1. Kafka概述
1. kafka是什么
kafka是分布式的、高并发的、基于发布/订阅模式的消息队列软件系统。
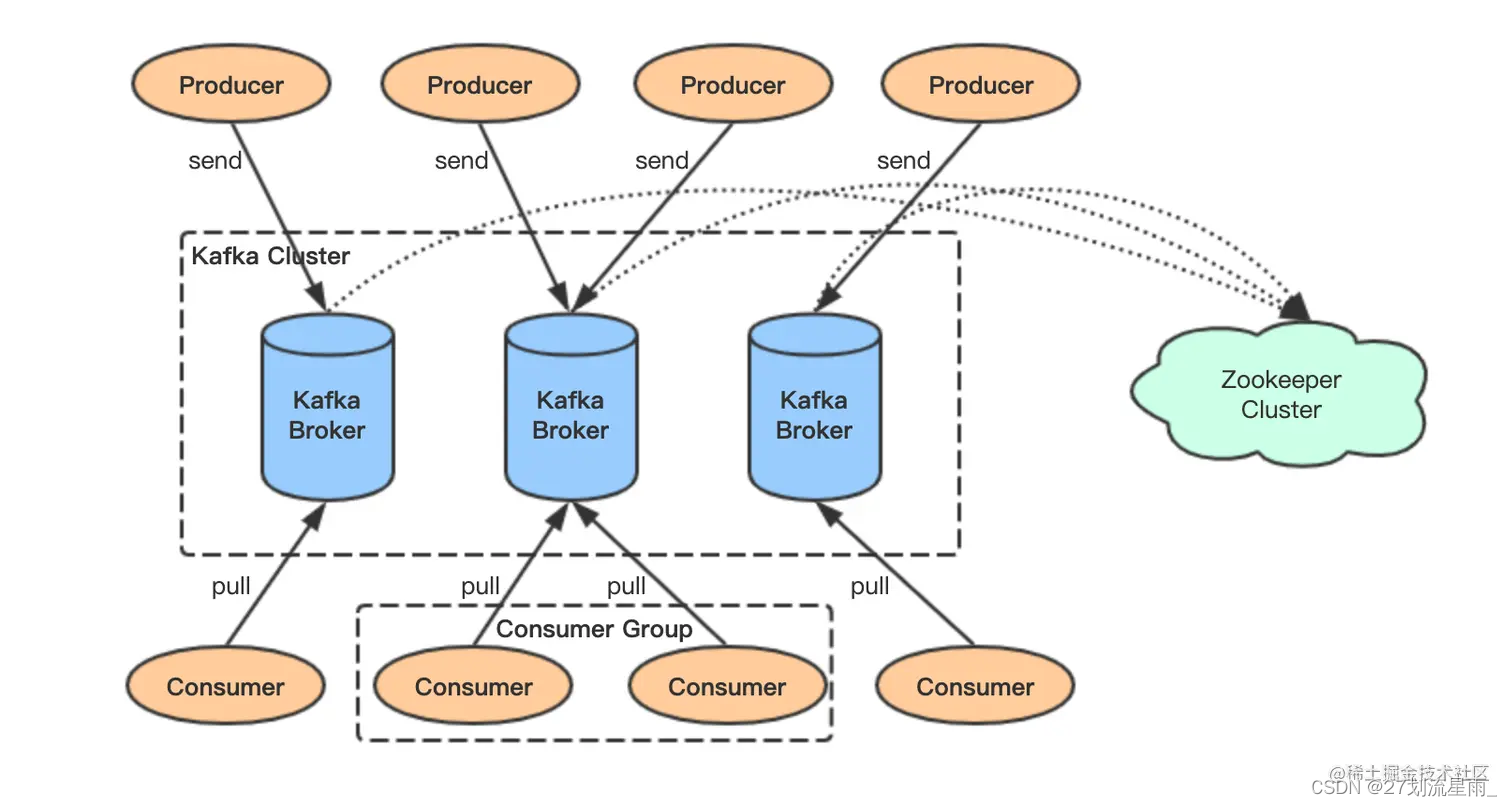
kafka中的重要组件
- Producer:消息生产者,发布消息到Kafka集群的终端或服务
- Consume:消费者,从Kafka集群中消费消息的终端或服务
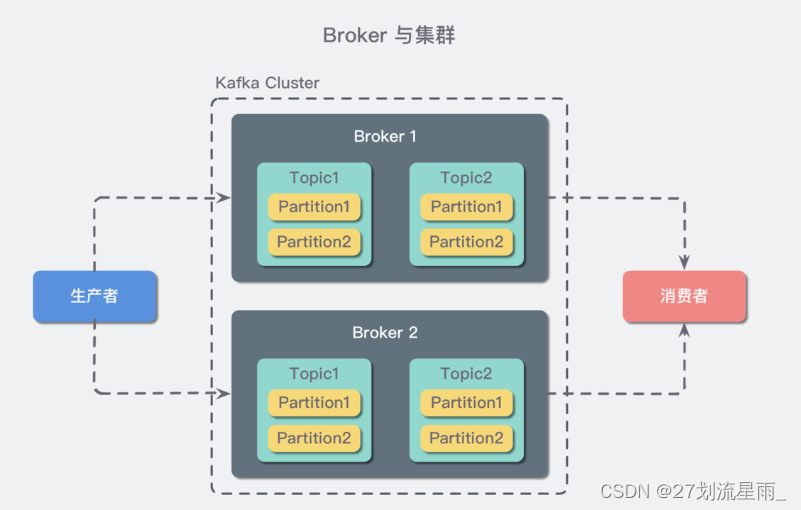
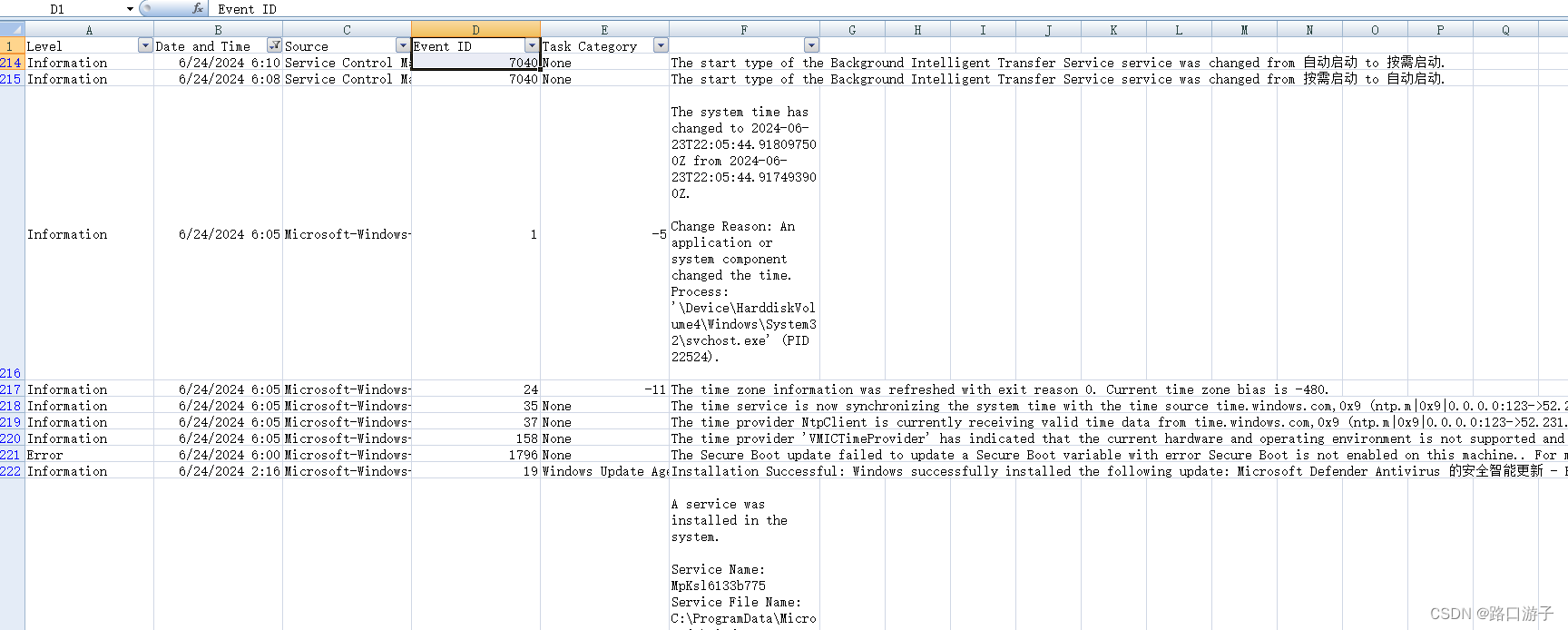
- Broker: 一个 Kafka 服务器也称为 Broker,它接受生产者发送的消息并
存入磁盘;Broker 同时服务消费者拉取分区消息的请求,返回目前已经提交的消息。 - 集群(cluster):若干个 Broker 组成一个 集群(Cluster),其中集群内某个 Broker 会成为集群控制器(Cluster Controller),它负责管理集群,包括分配分区到 Broker、监控 Broker 故障等。在集群内,一个分区由一个 Broker 负责,这个 Broker 也称为这个分区的 Leader;当然一个分区可以被复制到多个 Broker 上来实现冗余,这样当存在 Broker 故障时可以将其分区重新分配到其他 Broker 来负责。
-
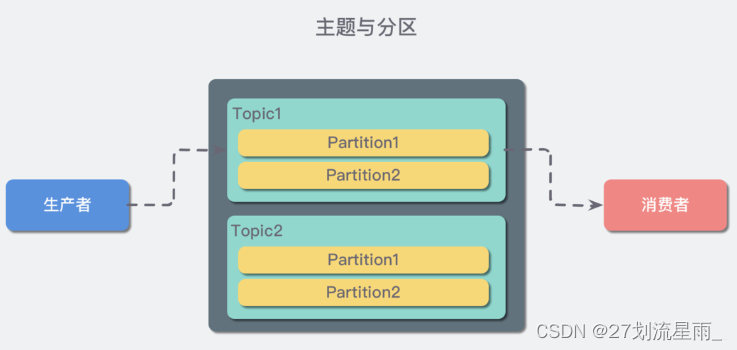
主题(Topic):主题(topic):一个 topic 里保存的是同一类消息,相当于对消息的分类,每个 producer 将消息发送到 kafka 中,都需要指明要存的 topic 是哪个,也就是指明这个消息属于哪一类。
-
Partition(分区):每个 topic 都可以分成多个 partition,每个 partition 在存储层面是 append log 文件。任何发布到此 partition 的消息都会被直接追加到 log 文件的尾部。为什么要进行分区呢?最根本的原因就是:kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,另外这样做也可以负载均衡,容纳更多的消费者。
-
Replica:即副本,为实现数据备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,为此 Kafka 提供了副本机制,一个 Topic 的每个 Partition 都有若干个副本,一个 Leader 副本和若干个 Follower 副本。
-
Leader:即每个
分区多个副本的主副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。 -
Follower:即每个分区多个副本的
从副本,会实时从 Leader 副本中同步数据,并保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会被选举并成为新的 Leader , 且不能跟 Leader 在同一个 Broker 上, 防止崩溃数据可恢复。 -
Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
-
ZooKeeper:ZooKeeper用于管理和协调Kafka代理。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后产品和消费者采取决定并开始与某些其他代理协调他们的任务。
kafka 特点
- kafka 是一个基于发布-订阅的分布式消息系统(消息队列)
- Kafka 面向大数据,消息保存在主题中,而每个 topic 有分为多个分区
- kafka 的消息数据保存在磁盘,每个 partition 对应磁盘上的一个文件,消息写入就是简单的文件追加,文件可以在集群内复制备份以防丢失
- 即使消息被消费,kafka 也不会立即删除该消息,可以通过配置使得过一段时间后自动删除以释放磁盘空间
- kafka依赖分布式协调服务Zookeeper,适合离线/在线信息的消费,与 storm 和 spark 等实时流式数据分析常常结合使用
Kafka 中 AR、ISR、OSR 三者的概念
- AR:分区中所有副本称为 AR
- ISR:所有与主副本保持一定程度同步的副本(包括主副本)称为 ISR
- OSR:与主副本滞后过多的副本组成 OSR
ZooKeeper的作用
2. Kafka工作流程
Kafka - 3.x 图解Broker总体工作流程
特点
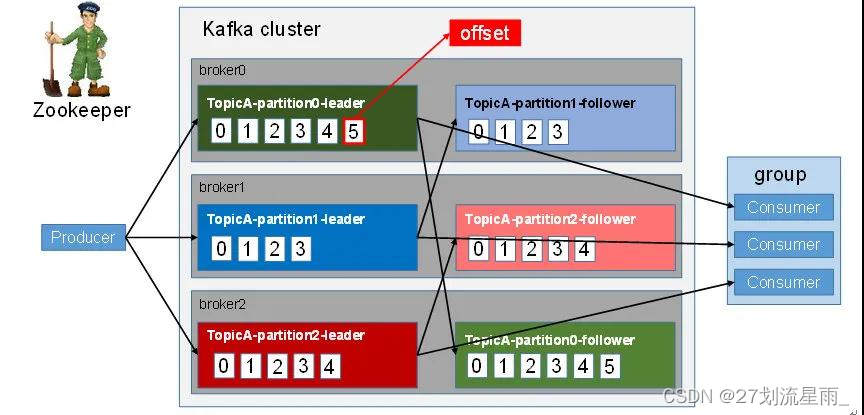
- 同一主题下的
不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序而不是主题有序。 - 一个主题可以横跨多个 broker,以此来提供比单个 broker 更强大的性能。
- Kafka 为分区引入了
多副本(Replica)机制,通过增加副本数量可以提升容灾能力。 - 同一分区的
不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader 副本负责处理读写请求,follower 副本只负责与 leader 副本的消息同步。副本处于不同的 broker 中,当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader 副本对外提供服务。Kafka 通过多副本机制实现了故障的自动转移,当 Kafka 集群中某个 broker 失效时仍然能保证服务可用。
topic组成
Kafka 工作流程和存储机制
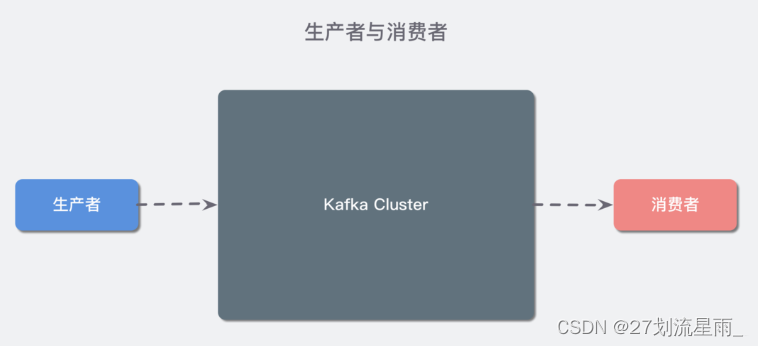
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的。
在 Kafka 中,一个 topic 可以分为多个 partition,一个 partition 分为多个 segment,每个 segment 对应两个文件:.index 和 .log 文件
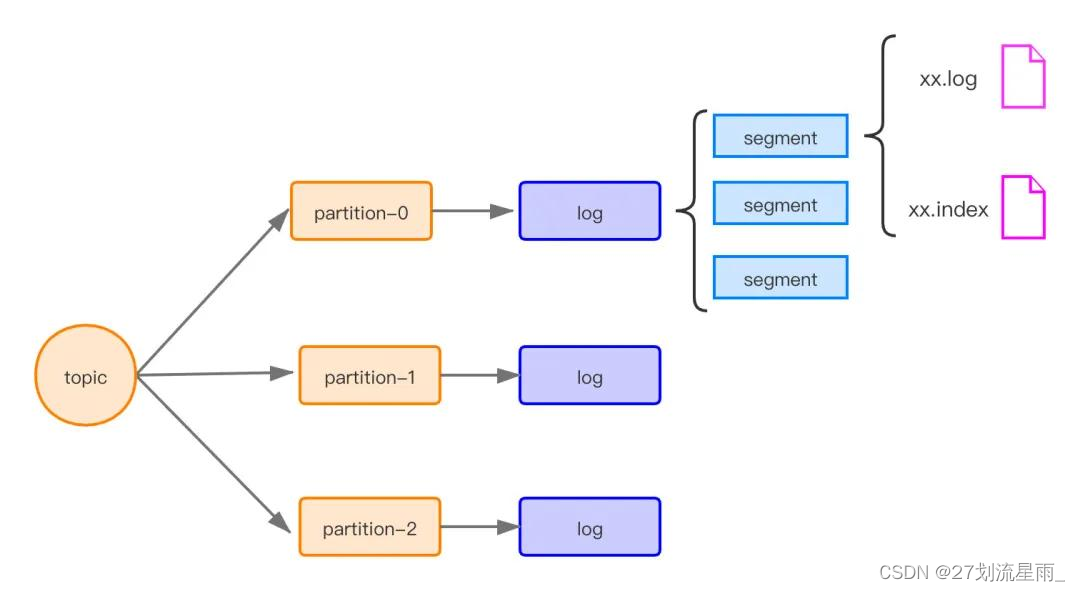
topic 是逻辑上的概念,而 patition 是物理上的概念,每个 patition 对应一个 log 文件,而 log 文件中存储的就是 producer 生产的数据,patition 生产的数据会被不断的添加到 log 文件的末端,且每条数据都有自己的 offset。
消费组中的每个消费者,都是实时记录自己消费到哪个 offset,以便出错恢复,从上次的位置继续消费。
写入流程

1)producer 先从 zookeeper 的 "/brokers/…/state"节点找到该 partition 的 leader
2)producer 将消息发送给该 leader
3)leader 将消息写入本地 log
4)followers 从 leader pull 消息,写入本地 log 后向 leader 发送 ACK
5)leader 收到所有 ISR 中的 replication 的 ACK 后,增加 HW(high watermark,最后 commit的 offset)并向 producer 发送 ACK
消费流程
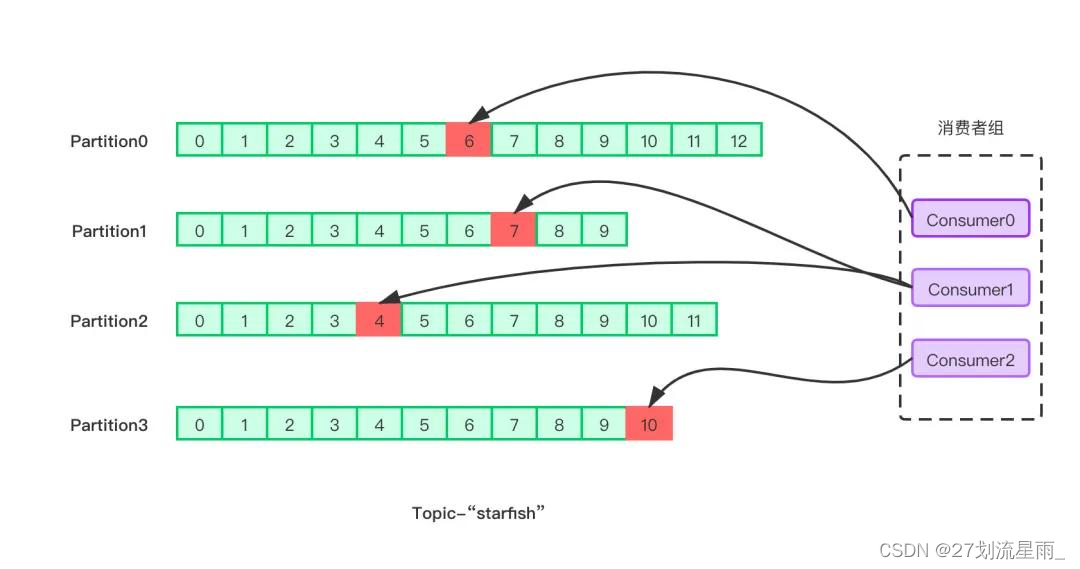
消费者是以 consumer group 消费者组的方式工作,由一个或者多个消费者组成一个组, 共同消费一个 topic。每个分区在同一时间只能由 group 中的一个消费者读取,但是多个 group 可以同时消费这个 partition。在图中,有一个由三个消费者组成的 group,有一个消费者读取主题中的两个分区,另外两个分别读取一个分区。某个消费者读取某个分区,也可以叫做某个消费者是某个分区的拥有者。
在这种情况下,消费者可以通过水平扩展的方式同时读取大量的消息。另外,如果一个消费者失败了,那么其他的 group 成员会自动负载均衡读取之前失败的消费者读取的分区。
消费者组最为重要的一个功能是实现广播与单播的功能。一个消费者组可以确保其所订阅的 Topic 的每个分区只能被从属于该消费者组中的唯一一个消费者所消费;如果不同的消费者组订阅了同一个 Topic,那么这些消费者组之间是彼此独立的,不会受到相互的干扰。
如果我们希望一条消息可以被多个消费者所消费,那么可以将这些消费者放到不同的消费者组中,这实际上就是广播的效果;如果希望一条消息只能被一个消费者所消费,那么可以将这些消费者放到同一个消费者组中,这实际上就是单播的效果。
分区的原因
-
方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个topic 又可以有多个 Partition 组成,因此整个集群就可以适应任意大小的数据了;消息日志文件会受到所在机器的文件系统大小的限制,分区之后,理论上一个topic可以处理任意数量的消息数据。 -
可以
提高并发,因为可以以 Partition 为单位读写了。
分区的原则
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key,通过对 key 进行 hash 出一个 patition
- patition 和 key 都未指定,使用轮询选出一个 patition。
3. kafka 中zookeeper的作用
深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列



![[MYSQL] MYSQL库的操作](https://img-blog.csdnimg.cn/direct/6abcbe72570746de8e5e908ef8beeb8d.png)