目录
- 前言
- 一,树形结构的关联式容器
- 二,set
- 1,set 的介绍
- 2,set 常用接口的使用
- (1) set 的插入,迭代器遍历
- (2) set 的区间构造,范围for
- (3) set 的删除
- 三,multiset
- 1, multiset 的介绍
- 2,multiset 的简单使用
- 四,map
- 1,map 的介绍
- 2,map 常用接口的使用
- (1) map 的构造
- (2) map 的迭代器和范围 for
- 3,map 中的下标访问符 [ ]
- (1),下标访问符 [ ] 的多种功能
- (2),统计字符串个数示例
- 五,multimap
- 1,multimap 的介绍
- 2,multimap 的简单使用
前言
在前面,我们已经接触过STL中的部分容器,比如:vector、list、deque等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高。
一,树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。下面一依次介绍每一个容器。
二,set
1,set 的介绍
(1) set是按照一定次序存储元素的容器
(2) 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
(3) set在底层是用二叉搜索树(红黑树) 实现的。
注意:
(1) set中的元素不可以重复(因此可以使用set进行去重)。
(2) 使用set的迭代器遍历set中的元素,可以得到有序序列。
(3) set中的元素默认排升序。
(4) set中查找某个元素,时间复杂度为:
l
o
g
2
n
log_2 n
log2n。
2,set 常用接口的使用
使用set容器要包含头文件:
#include <set>

set 常用接口的使用举例:
(1) set 的插入,迭代器遍历
功能:排序+去重。
void test_set1()
{
//K模型搜索
//排序+去重
//插入
set<int> s1;
s1.insert(1);
s1.insert(6);
s1.insert(4);
s1.insert(1);
s1.insert(14);
s1.insert(2);
s1.insert(5);
set<int>::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}

(2) set 的区间构造,范围for
void test_set2()
{
//区间构造
vector<int> v = { 2,8,4,6,3,9,2,4,5 };
set<int> s2(v.begin(), v.end());
//范围for
for (auto e : s2)
cout << e << " ";
}

(3) set 的删除
void test_set3()
{
set<int> s3 = { 6,9,2,7,3,4,7,8 };
for (auto e : s3)
cout << e << " ";
cout << endl;
//删除
s3.erase(8);
for (auto e : s3)
cout << e << " ";
cout << endl;
}

三,multiset
1, multiset 的介绍
multiset 与 set 的内容介绍,功能和函数接口基本相同。
set的区别是:multiset中的value元素可以重复,set是中value是唯一的。
2,multiset 的简单使用
此处只简单演示set与multiset的不同,其他接口接口与set相同。
void test_set2()
{
//K模型搜索
//排序 不去重,允许冗余
//插入
multiset<int> s1;
s1.insert(1);
s1.insert(6);
s1.insert(4);
s1.insert(1);
s1.insert(14);
s1.insert(2);
s1.insert(1);
s1.insert(5);
multiset<int>::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}

四,map
1,map 的介绍
(1) map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
(2) 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同。
(3) 在内部,map中的元素总是按照键值key进行比较排序的。
(4) map支持下标访问符(重点),即在[]中放入key,就可以找到与key对应value。
(5) map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
2,map 常用接口的使用
使用 map 需要包含头文件:
#include <map>

(1) map 的构造
map 的构造有多种方式,最常用并且最喜欢用的是方式4(因为简短)。
void test_map1()
{
map<string, string> dict;
// 1.有名对象
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
// 2.匿名对象
dict.insert(pair<string, string>("left", "左边"));
// 3.函数模版
dict.insert(make_pair("right", "右边"));
// 4.多参数构造函数的隐式类型转换
//pair<string, string> kv2 = { "string","字符串" };
dict.insert({ "string","字符串" });
// 5.initializer_list构造
map<string, string> dict2 = { { "left", "左边" } ,{ "string","字符串" } ,{"right", "右边"} };
}
(2) map 的迭代器和范围 for
a,普通迭代器 iterator,key不能修改 value可以修改。
const迭代器 const_iterator,key不能修改 value不能修改。
b,范围for遍历,要加引用&。
void test_map2()
{
map<string, string> dict;
//有名对象
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
//匿名对象
dict.insert(pair<string, string>("left", "左边"));
//函数模版
dict.insert(make_pair("right", "右边"));
//多参数构造函数的隐式类型转换
//pair<string, string> kv2 = { "string","字符串" };
dict.insert({ "string","字符串" });
//initializer_list构造
map<string, string> dict2 = { { "left", "左边" } ,{ "string","字符串" } ,{"right", "右边"} };
//迭代器遍历
map<string, string>::iterator it = dict2.begin();
while (it != dict2.end())
{
//it->first += 'x'; //err
//it->second += "x"; //ok
//cout << (*it).first << ":" << (*it).second << endl;
cout << it->first << ":" << it->second << endl;
//cout << it.operator->()->first << ":" << it.operator->()->second << endl;
it++;
}
cout << endl;
//范围for遍历,要加引用
//本质:是把迭代器中 *it 赋值给 kv
for (const auto& kv : dict2)
cout << kv.first << ":" << kv.second << endl;
cout << endl;
}

3,map 中的下标访问符 [ ]
首先来看看map中成员函数 operator[] 的简化实现:
V& operator[](const k& key)
return (*((this->insert(make_pair(k, mapped_type()))).first)).second;
为了避免大家看的头晕,上面两行代码的分步解析:
V& operator[](const K& key)
{
pair<iterator, bool> ret = this->insert(make_pair(key, V()));
//不管插入成功还是失败,返回的都是key节点的迭代器,新插入的或是已存在的
iterator it = ret.first;
return it->second;
}
由上面的代码可得出:
(1) operator[]:给的是key,返回key对应的value的引用;
(2) key存在,插入失败,返回 --> pair<存在的key所在节点的迭代器, false>
(3) key不存在,插入成功,返回 --> pair<新插入key所在节点的迭代器, true>
所以不管插入成功还是失败,返回的都是key节点的迭代器,新插入的或是已存在的。
(1),下标访问符 [ ] 的多种功能
void test_map3()
{
map<string, string> dict;
dict.insert({ "string","字符串" });
//插入(一般不这么用)
dict["right"];
//插入+修改
//operator[]返回的是value的引用,进行修改
dict["left"] = "左边";
//查找
cout << dict["string"] << endl;
//修改
dict["right"] = "右边";
//成员函数count的使用:返回 key 的个数
//在这里可以判断字符串在不在
string str;
cin >> str;
if (dict.count(str))
cout << "在" << endl;
else
cout << "不在" << endl;
}
通过监视窗口观察如下:

(2),统计字符串个数示例
方式1:
先查找判断要插入的字符串在不在,若第一次出现,就要插入,否则 value 值要++,统计起来比较麻烦。
void test_map2()
{
//统计字符串个数
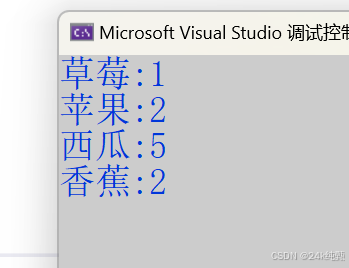
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "西瓜","香蕉", "苹果","西瓜", "香蕉","草莓" };
map<string, int> countMap;
for (auto& kv : arr)
{
auto it = countMap.find(kv);
if (it != countMap.end()) //前面出现过
it->second++;
else
//第一次出现
countMap.insert({ kv, 1}); //隐式类型转换
}
for (const auto& kv : countMap)
cout << kv.first << ":" << kv.second << endl;
cout << endl;
}
注意:map 中元素的顺序是按 key 排序的,就是这里的 string,默认排升序。
](https://i-blog.csdnimg.cn/direct/0f8ee144dd7b4b19a4fae98211398d6f.png)
方式2:
直接用 operator[] 的特性进行统计,核心代码只要一句。
void test_map2()
{
//统计字符串个数
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "西瓜","香蕉", "苹果","西瓜", "香蕉","草莓" };
map<string, int> countMap;
for (auto& kv : arr)
{
countMap[kv]++;
// 插入第一个,key是苹果,不存在,插入成功,
// 此时value是0,插入成功后返回value的引用再++就变成1了
}
for (const auto& kv : countMap)
cout << kv.first << ":" << kv.second << endl;
cout << endl;
}

五,multimap
1,multimap 的介绍
multimap 与 map 的内容介绍,功能和函数接口基本相同。
multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以重复的,multimap中没有重载operator[]操作符。
2,multimap 的简单使用
此处只简单演示map与multimap的不同,其他接口接口与map相同。
比如我们要对上面的水果出现的次数进行排序,有重复值,要用multimap:
void test_map2()
{
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "西瓜","香蕉", "苹果","西瓜", "香蕉","草莓" };
map<string, int> countMap;
for (auto& kv : arr)
{
countMap[kv]++;
//插入第一个,key是苹果,不存在,插入成功,
// 此时value是0,插入成功后返回value的引用再++就变成1了
//对次数排序,当有重复值时,要用multimap
multimap<int, string> sortMap;
for (auto& kv : countMap)
{
sortMap.insert({ kv.second, kv.first });
}
for (const auto& kv : sortMap)
cout << kv.first << ":" << kv.second << endl;
cout << endl;
}


![[web]-反序列化漏洞-easy入门](https://i-blog.csdnimg.cn/direct/3868df69b97e4c2cb0b33b2d26f0e4b4.png)