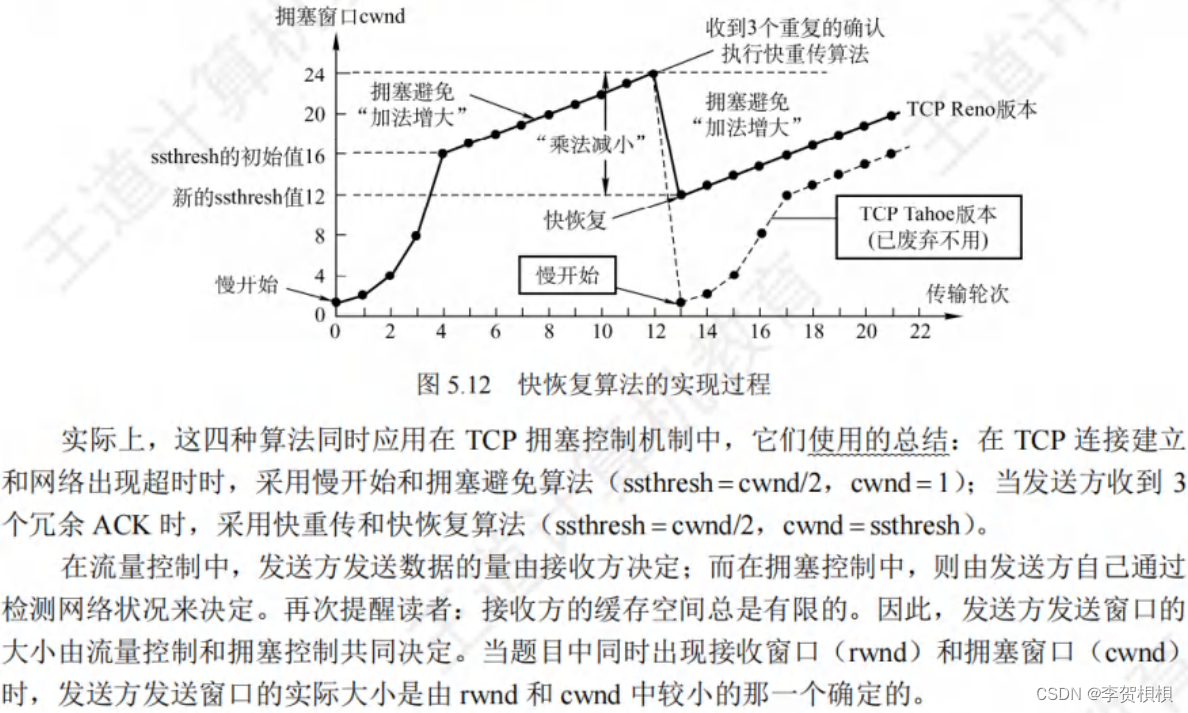
使用 pycharm 进行 python 爬虫的步骤:下载并安装 pycharm。创建一个新项目。安装 requests 和 beautifulsoup 库。编写爬虫脚本,包括获取页面内容、解析 html 和提取数据的代码。运行爬虫脚本。保存和处理提取到的数据。

用 PyCharm 进行 Python 爬虫的步骤
步骤 1:获取和安装 PyCharm
- 从官方网站下载并安装 PyCharm 社区版。
步骤 2:创建一个新项目
- 打开 PyCharm,单击“File”>“New Project”。
- 选择一个项目位置并指定一个项目名称。
步骤 3:安装必要的库
- 在项目解释器中安装 requests 和 BeautifulSoup 库。在终端窗口中运行以下命令:
| 1 |
|
步骤 4:编写爬虫脚本
- 在项目中创建一个新的 Python 文件,例如“web_crawler.py”。
- 编写以下爬虫代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
步骤 5:运行爬虫脚本
- 在 PyCharm 中,单击“Run”>“Run 'web_crawler'”。
步骤 6:保存和处理数据
- 提取到的数据可以保存到文件中、数据库中或使用其他方法进一步处理。
注意:
- 确保爬虫脚本包含适当的异常处理机制。
- 尊重网站的机器人协议和使用条款。






![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 数字排列游戏(200分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/32042c370ca64534b8347252bf707ac2.png)