-
zookeeper+Kafka
-
两个都是消息队列的工具
-
消息队列
-
出现原因:生产者产生的消息与消费者处理消息的效率相差很大。为了避免出现数据丢失而设立的中间件。
-
在消息的生产者与消费之间设置一个系统,负责缓存生产者与消费者之间的消息的缓存。将消息排序。
-
优点:
-
解耦
-
将生产者与消费者的关系解开,这样避免一端的程序出问题导致整个两端程序都不可用。
-
-
冗余
-
为生产者与消费者之间产生的数据做了冗余
-
-
扩展性
-
利用zookeeper可以具备良好的扩展性。
-
-
灵活性
-
消息队列的对象可以是各种不同的程序
-
-
峰值处理能力
-
生产者产生的消息如果具有波动性,某一时刻峰值很高,利用消息队列就可以承载压力,然后慢慢分配给消息的消费者。
-
-
可恢复性
-
可以采用群集备份
-
-
顺序保证
-
消息以排序的方式存在
-
-
缓存
-
在生产者与消费者之间起到了一个缓冲的作用
-
-
异步通信
-
生产者产生的消息与消费者消费消息可以不再同一时间。
-
-
-
-
消息队列产品
-
kafka
-
apache旗下的产品
-
一种高吞吐量分布式发布/订阅消息队列的开源系统
-
kafka术语
-
broker
-
每一个安装了kafka的服务器都可以称为一个broker
-
-
topic
-
一类消息的集合被称为主题,一个broker可以有多个topic。
-
-
producer
-
消息生产者
-
-
consumer
-
消息消费者
-
-
partition
-
存放消息的区域,每一个topic可以有多个partition,但是处理还是一个一个区域处理。每一个区域内的消息都会被分配一个id。offset (偏移量)
-
-
consumer GROUP
-
消费者组
-
-
messages
-
消息,通信的基本单位。
-
-
-
kafka架构
-

-
需要注意的是,kafka作为一个支持多生产者多消费者的架构,再写入消息时允许多个生产者写道同一个partition,但是消费者读取的时候一个partition仅允许一个消费者消费,但一个消费者可以消费多个partition。
-
kafka支持消息持久化存储,消息会被存储在缓冲区内,达成一定条件就会被写入磁盘。在写入磁盘是是按照顺序的。
-
topic与partition的关系
-
partition的数量决定了组成topic的log的数量, 因此推荐partition的数量要大于同时允许的consumer数量,要小于等于集群broker的数量。
-
-
-
zookeeper
-
一种分布式协调技术,用于解决分布式环境中多个进程之间的同步控制,让他们有序的访问某种共享资源,尽量减少脑裂的发生。
-
开源的分布式协调服务
-
-
解决问题
-
单点故障
-
-
工作原理
-
master启动
-
节点向zookeeper注册信息,在选举产生master时采用最小编号算法,既最先的编号最小。
-
-
master故障
-
出现故障的节点信息会被自动删除,再通过选举投票产生新的master。
-
zookeeper判断节点故障的依据: 节点必须与zookeeper保持心跳连接。 节点能够及时响应zookeeper的请求。
-
-
-
master恢复
-
master恢复后,会再次向zookeeper注册自身节点信息,编号就会变淡。
-
-
-
架构图
-

-
四个角色
-
leader:领导者
-
负责发起投票与决议,更新系统状态
-
3888,选举通信端口
-
-
-
follower:追随者
-
负责请求客户端的请求并将结果给客户端,在选举过程中参与投票。
-
-
observer:观察者角色
-
负责接收客户端请求,并将请求转发给leader。但不参与投票,目的是扩展系统,提高伸缩性。
-
watcher:观察者,监视者
-
sentinel:哨兵
-
-
-
client:客户端
-
负责向zookeeper发起请求。
-
-
-
-
zookeeper在kafka中的作用
-
broker注册
-
每一个kafka的master节点都会在zookeeper中注册信息,提供id,每个master整个id都必须唯一。
-
-
topic注册
-
每一个主题也会在zookeeper注册信息。
-
-
生产者与消费者的负载均衡(实际上是高可用)
-
分区与消费者的联系
-
消费进度offset记录
-
消费者注册
-
根据注册信息将消费者分配到不同的分区,以达到负载均衡的目的。
-
-
-
-
-
zookeeper+kafka部署
-
本案例以zookeeper3.6版本与kafka2.13版本为例
-
单节点部署kafka进行测试
-
可以设置hosts文件进行域名通信
-
安装依赖环境
-
yum -y install java 注意是1.8版本。
-
-
解压即可用移动到/etc/zookeeper
-
修改配置文件
-
可以单独指定数据目录
-
dataDir=/etc/zookeeper/zookeeper-data
-
然后将指定的目录创建出来
-
启动查看状态
-
./bin/zkServer.sh start
-
-
-
-
-
-
单节点部署zookeeper+kafka做测试
-
部署zookeeper
-
可以设置hosts文件进行域名通信
-
安装依赖环境
-
yum -y install java 注意是1.8版本。
-
-
解压即可用移动到/etc/zookeeper
-
修改配置文件
-
可以单独指定数据目录
-
dataDir=/etc/zookeeper/zookeeper-data
-
然后将指定的目录创建出来
-
之后启动查看状态
-
-
-
-
-
部署kafka
-
同样的解压即可用移动到/etc/kafka
-
同样的可以修改配置文件指定日志文件目录并将目录创建出来
-
log.dirs=/etc/kafka/kafka-logs
-
mkdir /etc/kafka/kafka-logs
-
-
启动kafka需要指定配置文件并可以设置为后台启动。
-
bin/kafka-server-start.sh config/server.properties &
-
-
-
需要注意启动时要先启动zookeeper,结束时要先结束kafka。
-
测试
-
创建topic
-
kafka-topics.sh --create --zookeeper kafka1:2181 --replication-factor 1 --partitions 1 --topic test
-
kafka-topic.sh --create --zookeeper broker域名或IP:端口一般2181 --replication-factor 集群master数量 --partitions 1 topic中分区数量 --topic 分区名
-
-
列出topic
-
kafka-topics.sh --list --zookeeper brokerIP/域名:端口(2181)
-
-
查看topic
-
kafka-topics.sh --describe --zookeeper kafka1:2181 --topic test
-
describ :描述
-
-
-
生产消息进入命令行模式
-
/kafka-console-producer.sh --broker-list kafka1:9092 -topic tes
-
9092kafka监听客户端连接的端口
-
-
-
消费消息,进入查看产生消费消息的界面
-
kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test
-
-
删除topic
-
kafka-topic.sh --delete --zookeeper Kafka服务器:端口 --topic 主题名
-
-
-
-
集群部署zookeeper+kafka
-
修改主机hosts文件,使之可以使用域名访问
-
安装zookeeper三台主机安装部署略有不同
-
准备前奏
-
防火墙与内核机制处理
-
安装依赖环境java
-
-
解压移动
-
tar zxvf apache-zookeeper-3.6.0-bin.tar.gz
-
mv apache-zookeeper-3.6.0-bin /etc/zookeeper
-
-
创建数据保存目录
-
mkdir zookeeper-data
-
-
修改配置文件
-
dataDir=/etc/zookeeper/zookeeper-data
-
指定数据保存目录
-
-
clientPort=2181
-
确定监听端口
-
-
添加节点注册信息有几个添加几个
-
server.1=192.168.10.101:2888:3888
-
2888:集群内部通信端口,主要用于选举leader
-
3888:其他服务器在选举leader时监听的端口。
-
-
-
-
创建id文件
-
echo '1' > /etc/zookeeper/zookeeper-data/myid
-
每个节点IP不同
-
-
-
最后启动并查看状态
-
-
安装kafka,节点配置相同
-
解压并移动
-
tar zxvf kafka_2.13-2.4.1.tgz
-
mv kafka_2.13-2.4.1 /etc/kafka
-
-
修改配置文件
-
listeners=PLAINTEXT://192.168.10.101:9092
-
监听客户端连接
-
-
log.dirs=/etc/kafka/kafka-logs
-
指定日志文件位置
-
-
num.partitions=1
-
分区数量,不能超过节点数。
-
-
集群地址信息
-
zookeeper.connect=192.168.10.101:2181,192.168.10.102:2181,192.168.10.103:2181
-
-
-
创建日志目录
-
mkdir /etc/kafka/kafka-logs
-
-
最后启动查看状态
-
测试
-
在任意一节点上创建topic
-
列出任意一节点的topic
-
进行生产与消费的对应
-
-
ELK日志系统添加接口对接Kafka
-
input { beats { port => "5044" codec => "json" } } output { kafka { bootstrap_servers => "192.168.10.101:9092,192.168.10.102:9092,192.168.10.103:9092" topic_id => "httpd-filebeat" batch_size => "5" codec => "json" } }
-
-
-
该集群中用到的端口
-
zookeeper客户端连接的端口:2181
-
zookeerper内部通信端口:2888
-
zookeeper监听选举过程的端口:3888
-
kafka监听客户端的接口:9092
-
-
-
-
-
-
zookeeper+kafka的消息队列
news2026/4/9 22:21:29
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1928533.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

nginx生成自签名SSL证书配置HTTPS
一、安装nginx
nginx必须有"--with-http_ssl_module"模块
查看nginx安装的模块:
rootecs-7398:/usr/local/nginx# cd /usr/local/nginx/
rootecs-7398:/usr/local/nginx# ./sbin/nginx -V
nginx version: nginx/1.20.2
built by gcc 9.4.0 (Ubuntu 9.4.0…


Leetcode—146. LRU 缓存【中等】(shared_ptr、unordered_map、list)
2024每日刷题(143)
Leetcode—146. LRU 缓存 先验知识 list & unordered_map 实现代码
struct Node{int key;int value;Node(int key, int value): key(key), value(value) {}
};class LRUCache {
public:LRUCache(int capacity): m_capacity(capa…
Spring Boot集成qwen:0.5b实现对话功能
1.什么是qwen:0.5b?
模型介绍:
Qwen1.5是阿里云推出的一系列大型语言模型。 Qwen是阿里云推出的一系列基于Transformer的大型语言模型,在大量数据(包括网页文本、书籍、代码等)进行了预训练。
硬件要求:…

SWDIO管脚作为GPIO
下面是使用FRDM-K32L2B3开发板和SDK中的frdmk32l2b_gpio_led_output程序做了一些测试,configure SWDIO pin as GPIO pin的流程。
查看手册,找到SWDIO对应的管脚,可以看到PTA3对应的SWDIO管脚。 2.修改Demo程序,在程序中设置SWDIO…

生物素四聚乙二醇叠氮;Biotin-PEG4-Azide
生物素四聚乙二醇叠氮,也被称为Biotin-PEG4-Azide或Azide-PEG4-Biotin,是一种重要的化学化合物,其CAS号为1309649-57-7。以下是对该化合物的详细介绍: 一、基本信息 中文名:生物素四聚乙二醇叠氮 英文名:Bi…

wps批量删除空白单元格
目录 原始数据1.按ctrlg键2.选择“空值”,点击“定位”3. 右击,删除单元格修改后的数据 原始数据 1.按ctrlg键 2.选择“空值”,点击“定位” 如图所示,空值已被选中
3. 右击,删除单元格 修改后的数据
Rust 使用 panic! 还是不用 panic!
使用 panic! 还是不用 panic!
那么,该如何决定何时应该 panic! 以及何时应该返回 Result 呢?如果代码 panic,就没有恢复的可能。你可以选择对任何错误场景都调用 panic!,不管是否有可能恢复,不过这样就是你代替调用者…

【python】基于随机森林和决策树的鸢尾花分类
目录 引言
决策树(Decision Tree)
随机森林(Random Forest)
数据集
结果
代码实现 引言
随机森林(Random Forest)和决策树(Decision Tree)是两种在机器学习中广泛使用的分类和…

STM32智能农业监测系统教程
目录
引言环境准备智能农业监测系统基础代码实现:实现智能农业监测系统 4.1 数据采集模块 4.2 数据处理与控制模块 4.3 通信与网络系统实现 4.4 用户界面与数据可视化应用场景:农业监测与管理问题解决方案与优化收尾与总结
1. 引言
智能农业监测系统通…

Java二十三种设计模式-建造者模式(4/23)
建造者模式:构建复杂对象的专家
引言
建造者模式(Builder Pattern)是一种创建型设计模式,用于创建一个复杂的对象,同时允许用户只通过指定复杂对象的类型和内容就能构建它们,它将对象的构建和表示分离&am…
【计算机毕业设计】002基于weixin小程序家庭记账本
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…

【JavaEE进阶】——SpringBoot 统⼀功能处理
目录
🚩拦截器
🎈什么是拦截器?
🎈如何使用拦截器
🎓自定义拦截器
🎓注册拦截器
🎈拦截器详解
🎓拦截路径
🎓拦截器执⾏流程
🔴DispatcherServlet 源码分析(了…

手机怎么看WiFi的IP地址
在如今数字化快速发展的时代,无线网络已成为我们日常生活中不可或缺的一部分。无论是工作、学习还是娱乐,我们可能都离不开WiFi的陪伴。然而,在使用WiFi的过程中,有时我们可能需要查看其IP地址,以便更好地管理我们的网…
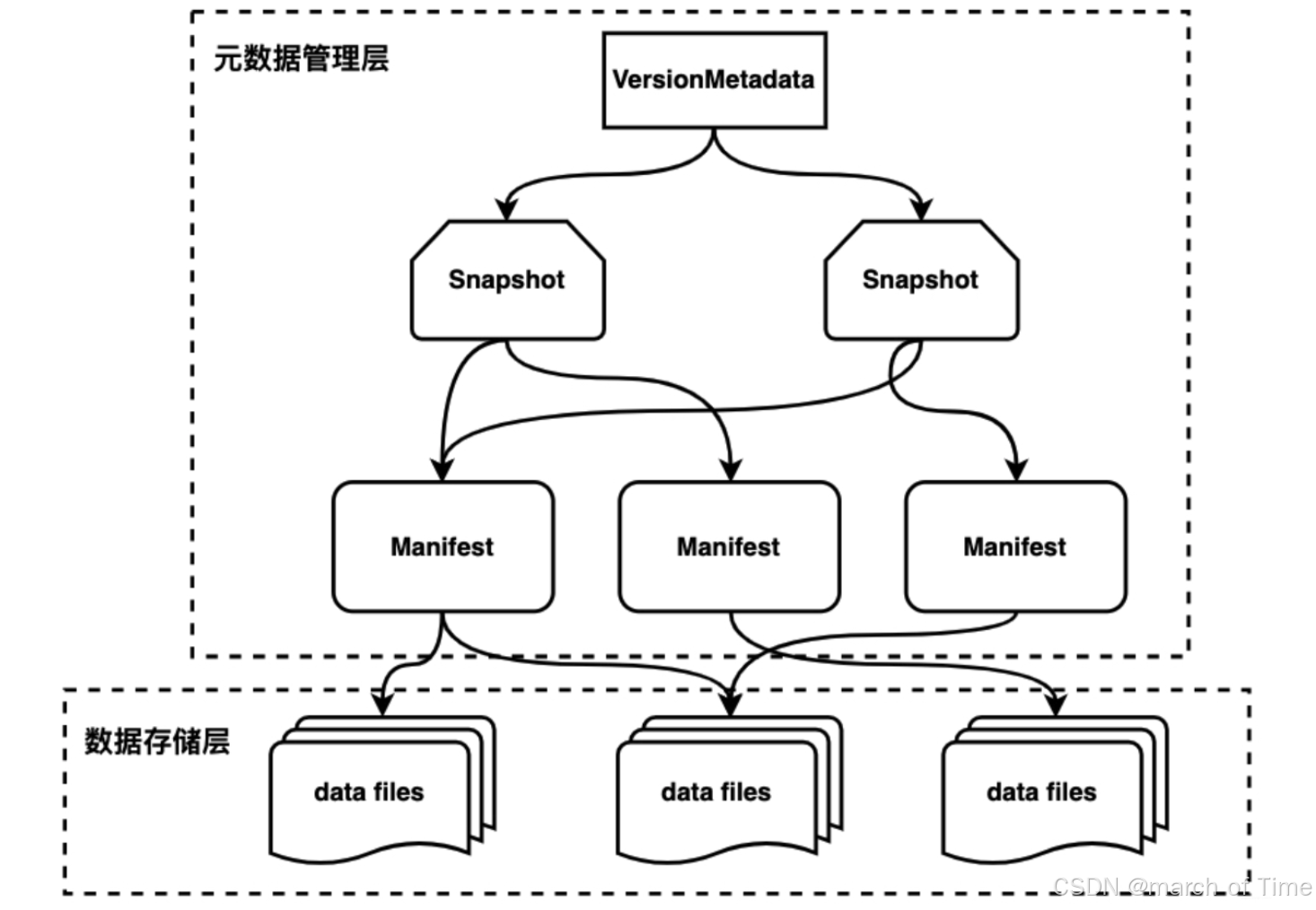
大数据hive表和iceberg表格式
iceberg:
https://iceberg.apache.org/ iceberg表,是一种面向大型分析数据集的开放表格式,旨在提供可扩展、高效、安全的数据存储和查询解决方案。它支持多种存储后端上的数据操作,并提供 ACID 事务、多版本控制和模式演化等特性,…
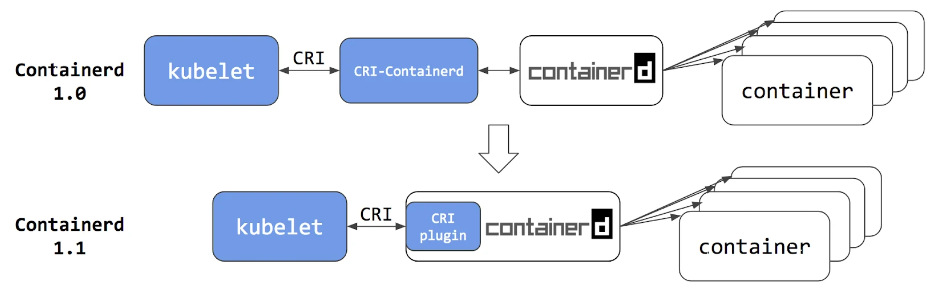
K8S 中的 CRI、OCI、CRI shim、containerd
哈喽大家好,我是咸鱼。
好久没发文了,最近这段时间都在学 K8S。不知道大家是不是和咸鱼一样,刚开始学 K8S、Docker 的时候,往往被 CRI、OCI、CRI shim、containerd 这些名词搞得晕乎乎的,不清楚它们到底是干什么用的。…
持续集成01--Git版本管理及基础应用实践
前言 本系列文章旨在深入探讨持续集成/持续部署(Continuous Integration/Continuous Deployment, CI/CD)流程中的各个环节,而本篇将聚焦于Git版本管理及其基本应用。通过本文,读者将了解到Git的基本原理、安装配置、基本命令以及如…

当农业遇见智能:机器学习引领农作物管理新时代
机器学习引领农作物管理新时代 1. 引言1.1 农业的重要性和现代农作物管理的挑战1.2 机器学习技术在农业中的潜力和应用前景 2. 机器学习在农作物管理中的基础应用2.1 数据驱动的农业决策数据收集与处理示例代码:传感器数据采集决策支持系统 2.2 传感器技术与数据采集…

ArcGIS Enterprise 命令行组件创建配置
1. 创建ArcGIS Server站点
使用 createsite工具
命令行直接执行
createsite.sh [-u <arg>] [-p <arg>] [-d <arg>] [-c <arg>]执行文件
createsite.sh [-f <FILE>]安装目录下会有类似的创建站点文件: 修改其中的内容,…

python中的re模块--正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科 学的一个概念。正则表达式通常被用来检索、替换那些符合某个模 式(规则)的文本 re模块作用
通过使用…