- 相关资源: github
第二课 图像分类与基础视觉模型
图像分类
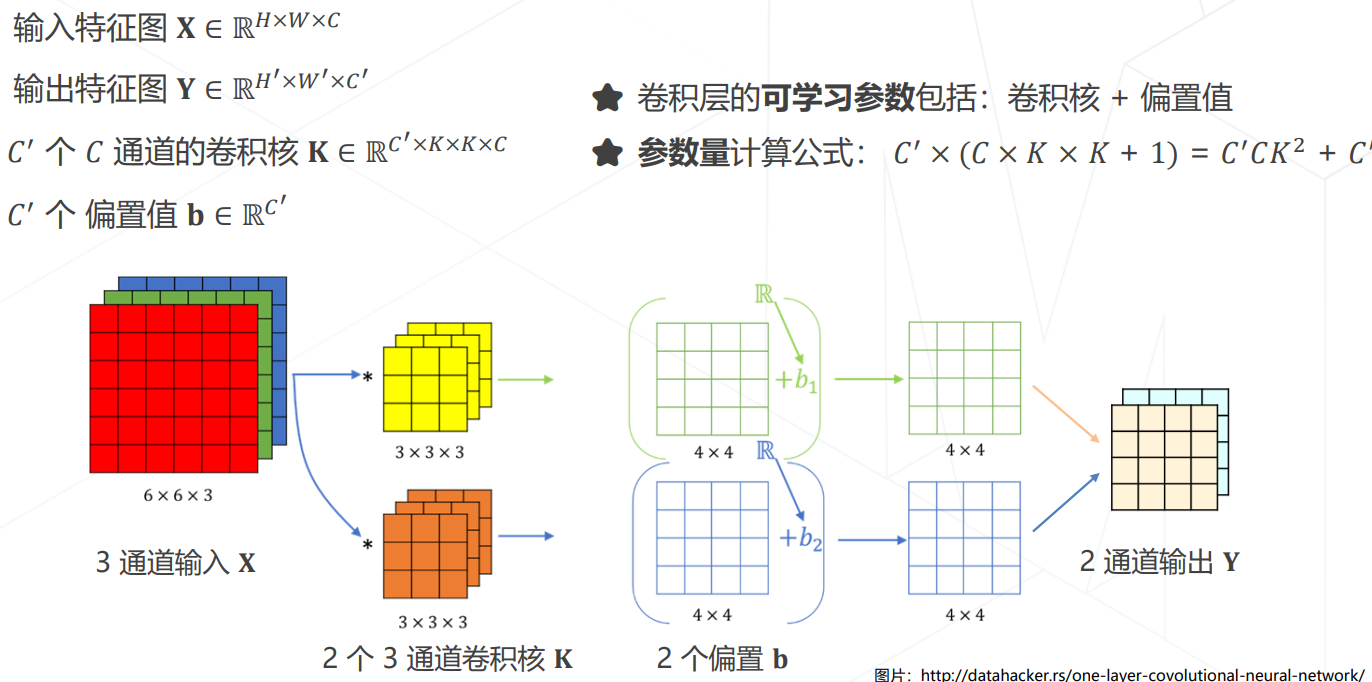
图像分类任务:给定一张图片,识别图像中的物体是什么 X ∈ R H ∗ W ∗ 3 → { 1 , 2.. , K } X\in R^{H*W*3} \rightarrow \{1,2..,K\} X∈RH∗W∗3→{1,2..,K};
从图片中学习:


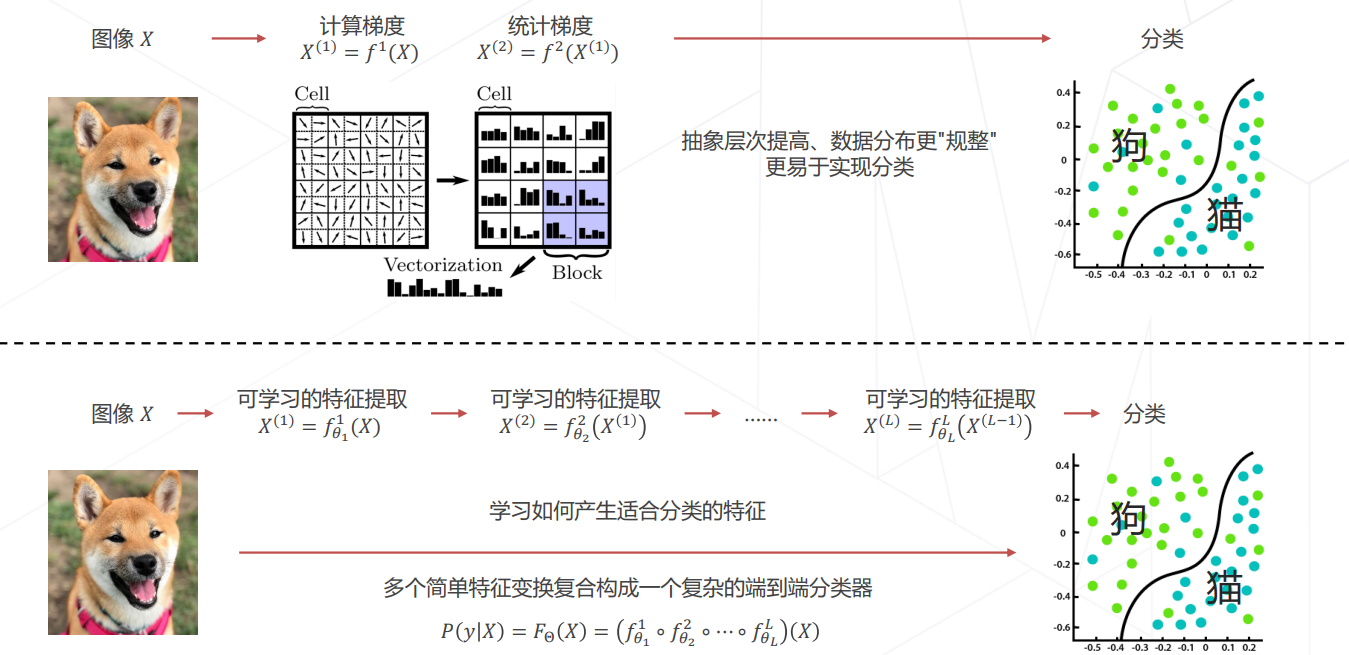

- 解决图像分类任务主要是两个部分:模型的设计、模型的学习

卷积神经网络
- AlexNet(2012)

- Deeper:
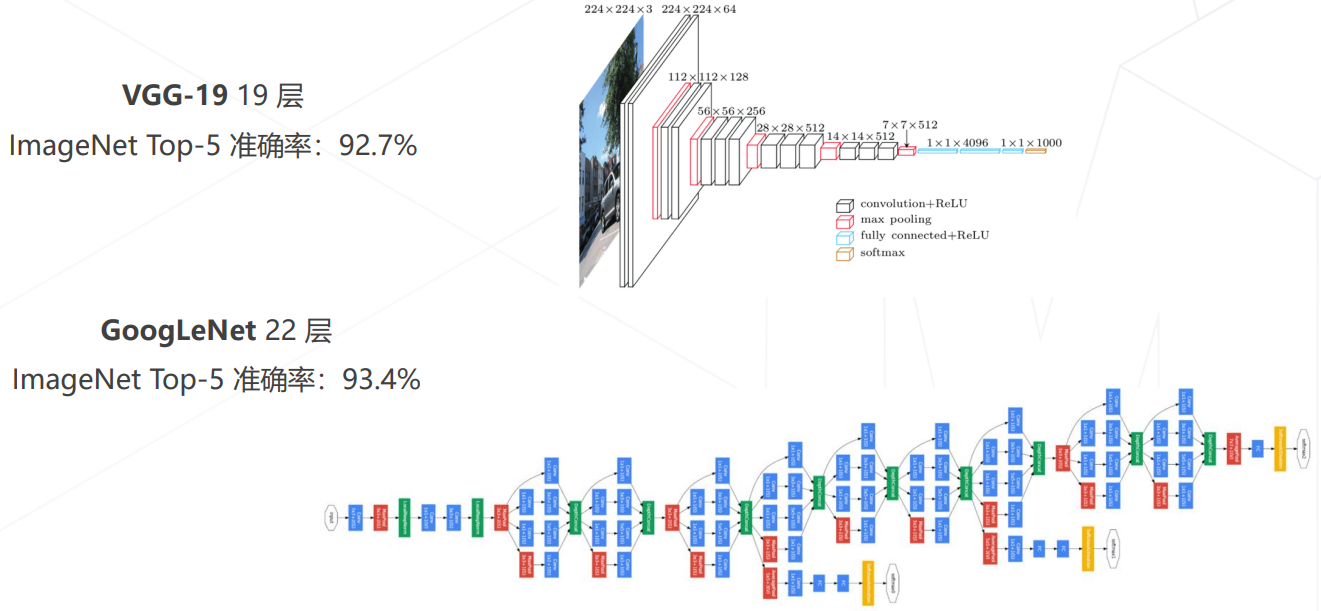
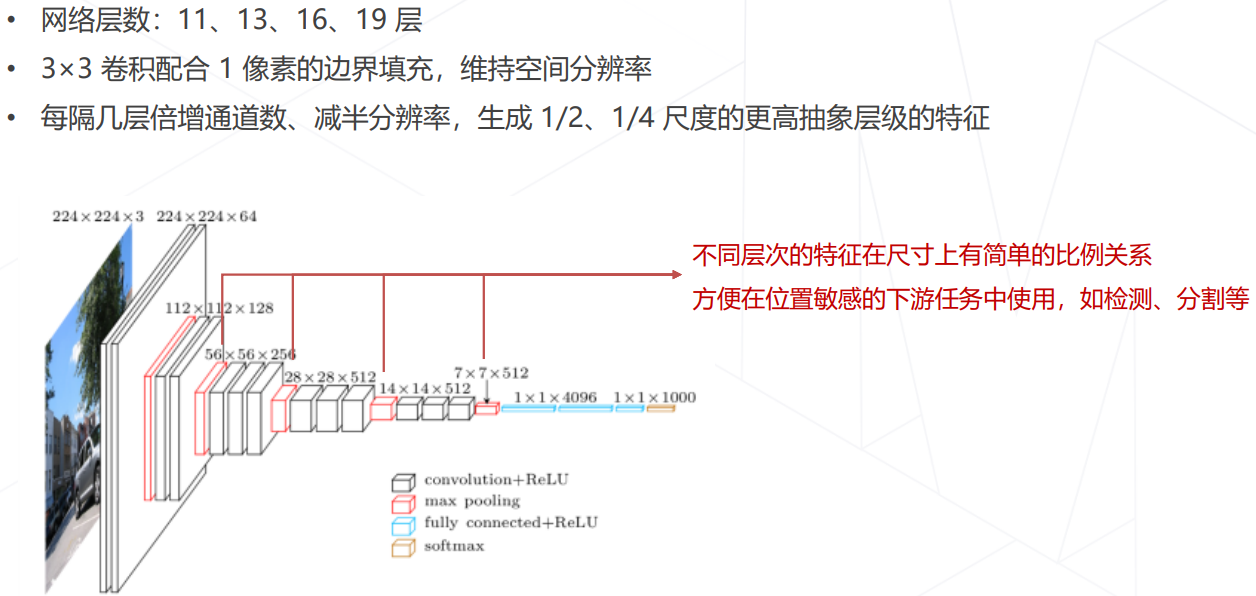
VGG
- VGG(2014):
Inception
- GoogLeNet(Inception v1, 2014)

ResNet (CVPR 2016 BestPaper, CV领域引用数十万)
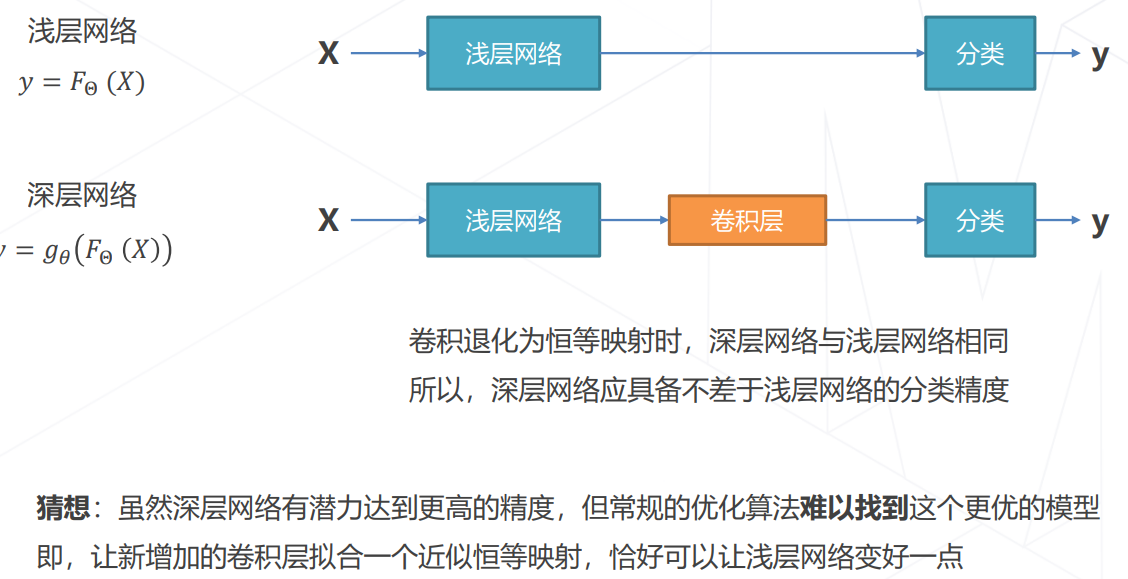
- 模型层数增加到一定程度后,分类正确率不增反降


- ResNet(2015)



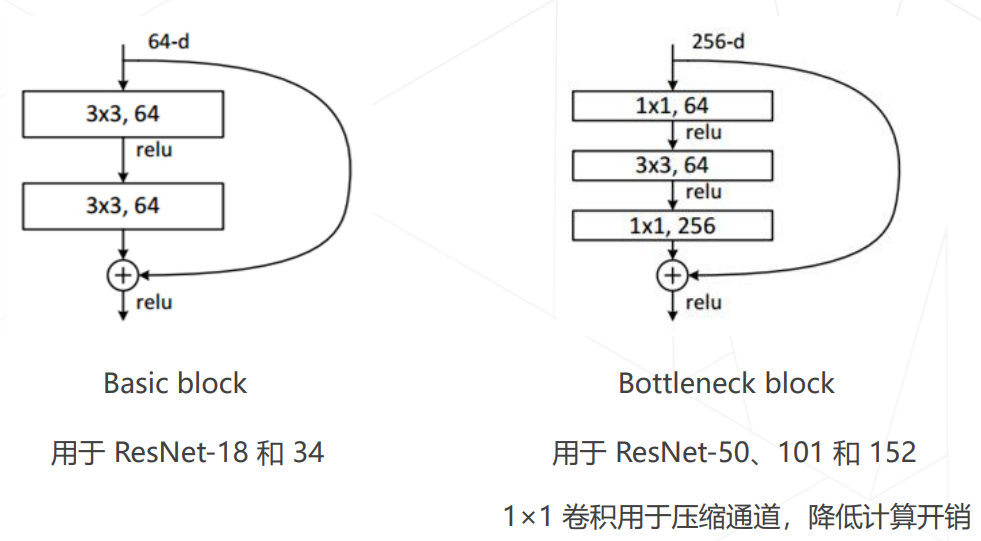
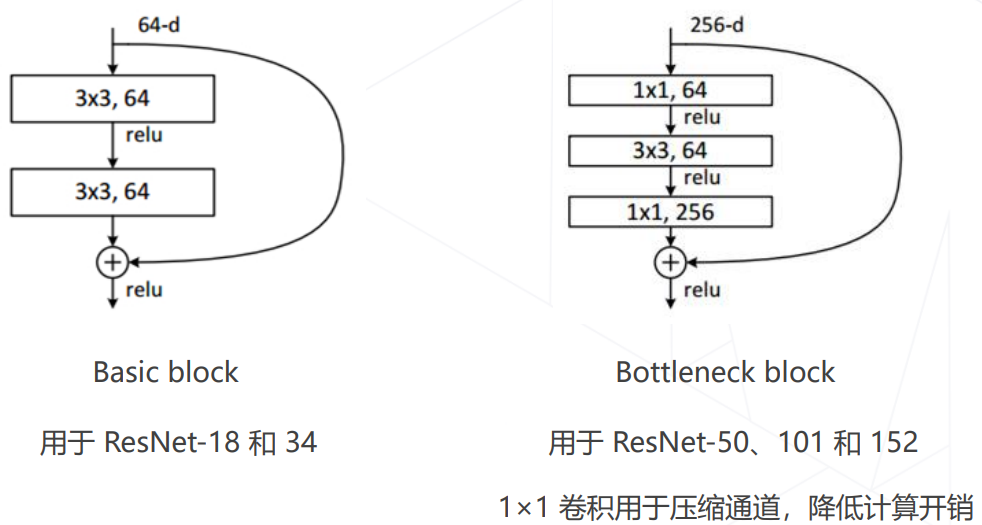
- ResNet 中的两种残差模块
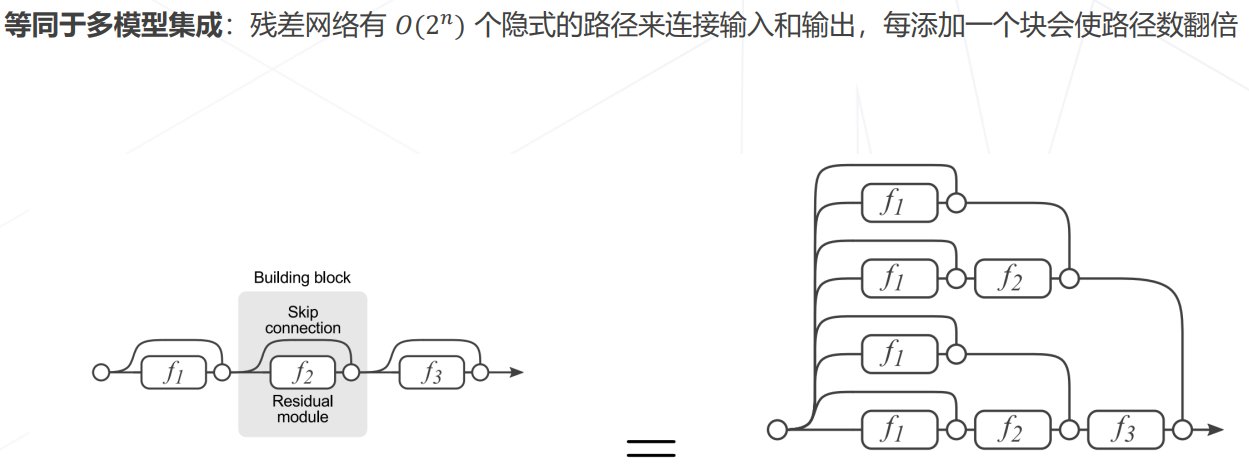
- ResNet 是深浅模型的集成:
- 残差链接让损失曲面更平滑:

- ResNet 后续改进:

更强的图像分类模型

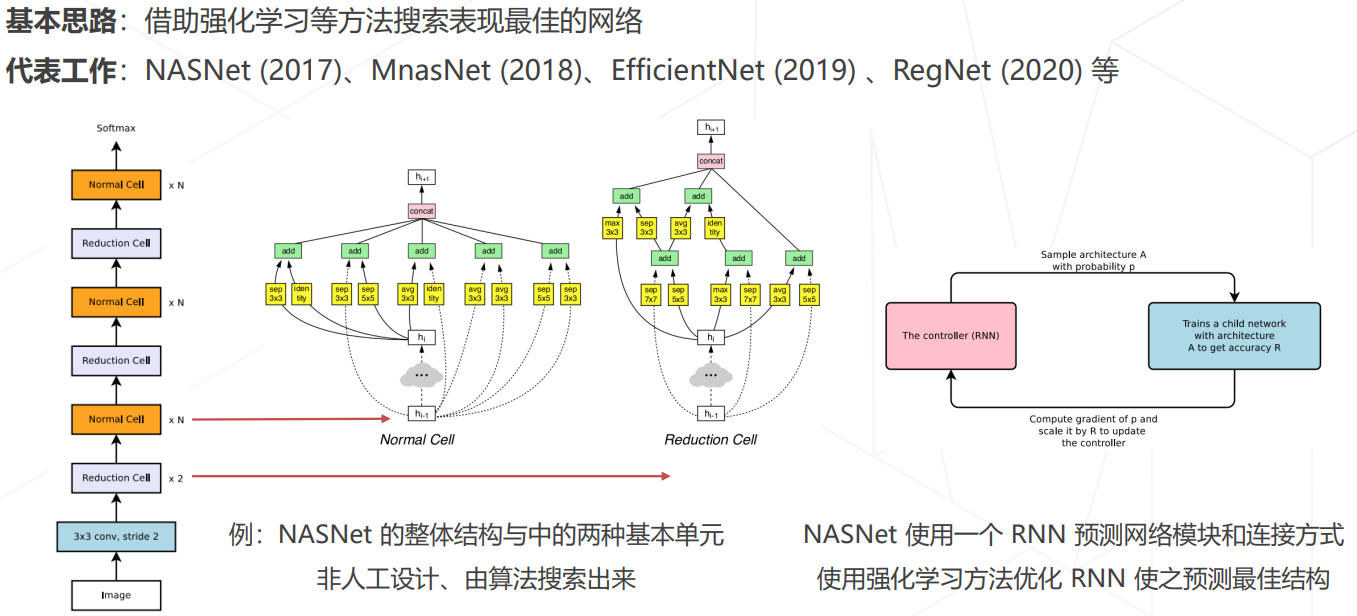
神经结构搜索 Neural Architecture Search (2016+)
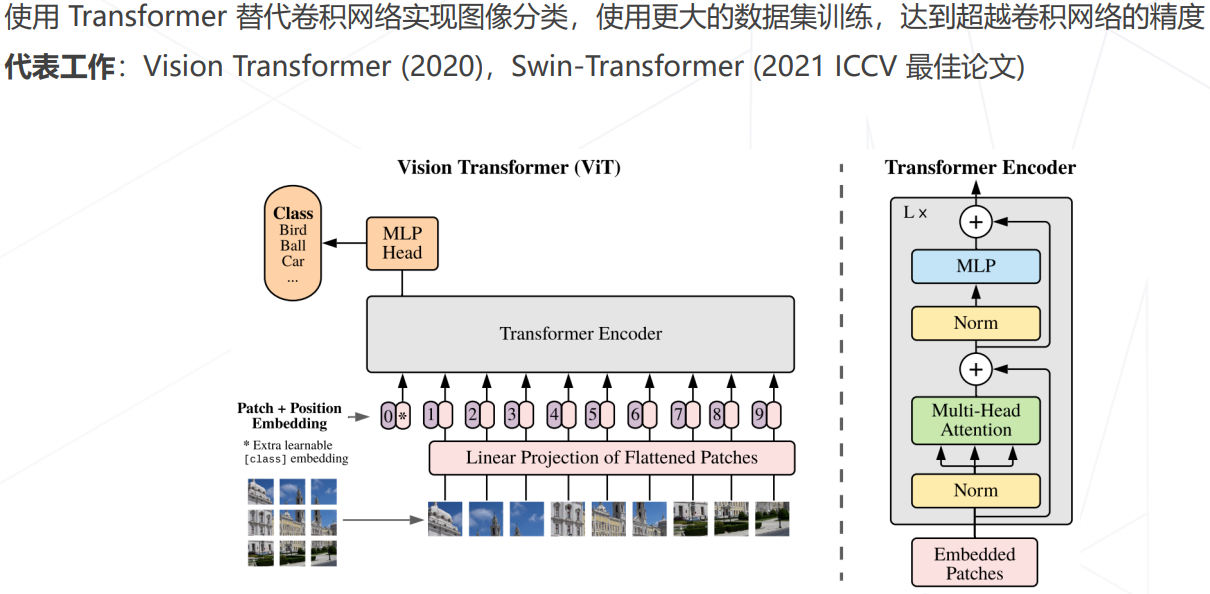
Vision Transformers (2020+)
- ConvNeXt (2022):

轻量化卷积神经网络

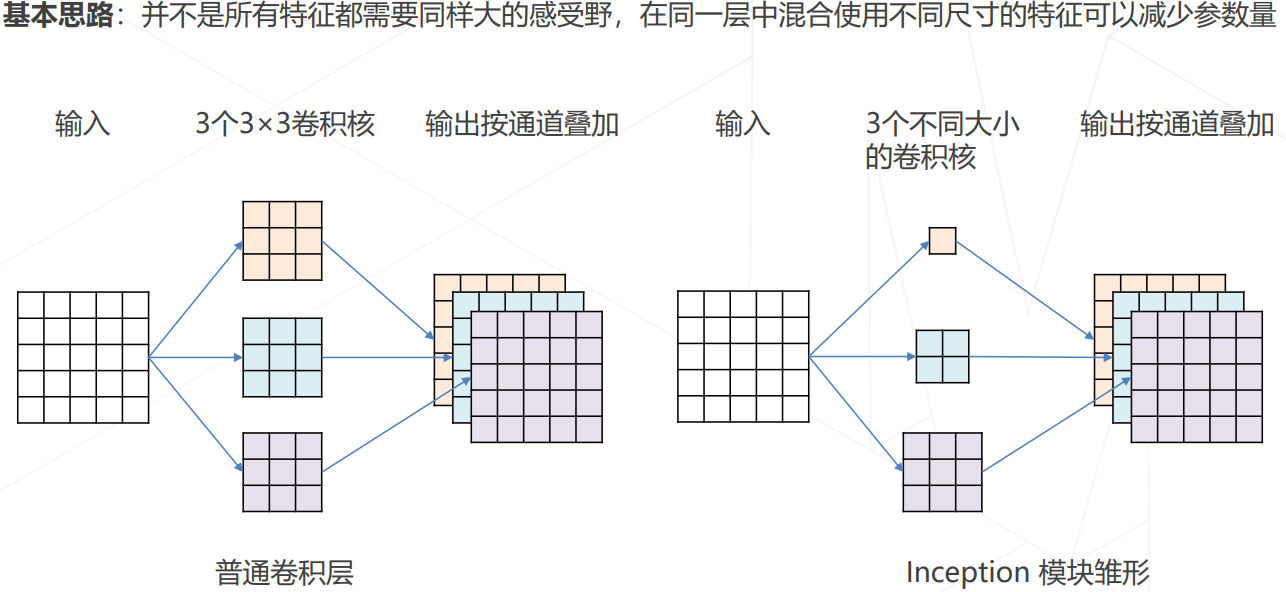
降低模型参数量和计算量的方法

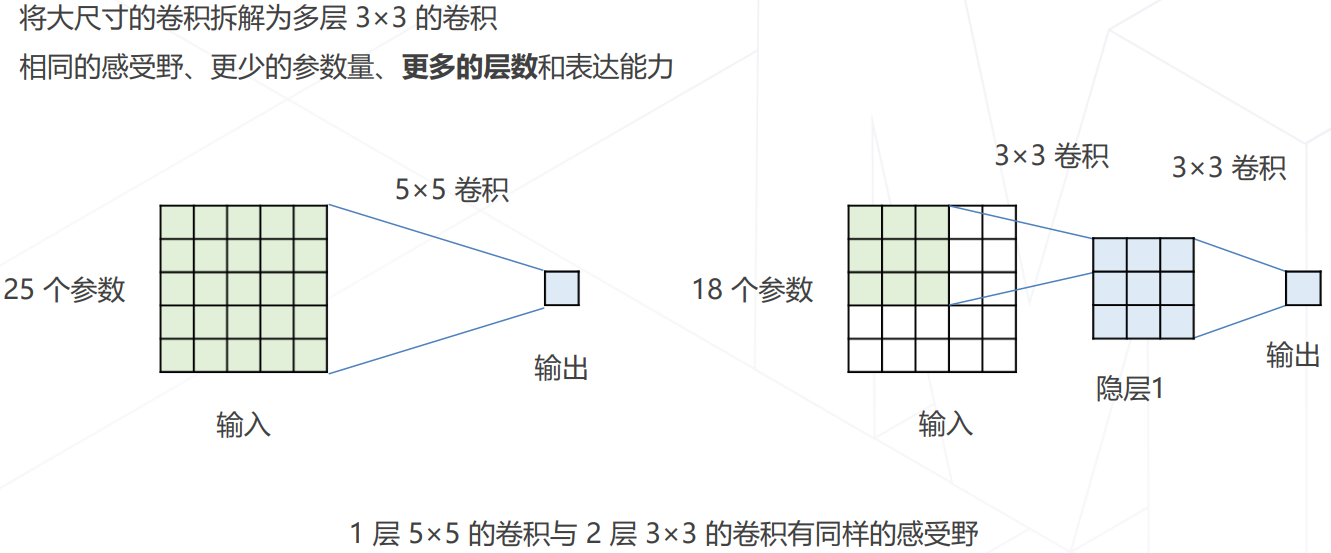
- GoogLeNet 使用不同大小的卷积核:
1x1 卷积
- ResNet 使用1×1卷积压缩通道数:
可分离卷积
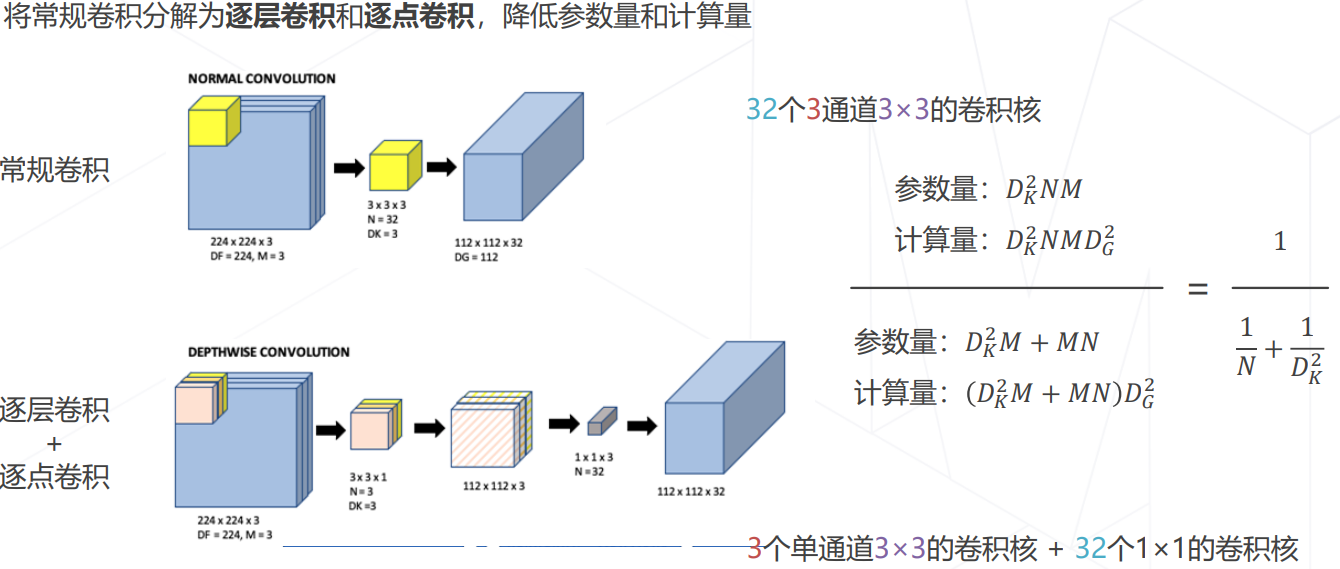
MobileNet V1/V2/V3 (2017~2019)

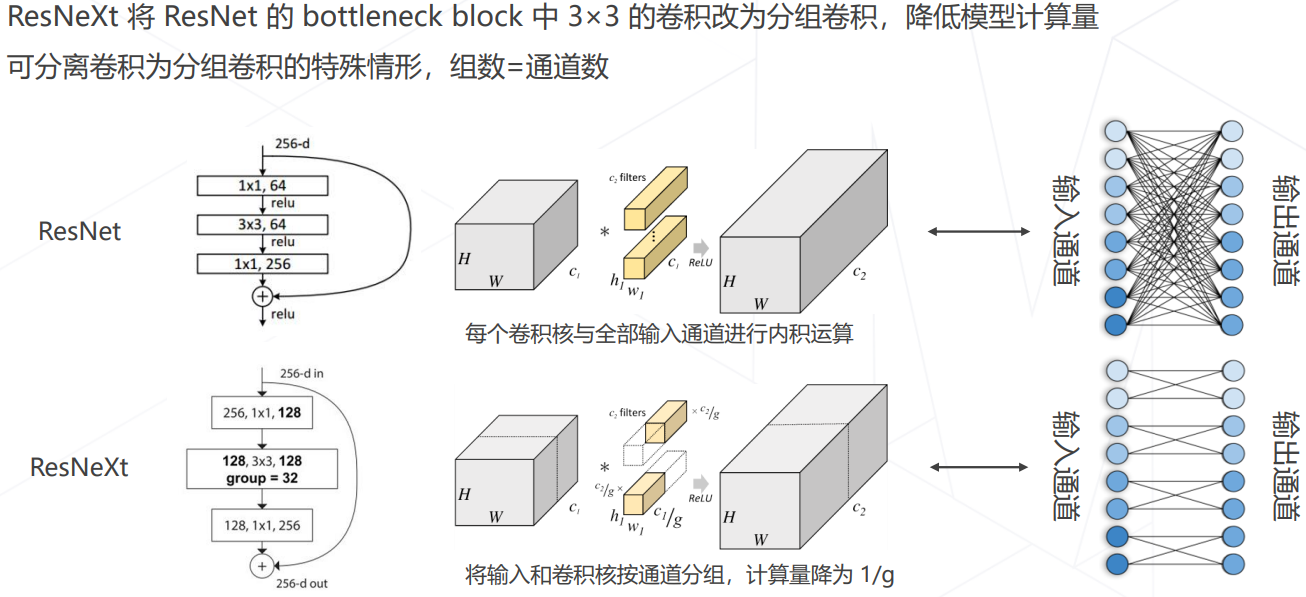
ResNeXt 中的分组卷积
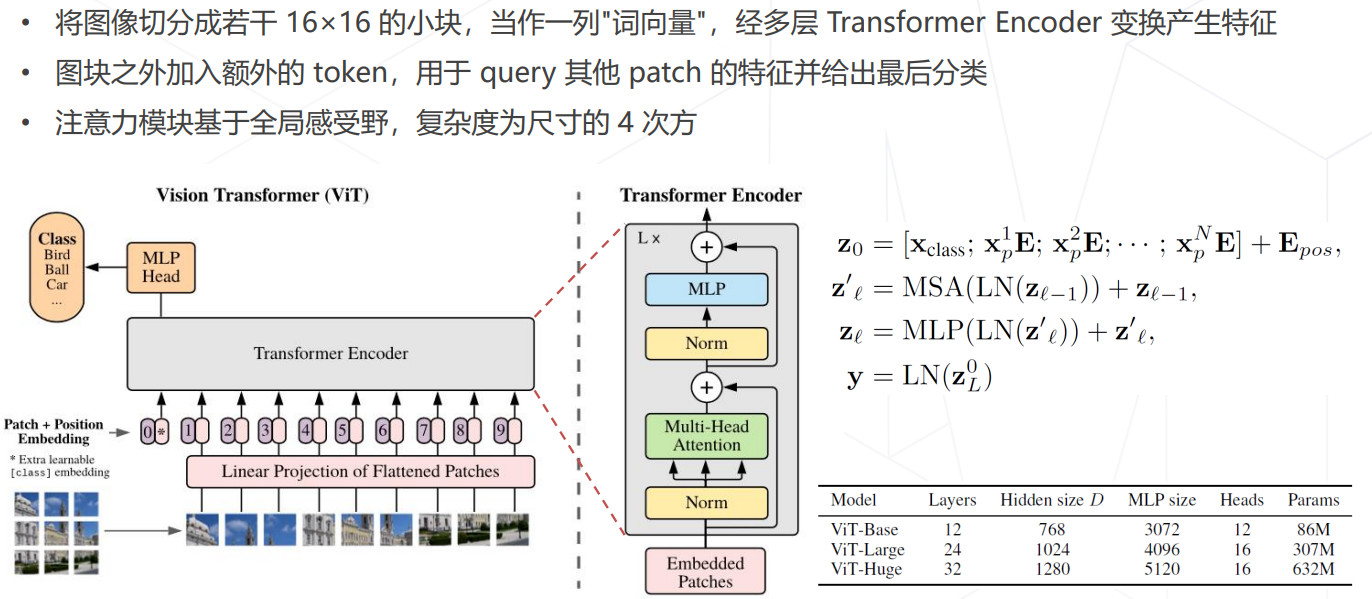
Vision Transformers
注意力机制 Attention Mechanism


多头注意力 Multi-head (Self-)Attention

1D 数据上的 Attention

Vision Transformer (2020)
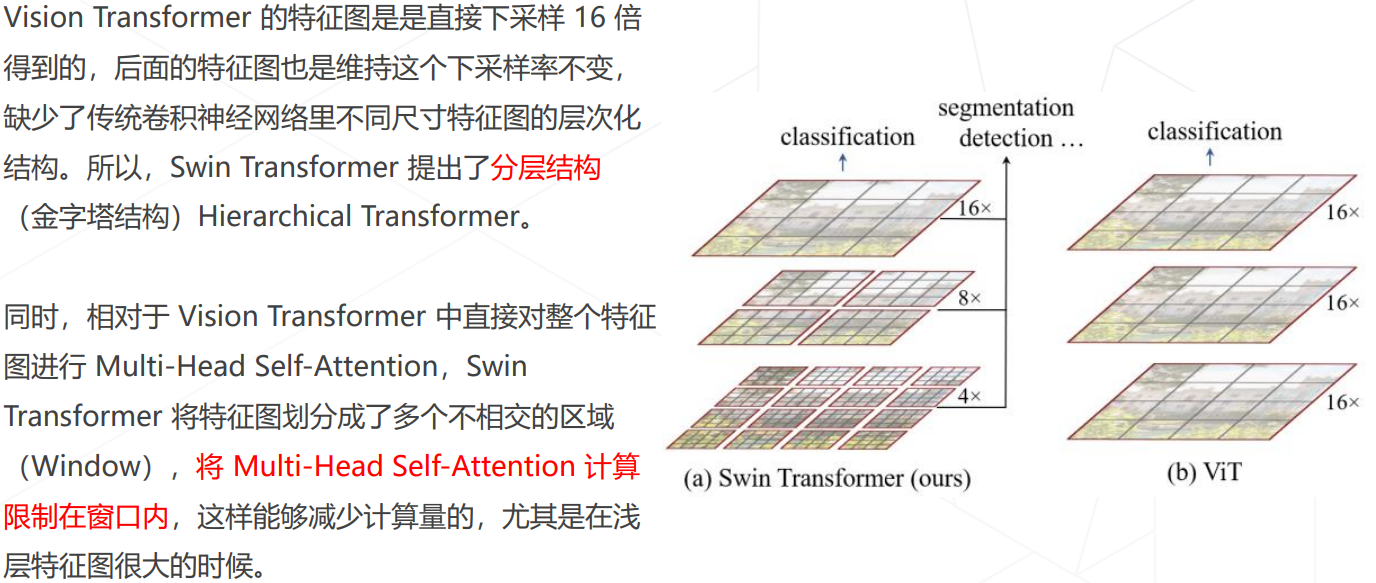
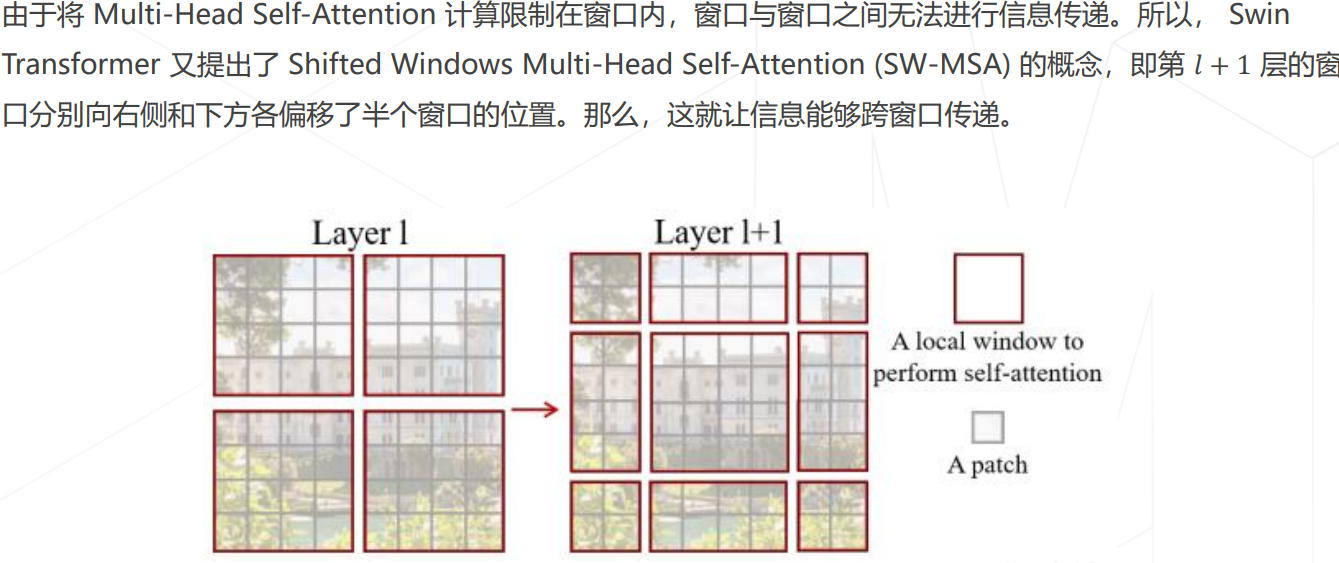
Swin Transformer (ICCV 2021 best paper)
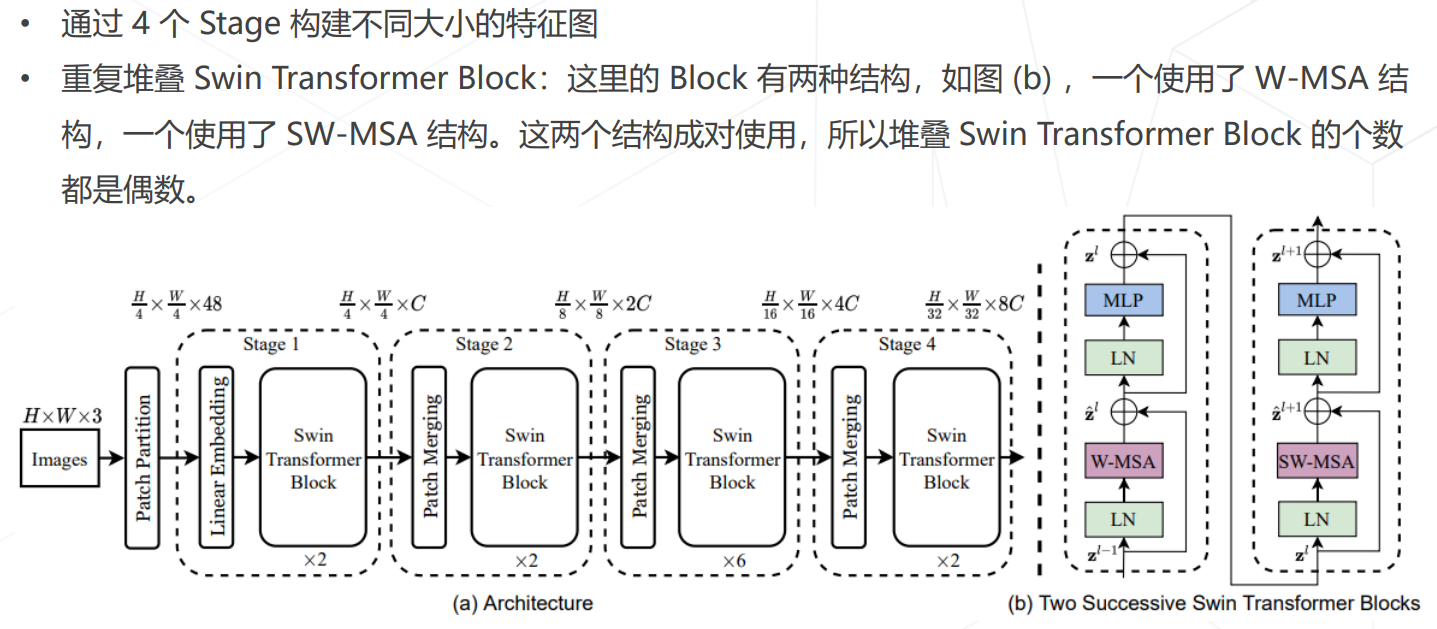
模型学习
这里略去基础知识,只保留与CV相关的部分。

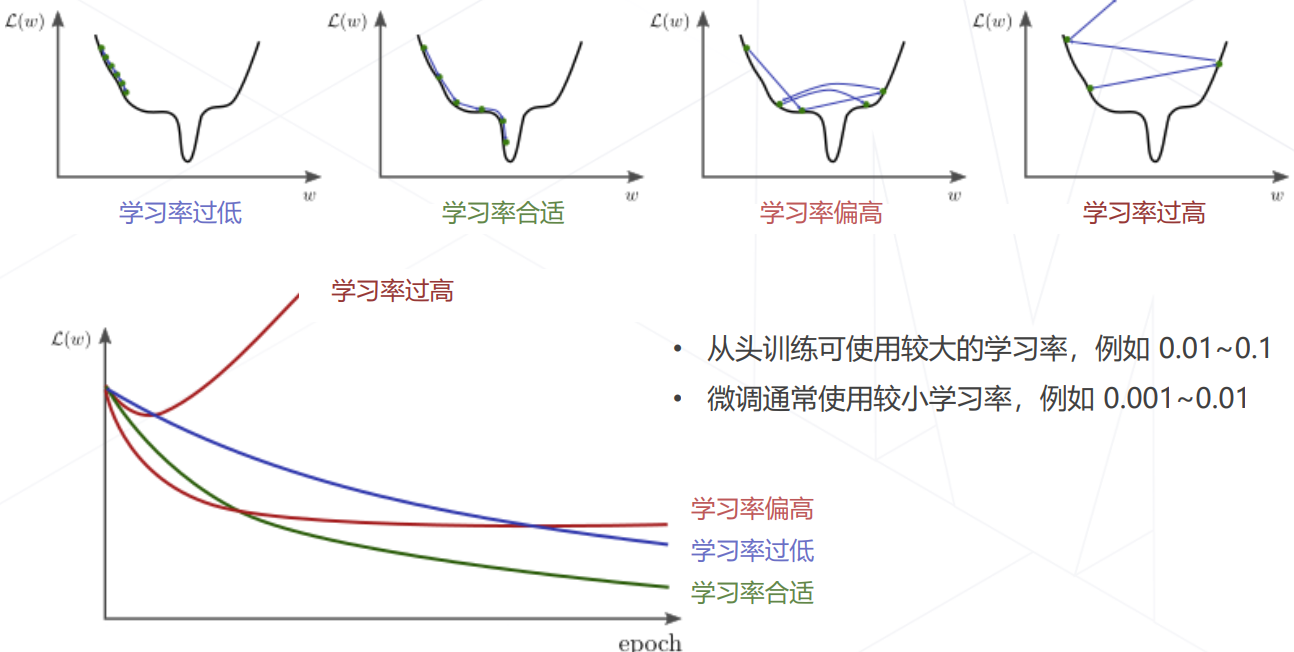
学习率与优化器策略
-
权重初始化:

-
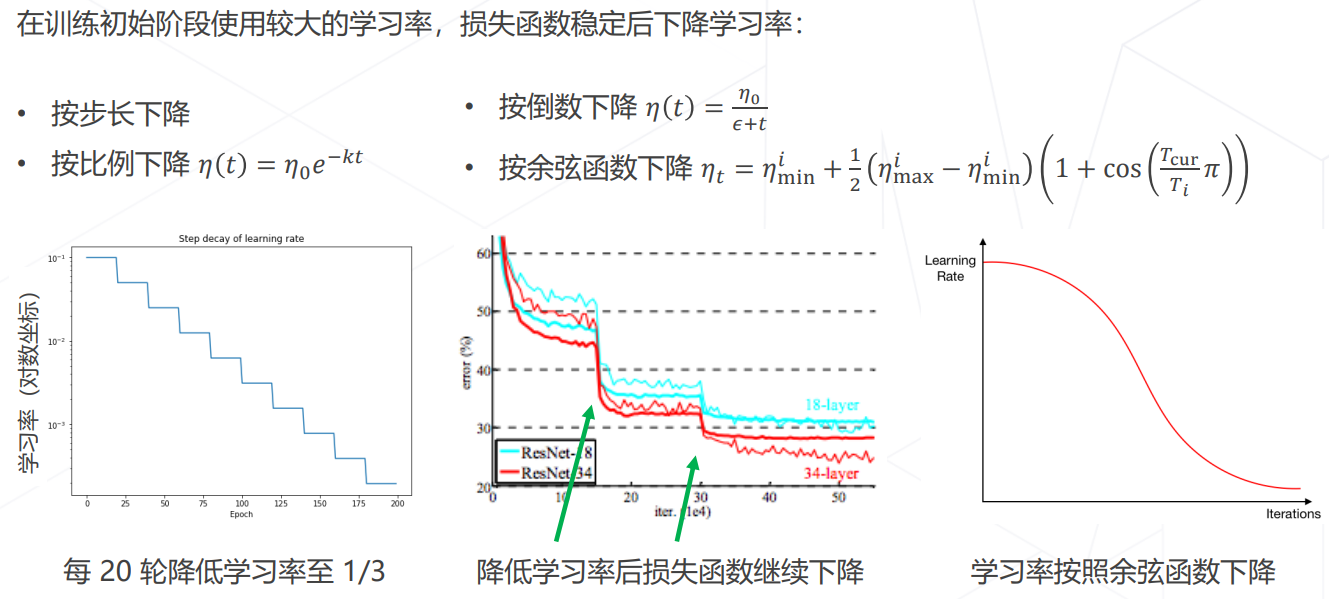
学习率退火 Annealing:
-
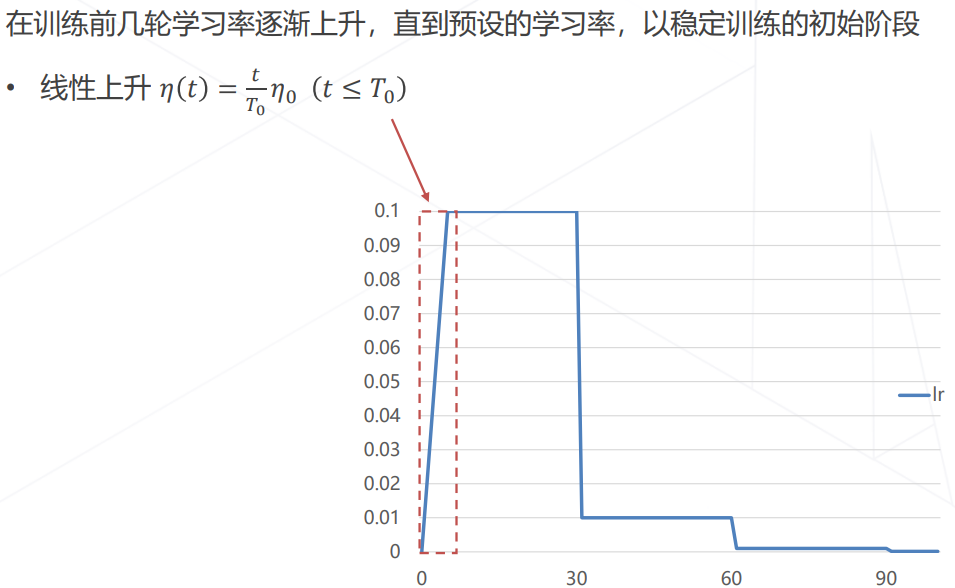
学习率升温 Warmup:
-
Linear Scaling Rule:

-
自适应梯度算法:
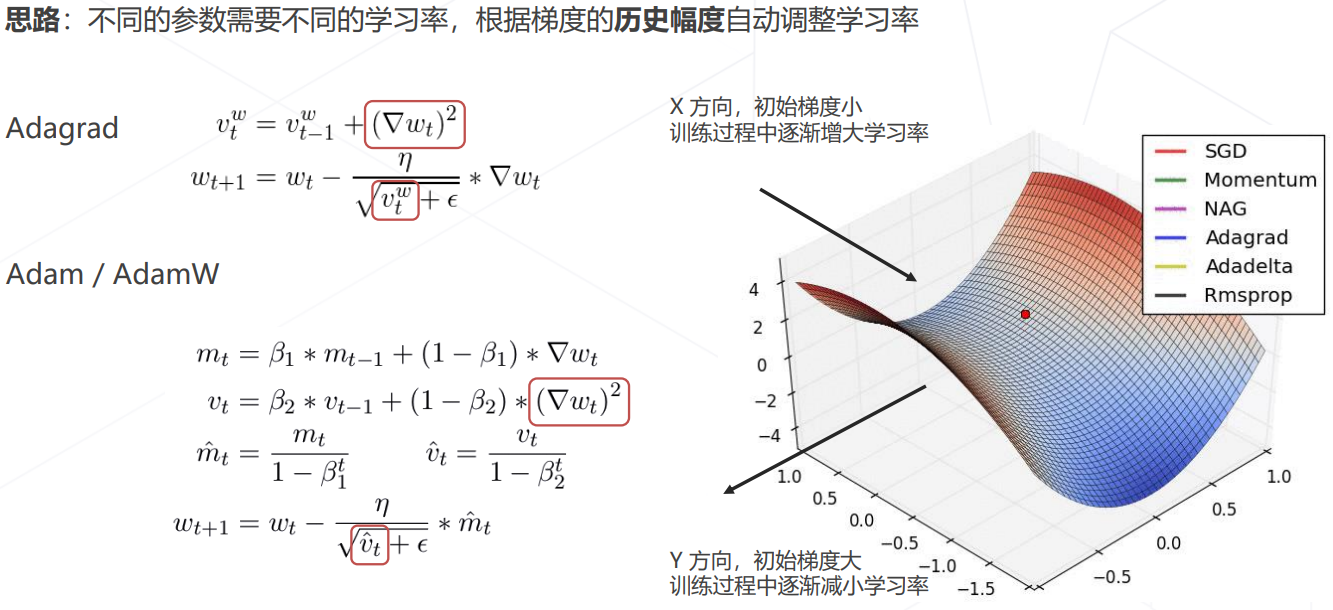
-
正则化与权重衰减 Weight Decay:

-
早停 Early Stopping:
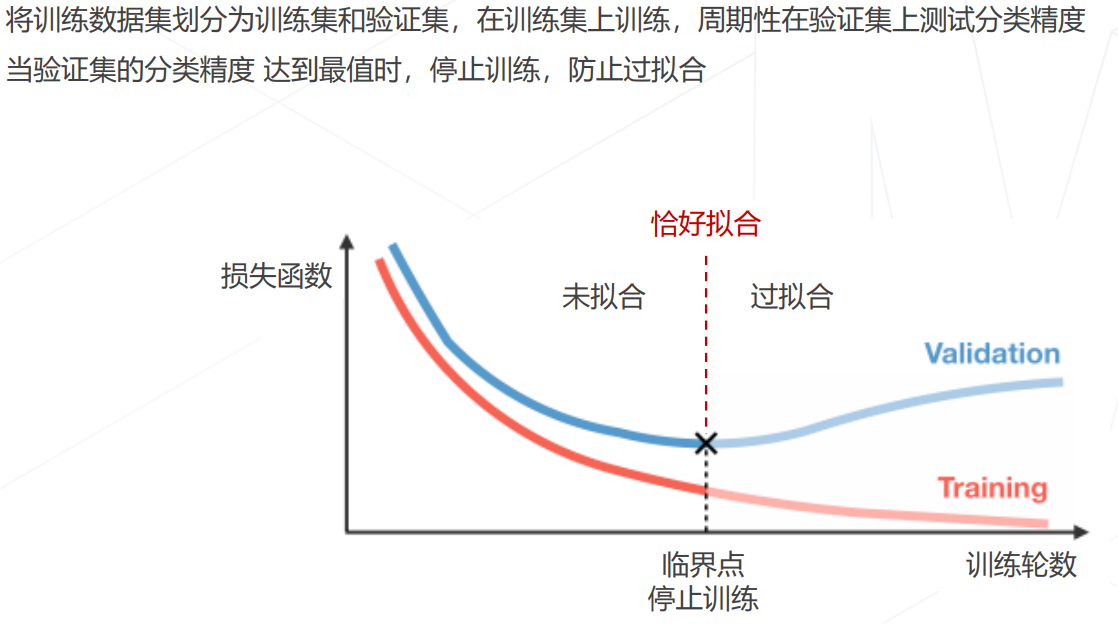
-
模型权重平均 EMA:
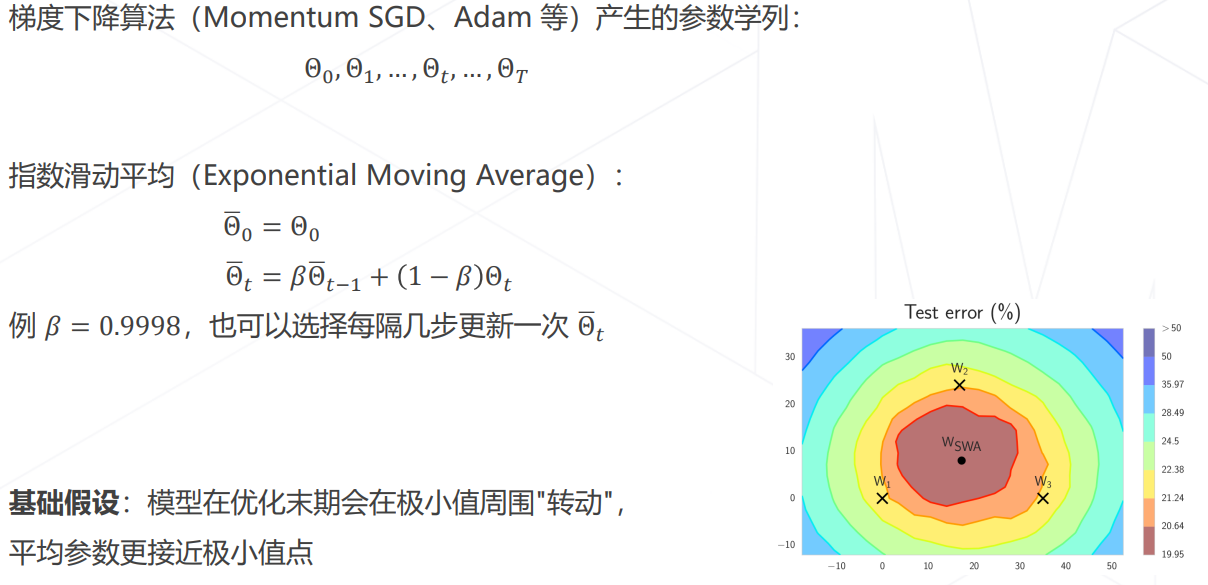
-
模型权重平均 Stochastic Weight Averaging:

数据增强

- 组合数据增强 AutoAugment & RandAugment

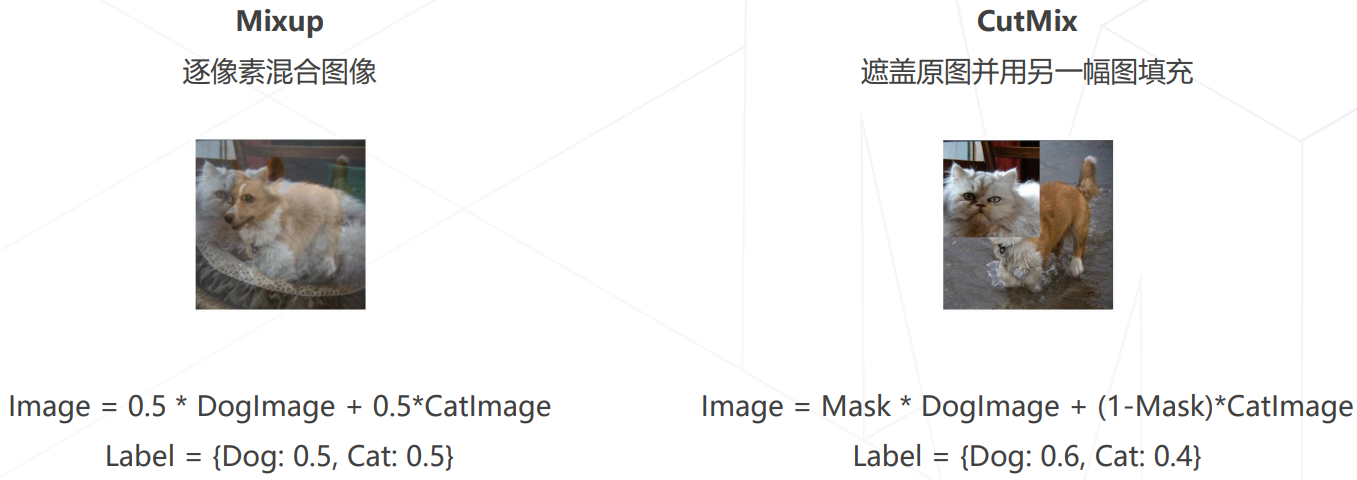
- 组合图像 Mixup & CutMix
- 标签平滑 Label Smoothing:
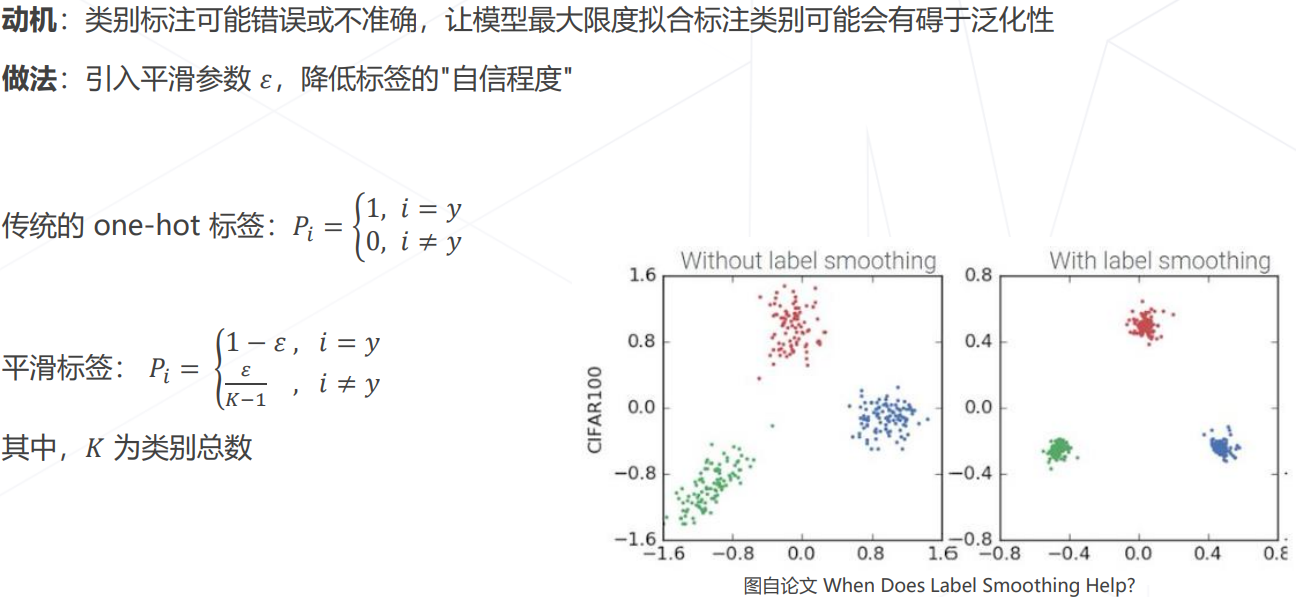
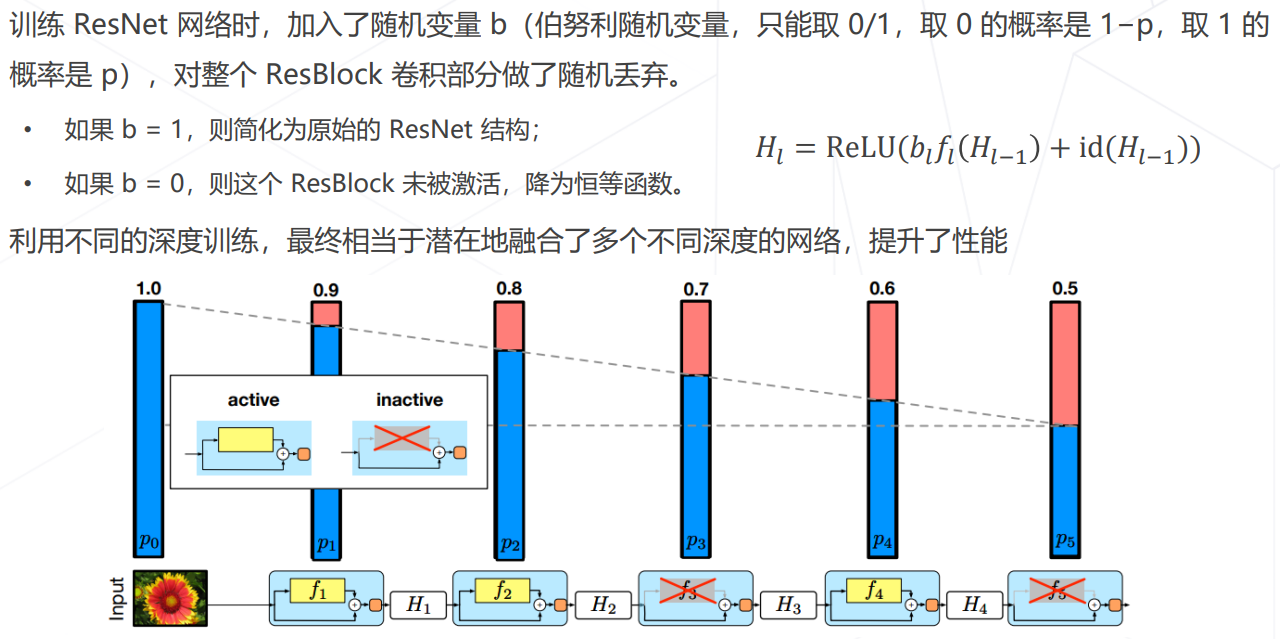
模型相关策略
丢弃层 Dropout

随机深度 Stochastic Depth
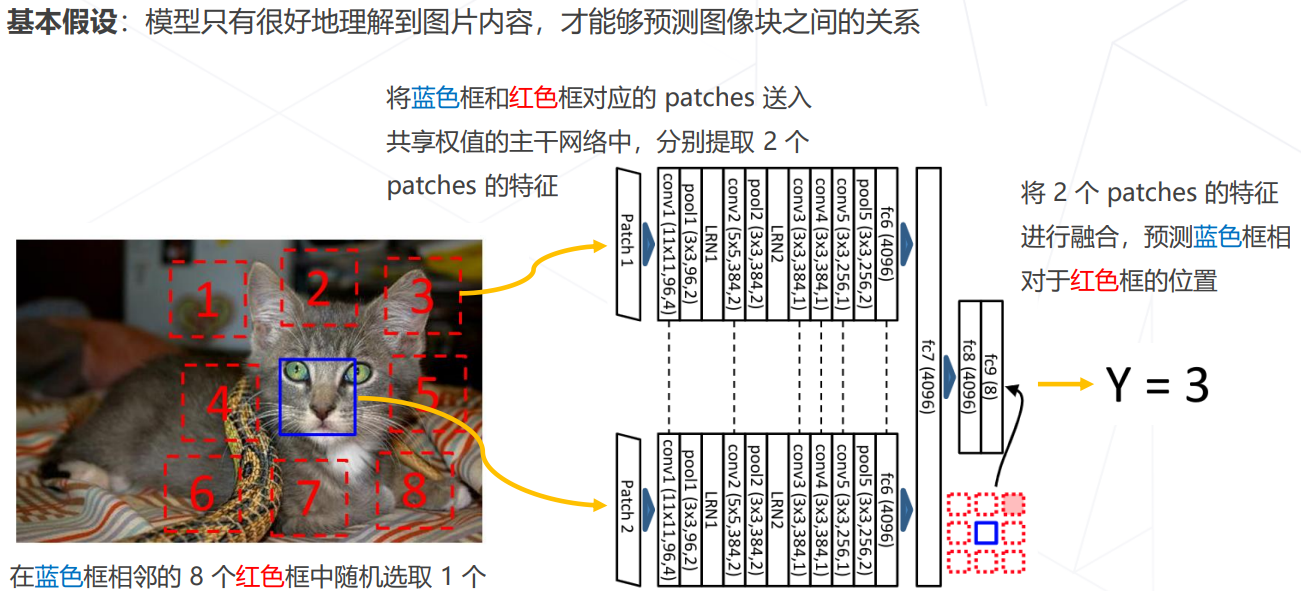
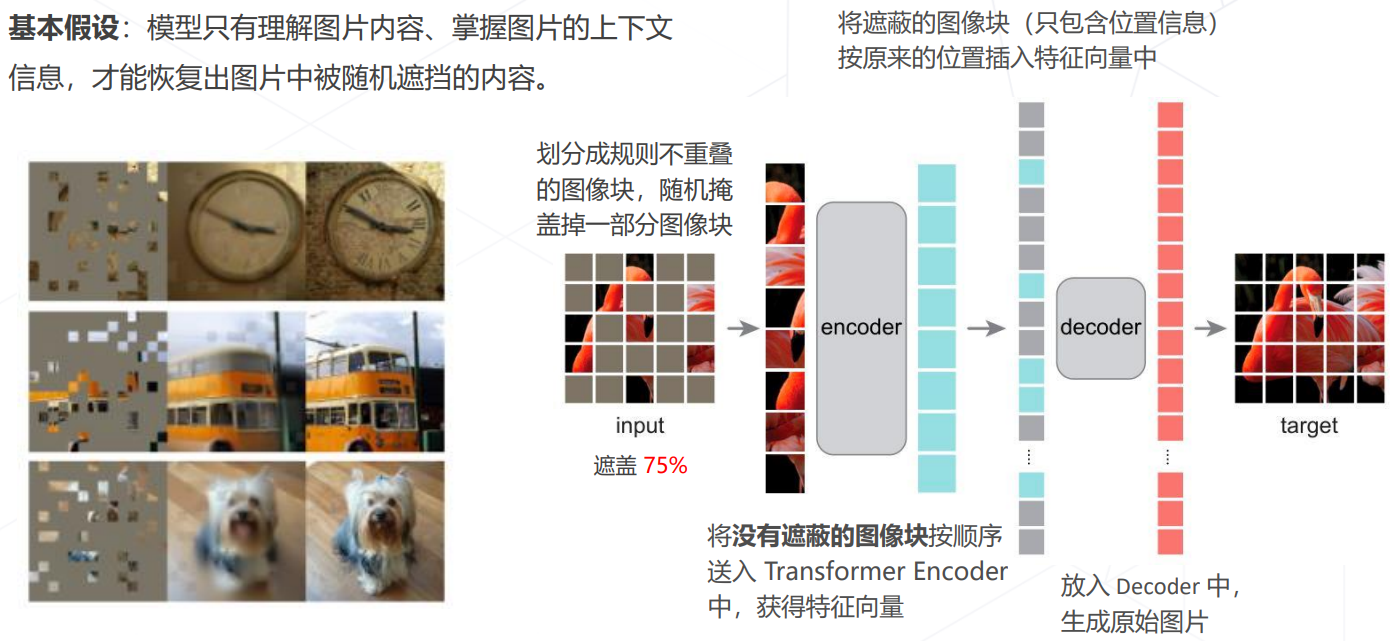
自监督学习

Relative Location (ICCV 2015)
SimCLR (ICML 2020)

Masked autoencoders (MAE, CVPR 2022)
MMClassification 介绍

后面笔记的具体内容放到 day3 的代码实现部分更好一点,因此笔记到这里就结束啦。