文章目录
- 1、前言
- 2、正则表达式
- 2.1、 概述
- 2.2、 特点
- 2.3、正则表达式-测试工具
- 3、知识点
- 3.1、 正则表达式定义
- 3.2、 正则表达式的组成
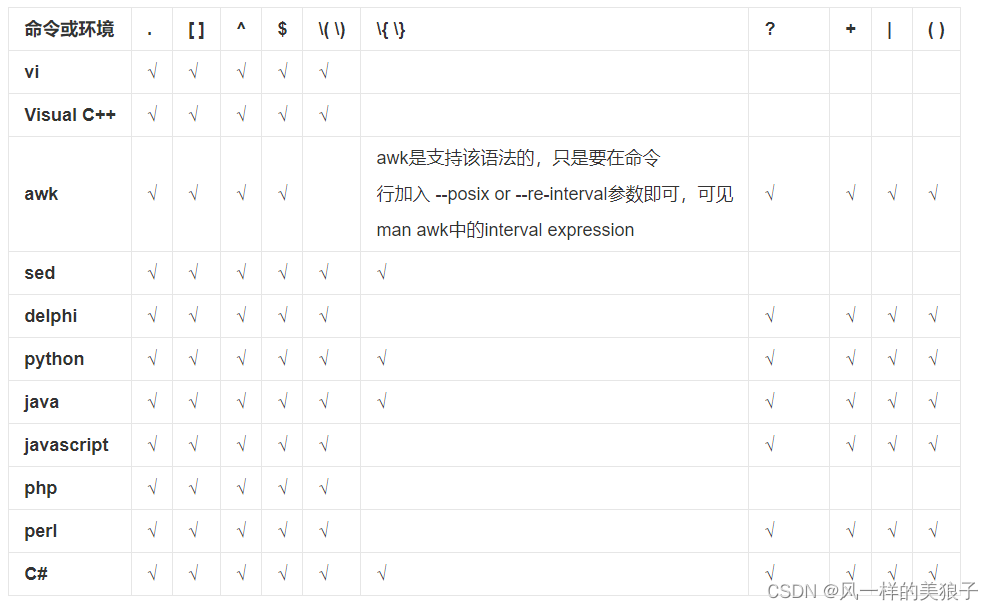
- 3.3、正则表达式语法支持情况
- 4、速记理解技巧
- 4.1、基础正则表达式
- 4.2、等价
- 4.3、常用运算符与表达式
- 4.4、分割语法
- 4.4.1、例型
- 4.4.2、例型语法与释义
- 4.4.3、实操例子释义
- 5、 结语
1、前言
上文我们讲到文本处理三剑客–grep继任者sed,通过正则表达式达到数据堆中如何快速定位到自己需要的内容。今天我们就更全面深入的讲解正则表达式的方方页面,揭开它的神秘面纱。
2、正则表达式
2.1、 概述
正则表达式又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE)。
它是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
通常被用来检索、替换那些符合某个模式(规则)的文本。
它并不仅限于某一种语言,但是在每种语言中有细微的差别。
2.2、 特点
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
- 灵活性、逻辑性和功能性非常的强;
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 对于刚接触的人来说,比较晦涩难懂。比如: 1\d*.\d*|0.\d*[1-9]\d*|0?.0+|0$
在实际开发中,一般都是直接复制写好的正则表达式.。即便这样我们还是要求会使用正则表达式并且根据实际情况修改正则表达式。比如数字:
^[0-9]*$
由于正则表达式主要应用对象是文本,因此它在各种文本编辑器场合都有应用,小到著名编辑器EditPlus,大到Microsoft Word、Visual Studio等大型编辑器,都可以使用正则表达式来处理文本内容。
2.3、正则表达式-测试工具
正所谓工欲善其事必先利其器! 手上没有几把好用的枪,咋开打。
所以我们需要知道下面几个称手的神兵利器:
http://www.regexpal.com/ 这个网站中,我们可以在线测试正则表达式。
推荐如下2个网站,它除了能够在线测试正则表达式,还包括了一个实例使我们直接测试,用于模仿学习。
https://c.runoob.com/front-end/854/ (重点推荐,可以生成不同语言的代码)
http://regexr.com/
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。只要认真阅读本教程,加上应用的时候进行一定的参考,掌握正则表达式不是问题。
3、知识点
3.1、 正则表达式定义
正则表达式 它是通过 使用字符串来描述、匹配一系列符合某个规则的字符串。
3.2、 正则表达式的组成
正则表达式由一些普通字符和一些元字符(metacharacters)组成。
1. 普通字符
大小写字母、数字、标点符号及一些其他符号。
2. 元字符
在正则表达式中具有特殊意义的专用字符。
\:转义字符,\!、\n等
^:匹配字符串开始的位置
$:匹配字符串结束的位置
.:匹配除\n之外的任意的一个字符
*:匹配前面子表达式0次或者多次
[list]:匹配list列表中的一个字符
[^list]:匹配任意不在list列表中的一个字符
\{n,m\}:匹配前面的子表达式n到m次,有\{n\}、\{n,\}、\{n,m\}三种格式,分别表示
表示前面的内容出现n次,
表示前面的内容出现n次以上(含n次),
表示前面的内容出现最少n次最多m次。
3. 扩展元字符
+:匹配前面子表达式内容出现1次及以上
?:匹配前面子表达式内容出现0次或者1次
():将括号中的字符串作为一个整体
|:以或的方式匹配字条串
3.3、正则表达式语法支持情况
4、速记理解技巧
4.1、基础正则表达式
.[ ]^$
因为这四个字符是所有语言都支持的正则表达式,所以我在此把这四个作为基础的正则表达式。
正则难理解因为里面有一个等价的概念,这个概念大大增加了理解难度,让很多初学者接触起来会感到一头雾水懵圈,但是我们如果把等价都恢复成原始写法,自己书写正则就超级简单了,就像我们平时讲话一样去写你自己的正则了:
4.2、等价
等价即我们平常讲的等同于的意思,表示同样的功能,用不同符号来书写。
- ?,*,+,\d,\w 都是等价字符
- ?等价于匹配长度{0,1}
- *等价于匹配长度{0,}
- +等价于匹配长度{1,}
- \d等价于[0-9]
- \D等价于[^0-9]
- \w等价于[A-Za-z_0-9]
- \W等价于[^A-Za-z_0-9]。
4.3、常用运算符与表达式
- ^ 开始
- ()域段
- [] 包含,默认是一个字符长度
- [^] 不包含,默认是一个字符长度
- {n,m} 匹配长度
- . 任何单个字符(. 字符点)
- | 或
- \ 转义
- $ 结尾
- [A-Z] 26个大写字母
- [a-z] 26个小写字母
- [0-9] 0至9数字
- [A-Za-z0-9] 26个大写字母、26个小写字母和0至9数字
- , 分割
4.4、分割语法
4.4.1、例型
- [A,B,E,W] 包含A或B或E或W字母
- [a,e,c,t] 包含a或e或c或t字母
- [0,3,5,9] 包含0或3或5或9数字
4.4.2、例型语法与释义
基础语法 “^([]{})([]{})([]{})$”
正则字符串 = “开始([包含内容]{长度})([包含内容]{长度})([包含内容]{长度})结束”
?,,+,\d,\w 这些都是简写的,完全可以用[]和{}代替,在(?😃(?=)(?!)(?<=)(?<!)(?i)(?)(+?)这种特殊组合情况下除外。
初学者可以忽略?,*,+,\d,\w一些简写标示符,学会了基础使用再按表自己去等价替换
4.4.3、实操例子释义
下面我们来以一些例子来做说明如下:
字符串;tel:021-0518-66620009111
原始正则:“^tel:[0-9]{1,3}-[0][0-9]{2,3}-[0-9]{8,11}$”
速记理解:开始 “tel:普通文本”[0-9数字]{1至3位}“-普通文本”[0数字][0-9数字]{2至3位}“-普通文本”[0-9数字]{8至11位} 结束"
等价简写后正则写法:“^tel:\d{1,3}-[0]\d{2,3}-\d{8,11}$” ,简写语法不是所有语言都支持。
5、 结语
上面针对正则表达式 讲述了这么多,因它并不仅限于某一种语言,所以在每种语言中都会有细微的差别。
想子解更多关于正则表达式内容可下载 《正则表达式日常使用大全及元字符大全使用说明》
参考资料
1 胡军伟, 秦奕青, 张伟. 正则表达式在Web信息抽取中的应用[J]. 北京信息科技大学学报(自然科学版), 2011, 26(6):86-89.
2 赵兴涛, 王斌君, 刘舒. 正则表达式在文档自动识别中的应用[J]. 中国人民公安大学学报:自然科学版, 2005, 11(04):38-40.
1-9 ↩︎

![03_PyTorch 模型训练[Dataset 类读取数据集]](https://img-blog.csdnimg.cn/67fc8af72b514af28c81d45885e93857.png)