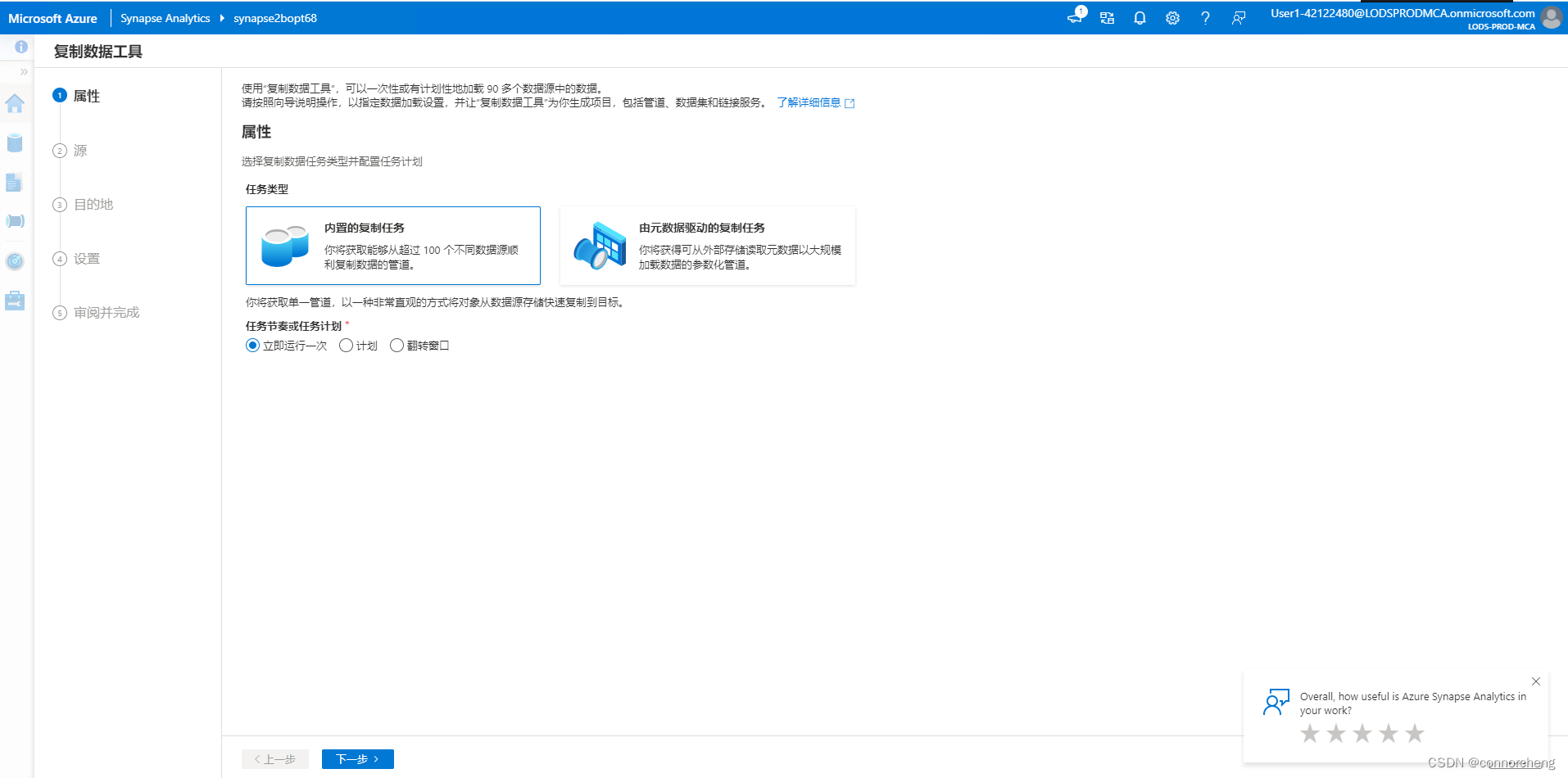
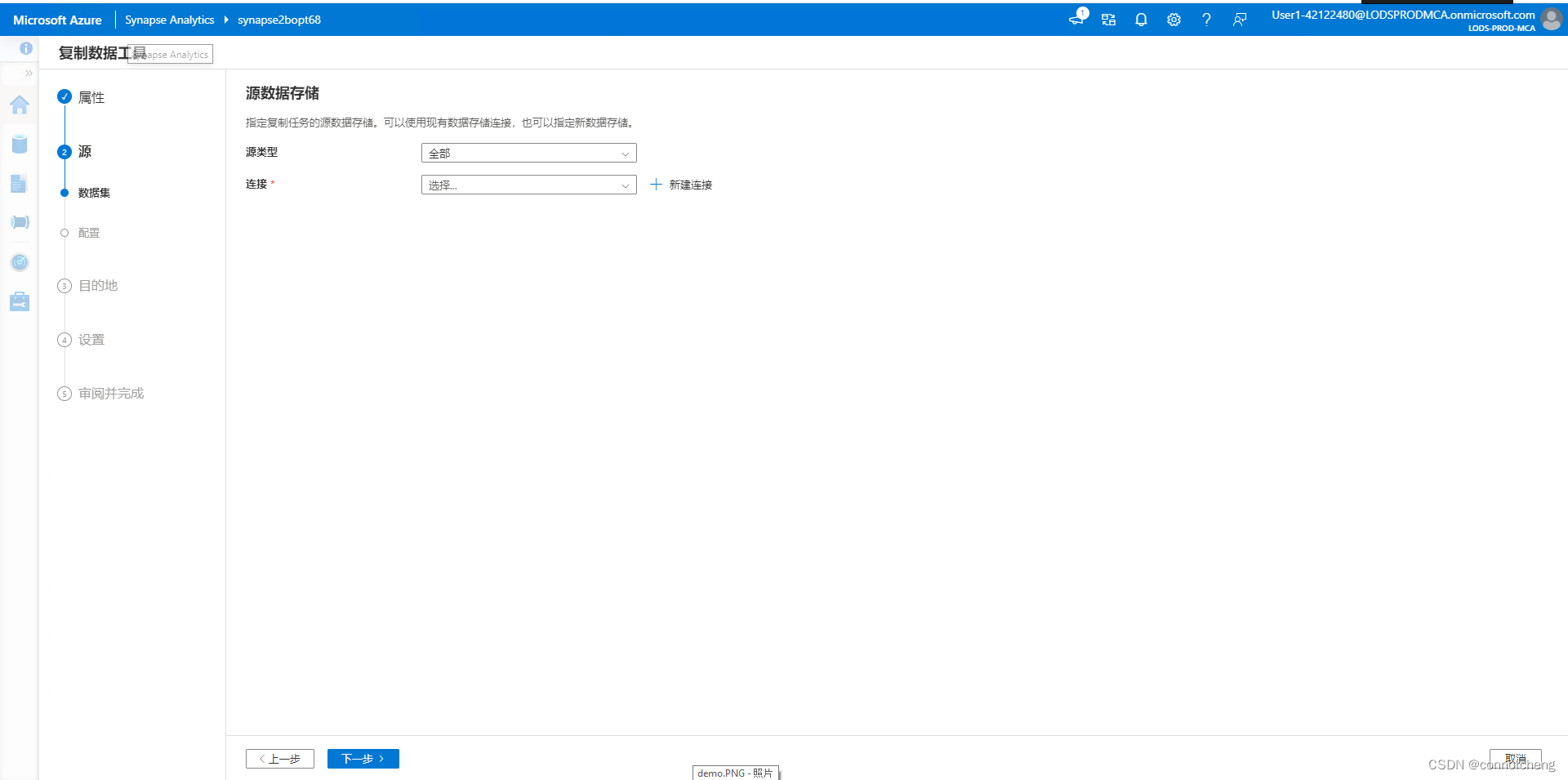
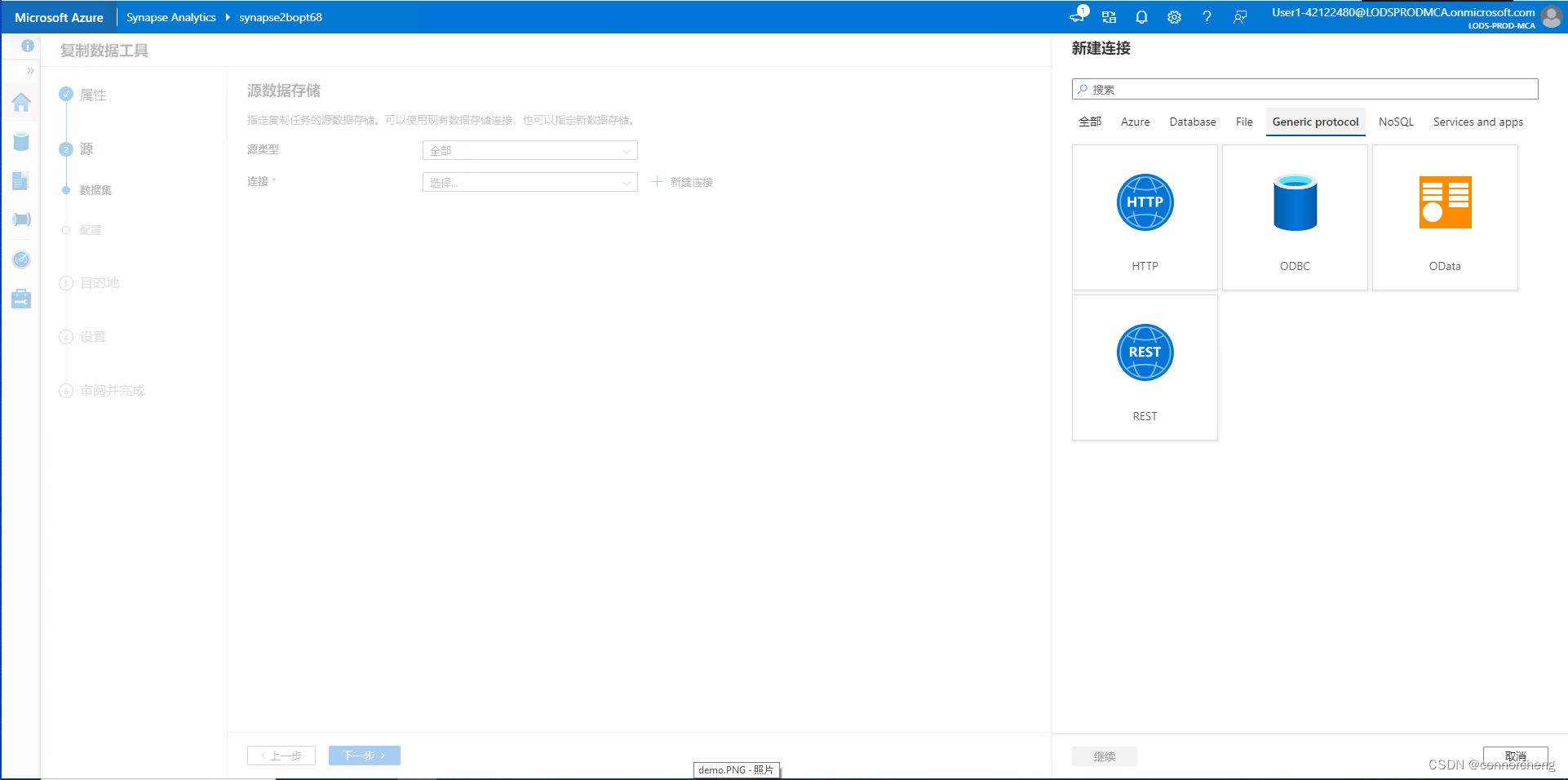
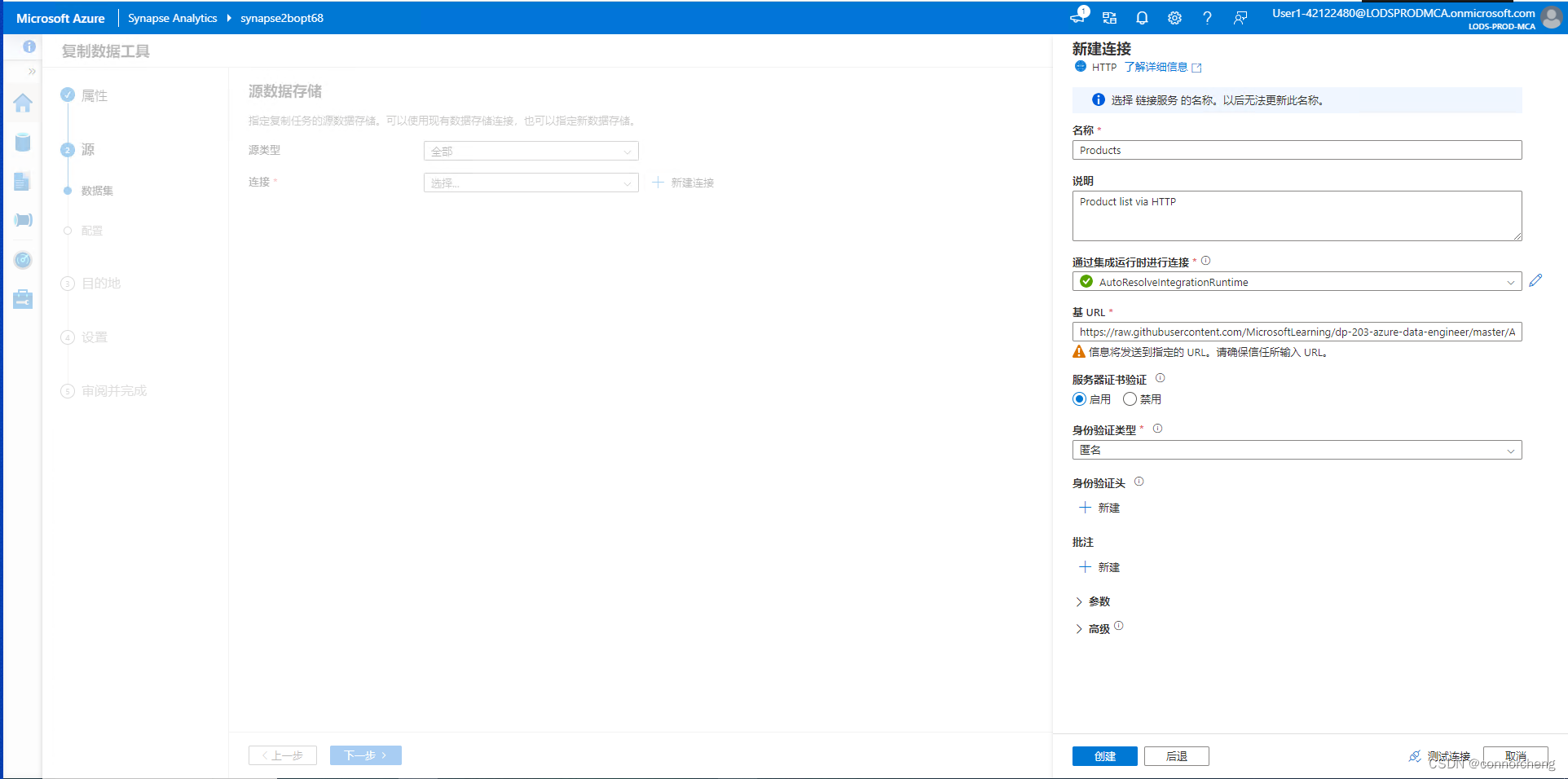
rm -r dp-203 -f
git clone https://github.com/MicrosoftLearning/dp-203-azure-data-engineer dp-203

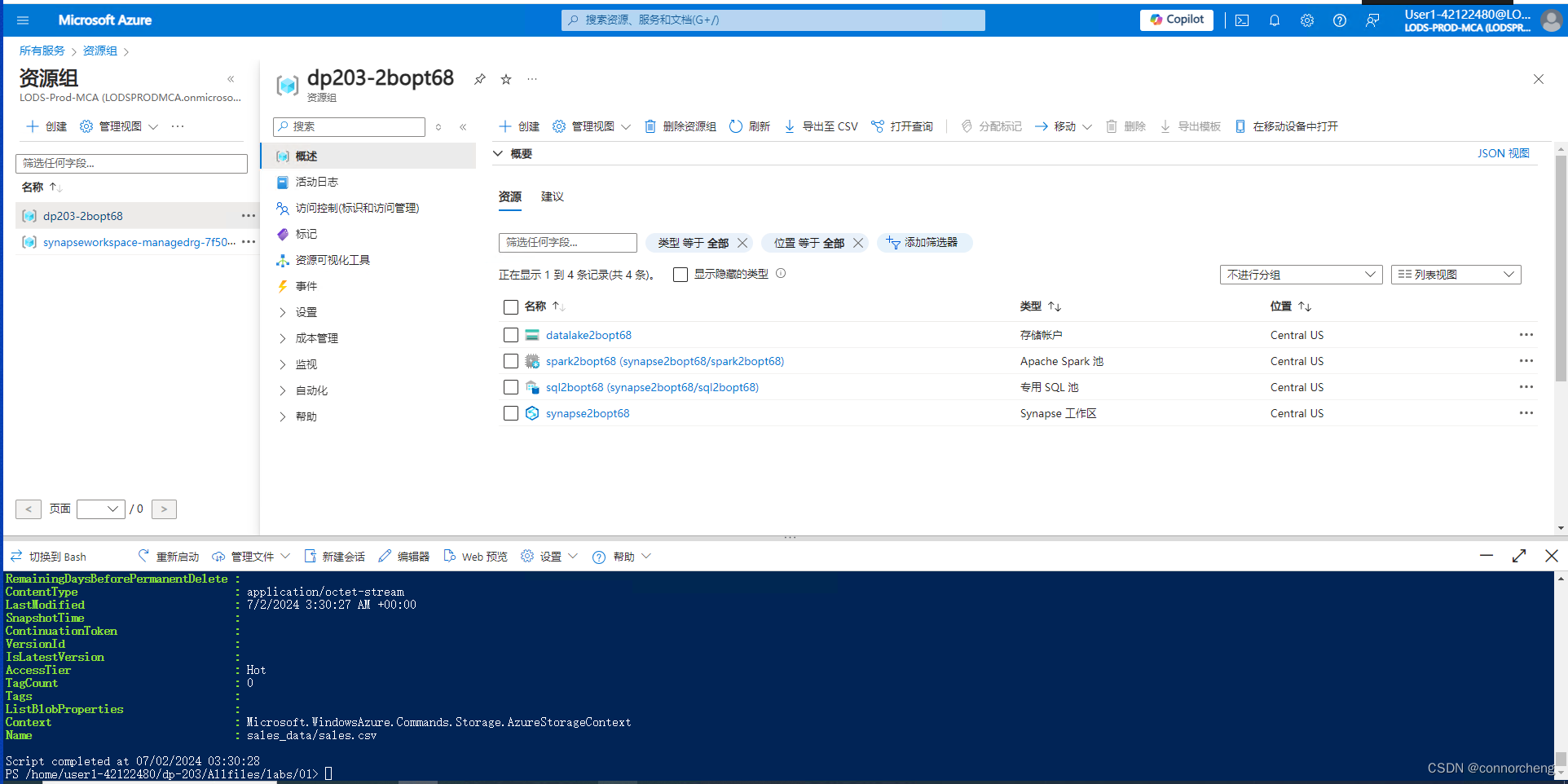
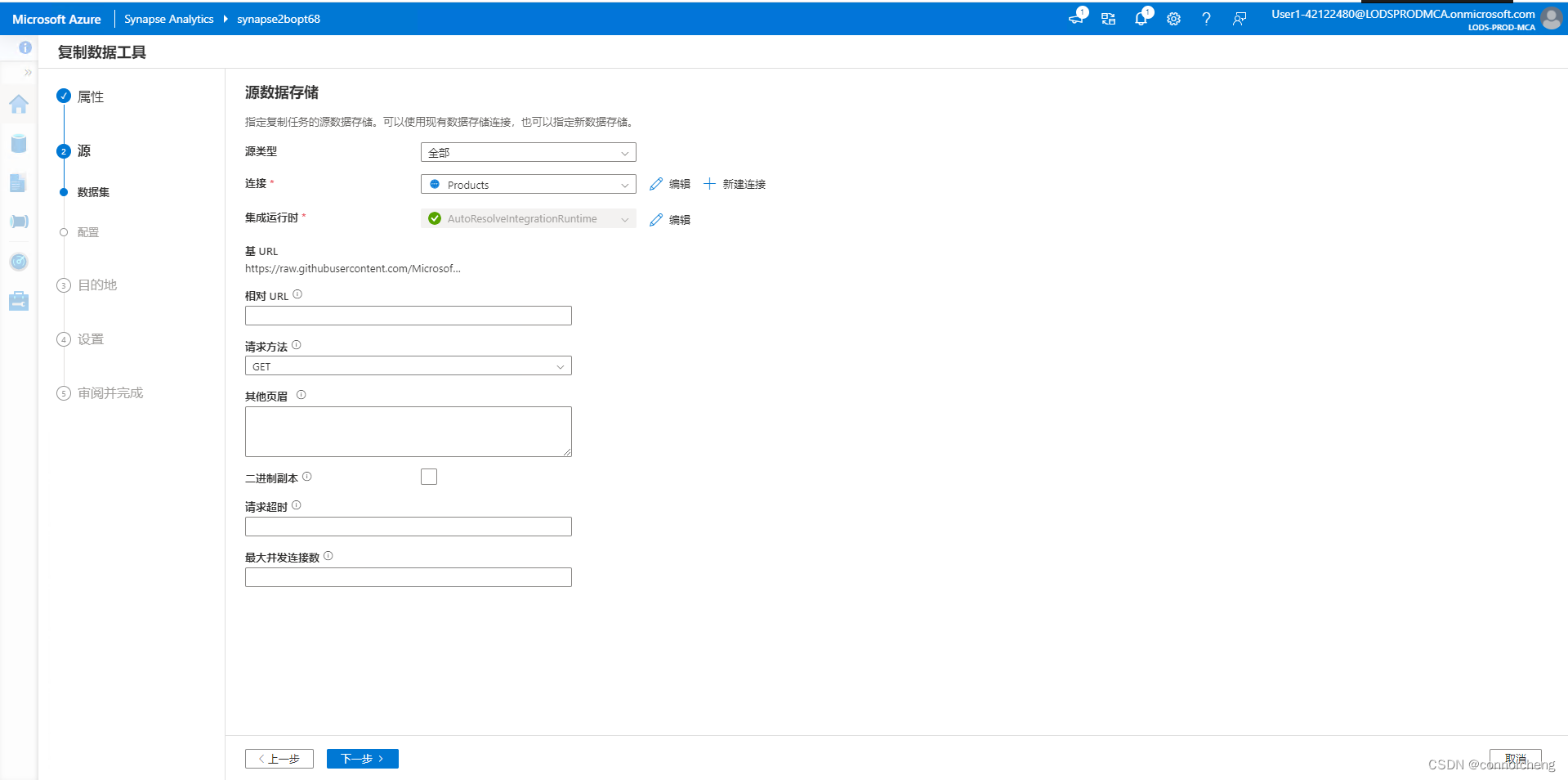
cd dp-203/Allfiles/labs/01
./setup.ps1

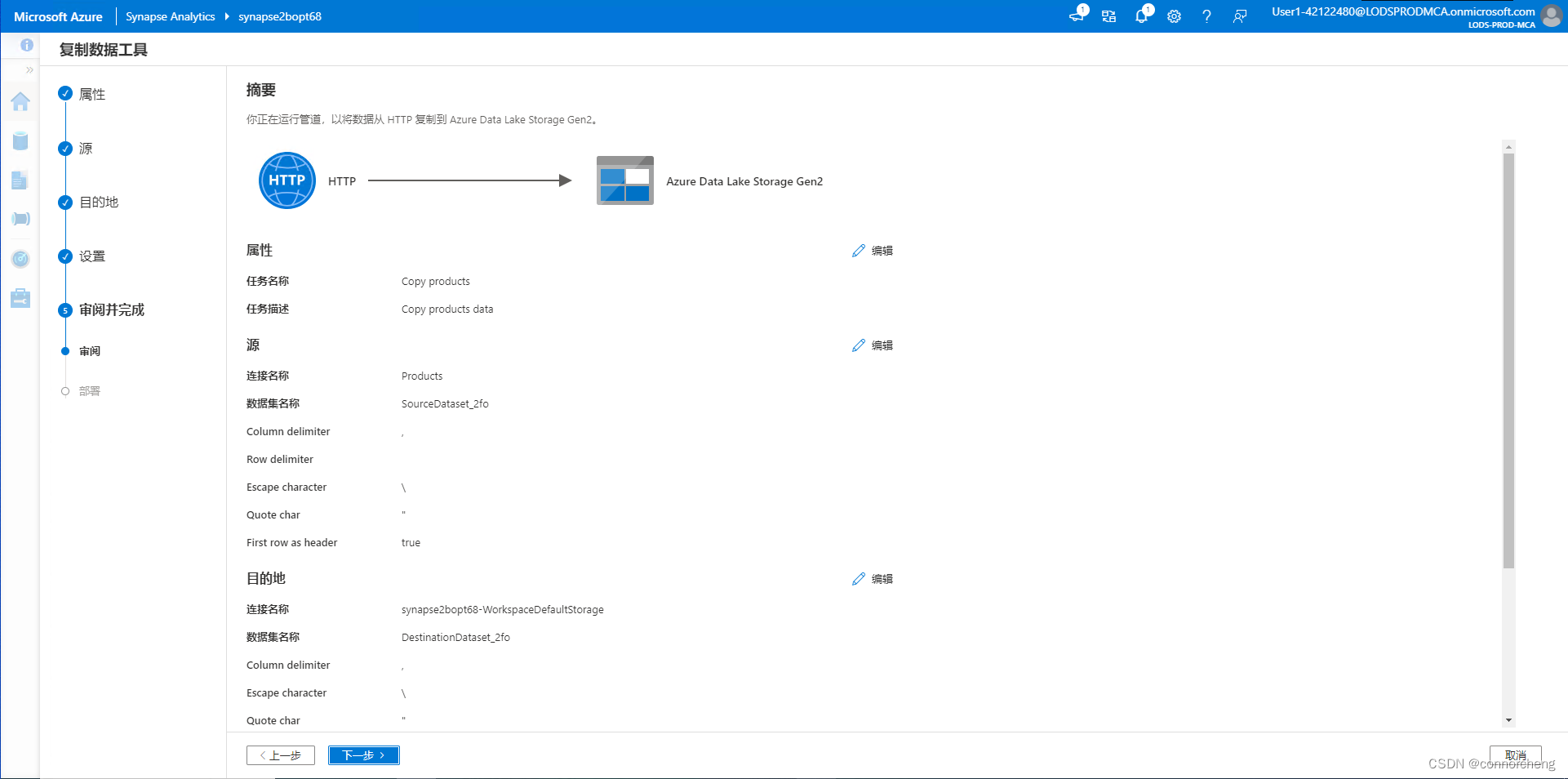
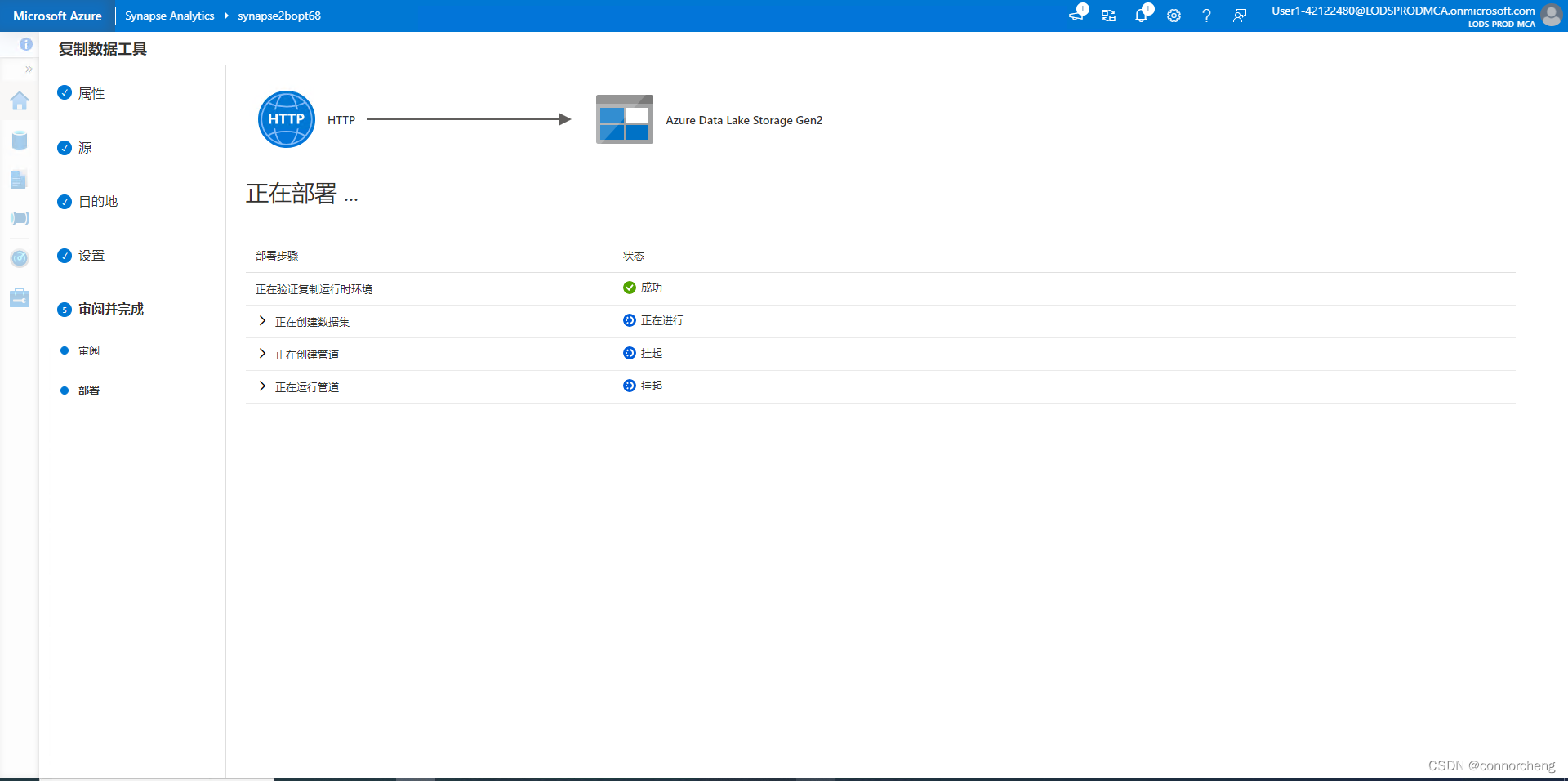
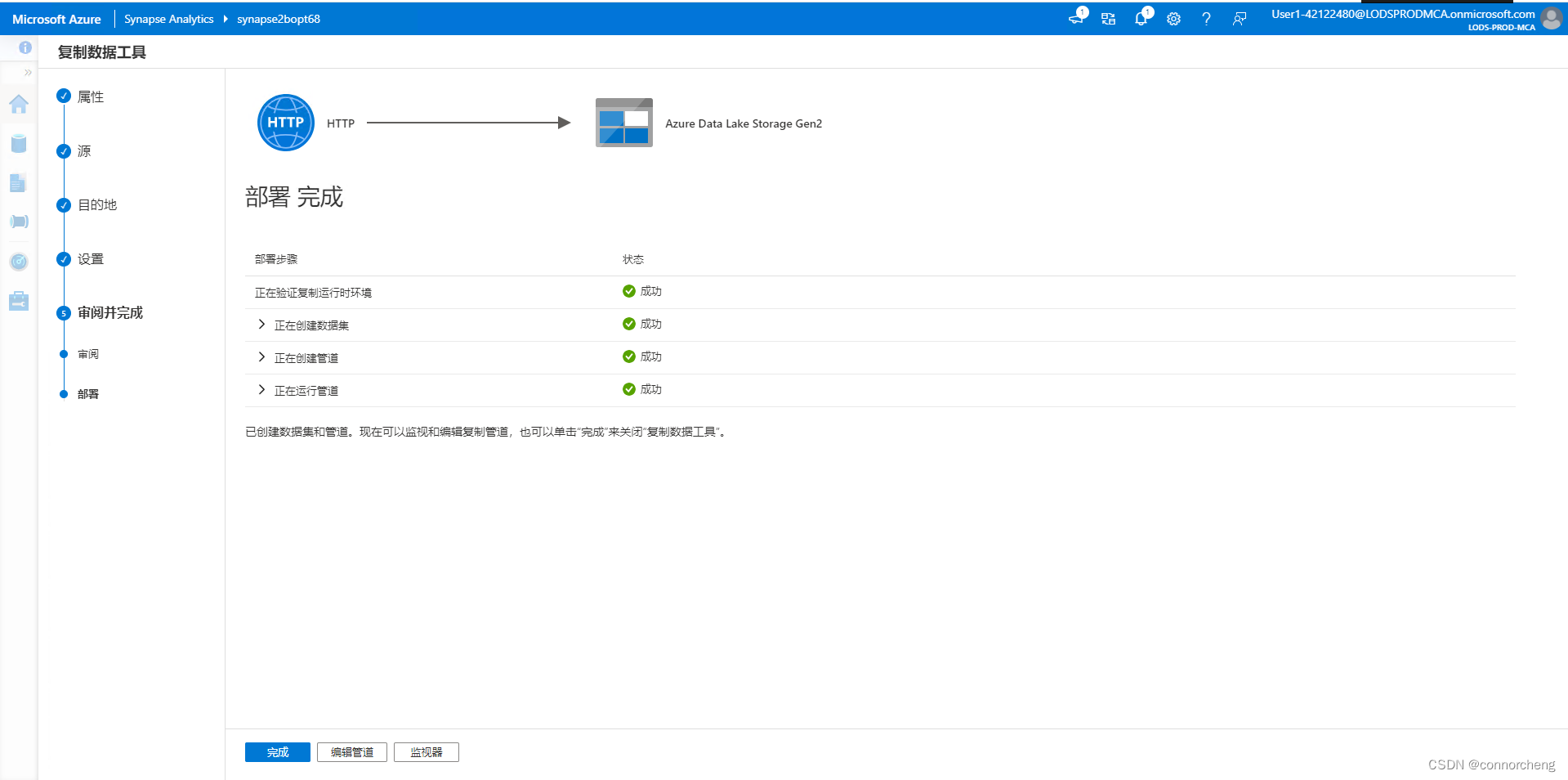
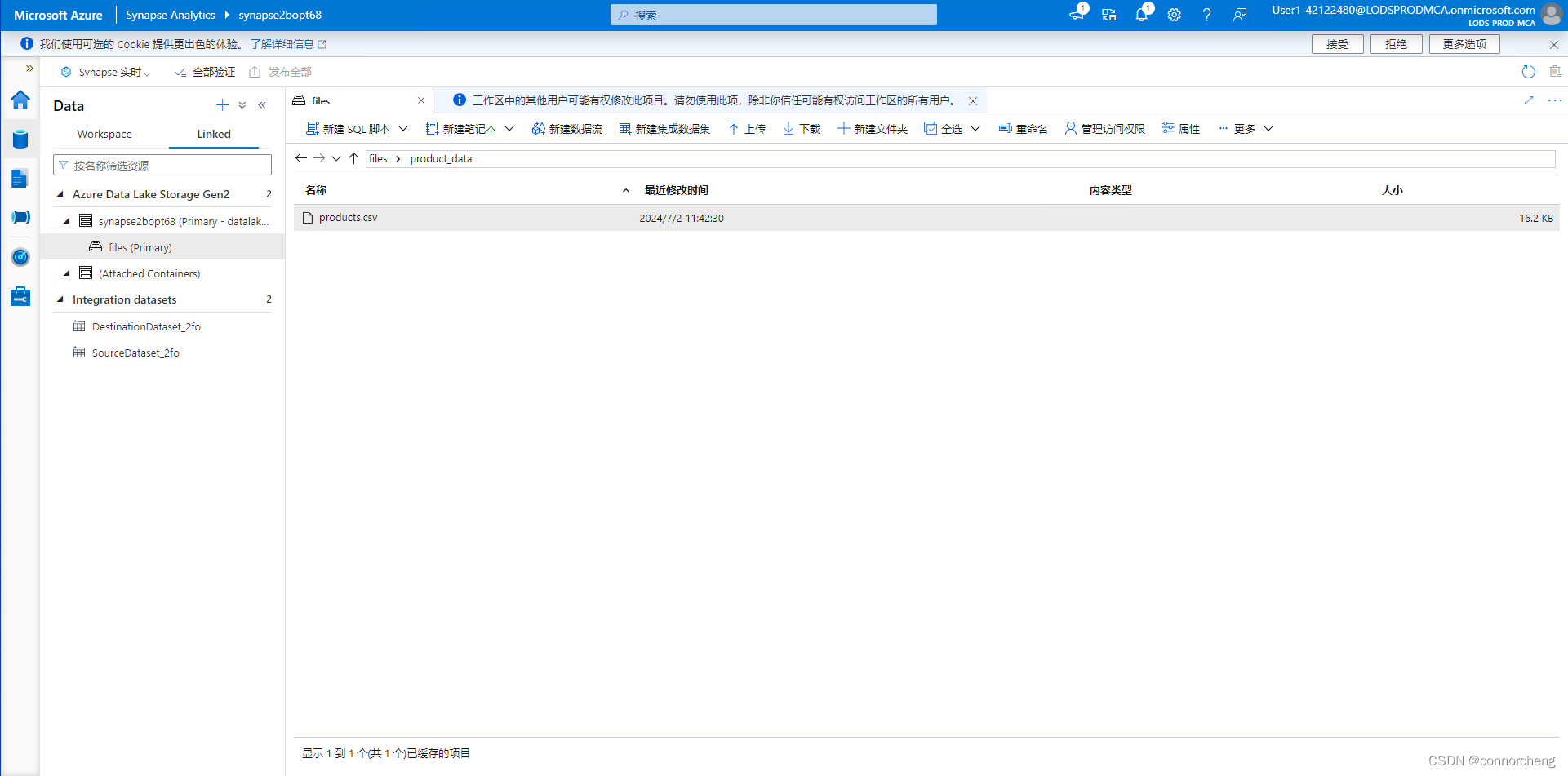
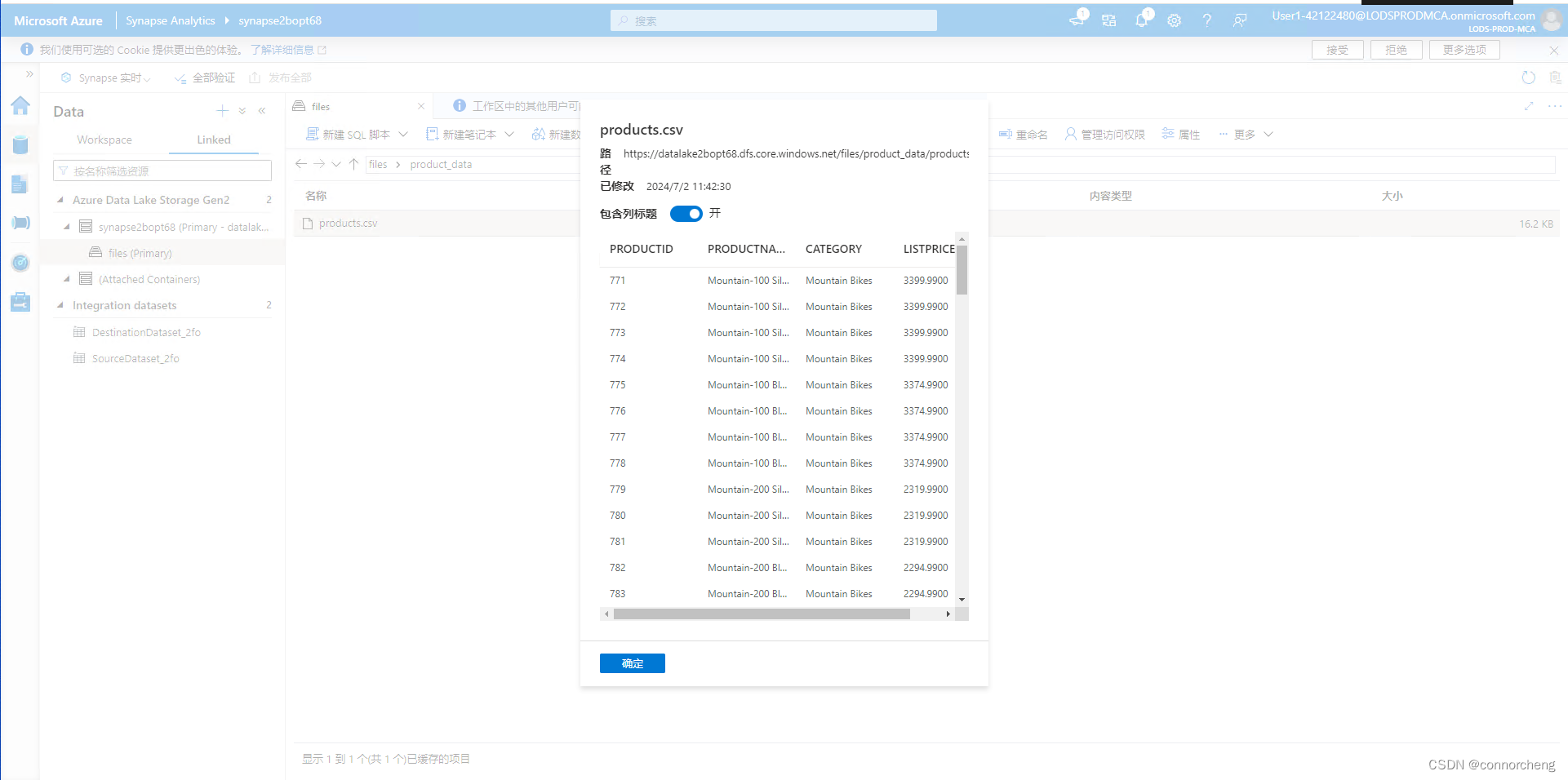
-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
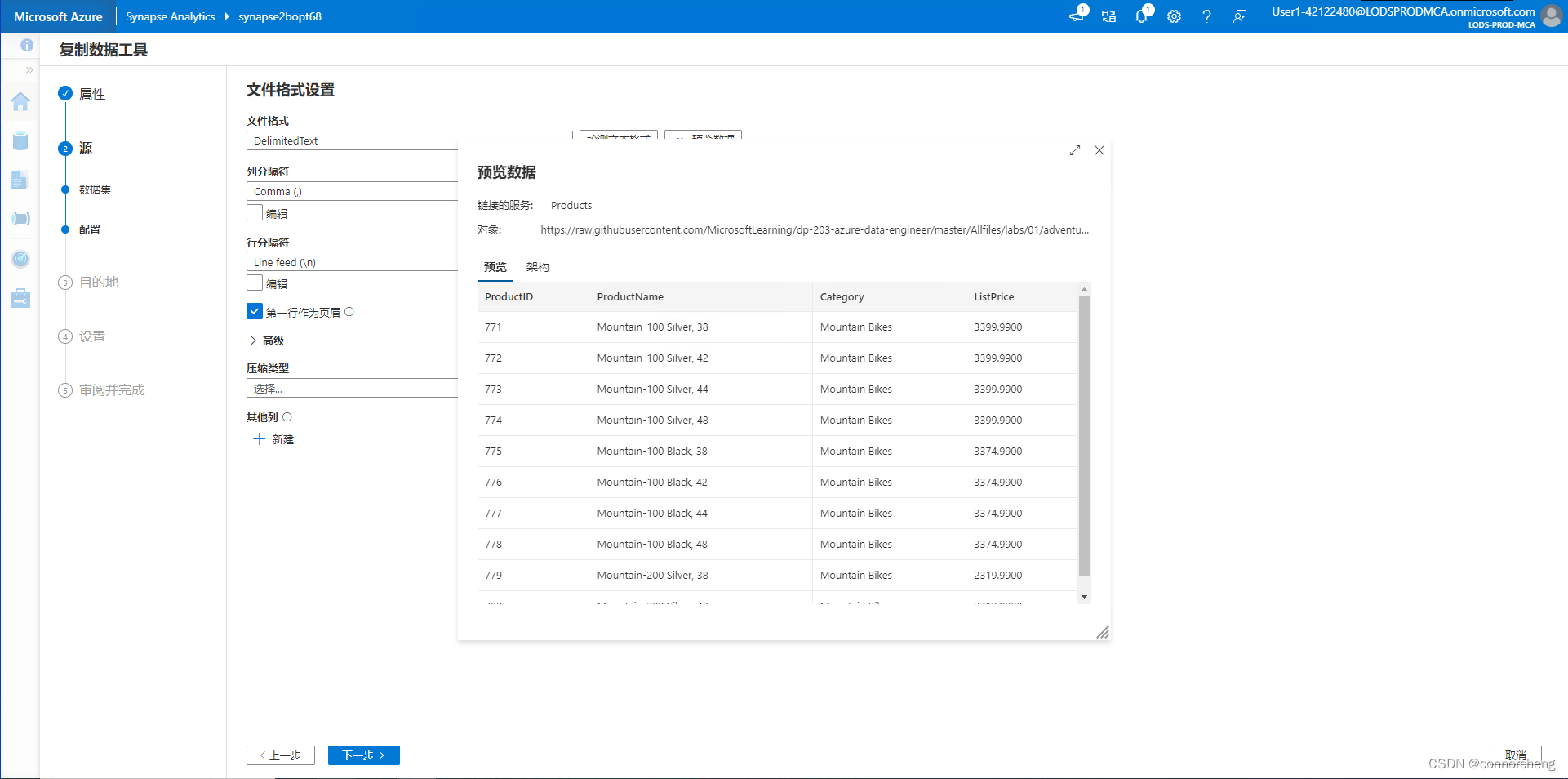
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/product_data/products.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0'
) AS [result]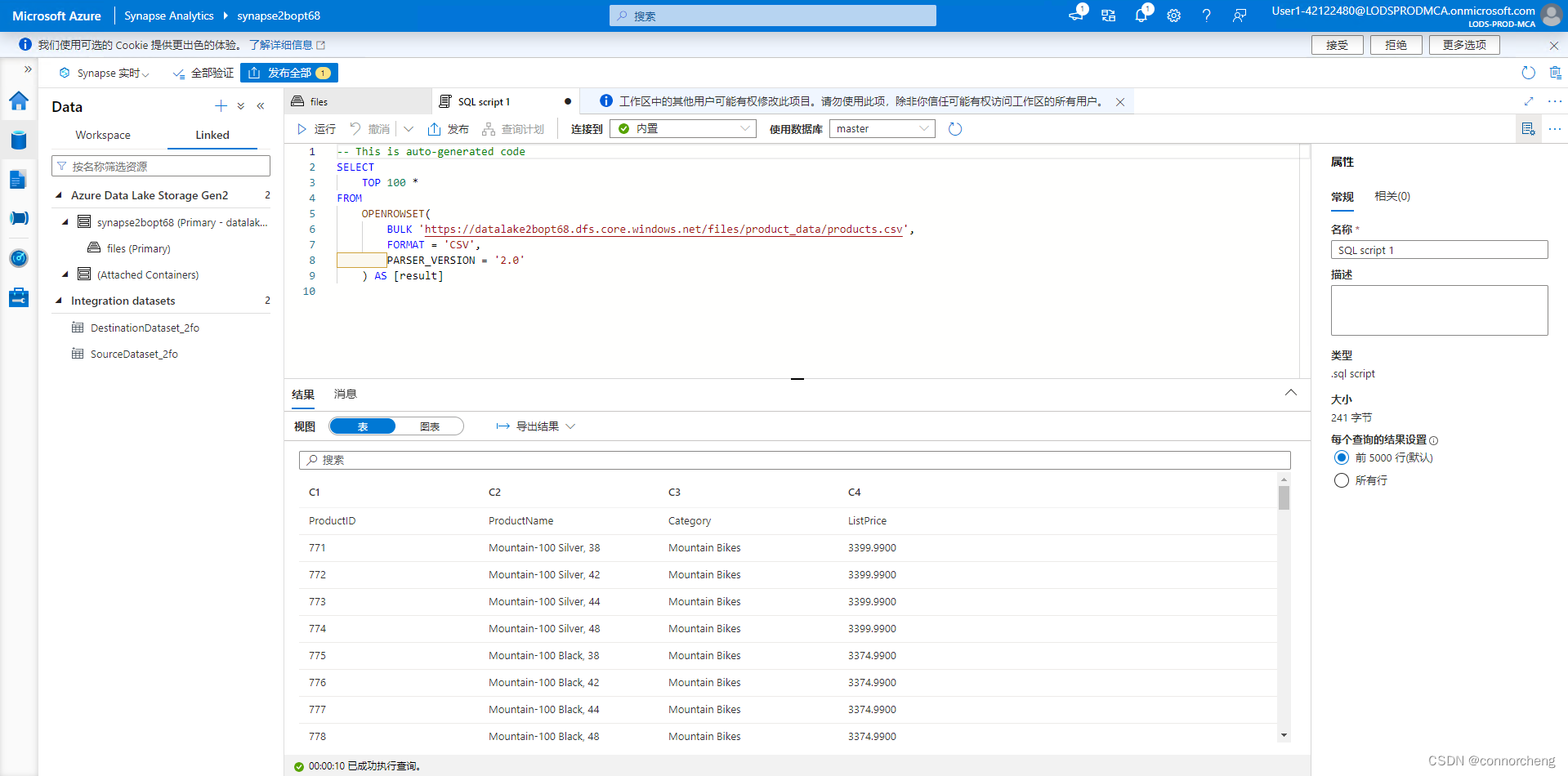
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/product_data/products.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
) AS [result]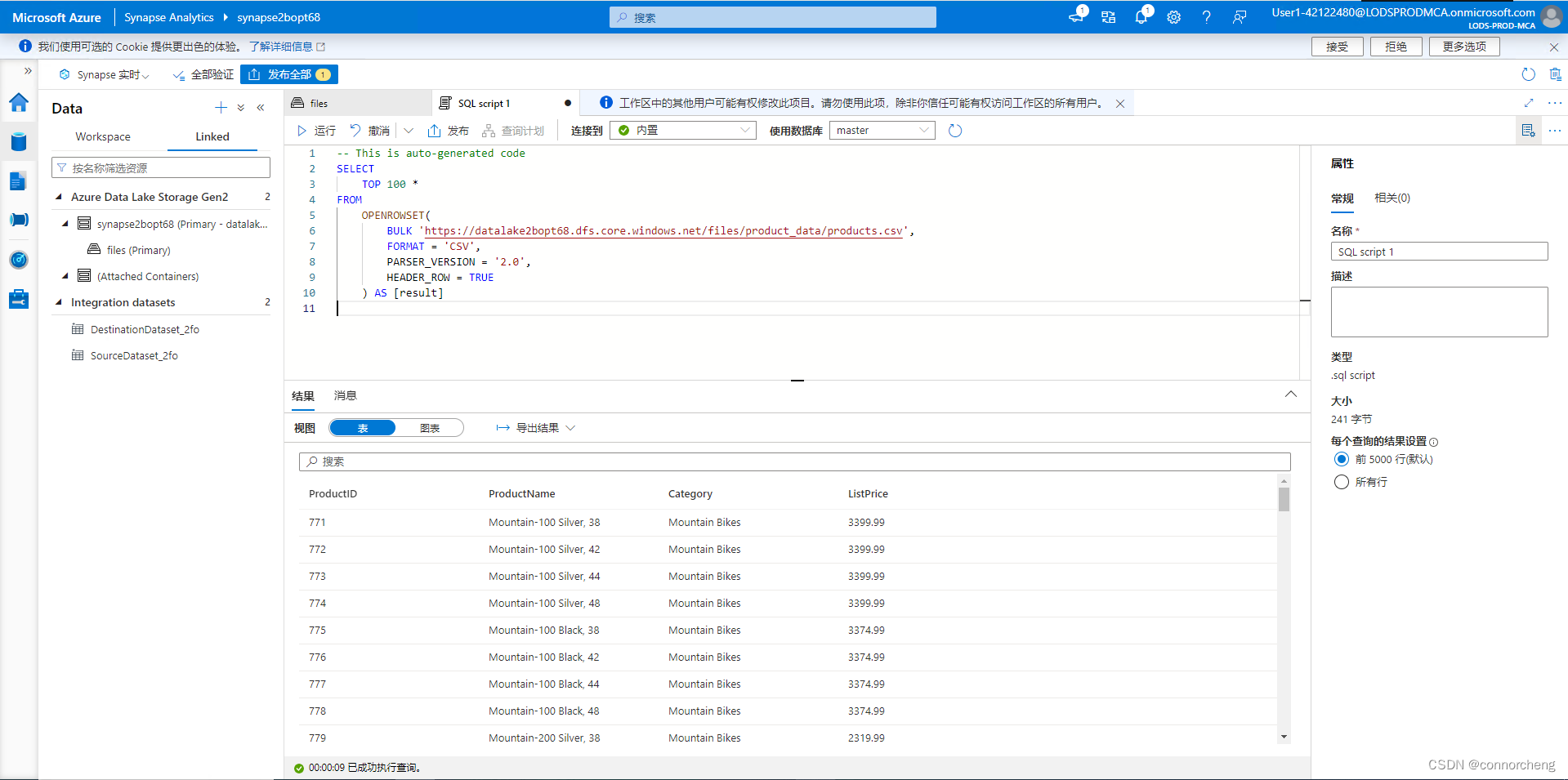
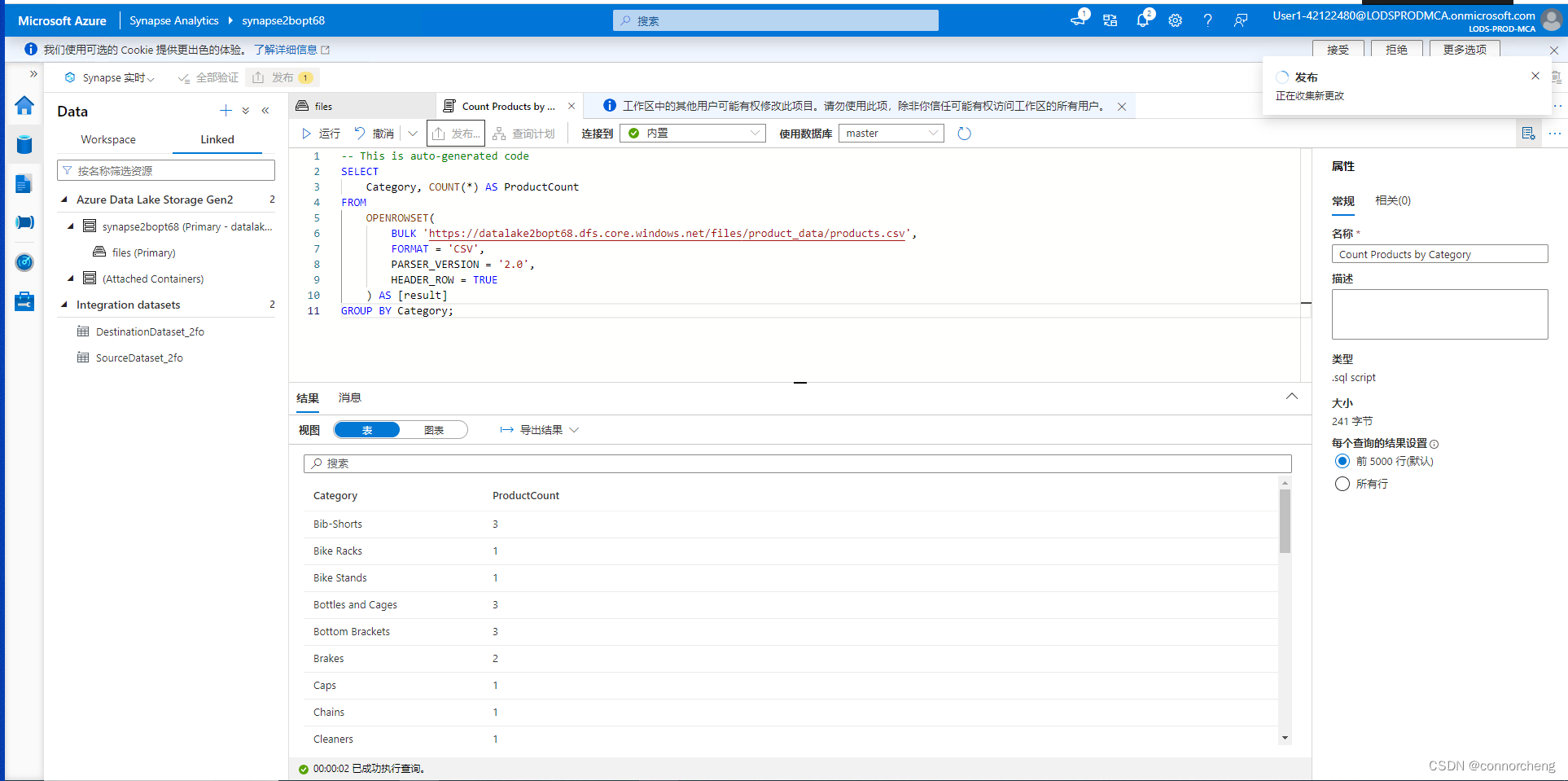
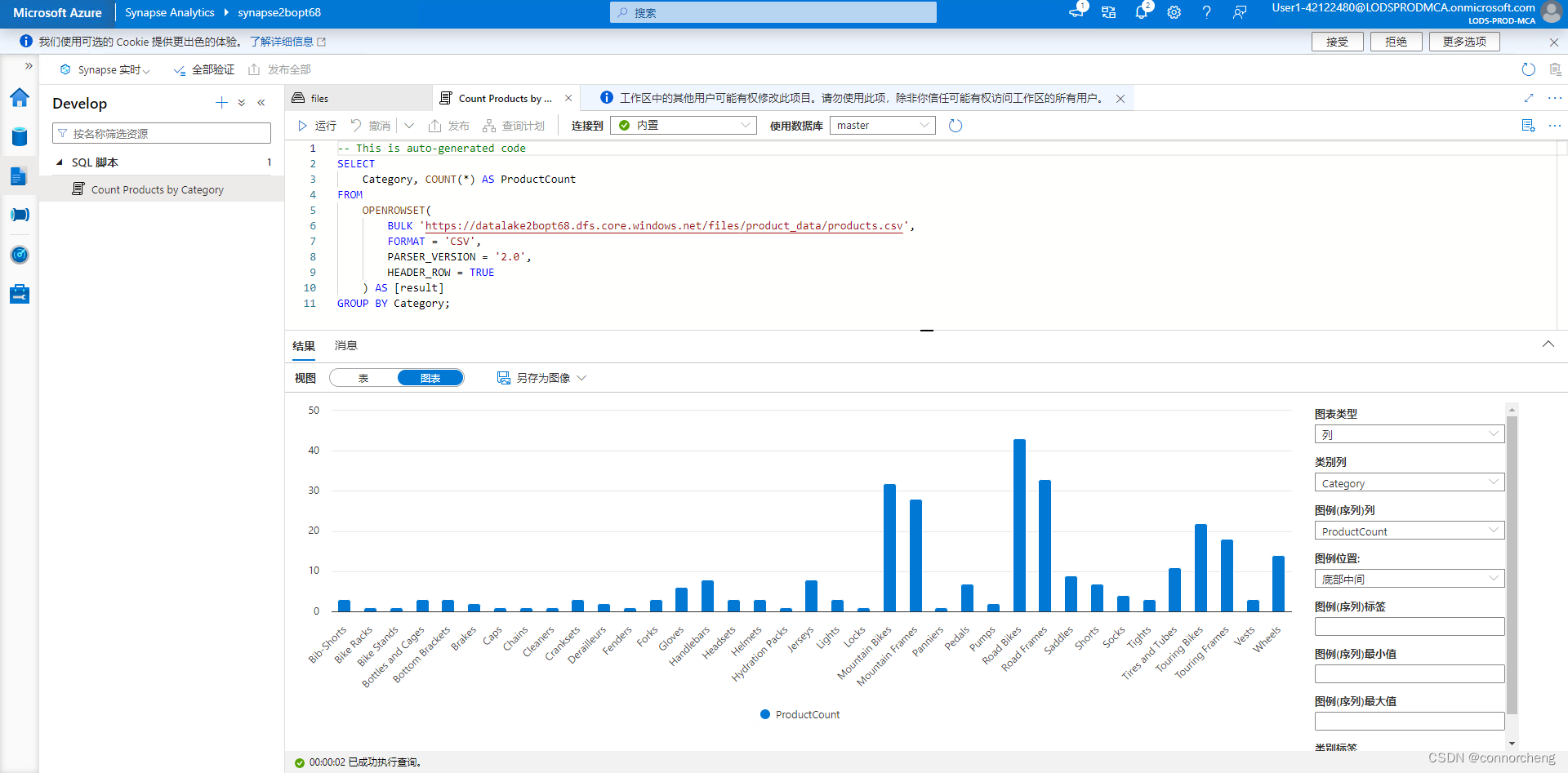
SELECT
Category, COUNT(*) AS ProductCount
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/product_data/products.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
) AS [result]
GROUP BY Category;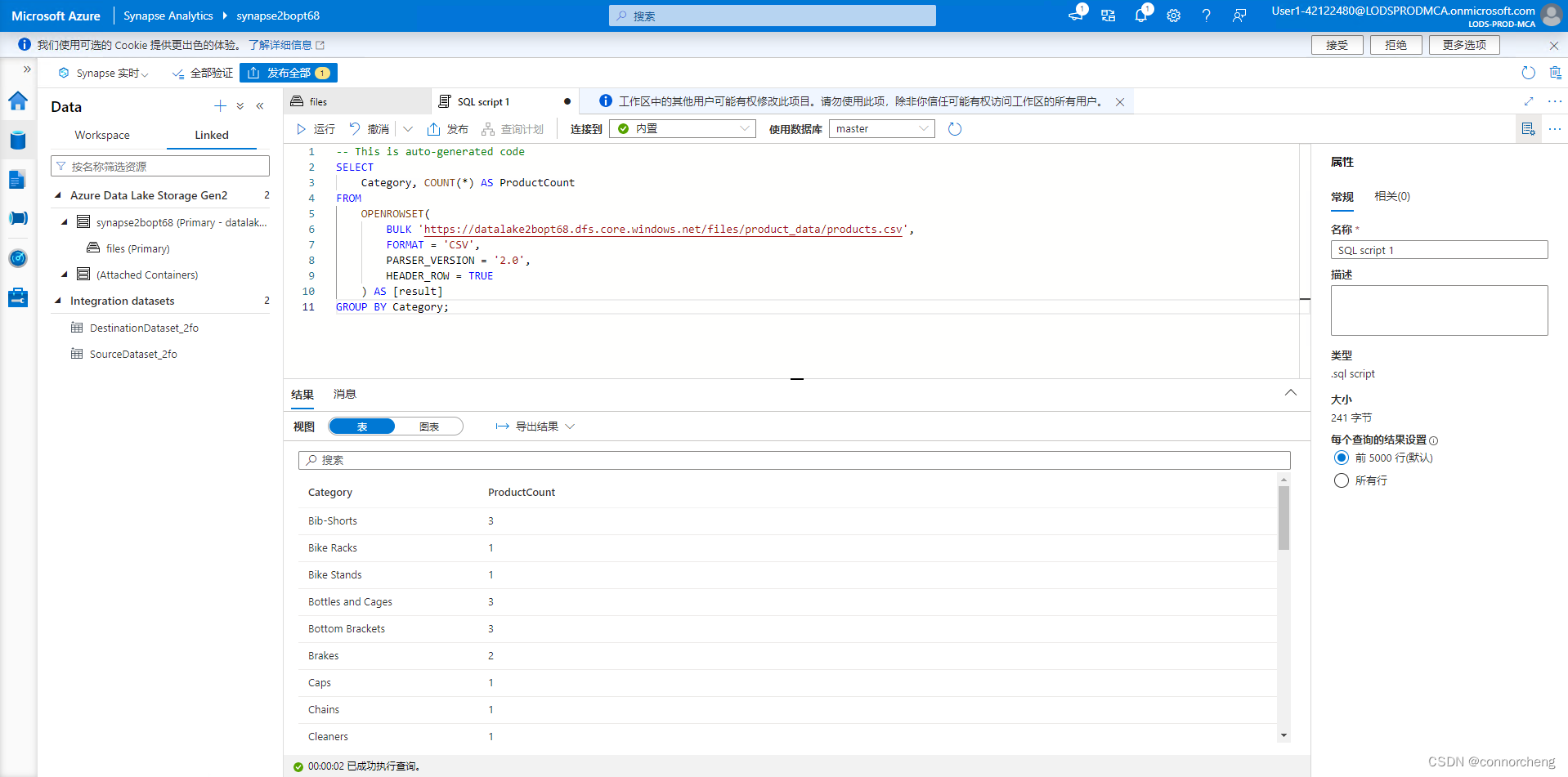
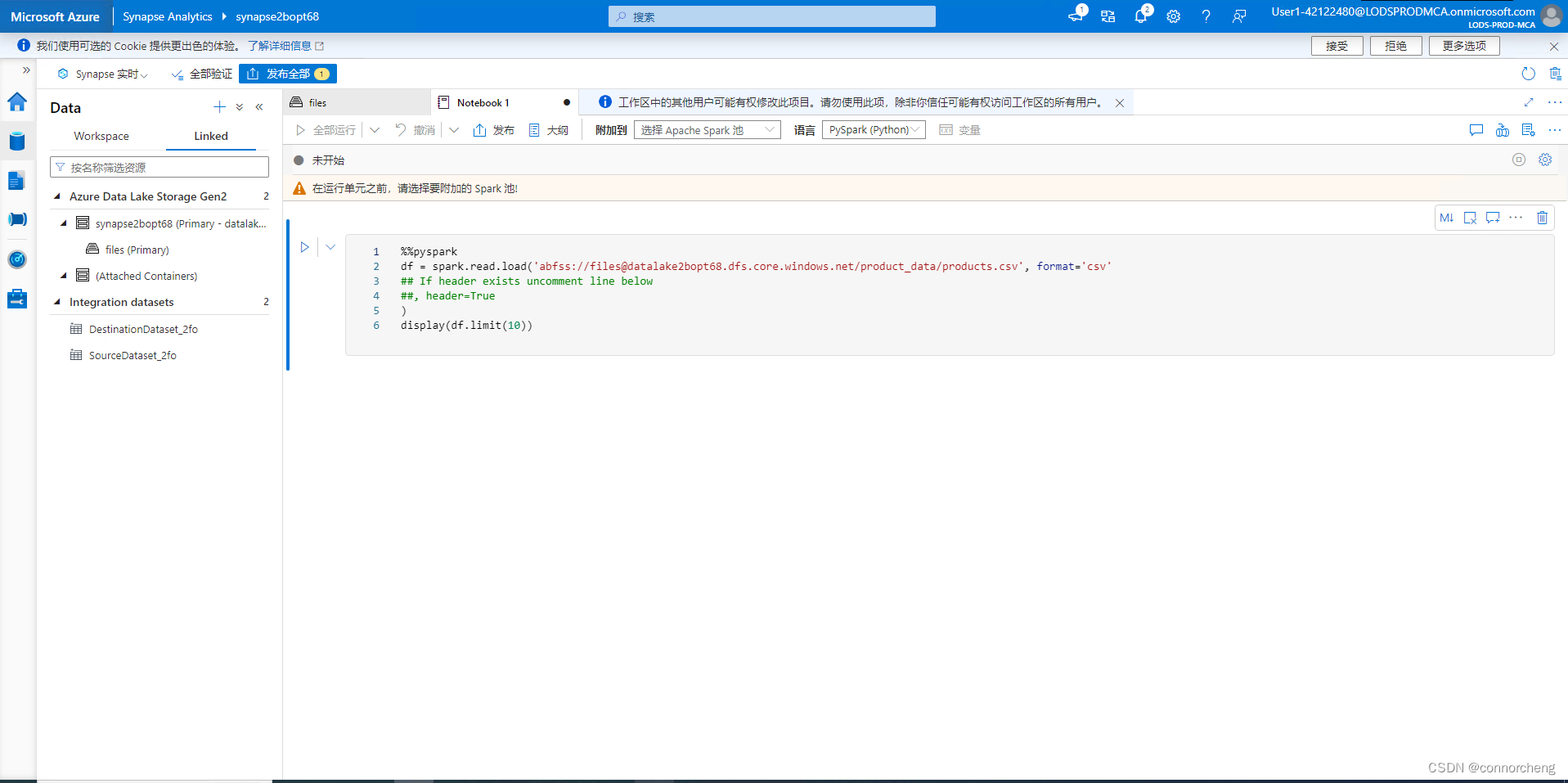
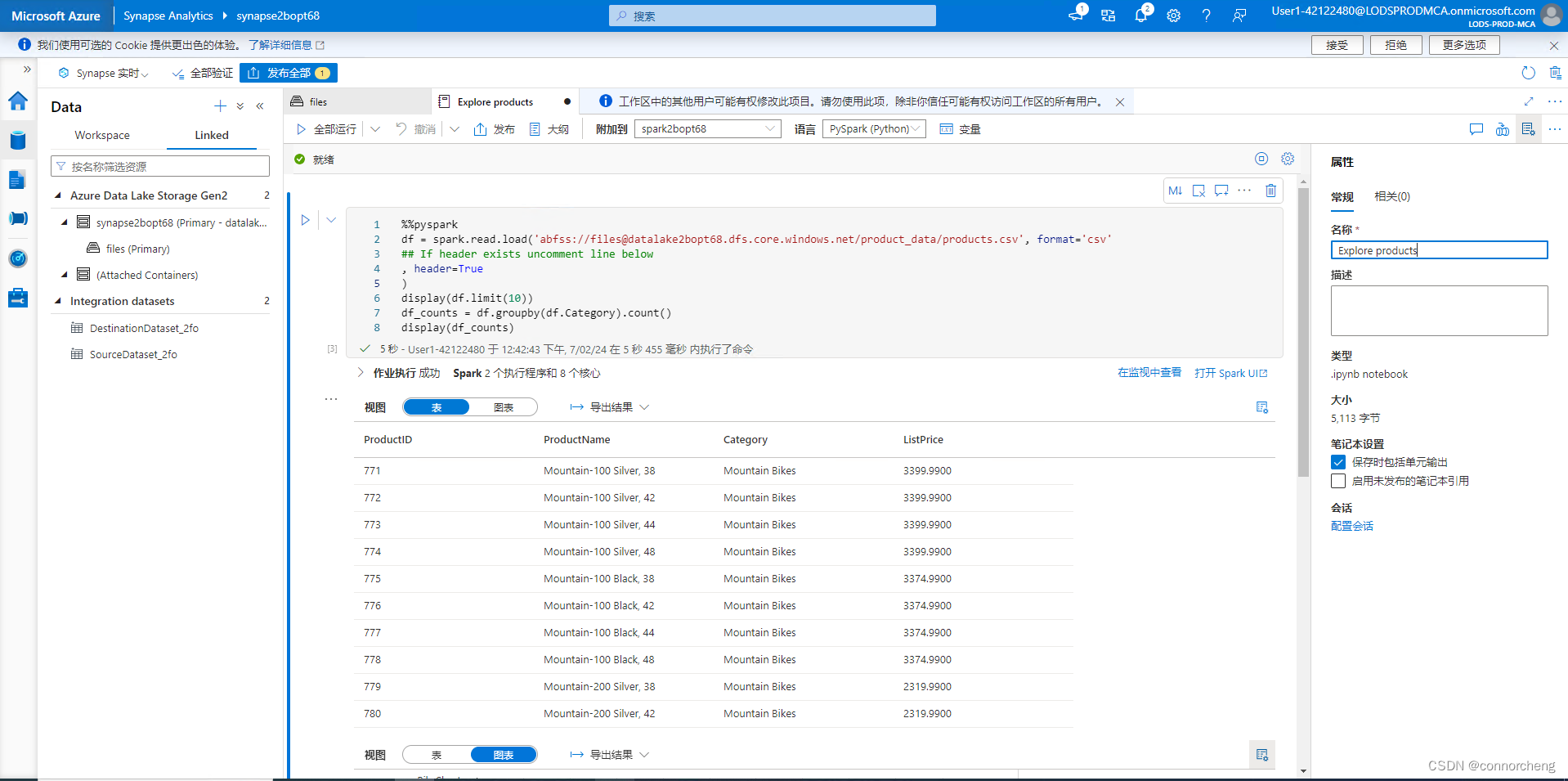
%%pyspark
df = spark.read.load('abfss://files@datalakexxxxxxx.dfs.core.windows.net/product_data/products.csv', format='csv'
## If header exists uncomment line below
##, header=True
)
display(df.limit(10))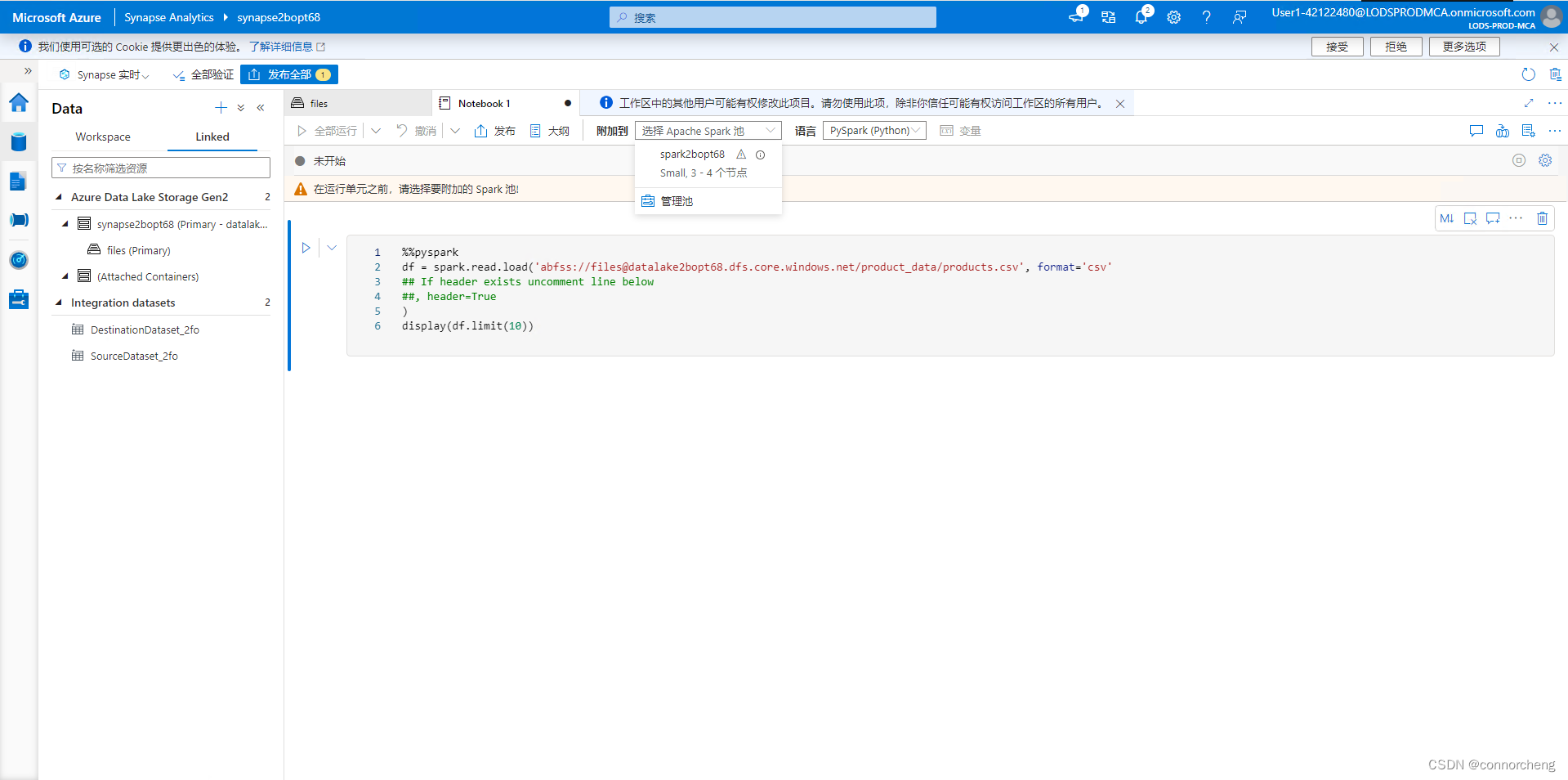
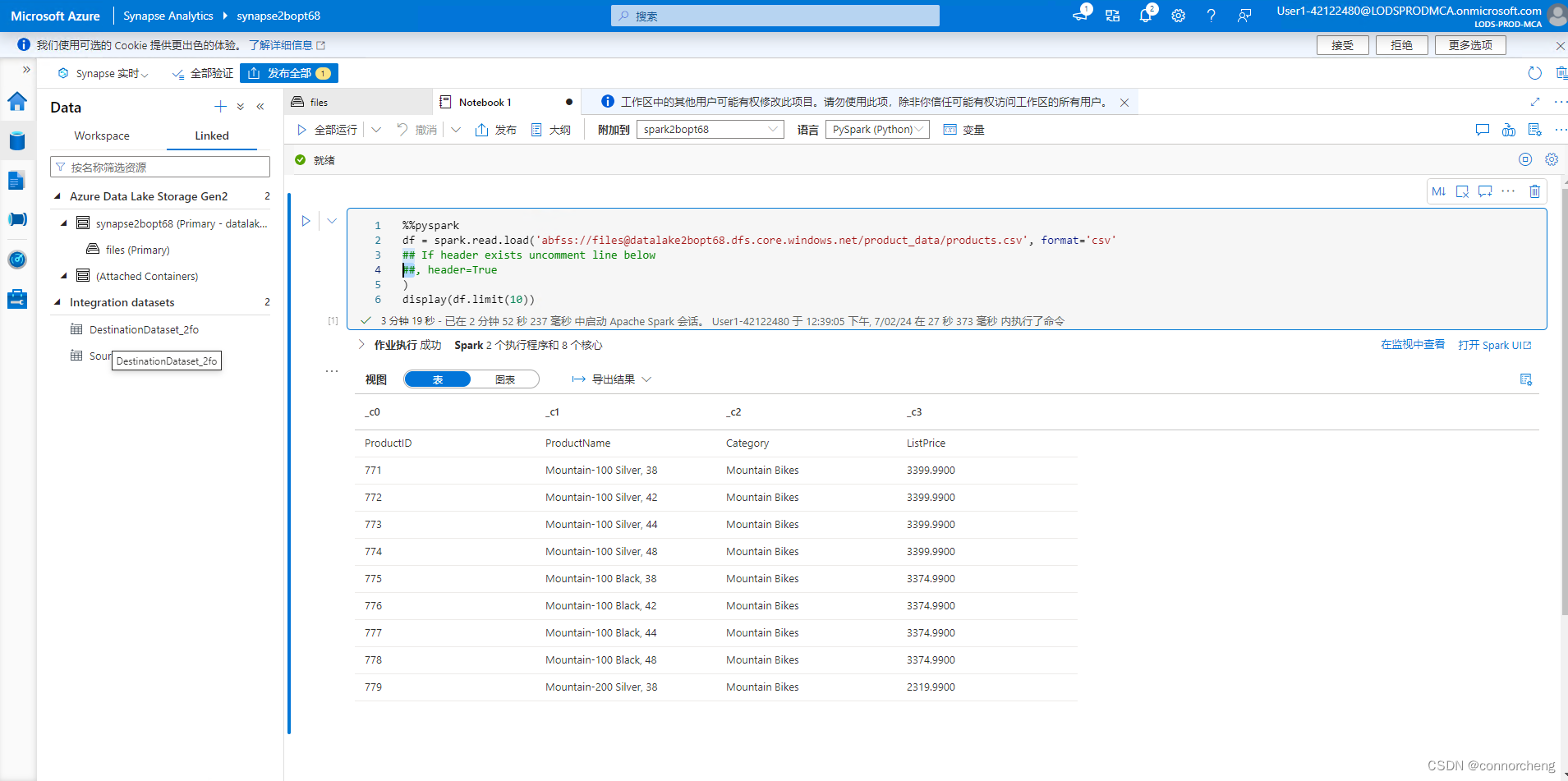
%%pyspark
df = spark.read.load('abfss://files@datalakexxxxxxx.dfs.core.windows.net/product_data/products.csv', format='csv'
## If header exists uncomment line below
, header=True
)
display(df.limit(10))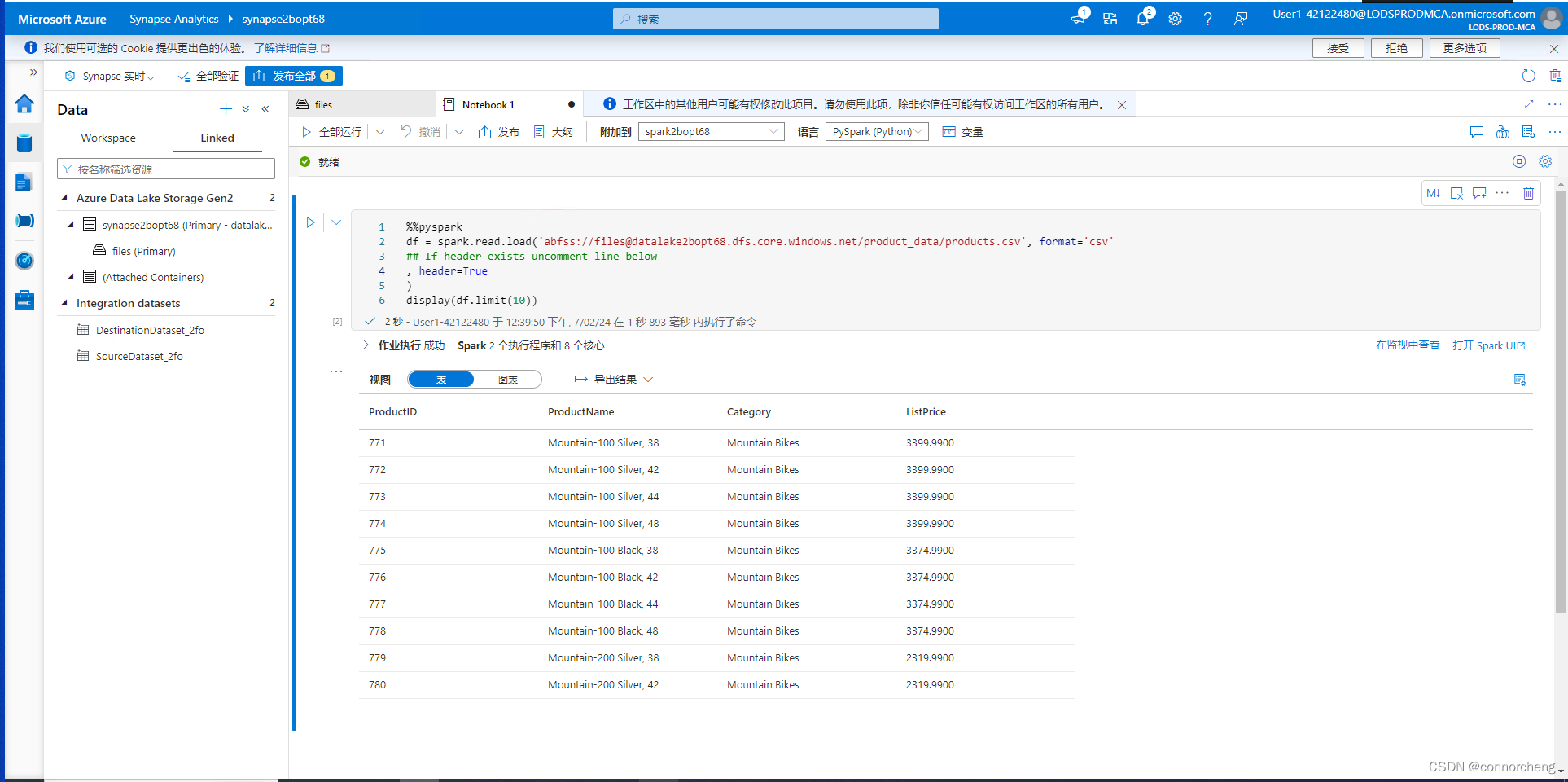
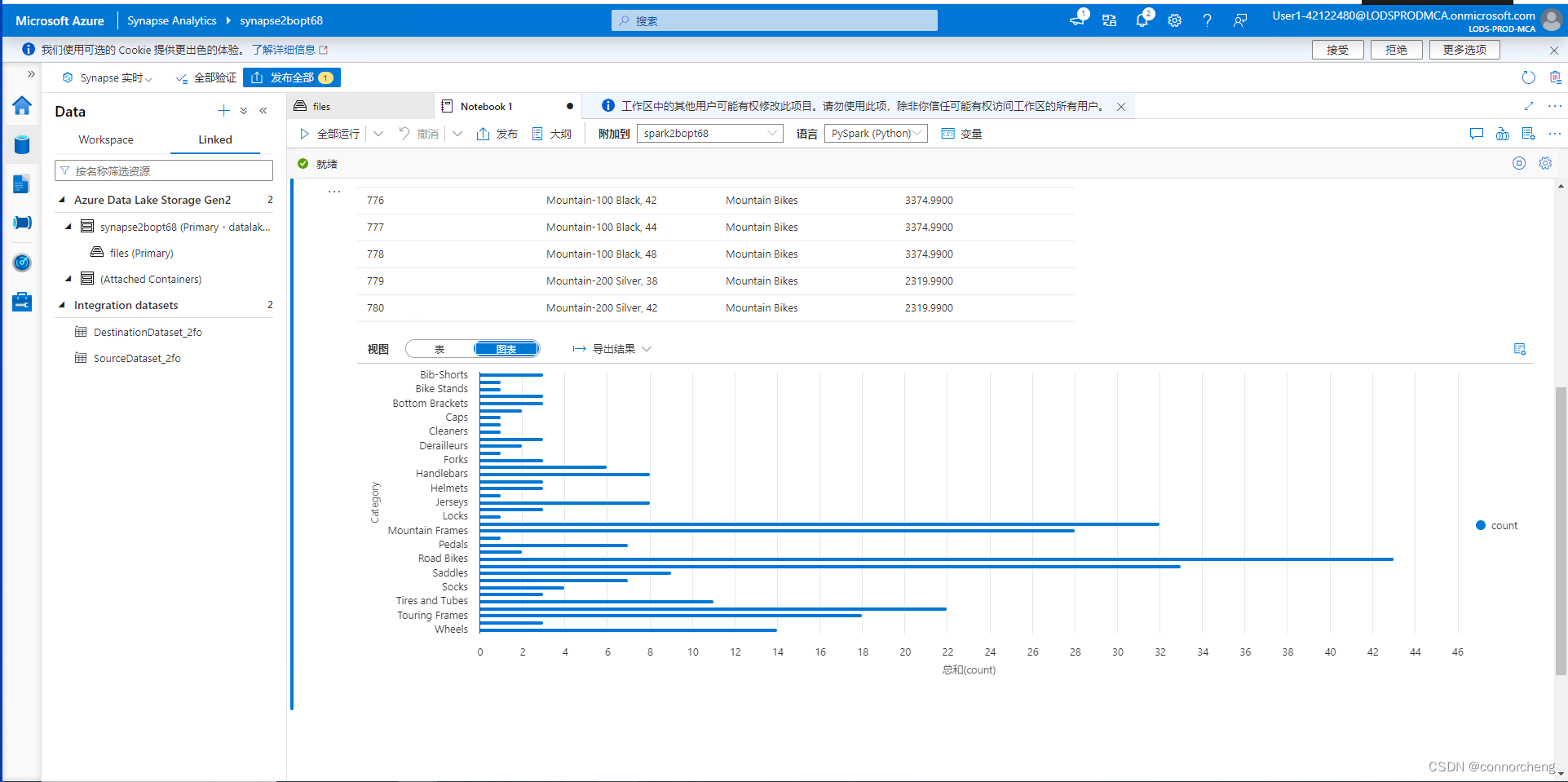
df_counts = df.groupby(df.Category).count()
display(df_counts)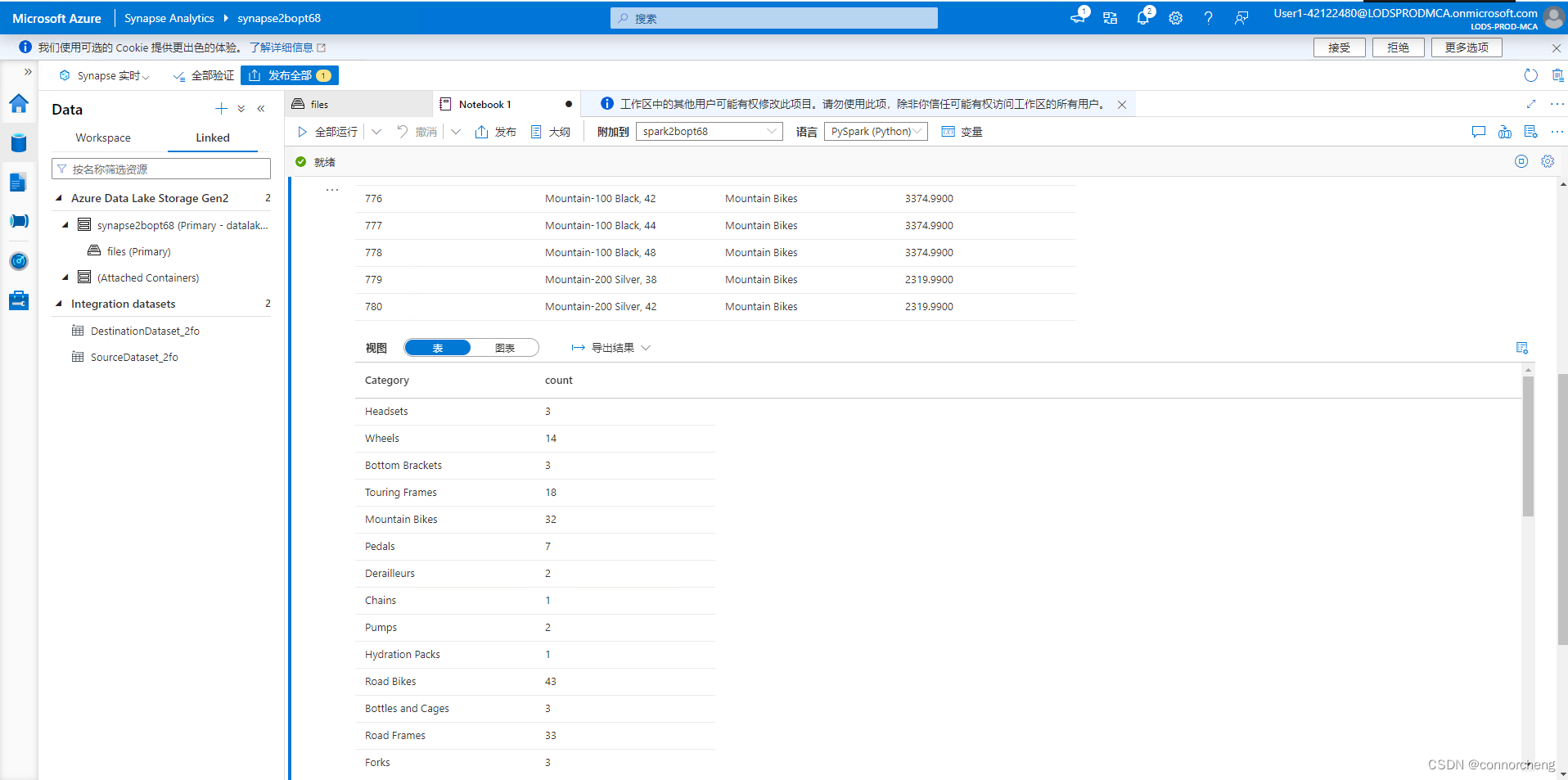
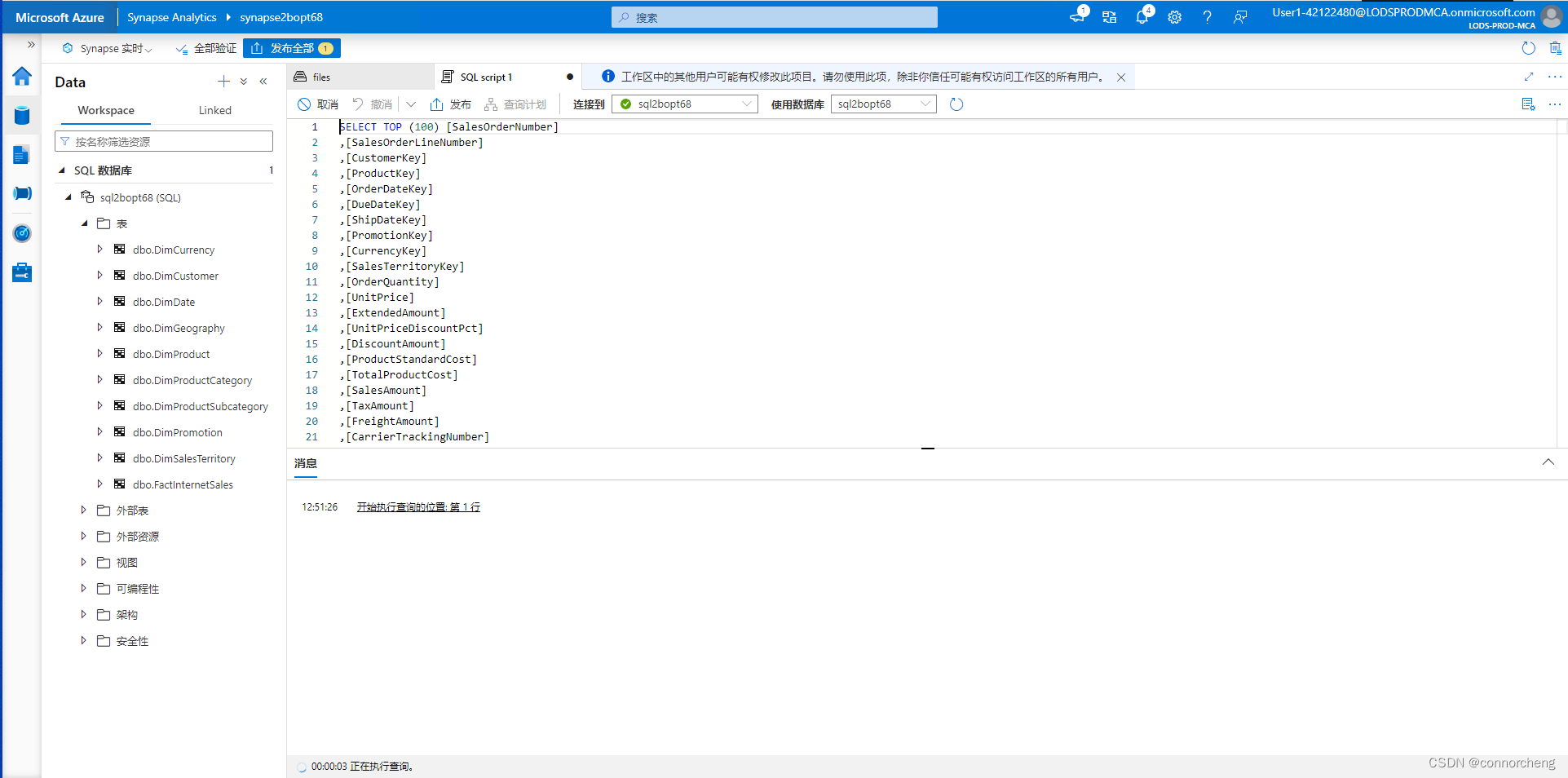
SELECT d.CalendarYear, d.MonthNumberOfYear, d.EnglishMonthName,
p.EnglishProductName AS Product, SUM(o.OrderQuantity) AS UnitsSold
FROM dbo.FactInternetSales AS o
JOIN dbo.DimDate AS d ON o.OrderDateKey = d.DateKey
JOIN dbo.DimProduct AS p ON o.ProductKey = p.ProductKey
GROUP BY d.CalendarYear, d.MonthNumberOfYear, d.EnglishMonthName, p.EnglishProductName
ORDER BY d.MonthNumberOfYear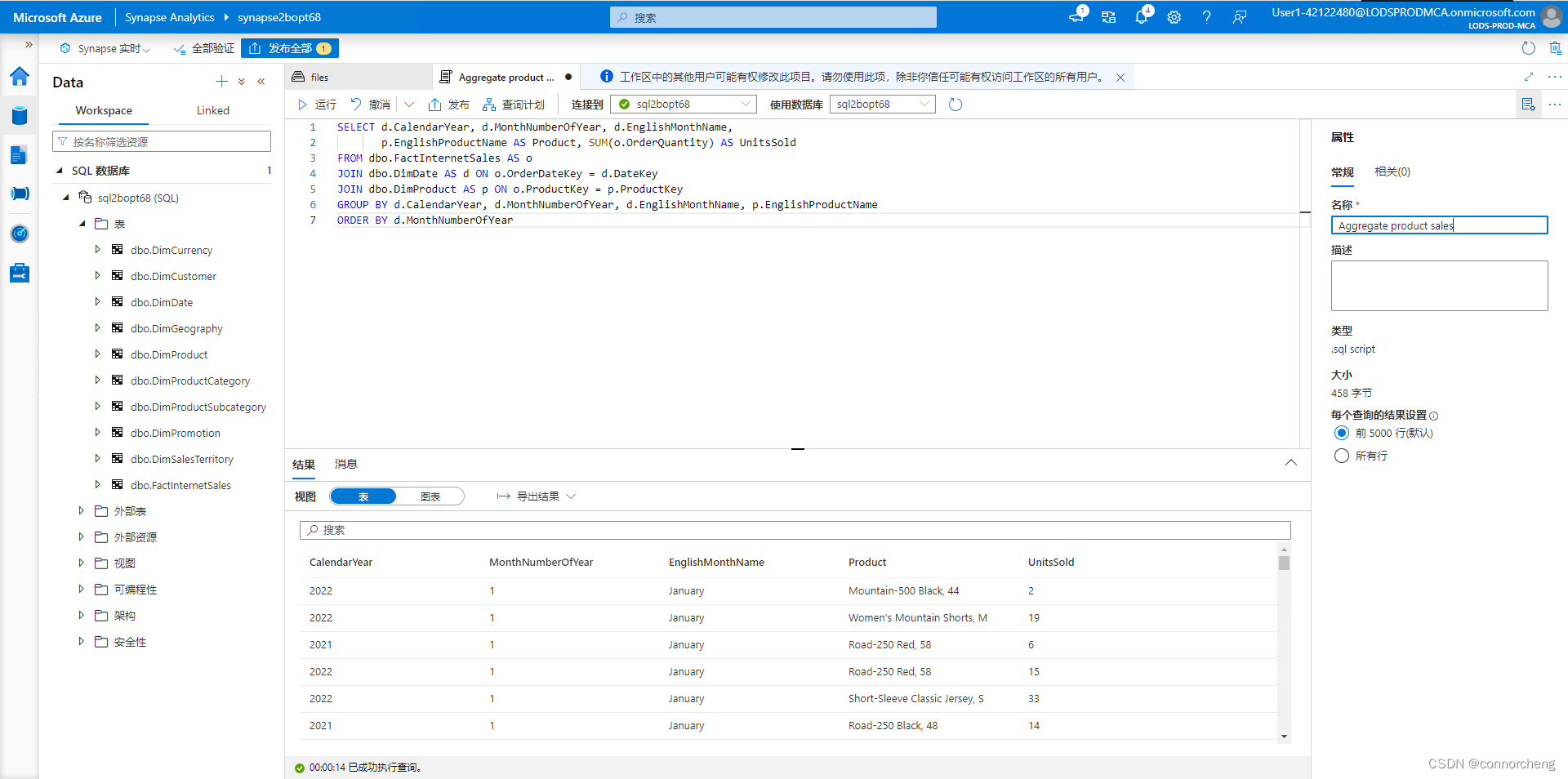










![[激光原理与应用-98]:南京科耐激光-激光焊接-焊中检测-智能制程监测系统IPM介绍 - 2 - 什么是激光器焊接? 常见的激光焊接技术详解](https://img-blog.csdnimg.cn/direct/cb6a02565e544d97a705d3a6dd7ddcc9.png)