【小白学Python】自定义图片的生成(一)
【小白学Python】自定义图片的生成(二)
【小白学Python】爬取数据(三)
目录
- ai文生图接口的获取
- python中调用ai接口
- 图片拼接
- 先将图片缩放
- 拼接图片
- 文字背景图代码
- 效果图
- 总结
在之前python学习的过程中,暂时完成了以下几个步骤:
1.从某乎爬取问答,生成txt文件
2.筛选自己想要的txt数据,读取txt文件
3.根据txt文件的问答数据,生成简易的背景图片。
现在生成的背景图片都比较单一,如下:

正好这段时间在用一个免费的基于stabble diffusion 3模型的文生图网站,我计划对之前的图片生成的过程进行优化。
调用上述网站的ai接口,图片的上半部分基于图片中的文字生成。
ai文生图接口的获取
F12打开浏览器的开发者工具,之后在网站上写入prompt提示语,选好图片生成的配置之后,点击生成。
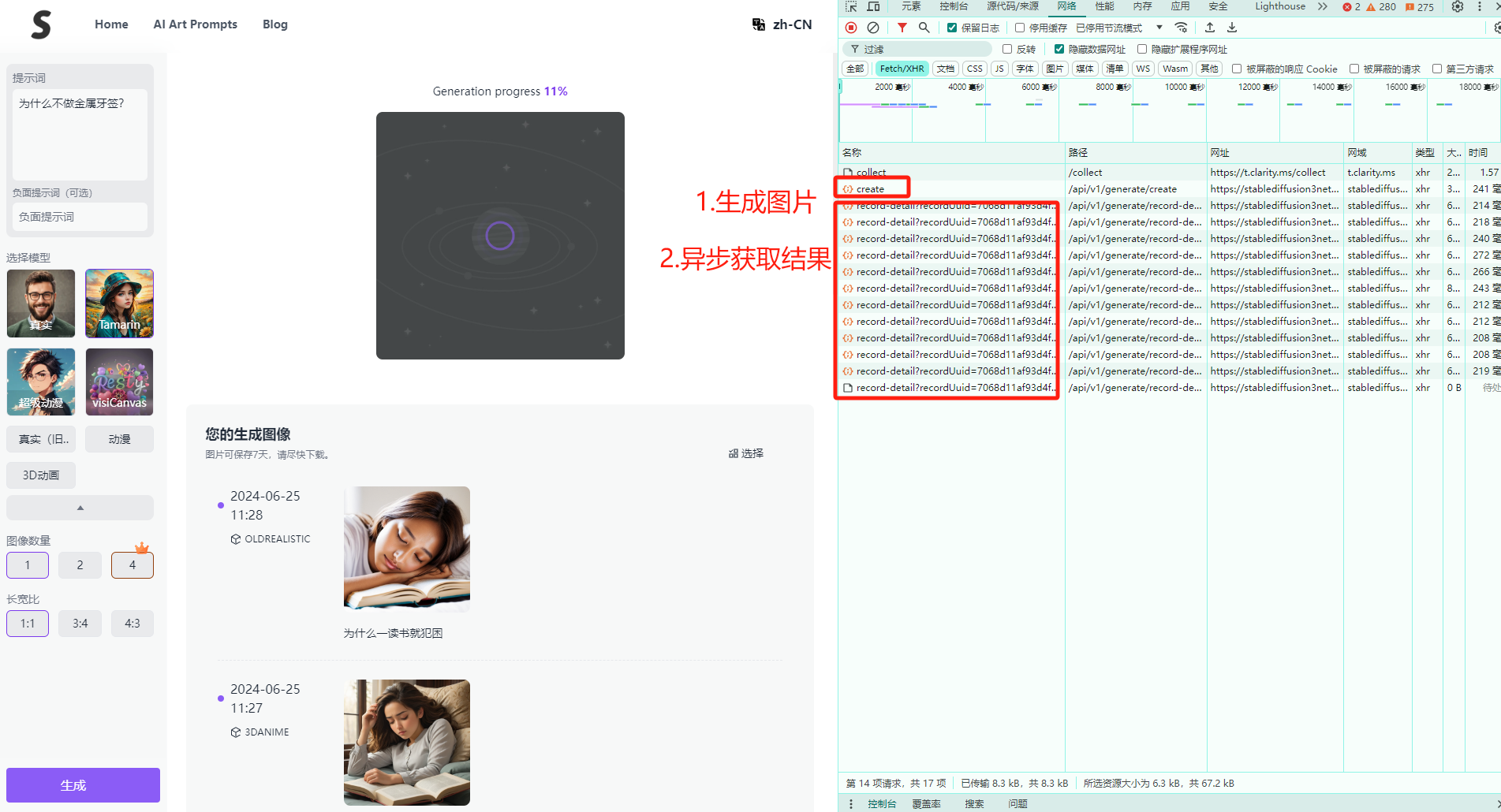
主要需要两个接口来生成图片
create图片生成record-detail异步获取图片生成
python中调用ai接口
将上述接口的调用参数、地址转换为python代码如下
def createPics(prompt):
url = ".../create"
requestsStr = {
"prompt": prompt,
"negativePrompt": "",
"model": "realistic",
# "model": "visiCanvas",
# "model": "oldRealistic",
# "model": "tamarin",
# "model": "superAnime",
"size": "1:1",
"batchSize": "1",
"imageUrl": ""
}
response = requests.post(url, json=requestsStr, headers=headers)
return response.json().get('data').get('recordUuid')
def getPicLinkUrl(prompt):
recordUuid = createPics(prompt)
picState = 'generating'
while picState != 'success':
url = "https://.../record-detail"
params = {
"recordUuid": recordUuid
}
response = requests.get(url, params=params)
response = response.json()
print(response)
sleep(5)
picState = response.get('data').get('picState')
return json.loads(response.get('data').get('picUrl'))[0]['picUrl']
输入prompt参数,调用上述方法,图片生成结果如下:

图片拼接
AI生成的图片风格各异,如果直接当做背景图会影响文字的展示,所以将AI生成的图片,拼在之前生成的文字背景图上面,并调整图片的大小。
先将图片缩放
def editPic(prompt):
picPath = "aipics/" + str(time.time()) + ".jpg"
download_image(getPicLinkUrl(prompt), picPath)
# 打开图片文件
image = Image.open(picPath)
# 定义缩放尺寸
new_width = 600
new_height = 600
# 使用Image对象的resize方法进行缩放
resized_image = image.resize((new_width, new_height))
# # 保存缩放后的图片
# resized_image.save(picPath)
# 关闭原始图片对象(可选步骤)
image.close()
return resized_image
拼接图片
def mergePics(image1, image2):
# 确保两张图片的尺寸相同(或者处理尺寸不同的情况)
if image1.size[0] != image2.size[0]: # 检查宽度是否相同
raise ValueError("Images must have the same width")
# 计算拼接后图片的尺寸
width = image1.size[0]
height = image1.size[1] + image2.size[1]
# 创建一张新图片,尺寸为拼接后的尺寸
merged_image = Image.new('RGB', (width, height))
# 将两张图片粘贴到新图片上
merged_image.paste(image1, (0, 0))
merged_image.paste(image2, (0, image1.size[1]))
# 保存拼接后的图片
merged_image.save('pics/'+ str(time.time()) + '.jpg')
# 显示拼接后的图片(可选)
merged_image.show()
文字背景图代码
def draw_text(text):
text = remove_between_chars(text, '@', ':')
# 设置图片大小
width, height = 600, 300
image = Image.new('RGB', (width, height), color='black')
# 加载字体文件,并设置字体大小
# 注意:确保arial.ttf字体文件路径是正确的
font = ImageFont.truetype('C:\\Windows\\Fonts\\simhei.ttf', 20)
# font.color = 'yellow'
# 创建画布
draw = ImageDraw.Draw(image)
# 使用draw的textsize方法获取文本大小
text_width, text_height = draw.textsize(text, font=font)
# 计算文字位置,使其居中
x = (width - text_width) / 2
y = (height - text_height) / 3.5
# 此处简单处理 如果将要到达边界,往字符串指定位置增加换行符
# 这里经过调试,我这里使用22比较合适,后续需要优化
if text_width > width - 10:
new_text = text[:25] + "\n\n " + text[25:]
# 绘制文字
x = (width - text_width // 2) / 2.5
draw.text((x, y), new_text, font=font, fill='white')
else:
# 绘制文字
draw.text((x, y), text, font=font, fill='white')
#ai生成的图片
prompt = str.replace(str.replace(text, '\n', ''), 'A: ', ' ')
image1 = editPic(prompt)
#合并图片背景图及ai生成的图片
mergePics(image1, image)
效果图



总结
由于我的原数据是爬取的QA形式,并没有经过优化,过于简洁,描述过少,其实并不适合AI文字生成图片的prompt,AI的理解大多数都出现了偏差,图片的生成比较随意,需要我的下一步优化。