1. 需求与设计
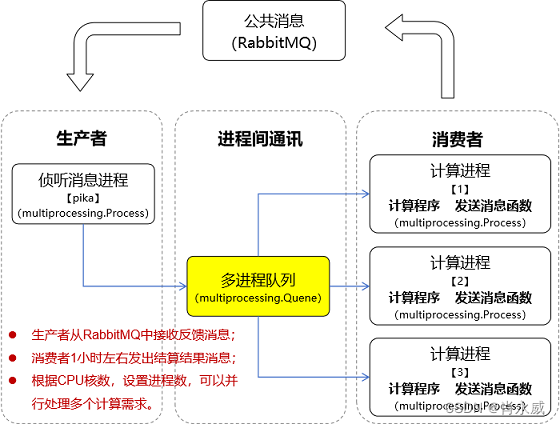
我所设计的计算服务旨在满足多个客户对复杂计算任务的需求。由于这些计算任务通常耗时较长且资源消耗较大,为了优化客户体验并减少等待时间,我采取了并行计算的策略来显著提升计算效率。
为实现这一目标,我计划利用Python的multiprocessing库来构建一个高效的多进程计算服务。同时,为了与外部的RabbitMQ消息队列系统无缝集成,我选择了pika库作为与RabbitMQ通信的桥梁。
在计算服务的架构中,我设计了生产者和消费者两个核心角色。生产者负责监听RabbitMQ队列中的消息,每当接收到新的消息时,它将从消息中提取出待处理的数据,并将其放入multiprocessing.Queue中等待处理。这个过程充分利用了multiprocessing.Queue提供的进程间通信机制,确保数据的可靠传递和同步。
与此同时,消费者进程则负责从multiprocessing.Queue中取出待处理的数据,进行实际的计算工作。这些计算任务可能需要大约一个小时的时间来完成,取决于数据的复杂性和计算资源的分配情况。一旦计算完成,消费者进程将把结果重新封装成消息,并通过pika库发送回RabbitMQ的指定队列中,以便客户或其他系统能够获取到这些结果。
通过这种设计,我的计算服务能够同时处理多个客户的计算请求,并通过并行计算的方式提高整体的处理效率。同时,RabbitMQ的引入使得服务的可扩展性和可靠性得到了极大的提升,即使在面对高并发或系统故障的情况下,也能保证数据的完整性和服务的稳定性。
2. multiprocessing多进行模块
multiprocessing模块是Python标准库的一部分,提供了一种基于多进程的并行计算方法。通过使用multiprocessing模块,可以利用多个CPU核心来并行处理任务,从而提高程序的执行效率。与多线程相比,多进程避免了全局解释器锁(GIL)的限制,因此在CPU密集型任务中表现更优。
2.1. multiprocessing模块的核心概念和功能
-
进程(Process):通过
multiprocessing.Process类可以创建和管理独立的进程。每个进程都有自己的内存空间,互不干扰。 -
进程间通信(IPC):
multiprocessing提供了多种进程间通信的机制,如Queue、Pipe、Value和Array。在代码中,我们使用multiprocessing.Queue来在主进程和工作进程之间传递数据。 -
同步(Synchronization):
multiprocessing模块还提供了同步原语,如Lock、Semaphore、Event、Condition和Barrier,用于协调进程之间的操作。
2.2. 代码中的multiprocessing使用说明
以下是代码中使用multiprocessing的主要部分的解释:
创建和管理进程
# 创建工作进程
processes = []
for _ in range(3):
p = multiprocessing.Process(target=worker, args=(data_queue, rabbitmq_params, target_queue))
p.start()
processes.append(p)
logger.info(f'Process started with PID: {p.pid}')
multiprocessing.Process类用于创建一个新的进程。target参数指定了该进程将运行的目标函数,这里是worker函数。args参数提供了传递给目标函数的参数。p.start()方法启动了进程。
进程间通信
# 创建一个multiprocessing.Queue用于进程间通信
data_queue = multiprocessing.Queue()
multiprocessing.Queue用于在主进程和工作进程之间传递数据。它是线程和进程安全的队列,提供了先进先出(FIFO)的数据传递方式。
工作进程函数
def worker(data_queue, rabbitmq_params, target_queue):
while True:
try:
data = data_queue.get()
if data is None:
break
result = compute_result(data)
try:
logger.info('Worker started')
connection = pika.BlockingConnection(rabbitmq_params)
channel = connection.channel()
except pika.exceptions.AMQPError as e:
logger.error(f"Error connecting to RabbitMQ in worker: {e}")
return
send_result_to_rabbitmq(channel, target_queue, result)
except Exception as e:
logger.error(f"An error occurred in worker: {e}")
try:
channel.close()
connection.close()
except pika.exceptions.AMQPError as e:
logger.error(f"Error closing RabbitMQ connection in worker: {e}")
logger.info('Worker finished')
worker函数从data_queue中获取数据进行处理。如果队列为空,data_queue.get()将阻塞直到有数据可用。- 处理完成后,结果通过
send_result_to_rabbitmq函数发送到RabbitMQ。
终止工作进程
# 等待所有工作进程结束
for p in processes:
data_queue.put(None) # 发送None信号以终止工作进程
for p in processes:
p.join()
- 向
data_queue发送None信号,通知工作进程终止。 - 使用
p.join()方法等待每个进程完成。这是一个阻塞调用,直到对应的进程终止。
2.3. 小结
multiprocessing模块通过创建独立的进程,利用多核CPU的能力并行处理任务。multiprocessing.Queue用于进程间通信,确保数据安全地在进程间传递。- 通过错误处理和日志记录,提高了程序的健壮性和可维护性。
这使得程序能够在多核环境中高效运行,并能够处理各种异常情况,确保程序的稳定性和可靠性。
3. 实践代码
import pika
import multiprocessing
import time
from loguru import logger
# 假设这是你的计算函数
def compute_result(data):
# 模拟计算过程
time.sleep(3 * 60) # 假设需要3分钟,换成随机
return f"Result for {data}"
# 发送结果到RabbitMQ的函数
def send_result_to_rabbitmq(channel, queue_name, result):
try:
channel.queue_declare(queue=queue_name, durable=True)
channel.basic_publish(
exchange='',
routing_key=queue_name,
body=result,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
logger.info(f"发送结果消息:{result} 到RabbitMQ")
except pika.exceptions.AMQPError as e:
logger.error(f"Error sending result to RabbitMQ: {e}")
raise
# 从RabbitMQ接收数据并放入队列的函数(生产者)
def consume_from_rabbitmq_and_enqueue(rabbitmq_connection, rabbitmq_queue, data_queue):
try:
channel = rabbitmq_connection.channel()
channel.queue_declare(queue=rabbitmq_queue, durable=True)
def callback(ch, method, properties, body):
try:
data_queue.put(body.decode('utf-8'))
logger.info(f"接收到消息:{body.decode('utf-8')}")
except Exception as e:
logger.error(f"Error putting message into data_queue: {e}")
channel.basic_consume(queue=rabbitmq_queue, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
except pika.exceptions.AMQPError as e:
logger.error(f"Error consuming from RabbitMQ: {e}")
raise
# 工作进程函数
def worker(data_queue,rabbitmq_params, target_queue):
# 由于计算时间长,连接很容易被断开
#try:
# logger.info('Worker started')
# workerconnection = pika.BlockingConnection(rabbitmq_params)
# channel = workerconnection.channel()
# channel.queue_declare(queue = target_queue, durable=True)
#except pika.exceptions.AMQPError as e:
# logger.error(f"Error connecting to RabbitMQ in worker: {e}")
# return
while True:
try:
# 从Queue中获取数据,如果队列为空,则阻塞等待
data = data_queue.get()
print(f'data_queue.get() is {data}')
if data is None:
# 收到None信号,表示应该退出
break
# 计算结果
result = compute_result(data)
try:
logger.info('Worker started')
workerconnection = pika.BlockingConnection(rabbitmq_params)
channel = workerconnection.channel()
channel.queue_declare(queue = target_queue, durable=True)
except pika.exceptions.AMQPError as e:
logger.error(f"Error connecting to RabbitMQ in worker: {e}")
return
# 发送结果到RabbitMQ
send_result_to_rabbitmq(channel, target_queue, result)
except Exception as e:
print(f"An error occurred: {e}")
try:
channel.close()
connection.close()
except pika.exceptions.AMQPError as e:
logger.error(f"Error closing RabbitMQ connection in worker: {e}")
logger.info('Worker finished')
# 主程序
if __name__ == "__main__":
rabbitmq_queue = 'hello_world'
target_queue = 'target_station_response_queue'
# 设置RabbitMQ连接和队列
credentials = pika.PlainCredentials('rabbit', '****') # mq用户名和密码
rabbitmq_params = pika.ConnectionParameters('192.168.*.*',port = 5671,virtual_host = '/dev',credentials = credentials)
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
try:
connection = pika.BlockingConnection(rabbitmq_params)
except pika.exceptions.AMQPError as e:
logger.error(f"Error connecting to RabbitMQ in main process: {e}")
exit(1)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 创建一个multiprocessing.Queue用于进程间通信
data_queue = multiprocessing.Queue()
# 创建工作进程
processes = []
for _ in range(3):
p = multiprocessing.Process(target=worker, args=(data_queue, rabbitmq_params, target_queue))
p.start()
processes.append(p)
print(f'process id = {p.pid}')
# 假设这里是生产数据到Queue的代码(这里用模拟数据代替)
channel = connection.channel()
for i in range(10): # 发送10个模拟数据
send_result_to_rabbitmq(channel, rabbitmq_queue, str(i))
time.sleep(2) # 模拟生产数据的间隔
'''
# 当所有数据都生产完毕后,发送None信号给所有工作进程以结束它们
for _ in range(3):
data_queue.put(None)
'''
try:
consume_from_rabbitmq_and_enqueue(connection, rabbitmq_queue, data_queue)
except Exception as e:
logger.error(f"Error in consuming from RabbitMQ and enqueuing: {e}")
# 等待所有工作进程结束
for p in processes:
data_queue.put(None) # 发送None信号以终止工作进程
for p in processes:
p.join()
try:
connection.close()
except pika.exceptions.AMQPError as e:
logger.error(f"Error closing RabbitMQ connection in main process: {e}")
logger.info("All processes have finished.")
4. 编者按
在当今日益复杂的数据处理场景中,高效、可靠的计算服务对于企业和个人用户而言都至关重要。特别是在需要处理大量计算任务,且这些任务耗时较长、资源消耗较大的情况下,如何优化计算流程、减少用户等待时间,成为了我们必须面对的挑战。
本博客详细探讨了如何利用Python的multiprocessing库和pika库构建一个高效、可扩展的多进程计算服务,并通过RabbitMQ实现与外部系统的消息通讯。这一实践不仅解决了计算资源瓶颈问题,还显著提升了服务的整体性能和可靠性。
在整个实践过程中,我们特别感谢“文言一心”提供的指导和帮助。文言一心能够根据我们的需求快速编写出程序框架,大大提高了我们的工作效率。同时,其丰富的实践经验和专业知识也为我们提供了宝贵的参考和借鉴。同时,也感谢ChatGPT验证上述方案和专业指导。
通过本博客的分享,我们希望能够为读者提供一种高效、可靠的多进程计算服务实现方案,并希望能够帮助读者更好地理解和应用Python的multiprocessing库和pika库。在未来的数据处理和计算服务中,我们相信这一实践将发挥越来越重要的作用。
欢迎反馈。
参考:
[1]. ithicker. 多进程(多核运算)Multiprocessing. CSDN博客. 2021.02
[2]. 擒贼先擒王. Python 多进程:multiprocessing、aiomultiprocess(异步多进程). CSDN博客. 2024.05