视频网址
仅仅是笔记记录,若有错误请指出。
零碎的
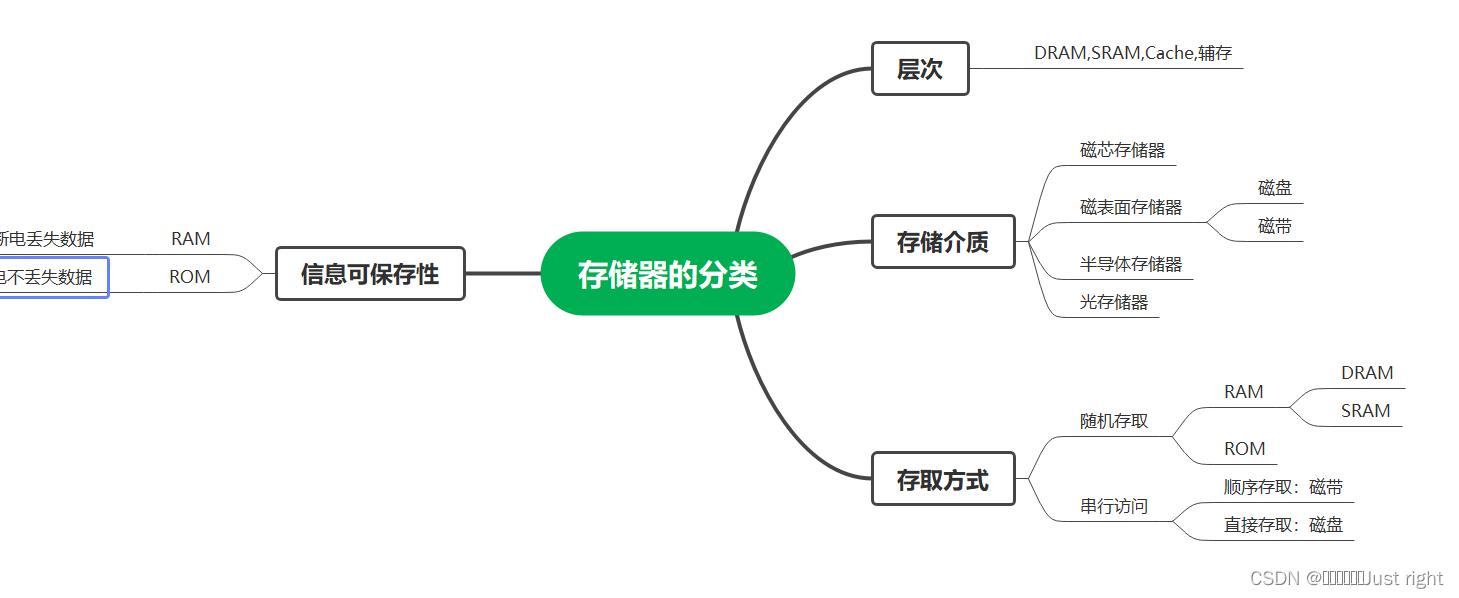
存储器的分类
- 磁表面存储器:磁盘,磁带
- 磁芯存储器
- 半导体存储器 RAM ROM
- 光存储器
看下面这个思维导图
存储器的性能指标
- 存储容量:存储字数×字长
- 单位成本: 每位价格=总成本/总容量
- 存储速度:数据传输率=数据的宽度/存储周期
- 存取时间Ta:启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间
- 存取周期Tm:连续两次独立得访问存储器操作(读或写)之间所需得最小时间间隔
- 主存带宽Bm:数据传输率,表示每秒从主存进出信息得最大数量,单位字/秒 字节/秒(B/s)或位/秒(b/s)
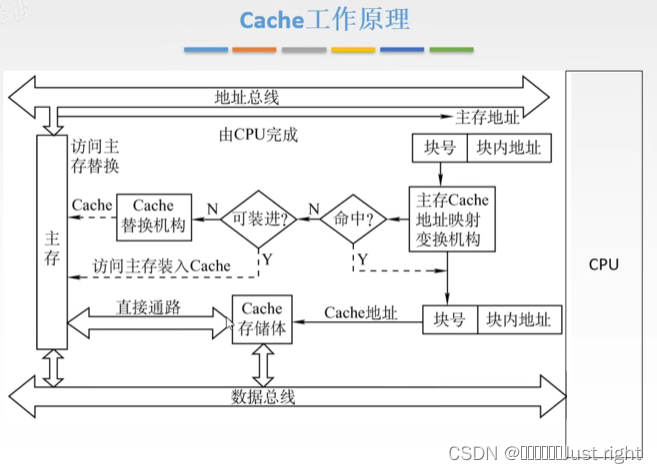
存储器与CPU的协同工作
存储器的简单模型及寻址的概念
存储器芯片的基本结构

- 译码驱动电路:将地址总线的地址信号翻译乘对应存储单元的选通信号
- 存储矩阵:由大量相同的位存储单元阵列构成
- 读写电路:用来完成读/写操作。包括读出放大器和写入电路
- 地址线:单向输入,其根数与存储字的个数有关
- 数据线:双向的,其根数与读出或写入的数据位数有关
- 片选线:控制哪个存储芯片被选中
数据线数和地址线数共同反映存储芯片容量的大小
如:地址线11根,数据线8根,则芯片容量=211×8=16KB
寻址
按字节、字、半字、双字寻址,个人理解就是对内存以字节、字、半字、双字进行分割
内存储器的容量位1KB,字长为4B,
按字节寻址:210B/1B=210=1K,也就是1K个存储单元
按字寻址:210B/22B=28,也就是256个存储单元
按半字寻址:210B/21B=29,也就是512个存储的那元
按双字寻址:210B/23B=27,也就是128个存储单元
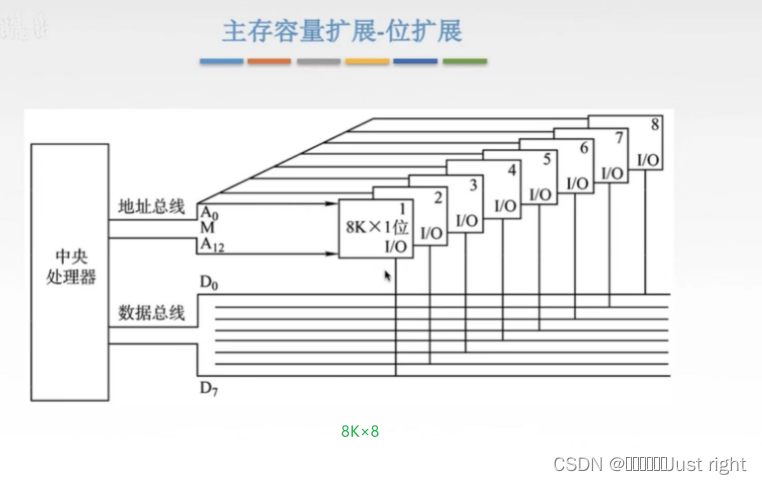
主存与CPU的连接
位扩展
字扩展
- 线选法
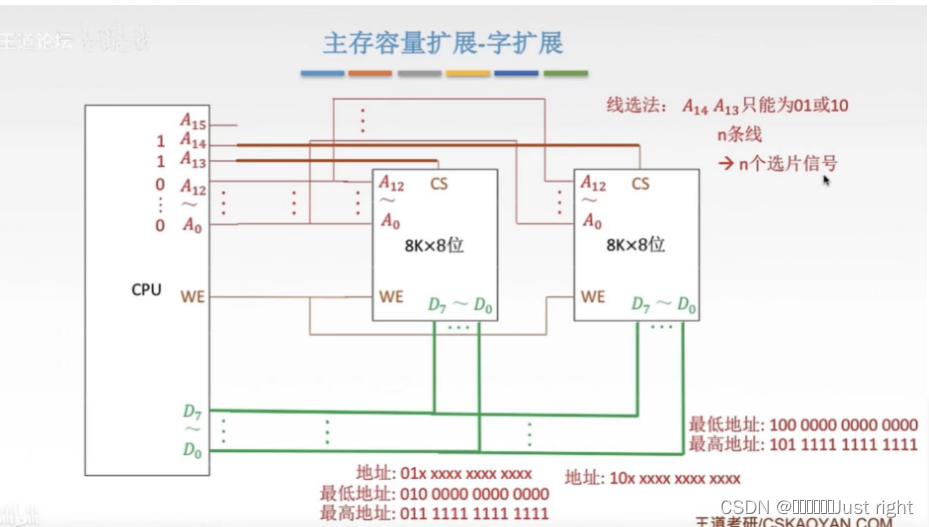
- 译码片选法

插曲:译码器:就是74LS138之类的译码器

- 使用译码器对主存容量进行字扩展
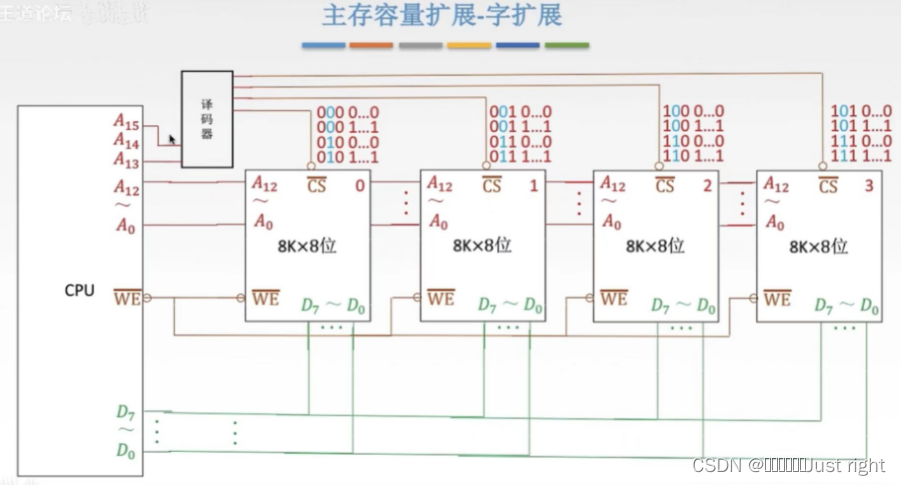
字位同时扩展
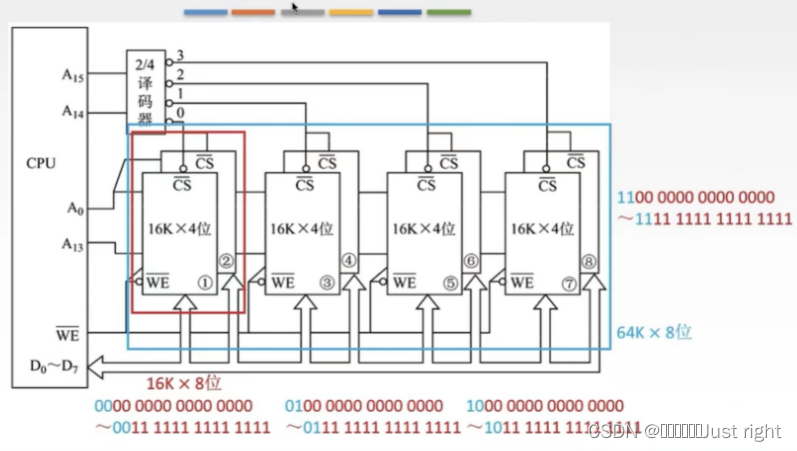
总结:

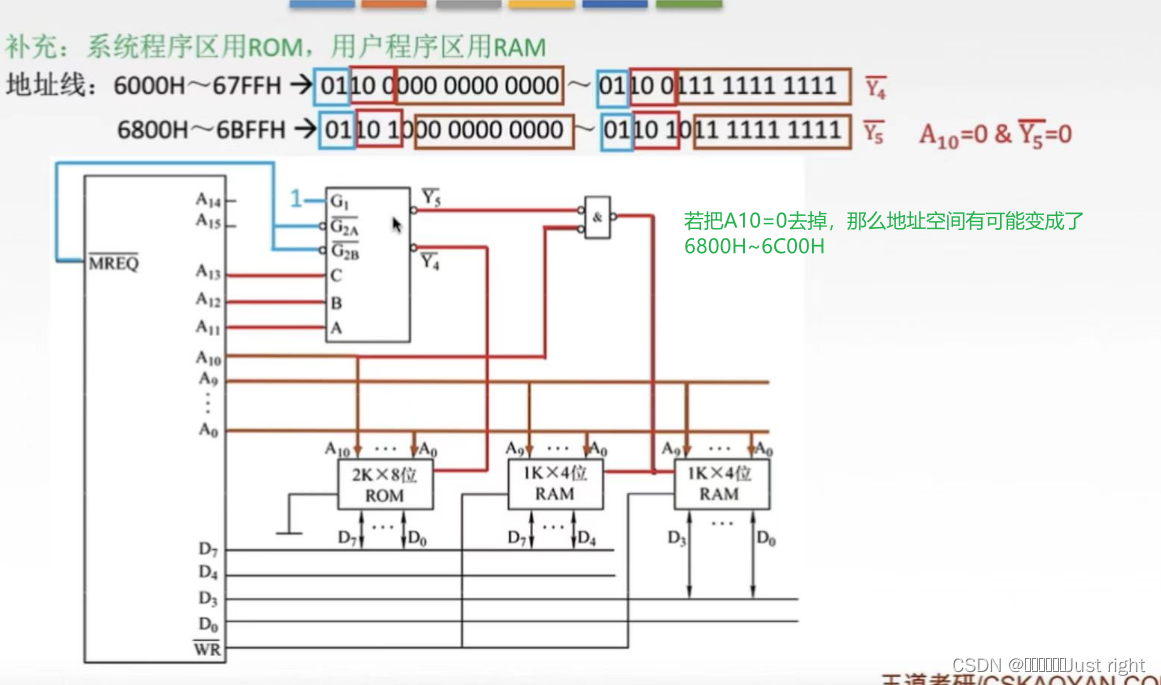
小练习

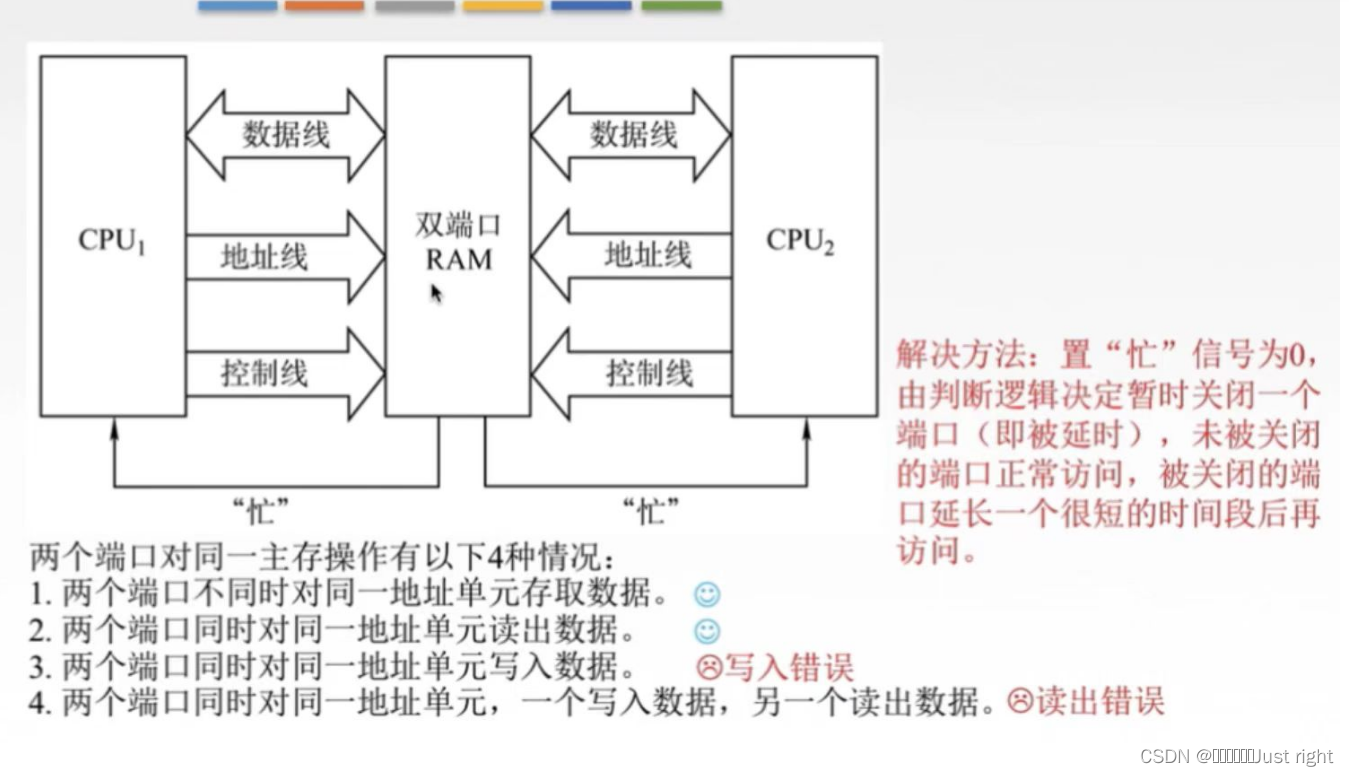
双口RAM和多模块存储器
- 双口RAM
- 多模块存储器
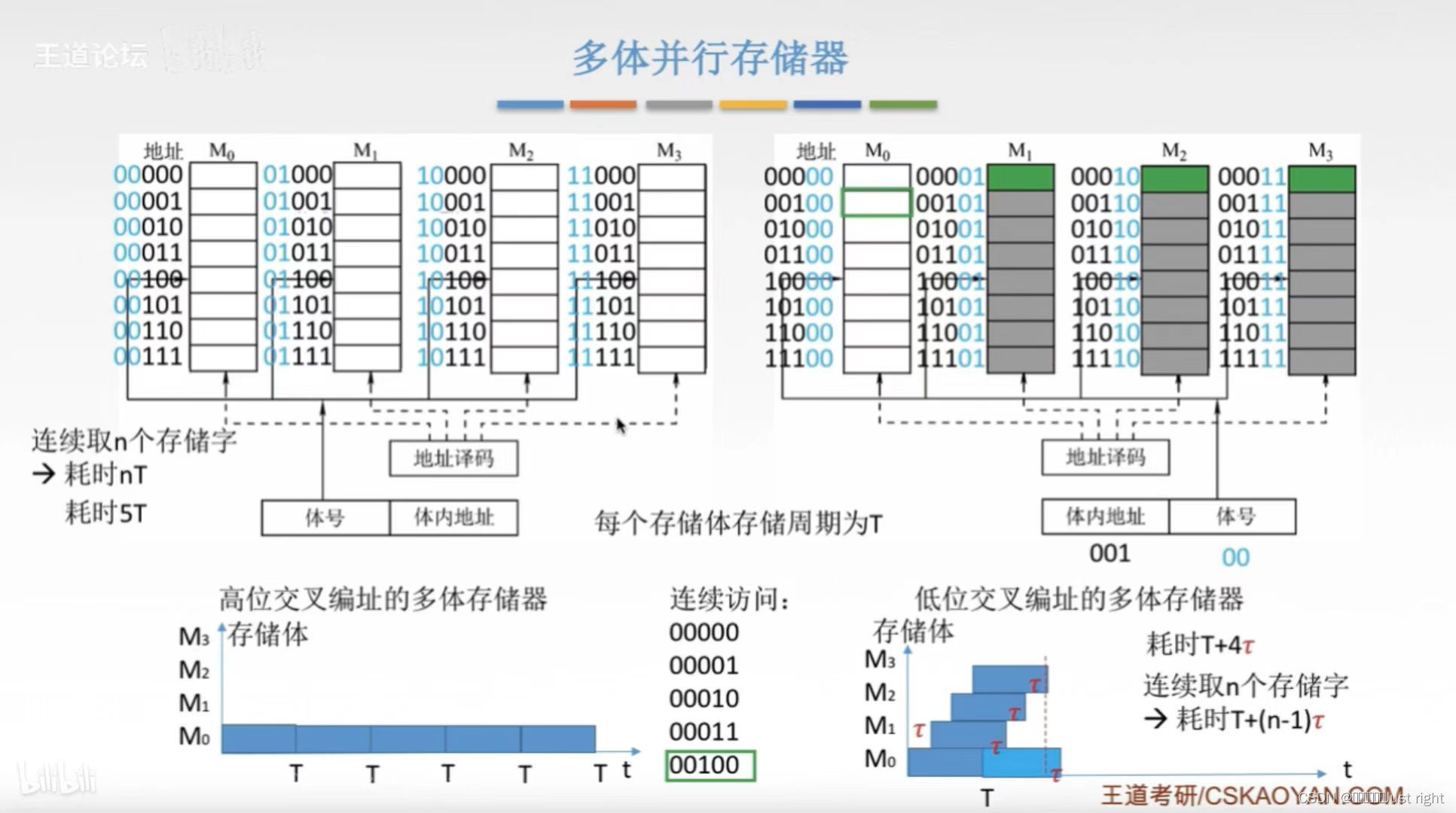
低位交叉编址:存取时间+恢复时间=一个周期,在恢复时间中可以访问下一个存储单元,高位交叉编址的恢复时间没有利用起来
计算题:
模块数m=4,存储周期为T,字长为W,数据总线宽度为W,总线传输周期为r,连续存取n个字,求交叉存储器的带宽
就是有m个存储体,存储周期为T,字长为W,每个r时间启动下一个存储体,连续存取n个字,求存储器的存取速率
连续存取n个字耗时=T+(n-1)r
带宽=(nw)/(T+(n-1)r)
低位交叉编址可以并行工作,如总线宽度为mW时,可以同时取出长度为mW的数据
高速缓冲存储器
局部性原理
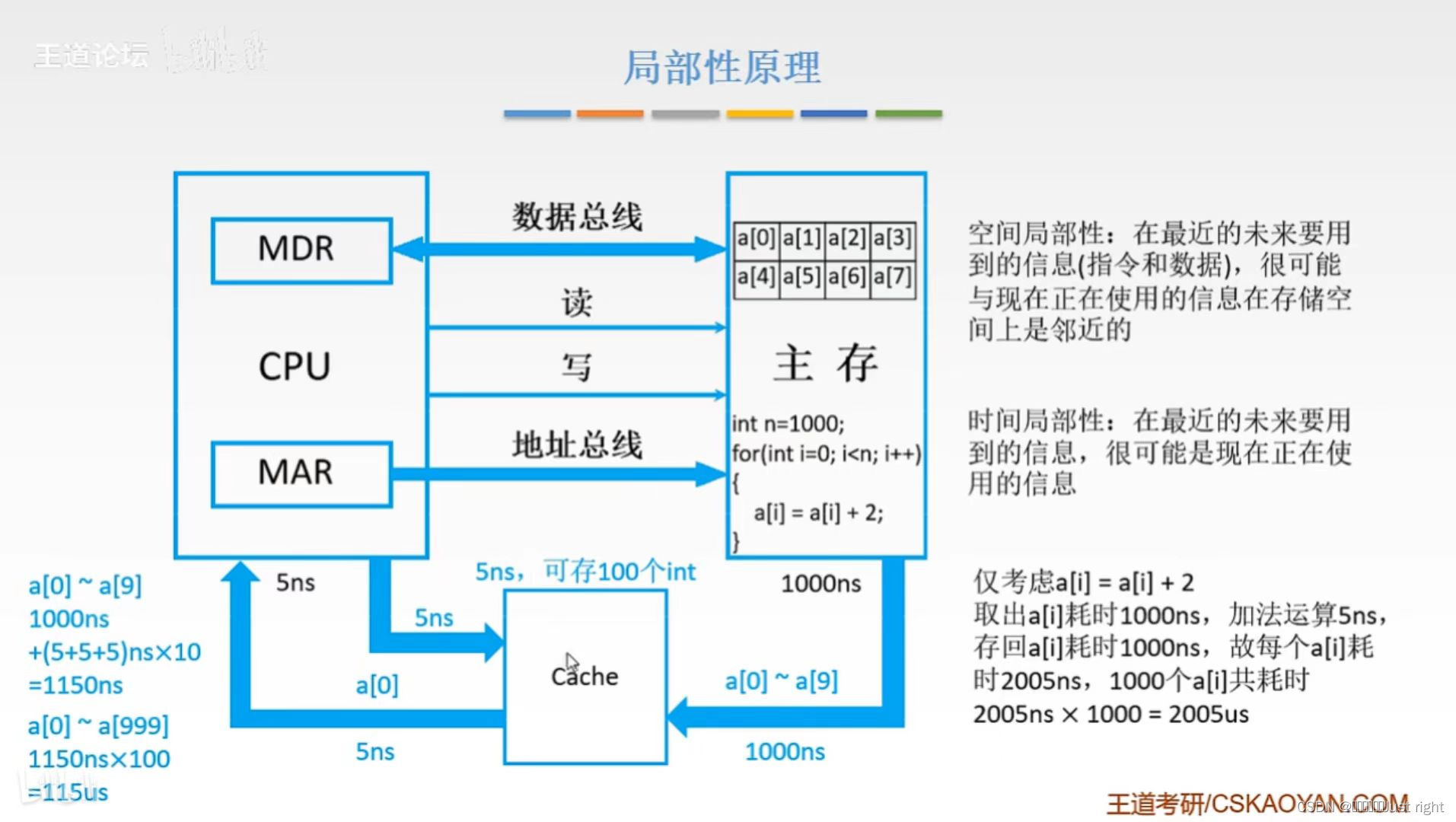
3个5ns怎么来的,a[0]->CPU 5ns,CPU进行加法运算 5 ns,存回原存储单元 5ns,这是数组的一个元素所耗时,一共有10个,所以要×10
命中率H:CPU欲访问的信息已在Cache中的比率.设一个程序执行期间,Cache的总命中次数为Nc,访问内存的总次数为Nm,则H=Nc/(Nc+Nm),缺失率 M =1-H.
设Tc为命中时的Cache访问时间,Tm为未命中时的访问时间,那么Cache—主存系统的平均访问时间Ta=Htc+(1-H)tm
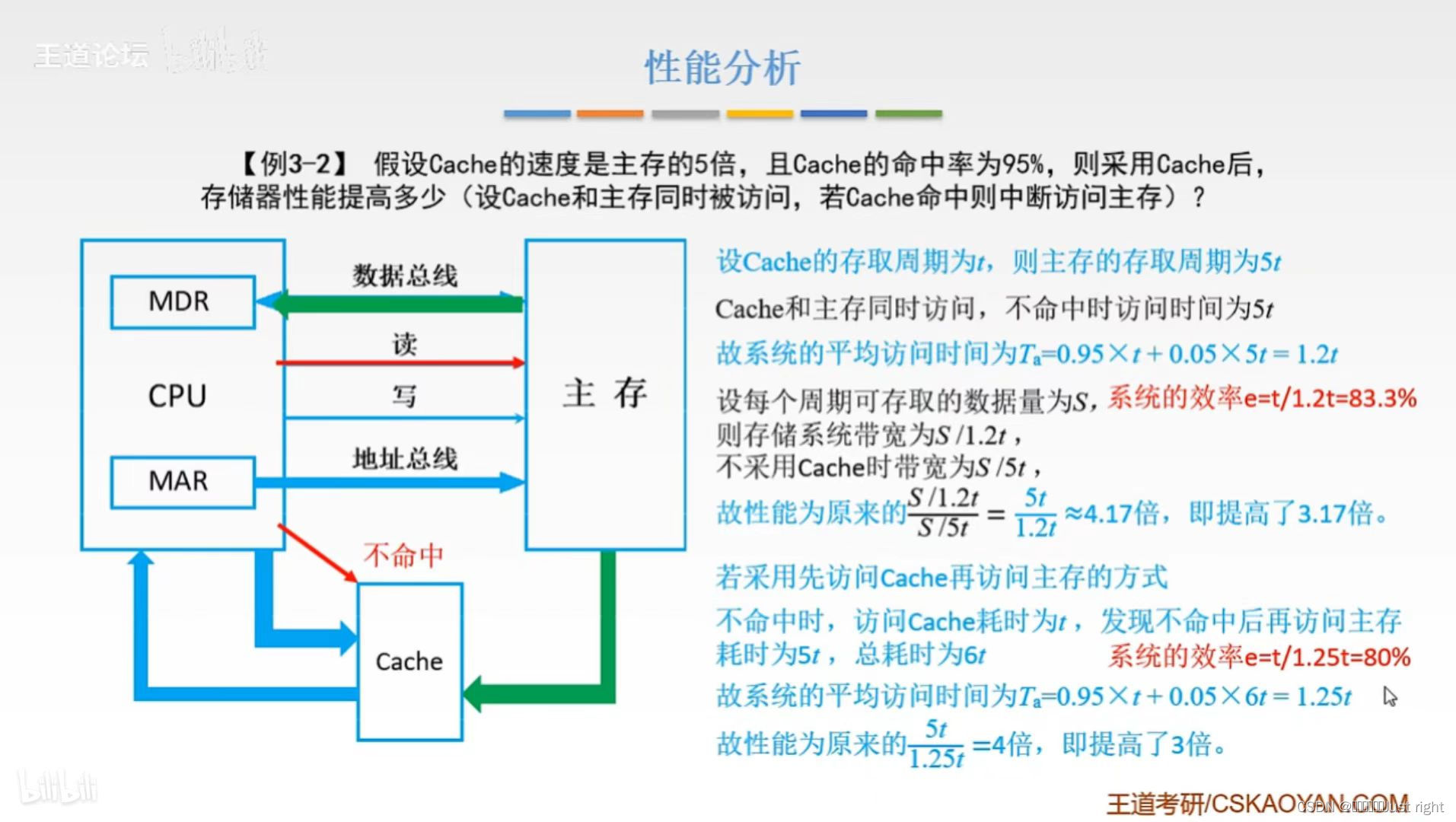
性能分析
只用写图片中蓝色的字,系统的效率e=t/系统的平均访问时间
地址映射
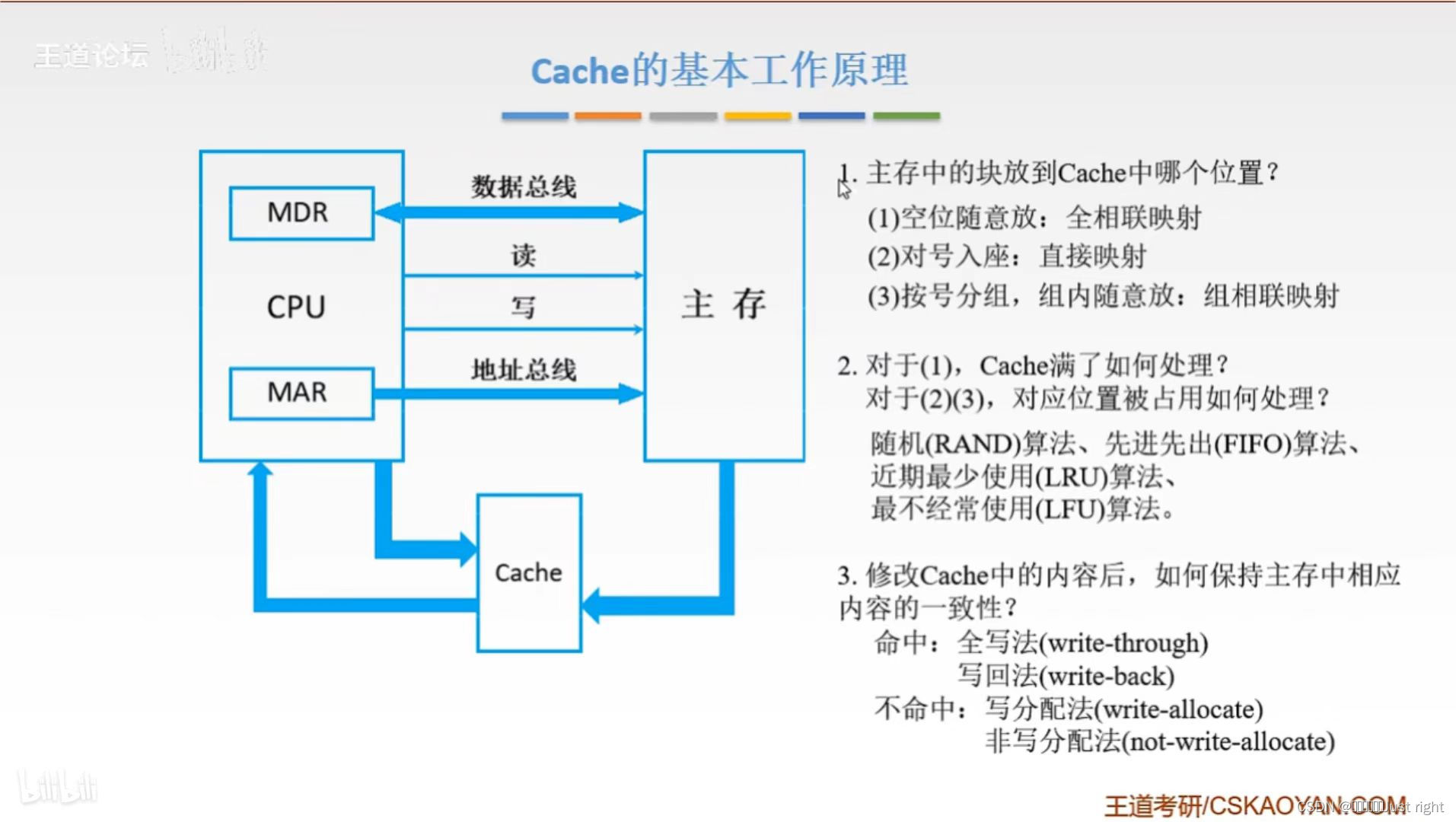
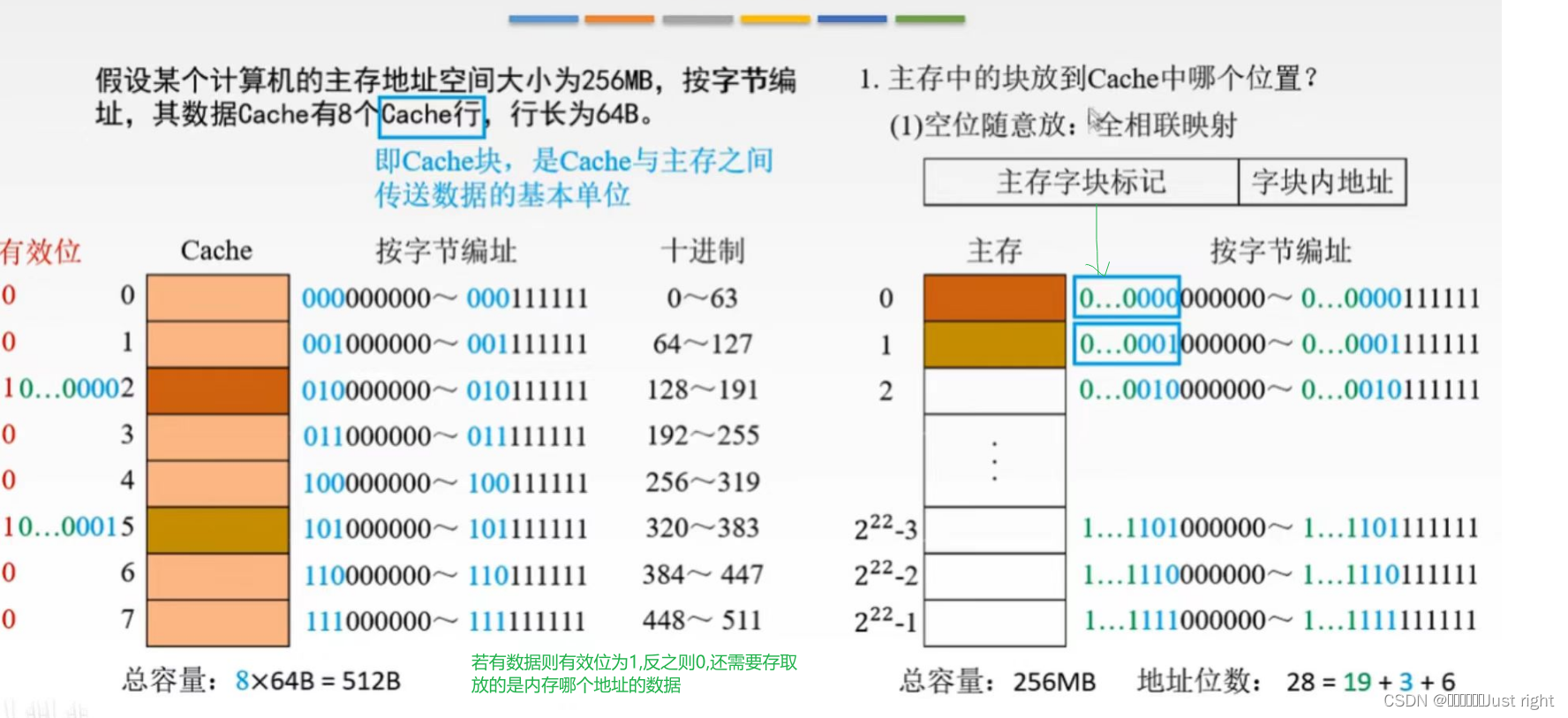
- 全相联映射:就是空位随便放


总结:

需要理解的 :
全相联:主存字块标记|字块内地址
直接映射:主存字块标记|Cache字块地址|字块内地址
组相联:主存字块标记|组地址|字块内地址
标记项:有效位,标记位
替换算法
- 随机算法(RAND):随机地确定替换地Cache块。它的实现比较简单,但没有依据程序访问的局部性原理,故可能命中率较低
- 先进先出算法(FIFO):选择最早调入的行进行替换。它比较容易实现。也没有依据程序访问的局部性原理,可能会把一些需要经常使用的程序块也作为最早进入Cache的块替换掉(如循环程序)
- 近期最少使用算法(LRU):依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,是堆栈类算法.实现:每行设置一个计数器,Cache每命中一次,命中行计数器清零,其他行计数器都加1,替换的时候将计数值最大的行踢出去
- 最不经常使用算法(LFU):将一段时间内被访问次数最少的存储行换出,也需要设置一个计数器,从0开始计数,被访问的行计数器加1,替换时将计数值最小的行换出
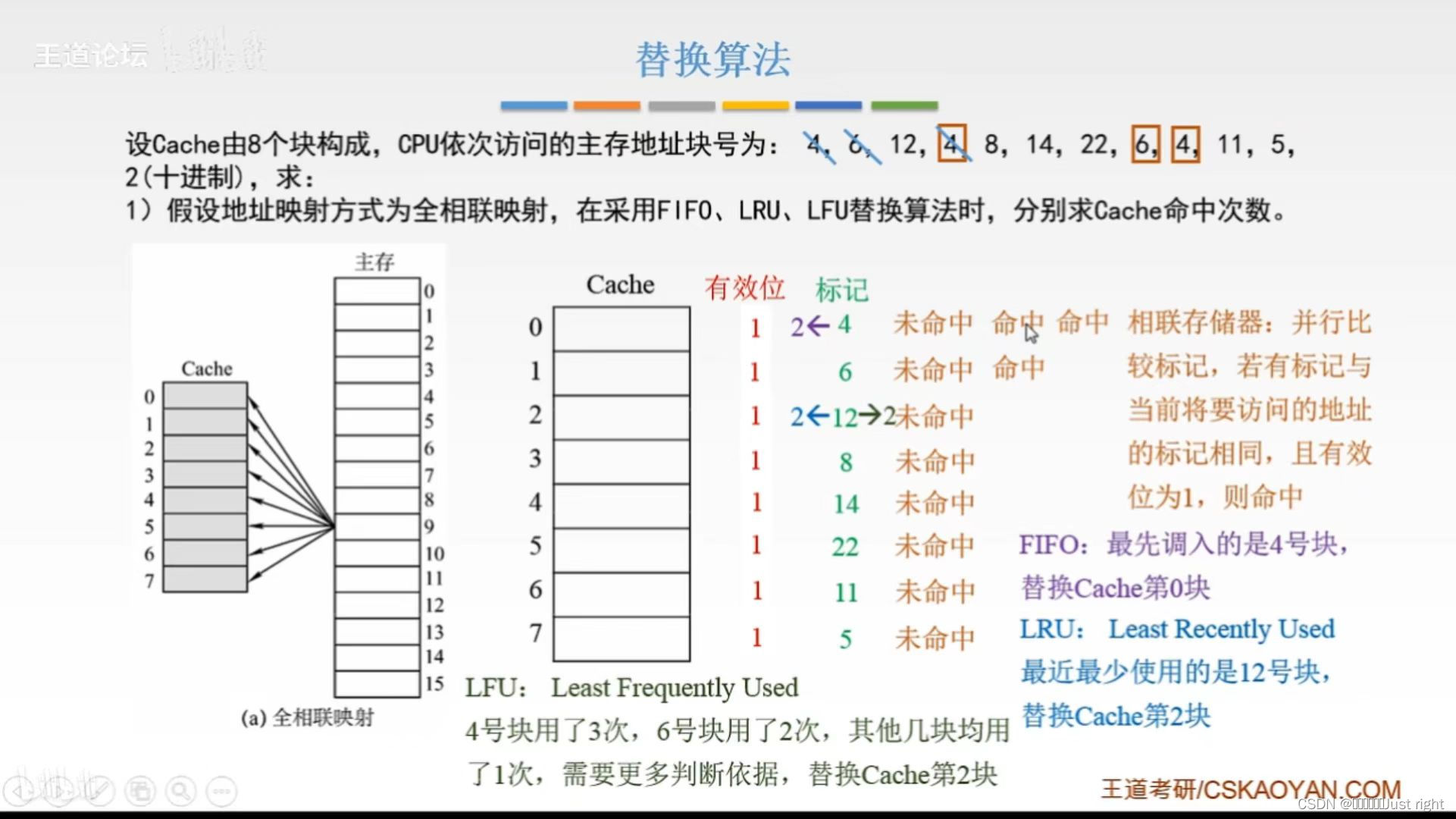
例子:
全相联映射:空位随意放,这里按照顺序来放,LRU算法视频上是这么说的:从后往前找,保留最后一个主存地址块号,从前往后数,第一个就是被踢出去的主存地址块号。
到了2的时候,Cache已经满了,
5,11 只有一个那保留
4 出现了三次,前面两次的划掉,保留最后一个
6 出现了两次,第一次的划掉,保留最后一个
22 14 8 只有一个那保留
从前往后数,第一个就是12,被踢出去的就是12.
个人理解:从前往后数,在cache中找到第一个为未命中的(以最新状态为准,比如说4 未命中 命中 命中,那么最新状态就是命中),直接踢出去


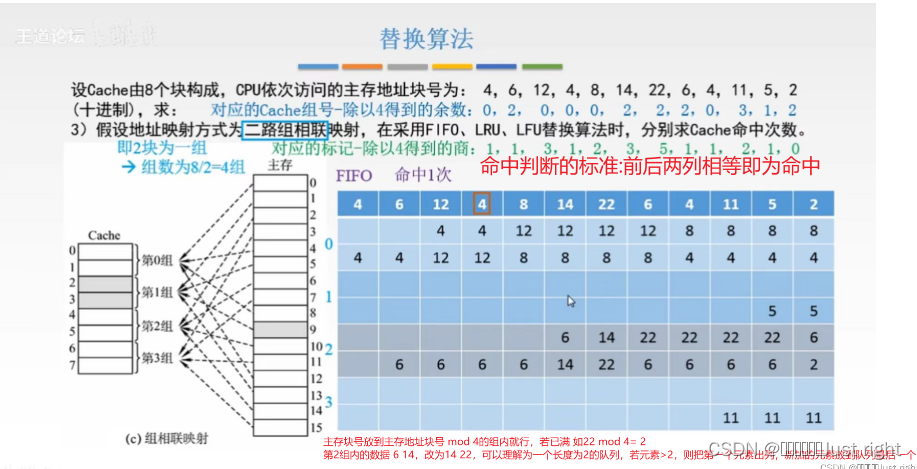
过程: 替换策略以FIFO为例
商 余数 组号 第几个 标记就是商
4 除以 4 1 0 0 1
6 除以 4 1 2 2 1
12 除以4 3 0 0 2
4 除以4 1 0 商和余数相同命中了
8 除以4 2 0 0 满了把4替换出去
14 除以4 3 2 2 2
22 除以4 5 2 2 满了把6替换出去
6 除以 4 1 2 2 满了把14替换出去
4 除以4 1 0 0 满了把12踢出去
11 除以4 2 3 3 1
5 除以4 1 1 1
2 除以4 0 2 2 把22 踢出去
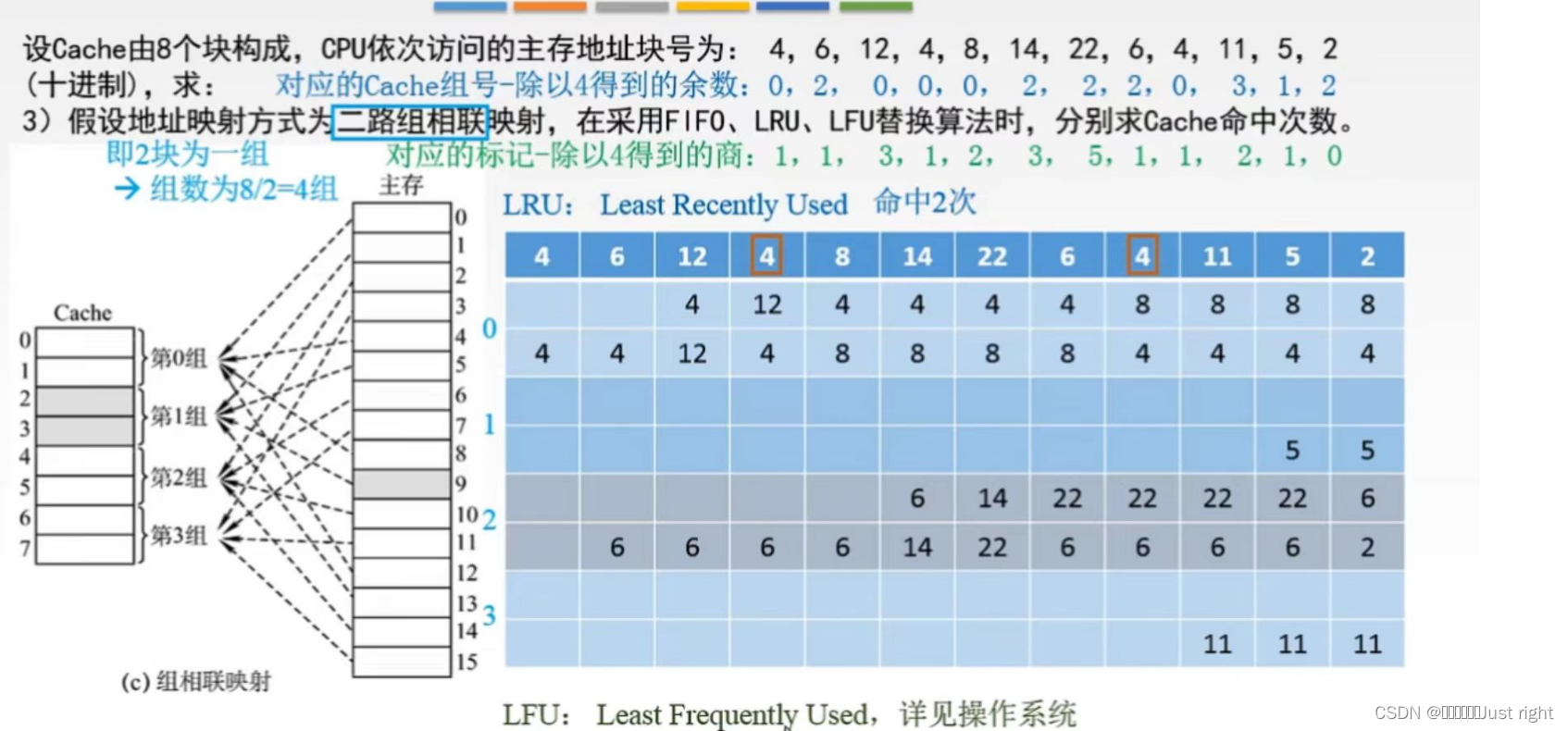
二路组相联映射
已知 除数 商 余数 倒推出被除数
除数;Cache的组数,这个是固定死的
商就是 标记
余数就是确定Cache是那一组的
那么只要商(标记)和余数(Cache的组号)相同倒推出来的被除数一定相同
例题:

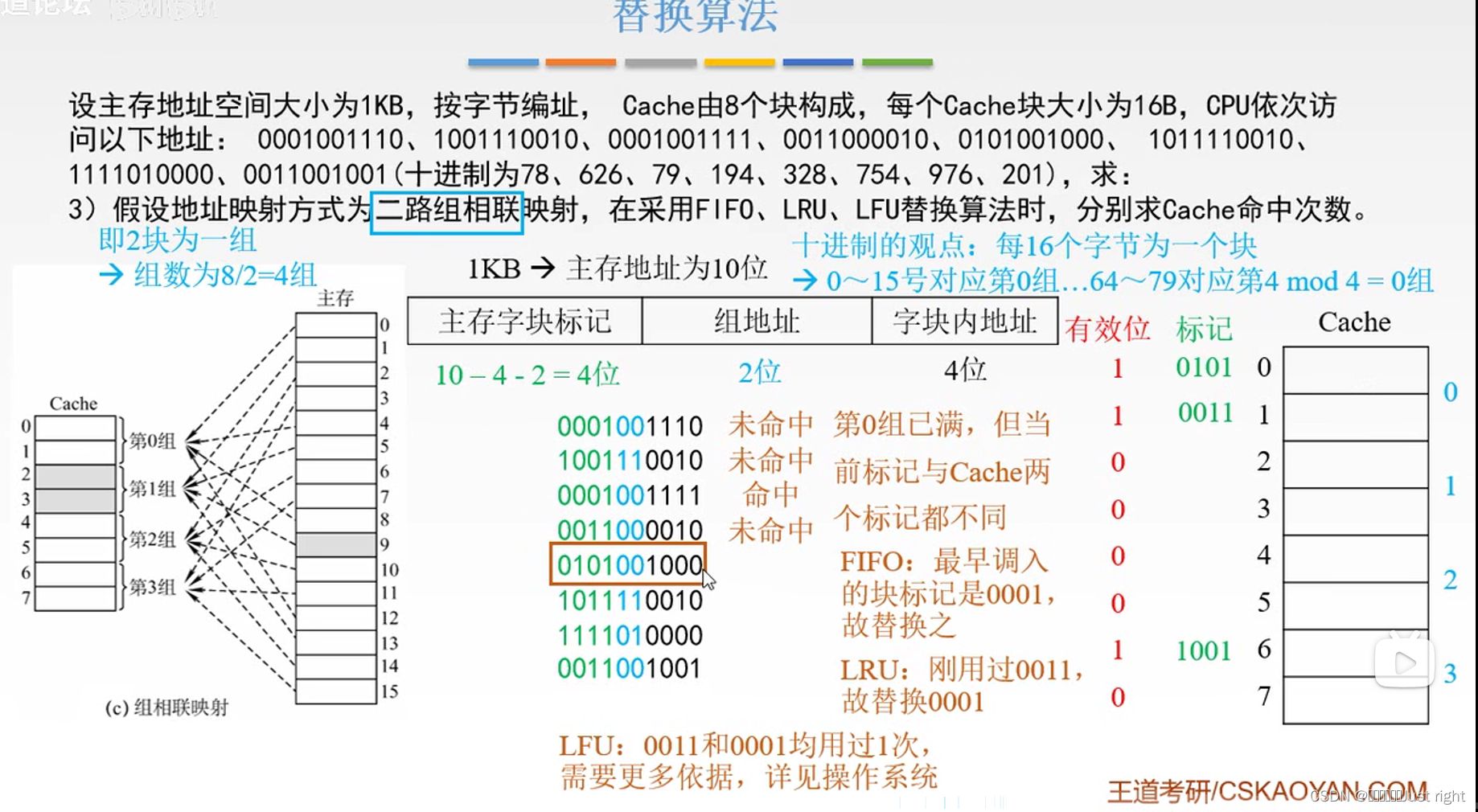
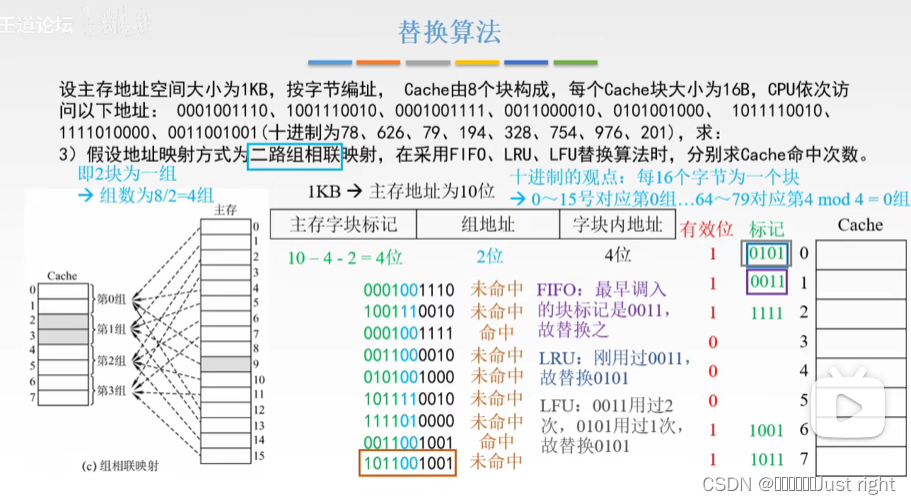
Cache工作原理
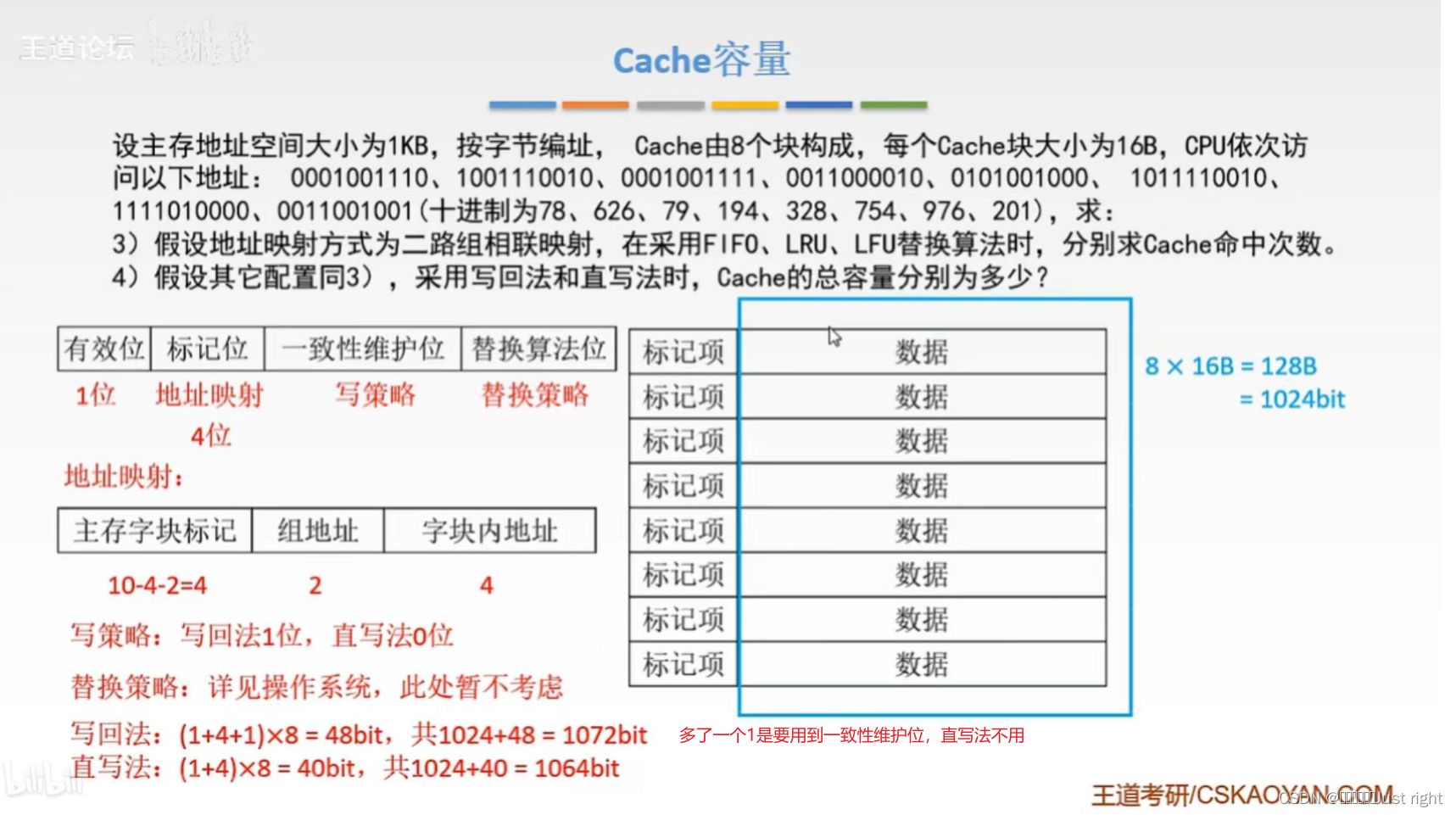
需要知道的:
- 地址结构的分析
十进制:地址除以组数,商为标记Tag,余数为组号Index
二进制:组数为2的n次方,高位为Tag,低位为组号Index - Cache容量的几岁按
标记项:
地址映射:有效位,标记位
替换算法:替换算法控制位
写策略:一致性维护位
数据项
写策略
命中
解决的问题就是如何保证Cache中的数据与主存中的数据保持一致的问题
-
写回法:写命中时改Cache中的内容,等该块被踢出去的时候再写回内存
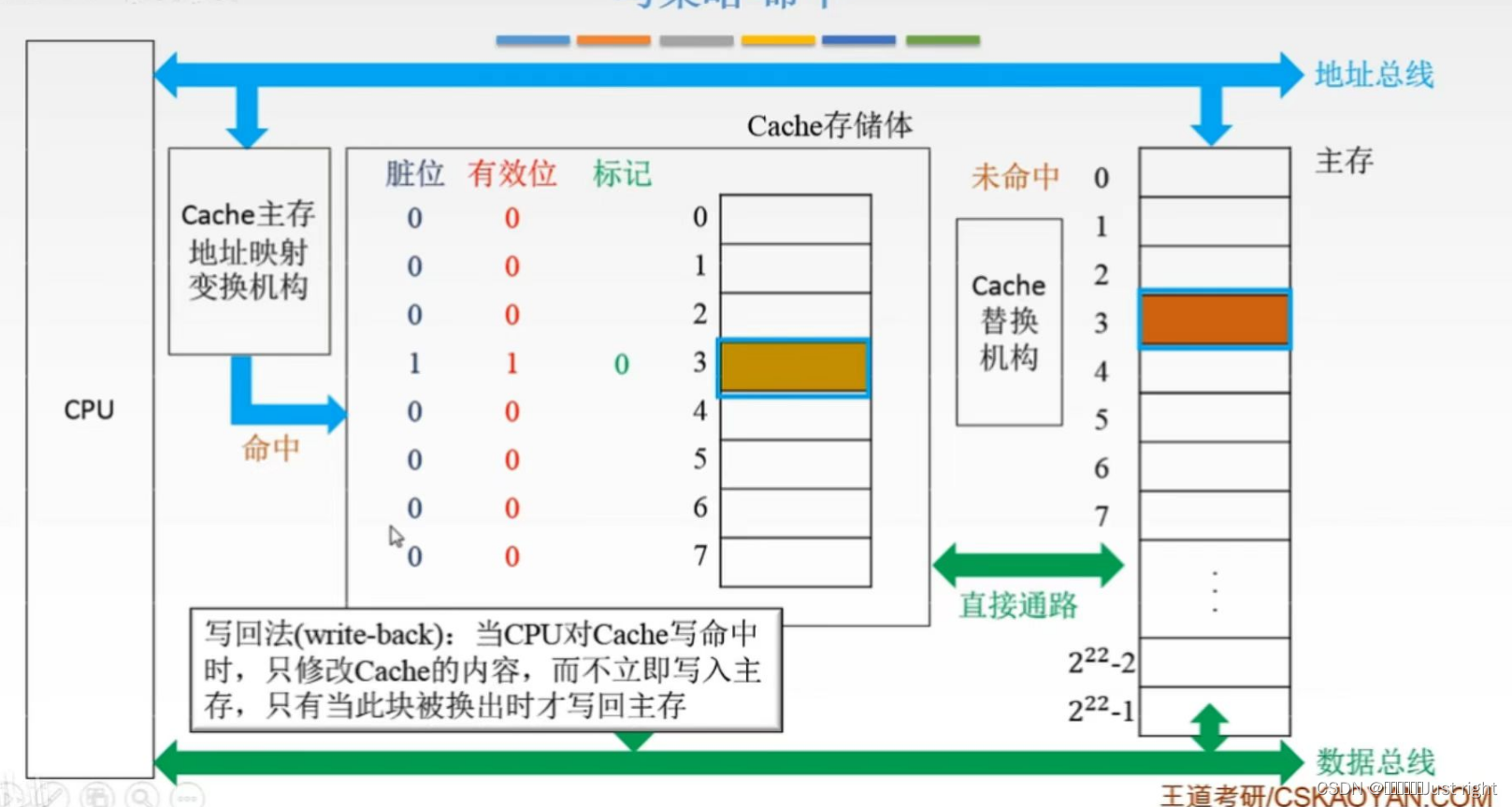
-
全写法:就是写命中的时候同时把数据写入Cache和主存

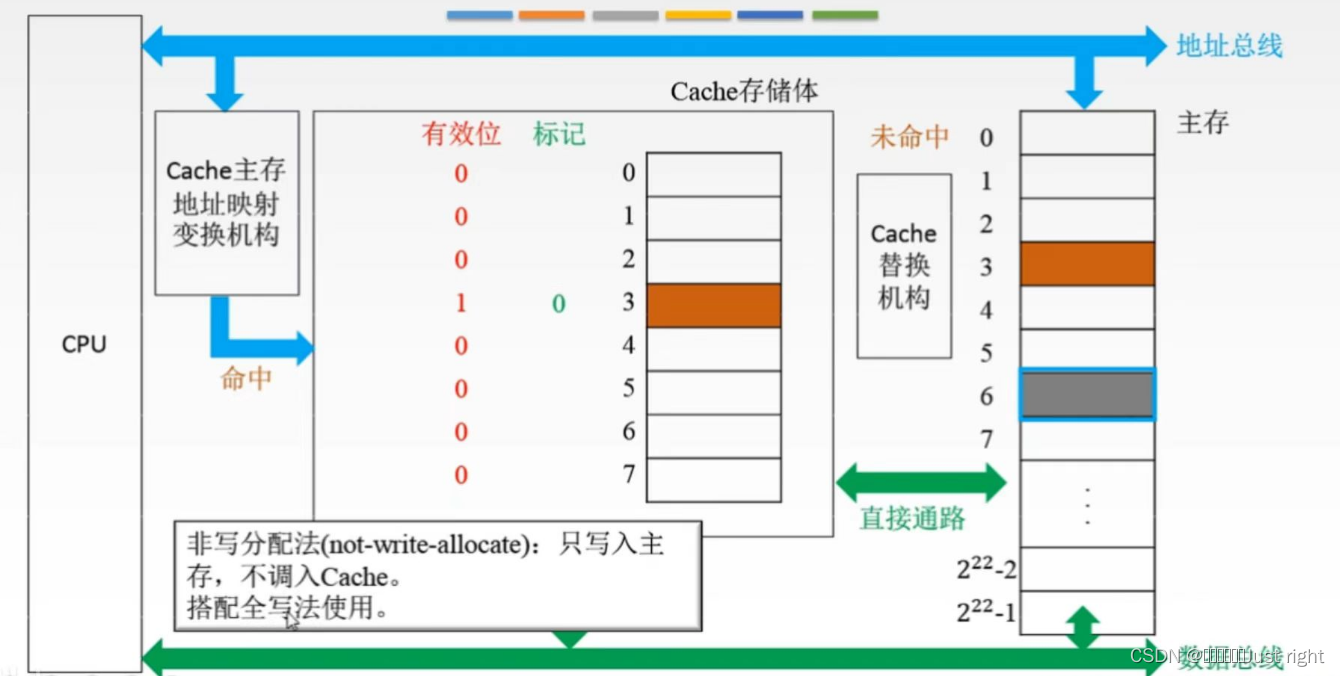
未命中
-
非写分配法:只写入主存,不调入Cache
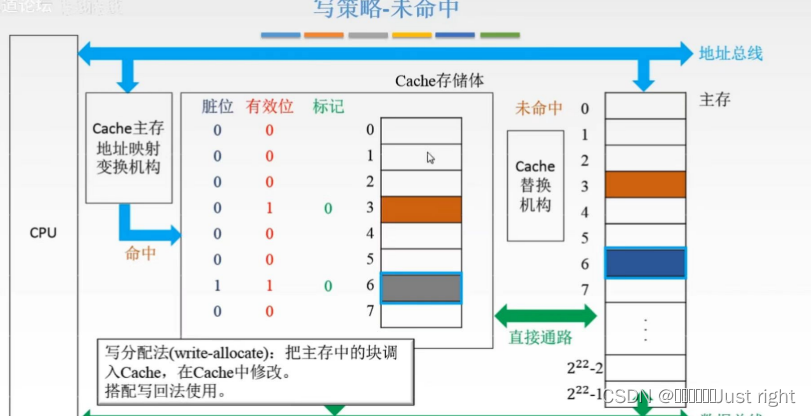
-
写分配法:把主存中的块调入Cache,在Cache中修改,搭配写回法使用
小结
写回法搭配写分配法: CPU <——>Cache<——>主存
全写法搭配非写分配法: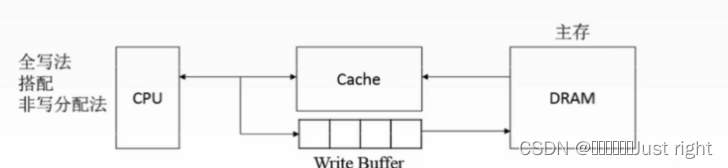
虚拟存储器

-
页式虚拟存储器
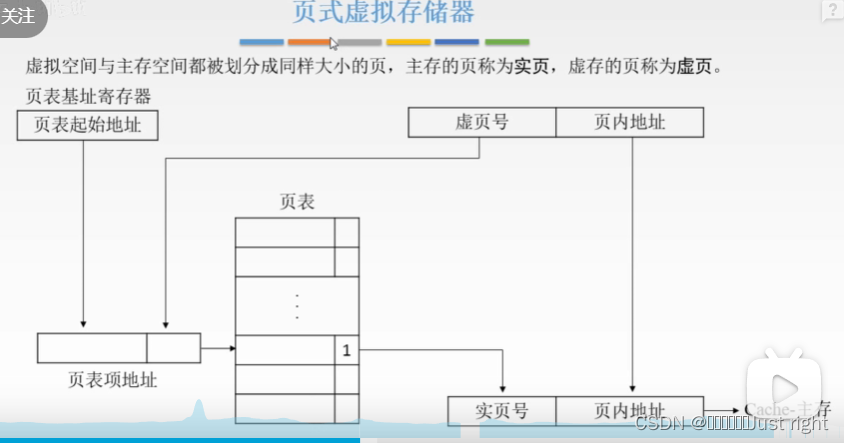
-
段式虚拟存储器
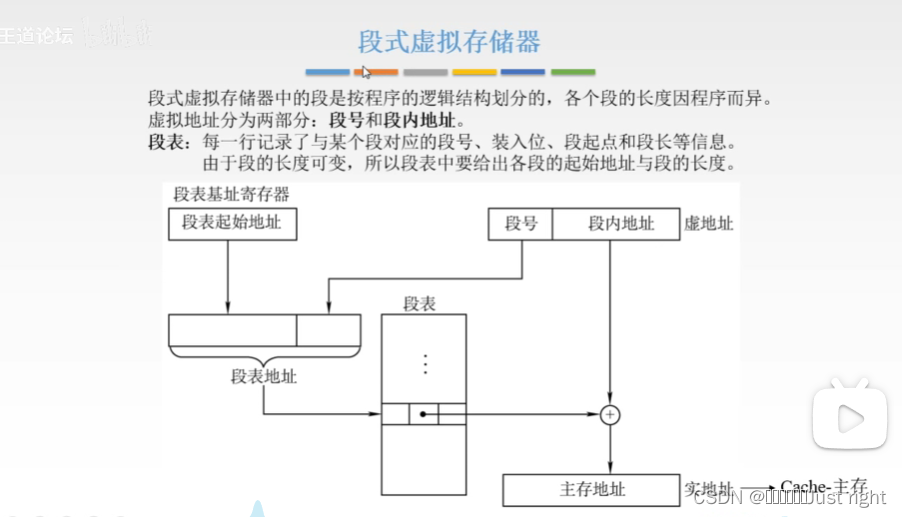
-
段页式虚拟存储器
把程序按逻辑结构分段,每段再划分为固定大小的页,主存空间也划分为大小相等的页,程序对主存的调入,调出以页为基本单位,每个程序对应一个段表,每段对应一个页表。虚拟地址:段号+段内页号+页内地址
例题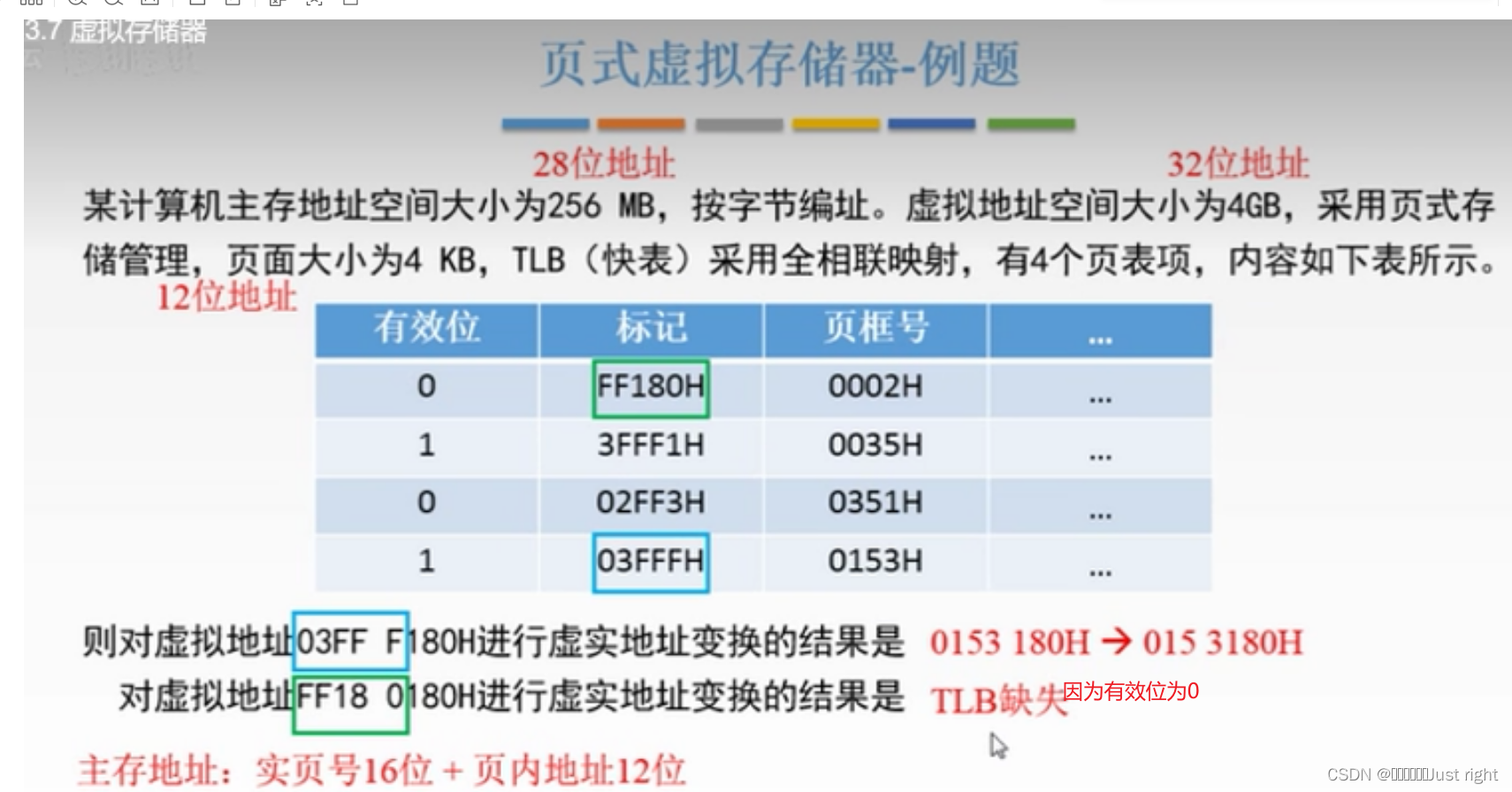
-
快表TLB
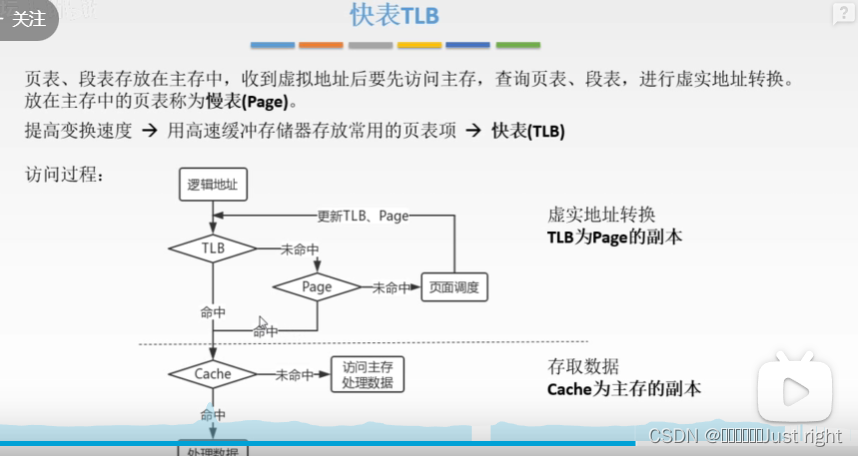
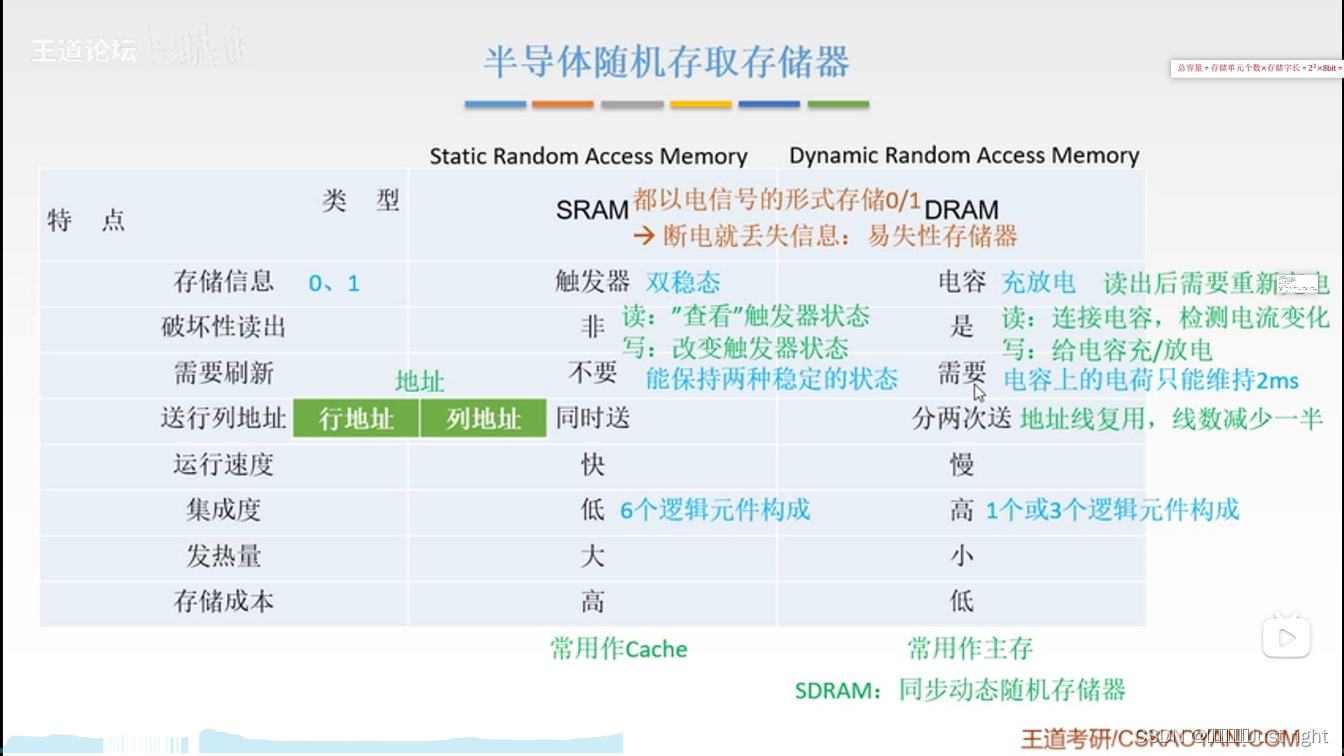
半导体存储器
RAM
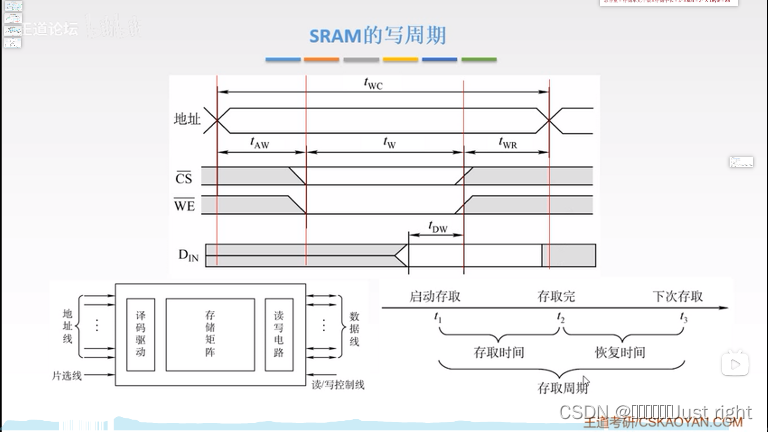
存储周期:从启动存储到下次存取的时间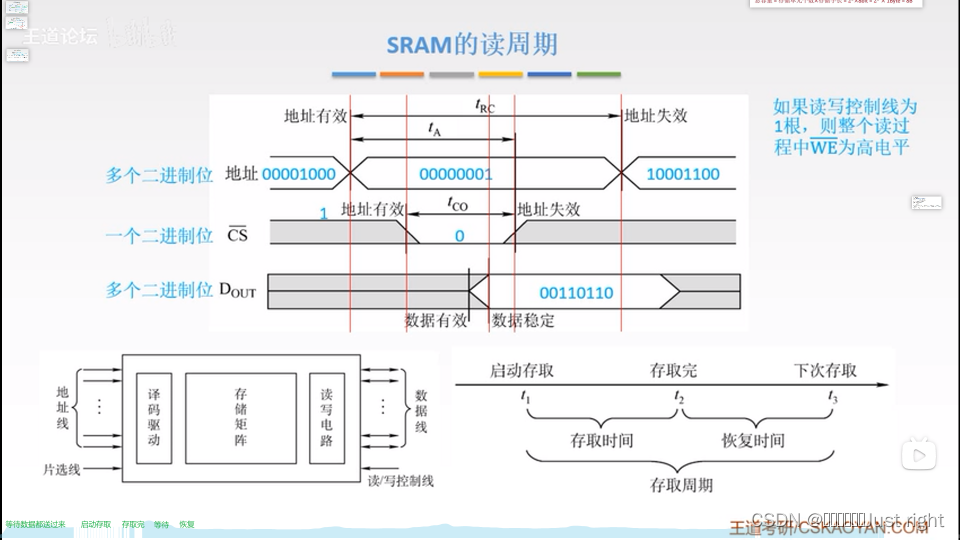
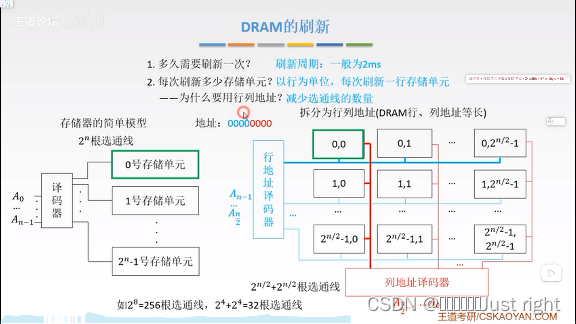
DRAM的刷新
- 一般是2ms刷新一次
- 每次刷新一行
之所以要用行列地址,是需要减少连通线的数量 - 刷新就是读出一行的信息后重新写入,占用1个读/写周期
刷新方案1
每次读写完都刷新一行 也就是分散刷新,当写作业举例,这个就是天天写作业
系统的存储周期变为1μs,前0.5μs用于正常读写,后0.5μs用于刷新某行
刷新方案2
2ms内集中安排时间全部刷新,存储周期还是0.5μs,用于刷新存储器的时间称为访存“死区”。就是开学前一天疯狂补作业
刷新方案3
2ms内每行刷新1次即可。2ms内产生128次刷新请求,每隔2ms/128=15.6μs一次 每个15.6μs内有0.5μs的“死时间”

ROM
- MROM(掩膜式只读存储器) 存储内容由半导体制造厂按用户提出的要求在芯片的生产过程中直接写入,无法修改
- PROM(一次可编程只读存储器) 需用用专门的设备一次性写入,之后无法修改
- EPROM(可擦除可编程只读存储器)
- UVEPROM(紫外线擦除)
- EEPROM(电擦除)
- Flash Memory(闪存) 就是U盘
- SSD(固态硬盘) 控制单元+Flash芯片