目录
1、字符串
1.1、字符串的常用操作
1.2、格式化字符串
1.2.1、占位符格式化字符串
1.2.2、f-string格式化字符串
1.2.3、str.format( )格式化字符串
1.3、数据的验证
1.4、正则表达式
1.5.1元字符
1.5.2限定符
1.5.3其他字符
1.5.4re模块
1、字符串
1.1、字符串的常用操作
| 方法名 | 描述说明 |
| str.lower() | 将str字符串全部转成小写字母,结果为一个新的字符串 |
| str.upper() | 将str字符串全部转成大写字母,结果为一个新的字符串 |
| str.split(sep=None) | 把str按照指定的分隔符sep进行分隔,结果为列表类型 |
| str.count(sub) | 结果为sub这个字符串在str中出现的次数 |
| str.find(sub) | 查询sub这个字符串在str中是否存在,如果不存在结果为-1,如果存在,结果为sub首次出现的索引 |
| str.index(sub) | 功能与find()相同,区别在于要查询的子串sub不存在时,程序报错 |
| str.startswith(s) | 查询字符串str是否以子串s开头 |
| str.endswith(s) | 查询字符串str是否以子串s结尾 |
| str.replace(old,news) | 使用news替换字符串s中所有的old字符串,结果是一个新的字符串 |
| str.center(width,fillchar) | 字符串str在指定的宽度范围内居中,可以使用fillchar进行填充 |
| str.join(iter) | 在iter中的每个元素的后面都增加一个新的字符串str |
| str.strip(chars) | 从字符串中去掉左侧和右侧chars中列出的字符串 |
| str.lstrip(chars) | 从字符串中去掉左侧chars中列出的字符串 |
| str.rstrip(chars) | 从字符串中去掉右侧chars中列出的字符串 |
1.2、格式化字符串
格式化字符串是指在字符串中插入特定的占位符,以便在运行时将变量的值动态地替换成字符串中的相应位置。
通过格式化字符串,可以方便地将变量的值和其他文本内容组合成一个完整的字符串。在许多编程语言中,都有内置的格式化字符串的函数或语法。
格式化字符串有3种方法:占位符、f-string、str.format( )。
1.2.1、占位符格式化字符串
当我们使用占位符时,有以下三种占位符时较为常用的:
| 占位符 | 描述 |
| %s | 替换字符串格式 |
| %d | 替换十进制整数格式 |
| %f | 替换浮点数格式 |
对于这几种占位符的使用,早在ROS学习笔记(九、Python编写服务器和客户端)中已有使用。【【链接如下:http://t.csdnimg.cn/j7mpV】】
在ros笔记中编写服务器时,我们编写的代码如下所示:
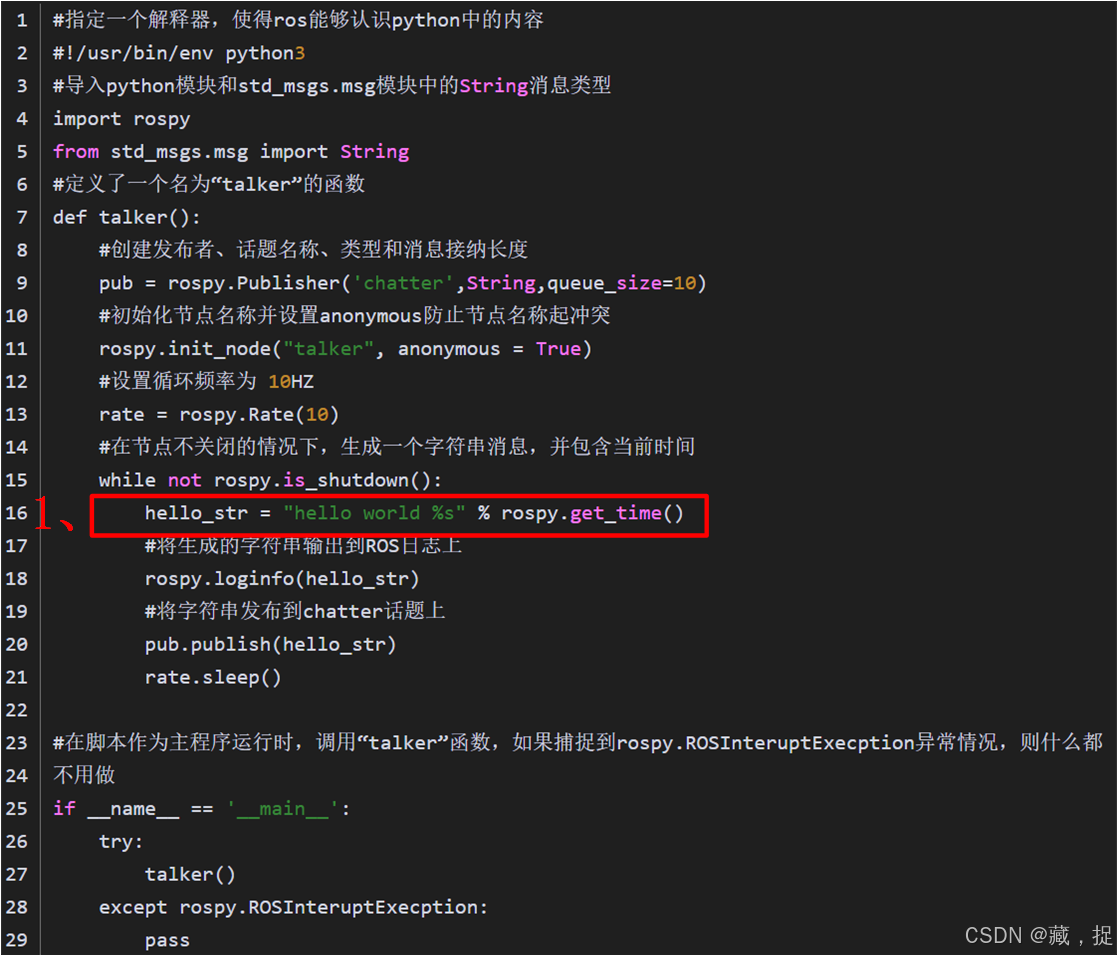
在1位置处,在一个完整的字符串中使用了%s占位符,在完整的字符串外面,则是变量的值,最后将会输出“ hello world ( time ) ”。
同理,可得%d和%f的使用方法。
1.2.2、f-string格式化字符串
f-string的使用格式早在我的PYTHON学习笔记(一、python基础语法)中有过涉及。具体代码如下所示:
【【链接如下:http://t.csdnimg.cn/nzLJe】】
name = '小鬼'
age = '18'
score = '99.99'
d1 = f'我的名字是:{name},我的年龄是:{age},我的考试的分数是:{score}'
print(d1)
输出结果:
我的名字是:小鬼,我的年龄是:18,我的考试的分数是:99.991.2.3、str.format( )格式化字符串
str.format( )格式化字符串的意思是:通过在大括号中放入序列号,按照序列号调用format( )函数中的变量的方法。
示例如下:
name = '小鬼'
age = '18'
score = '99.99'
d1 = '我的名字是:{0},我的年龄是:{1},我的考试的分数是:{2}'
print(d1.format(name,age,score))
输出结果:
我的名字是:小鬼,我的年龄是:18,我的考试的分数是:99.99当然,format( )函数可以做到更加详细的应用,有如下一些应用:
| 形式 | 描述 |
| : | 引导符号,后面的所有符号都需要引导符 |
| 填充 | 用于填充单个字符 |
| 对齐方式 | <为左对齐,>右对齐,^居中对齐 |
| 宽度 | 字符串的输出宽度 |
| , | 数字的千位分隔符 |
| .精度 | 浮点数,小数部分的精度或字符串的最大输出长度 |
| 类型 | 整数类型:b/d/o/x/X 浮点数类型:e/E/f/% |
1.3、数据的验证
数据的验证是指:程序对用户输入的数据进行“ 合法 ”性的验证。
数据的验证包含以下指令,可以对数据进行验证:
| 方法名 | 描述说明 |
| str.isdigit() | 所有字符都是数字(阿拉伯数字) |
| str. isnumeric() | 所有字符都是数字 |
| str. isalpha() | 所有字符都是字母(包含中文字符) |
| str.isalnum() | 所有字符都是数字或字母(包含中文字符) |
| str.islower() | 所有字符都是小写 |
| str.isupper() | 所有字符都是大写 |
| str.istitle() | 所有字符都是首字母大写 |
| str.isspace() | 所有字符都是空白字符(\n、\t等) |
1.4、正则表达式
正则表达式是一种用于匹配和处理文本的工具,它可以用来在文本中查找、替换、提取或验证特定的模式。正则表达式可以快速、方便地对文本进行复杂的操作,因此在计算机科学和软件开发中非常常用。
正则表达式的出现主要是为了满足处理文本的需求。在大量的文本处理任务中,如文本搜索、文件批量处理、数据清洗等,正则表达式可以帮助我们高效地完成工作。正则表达式具有强大的模式匹配能力,在处理复杂的文本结构时非常有用。
通过使用正则表达式,我们可以灵活地指定需要匹配的模式,包括具体的字符、字符集合、数量、位置等。正则表达式还提供了一些特殊字符和操作符,用于表示特定的模式,如通配符、分组、选择、重复等。通过灵活地组合和使用这些模式和操作符,我们可以实现对文本的精确匹配和处理。
1.5.1元字符
元字符是:具有特殊意义的专用字符。
| 描述说明 | 举例 | 结果 |
| 匹配任意字符(除\n) | ’p\nytho\tn’ | p、y、t、h、o、\t、n |
| 匹配字母、数字、下划线 | ‘python\n123’ | p、y、t、h、o、n、1、2、3 |
| 匹配非字母、数字、下划线 | ‘python\n123’ | \n |
| 匹配任意空白字符 | ‘python\t123’ | \t |
| 匹配任意非空白字符 | ‘python\t123’ | p、y、t、h、o、n、1、2、3 |
| 匹配任意十进制数 | ‘python\t123’ | 1、2、3 |
1.5.2限定符
限定符是:是用来限定匹配次数的
| 限定符 | 描述说明 | 举例 | 结果 |
| ? | 匹配前面的字符0次或1次 | colou?r | 可以匹配color或colour |
| + | 匹配前面的字符1次或多次 | colou+r | 可以匹配colour或colouu...r |
| * | 匹配前面的字符0次或多次 | colou*r | 可以匹配color或colouu....r |
| {n} | 匹配前面的字符n次 | colou{2}r | 可以匹配colouur |
| {n,} | 匹配前面的字符最少n次 | colou{2,}r | 可以匹配colouur或colouuu...r |
| {n,m} | 匹配前面的字符最小n次,最多m次 | colou{2,4}r | 可以匹配colouur或colouuur或colouuuur |
1.5.3其他字符
| 其它字符 | 描述说明 | 举例 | 结果 |
| 区间字符[ ] | 匹配[ ]中所指定的字符 | [.?!] [0-9] | 匹配标点符号点、问号,感叹号 匹配0、1、2、3、4、5、6、7、8、9 |
| 排除字符^ | 匹配不在[ ]中指定的字符 | [^0-9] | 匹配除0、1、2、3、4、5、6、7、8、9的字符 |
| 选择字符| | 用于匹配|左右的任意字符 | \d{18}|\d{15} | 匹配15位身份证或18位身份证 |
| 转义字符 | 同Python中的转义字符 | \. | 将.作为普通字符使用 |
| [\u4e00-\u9fa5] | 匹配任意一个汉字 | ||
| 分组() | 改变限定符的作用 | six|fourth (six|four)th | 匹配six或fourth 匹配sixth或fourth |
1.5.4re模块
re模块是内置模块,用于实现python中正则表达式的操作。
| 函数 | 功能描述 |
| re.match(pattern,string,flags=0) | 用于从字符串的开始位置进行匹配,如果起始位置匹配成功,结果为Match对象,否则结果为None。 |
| re.search(pattern,string,flags=0) | 用于在整个字符串中搜索第一个匹配的值,如果匹配成功,结果为Match对象,否则结果为None。 |
| re.findall(pattern,string,flags=0) | 用于在整个字符串搜索所有符合正则表达式的值,结果是一个列表类型。 |
| re.sub (pattern,repl,string,count,flags=0) | 用于实现对字符串中指定子串的替换 |
| re.split(pattern,string,maxsplit,flags=0) | 字符串中的split()方法功能相同,都是分隔字符串 |
我们对字符串的学习就结束了!!!(●ˇ∀ˇ●)