一、故障起因
起因是用户反馈系统很卡,我登录普罗米修斯一看,发现docker部署得集群下的一个java应用服务器cpu爆了,直接冲到了1000%以上了,接着就是各种接口超时报警等,赶紧打开对应的服务器查看进程情况,这会使用jstack和top命令定位哪个线程占用的cpu比较大,定位代码问题。
二、常见的cpu100%以上异常的情况
程序中存在内存泄漏或者内存溢出,导致 JVM 不断进行垃圾回收;
代码中调用的某些资源造成的死锁或者是代码的死循环导致的cpu超频计算,或者长时间占用cpu的操作,像一些递归的使用、循环操作等等,或者一些特别复杂的正则匹配引起;
程序中存在大量的 IO 操作;
程序中存在大量的数据库操作,导致数据库连接池的耗尽和数据库负载过高。
三、排查方法
排查cpu过高的java导出日志,交给开发排查问题
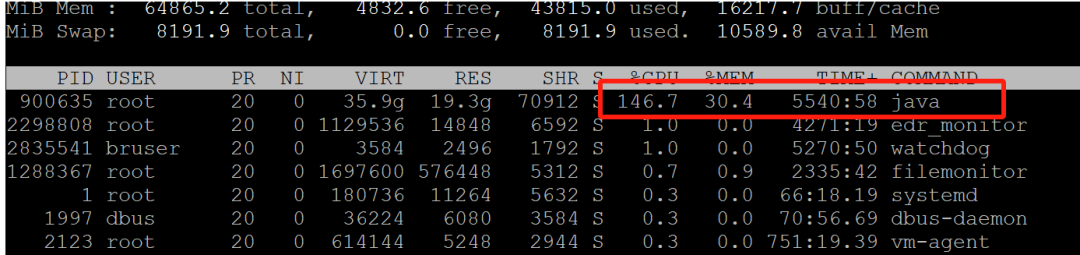
1.top查看cpu使用率比较高的线程
top打印
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
900635 root 20 0 36.1g 19.4g 70976 S 153.0 30.7 5619:07 java