原创文章第603篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。
我们重新更新了可转债的全量数据,包含全量已经退市的转债。
——这是与股票市场不一样的地方,股票退市相对少,而转债本身就有退出周期。
因此,如果没有包含进来,那么策略就是有偏差的。
双低指标,单调性非常好:
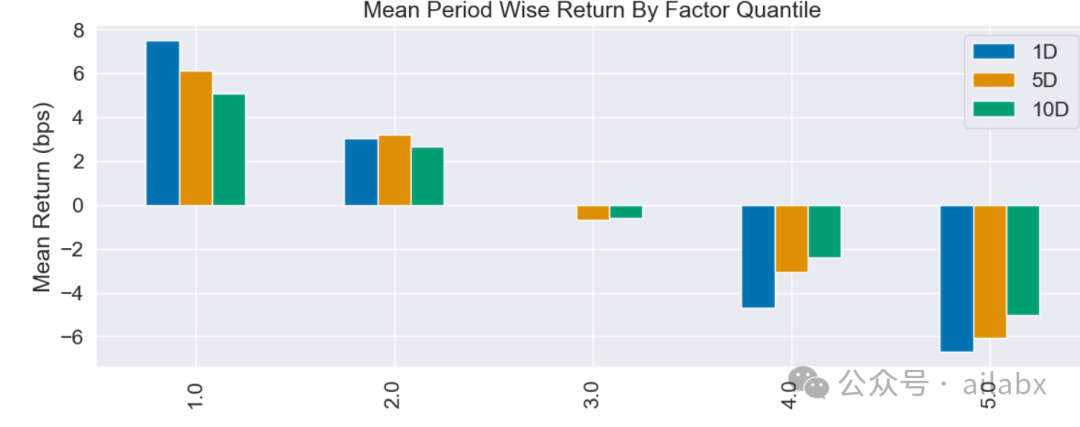
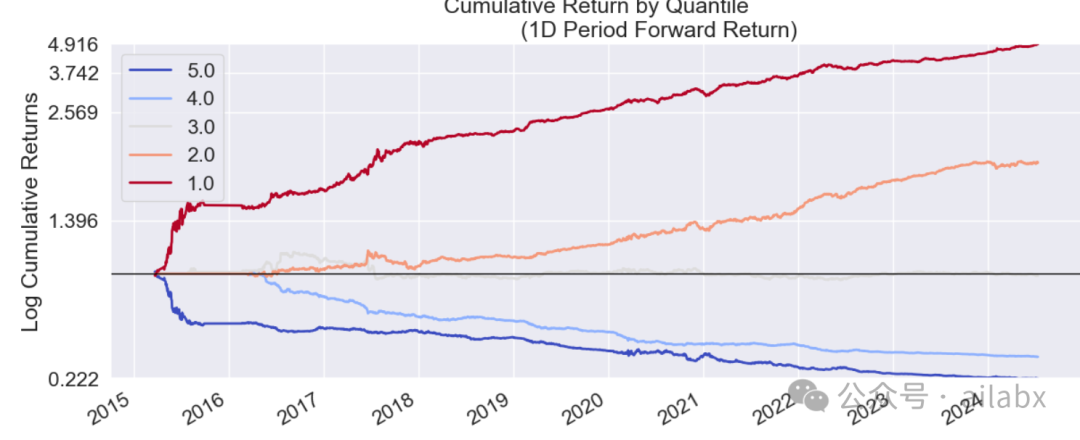
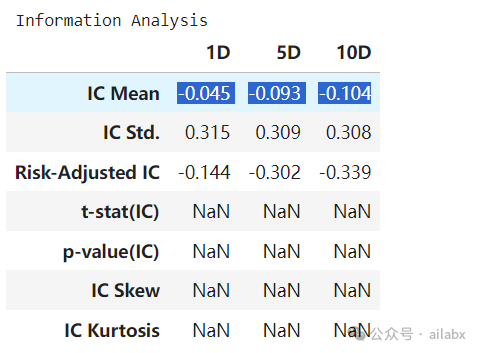
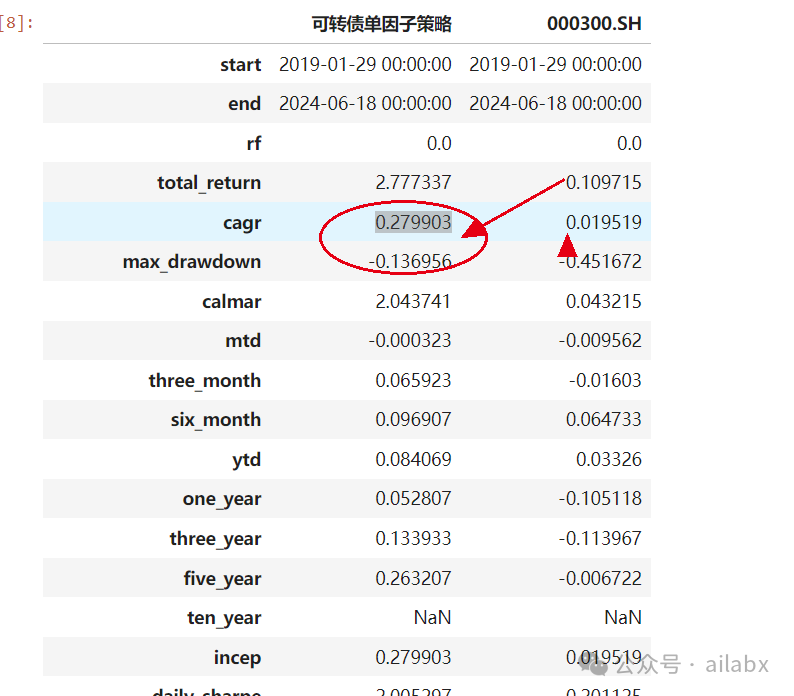
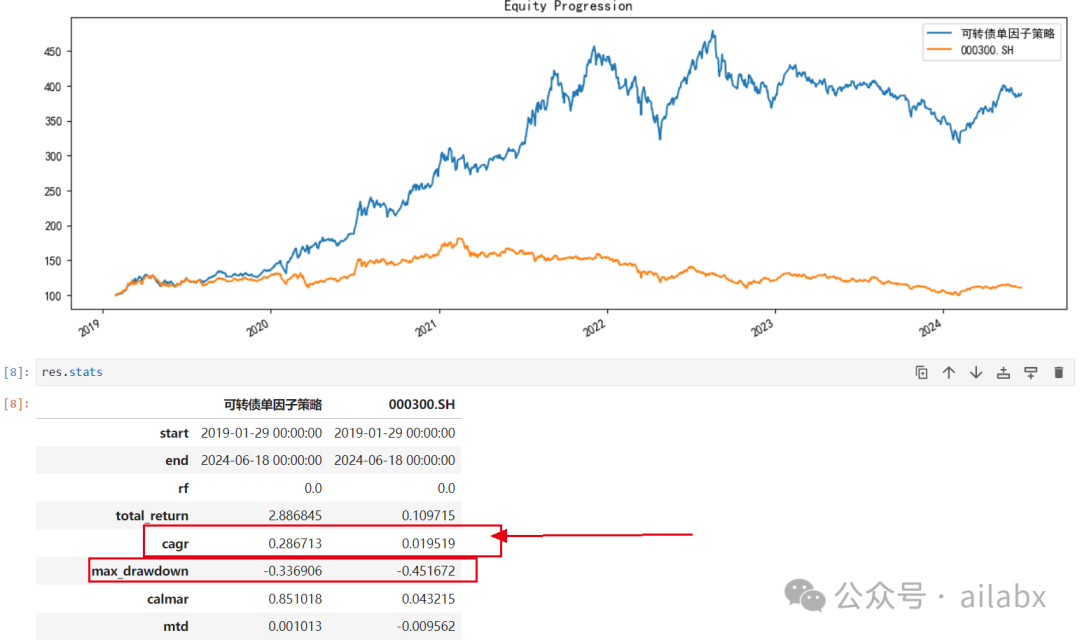
单因子回测一下:
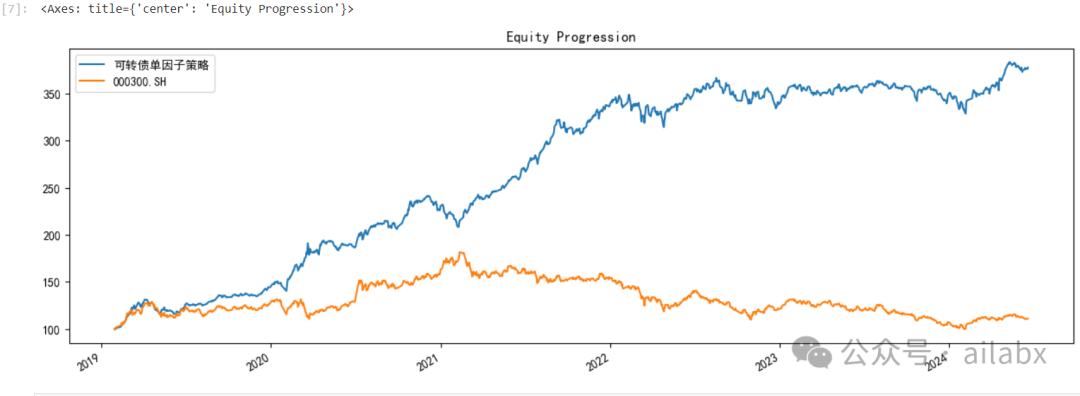
年化27.9%,最大回撤-13.6%。
策略核心代码如下:
import bt
from bt_algos_extend import SelectTopK
order_by = 'close'#'double_low'#'double_low'
signal = CSVDataloader.get_col_df(df,col=order_by)
#signal.dropna(inplace=True)
all = []
for K in [30,]:
s = bt.Strategy('可转债单因子策略'.format(K), [
bt.algos.RunWeekly(),
SelectTopK(signal,K,sort_descending=False),
bt.algos.WeighEqually(),
bt.algos.Rebalance()])
all.append(s)
stras = [bt.Backtest(s, data) for s in all]
把转债的价格单独拆分出来:
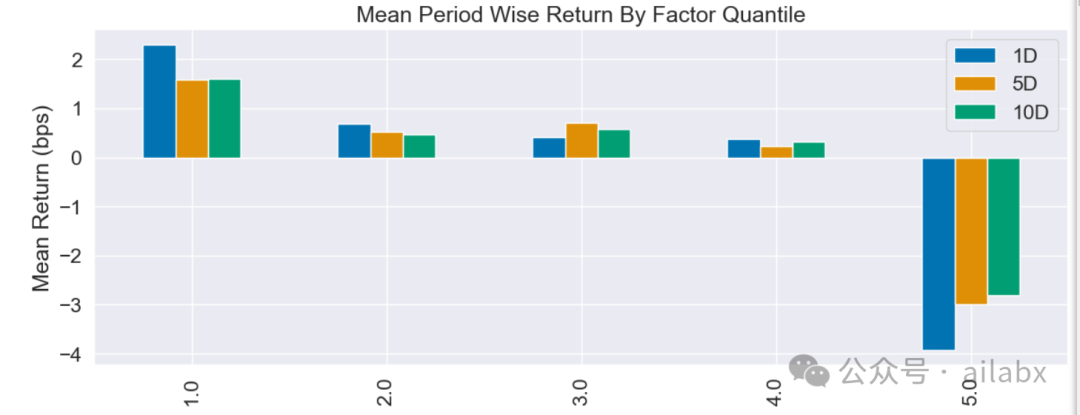
分层单调性一般:
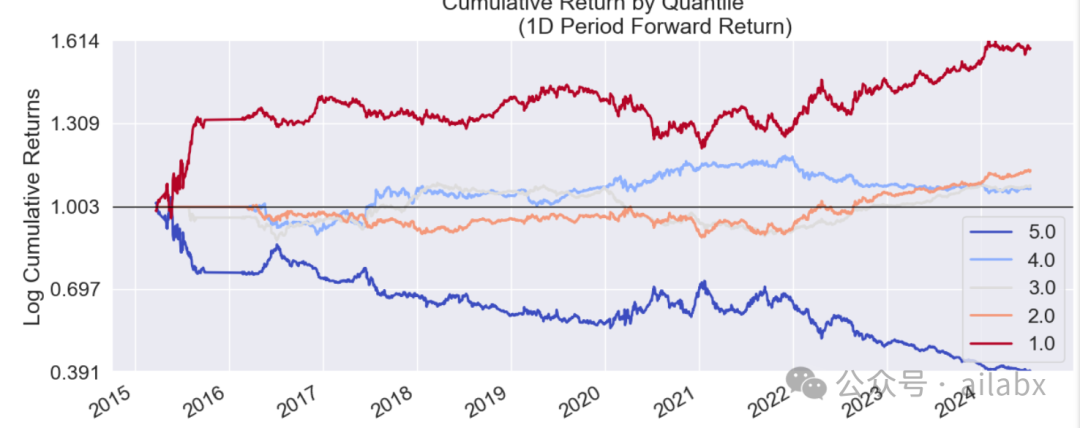
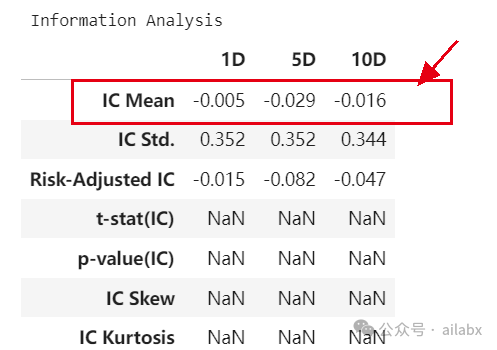
IC值很好,但回测结果一般。
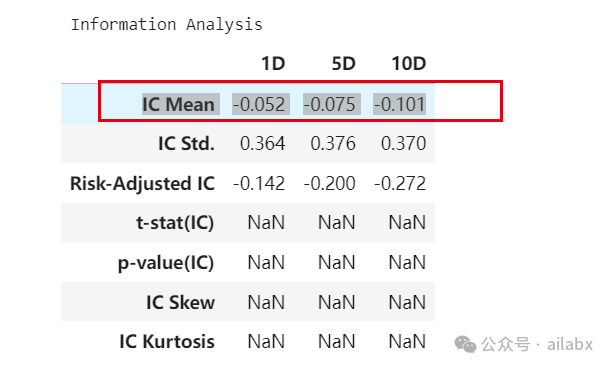
回测结果,年化12.6%,最大回撤-11.7%。
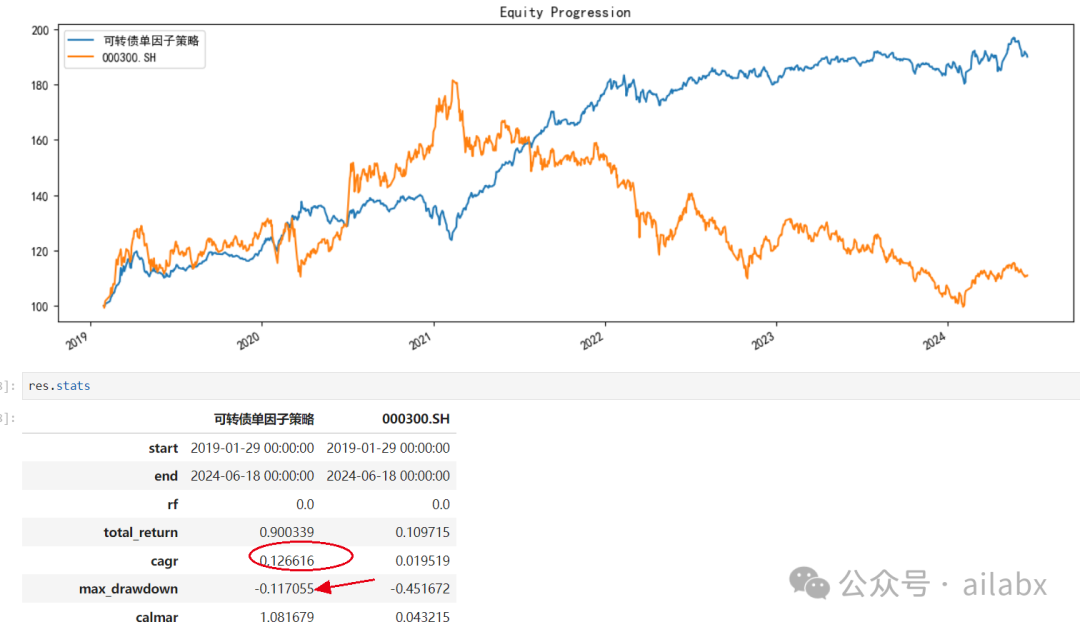
转股溢价率因子——单调性良好:
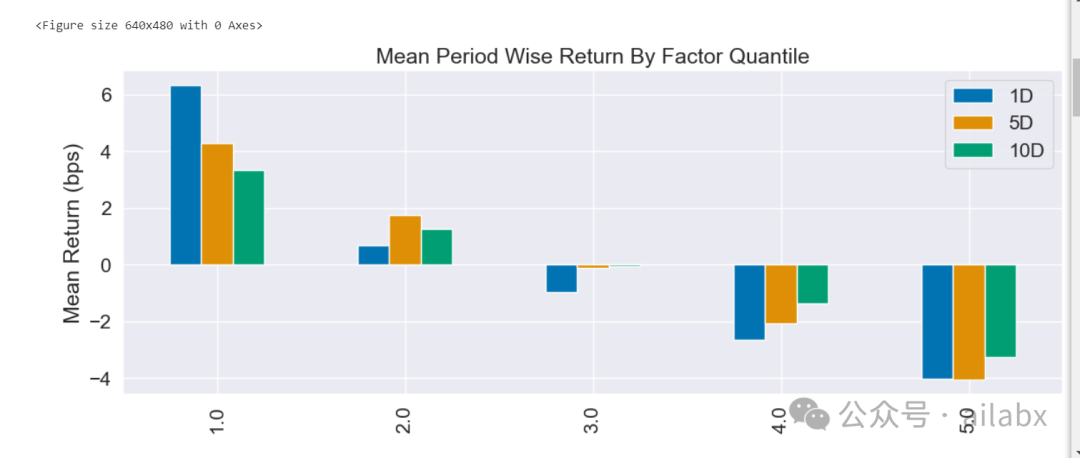
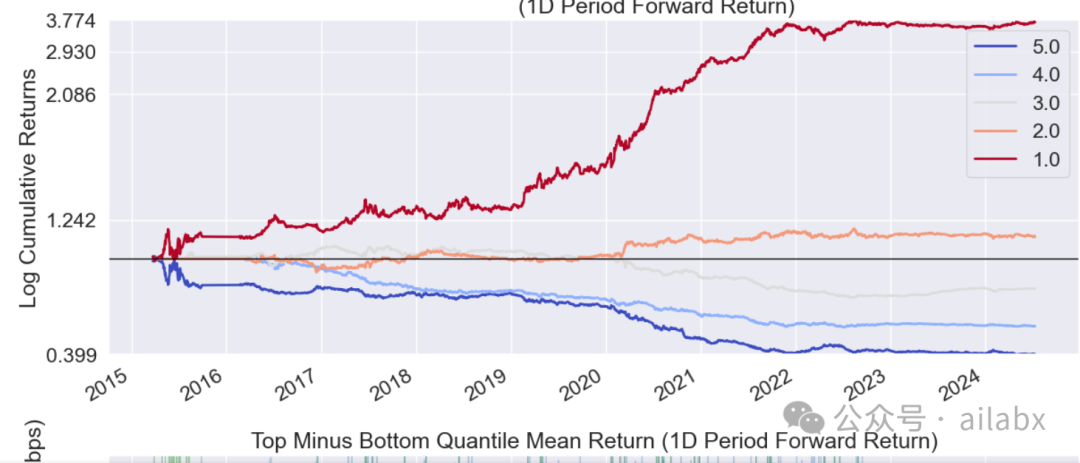
IC值一般:
年化28.6%,回撤-33.6%。
三个因子的分析结果看下来,有一个简单的结果:
分层单调性,对于轮动因子非常。
IC值大,但分层效果不好,大概率因子里包含了非线性因素。
IC值大的因子,可以经由机器学习模型来组合。
今天我们开始用机器学习的方式来初筛因子集。
咱们还是使用lightGBM集成学习的方式,决策树是可以筛选特征的重要性的。
import pandas as pd
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error, r2_score
def calc_metrics(model, X, y):
y_pred = model.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print('r2:', r2, 'mse:', mse)
def split_data(df, date):
df_train = df[df.index <= date]
df_val = df[df.index > date]
return df_train, df_val
def train(df_train, df_val, feature_cols, label_col='label'):
model = LGBMRegressor(boosting='gbdt', # gbdt \ dart
n_estimators=600, # 迭代次数
learning_rate=0.1, # 步长
max_depth=10, # 树的最大深度
seed=42, # 指定随机种子,为了复现结果
num_leaves=250,
# min_split_gain=0.01,
lambda_l1=2,
lambda_l2=2000
)
X_train = df_train[feature_cols]
y_train = df_train[label_col]
X_test = df_val[feature_cols]
y_test = df_val[label_col]
model.fit(X_train, y_train)
calc_metrics(model, X_train, y_train)
calc_metrics(model, X_test, y_test)
"""模型保存"""
from config import DATA_DIR
# model.booster_.save_model(DATA_DIR.joinpath('models').joinpath('lgb_regressor.txt'))
feat_importances = pd.Series(model.feature_importances_, index=X_train.columns).sort_values(ascending=False)
print(feat_importances.head(20))
return model
if __name__ == '__main__':
import pandas as pd
from config import DATA_DIR_BASIC
from datafeed.dataloader import CSVDataloader
# bonds = pd.read_csv(DATA_DIR_BASIC.joinpath('cb_list2.csv'))
# bonds = bonds[bonds['delist_date'] is None]
# bonds = bonds['ts_code']
df = CSVDataloader.get_df(symbols=None, set_index=True, start_date='20190101', path='bonds_all')
print(df)
df = CSVDataloader.calc_expr(df, ['close+cb_over_rate', 'roc(close,20)', 'ta_cci(high,low,close,20)',
'shift(close,-10)/close-1'],
['double_low', 'roc_20', 'cci_20', 'label'])
df.dropna(inplace=True)
df_train, df_val = split_data(df, '2023-12-31')
train(df_train, df_val, feature_cols=['cb_over_rate','close','bond_value','cb_value','ps_ttm','bond_over_rate','double_low', 'pb','pe_ttm'], label_col='label')
机器学习的权重排序:
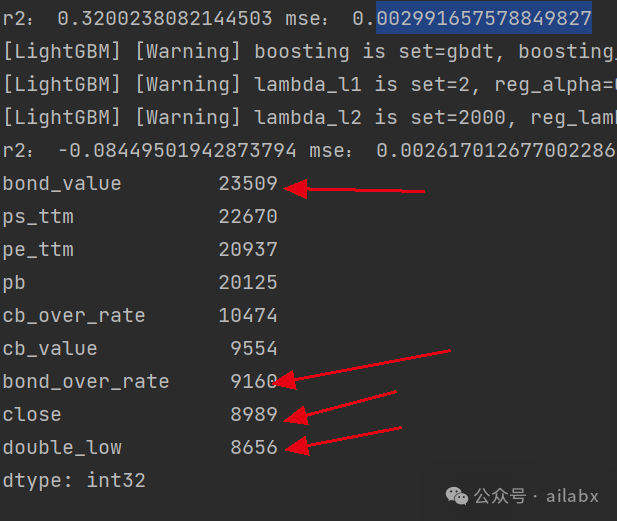
bond_value IC值不明显,分层不单调,但lightGBM的权重重要性很高。这一点是比较矛盾的。
代码在这里:
AI量化实验室——2024量化投资的星辰大海
吾日三省吾身
欲速则不达。——这句老话非常有道理。
有时候,我们总希望把一些不喜欢的事情,尽快终结掉。
在评估不够充分时就快速推进事情。
结果有可能,事情也许办了,但引入其他更加不可控的事情。
有时候,淡定一点,把事情处理得稳妥一点,后续的事情会更少。
好事多磨,淡定一点。
历史文章:
全量可转债:平价底价溢价率与正股PB的单因子分析(附python代码)
代码发布:quantlabv5.3,可转债所有数据及双低、动量因子策略,单因子分析框架
量化私募公司的多因子构建方案(附python代码)
年化22.8%的单因子分析:基于Alphalens做可转债全市场数据的单因子分析(附python代码+全量数据)
AI量化实验室——2024量化投资的星辰大海



















