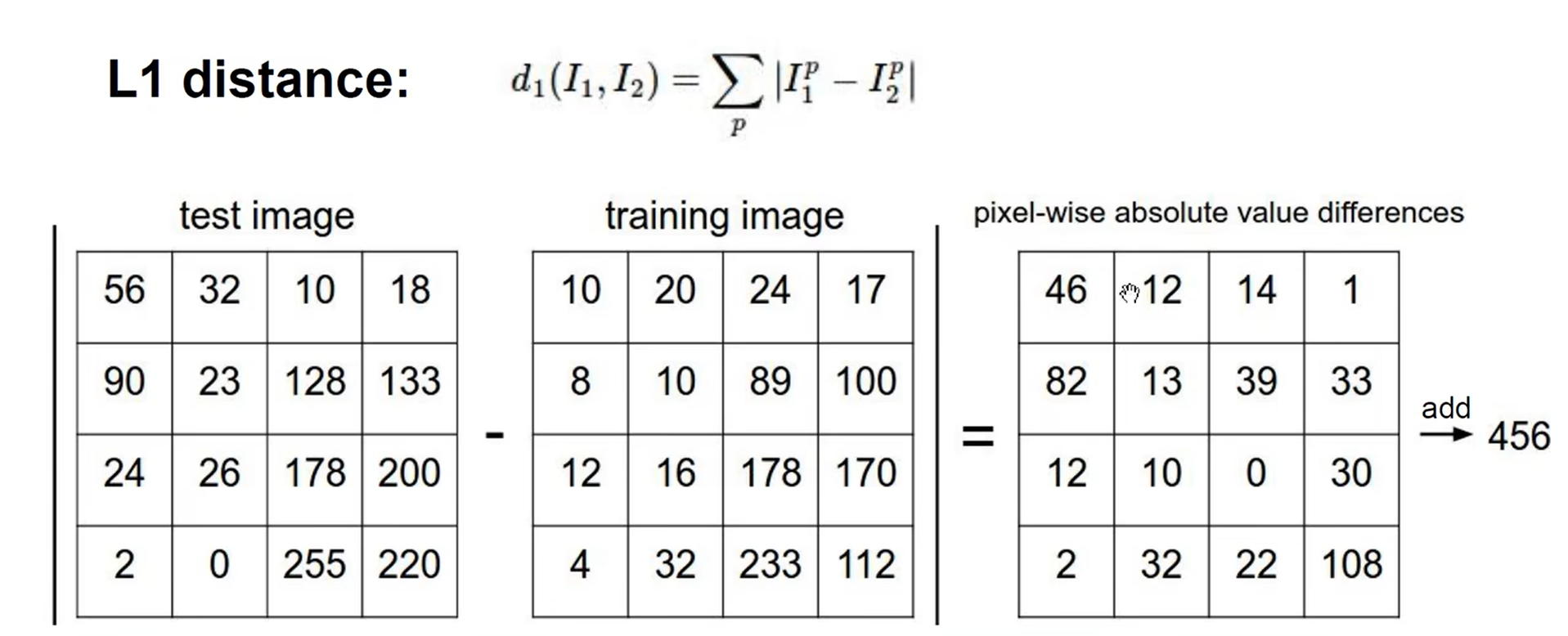
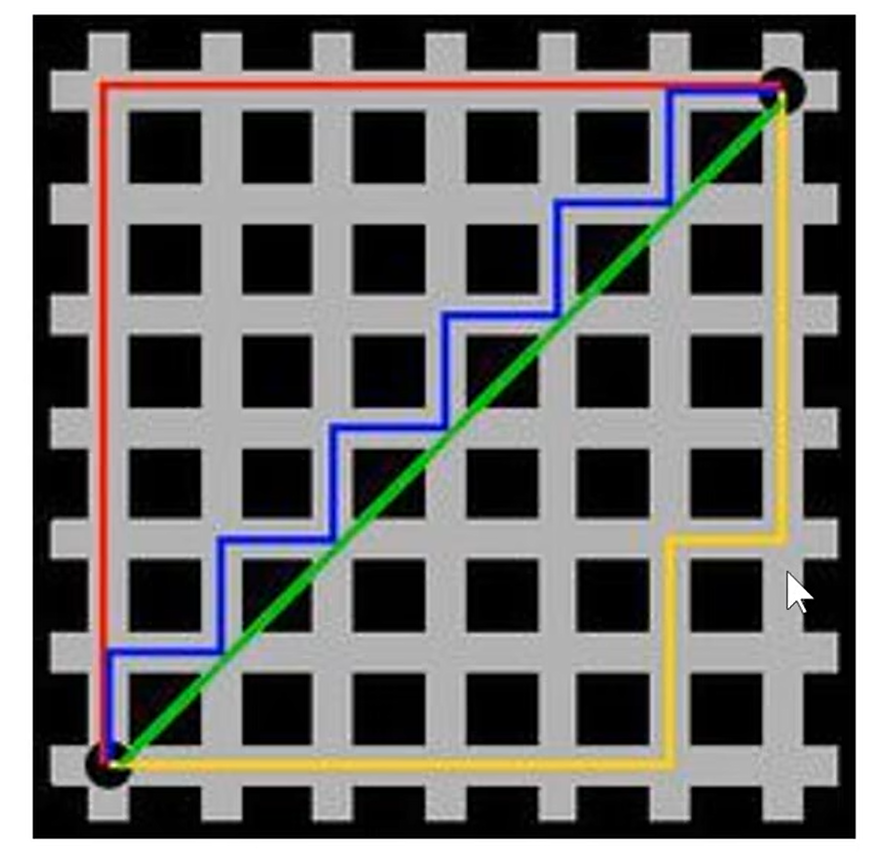
LI距离python代码实现:

LI距离与L2距离对比:
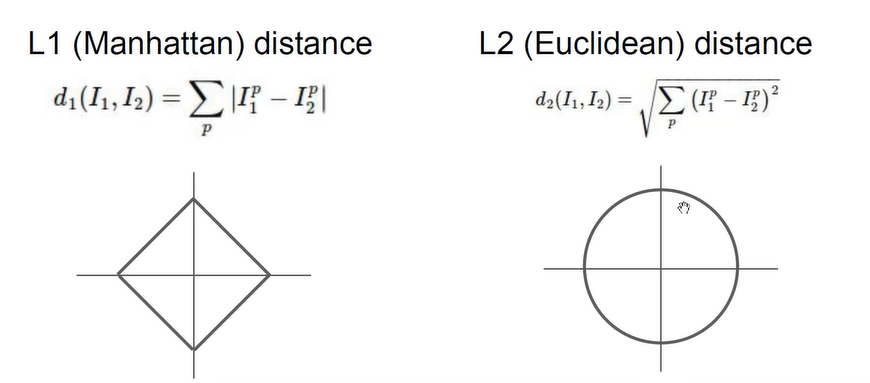
- L1距离对坐标系角度变化比较明显
- L1距离适用于坐标系明确的情况:薪水和出勤
KNN图像分类的缺点:
- 运算比较慢
- 距离作为划分的特征不够明显
- 随着维度增加计算量快速增大
- 线性分类、损失函数与梯度下降
铰链损失函数:

正则化:
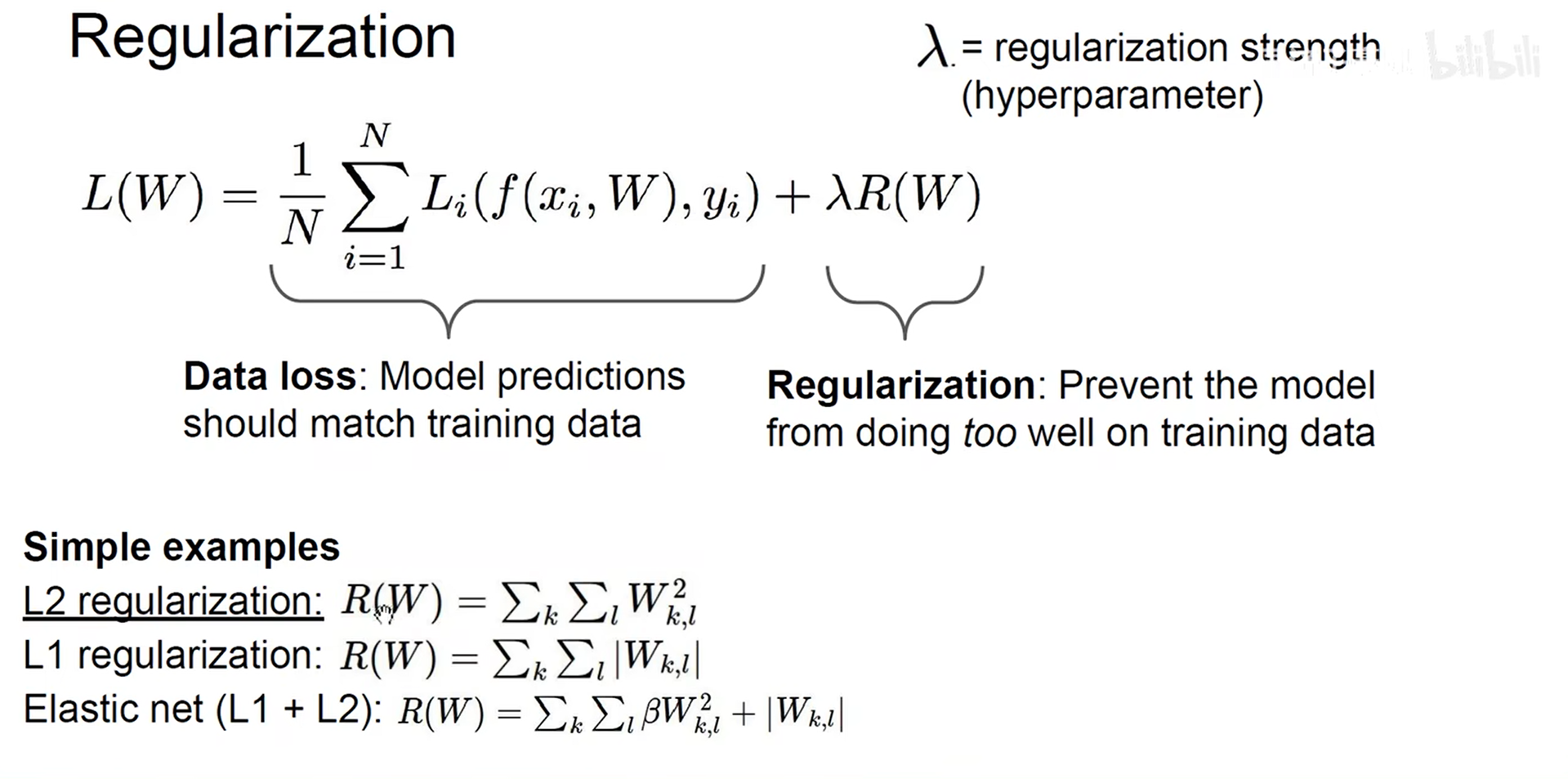


Softmax 分类器:交叉熵损失函数

导数:
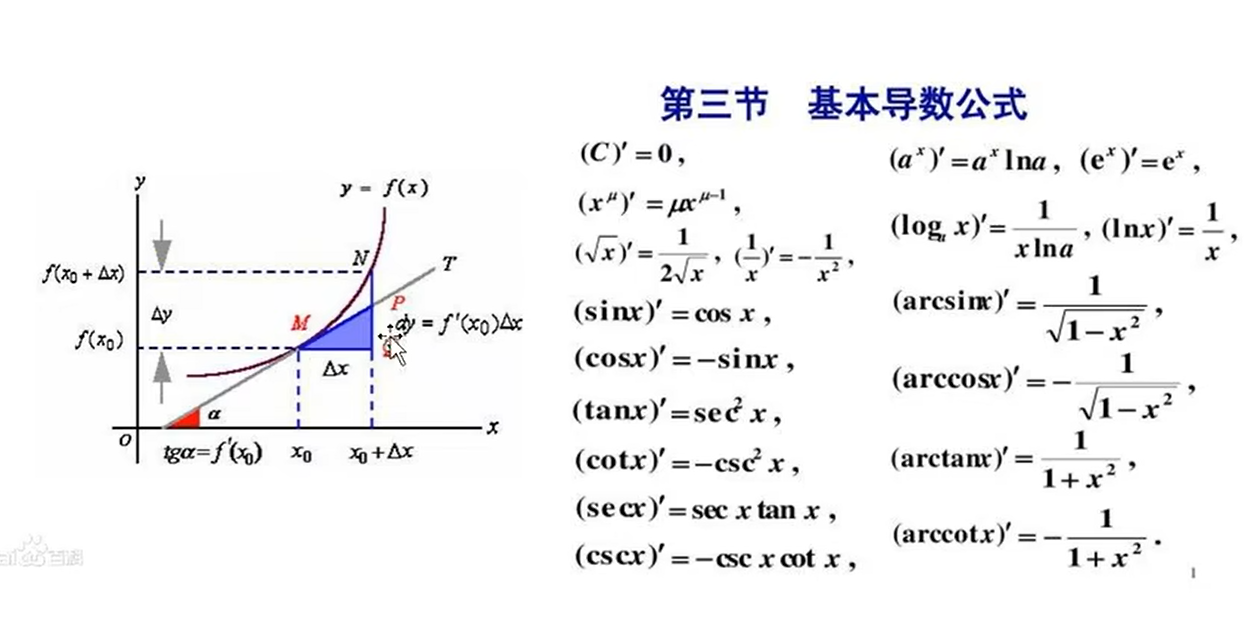
数值解和解析解两种方式:

梯度下降算法:
是损失函数下降,不是梯度本身下降
SGD算法:

- 一般选择2的指数作为批次
- 神经网络与反向传播
类比自然神经元:
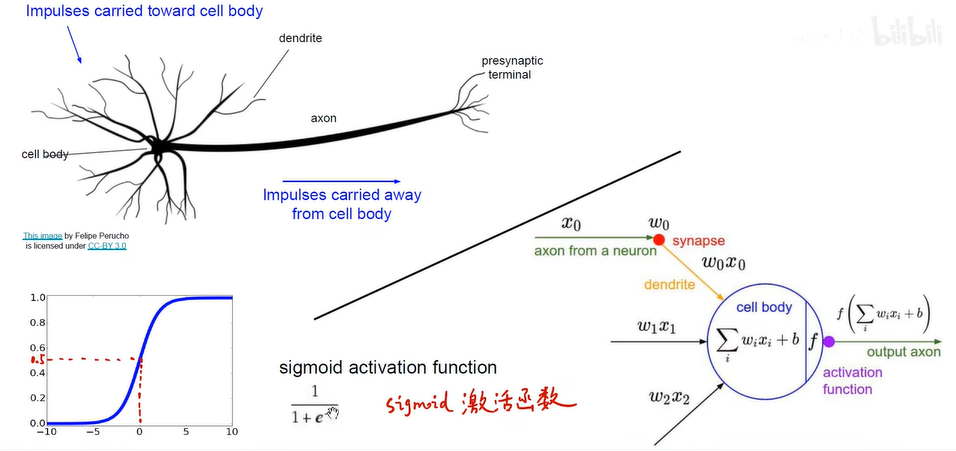
反向传播:
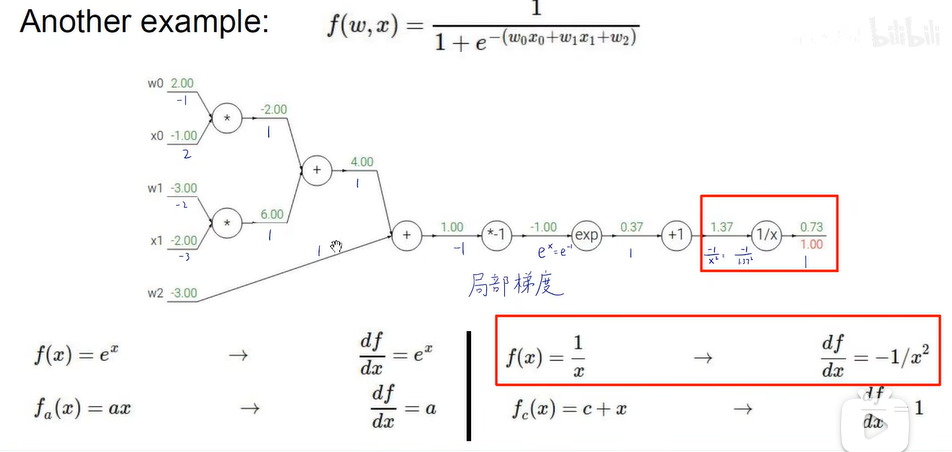
梯度流的形式:
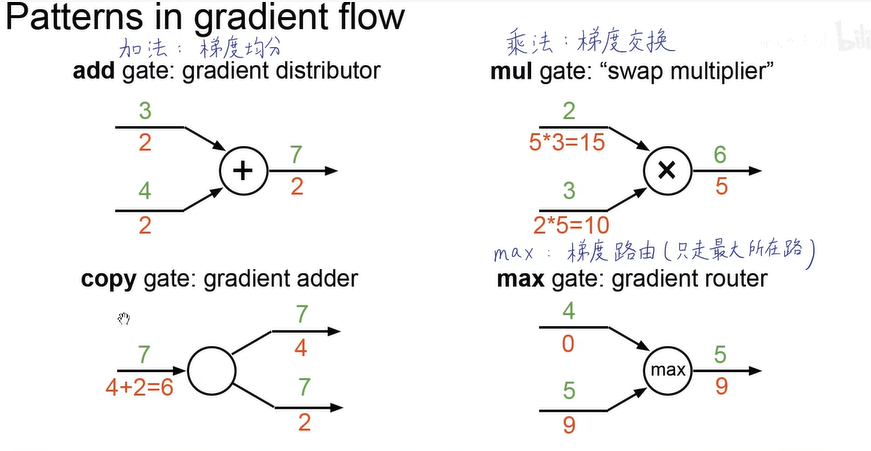
向量的分类:

- 卷积神经网络
卷积核:
- 使用卷积核个数有多少,通道就有多少

- 卷积核的作用是提取特征
池化:
- 使得神经网络具有平移不变性
- 减少参数量
- 防止过拟合
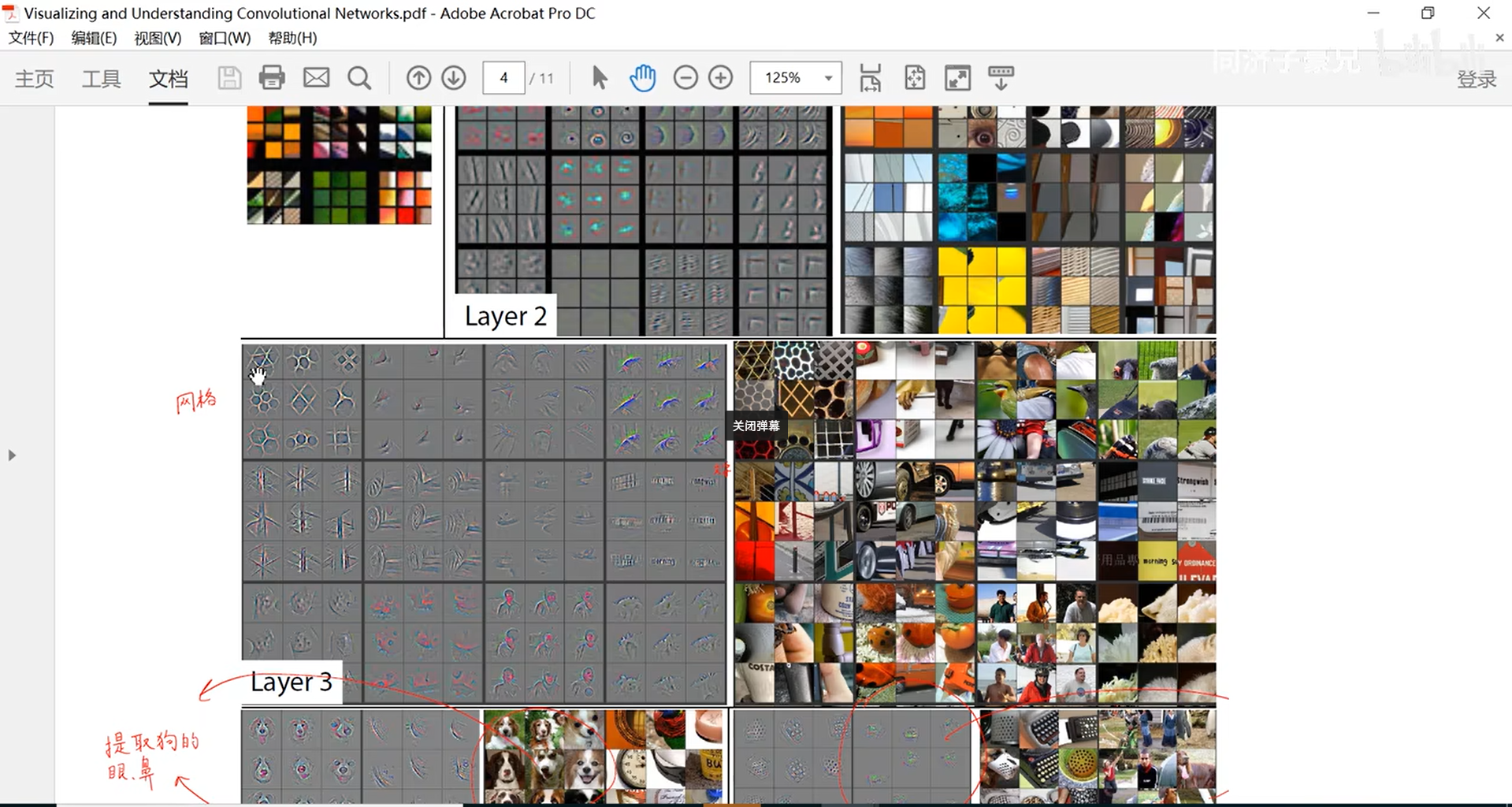
- 可视化卷积神经网络
-
提取图像编码参数,进行降维之后进行可视化
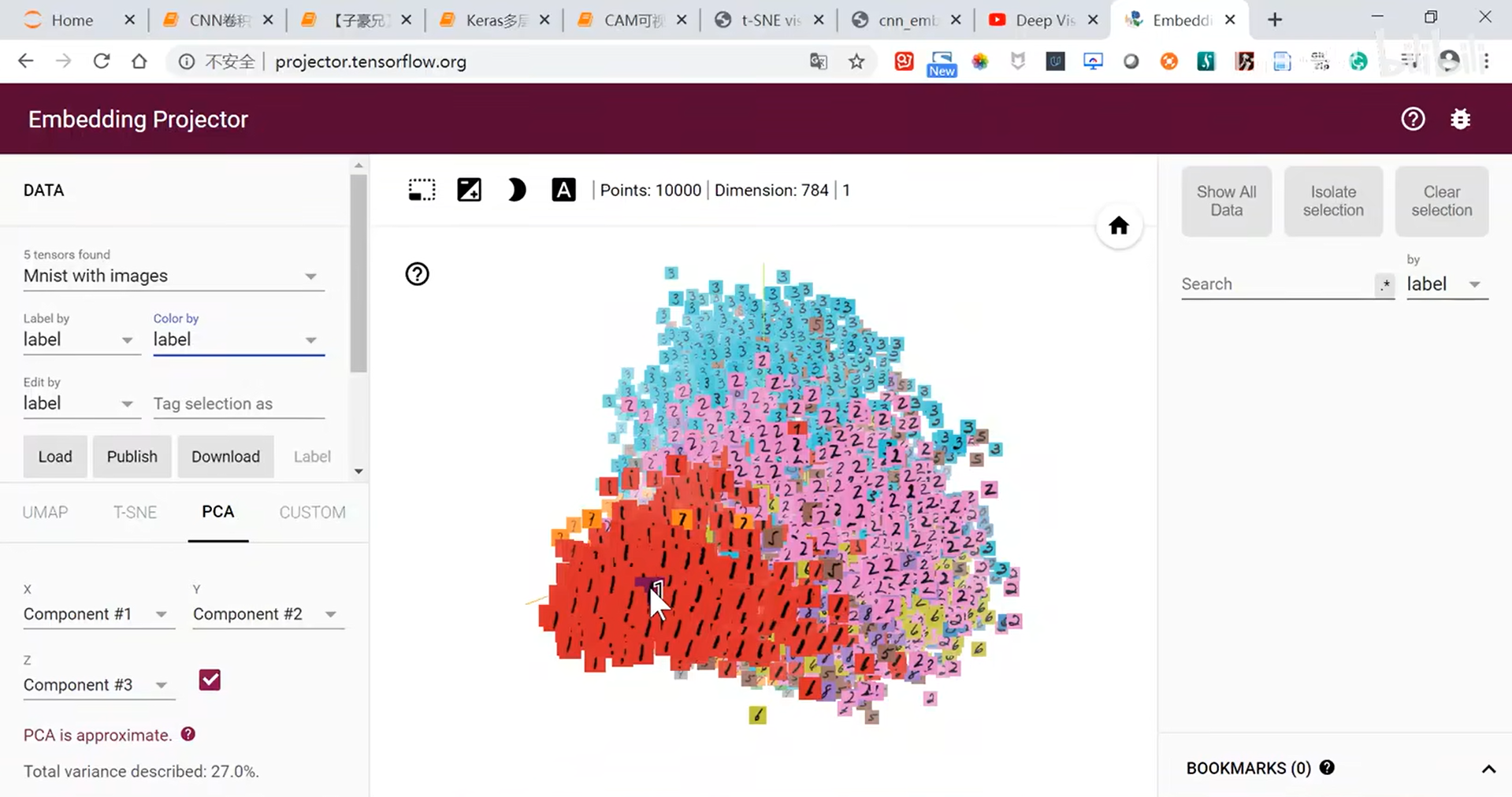
-
遮挡实验
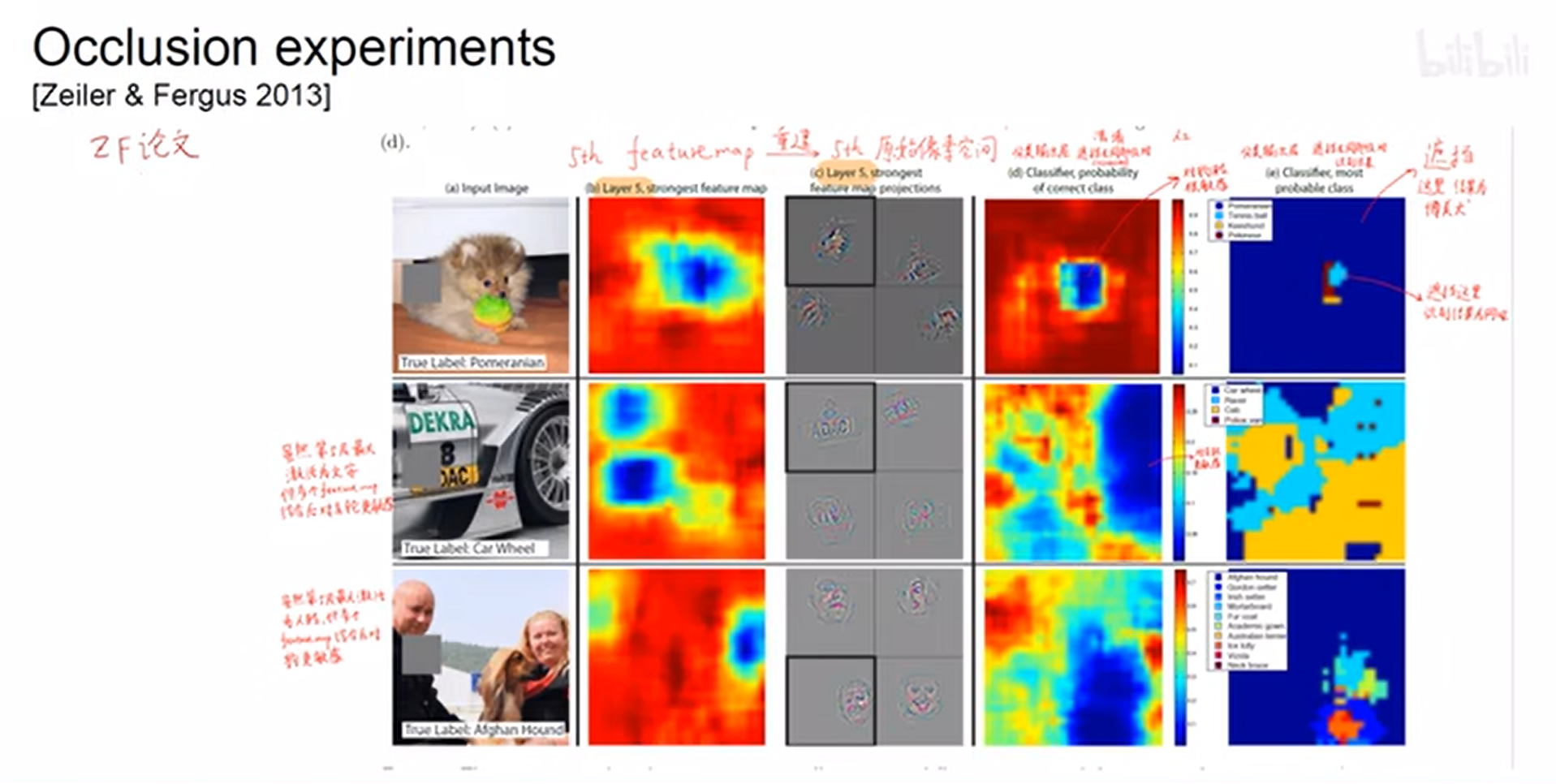
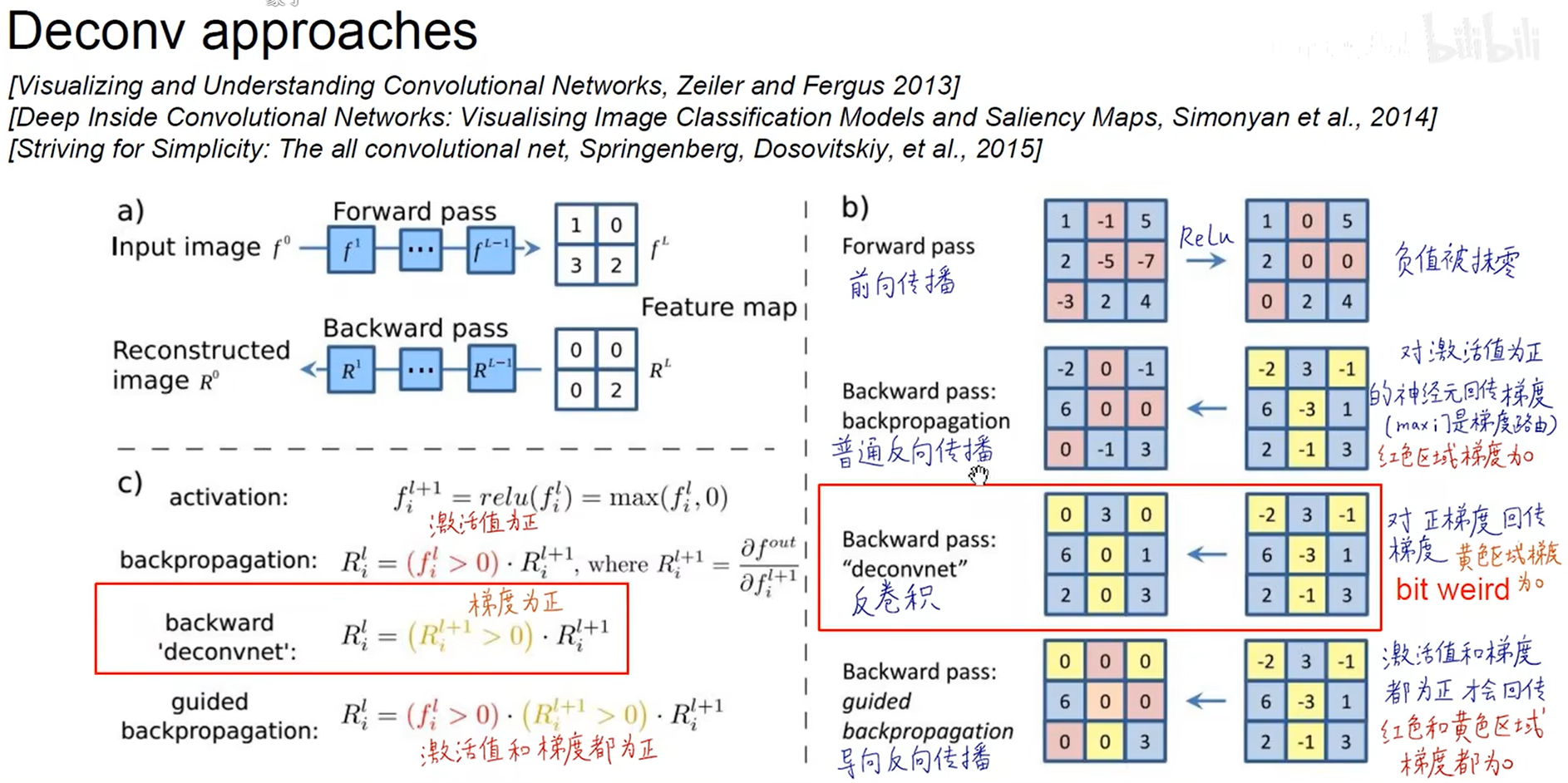
- 反卷积方法
- 训练神经网络 (一)
- 激活函数



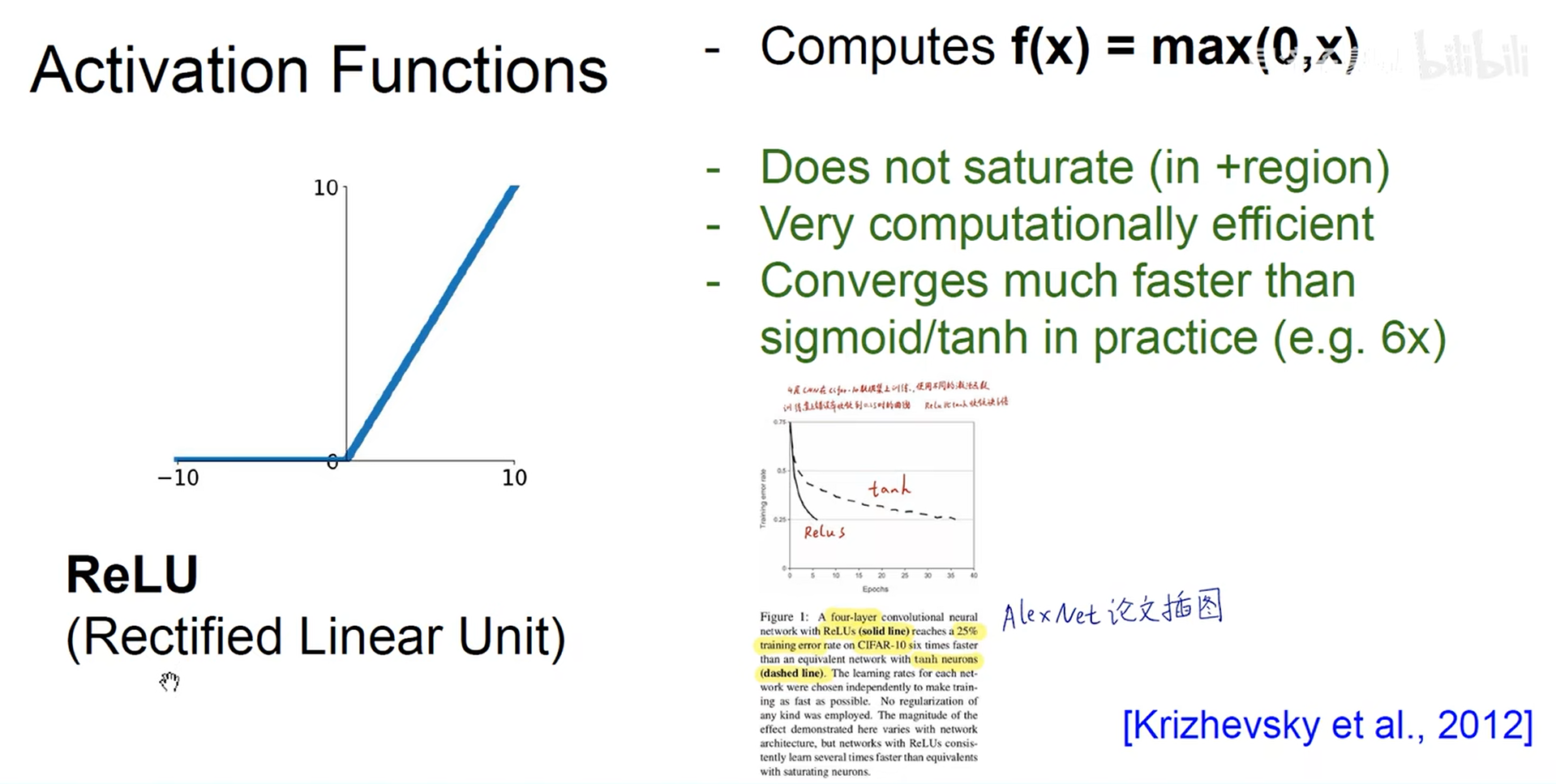
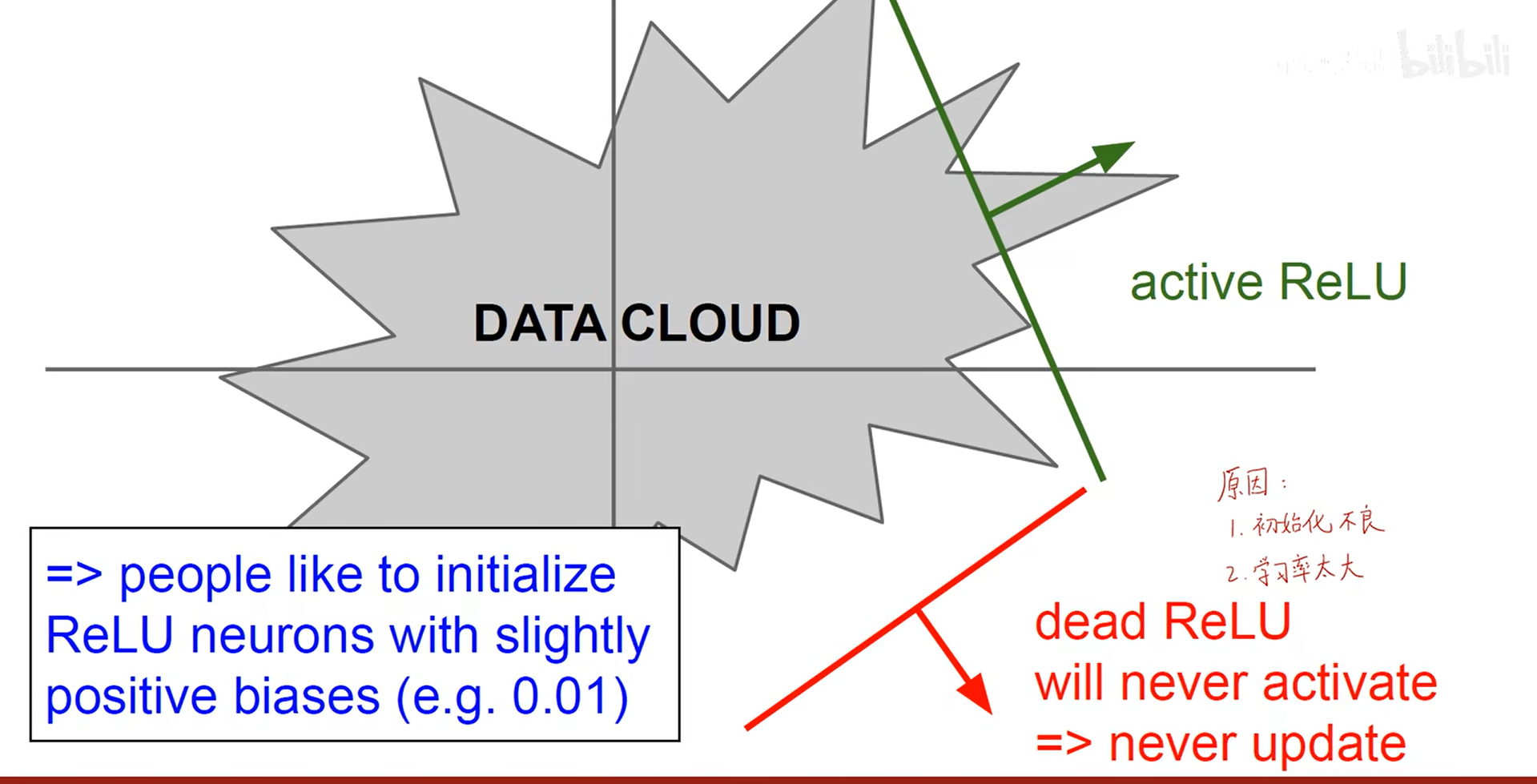



- 二分类可以使用sigmoid
数据预处理:

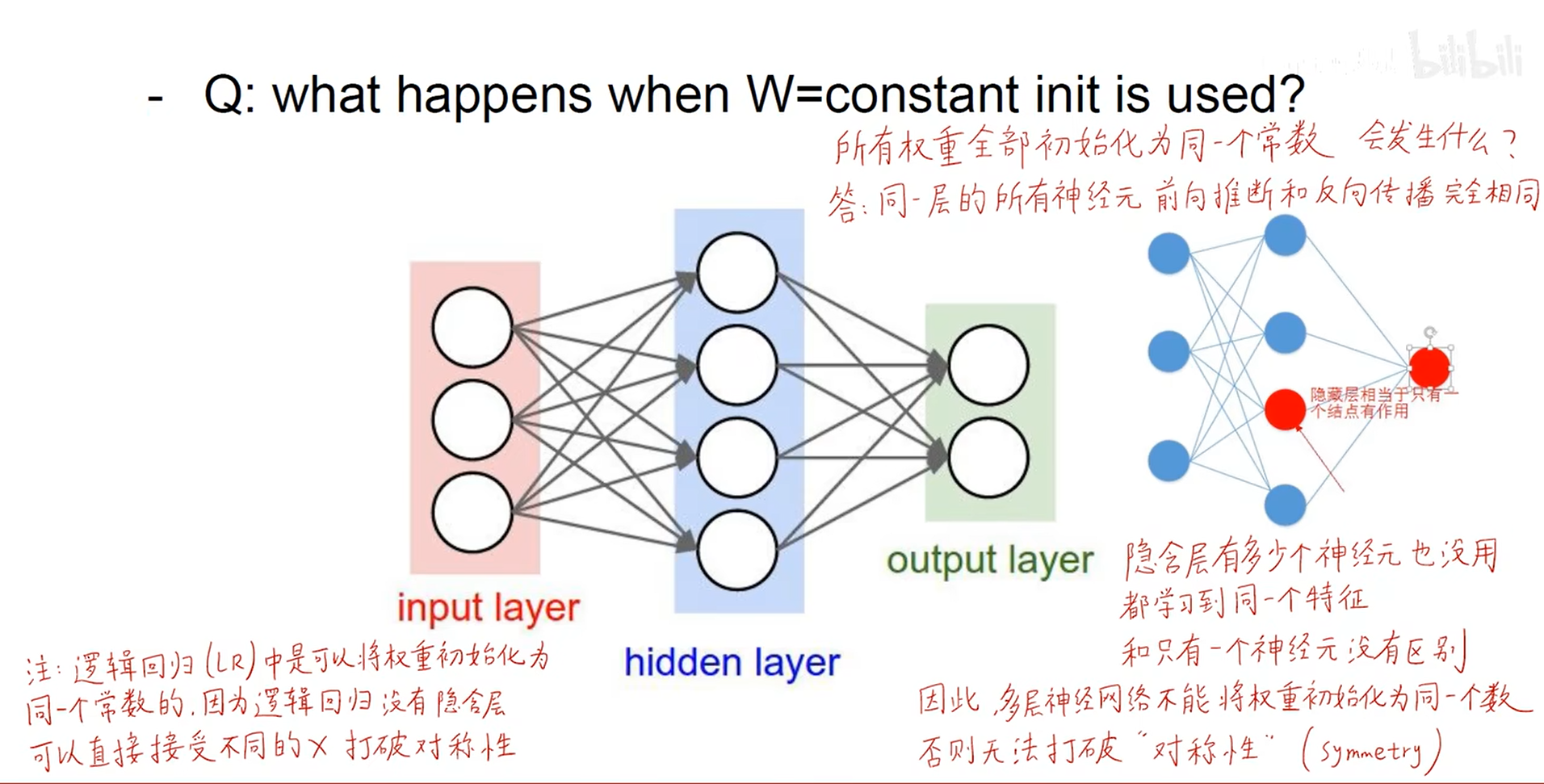
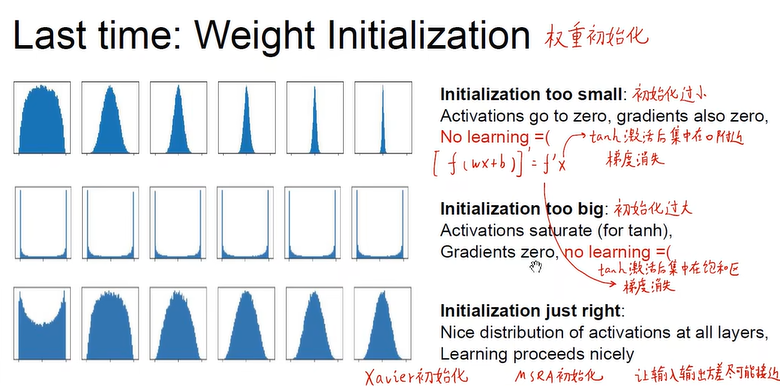
- 权重初始化
- 权重设置为同一个数? 不行。这样每一个神经元的完全相同。
- 参数随机初始化?
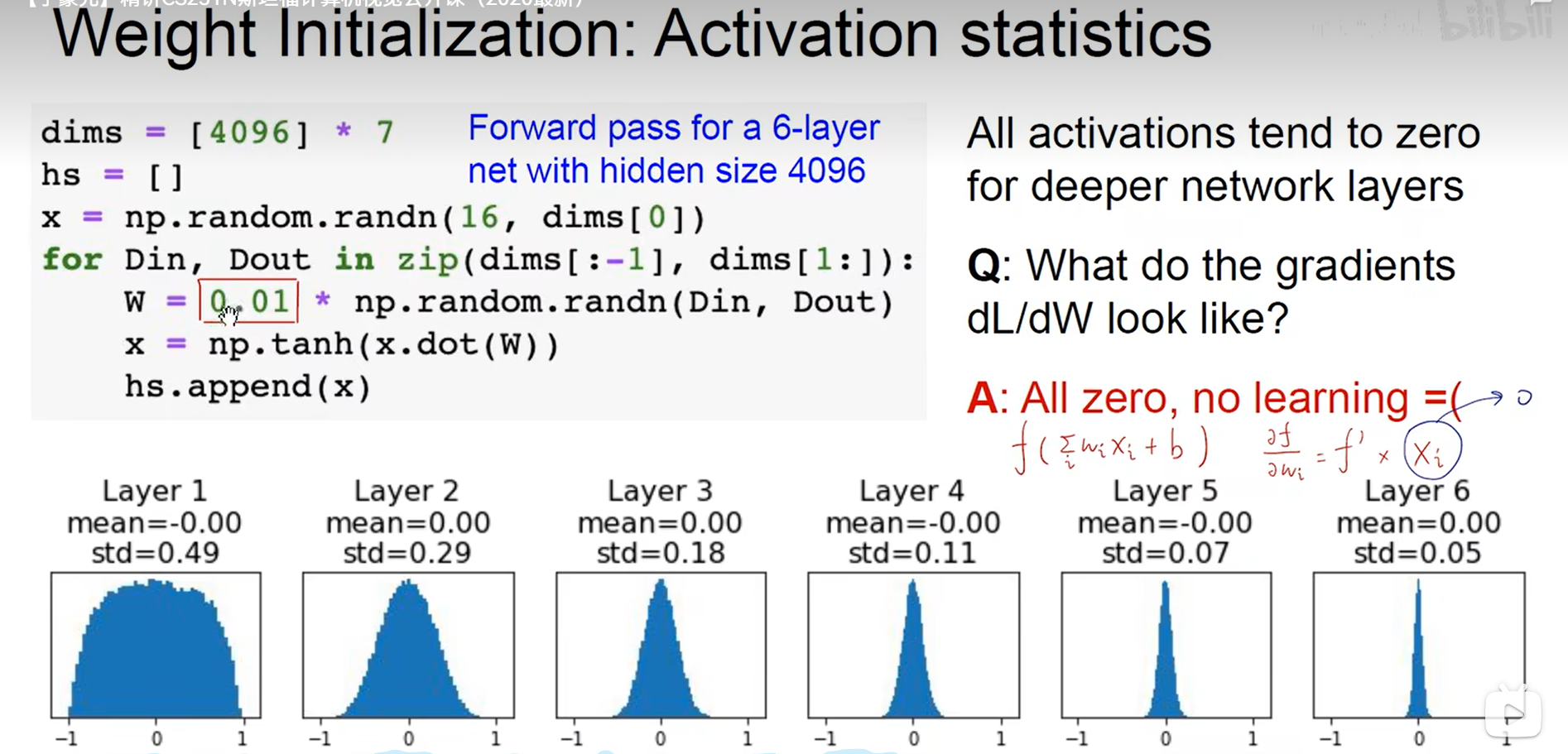

该种初始化会导致梯度消失。
- Xavier初始化
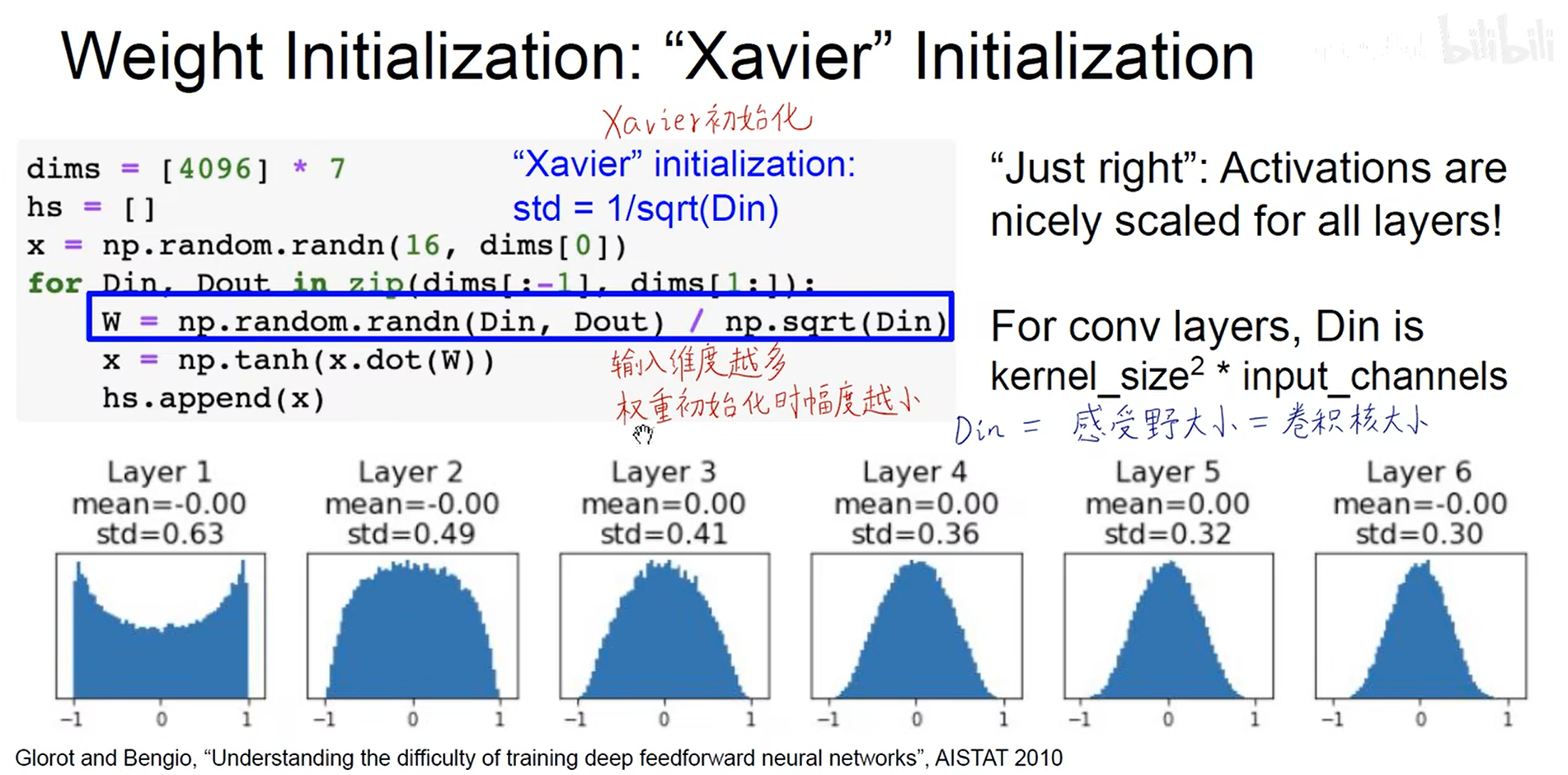
根据输入的维度进行确认。

在relu上不成立,该方法前提要求w和x关于0对称,但是relu>=0
- Kaiming/MSRA Initialization 何凯明提出初始化方法 【针对ReLU】
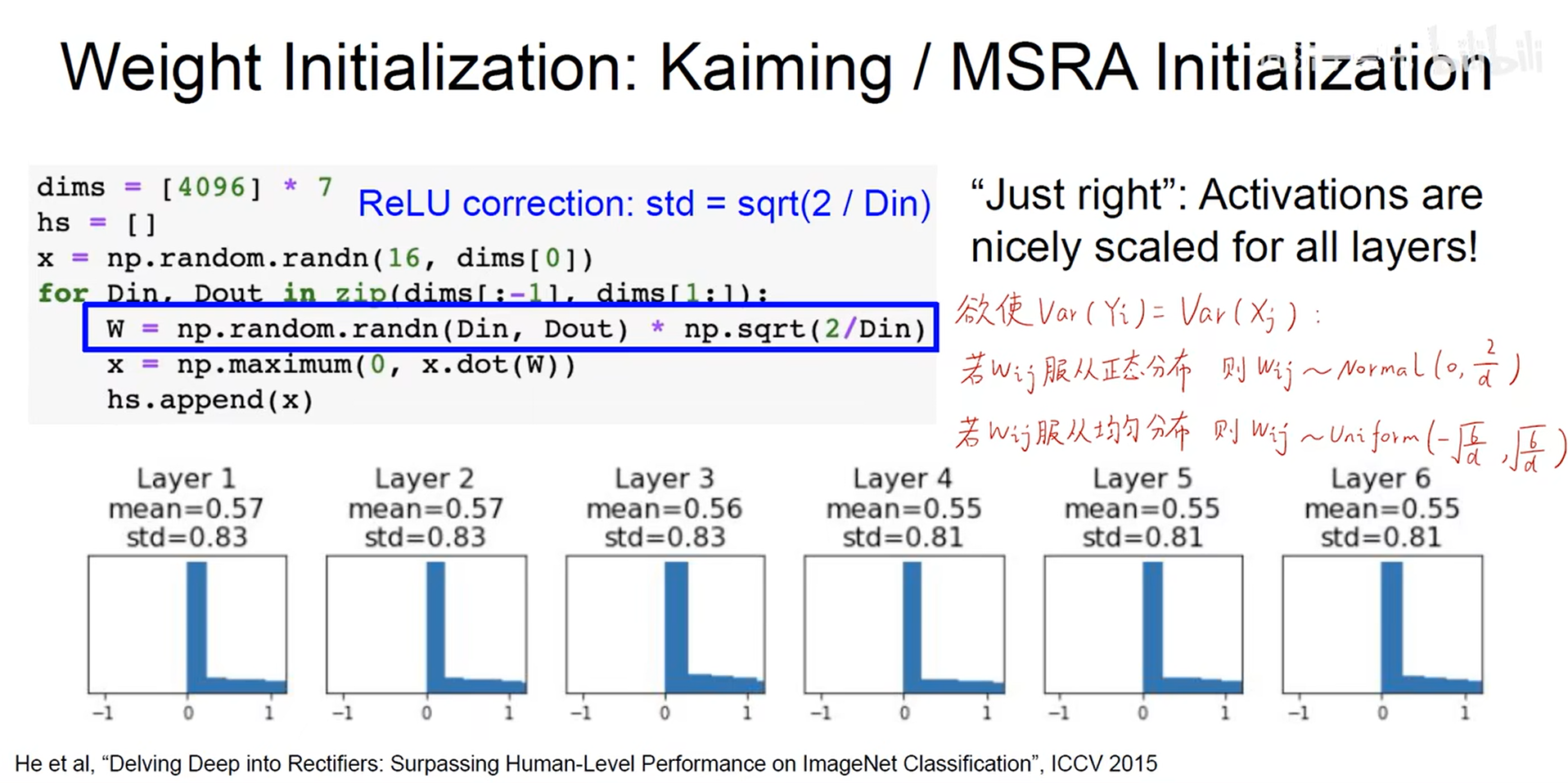

- Batch Normalization (批归一化)

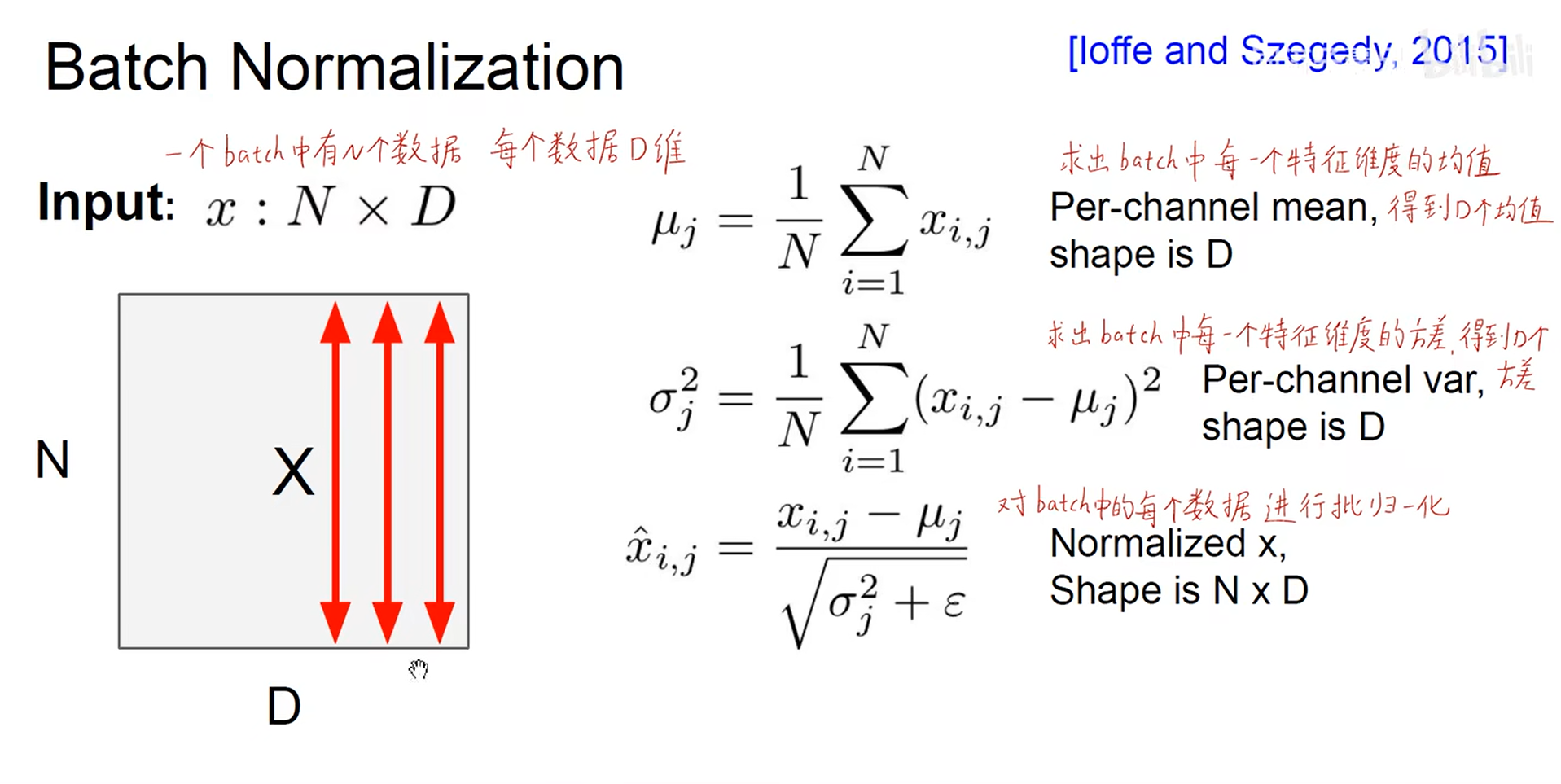
测试时用训练全局的方差和均值的的数据代替批处理的。训练里面使用的每batch的一批的。


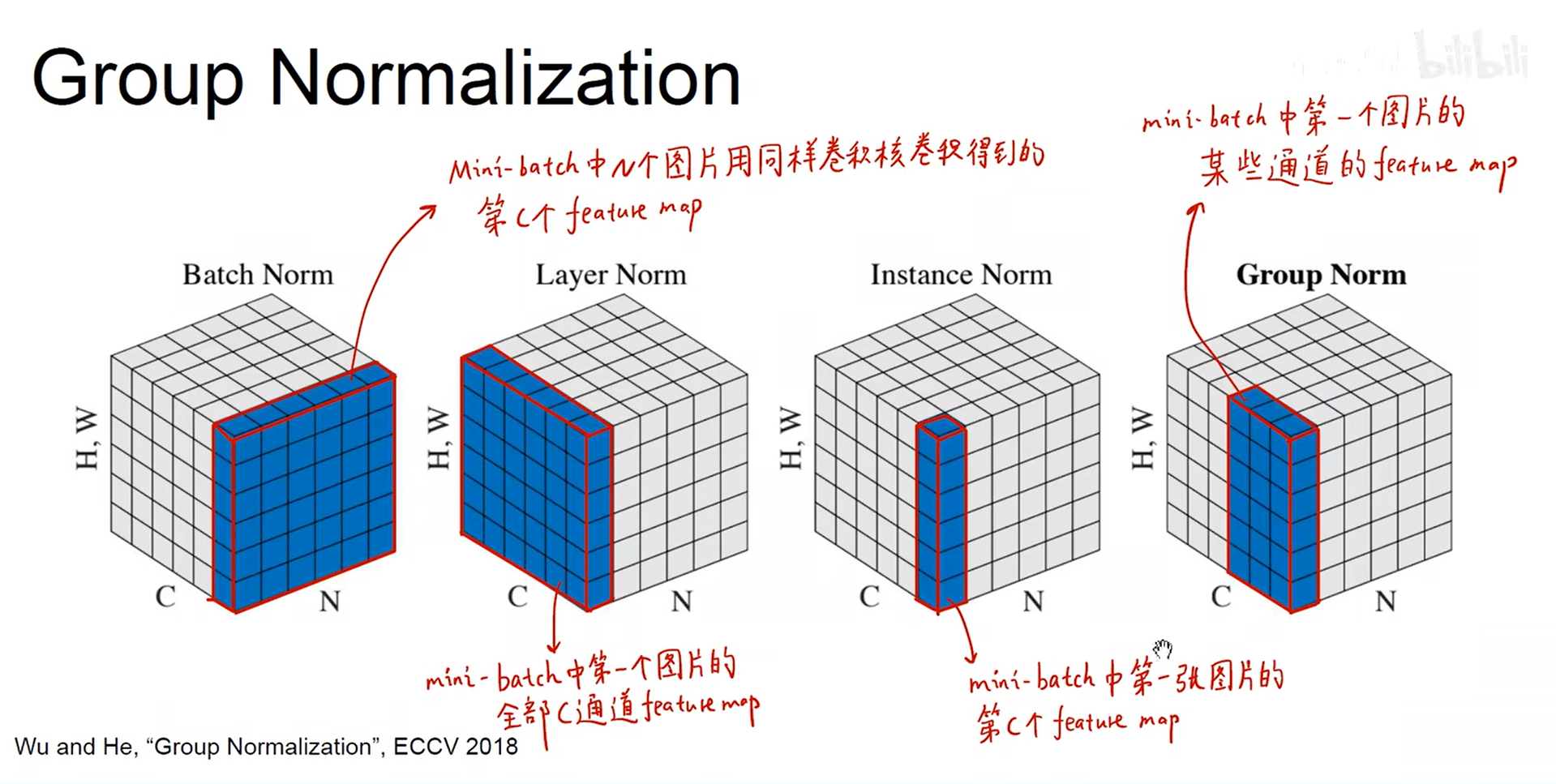
- 总结


- 训练神经网络 (二)
- 优化器
- 传统随机梯度下降优化的缺点:

竖直方向上存在冗余的梯度
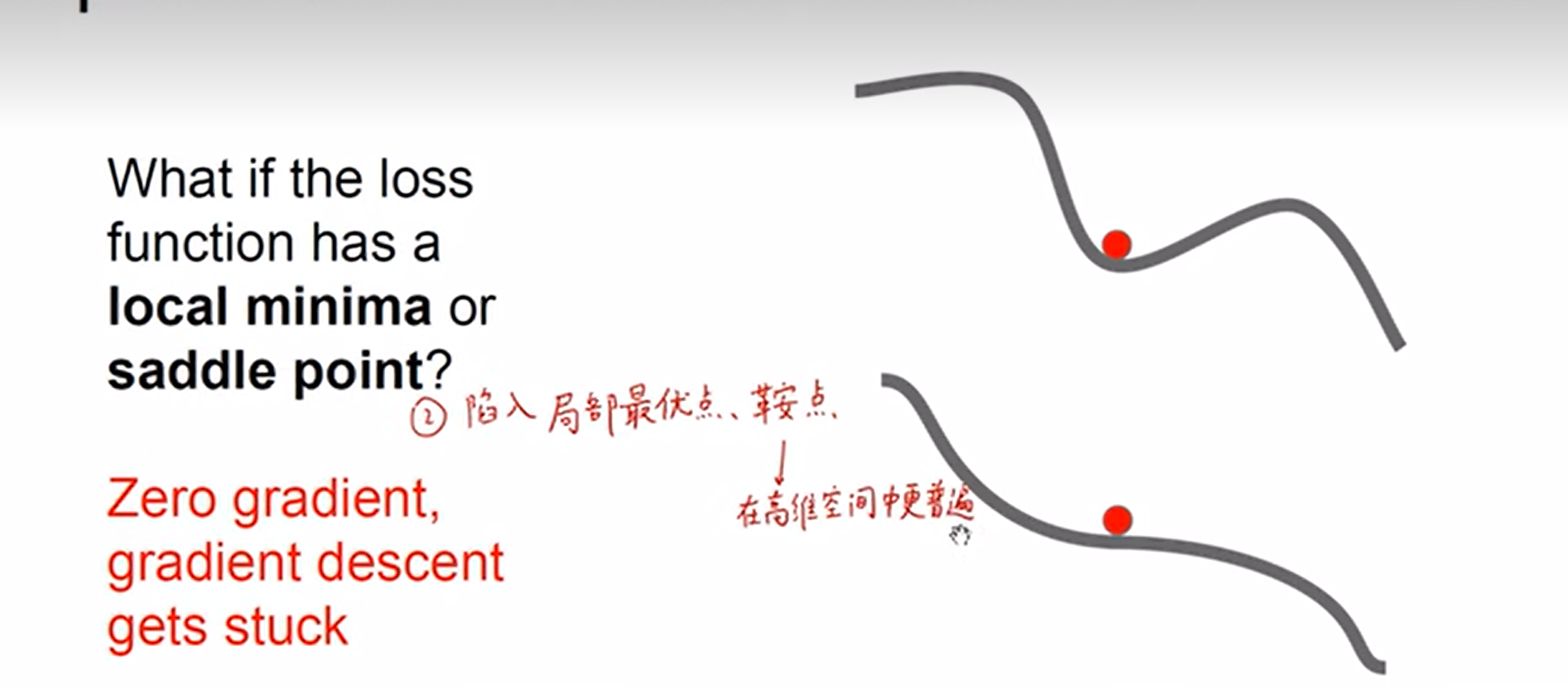
陷入局部最优点
– SGD

– SGD + 动量 【Momentum】

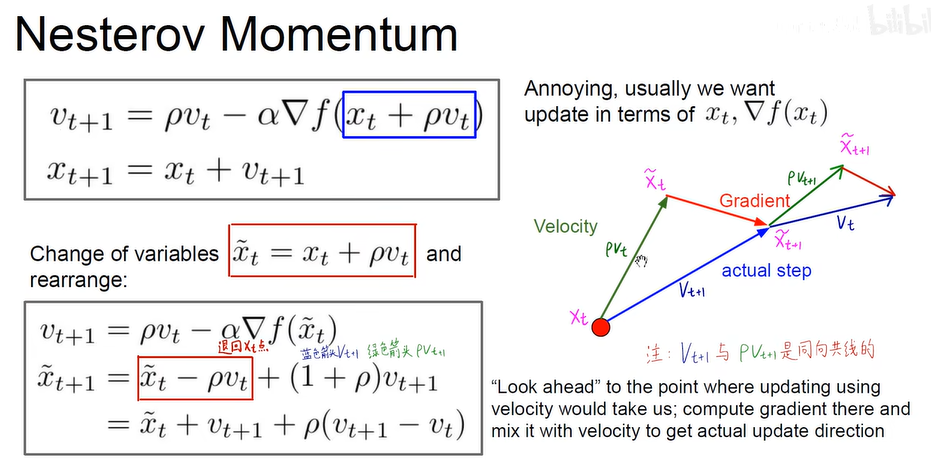
– Nesterov Momentum 【NAG】
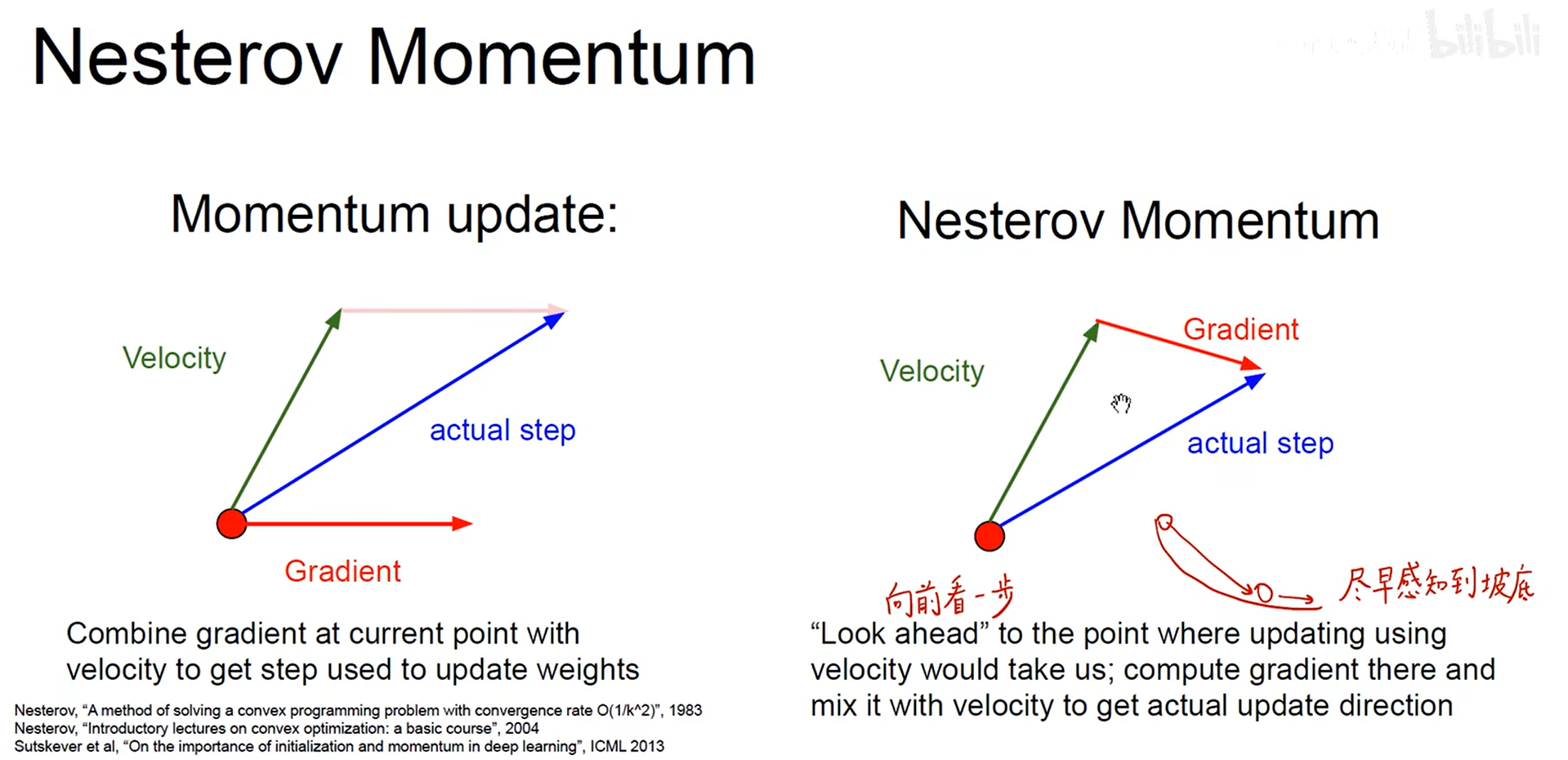
优化:先看动量下一步根据下一步再计算梯度
– AdaGrad

随着累加分母会变的越来越大,更新量会越来越小。
– RMSProp (Leakly AdaGrad)
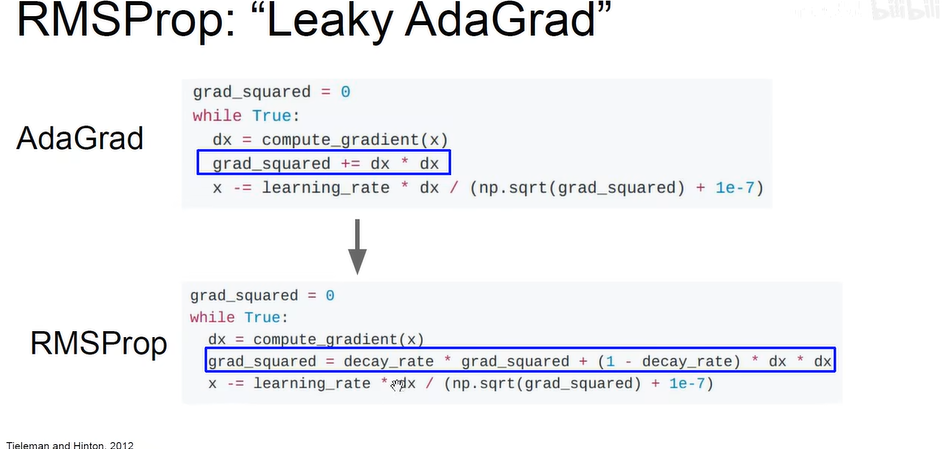
引入了衰减因子,类似于动量中的ρ
– Adam( almost)
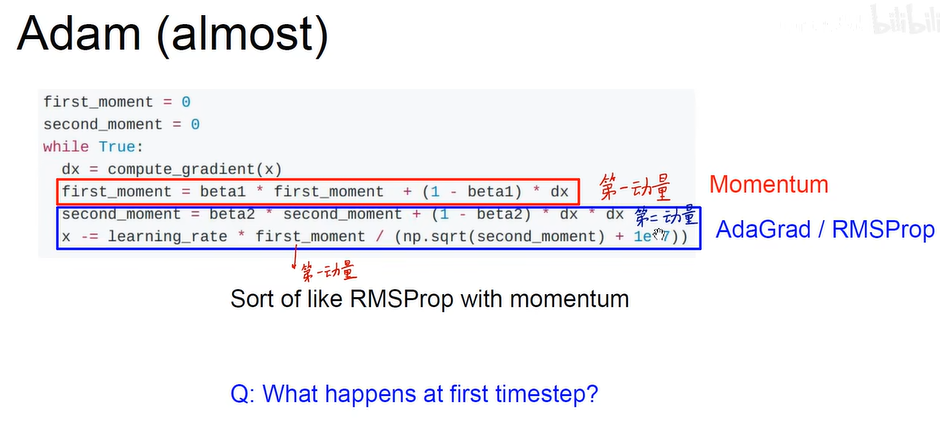
综合考虑了第一和第二动量
– Adam (full form)

- 学习率
- 如何评价一个好的学习率?

– 二阶优化法(牛顿法)
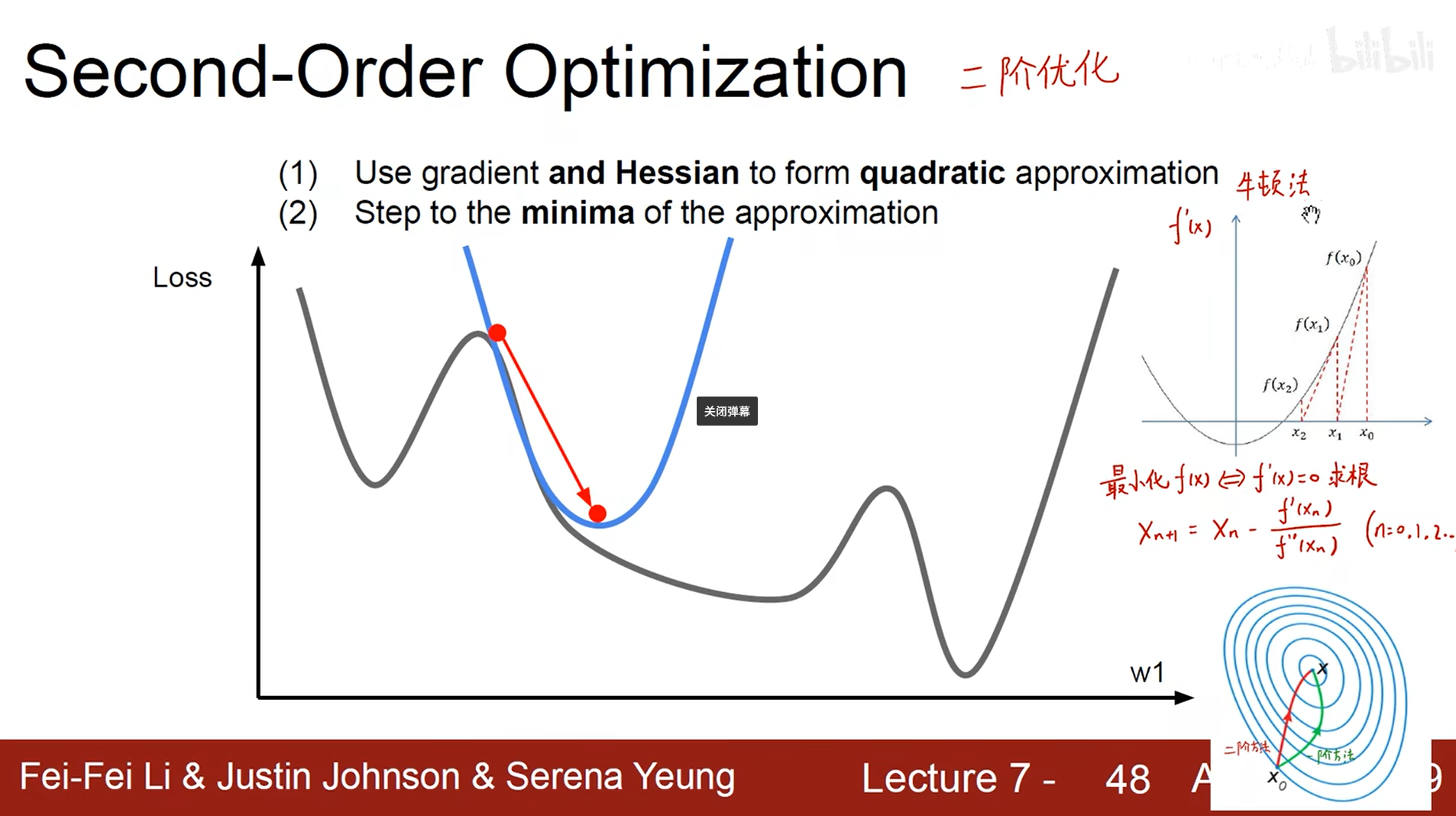
一阶导数除以二阶导数,无需设置学习率

海森矩阵有时候计算量比较大,所以不普遍应用,参数爆炸

采用拟牛顿法解决上述的问题。
- 防止过拟合
提前停止
- 模型集成

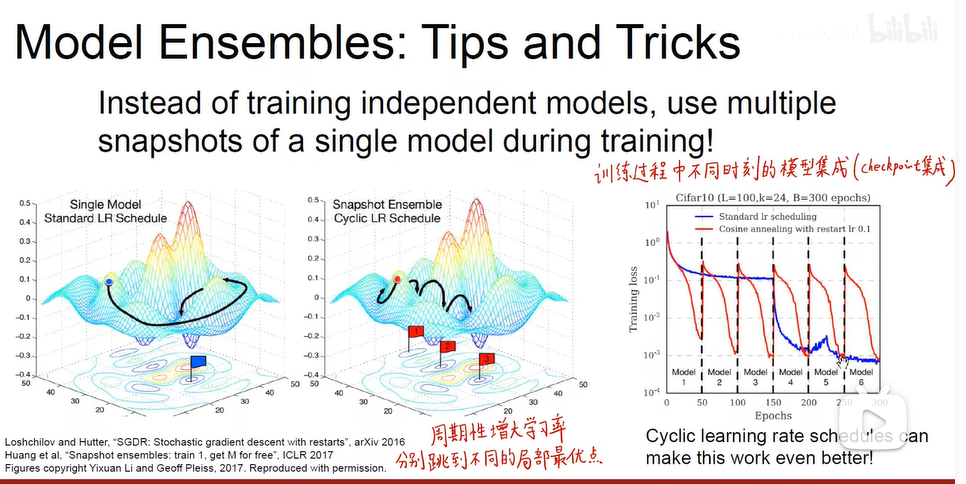
采用训练过程中不同时刻的模型进行集成;多个局部最优点进行集成学习
- 正则化
– Dropout
-
随机掐死一半的神经元,有效防止过拟合
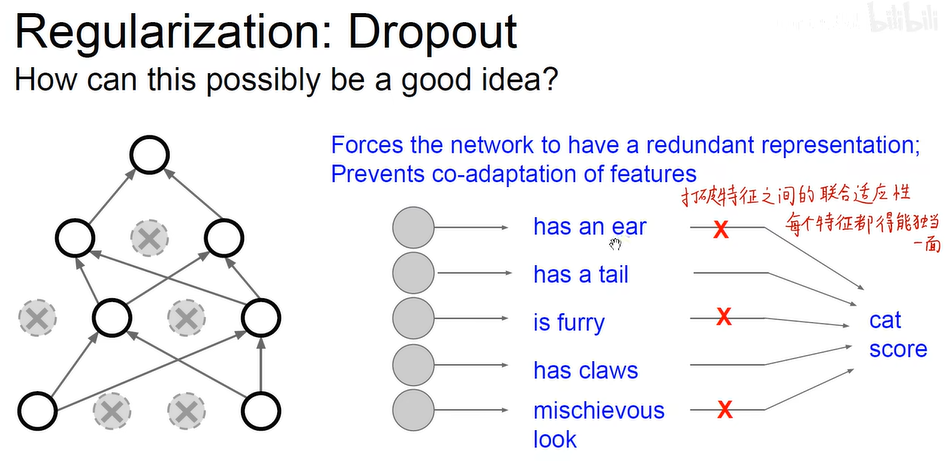
每个神经元都能够独当一面,减少神经元中的联合依赖和适应性;起到模型集成的效果;找到了主要矛盾,起到了稀疏性 -
测试阶段不需要该操作,测试的时候需要补偿随机的P(0.5)
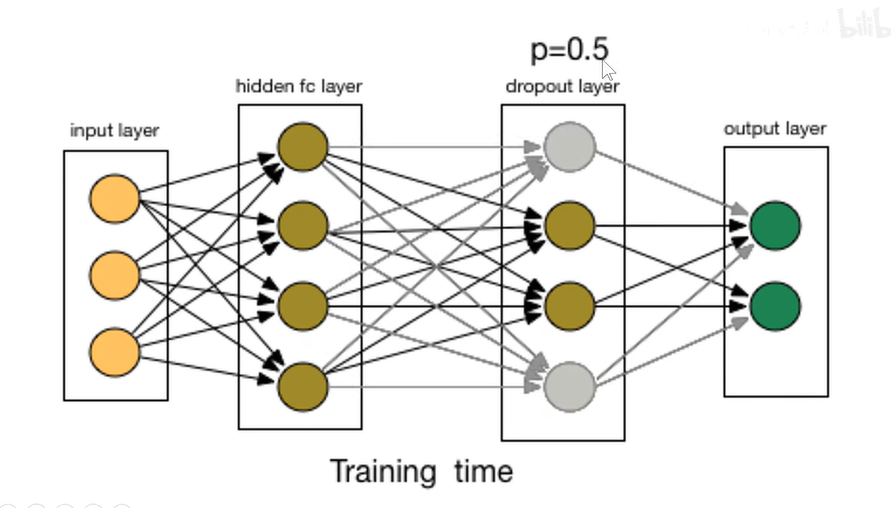
p=0.5能够使得各个神经元独立平等,不会出现部分神经元比重过大的情况,对应了 2 n 2^n 2n个模型。缺点是训练时间增加了。 -
有效性的解释:



- 数据增强 (data augement)
- 相当于增加了数据;
- 图像裁剪,水平翻转,颜色的偏移和翻转,
– drop connect
- 随机掐死某一些参数
– Fractional Max Pooling
- 随机池化,训练过程中随机生成,大小不确定
– Stochastic Depth
- 随机掐死一些层(resnet),可以使得网络的深度更大。
– Cutout
- 扣掉图片的一部分
- 将不同的物品的图片掺在一起
- 超参数选择
- 检验初试损失函数
- 在小数据集上尝试过拟合

- 总结

- 卷积神经网络工程实践技巧
– 卷积

- 卷积核本质是二维信号滤波器
- 卷积的本质是提取图像不同频率的特征
加速卷积运算的方法:

– imcol
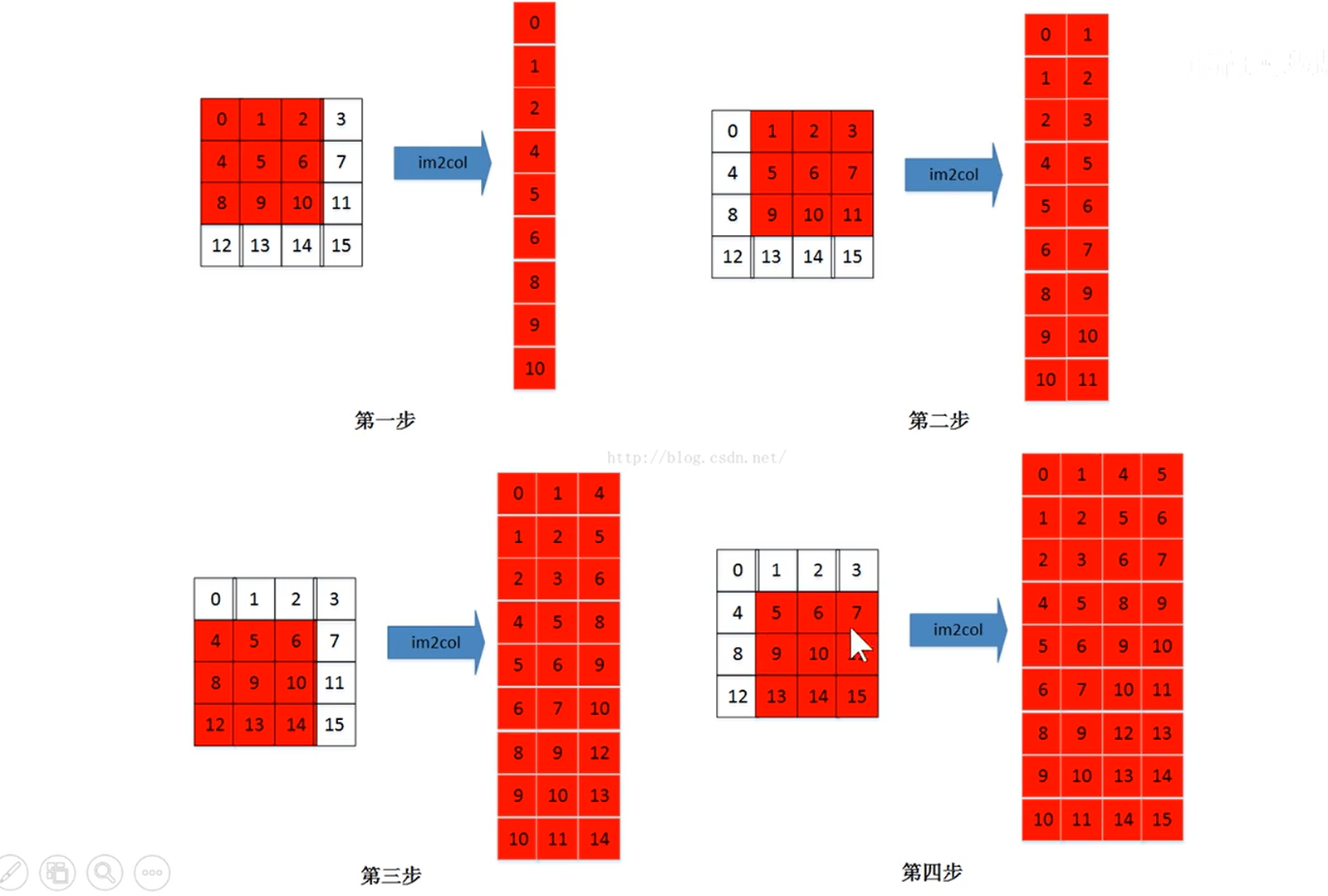
– FFT

- 迁移学习与fine tuning
- 迁移学习
借助预训练模型,泛化自己的数据集。借助冻结的模型进行特征的提取。
- 数据库太小的处理方法?

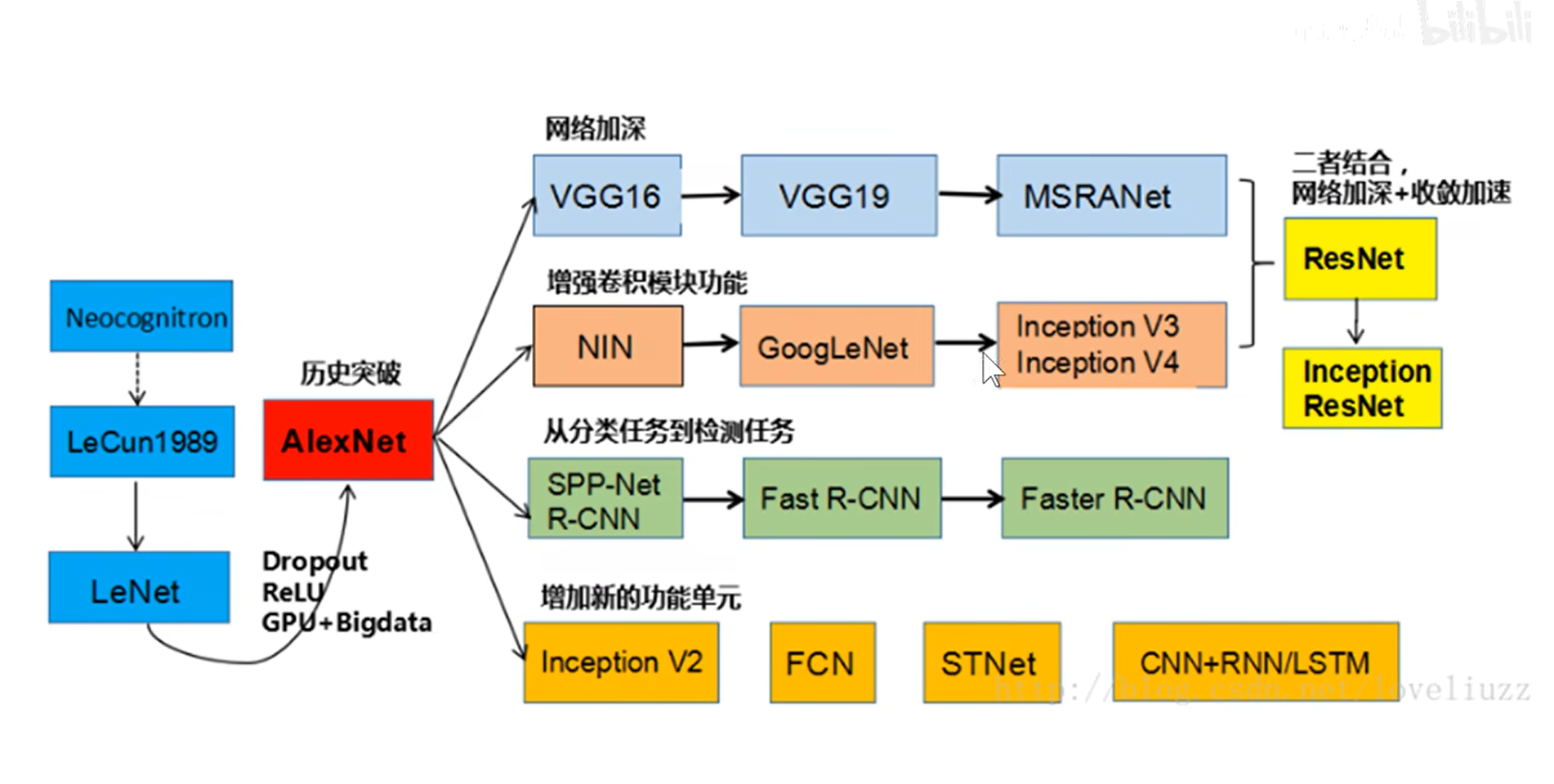
- 卷积神经网络结构案例分析

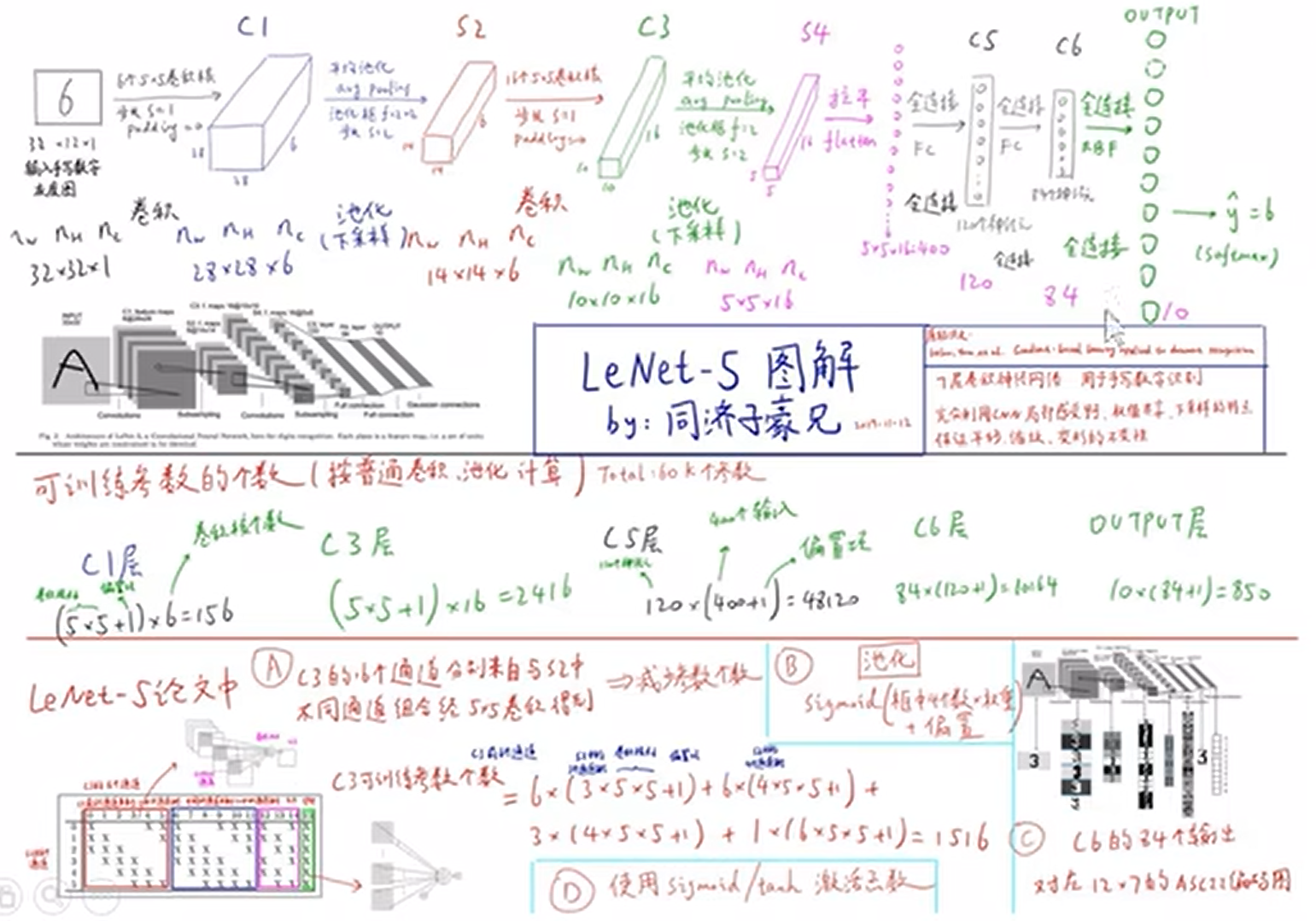
. LeNet-5
. AlexNet
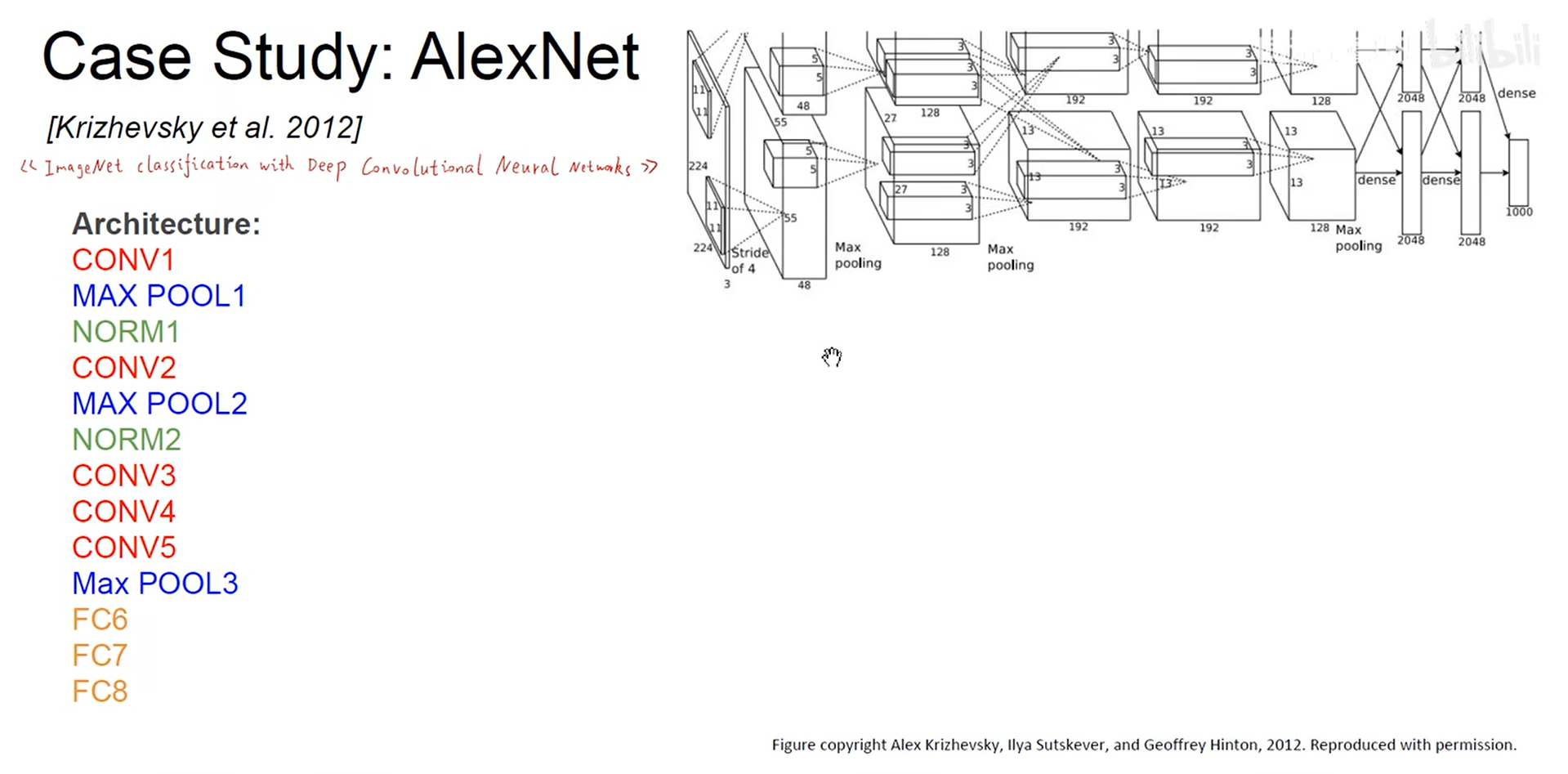

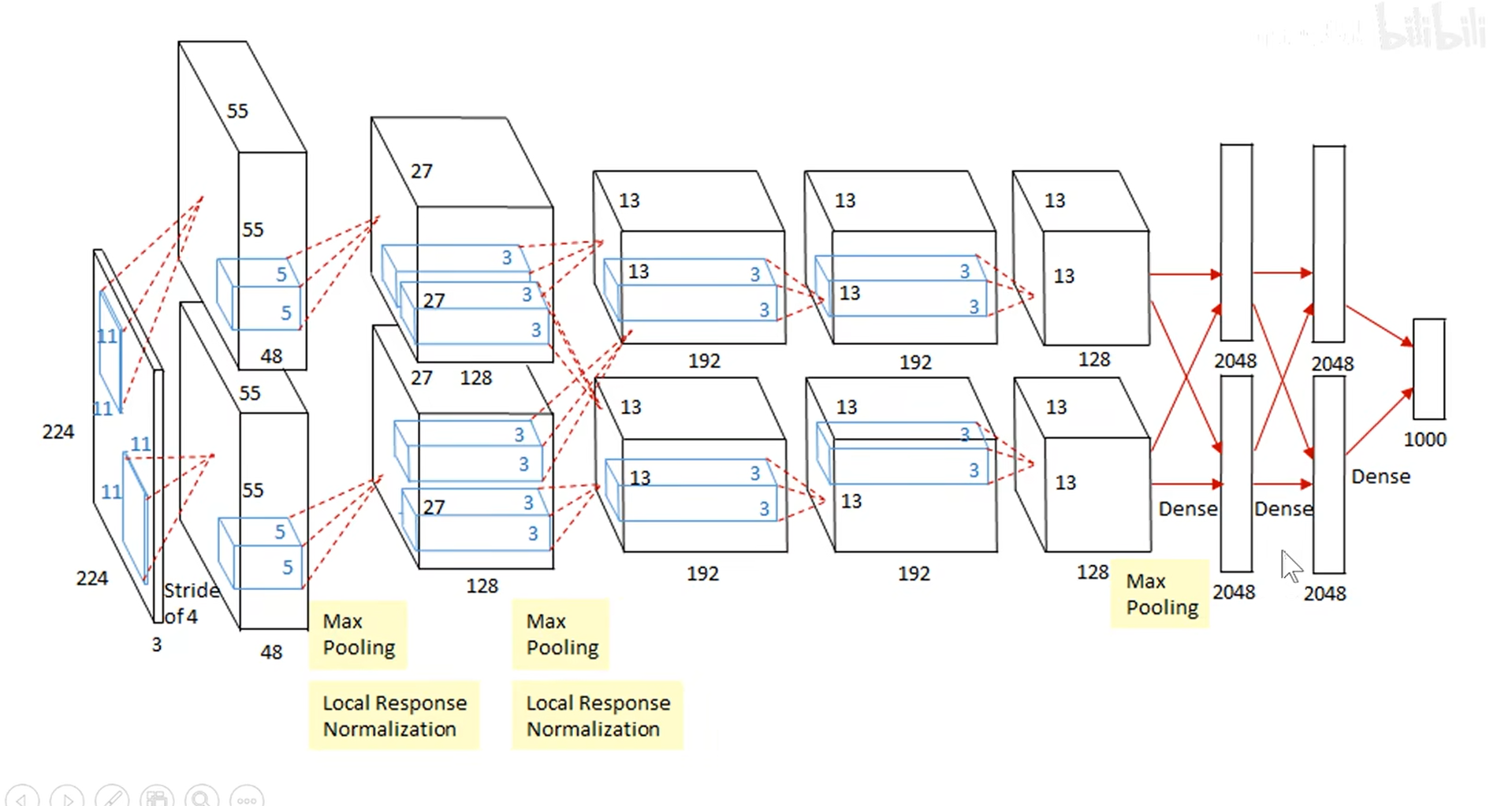
- 在LeNet的基础上进行改进
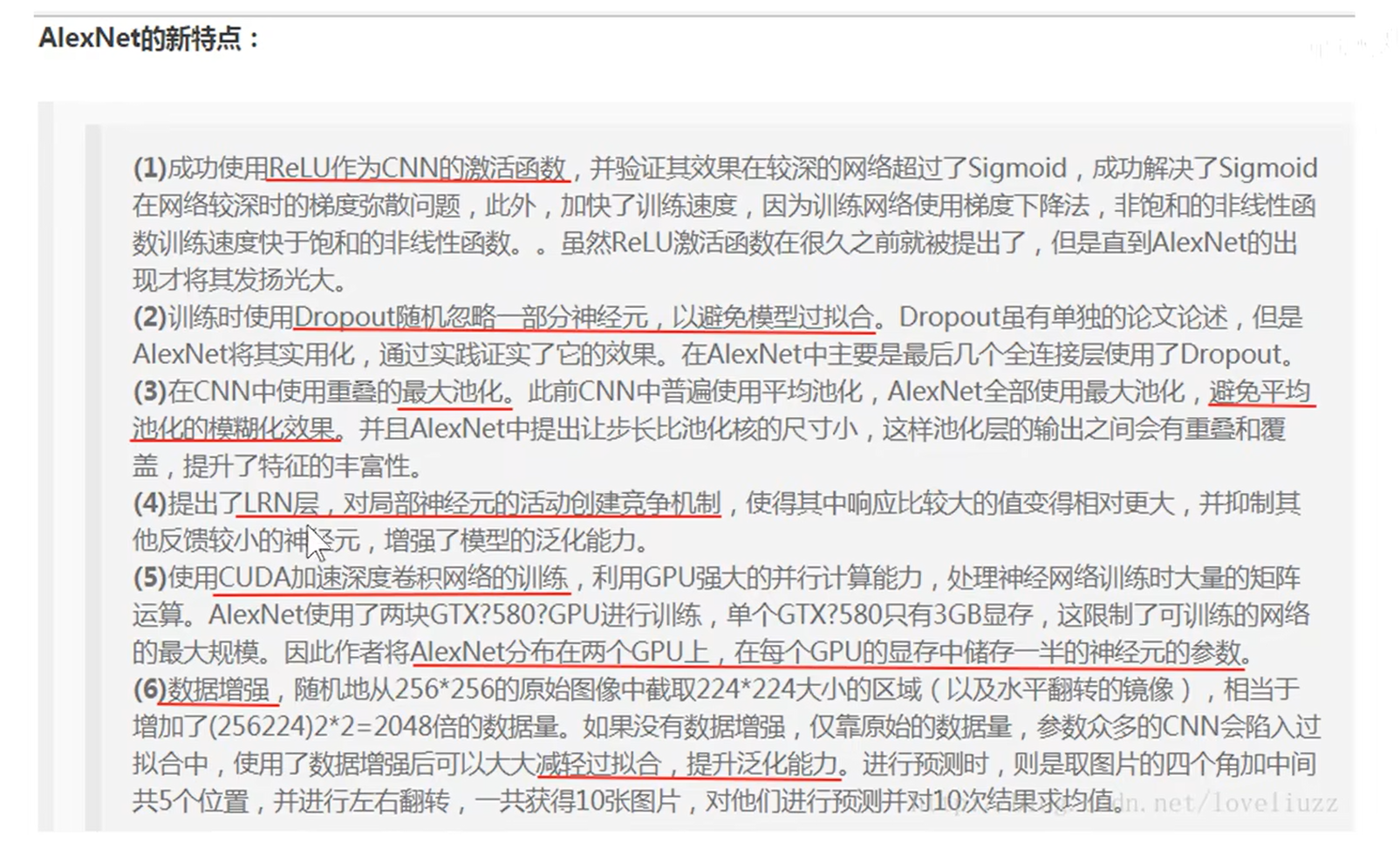
. ZFNet (可视化理解反卷积)
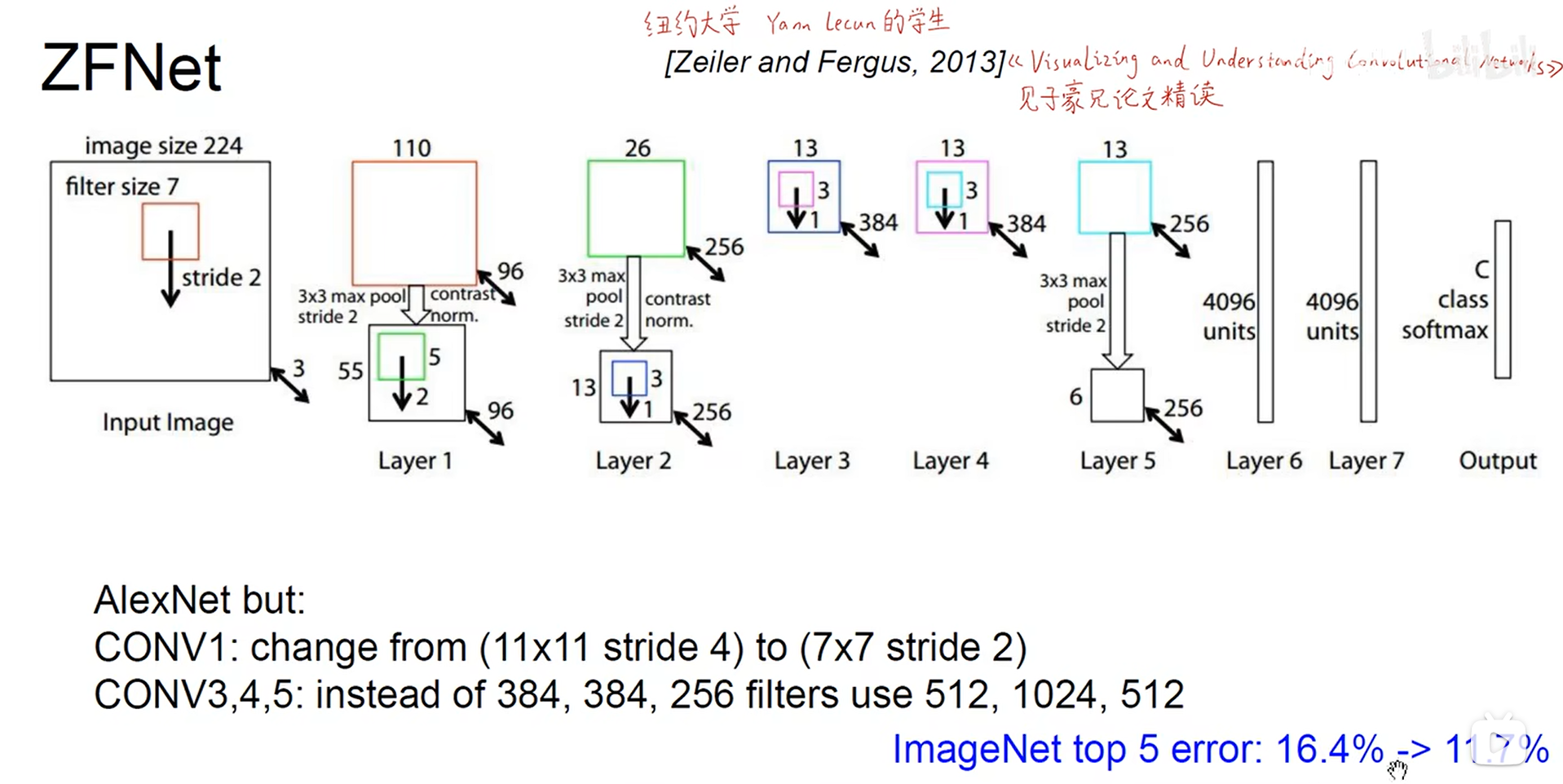
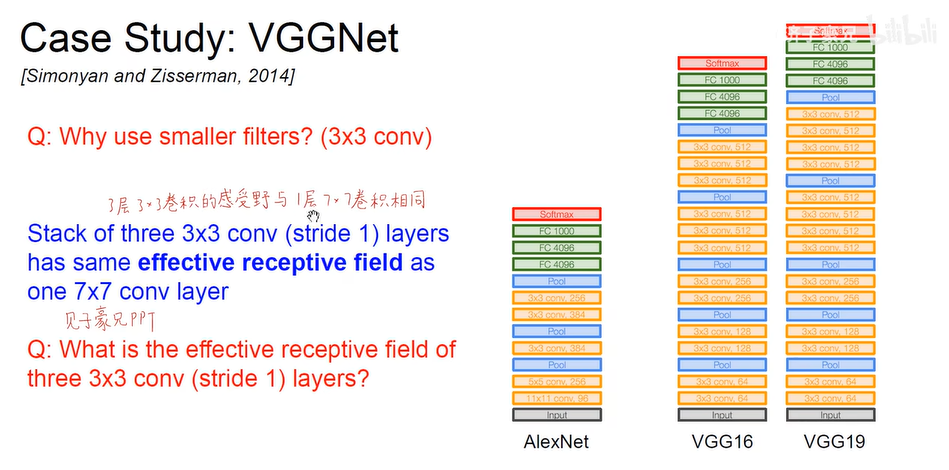
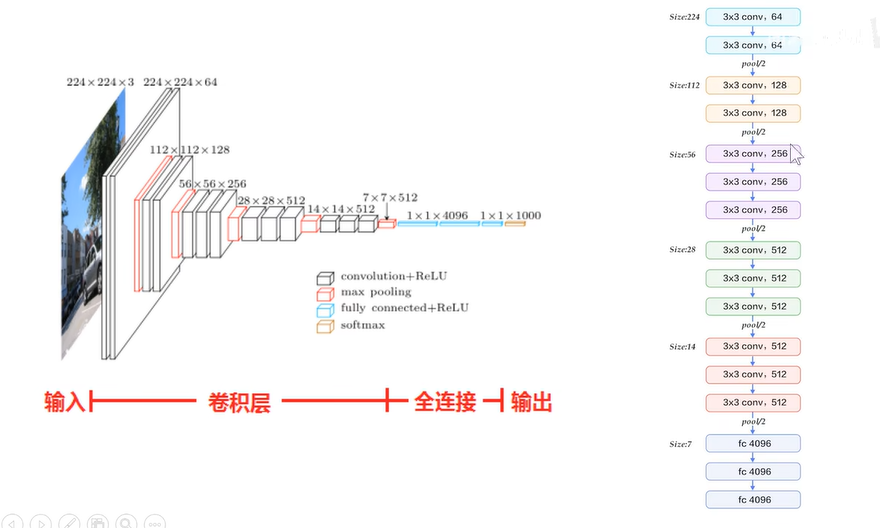
.VGG

.GoogleNet
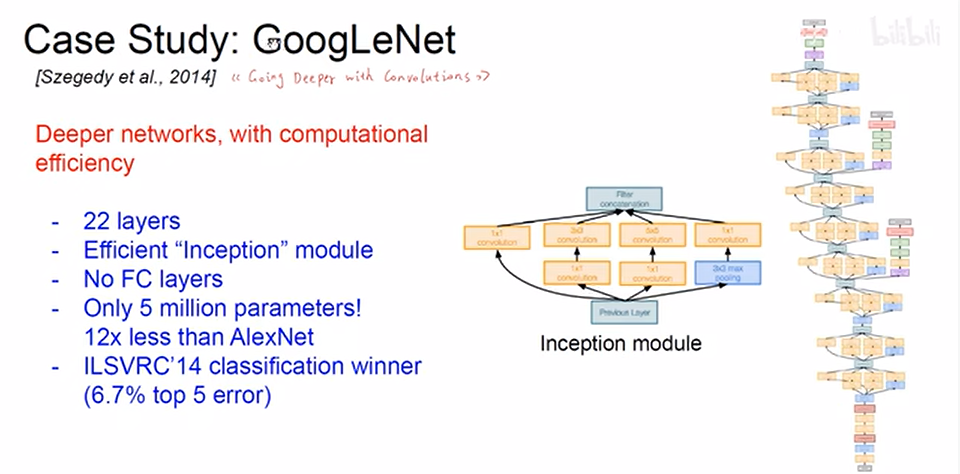
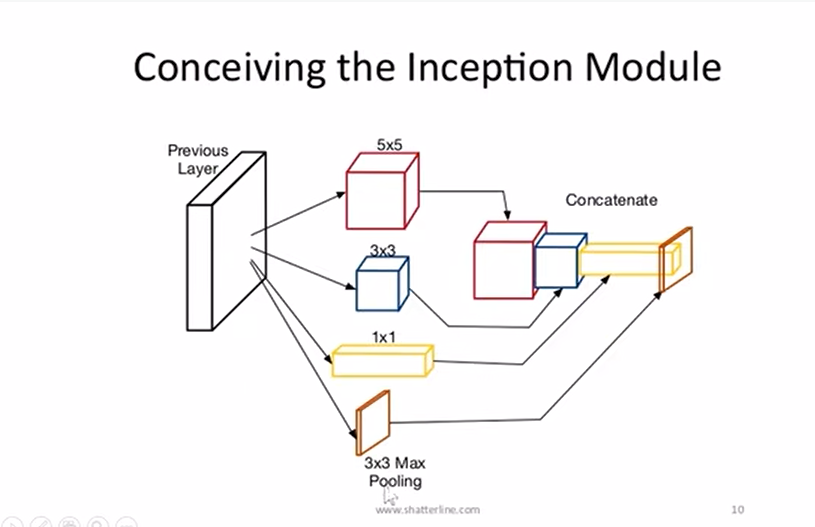
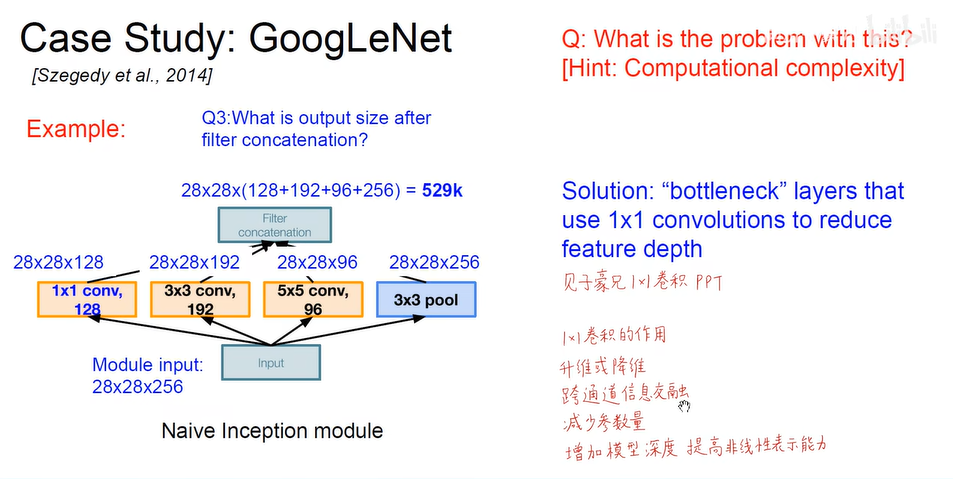
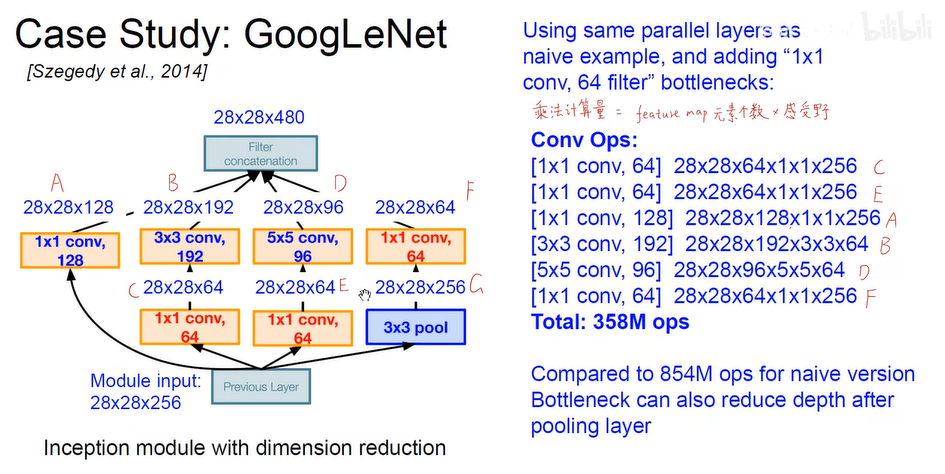
- inception模块, 不同类型的卷积层最后叠加
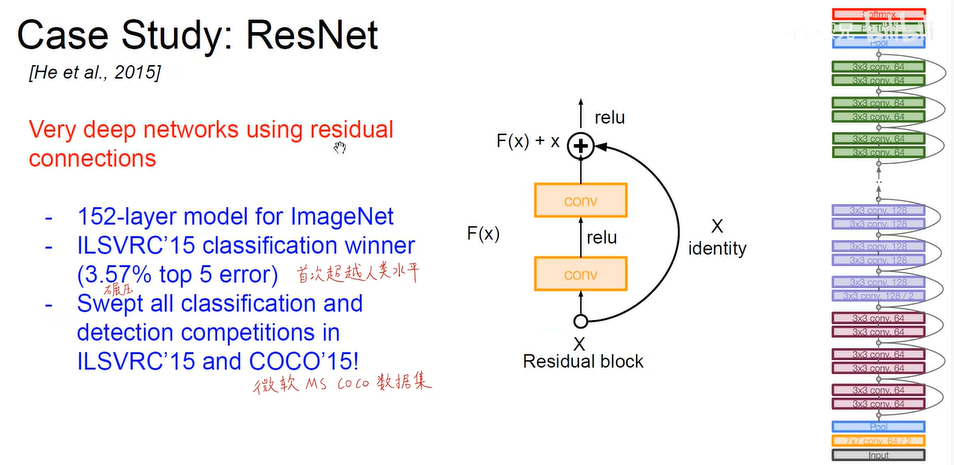
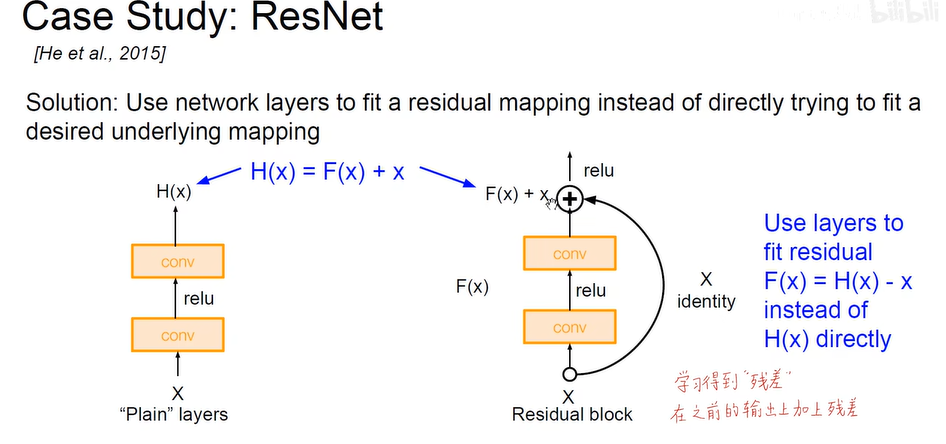
.ResNet

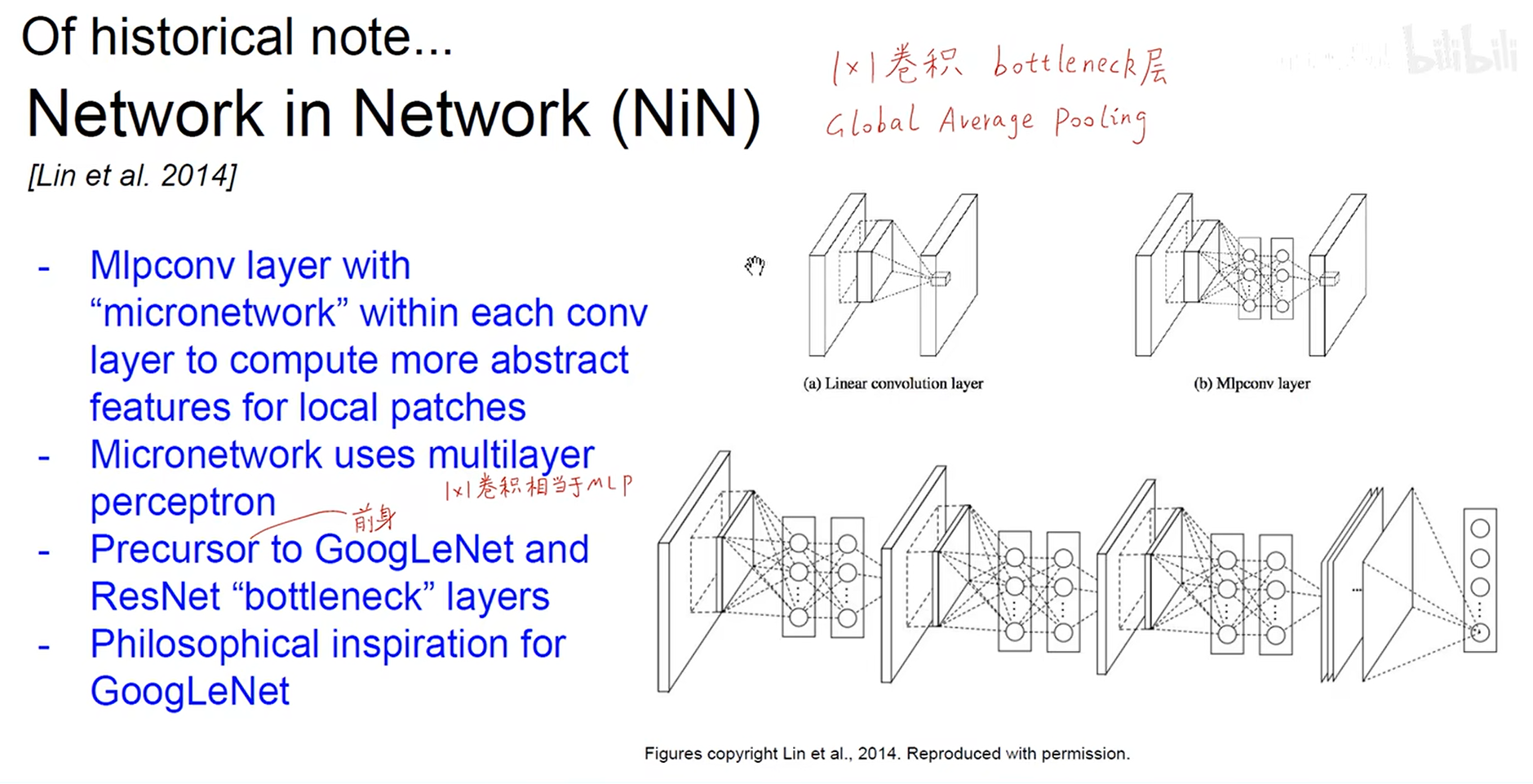
.NetWork in NetWork
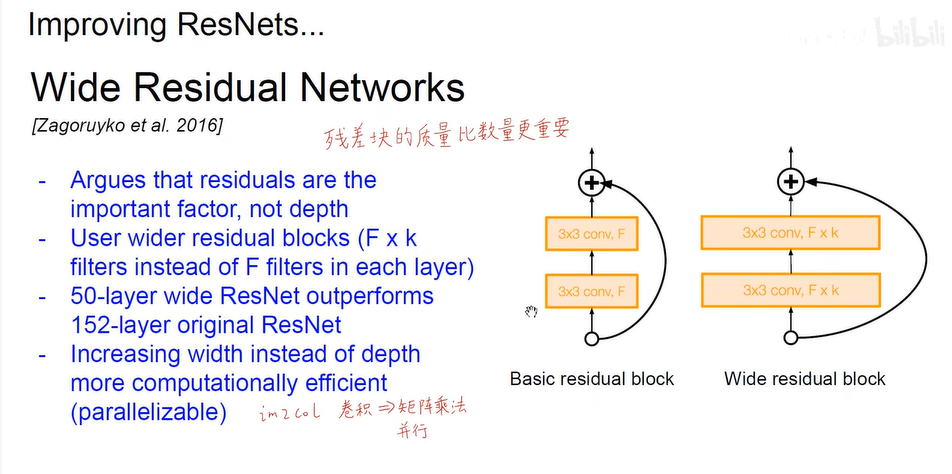
- 残差块的质量大于数量的重要性
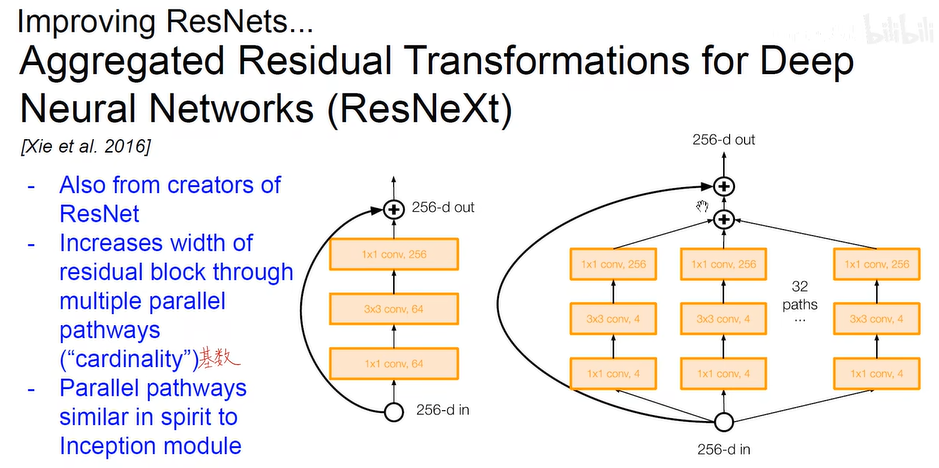
- 分形网络
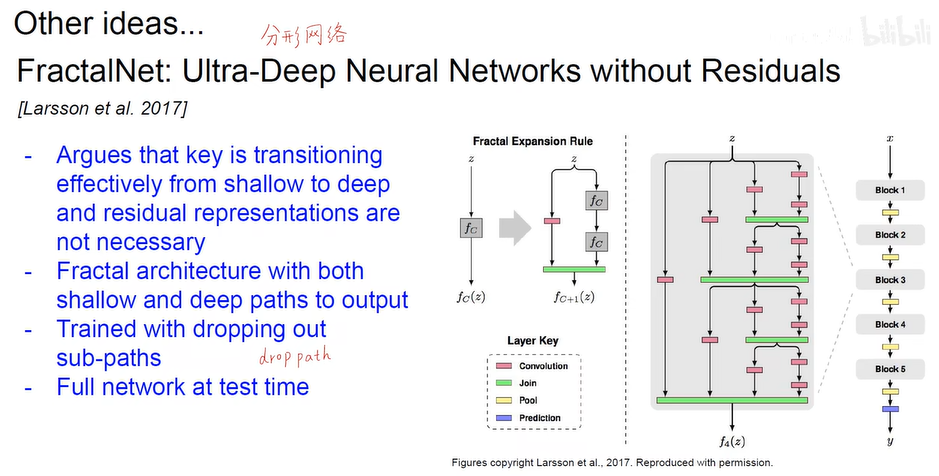
- 全附庸模型
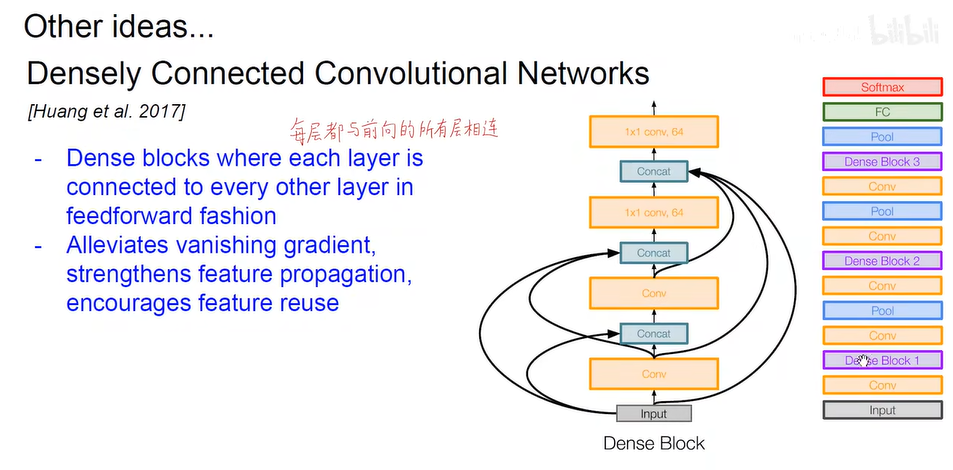
- 可部署移动设备
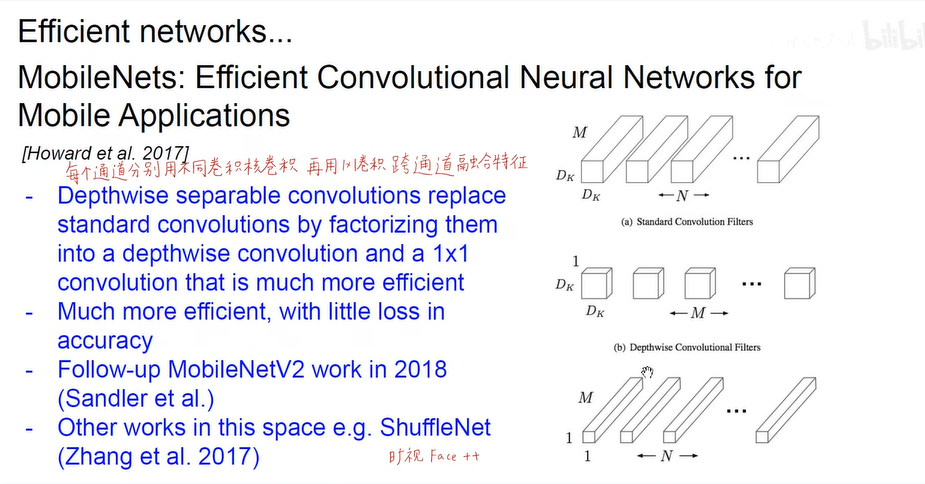
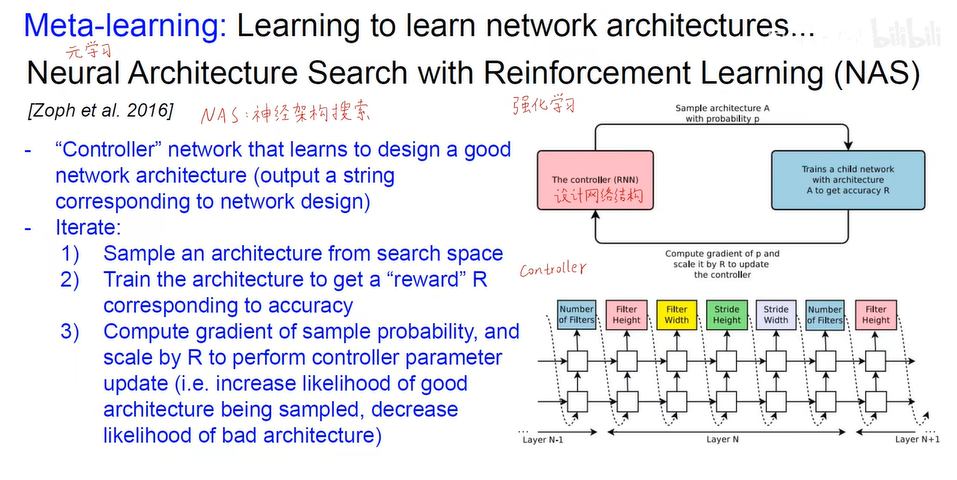
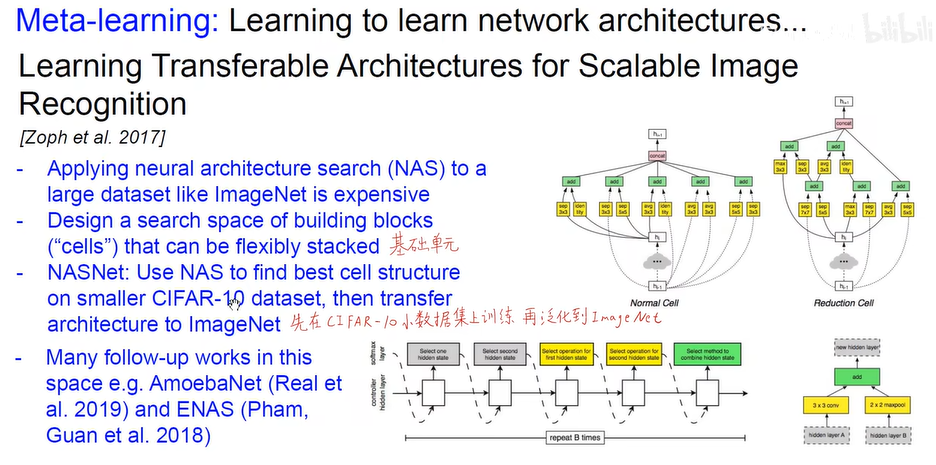
- 元学习 (AI自己训练网络)
- 总结
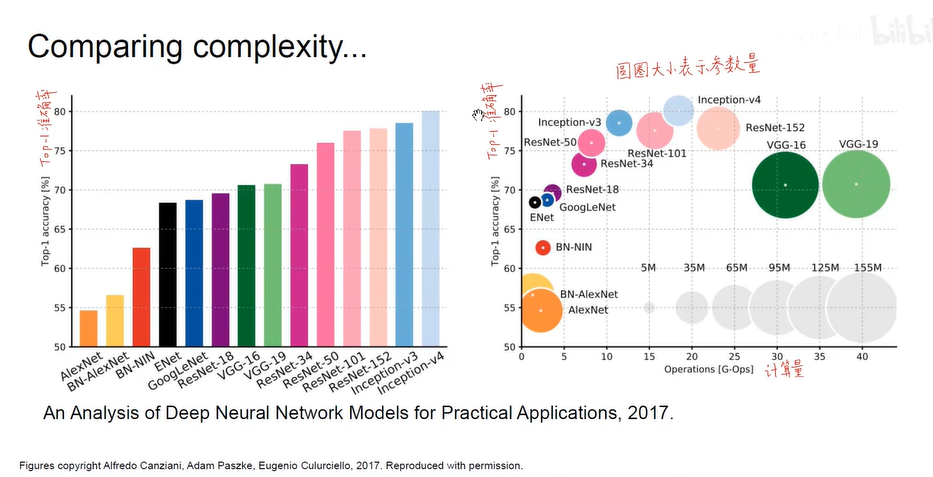
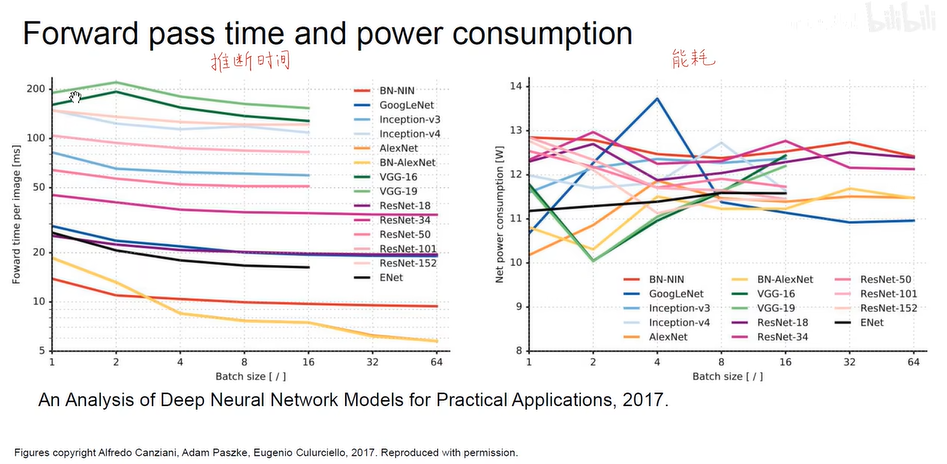


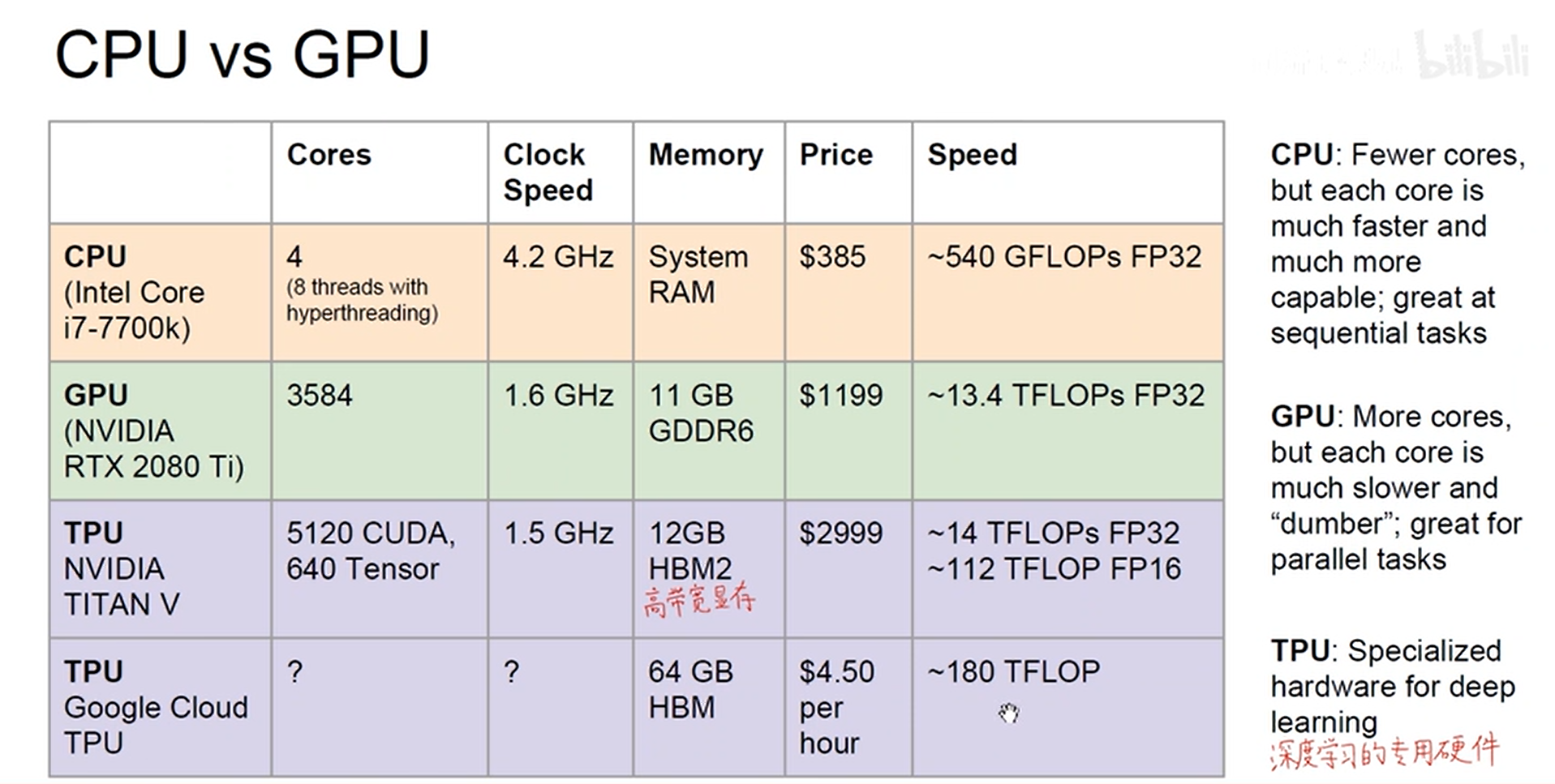
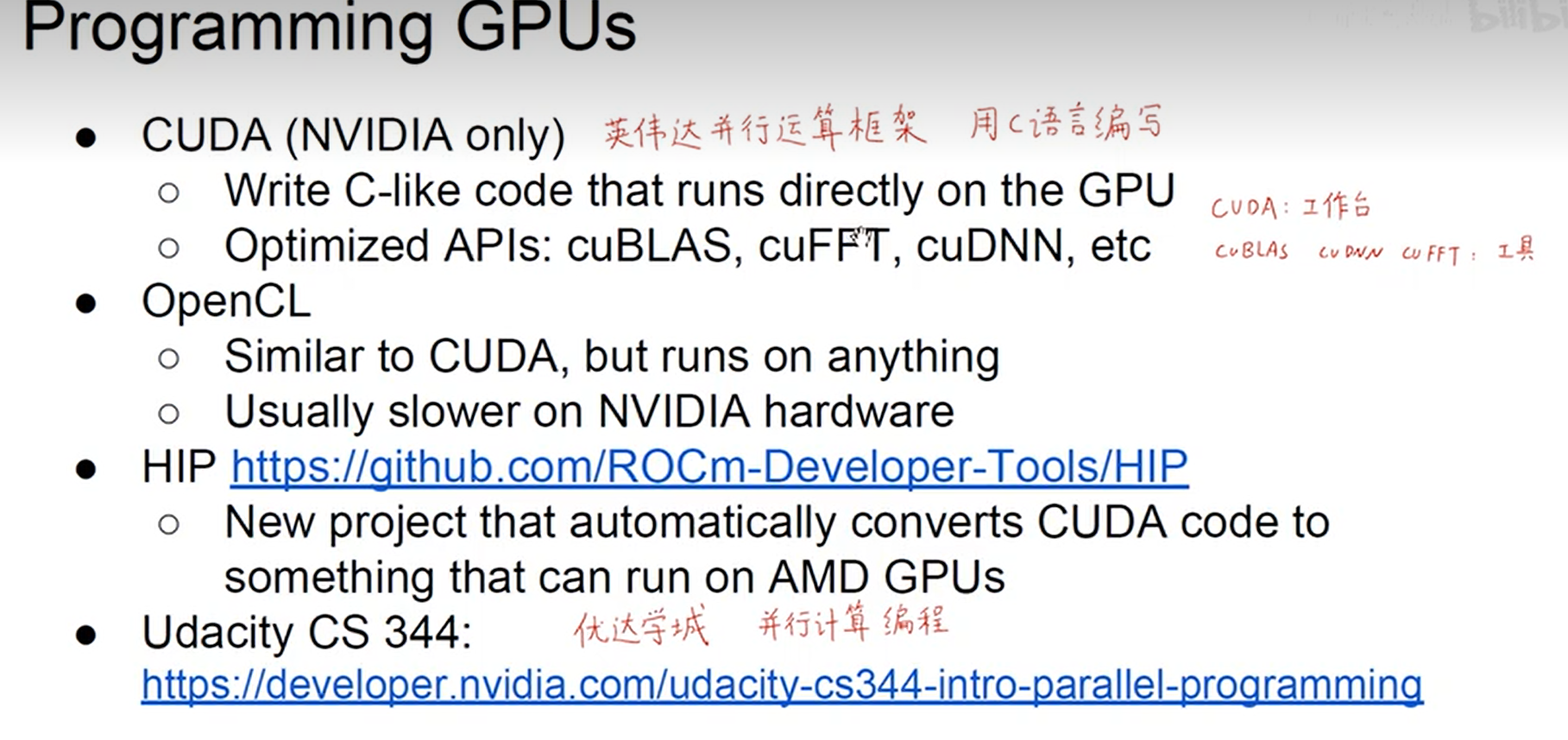
- 深度学习硬件算力基础 (GPU & TPU)

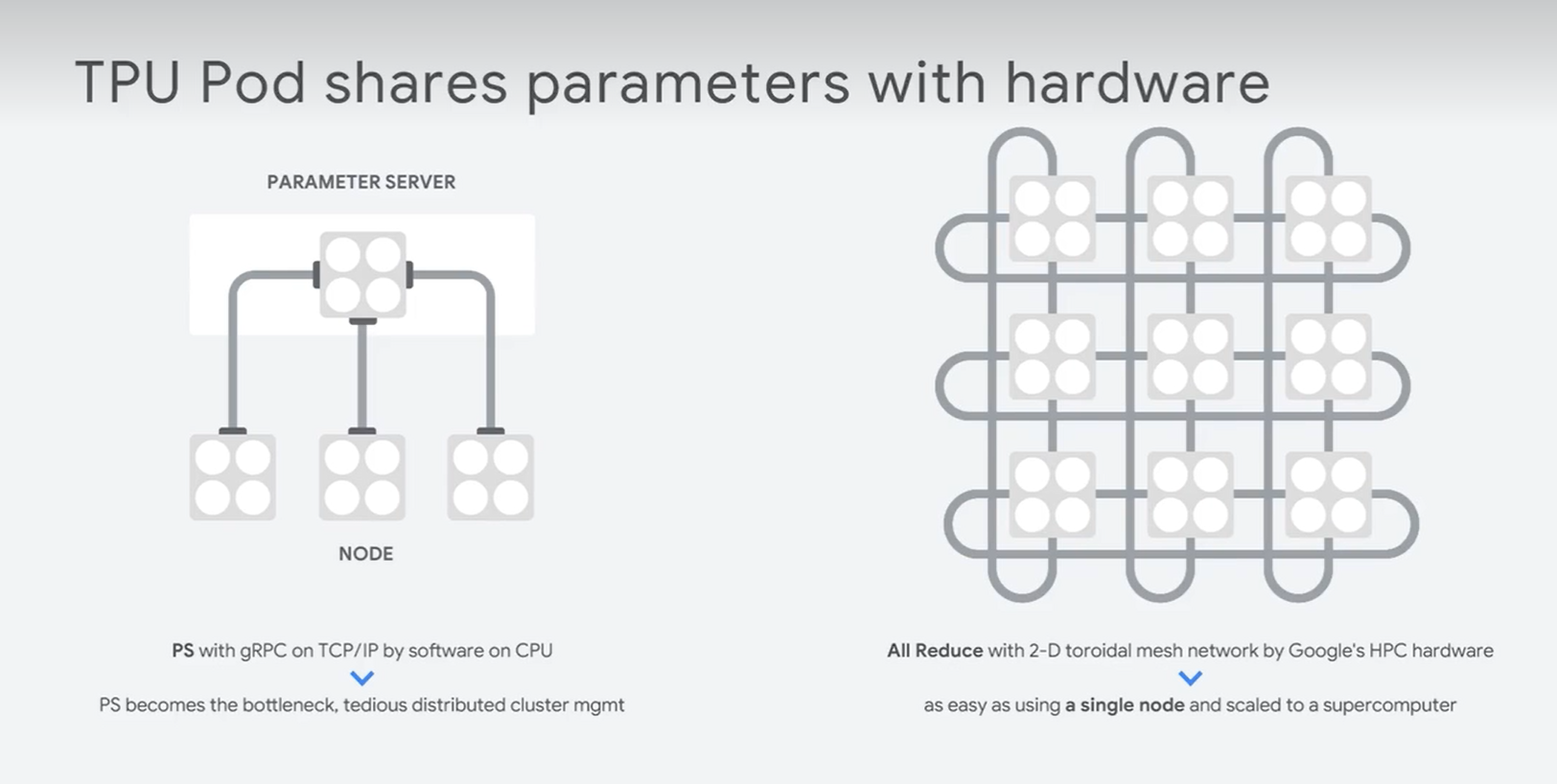
英特尔神经棒:
能够实现嵌入式调用神经模型。进行边缘计算,对本地的硬件的要求比较高。
模型尺寸过大的危害:

- 主要能耗在于内存数据的读取
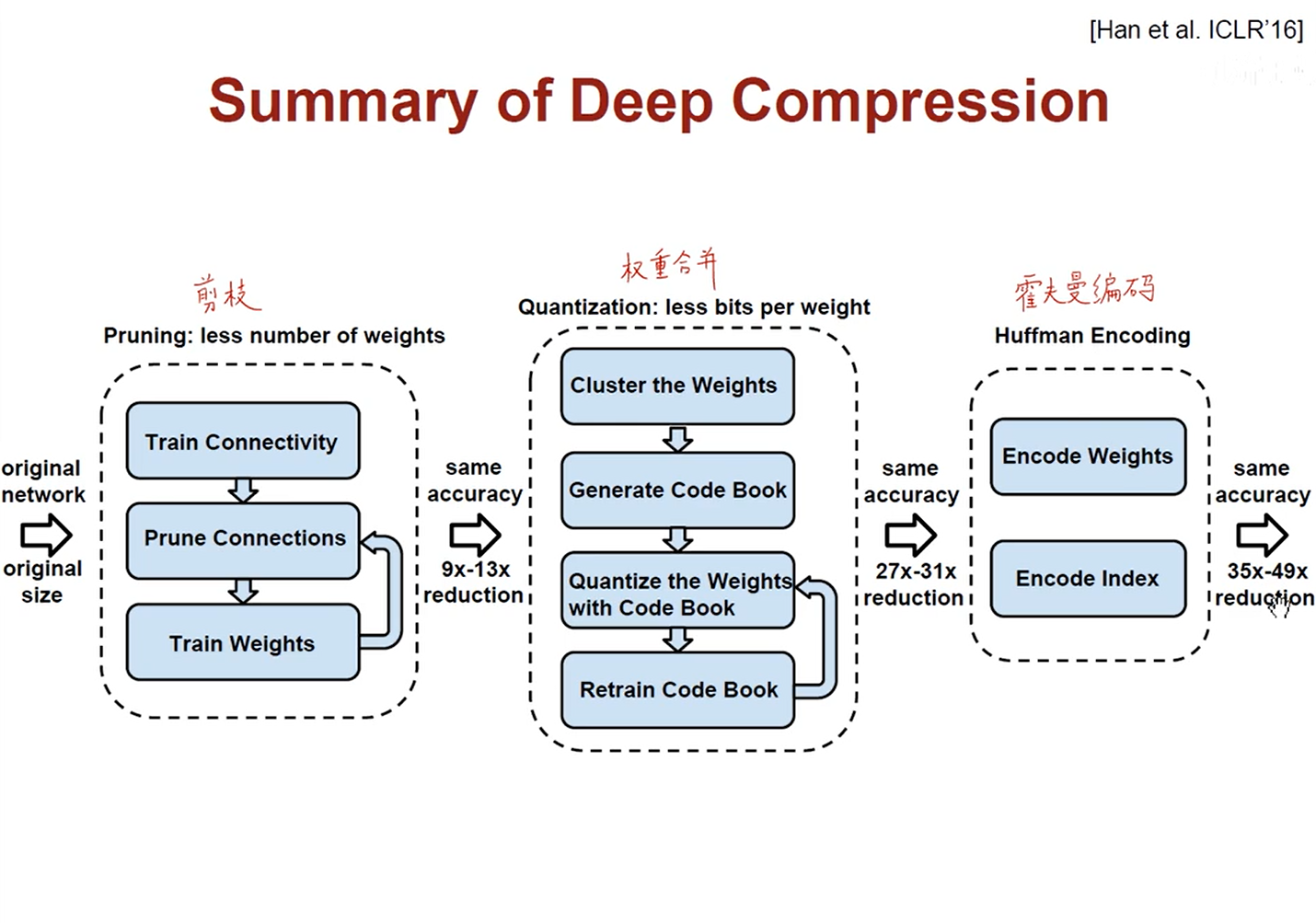
– 加速推断的算法

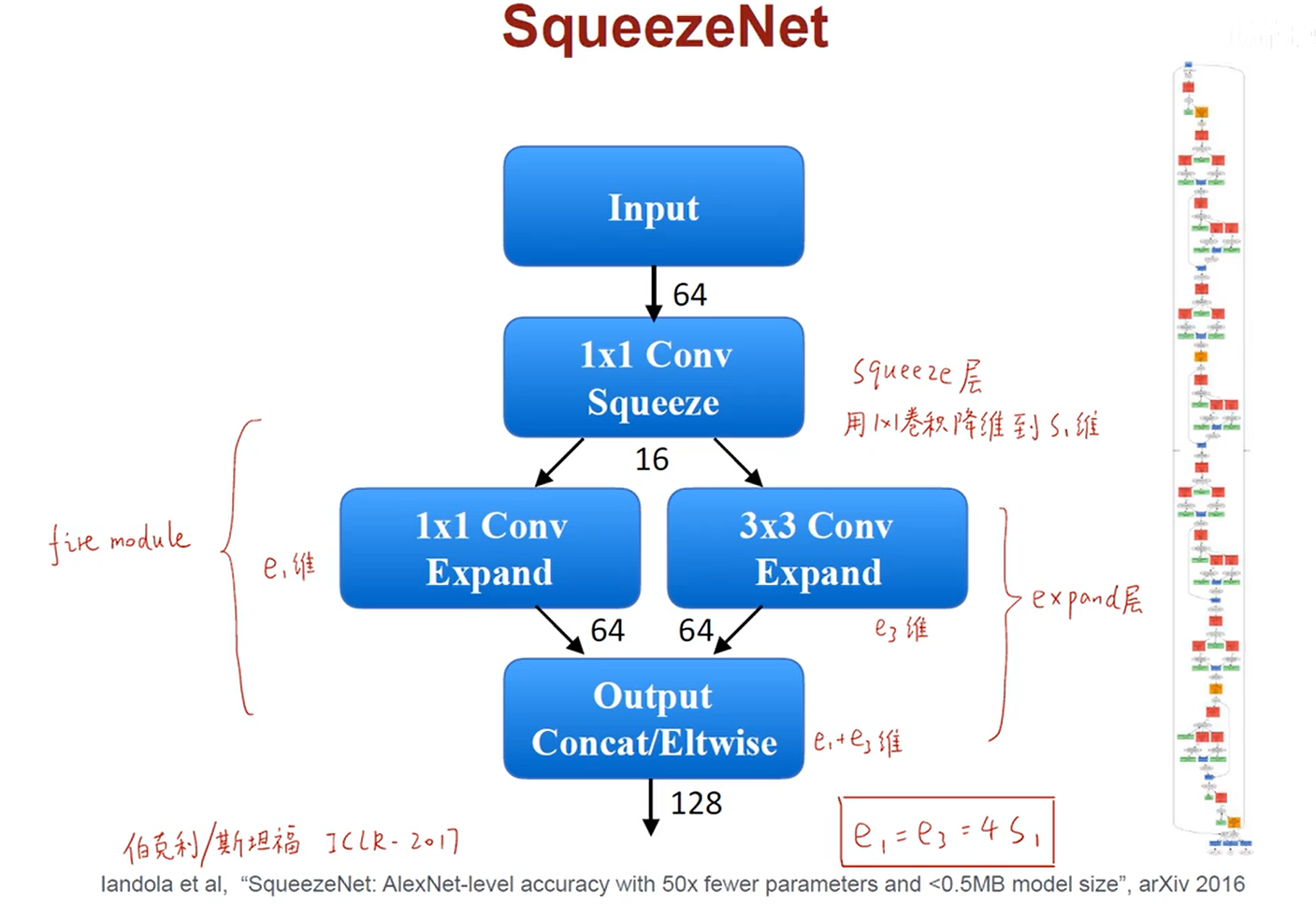
– SqueezenNet
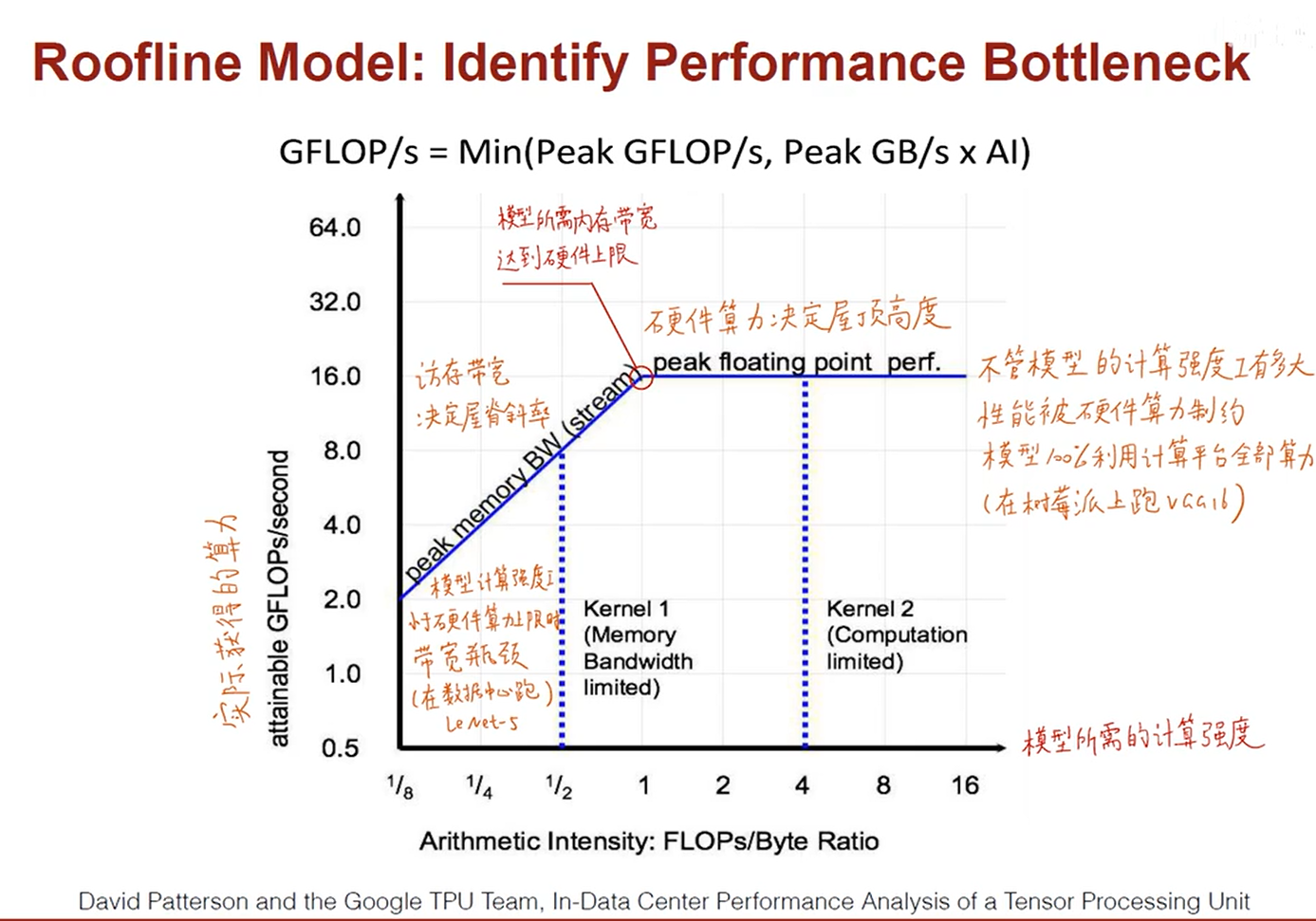

- 深度学习软件编程框架
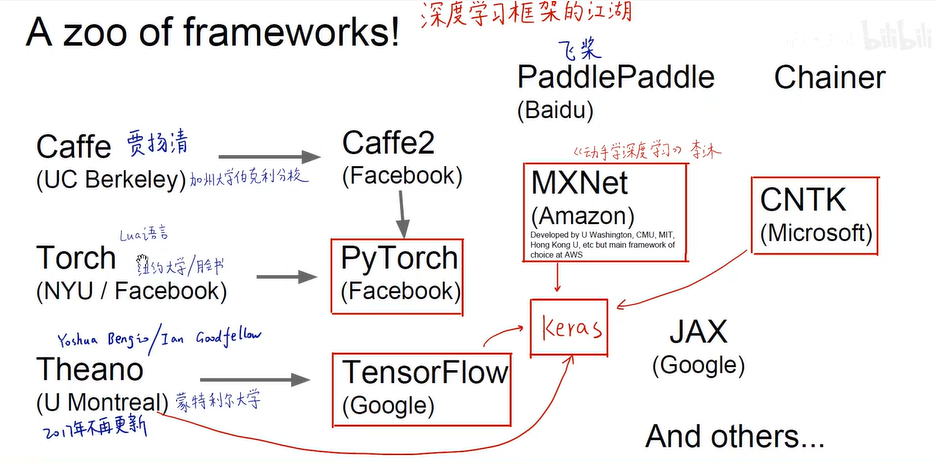
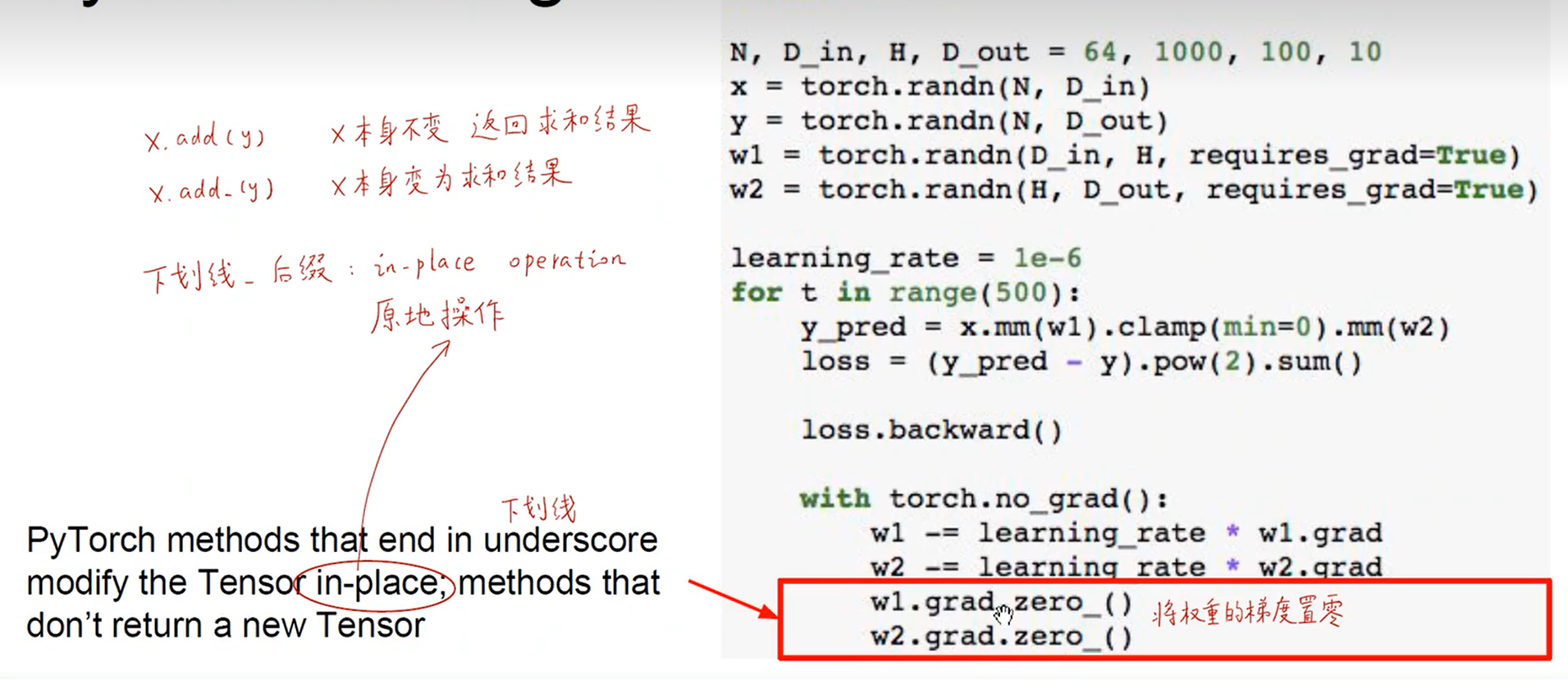
- Pytorch

- 加下划线参数本身会被重置为0,否则只是输出返回0
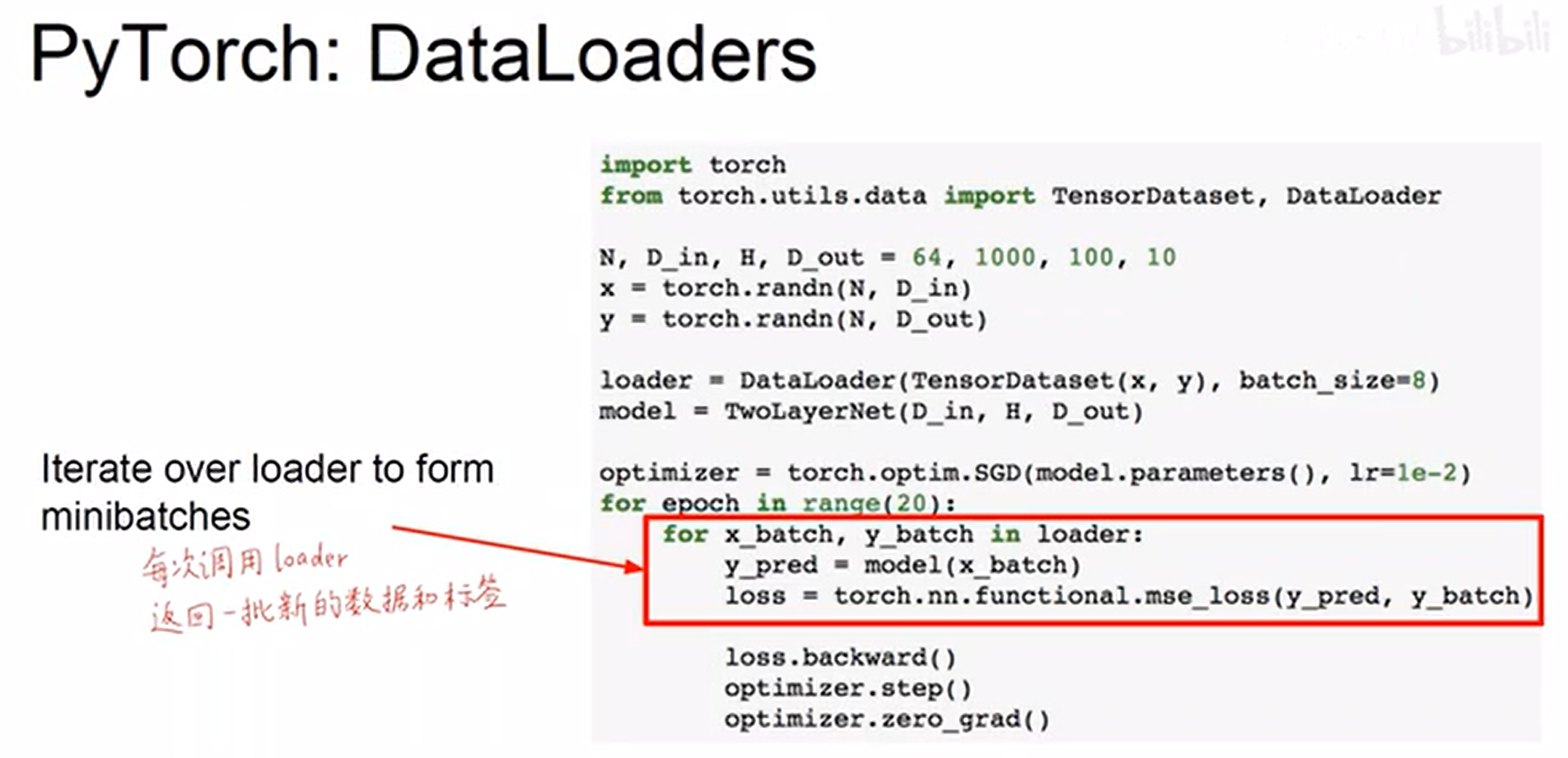
Dataloader:
预训练模型:

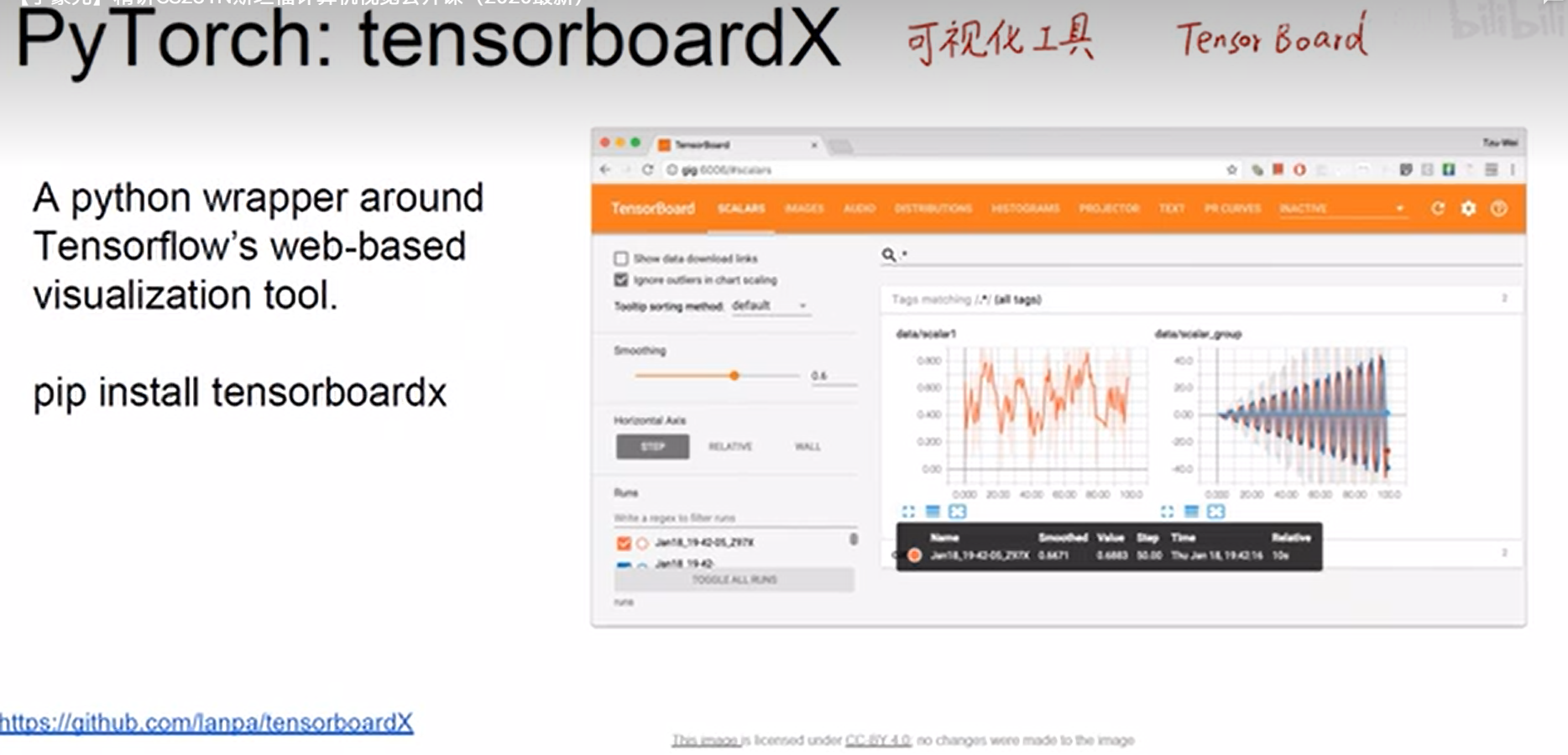
可视化工具:

构建动态计算图:

other:静态图

- TensorFlow

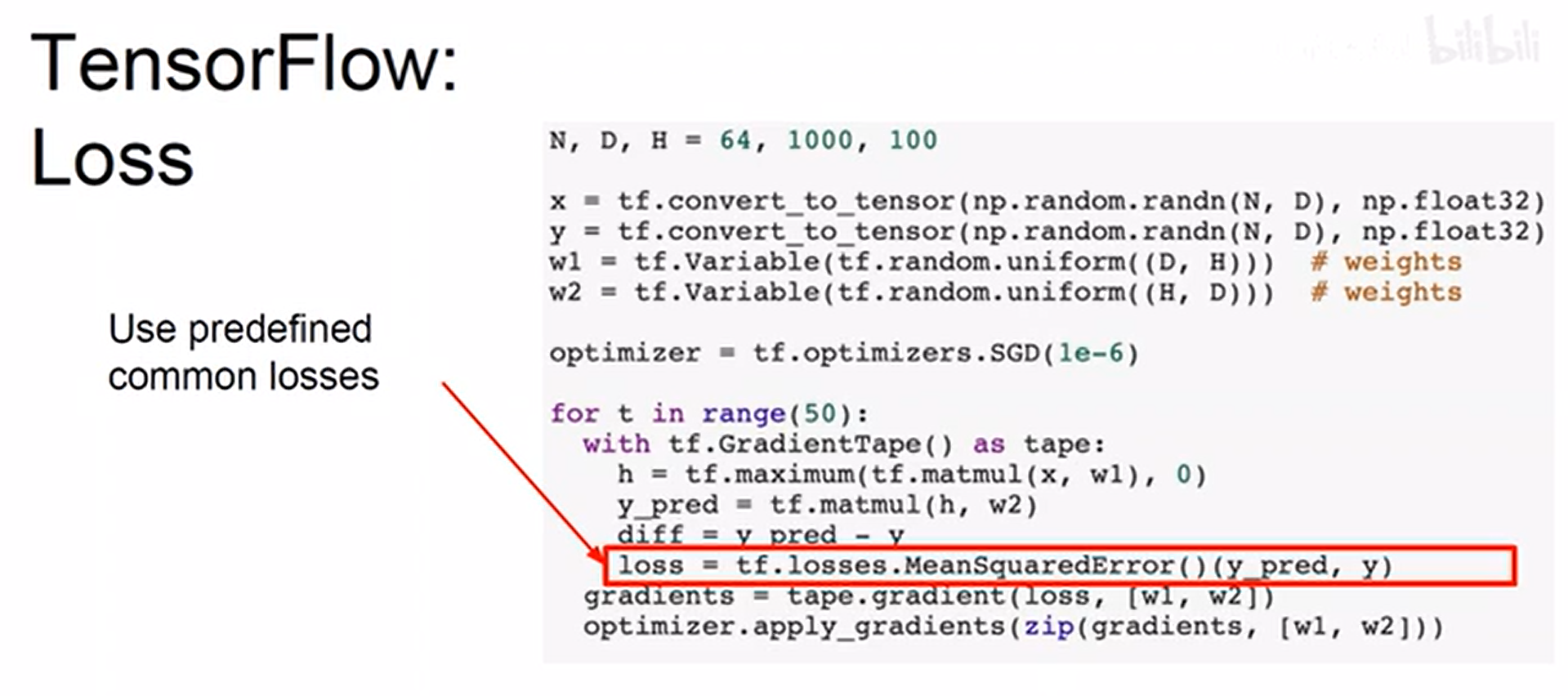
- Keras (对小白用户最友好,简单易上手)

- 建议

- 循环神经网络
目前已经学习过两大类神经网络:全连接神经网络,卷积神经网络 (视频)
马上学习:RNN(处理序列数据)

RNN时间维度全局共享,CNN空间维度的全局共享
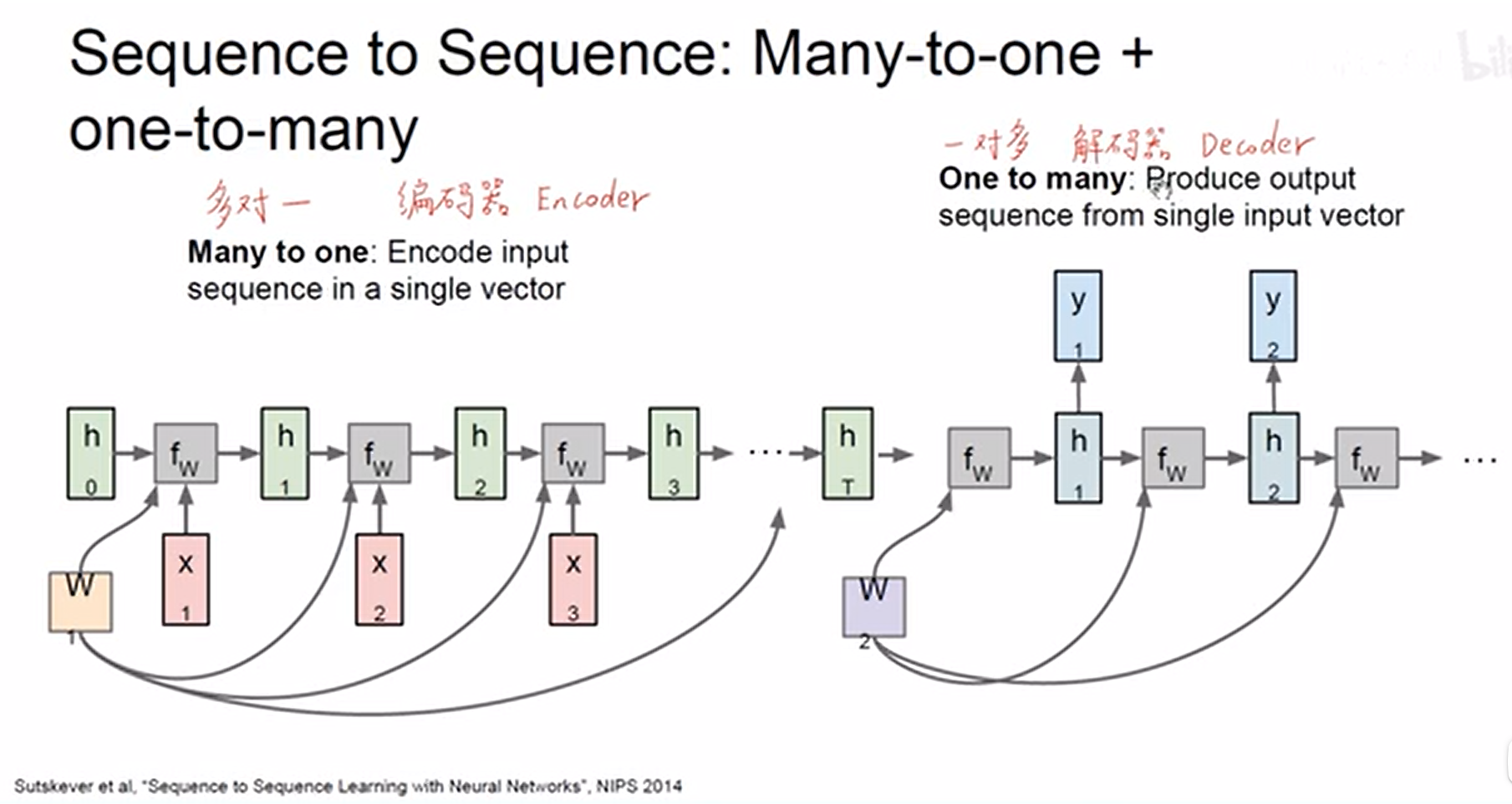
– 编码器 & 解码器
– RNN梯度消失与梯度爆炸
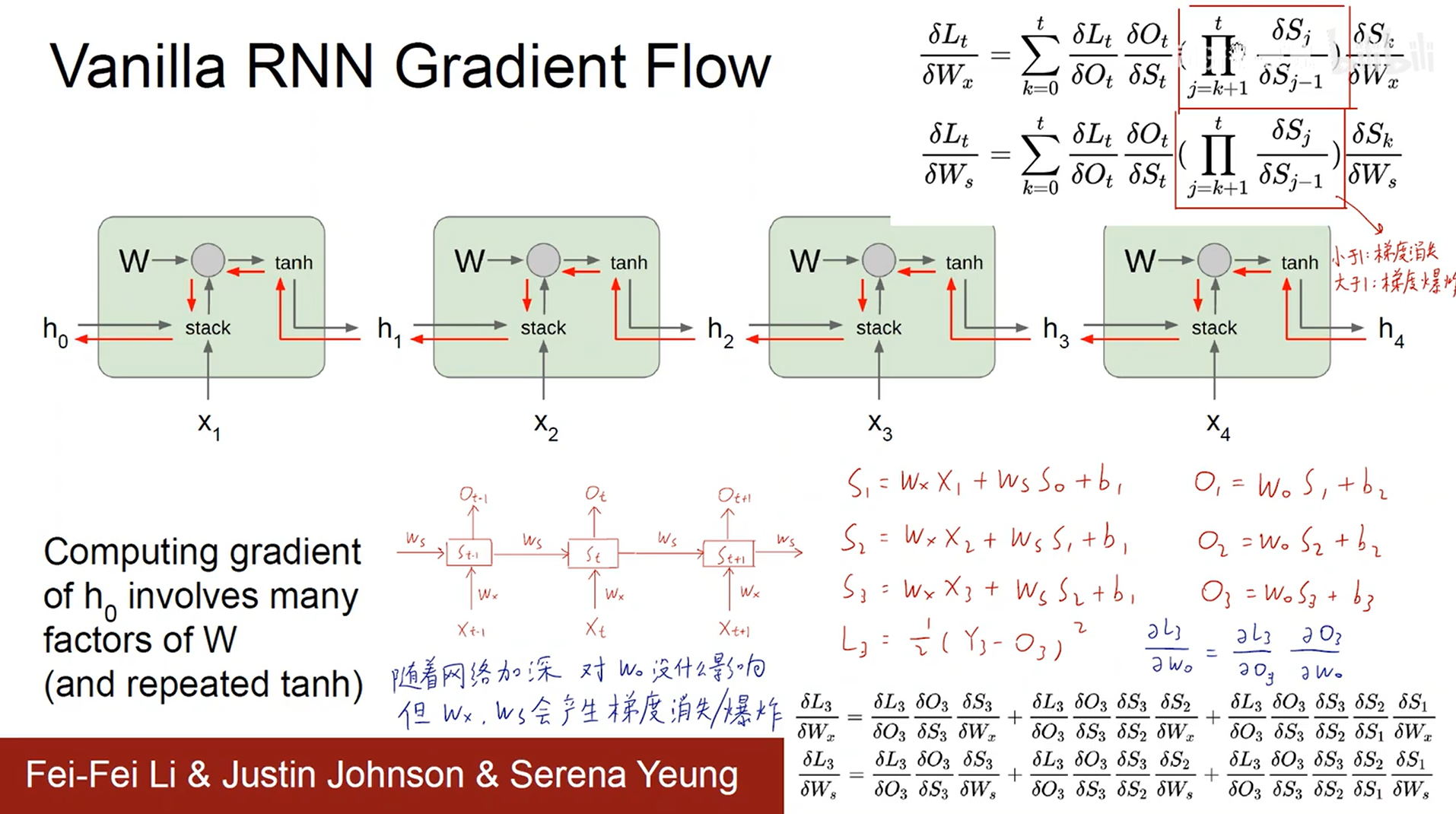
训练时间越长,越有可能出现。
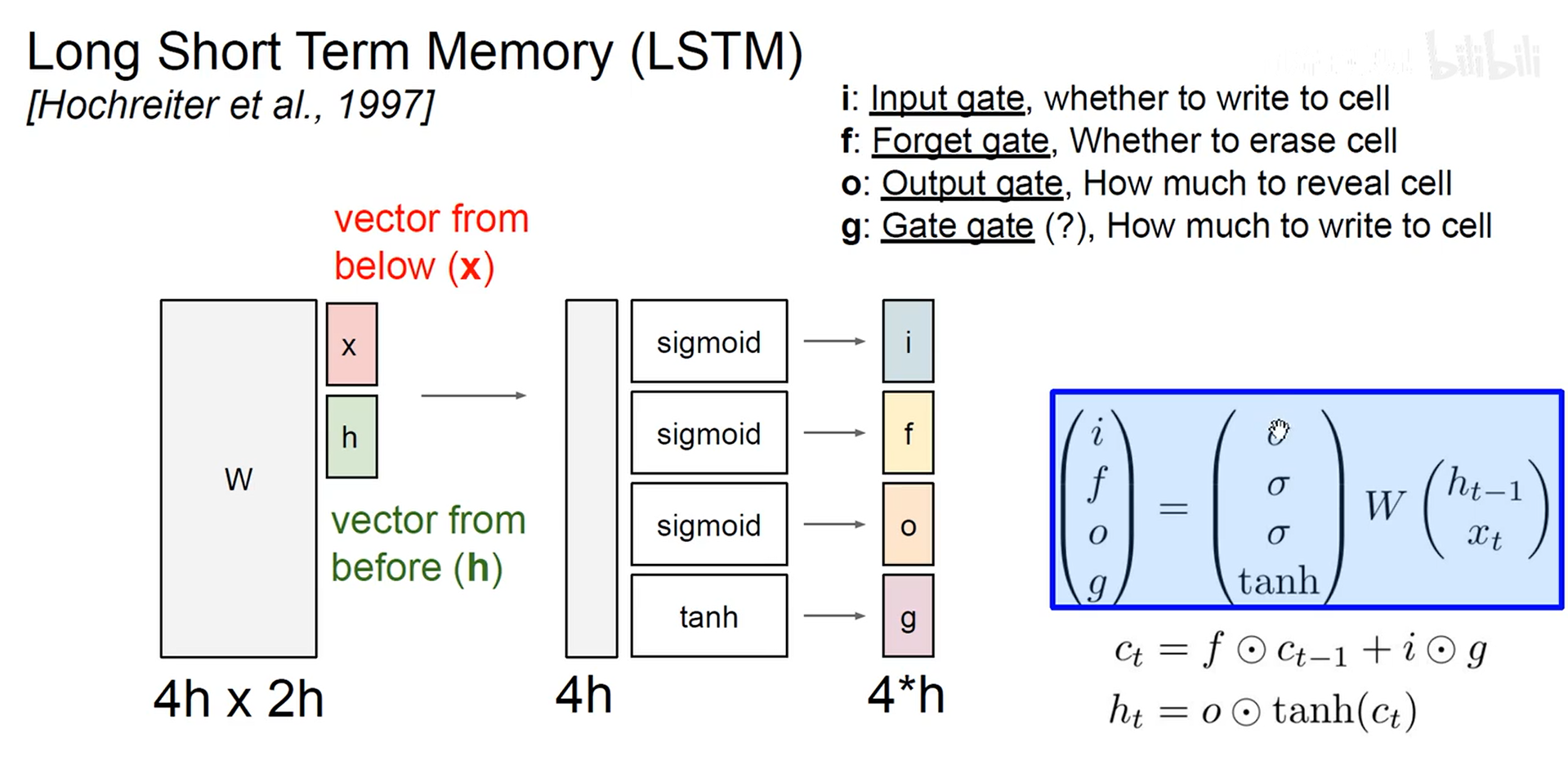
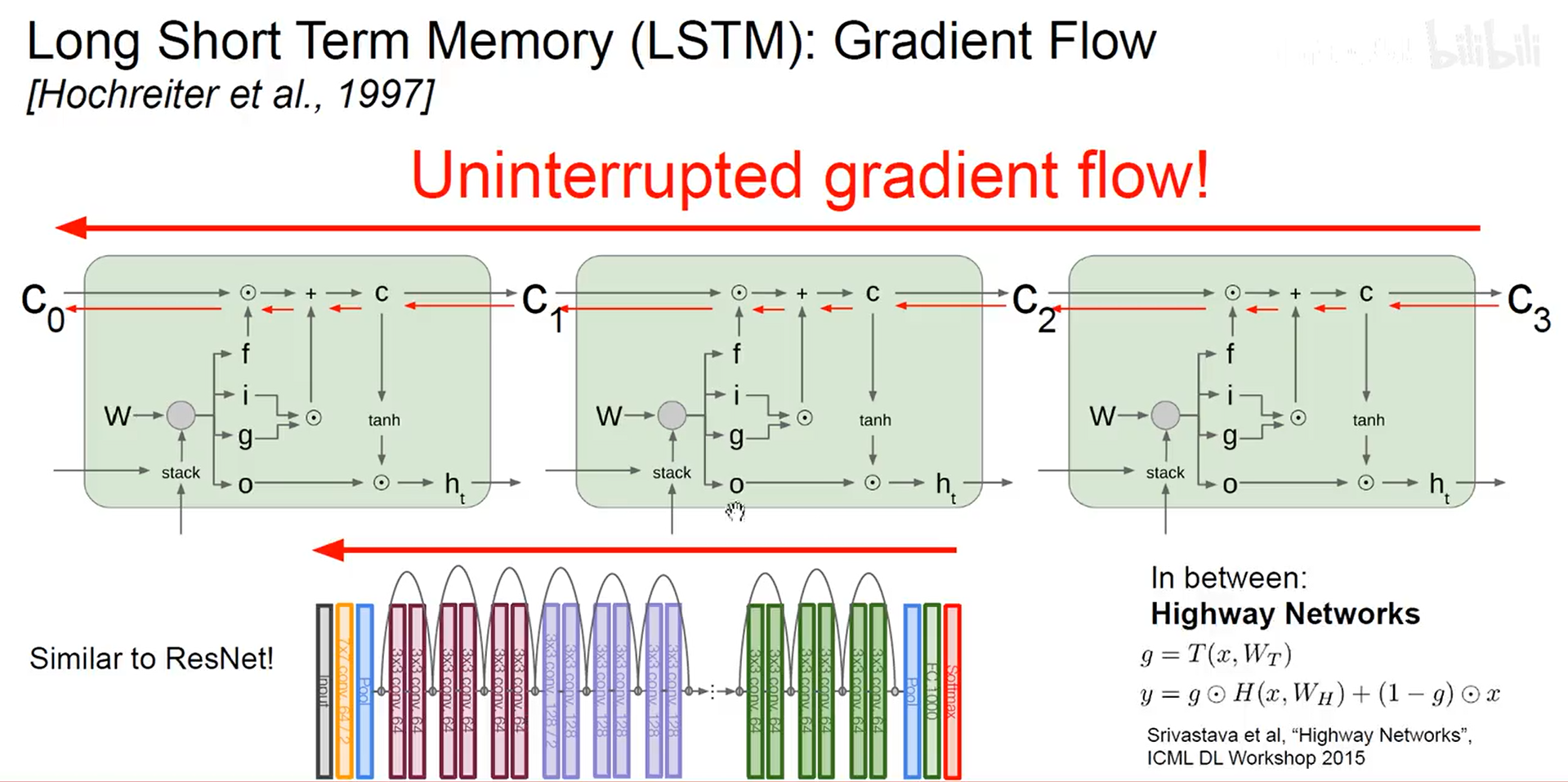
- LSTM
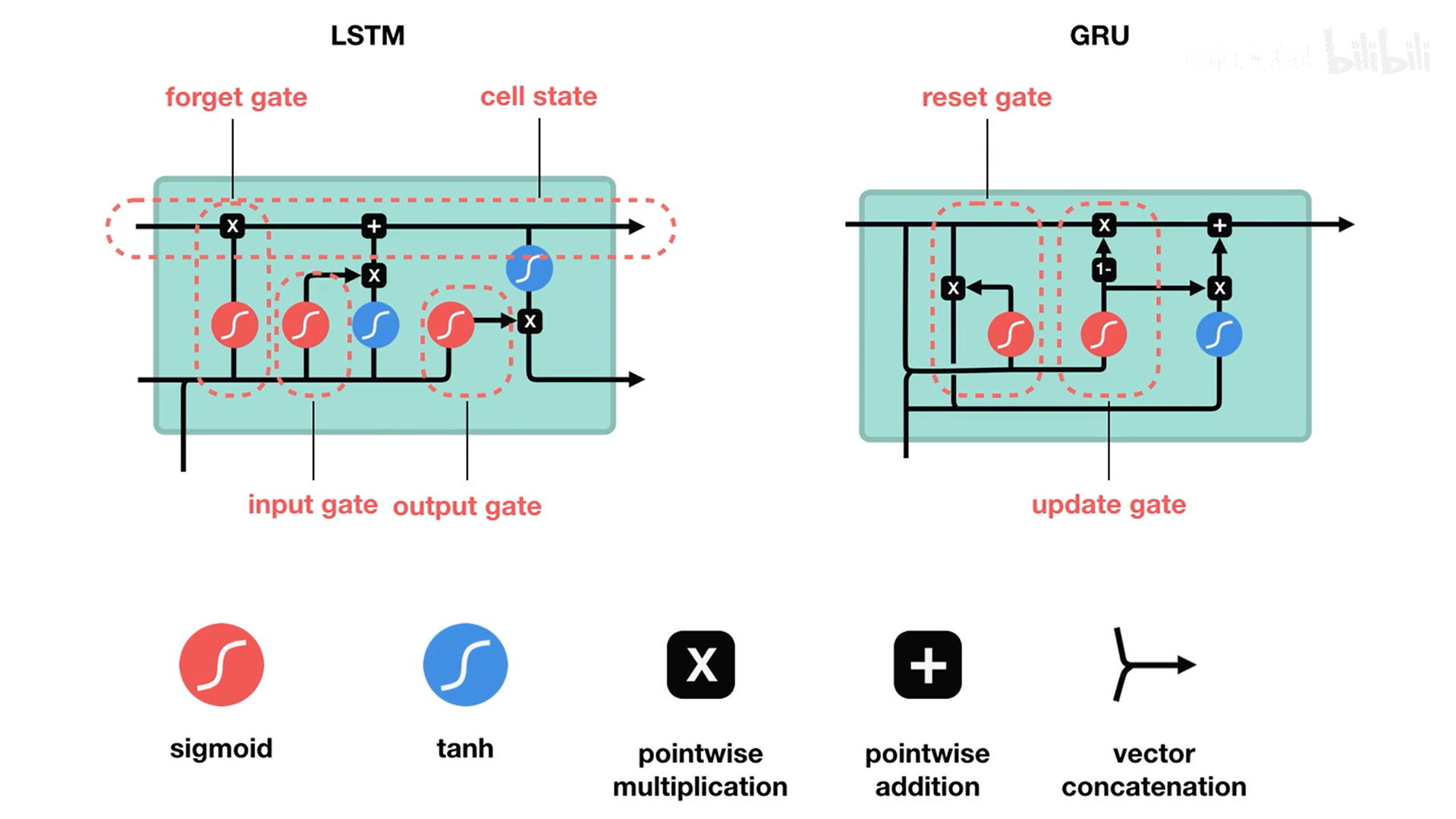
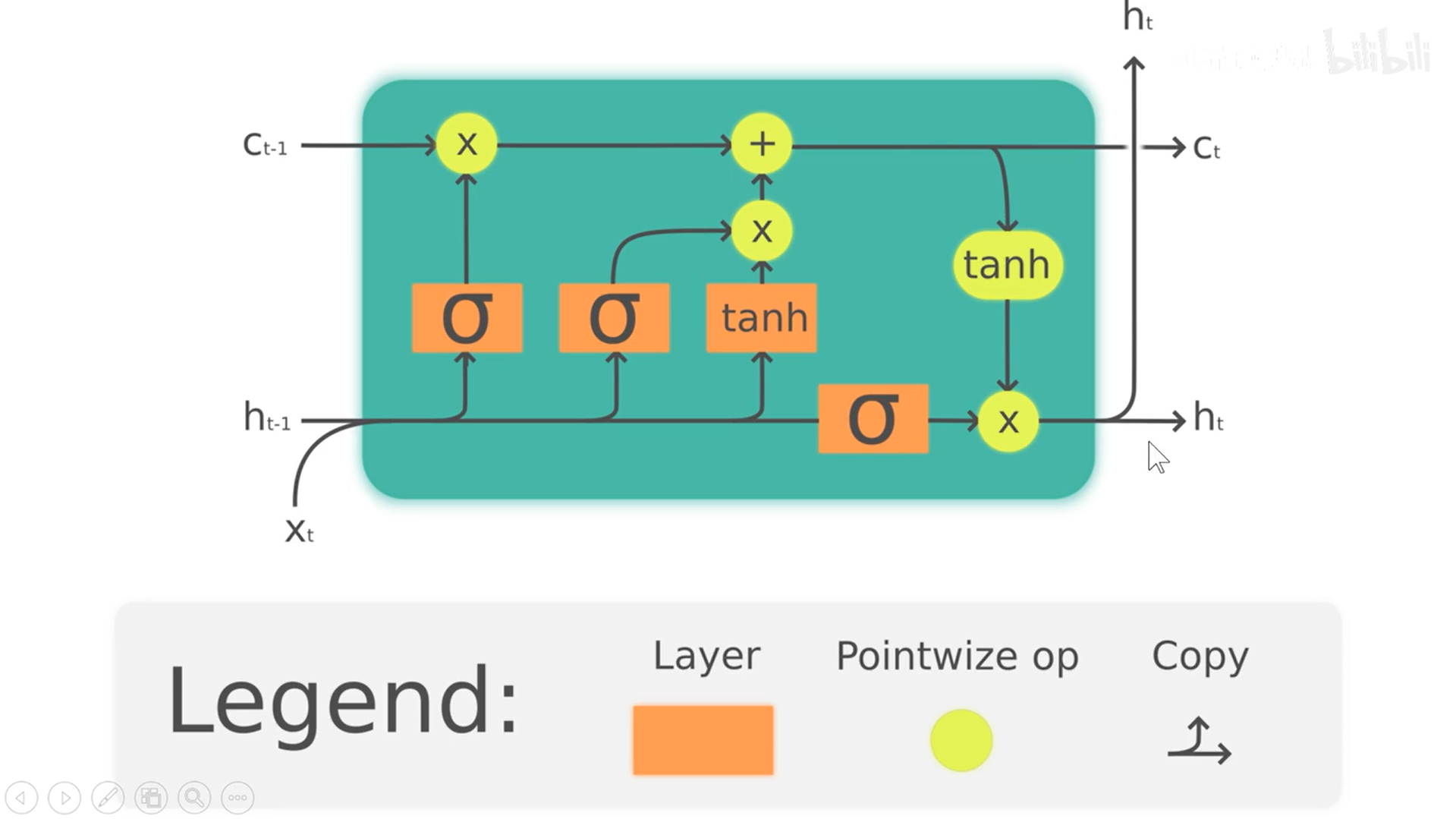
C t C_t Ct为长期记忆,贯穿时间轴,与神经元内部的交互信息较少
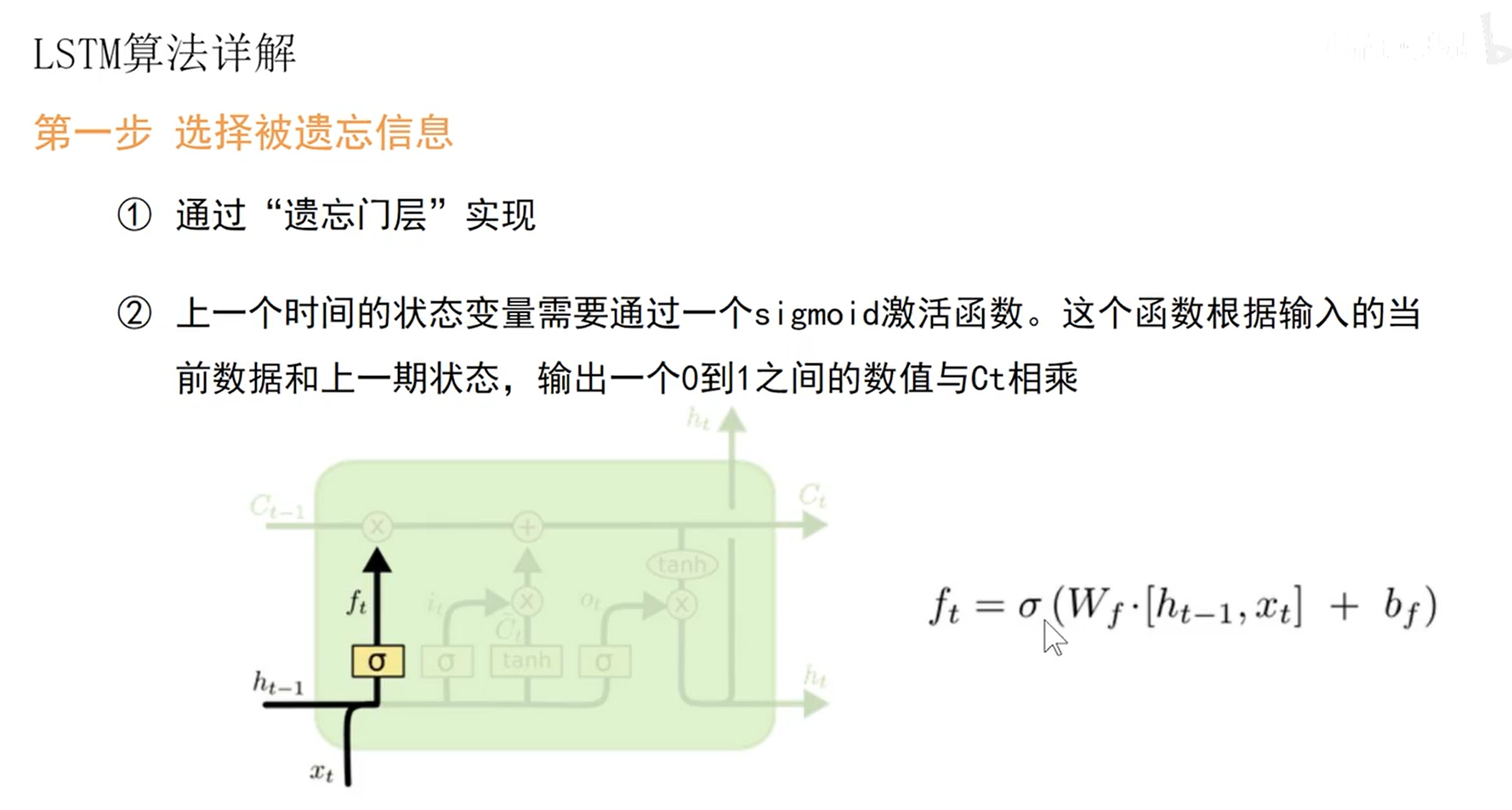
- 选择被遗忘的信息
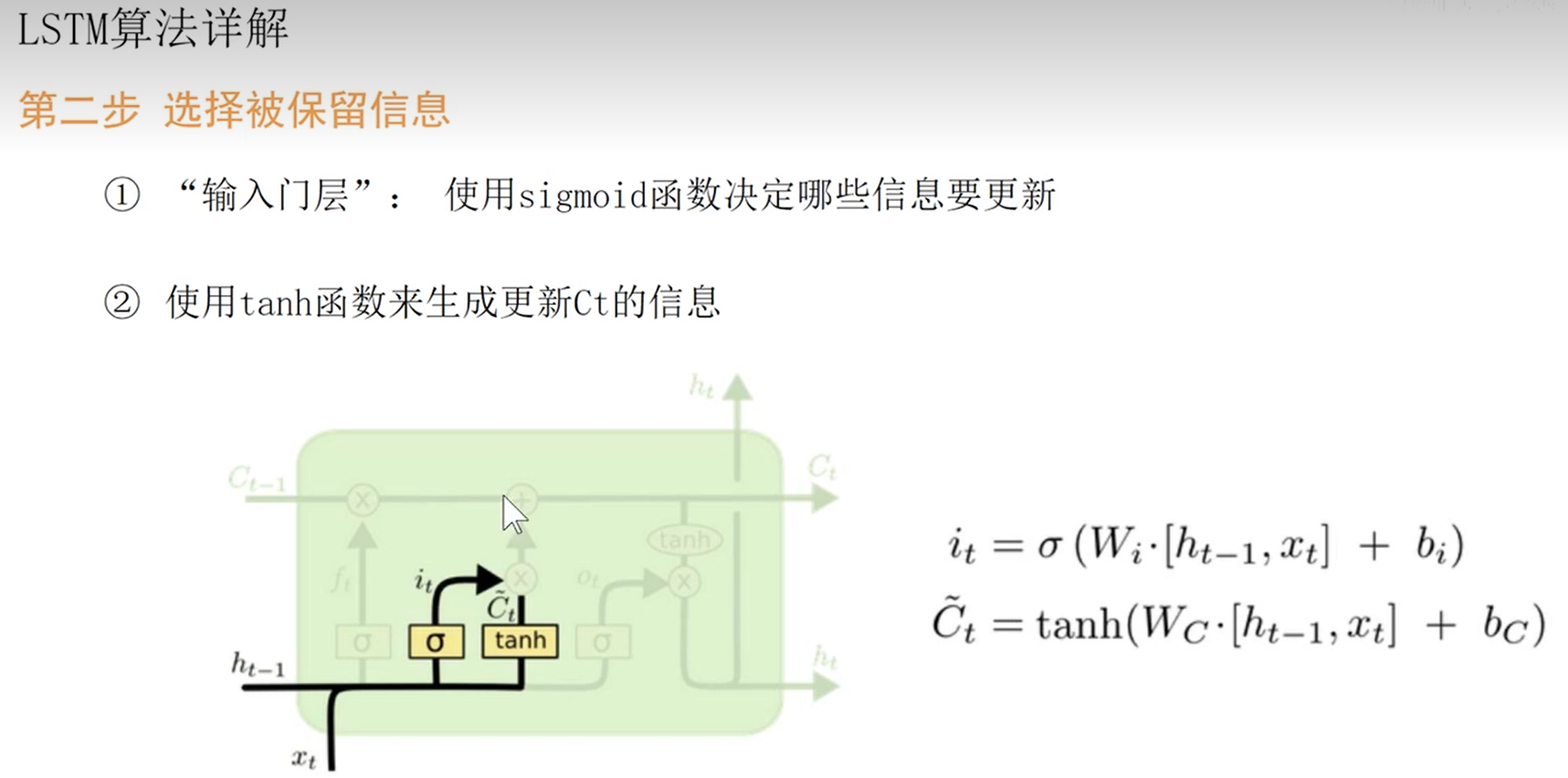
- 选择被保留的信息
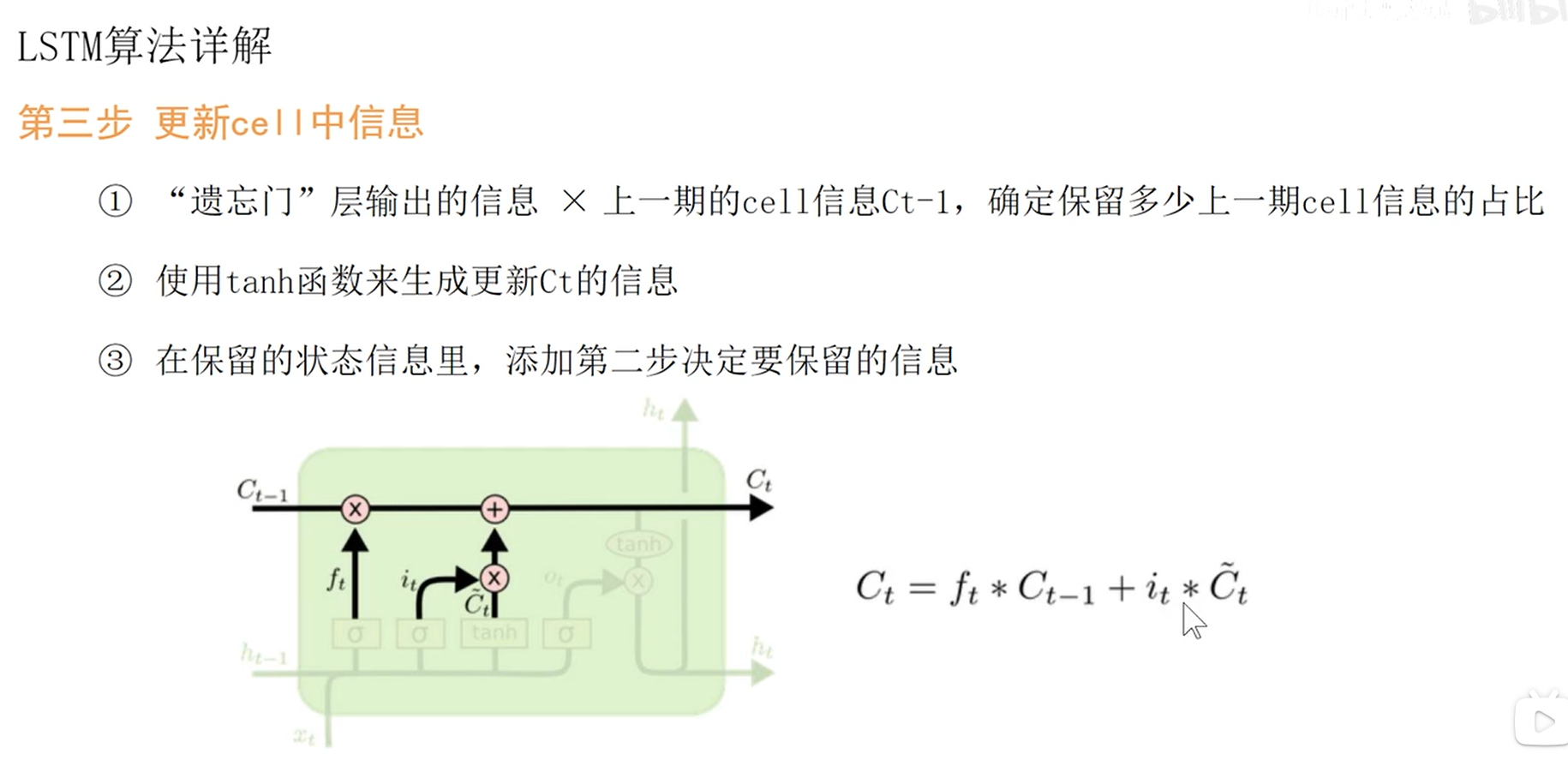
- 更新CELL中的信息
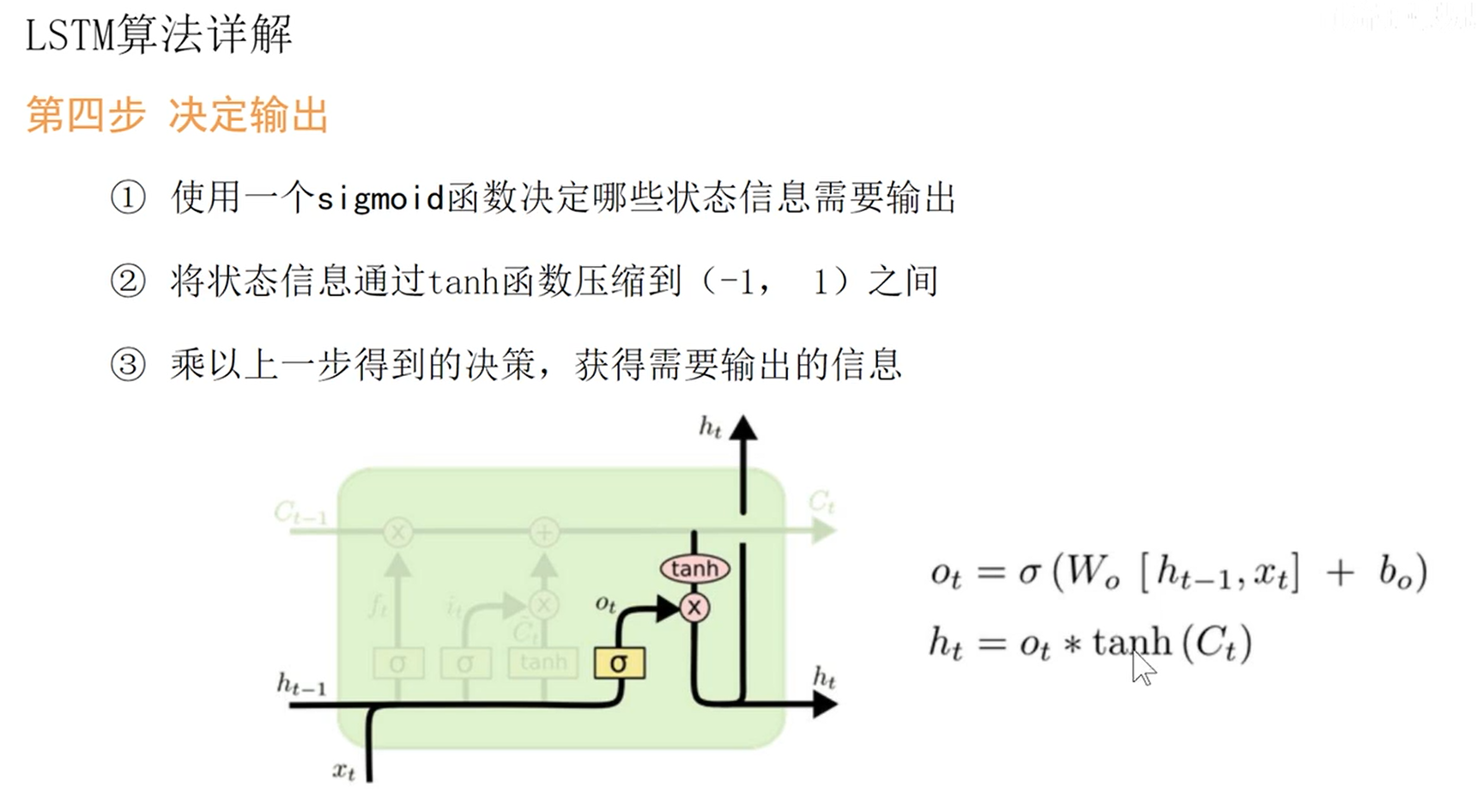
- 短期记忆为每个小模型的输出
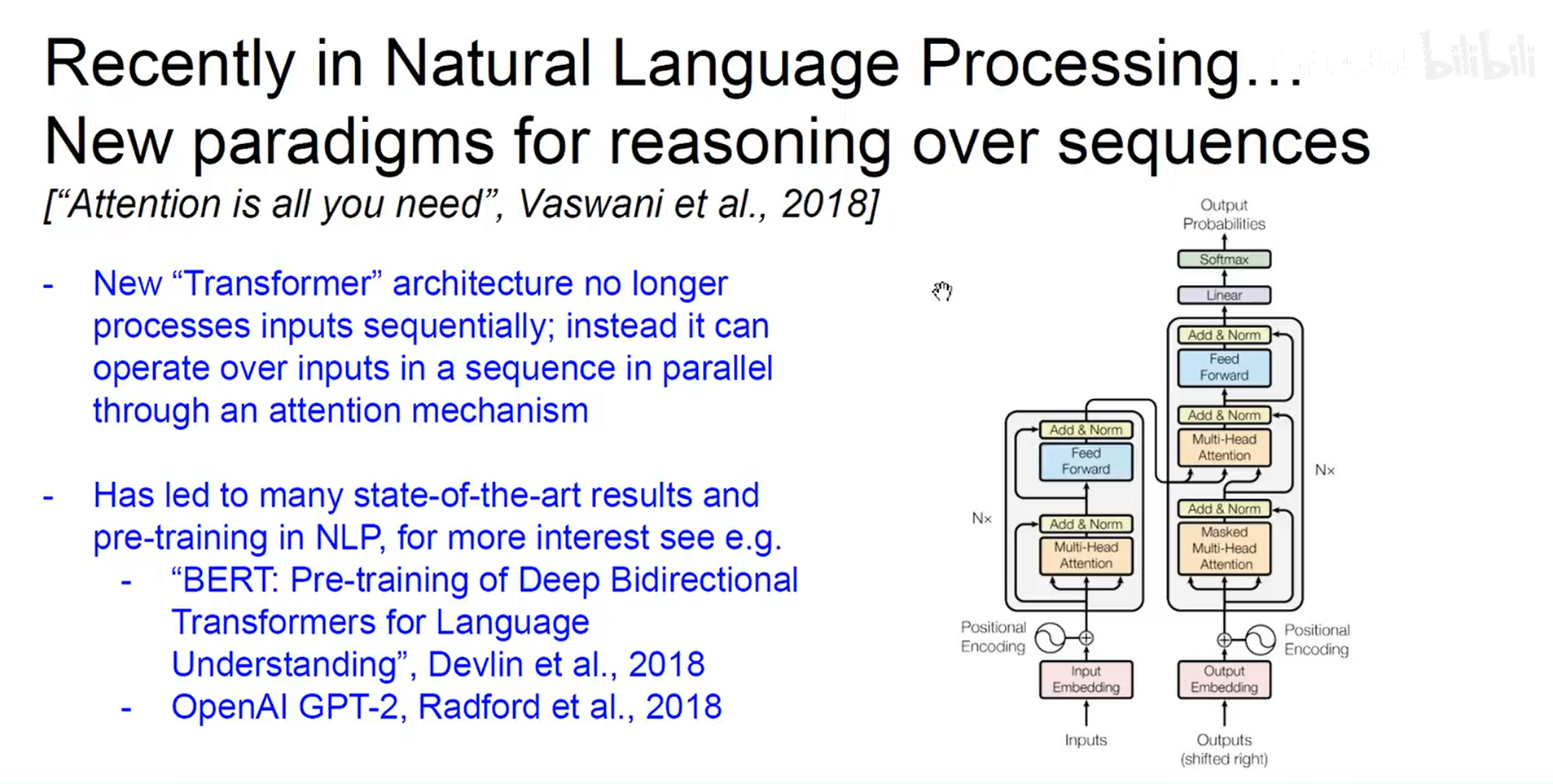
-Transformer

- 总结

*感谢子豪大佬的精彩视频讲解❀