Map-增强的Map集合
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false。
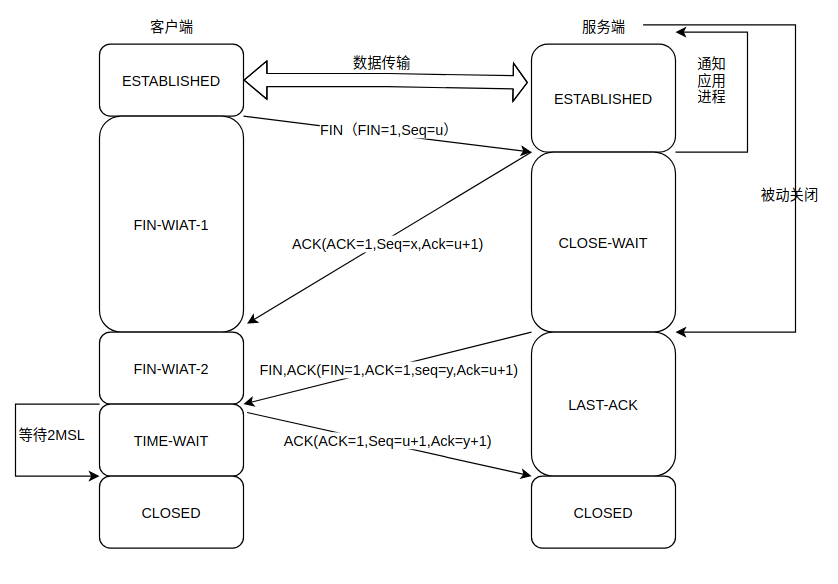
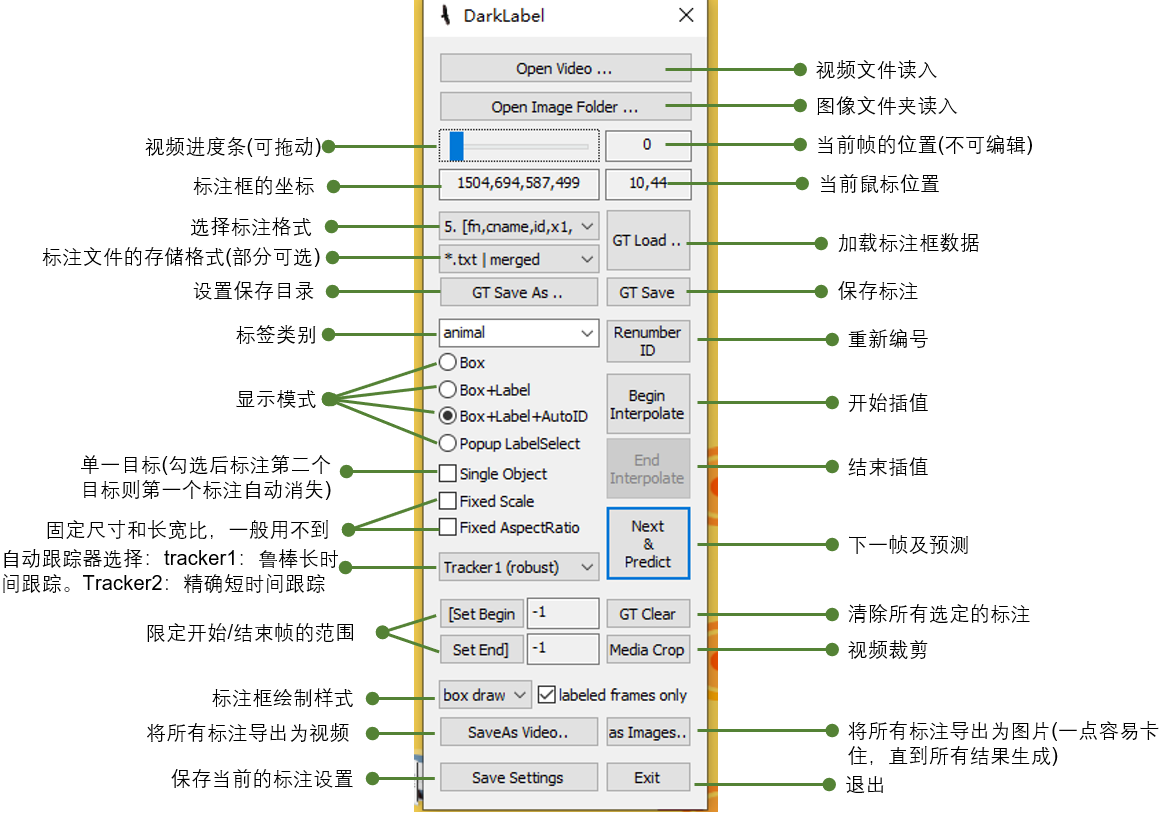
key和value之间存在单向一对一关系,即通过指定的key,总能找到唯一的、确定的value。从Map中取出数据时,只要给出指定的key,就可以取出对应的value。如果把Map的两组值拆开来看,Map里的数据有如图所示的结构。
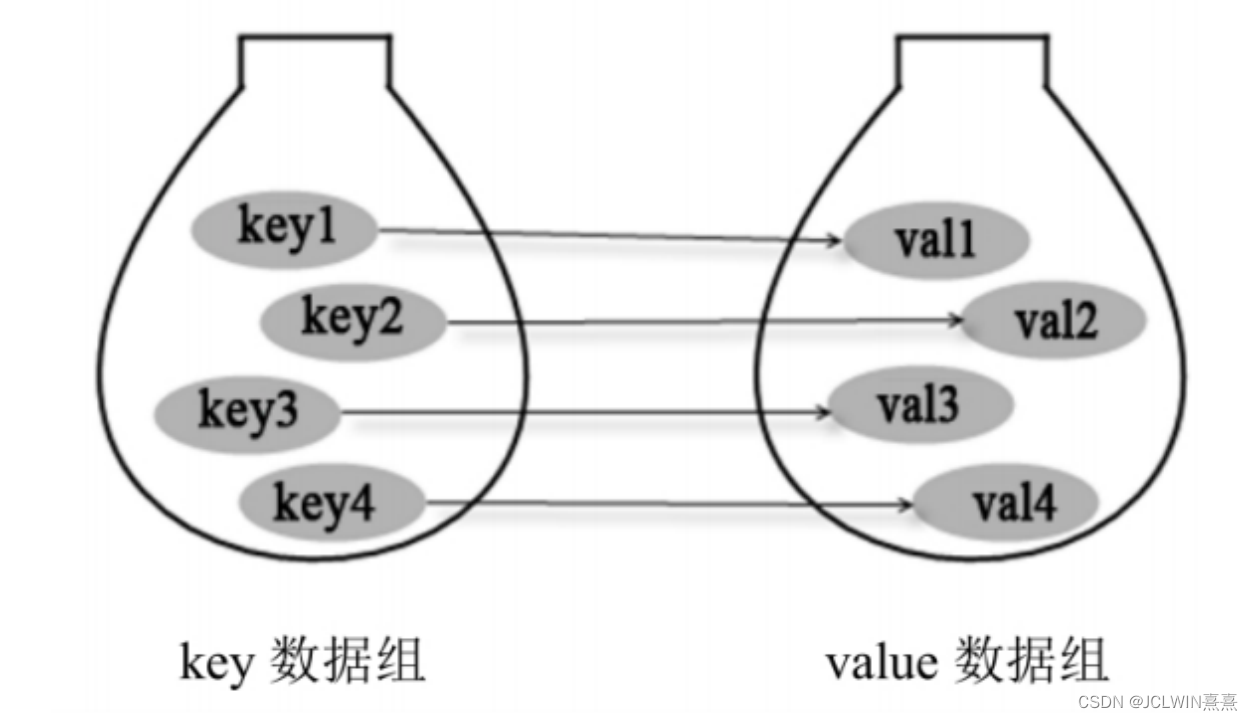
从图中可以看出,如果把Map里的所有key放在一起来看,它们就组成了一个Set集合(所有的key没有顺序,key与key之间不能重复),实际上Map确实包含了一个keySet()方法,用于返回Map里所有key组成的Set集合。
不仅如此,Map里key集和Set集合里元素的存储形式也很像,Map子类和Set子类在名字上也惊人地相似,比如Set接口下有HashSet、LinkedHashSet、SortedSet(接口)、TreeSet、EnumSet等子接口和实现类,而Map接口下则有HashMap、LinkedHashMap、SortedMap(接口)、TreeMap、EnumMap等子接口和实现类。正如它们的名字所暗示的,Map的这些实现类和子接口中key集的存储形式和对应Set集合中元素的存储形式完全相同。
Map和Set基本是一脉相传,如果把key-value对中的value当成key的附庸:key在哪里,value就跟在哪里。这样就可以像对待Set一样来对待Map了。事实上,Map提供了一个Entry内部类来封装key-value对,而计算Entry存储时则只考虑Entry封装的key。从Java源码来看,Java是先实现了Map,然后通过包装一个所有value都为空对象的Map就实现了Set集合。
Map与List又有类似之处,如果把Map里的所有value放在一起来看,它们又非常类似于一个List:元素与元素之间可以重复,每个元素可以根据索引来查找,只是Map中的索引不再使用整数值,而是以另一个对象作为索引。如果需要从List集合中取出元素,则需要提供该元素的数字索引;如果需要从Map中取出元素,则需要提供该元素的key索引。因此,Map有时也被称为字典,或关联数组。Map接口中定义了如下常用的方法。
1.void clear():删除该Map对象中的所有key-value对。
2.boolean containsKey(Object key):查询Map中是否包含指定的key,如果包含则返回true。
3.boolean containsValue(Object value):查询Map中是否包含一个或多个value,如果包含则返回true。
4.Set entrySet():返回Map中包含的key-value对所组成的Set集合,每个集合元素都是Map.Entry(Entry是Map的内部类)对象。
5.Object get(Object key):返回指定key所对应的value;如果此Map中不包含该key,则返回null。
6.boolean isEmpty():查询该Map是否为空(即不包含任何key-value对),如果为空则返回true。
7.Set keySet():返回该Map中所有key组成的Set集合。
8.Object put(Object key, Object value) : 添 加 一 个 keyvalue对,如果当前Map中已有一个与该key相等的key-value对,则新的key-value对会覆盖原来的key-value对。
8.void putAll(Map m):将指定Map中的key-value对复制到本Map中。
9.Object remove(Object key) : 删除指定key所对应的keyvalue对,返回被删除key所关联的value,如果该key不存在,则返回null。
10.boolean remove(Object key, Object value):这是Java 8新 增的方法,删除指定key、value所对应的key-value对。如果从 该Map中成功地删除该key-value对,该方法返回true,否则返回false。
11.int size():返回该Map里的key-value对的个数。
12.Collection values() :返回该Map里所有的value组成的Collection。
Map接口提供了大量的实现类,典型实现如HashMap和Hashtable等、HashMap的子类LinkedHashMap,还有SortedMap子接口及该接口的实现类TreeMap,以及WeakHashMap、IdentityHashMap等。下面将详细介绍Map接口实现类。
Map中包括一个内部类Entry,该类封装了一个key-value对。Entry包含如下三个方法。
1.Object getKey():返回该Entry里包含的key值。
2.Object getValue():返回该Entry里包含的value值。
3.Object setValue(V value):设置该Entry里包含的value值并返回新设置的value值。
Map集合最典型的用法就是成对地添加、删除key-value对,接下来即可判断该Map中是否包含指定key,是否包含指定value,也可以通过Map提供的keySet()方法获取所有key组成的集合,进而遍历Map中所有的key-value对。
Java 8为Map增加了如下方法:
1.remove(Object key,Object value)默认方法。
2.Object compute(Object key,BiFunction remappingFunction):该方法使用
remappingFunction根据原key-value对计算一个新value。只要新value不为null,就使用 新value覆盖原value;如果原value不为null,但新value为null,则删除原key-value对;如果原value、新value同时为null,那么该方法不改变任何key-value对,直接返回null。
3.Object computeIfAbsent(Object key, Function mappingFunction):如果传给该方法的key参数在Map中对应的value为null,则使用mappingFunction根据key计算一个新的结 果,如果计算结果不为null,则用计算结果覆盖原有的value。 如果原Map原来不包括该key,那么该方法可能会添加一组keyvalue对。
4.Object computeIfPresent(Object key, BiFunction remappingFunction):如果传给该方法的key参数在Map中对应 的value不为null,该方法将使用remappingFunction根据原
key、value计算一个新的结果,如果计算结果不为null,则使 用该结果覆盖原来的value;如果计算结果为null,则删除原key-value对。
5.void forEach(BiConsumer action):该方法是Java 8为Map新 增的一个遍历key-value对的方法,通过该方法可以更简洁地遍历Map的key-value对。
6.Object getOrDefault(Object key, V defaultValue):获取 指 定 key 对 应 的 value 。 如 果该key不存在,则返回defaultValue。
7.Object merge(Object key, Object value, BiFunction remappingFunction):该方法会先根据key参数获取该Map中对 应的value。如果获取的value为null,则直接用传入的value覆 盖原有的value(在这种情况下,可能要添加一组key-value对);如果获取的value不为null,则使用remappingFunction函数根据原value、新value计算一个新的结果,并用得到的结果去覆盖原有的value。
8.Object putIfAbsent(Object key, Object value):该方法会 自动检测指定key对应的value是否为null,如果该key对应的value为null,该方法将会用新value代替原来的null值。
9.Object replace(Object key, Object value):将Map中指定key对应的value替换成新value。与传统put()方法不同的是, 该方法不可能添加新的key-value对。如果尝试替换的key在原Map中不存在,该方法不会添加key-value对,而是返回null。
10.boolean replace(K key, V oldValue, V newValue):将Map中指定key-value对的原value替换成新value。如果在Map中找 到指定的key-value对,则执行替换并返回true,否则返回false。
11.replaceAll(BiFunction function):该方法使用BiFunction对原key-value对执行计算,并将计算结果作为该key-value对的value值。
改进的HashMap和Hashtable(废弃)实现类
HashMap和Hashtable都是Map接口的典型实现类,它们之间的关系完全类似于ArrayList和Vector的关系:Hashtable是一个古老的Map实现类,它从JDK 1.0起就已经出现了,当它出现时,Java还没有提供Map接口,所以它包含了两个烦琐的方法,即elements()(类似于Map接口定义的values()方法)和keys()(类似于Map接口定义的keySet()
方法),现在很少使用这两个方法。
目前都用HashMap,Java 8改进了HashMap的实现,使用HashMap存在key冲突时依然具有较好的性能。此外,Hashtable和HashMap存在两点典型区别。
➢ Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable的性能高一点;但如果有多个线程访问同一个Map对象时,使用Hashtable实现类会更好。
➢ Hashtable不允许使用null作为key和value,如果试图把null值放进Hashtable中,将会引发NullPointerException异常;但HashMap可以使用null作为key或value。
由于HashMap里的key不能重复,所以HashMap里最多只有一个keyvalue对的key为null,但可以有无数多个key-value对的value为null。与Vector类似的是,尽量少用Hashtable实现类,即使需要创建线程安全的Map实现类,也无须使 用Hashtable实现类,可以通过Collections工具类把HashMap变成线程安全的。
为了成功地在HashMap、Hashtable中存储、获取对象,用作key的对象必须实现hashCode()方法和equals()方法。与HashSet集合不能保证元素的顺序一样,HashMap、Hashtable也不能保障key-value对的顺序,Hashtable判断两个key相等的标准也是:两个key通过equals()方法比较返回true,两个key的hashCode值也相等。
除此之外,HashMap、Hashtable中还包含一个containsValue()方法,用于判断是否包含指定的value。那么HashMap、Hashtable如何判断两个value相等呢?HashMap、Hashtable判断两个value相等的标准更简单:只要两个对象通过equals()方法比较返回true即可。
当使用自定义类作为HashMap、Hashtable的key时,如果重写该类的equals(Object obj)和hashCode()方法,则应该保证两个方法的判断标准一致—当两个key通过equals()方法比较返回true时,两个key的hashCode()返回值也应该相同。
LinkedHashMap实现类
HashSet有一个LinkedHashSet子类,HashMap也有一个LinkedHashMap子类;LinkedHashMap也使用双向链表来维护key-value对的顺序(其实只需要考虑key的顺序),该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可),同时又可避免使用TreeMap所增加的成本。
LinkedHashMap需要维护元素插入的顺序,因此性能略低于HashMap;但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。
Java 8也为Map新增forEach()方法来遍历Map集合。
Map的典型应用-------配置文件,使用Properties类读写属性文件
Properties类是Hashtable类的子类,该对象在处理属性文件时特别方便(Windows操作平台上的ini文件就是一种属性文件)。Properties类可以把Map对象和属性文件关联起来,也就是可以把Map对象中的key-value对写入属性文件中,也可以把属性文件中的“属性名=属性值”加载到Map对象中。由于属性文件里的属性名、属性值只能是字符串类型,所以Properties类里的key、value都是字符串类型。该类提供了如下三个方法来修改Properties里的key、value值。Properties相当于一个key、value都是String类型的Map。提供了如下方法:
➢ String getProperty(String key):获取Properties中指定属性名对应的属性值,类似于Map的get(Object key)方法。
➢ String getProperty(String key, String defaultValue): 该方法与前一个方法基本相似。该方法多一个功能,如果Properties中不存在指定的key时,则该方法指定默认值。
➢ Object setProperty(String key, String value):设置属性值,类似于Hashtable的put()方法。
除此之外,它还提供了两个读写属性文件的方法,就是将Properties对象写入文件中。
➢ void load(InputStream inStream):从属性文件(以输入流表示)中加载key-value对,把加载到的key-value对追加到Properties里(Properties是Hashtable的子类,它不保证keyvalue对之间的次序)。
➢ void store(OutputStream out, String comments) :将Properties中的key-value对输出到指定的属性文件(以输出流表示)中。
SortedMap接口和TreeMap实现类
Set接口----SortedSet子接口----TreeSet实现类;
Map接口----SortedMap子接口----TreeMap实现类;
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。
TreeMap也有两种排序方式。
1.自然排序:TreeMap的所有key必须实现Comparable接口,而且所有的key应该都是同一个类的对象,否则将抛出ClassCastException异常。
2.定制排序:创建TreeMap时,传入一个Comparator对象,该对象负责对TreeMap中的所有key进行排序。采用定制排序时不要求Map的key实现Comparable接口。
类似于TreeSet中判断两个元素相等的标准,TreeMap中判断两个key相等的标准是:两个key通过compareTo()方法返回0,TreeMap即认为这两个key是相等的。
如果使用自定义类作为TreeMap的key,且想让TreeMap良好地工作,则重写该类的equals()方法和compareTo()方法时应保持一致的返回结果:两个key通过equals()方法比较返回true时,它们通过compareTo()方法比较应该返回0。如果equals()方法与compareTo()方法的返回结果不一致,TreeMap与Map接口的规则就会冲突。
再次强调:
Set和Map的关系十分密切,Java源码就是先实现了HashMap、TreeMap等集合,然后通过包装一个所有的value都为空对象的Map集合实现了Set集合类。
与TreeSet类似的是,TreeMap中也提供了一系列根据key顺序访问key-value对的方法。
➢ Map.Entry firstEntry():返回该Map中最小key所对应的key-value对,如果该Map为空,则返回null。
➢ Object firstKey():返回该Map中的最小key值,如果该Map为空,则返回null。
➢ Map.Entry lastEntry():返回该Map中最大key所对应的keyvalue对,如果该Map为空或不存在这样的key-value对,则都返回null。
➢ Object lastKey():返回该Map中的最大key值,如果该Map为空或不存在这样的key,则都返回null。
➢ Map.Entry higherEntry(Object key):返回该Map中位于key后一位的key-value对(即大于指定key的最小key所对应的keyvalue对)。如果该Map为空,则返回null。
➢ Object higherKey(Object key):返回该Map中位于key后一位 的key值(即大于指定key的最小key值)。如果该Map为空或不存在这样的key-value对,则都返回null。
➢ Map.Entry lowerEntry(Object key):返回该Map中位于key前 一位的key-value对(即小于指定key的最大key所对应的keyvalue对)。如果该Map为空或不存在这样的key-value对,则都返回null。
➢ Object lowerKey(Object key):返回该Map中位于key前一位 的key值(即小于指定key的最大key值)。如果该Map为空或不存在这样的key,则都返回null。
➢ NavigableMap subMap(Object fromKey, boolean fromInclusive, Object toKey, boolean toInclusive):返回 该Map的子Map,其key的范围是从fromKey(是否包括取决于第二个参数)到toKey(是否包括取决于第四个参数)。
➢ SortedMap subMap(Object fromKey, Object toKey):返回该Map的子Map,其key的范围是从fromKey(包括)到toKey(不包括)。
➢ SortedMap tailMap(Object fromKey):返回该Map的子Map,其key的范围是大于fromKey(包括)的所有key。
➢ NavigableMap tailMap(Object fromKey, boolean inclusive) :返回该Map的子 Map , 其key的范围是大于fromKey(是否包括取决于第二个参数)的所有key。
➢ SortedMap headMap(Object toKey):返回该Map的子Map,其key的范围是小于toKey(不包括)的所有key。
➢ NavigableMap headMap(Object toKey, boolean inclusive) :返回该Map的子 Map , 其key的范围是小于toKey(是否包括取决于第二个参数)的所有key。
提示:
表面上看起来这些方法很复杂,其实它们很简单。因为TreeMap中的key-value对是有序的,所以增加了访问第一个、前一个、后一 个、最后一个key-value对的方法,并提供了几个从TreeMap中截取子TreeMap的方法。
WeakHashMap实现类(没大用)
WeakHashMap与HashMap的用法基本相似。与HashMap的区别在于,HashMap的key保留了对实际对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap的所有key所引用的对象就不会被垃圾回收,HashMap也不会自动删除这些key 所对应的 key-value对;但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,WeakHashMap也可能自动删除这些key所对应的key-value对。
WeakHashMap中的每个key对象只持有对实际对象的弱引用,因此,当垃圾回收了该key所对应的实际对象之后,WeakHashMap会自动删除该key对应的key-value对。
IdentityHashMap实现类(啥用?)
这个Map实现类的实现机制与HashMap基本相似,但它在处理两个key相等时比较独特:在IdentityHashMap中,当且仅当两个key严格相等(key1==key2)时,IdentityHashMap才认为两个key相等;对于普通的HashMap而言,只要key1和key2通过equals()方法比较返回true,且它们的hashCode值相等即可。
注意:
IdentityHashMap是一个特殊的Map实现!此类实现Map接口时, 它有意违反Map的通常规范:IdentityHashMap要求两个key严格相等时才认为两个key相等,IdentityHashMap提供了与HashMap基本相似的方法,也允许使用null作为key和value。与HashMap相似:IdentityHashMap也不保证key-value对之间的顺序,更不能保证它们的顺序随时间的推移保持不变。
EnumMap实现类
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap具有如下特征。
➢ EnumMap在内部以数组形式保存,所以这种实现形式非常紧凑、高效。
➢ EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺 序 )来维护key-value对的顺序,当程序通过keySet() 、entrySet()、values()等方法遍历EnumMap时可以看到这种顺序。
➢ EnumMap不允许使用null作为key,但是null可以作为value,如果试图使用null作为key时将抛出NullPointerException异常。如果只是查询是否包含值为null的key,或只是删除值为null的key,都不会抛出异常。与创建普通的Map有所区别的是,创建EnumMap时必须指定一个枚举类,从而将该EnumMap和指定枚举类关联起来。
再次进度map内部性能大比拼!!!各Map实现类的性能分析
对于Map的常用实现类而言,虽然HashMap和Hashtable的实现机制几乎一样,但由于Hashtable是一个古老的、线程安全的集合,因此HashMap通常比Hashtable要快。
TreeMap通常比HashMap、Hashtable要慢(尤其在插入、删除key-value对时更慢),因为TreeMap底层采用红黑树来管理key-value对(红黑树的每个节点就是一个key-value对)。使用TreeMap有一个好处:TreeMap中的key-value对总是处于有序状态,无须专门进行排序操作。当TreeMap被填充之后,就可以调用keySet(),取得由key组成的Set,然后使用toArray()方法生成key的 数组,接下来使用Arrays的binarySearch()方法在已排序的数组中快速地查询对象。
对于一般的应用场景,程序应该多考虑使用HashMap,因为HashMap正是为快速查询设计的(HashMap底层其实也是采用数组来存储key-value对)。但如果程序需要一个总是排好序的Map时,则可以考虑使用TreeMap。
LinkedHashMap比HashMap慢一点,因为它需要维护链表来保持Map中key-value时的添加顺序。IdentityHashMap性能没有特别出色之处,因为它采用与HashMap基本相似的实现,只是它使用==而不是equals()方法来判断元素相等。EnumMap的性能最好,但它只能使用同一个枚举类的枚举值作为key。
HashSet和HashMap的性能选项
对于HashSet及其子类而言,它们采用hash算法来决定集合中元素的存储位置,并通过hash算法来控制集合的大小;
对于HashMap、Hashtable及其子类而言,它们采用hash算法来决定Map中key的存储,并通过hash算法来增加key集合的大小。
hash表里可以存储元素的位置被称为“桶(bucket)”,在通常情况下,单个“桶”里存储一个元素,此时有最好的性能:hash算法可以根据hashCode值计算出“桶”的存储位置,接着从“桶”中取出元素。但hash表的状态是open的:在发生“hash冲突”的情况下,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。因为HashSet和HashMap、Hashtable都使用hash算法来决定其元素 (HashMap则只考虑key)的存储,因此HashSet、HashMap的hash表包含如下属性。
1.容量(capacity):hash表中桶的数量。
2.初始化容量(initial capacity):创建hash表时桶的数量。HashMap和HashSet都允许在构造器中指定初始化容量。
3.尺寸(size):当前hash表中记录的数量。
4.负 载 因 子 ( load factor ):负载因子==“size/capacity”计算而得。负载因子为0,表示空的hash表,0.5表示半满的hash表,依此类推。轻负载的hash表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)。除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增 加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashSet和HashMap、Hashtable的构造器允许指定一个负载极限,HashSet和HashMap、Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折 中:较高的“负载极限”可以降低hash表所占用的内存空间,但会增 加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询);较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销。程序员可以根据实际情况来调整HashSet和HashMap的“负载极限”值。
如果开始就知道HashSet和HashMap、Hashtable会保存很多记录,则可以在创建时就使用较大的初始化容量,如果初始化容量始终大于HashSet和HashMap、Hashtable所包含的最大记录数除以“负载极限”,就不会发生rehashing。使用足够大的初始化容量创建HashSet和HashMap、Hashtable时,可以更高效地增加记录,但将初始化容量设置太高可能会浪费空间,因此通常不要将初始化容量设置得过高。