Retrieval Augmentor 检索增强器
RetrievalAugmentor 是 RAG 管道的入口点。它负责使用从各种来源检索的相关 Content 来扩充 ChatMessage 。
可以在创建 AiService 期间指定 RetrievalAugmentor 的实例:
Assistant assistant = AiServices.builder(Assistant.class)
...
.retrievalAugmentor(retrievalAugmentor)
.build();每次调用 AiService 时,都会调用指定的 RetrievalAugmentor 来扩充当前的 UserMessage 。
可以使用LangChain4j中提供的 RetrievalAugmentor 的默认实现(DefaultRetrievalAugmentor) 或 实现自定义实现。
Default Retrieval Augmentor 默认检索增强器
LangChain4j 提供了RetrievalAugmentor接口的现成实现: DefaultRetrievalAugmentor ,它应该适合大多数 RAG 用例。
官方使用示例:
public class _04_Advanced_RAG_with_Metadata_Example {
/**
* Please refer to {@link Naive_RAG_Example} for a basic context.
* <p>
* Advanced RAG in LangChain4j is described here: https://github.com/langchain4j/langchain4j/pull/538
* <p>
* This example illustrates how to include document source and other metadata into the LLM prompt.
*/
public static void main(String[] args) {
Assistant assistant = createAssistant("documents/miles-of-smiles-terms-of-use.txt");
// Ask "What is the name of the file where cancellation policy is defined?".
// Observe how "file_name" metadata entry was injected into the prompt.
startConversationWith(assistant);
}
private static Assistant createAssistant(String documentPath) {
Document document = loadDocument(toPath(documentPath), new TextDocumentParser());
EmbeddingModel embeddingModel = new BgeSmallEnV15QuantizedEmbeddingModel();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(300, 0))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.build();
// Each retrieved segment should include "file_name" and "index" metadata values in the prompt
ContentInjector contentInjector = DefaultContentInjector.builder()
// .promptTemplate(...) // Formatting can also be changed
.metadataKeysToInclude(asList("file_name", "index"))
.build();
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentRetriever(contentRetriever)
.contentInjector(contentInjector)
.build();
ChatLanguageModel chatLanguageModel = OpenAiChatModel.builder()
.apiKey(OPENAI_API_KEY)
.baseUrl(OPENAI_API_URL)
.logRequests(true)
.build();
return AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.retrievalAugmentor(retrievalAugmentor)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();
}
}源码逻辑梳理:
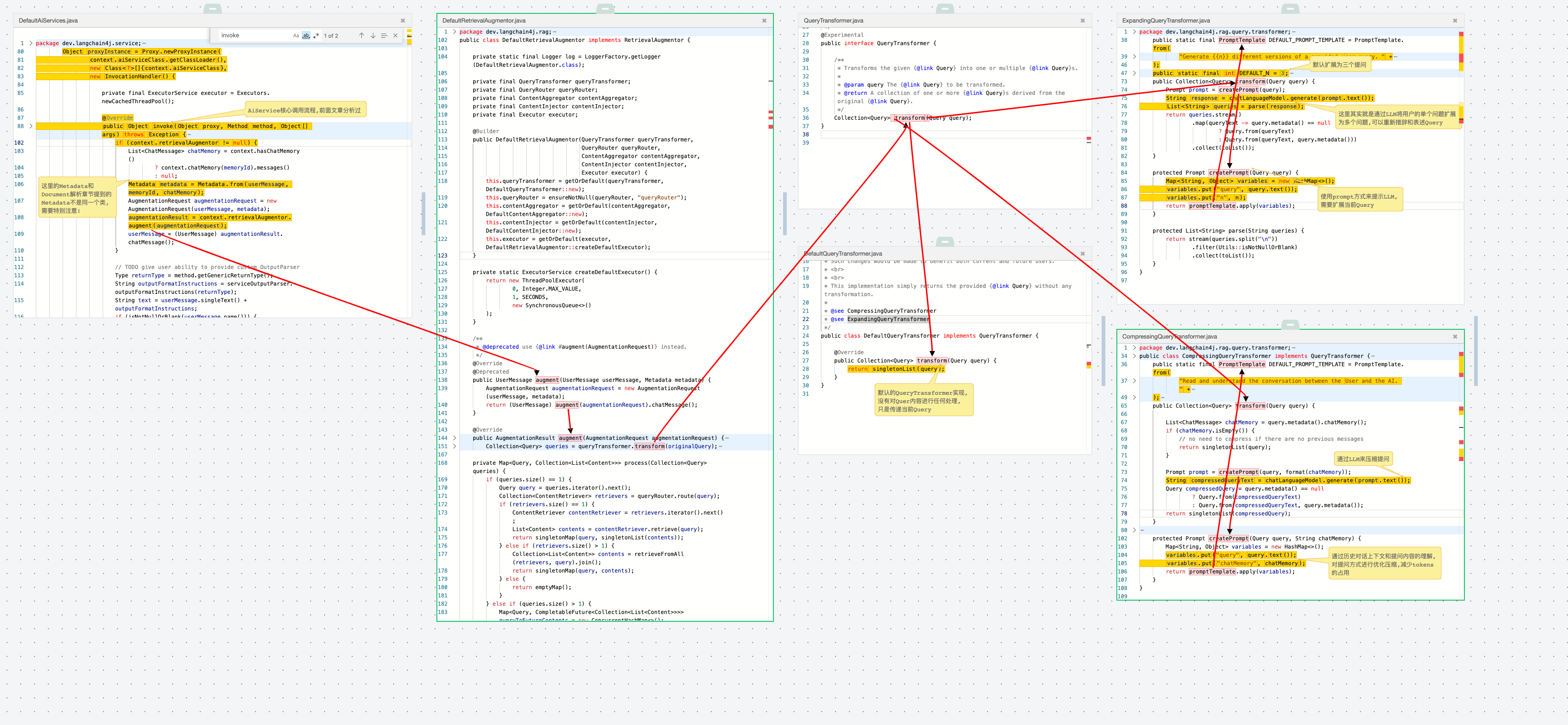
- 用户在定义
AiService的时候需要设置是否需要检索增强器 - 在触发
AiService的调用的时候会在invoke()函数中检查是否有添加RetrievalAugmentor增强器 - 如果有则会调用
context.retrievalAugmentor.augment(augmentationRequest)对Query进行处理:
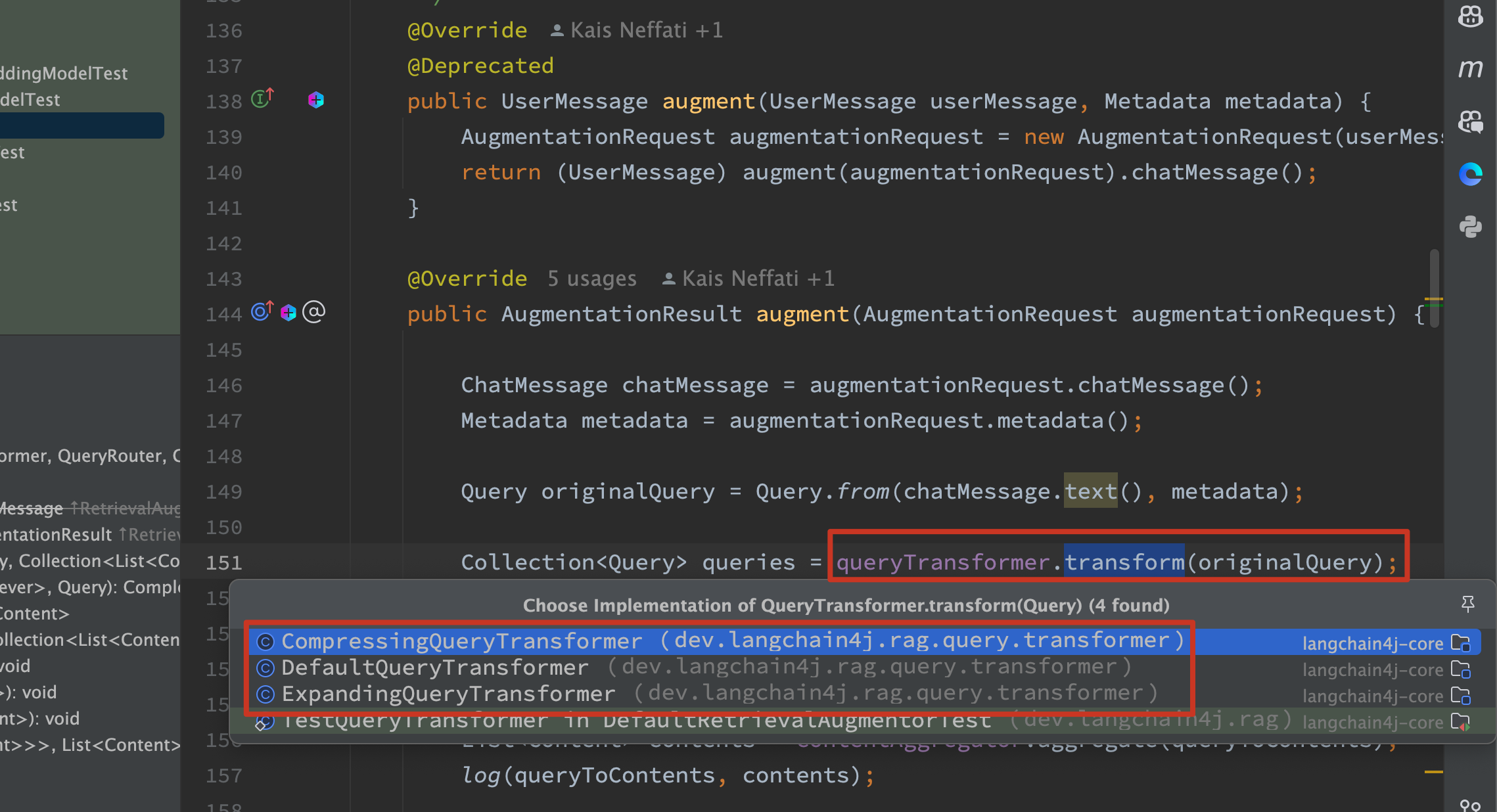
augment()方法中使用的QueryTransformer有三种实现类:
-
DefaultQueryTransformer: 默认的转换器,不会对Query做任何处理,而是封装成集合后返回。ExpandingQueryTransformer: 扩展转换器,对Query进行措辞的修改和拆分为多个(默认3个)具体的Query,达到增强效果。CompressingQueryTransformer:压缩转换器,根据提供的历史聊天和当前提问内容,LLM理解后会给出更精确的提问。
Query
Query表示 RAG 管道中的用户查询。它包含查询文本和查询元数据。
Query Metadata 查询元数据
Query中的Metadata包含可能对 RAG 管道的各个组件有用的信息,例如:
Metadata.userMessage()- 应该增强的原始UserMessageMetadata.chatMemoryId()-@MemoryId注释的方法参数的值。这可用于识别用户并在检索期间应用访问限制或过滤器。Metadata.chatMemory()- 所有历史的ChatMessages。这可以帮助理解提出Query的上下文。
Query Transformer 查询转换
QueryTransformer将给定的Query转换为一个或多个Query 。目标是通过修改或扩展原始Query来提高检索质量。
一些已知的改进检索的方法包括:
- Query compression 查询压缩
- Query expansion 查询扩展
- Query re-writing 查询重写
- Step-back prompting 后退提示
- Hypothetical document embeddings (HyDE) 假设文档嵌入
Content
Content表示与用户Query相关的内容。目前,它仅限于文本内容(即TextSegment ),但将来它可能支持其他模式(例如,图像、音频、视频等)。
Content Retriever 内容检索
ContentRetriever使用给定的Query从底层数据源检索Content 。底层数据源几乎可以是任何东西:
Embedding store陷入存储Full-text search engine全文搜索引擎Hybrid of vector and full-text search矢量和全文搜索的混合Web Search Engine网络搜索引擎Knowledge graph知识图谱SQL databaseSQL数据库
Embedding Store Content Retriever 嵌入存入内容检索
EmbeddingStoreContentRetriever使用EmbeddingModel来嵌入Query从EmbeddingStore检索相关Content 。
使用示例:
EmbeddingStore embeddingStore = ...
EmbeddingModel embeddingModel = ...
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
// maxResults can also be specified dynamically depending on the query
.dynamicMaxResults(query -> 3)
.minScore(0.75)
// minScore can also be specified dynamically depending on the query
.dynamicMinScore(query -> 0.75)
.filter(metadataKey("userId").isEqualTo("12345"))
// filter can also be specified dynamically depending on the query
.dynamicFilter(query -> {
String userId = getUserId(query.metadata().chatMemoryId());
return metadataKey("userId").isEqualTo(userId);
})
.build();Web Search Content Retriever 网络搜索内容
WebSearchContentRetriever使用WebSearchEngine从网络检索相关Content 。
目前WebSearchEngine接口有 2 个实现:
langchain4j-web-search-engine-google-custom模块中的GoogleCustomWebSearchEnginelangchain4j-web-search-engine-tavily模块中的TavilyWebSearchEngine
使用示例:
WebSearchEngine googleSearchEngine = GoogleCustomWebSearchEngine.builder()
.apiKey(System.getenv("GOOGLE_API_KEY"))
.csi(System.getenv("GOOGLE_SEARCH_ENGINE_ID"))
.build();
ContentRetriever contentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(googleSearchEngine)
.maxResults(3)
.build();SQL Database Content Retriever SQL数据库内容检索
SqlDatabaseContentRetriever是ContentRetriever的实验性实现,可以在langchain4j-experimental-sql模块中找到。后续可能会删除或改动较大,所以并不推荐直接使用到生产。
它使用DataSource和LLM为给定的自然语言Query生成并执行 SQL 查询。
使用示例:
public class _10_Advanced_RAG_SQL_Database_Retreiver_Example {
/**
* Please refer to {@link Naive_RAG_Example} for a basic context.
* <p>
* Advanced RAG in LangChain4j is described here: https://github.com/langchain4j/langchain4j/pull/538
* <p>
* This example demonstrates how to use SQL database content retriever.
* <p>
* WARNING! Although fun and exciting, {@link SqlDatabaseContentRetriever} is dangerous to use!
* Do not ever use it in production! The database user must have very limited READ-ONLY permissions!
* Although the generated SQL is somewhat validated (to ensure that the SQL is a SELECT statement),
* there is no guarantee that it is harmless. Use it at your own risk!
* <p>
* In this example we will use an in-memory H2 database with 3 tables: customers, products and orders.
* See "resources/sql" directory for more details.
* <p>
* This example requires "langchain4j-experimental-sql" dependency.
*/
public static void main(String[] args) {
Assistant assistant = createAssistant();
// You can ask questions such as "How many customers do we have?" and "What is our top seller?".
startConversationWith(assistant);
}
private static Assistant createAssistant() {
DataSource dataSource = createDataSource();
ChatLanguageModel chatLanguageModel = OpenAiChatModel.withApiKey(OPENAI_API_KEY);
ContentRetriever contentRetriever = SqlDatabaseContentRetriever.builder()
.dataSource(dataSource)
.chatLanguageModel(chatLanguageModel)
.build();
return AiServices.builder(Assistant.class)
.chatLanguageModel(chatLanguageModel)
.contentRetriever(contentRetriever)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();
}
private static DataSource createDataSource() {
JdbcDataSource dataSource = new JdbcDataSource();
dataSource.setURL("jdbc:h2:mem:test;DB_CLOSE_DELAY=-1");
dataSource.setUser("sa");
dataSource.setPassword("sa");
String createTablesScript = read("sql/create_tables.sql");
execute(createTablesScript, dataSource);
String prefillTablesScript = read("sql/prefill_tables.sql");
execute(prefillTablesScript, dataSource);
return dataSource;
}
private static String read(String path) {
try {
return new String(Files.readAllBytes(toPath(path)));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static void execute(String sql, DataSource dataSource) {
try (Connection connection = dataSource.getConnection(); Statement statement = connection.createStatement()) {
for (String sqlStatement : sql.split(";")) {
statement.execute(sqlStatement.trim());
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}Azure AI Search Content Retriever Azure AI 搜索内容检索
AzureAiSearchContentRetriever可以在langchain4j-azure-ai-search模块中找到。
Neo4j Content Retriever Neo4j 内容检索
Neo4jContentRetriever可以在langchain4j-neo4j模块中找到。
Query Router 查询路由
QueryRouter负责将Query路由到适当的ContentRetriever 。
Default Query Router 默认查询路由
DefaultQueryRouter是DefaultRetrievalAugmentor中使用的默认实现。它将每个Query路由到所有配置的ContentRetriever 。
Language Model Query Router 大语言模型查询路由
LanguageModelQueryRouter使用LLM决定将给定的Query路由到何处。