在 Python 的 Beautiful Soup 库中,NavigableString 对象用于表示解析树中的文本内容。
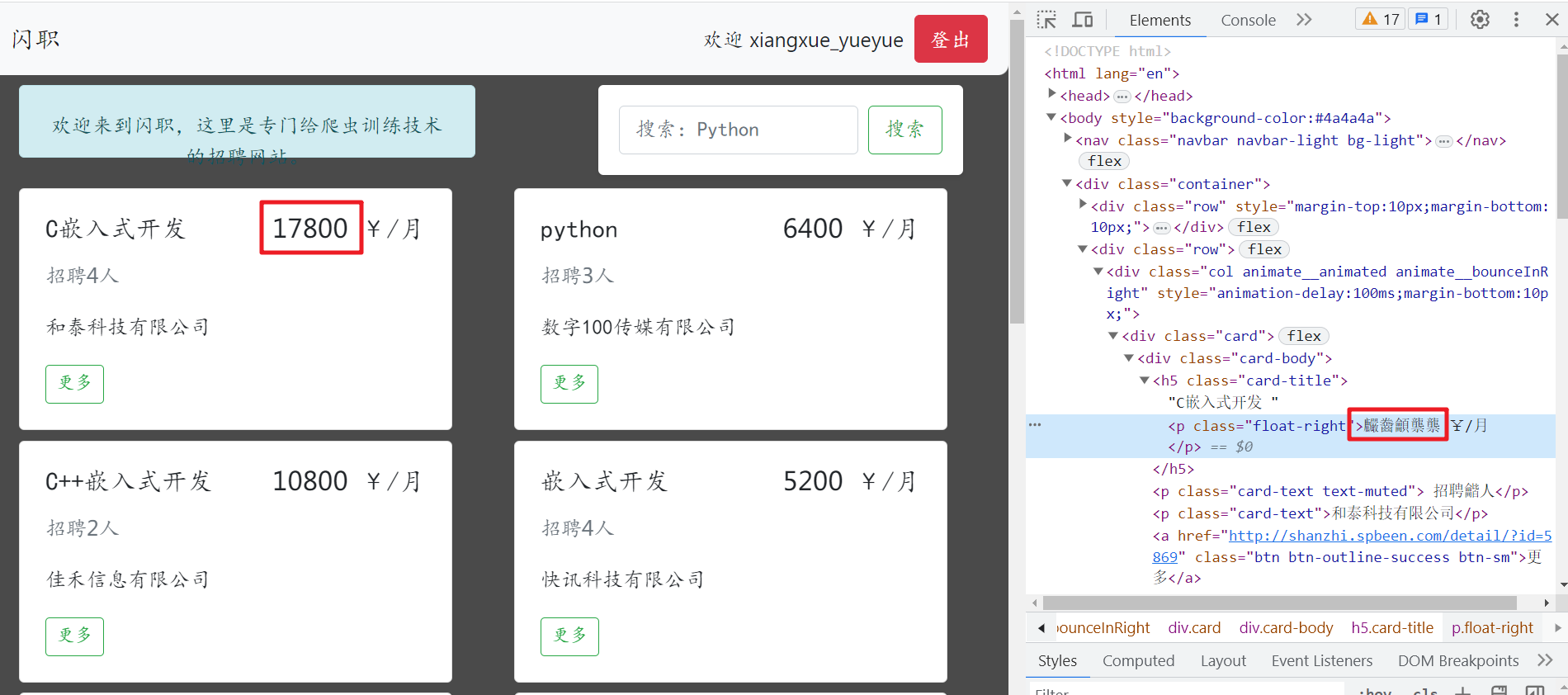
有时候在获取json格式,解析BeautifulSoup的时候,可能会遇到这个问题。
那可能是在 NavigableString 对象上调用 .text 属性,因此就会出现 'NavigableString' object has no attribute 'text' 的错误。
以下是一些解决这个问题的方法:
-
使用
prettify():检查解析树:
如果你不确定如何获取文本,可以打印整个解析树来查看结构:print(soup.prettify())prettify() 可以将所有节点变得格式化,规范化, 这将帮助你理解
NavigableString对象在文档中的位置,但是要注意它最后会输出成str。详细写法:

-
通过父标签获取文本:
如果你尝试获取一个标签内的文本,应该使用其 父标签 的.text属性,而不是NavigableString对象的属性。例如:from bs4 import BeautifulSoup html = '<div>Some text <b>and some bold text</b></div>' soup = BeautifulSoup(html, 'html.parser') div_text = soup.div.text print(div_text) # 输出: 'Some text and some bold text' -
转换为字符串:
如果你需要从NavigableString对象获取文本,可以直接将其转换为字符串:nav_string = soup.div.b.string text = str(nav_string) print(text) # 输出: 'and some bold text' -
使用
.strip()方法:
NavigableString对象的文本可能包含额外的空格或换行符。使用.strip()方法可以清除这些空白字符:stripped_text = nav_string.strip() print(stripped_text) -
遍历解析树:
如果需要从复杂的 HTML 文档中提取文本,可以遍历解析树并收集所有NavigableString对象的文本:texts = [element.strip() for element in soup.div.descendants if isinstance(element, NavigableString)] -
检查文档类型:
确保你使用的是正确的解析器(如html.parser或lxml),并且 HTML 文档是正确解析的。 -
更新 Beautiful Soup 库:
如果你使用的是较旧版本的 Beautiful Soup,可能会遇到一些已知的问题或不一致的行为。尝试更新到最新版本:pip install --upgrade beautifulsoup4
通过这些方法,你应该能够解决 'NavigableString' object has no attribute 'text' 的问题,并正确地从 Beautiful Soup 解析树中提取文本啦!


















![[C++] 深入浅出list容器](https://img-blog.csdnimg.cn/img_convert/d205e4c28334a9540856347a4892d5ff.png)