目录
前言
什么是分词器?
ik分词器简介
ik分词器和默认分词器的对比
ik分词器介绍
ik分词器的分词问题
自定义词库
主配置解说
通过配置文件自定义词库
Step1: 新建自定义分词库
Step2: 将我们的自定义词添加到ik的配置文件中
Step3: 重启es,查看分词
配置化方式自定义词库存在的问题
热更新词库方案
ik分词器热更新词库实践
IK分词器源码下载
导入maven工程
源码中词典加载大体流程
修改源码
修调整elasticsearch.version
在pom文件中添加mysql驱动器依赖
创建数据库配置文件jdbc-reload.properties,放在IK项目的config文件夹下
新增HotDictReloadThread类
修改org.wltea.analyzer.dic.Dictionary#loadMainDict方法
修改org.wltea.analyzer.dic.Dictionary#loadStopWordDict方法
org.wltea.analyzer.dic.Dictionary#initial调用HotDictReloadThread方法
修改插件的权限
建立数据库表
打包
加入依赖
package
安装
测试验证
关键词验证
1. “水平思维”关键词验证
2. 网络流行语“他是显眼包”验证
3. 网络流行语“香菇蓝瘦”验证
停用词验证
1. “我是熊二呢”短语验证
2. “一个老流氓”短语验证
总结
前言
本篇文章介绍了ElasticSearch分词器相关内容,介绍了什么是分词器,什么是ik分词器,ik分词器目前存在的问题以及如何通过修改ik分词器的源码来实现热更新词库。
什么是分词器?
Elasticsearch是基于倒排索引来实现搜索功能,而倒排索引的基础就是分词。Elasticsearch默认的分词器支持英文的分词,因为分词很简单,基本基于空格就可以分出来,而汉语的分词则困难很多。分词是把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个 匹配操作。
ik分词器简介
ik分词器和默认分词器的对比
默认的中文分词器是将每个字看成一个词,比如"中国人很喜欢吃油条",会被分为“中 国 人 很 喜 欢 吃 油 条”这几个字,而采用IK分词器 可以分为“中国人 很 喜欢 吃 油条”,看下上面分词后的结果,肯定是 ik 的分词结果比较符合中文。
以“中国人很喜欢吃油条”这个句话为例,标准分词器会将这句话分为:“中” “国” “人” “很” “喜” “欢” “吃” “油” “条”,例如:
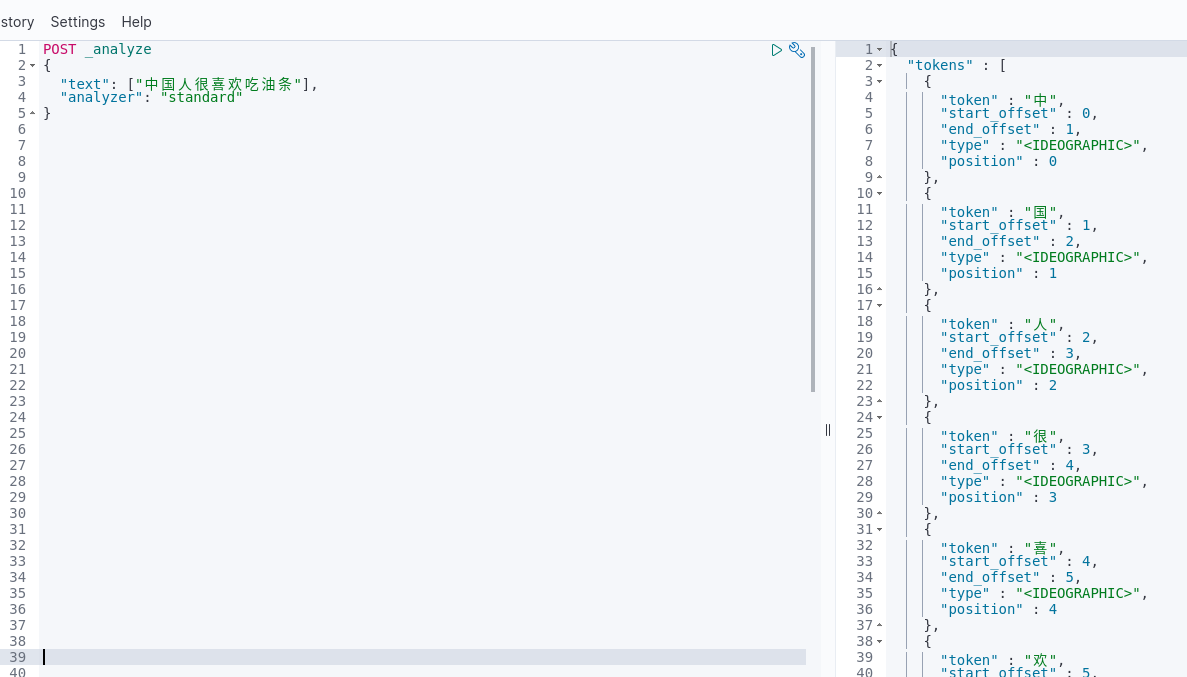
可以看出来,很不符合中文词的表述习惯,因为这段话不仅仅可以分为这10个字,还可以组成如:“中国”,“中国人”,“喜欢”等等。
我们来看看ik分词器的分词效果,以ik分词器的ik_max_word为例,“中国人很喜欢吃油条”这句话就可以拆成很多种,如:“中国人”,“中国”,“国人”,“很喜欢”等,例如:
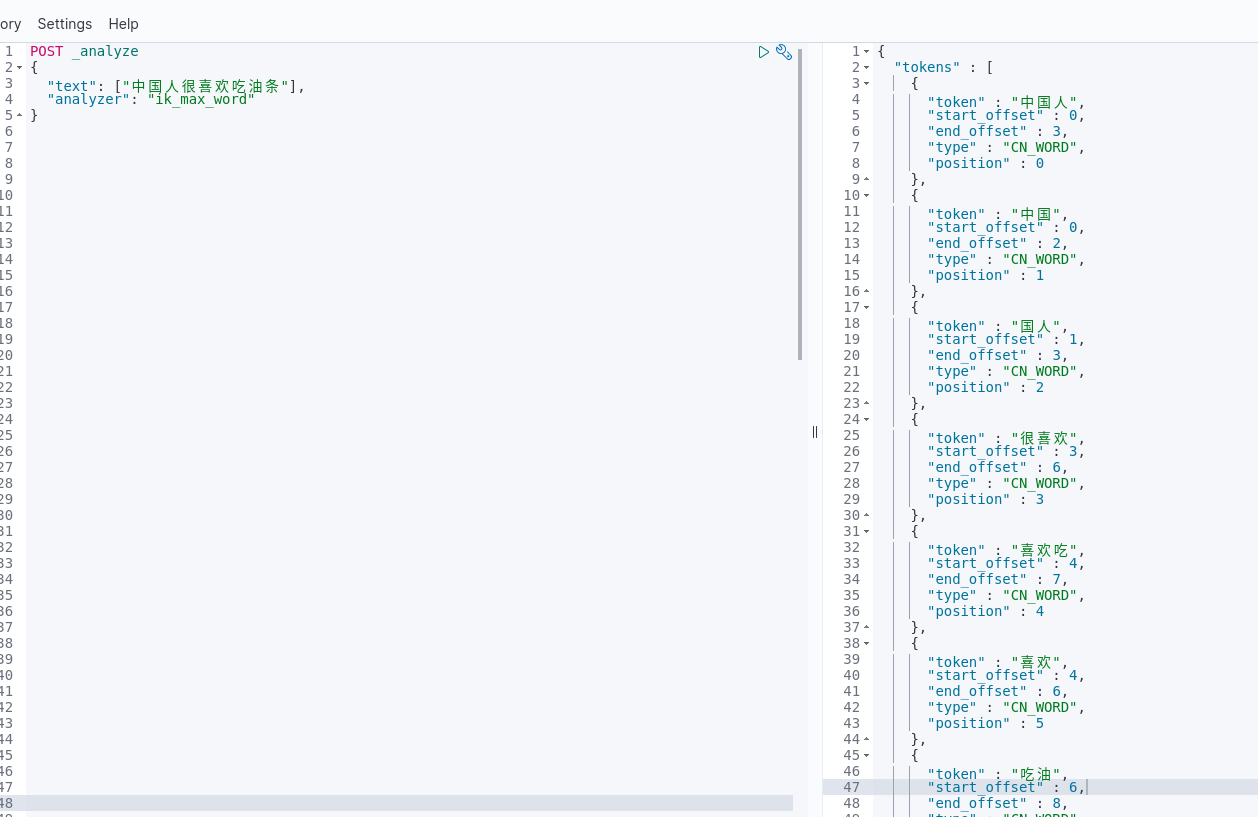
从上面分词后的结果可以看出,肯定是ik分词结果比较符合中文习惯
ik分词器介绍
在搜索引擎领域,比较成熟和流行的中文分词器,就是ik分词器,它提供了2种分词的模式,分别为ik_max_word和ik_smart
-
ik_max_word:将需要分词的文本做最小粒度的拆分,尽量分更多的词
-
ik_smart:将需要分词的文本做最大粒度的拆分
ik_max_word 的分词效果
语句
POST _analyze
{
"text": ["中国人很喜欢吃油条"],
"analyzer": "ik_max_word"
}结果
{
"tokens" : [
{
"token" : "中国人",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "国人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "很喜欢",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "喜欢吃",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "喜欢",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "吃油",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "油条",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 7
}
]
}ik_smart的分词效果
语句
POST _analyze
{
"text": ["中国人很喜欢吃油条"],
"analyzer": "ik_smart"
}结果
{
"tokens" : [
{
"token" : "中国人",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "很喜欢",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "吃",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "油条",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
}
]
}ik分词器的分词问题
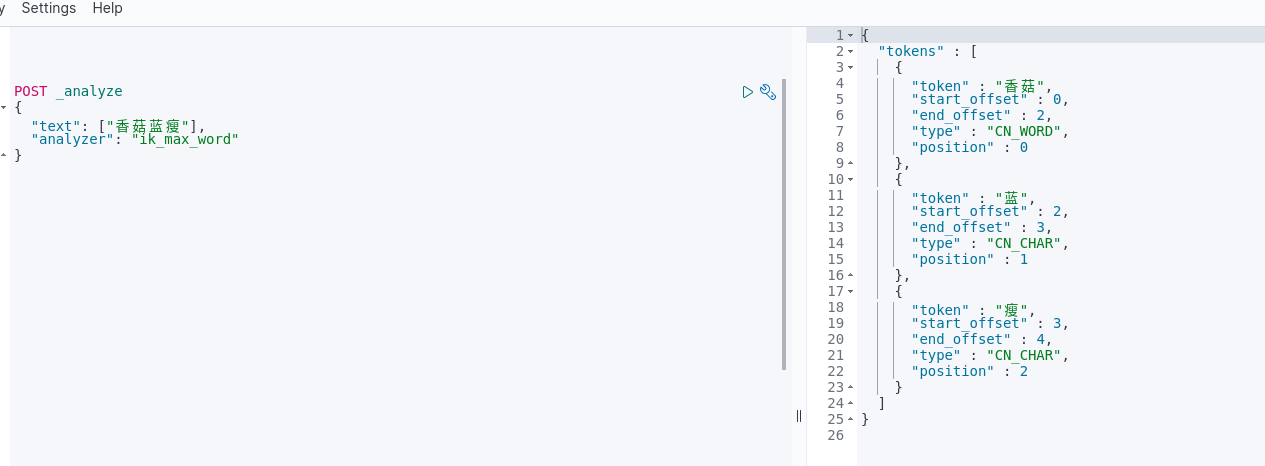
虽然通过ik_smart和ik_max_word可以做到中文分词效果,但是如果对于一些网络流行语或者我们公司内部的一些自定义的短语,无法做到分词的效果,如网络流行语:“香菇蓝瘦”,我们期望的是“香菇蓝瘦”也是其中的一个词,然后并没有
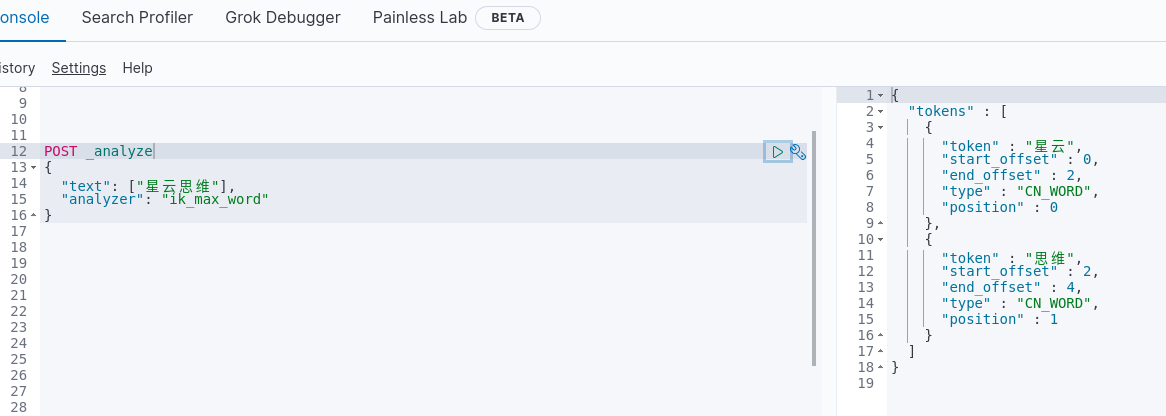
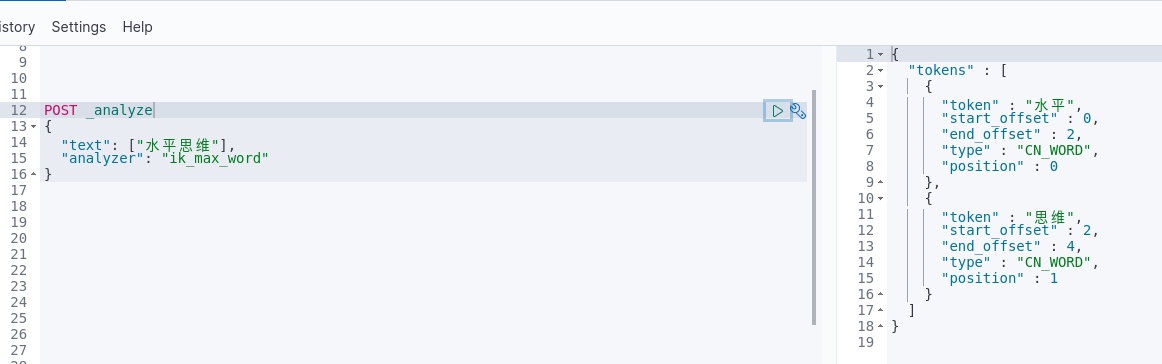
如公司的一些短语,如“星云思维”、“水平思维”,我们期望它成为一个完整的词,然后确没有
那么如何去按照我们定义的词去进行分词自适应呢?
自定义词库
主配置解说
ik配置文件地址:/usr/share/elasticsearch/plugins/ik/config 目录下都是存放配置文件

下面是这些主要配置文件含义:
-
IKAnalyzer.cfg.xml:用来配置自定义词库
-
main.dic:原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起,每个单词占据一行
-
quantifier.dic:放了一些单位相关的词
-
suffix.dic:放了一些后缀
-
surname.dic:中国的姓氏
-
stopword.dic:英文停用词
-
preposition.dic:介词词典
IKAnalyzer.cfg.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>ik原生最重要的两个配置文件
-
main.dic:包含了原生的中文词语,会按照这个里面的词语去分词
-
stopword.dic:包含了英文的停用词。custom/ext_stopword.dic 中包含了中文的一些扩展词
什么是停用词?与其他词相比,功能词没有什么实际含义,比如'the'、'is'、'at'、'which'、'on'等。
通过配置文件自定义词库
通过配置化的方式新增词库主要分为3步,分别为:
1. 新建自定义分词库
2. 添加到ik的配置文件中
3. 重启es,查看分词
下面介绍一下这3步的具体配置
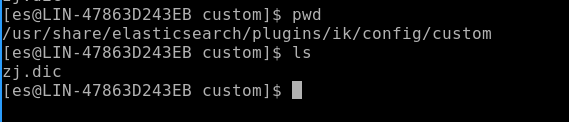
Step1: 新建自定义分词库
我们在/usr/share/elasticsearch/plugins/ik/config目录下新建一个文件夹custom,然后建一个dic文件(zj.dic),如:
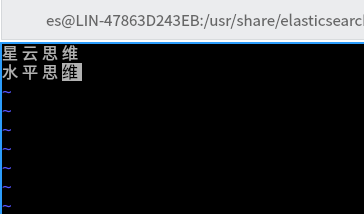
把这些热门词放到该文件中,如:
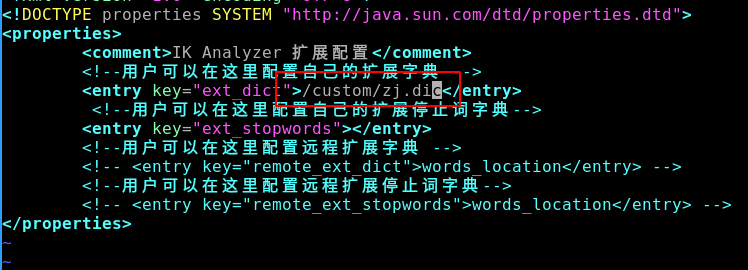
Step2: 将我们的自定义词添加到ik的配置文件中
Step3: 重启es,查看分词
重启es,然后在kibana上查看分词
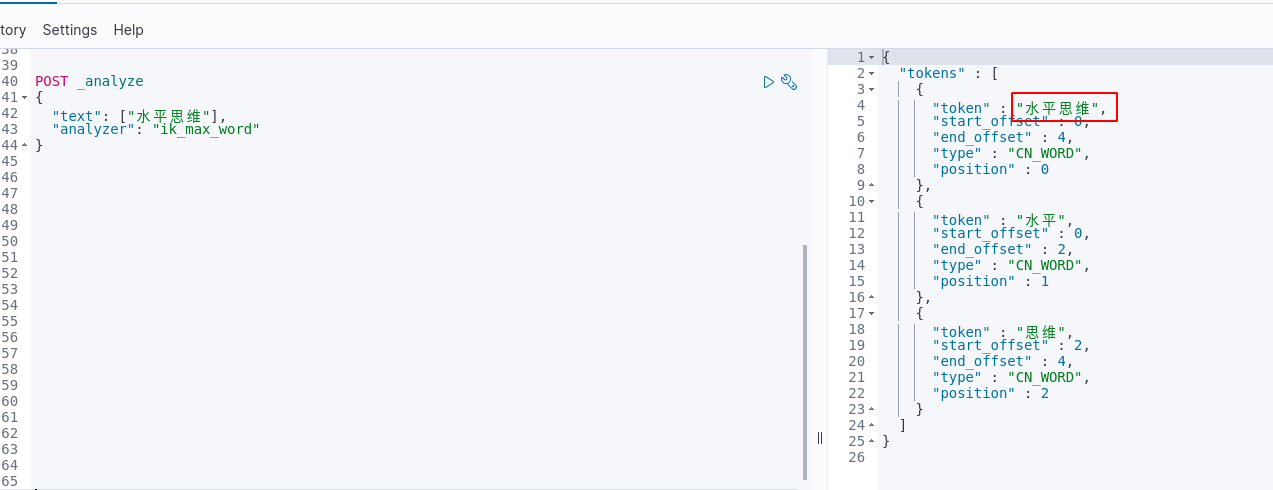
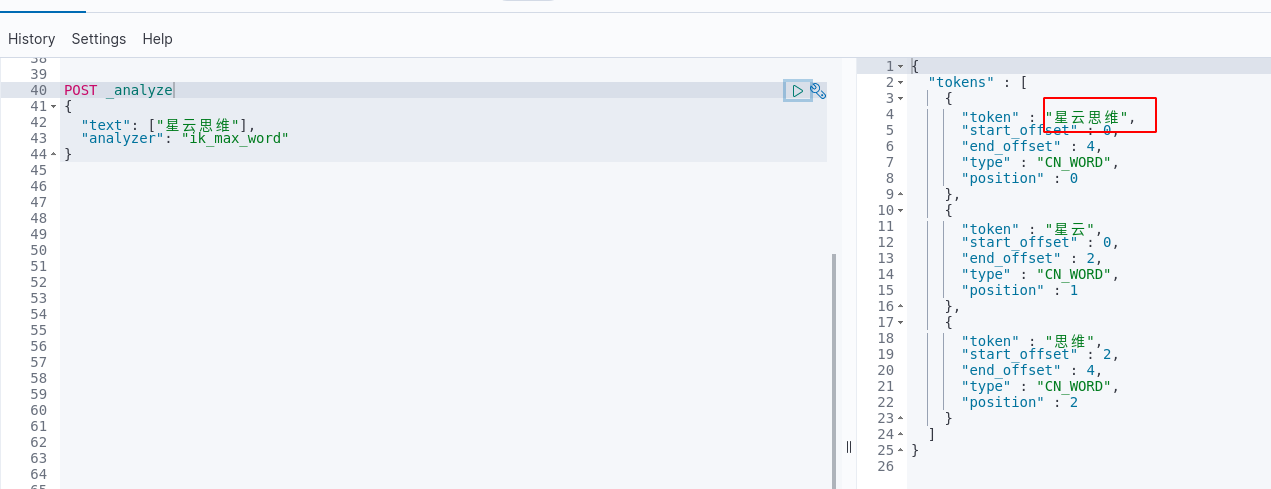
这样我们通过配置化的方式实现了分词效果
配置化方式自定义词库存在的问题
我们使用配置化的方式自定义词库的时候,每次都得重启,而且得逐个节点依次修改,是不是有点不方便呢?这种方式的主要缺点有:
-
每次添加完词库,都要重启es才能生效,非常麻烦
-
es是分布式的,生产环境一般几十个个es节点,每次添加完词库,然后重启节点,可想而知......
热更新词库方案
目前ik分词器热更新词库的方案有两种
-
修改ik分词器源码,后台启动一个线程,每隔一段时间从MySQL数据库中,抽取数据,进行自动加载词库
-
基于ik分词器原生的热更新方案,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新
推荐第一种方案修改ik分词器源码, 第二种方案ik git社区官方都不建议采用,不太稳定。下面也是围绕着第一种方案进行源码改造来实现热更新词库
ik分词器热更新词库实践
IK分词器源码下载
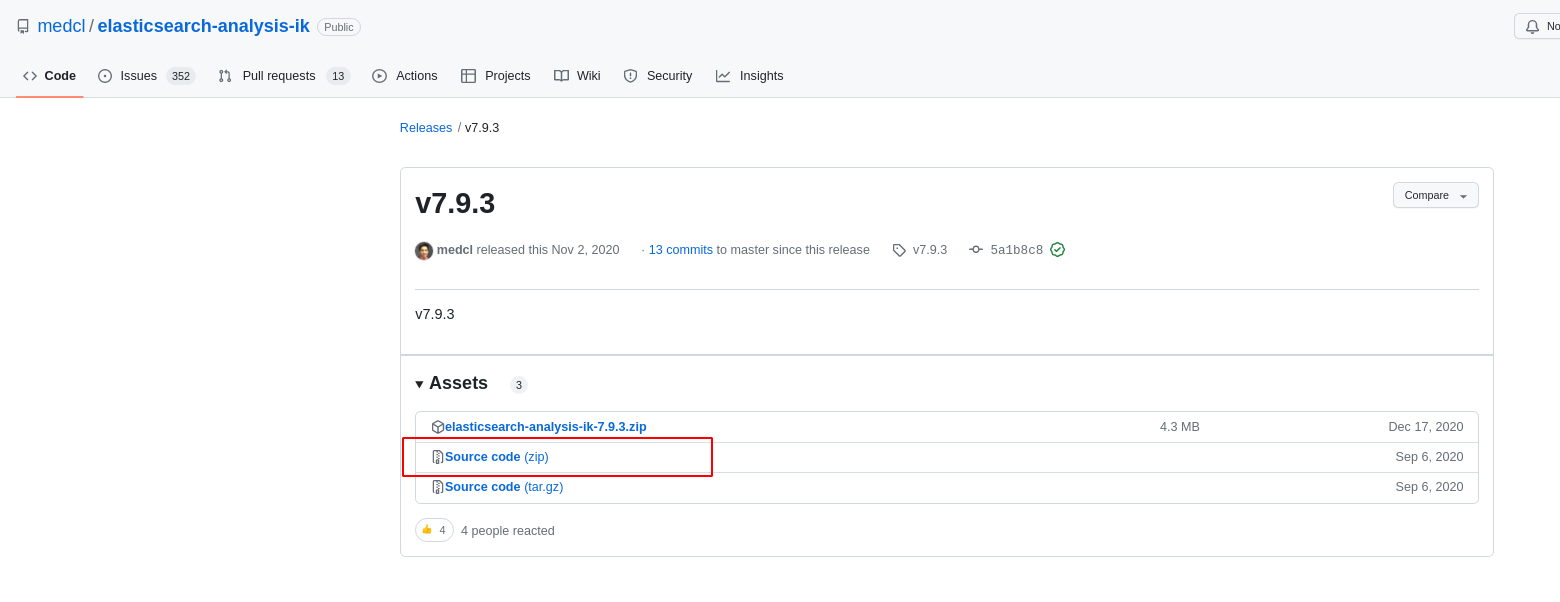
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
我选择的版本是7.9.3的版本,选中图中的Source code(zip)进行下载
导入maven工程
源码中词典加载大体流程
ik分词器实现了ES的AnalysisPlugin接口,通过工厂方法初始化词典,加载默认配置
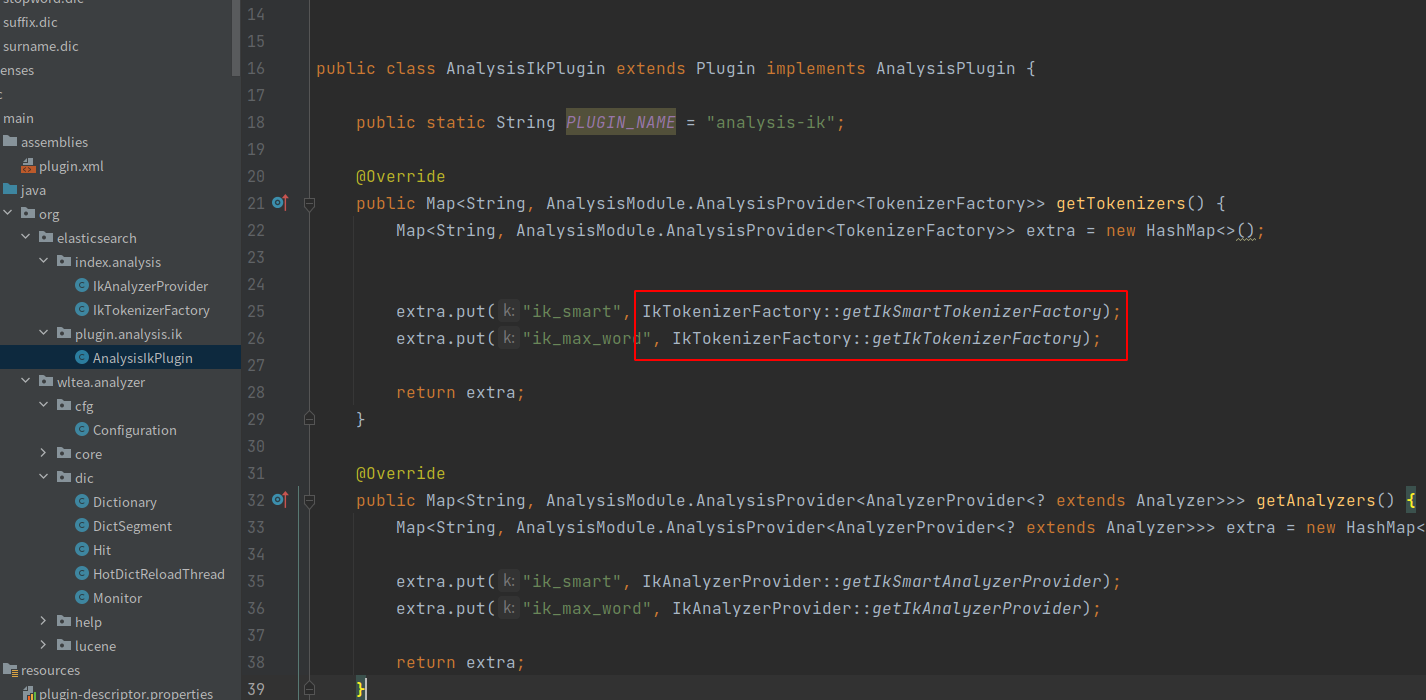
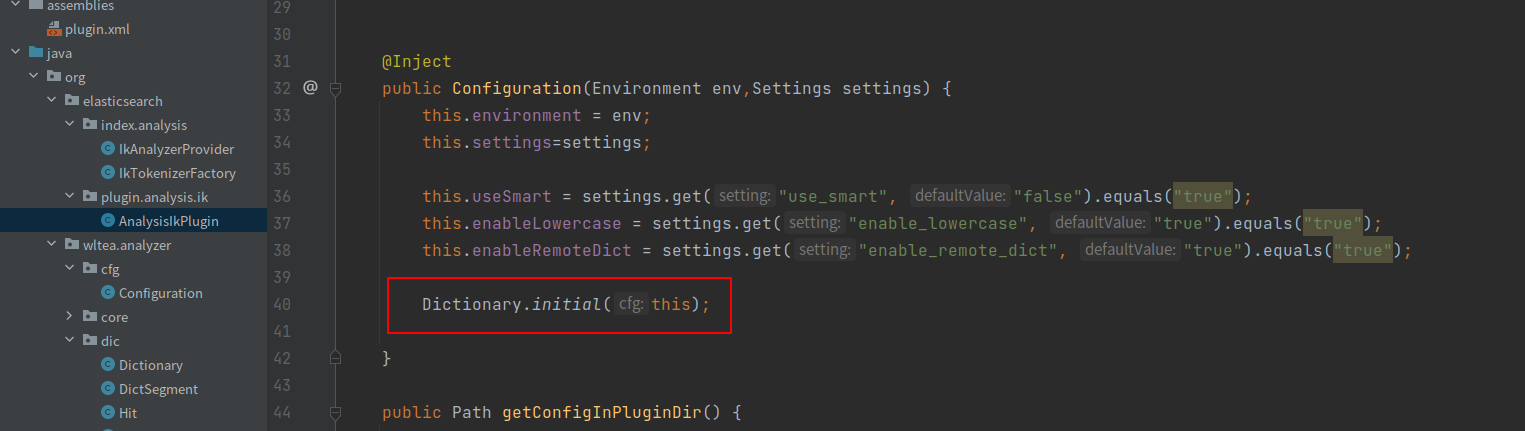
默认会根据DefaultConfiguration找到主词典和中文量词词典路径,同时DefaultConfiguration会根据classpath下配置文件IKAnalyzer.cfg.xml,找到扩展词典和停止词典路径,用户可以在该配置文件中配置自己的扩展词典和停止词典。找到个词典路径后,初始化Dictionary.java,Dictionary是单例的。在Dictionary的构造函数中加载词典。Dictionary是IK的词典管理类,真正的词典数据是存放在DictSegment中,该类实现了一种树结构,如下图。
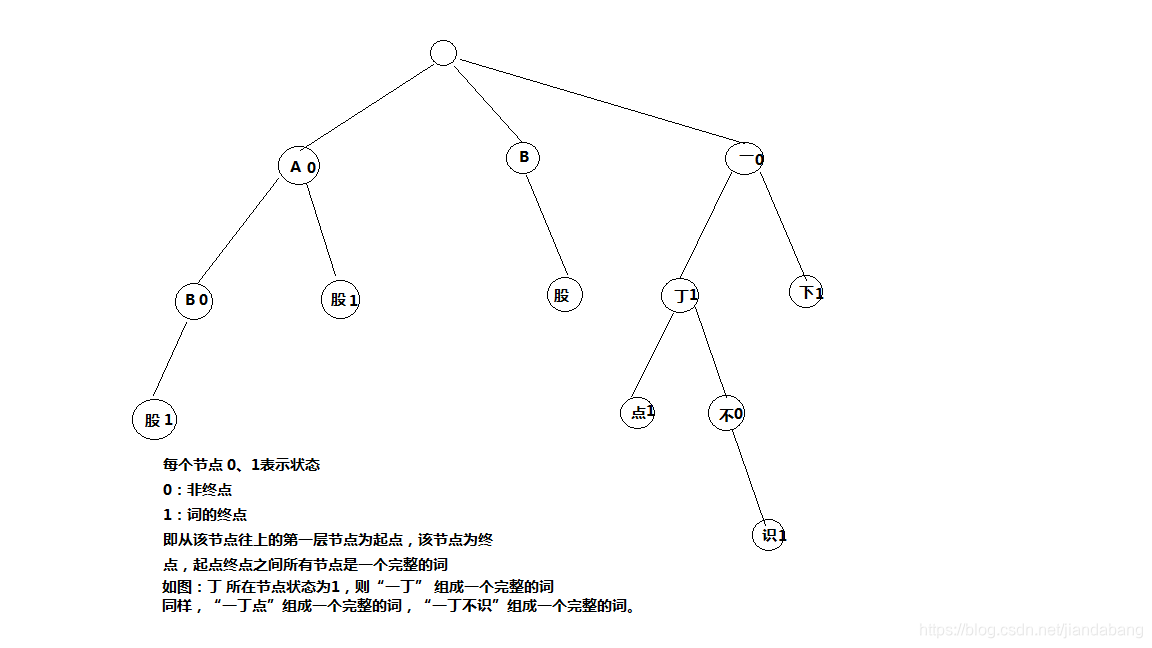
举个例子,要对字符串“A股市场”进行分词,首先拿到字符串的第一个字符'A',在上面的tree中可以匹配到A节点,然后拿到字符串第二个字符'股',首先从前一个节点A往下找,我们找到了股节点,股是一个终点节点。所以,“A股“是一个词。
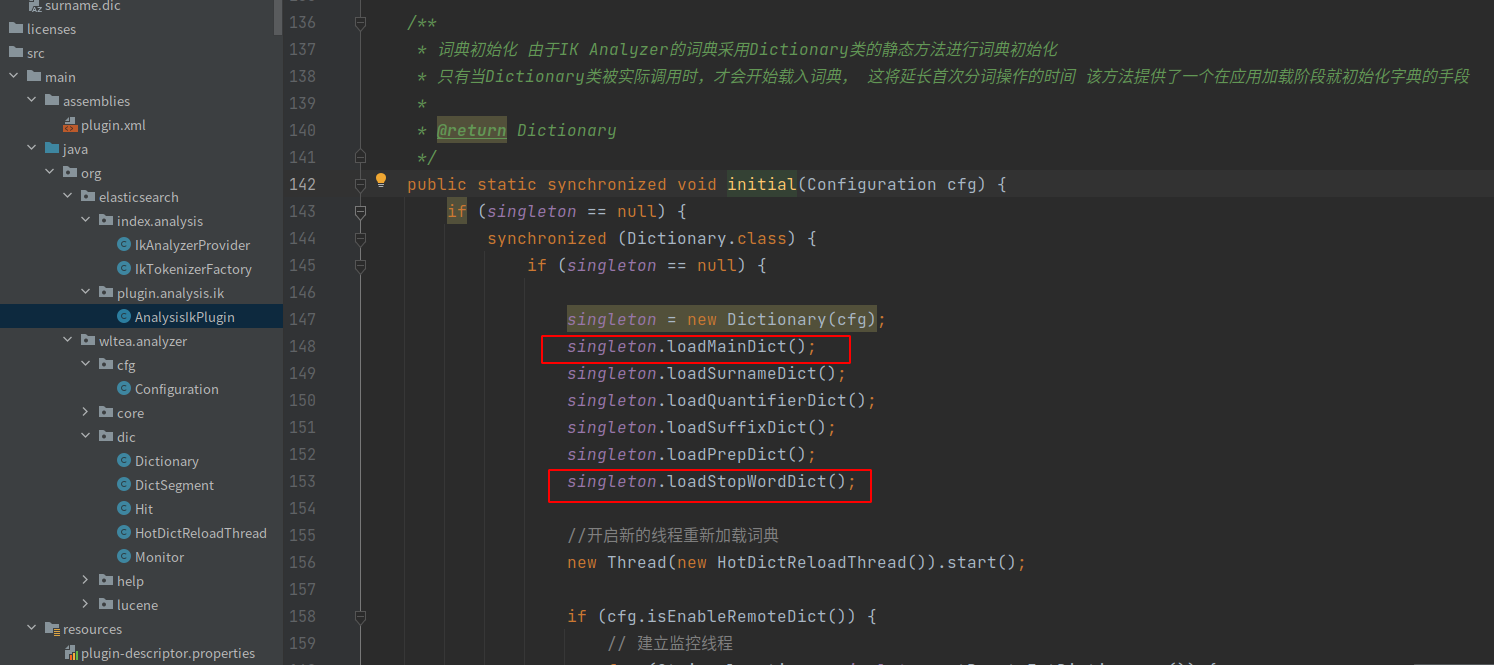
Dictionary加载主词典,以,将主词典保存到它的_MainDict字段中,加载完主词典后,立即加载扩展词典,扩展词典同样保存在_MainDict中。
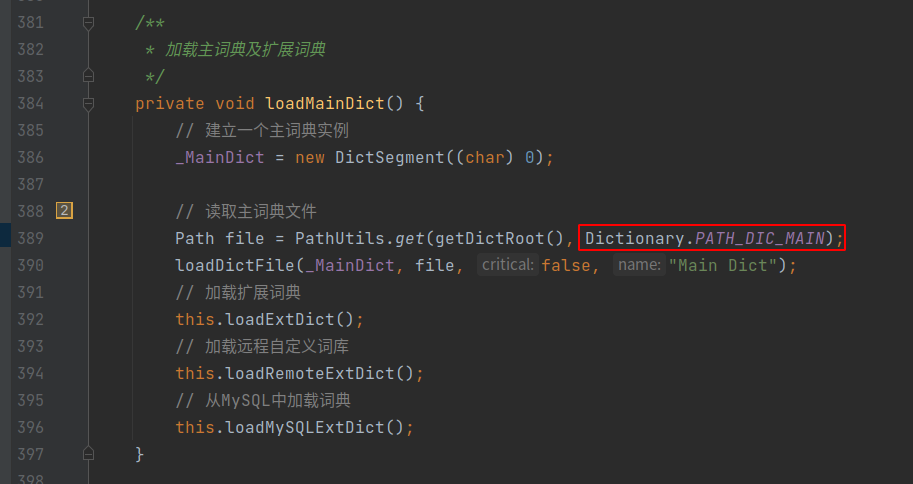
fillSegment方法是DictSegment加载单个词的核心方法,charArray是词的字符数组,先是从存储节点搜索词的第一个字符开始,如果不存在则创建一个节点用于存储第一个字符,后面递归存储,直到最后一个字符。
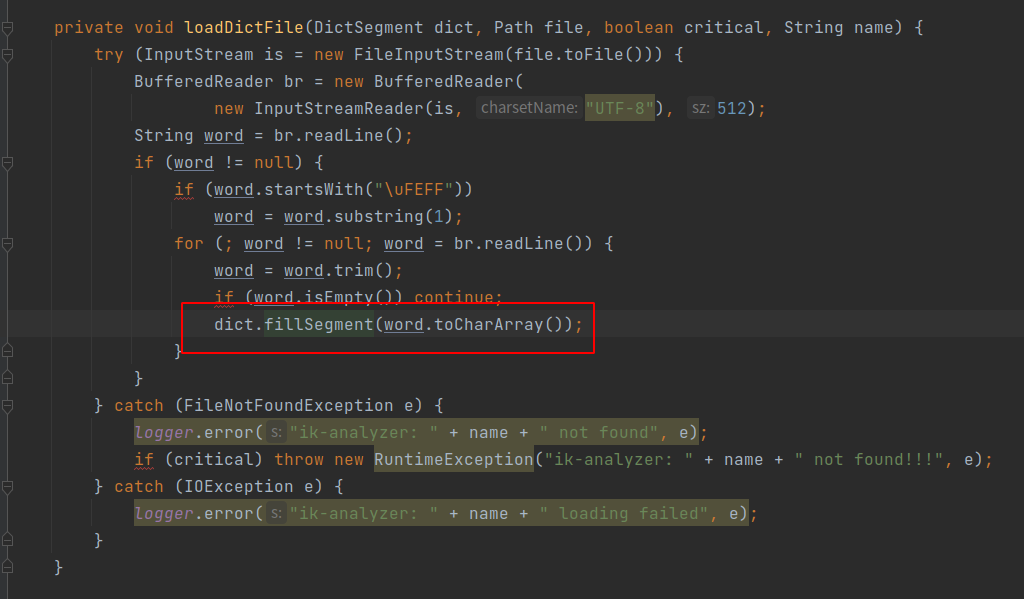
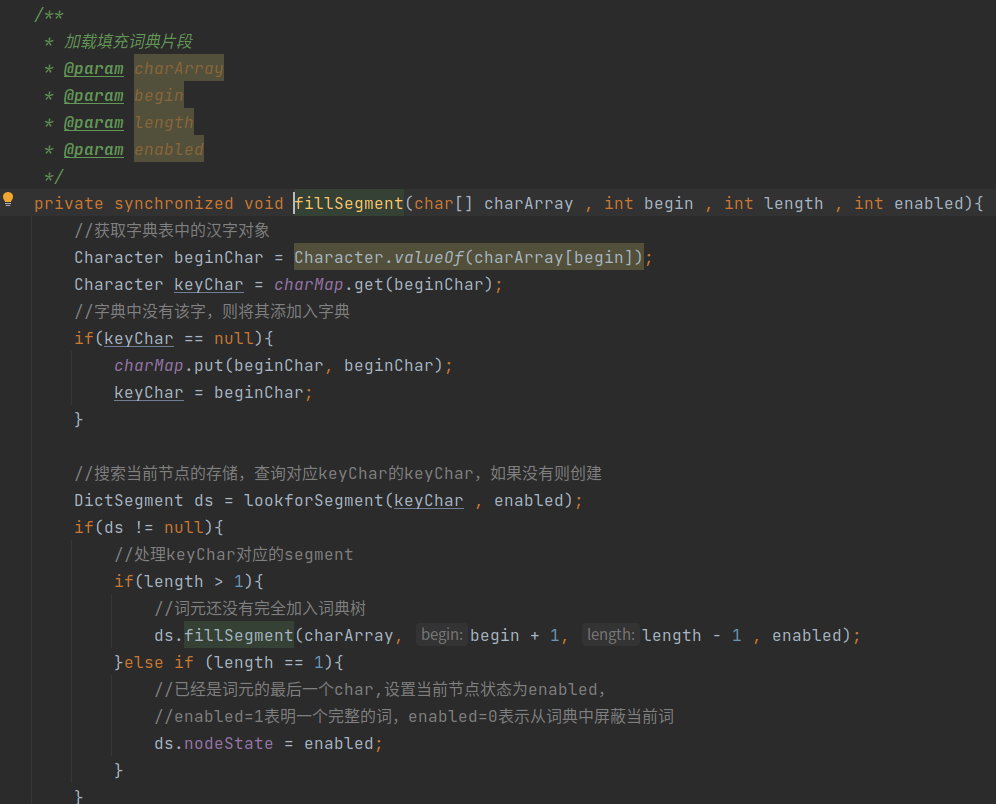
因此,我们只需要在加载加载主词典及扩展词典的时候,通过fillSegment方法填充词典即可,下面介绍具体的源码修改流程。
修改源码
简单说下整体思路: 开启一个后台线程,扫描mysql中定义的表,加载数据。
修调整elasticsearch.version
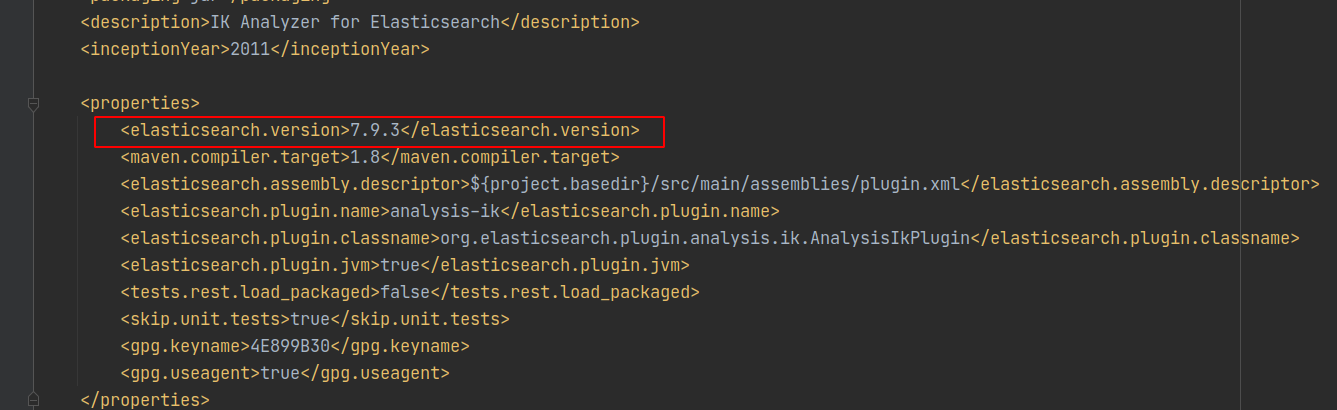
本次下载的是7.9.3版本,但是下载下来后是7.4.0版本,因为我用的是7.9.3版本的ES这里需要改一下版本
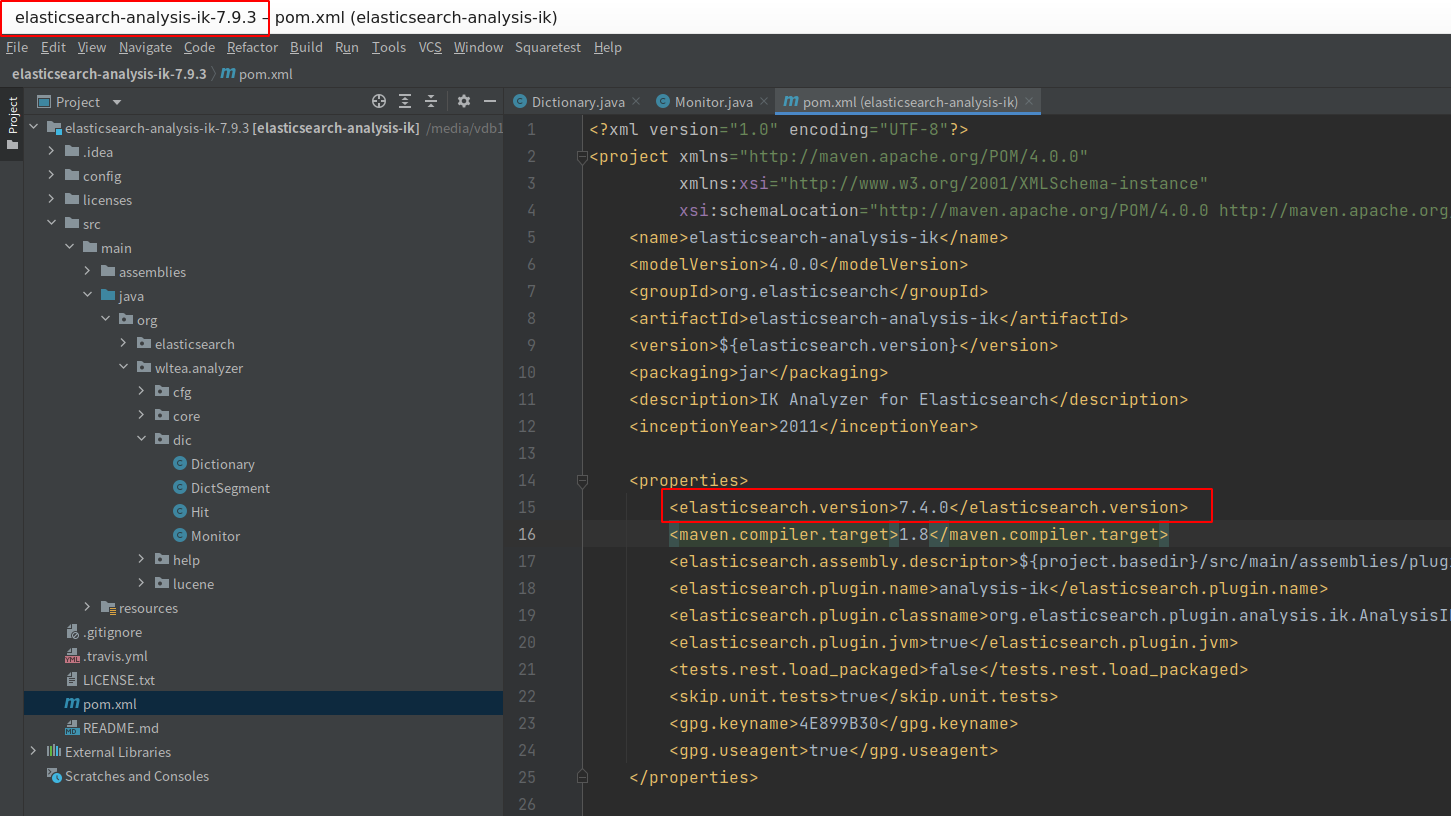
修改为:
在pom文件中添加mysql驱动器依赖
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>创建数据库配置文件jdbc-reload.properties,放在IK项目的config文件夹下
jdbc.url=jdbc:mysql://10.xxx.xxx.XX:3306/canal-test?serverTimezone=UTC
jdbc.user=ueranme
jdbc.password=password
jdbc.reload.extend.sql=select word from es_extra_main
jdbc.reload.stop.sql=select word from es_extra_stopword
# 间隔时间 毫秒
jdbc.reload.interval=10000reload间隔,1秒钟轮训一次
新增HotDictReloadThread类
在org.wltea.analyzer.dic目录下,新增一个HotDictReloadThread类,死循环去调用Dictionary.getSingleton().reLoadMainDict(),重新加载词典,HotDictReloadThread结构如下:
package org.wltea.analyzer.dic;
import org.wltea.analyzer.help.ESPluginLoggerFactory;
/**
* @author
* @version 1.0
* @date 2024/1/12 下午7:21
* <p>Copyright: Copyright (c) 2024<p>
*/
public class HotDictReloadThread implements Runnable {
private static final org.apache.logging.log4j.Logger logger = ESPluginLoggerFactory.getLogger(HotDictReloadThread.class.getName());
@Override
public void run() {
while (true) {
logger.info("[======HotDictReloadThread======] begin to reload hot dict from dataBase......");
Dictionary.getSingleton().reLoadMainDict();
}
}
}看下reLoadMainDict这个方法的执行逻辑
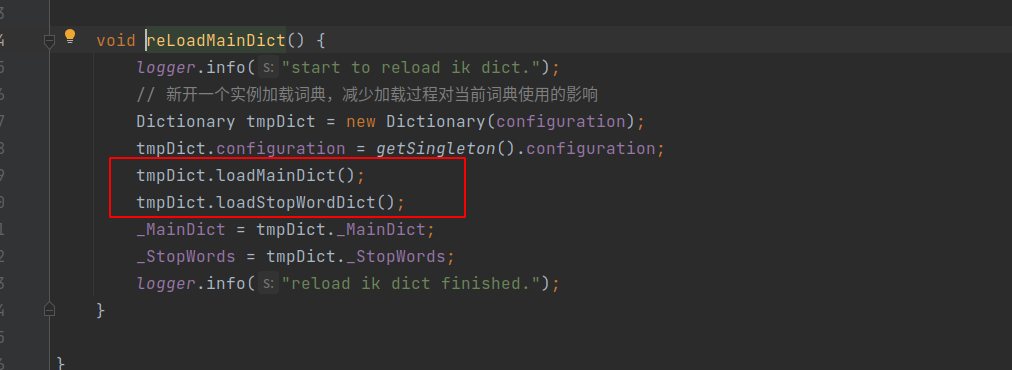
reLoadMainDict方法的核心逻辑有两块:
-
tmpDict.loadMainDict():加载主词库
-
tmpDict.loadStopWordDict():加载停用词词库
由此可以看出,只要我们把读取数据库的逻辑放到这两个方法里面就可以了,下面我们分别来修改这两个方法。
修改org.wltea.analyzer.dic.Dictionary#loadMainDict方法
通过修改loadMainDict来读取MySQL中的主词库,来实现热加载,修改的点如下:
增加this.loadMySQLExtDict(),该方法就是将MySQL表中的数据加载到词库中
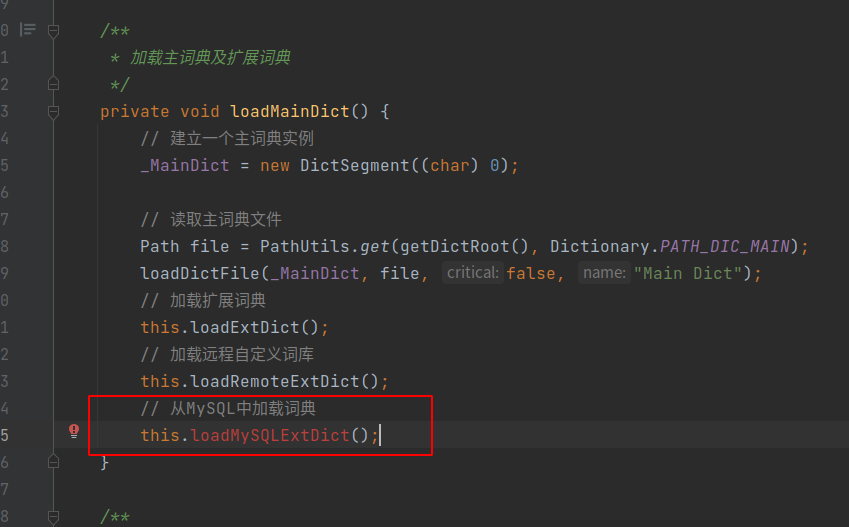
loadMySQLExtDict()方法的主体逻辑是通过JDBC查询MySQL
代码如下:
private static Properties prop = new Properties();
static {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
logger.error("error", e);
}
}
/**
* 从mysql加载热更新词典
*/
private void loadMySQLExtDict() {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Path file = PathUtils.get(getDictRoot(), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile()));
logger.info("[==========]jdbc-reload.properties");
for(Object key : prop.keySet()) {
logger.info("[==========]" + key + "=" + prop.getProperty(String.valueOf(key)));
}
logger.info("[==========]query hot dict from mysql, " + prop.getProperty("jdbc.reload.extend.sql") + "......");
conn = DriverManager.getConnection(
prop.getProperty("jdbc.url"),
prop.getProperty("jdbc.user"),
prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.extend.sql"));
while(rs.next()) {
String theWord = rs.getString("word");
logger.info("[==========]hot word from mysql: " + theWord);
_MainDict.fillSegment(theWord.trim().toCharArray());
}
Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval"))));
} catch (Exception e) {
logger.error("erorr", e);
} finally {
if(rs != null) {
try {
rs.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
}
}修改org.wltea.analyzer.dic.Dictionary#loadStopWordDict方法
在loadStopWordDict方法中增加loadMySQLStopWordDict,该方法实现从MySQL中加载停用词到词典中
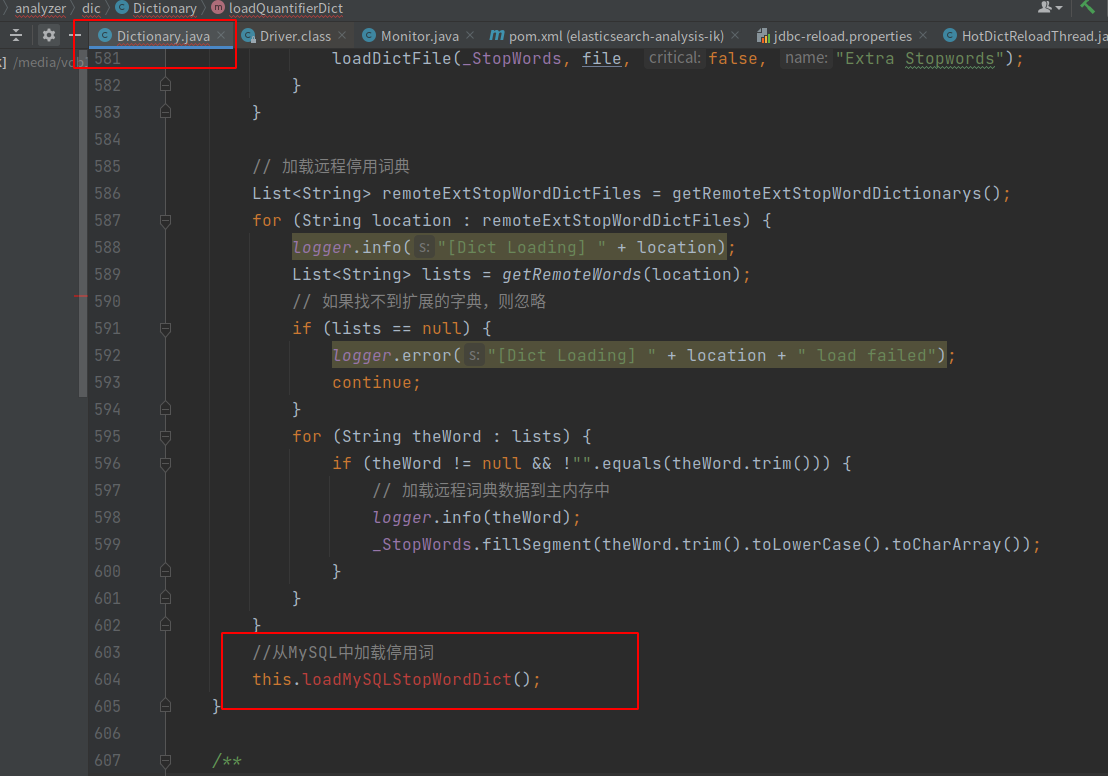
loadMySQLStopWordDict实现代码为:
/**
* 从mysql加载停用词
*/
private void loadMySQLStopWordDict() {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
Path file = PathUtils.get(getDictRoot(), "jdbc-reload.properties");
prop.load(new FileInputStream(file.toFile()));
logger.info("[====loadMySQLStopWordDict======] jdbc-reload.properties");
for(Object key : prop.keySet()) {
logger.info("[==========]" + key + "=" + prop.getProperty(String.valueOf(key)));
}
logger.info("[==========]query hot stop word dict from mysql, " + prop.getProperty("jdbc.reload.stop.sql") + "......");
conn = DriverManager.getConnection(
prop.getProperty("jdbc.url"),
prop.getProperty("jdbc.user"),
prop.getProperty("jdbc.password"));
stmt = conn.createStatement();
rs = stmt.executeQuery(prop.getProperty("jdbc.reload.stop.sql"));
while(rs.next()) {
String theWord = rs.getString("word");
logger.info("[==========]hot stop word from mysql: " + theWord);
_StopWords.fillSegment(theWord.trim().toCharArray());
}
Thread.sleep(Integer.valueOf(String.valueOf(prop.get("jdbc.reload.interval"))));
} catch (Exception e) {
logger.error("error", e);
} finally {
if(rs != null) {
try {
rs.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
logger.error("error", e);
}
}
}
}org.wltea.analyzer.dic.Dictionary#initial调用HotDictReloadThread方法

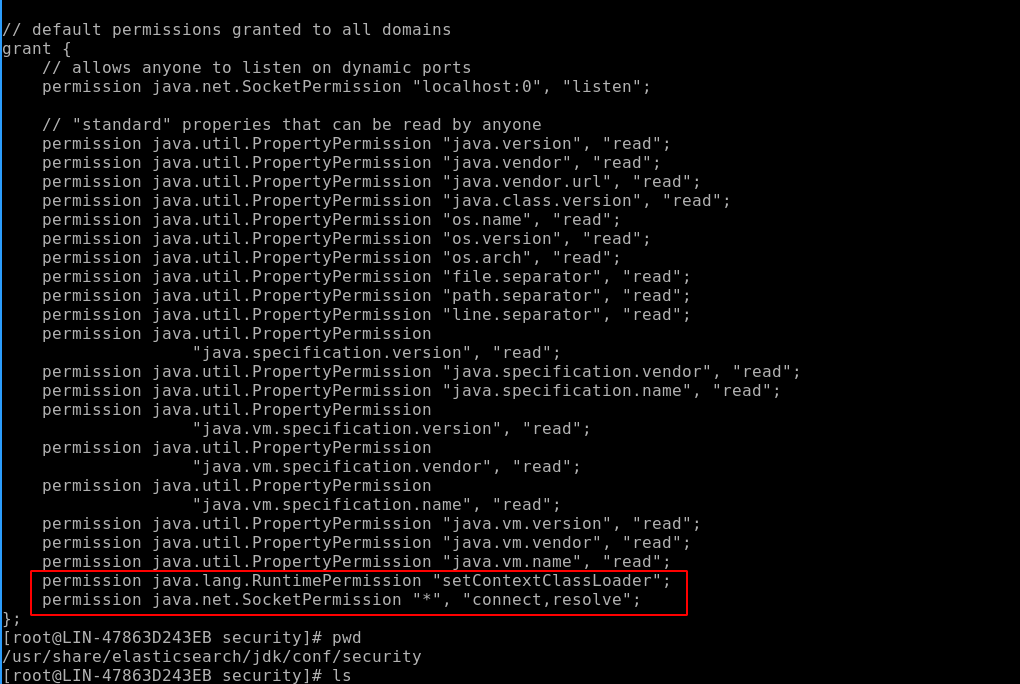
修改插件的权限
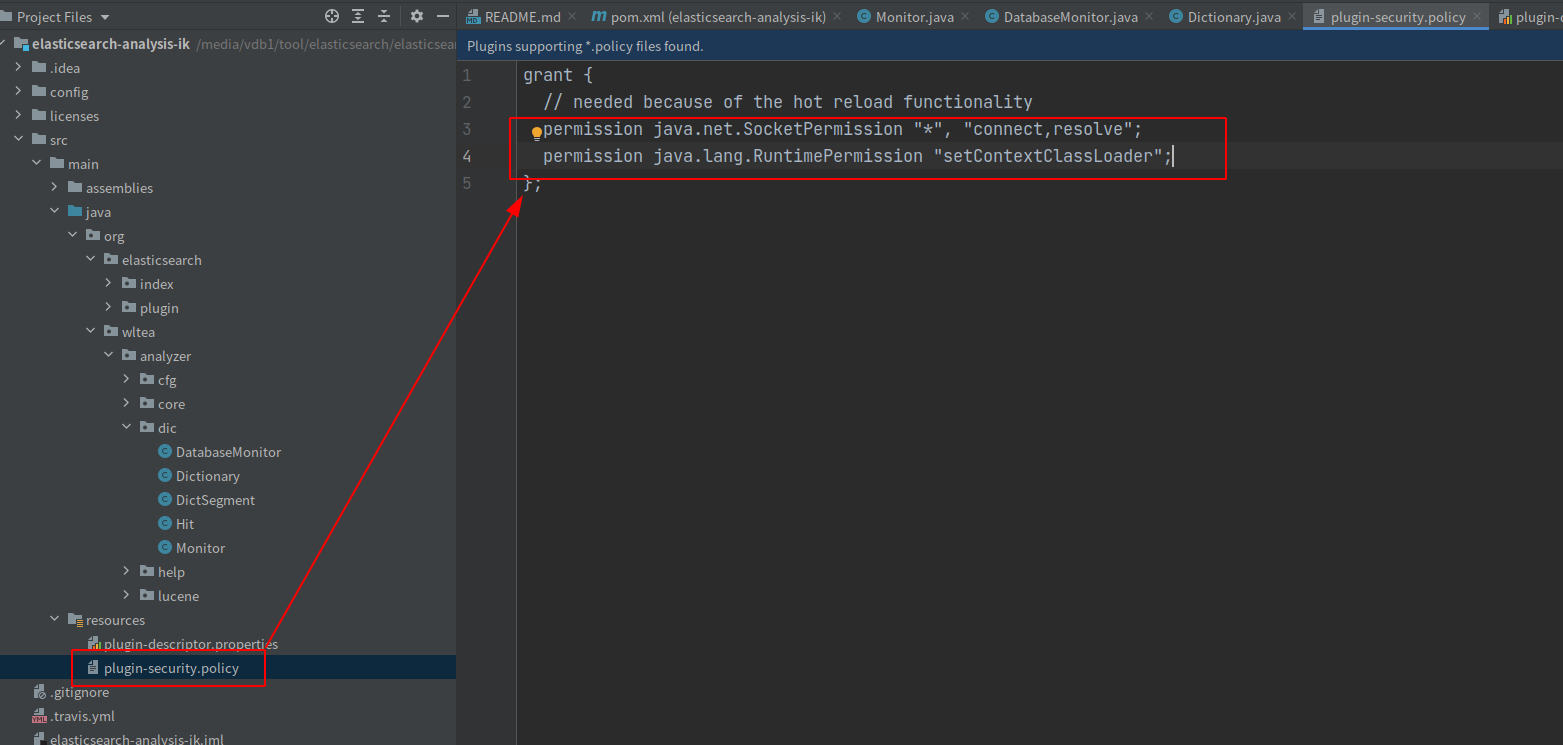
grant {
// needed because of the hot reload functionality
permission java.net.SocketPermission "*", "connect,resolve";
permission java.lang.RuntimePermission "setContextClassLoader";
};如何还不行的话,切换到/usr/share/elasticsearch/jdk/conf/security目录下,在java.policy文件最后一行加上
permission java.lang.RuntimePermission "setContextClassLoader";
如果还有java.net.SocketPermission的报错,则在java.policy文件的后面再加上
permission java.net.SocketPermission "*", "connect,resolve";
建立数据库表
CREATE TABLE `es_extra_main`
(
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`word` varchar(255) CHARACTER SET utf8mb4 NOT NULL COMMENT '词',
`is_deleted` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否已删除',
`update_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP (6) COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `es_extra_stopword`
(
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`word` varchar(255) CHARACTER SET utf8mb4 NOT NULL COMMENT '词',
`is_deleted` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否已删除',
`update_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP (6) COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;打包
加入依赖
将MySQL的jar包依赖加入进来,否则打包会缺少jar包保持错。
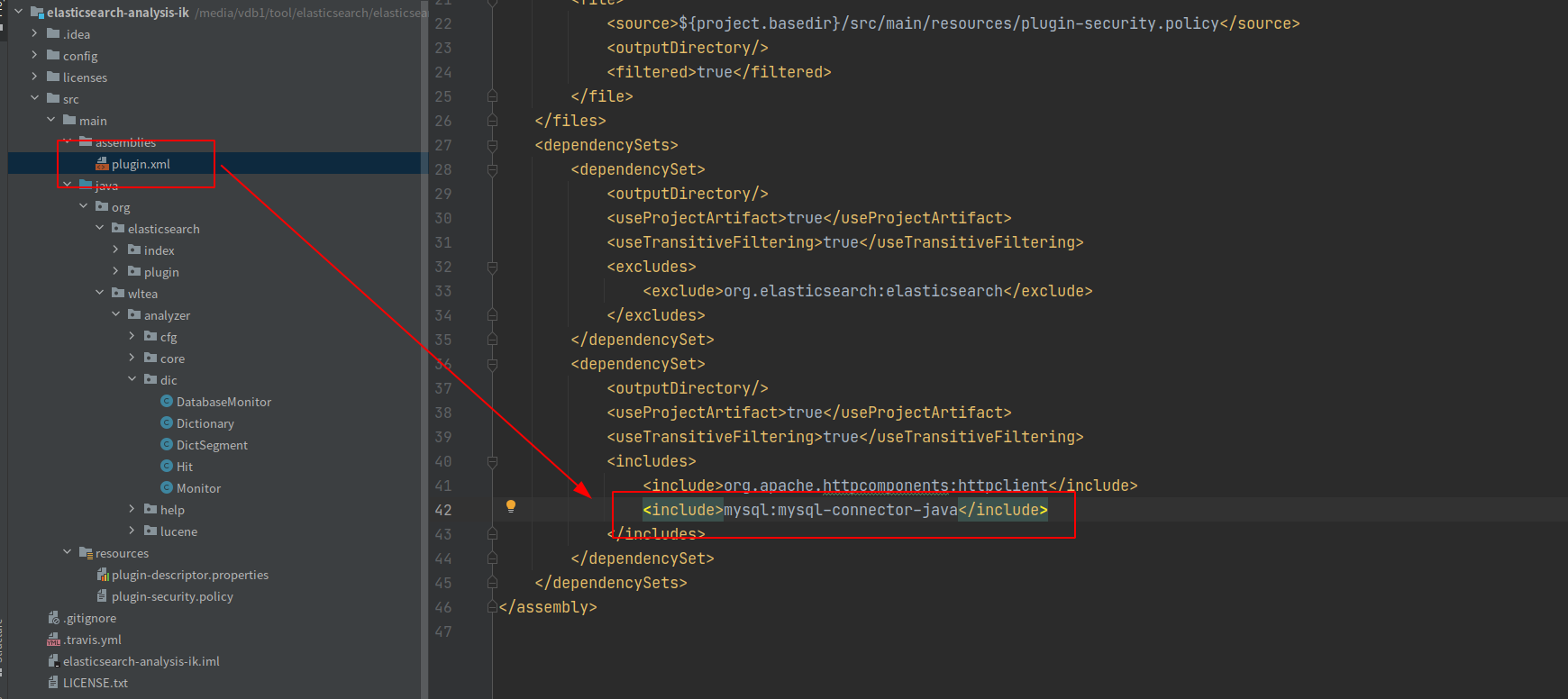
<include>mysql:mysql-connector-java</include>
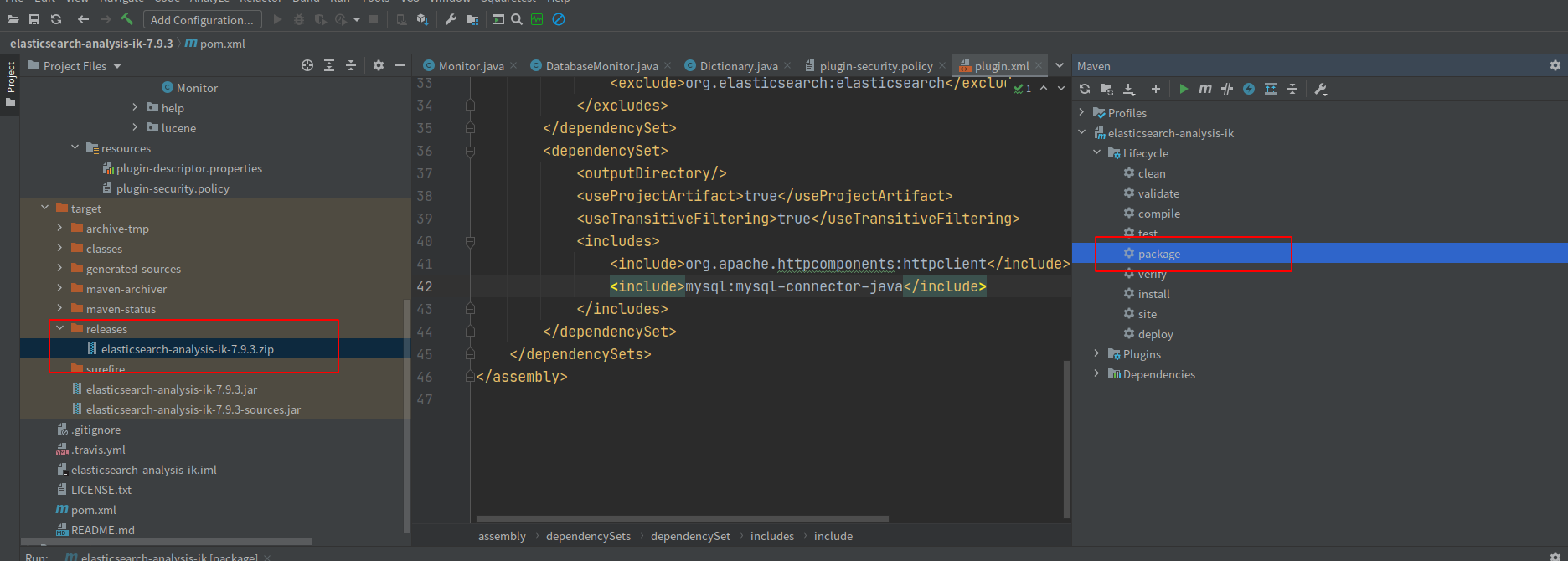
package
打包成zip文件,然后加压成文件夹
安装
将elasticsearch-analysis-ik-7.9.3.zip文件拷贝到/usr/share/elasticsearch/plugins/ik目录下:
cp elasticsearch-analysis-ik-7.9.3.zip /usr/share/elasticsearch/plugins/ik/
解压
unzip elasticsearch-analysis-ik-7.9.3.zip
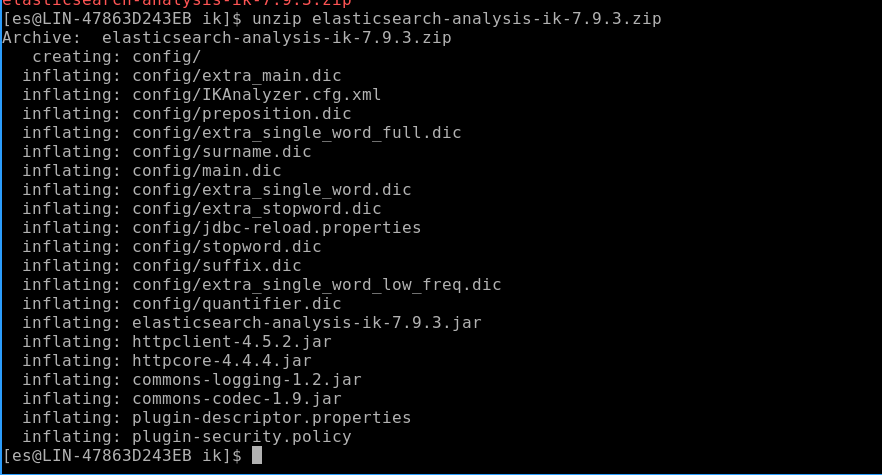
然后重启es和kibana,可以看到es已经开始加载词库了
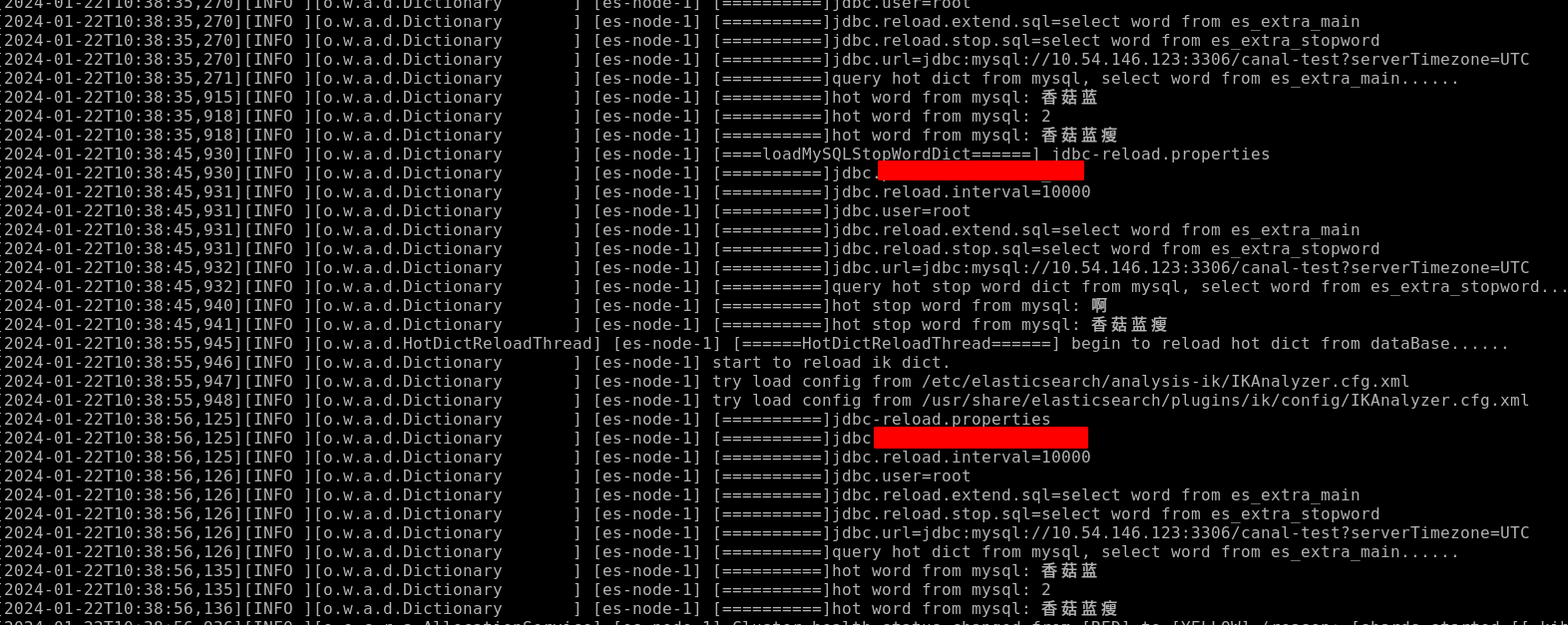
测试验证
在数据库表中中新增下面自己的想要的关键词,然后去Kibana中做测试验证
关键词验证
1. “水平思维”关键词验证
未在数据中插入词库验证
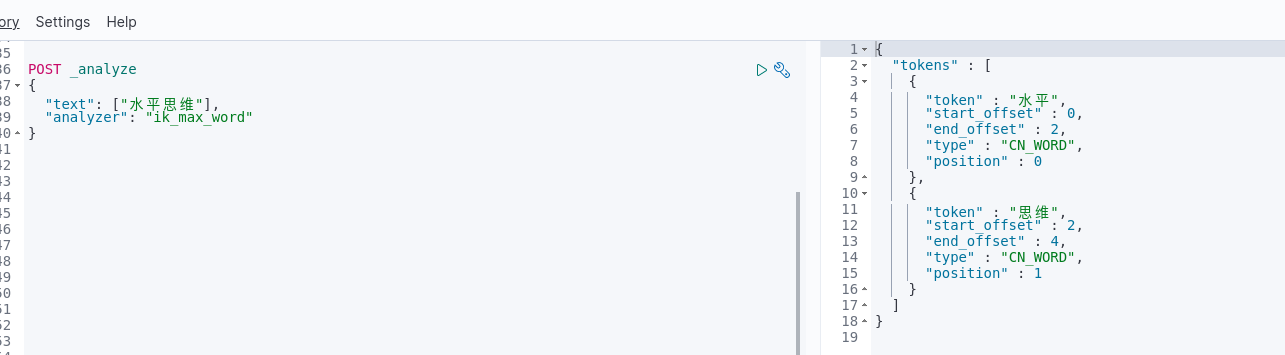
在数据中插入词库验证,插入“水平思维”
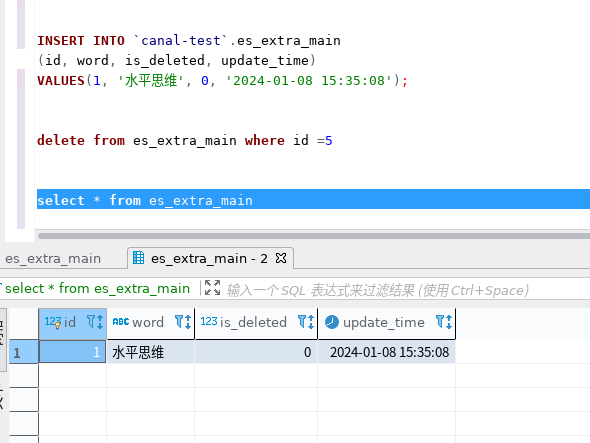

分词的效果
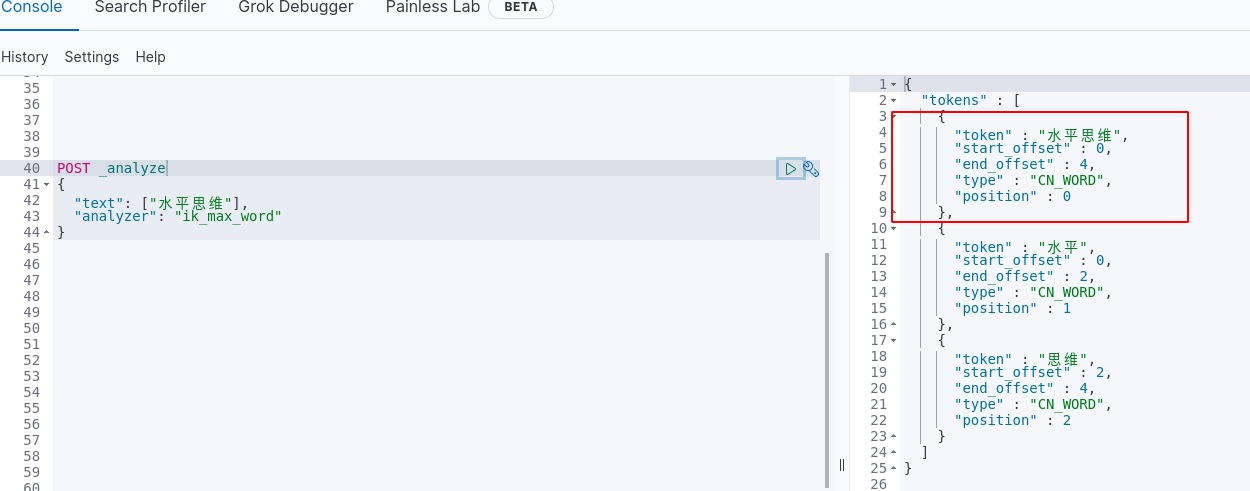
2. 网络流行语“他是显眼包”验证
在数据中插入网络流行语“显眼包”验证,插入“他是显眼包”
插入之前
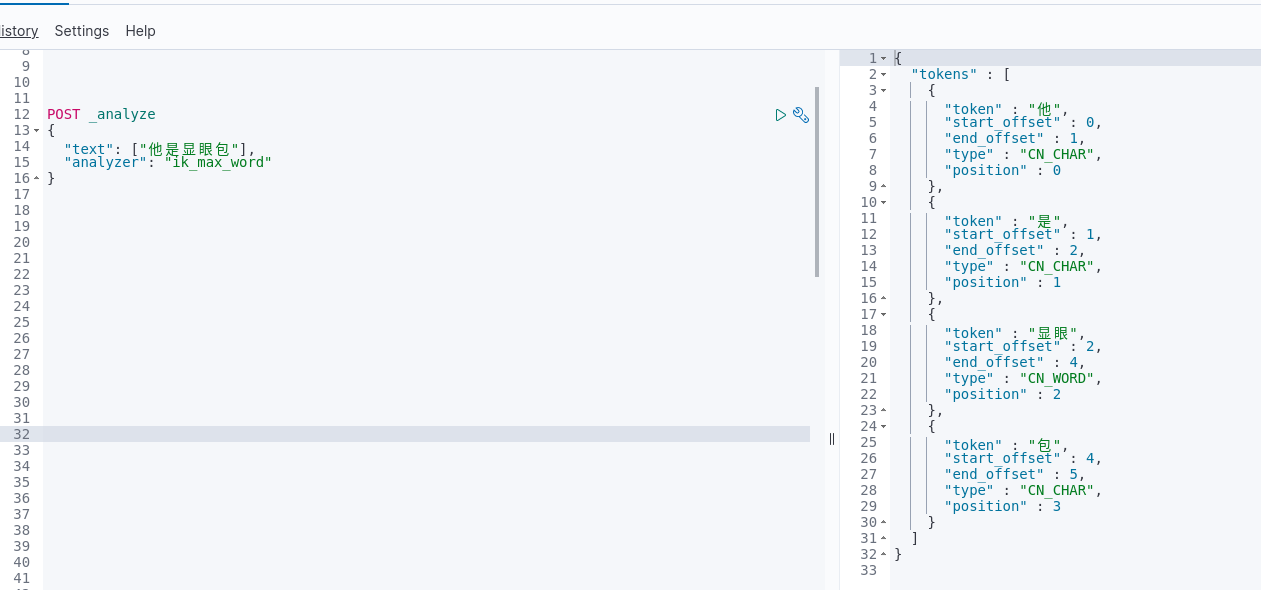
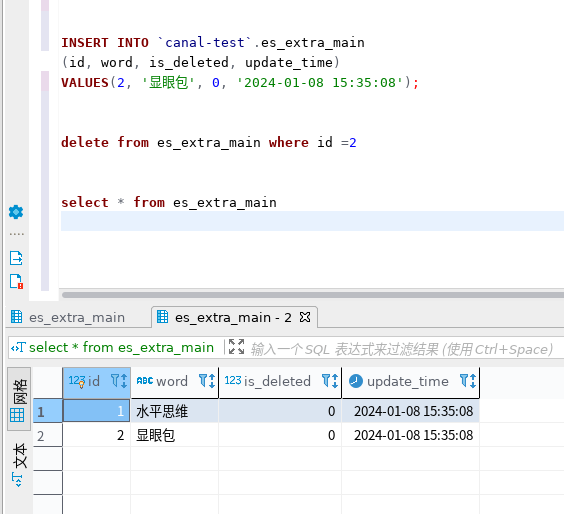
数据库中增加“显眼包”,验证
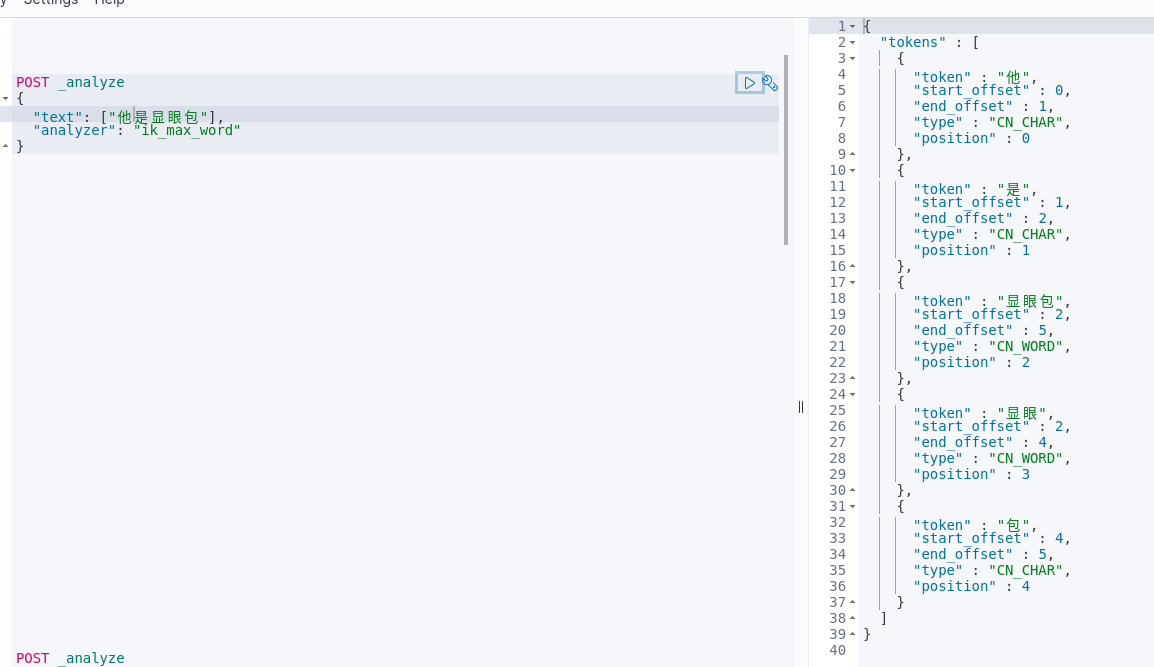
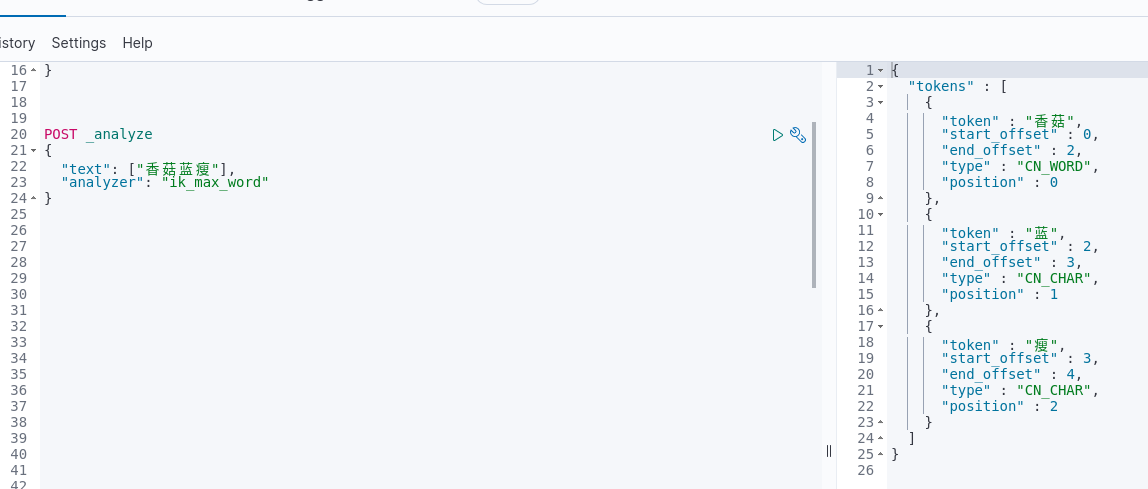
3. 网络流行语“香菇蓝瘦”验证
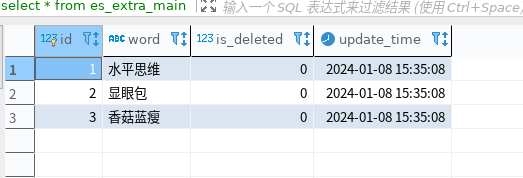
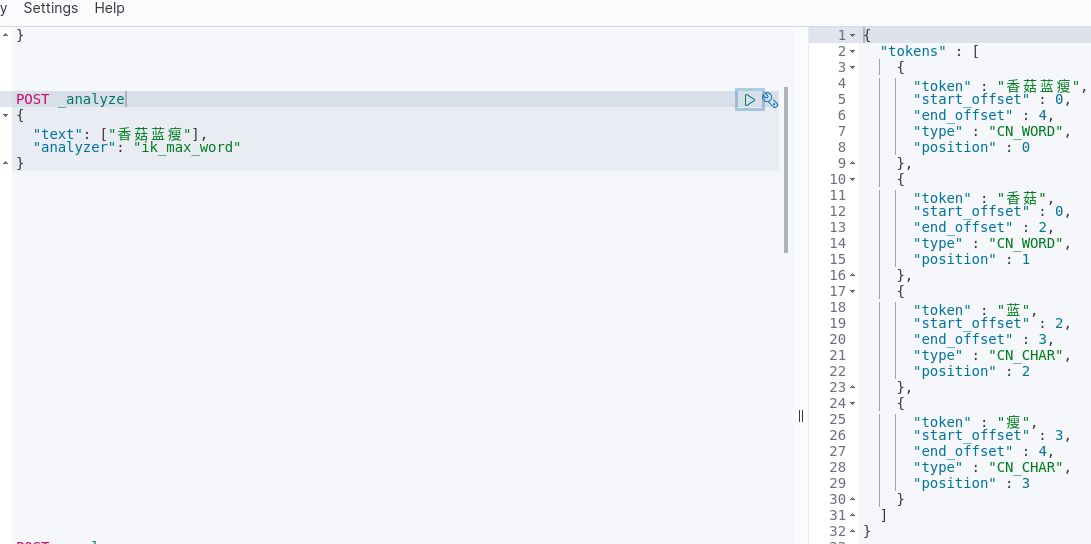
停用词验证
停用词指的是有些词是关键词,但是出于某些业务场景,不想使用这些关键词被检索到,可以将这些词语放到停用词典
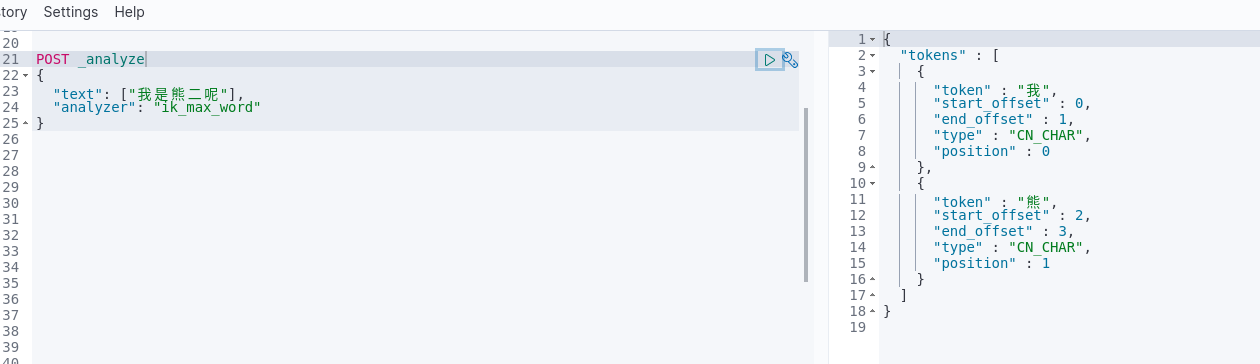
1. “我是熊二呢”短语验证
验证前,测试短语“我是熊二呢”
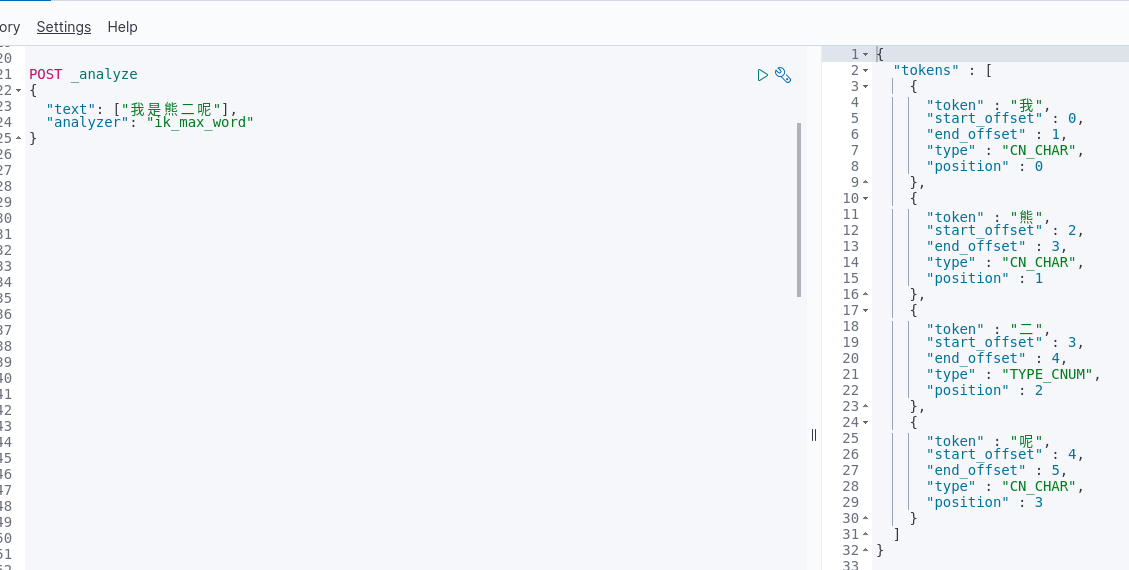
我们将“呢”、“二”放到停用词中
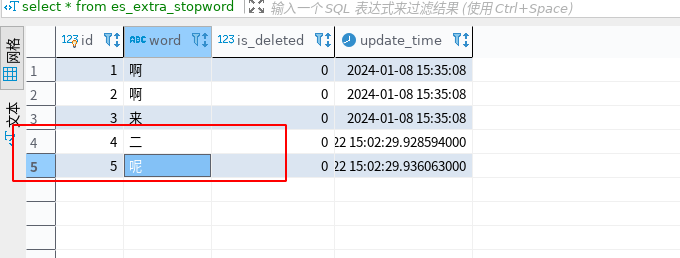
在kibana上验证,发现“呢”、“二”已经没了
2. “一个老流氓”短语验证
验证前,测试短语“一个老流氓”,分词后的效果为:
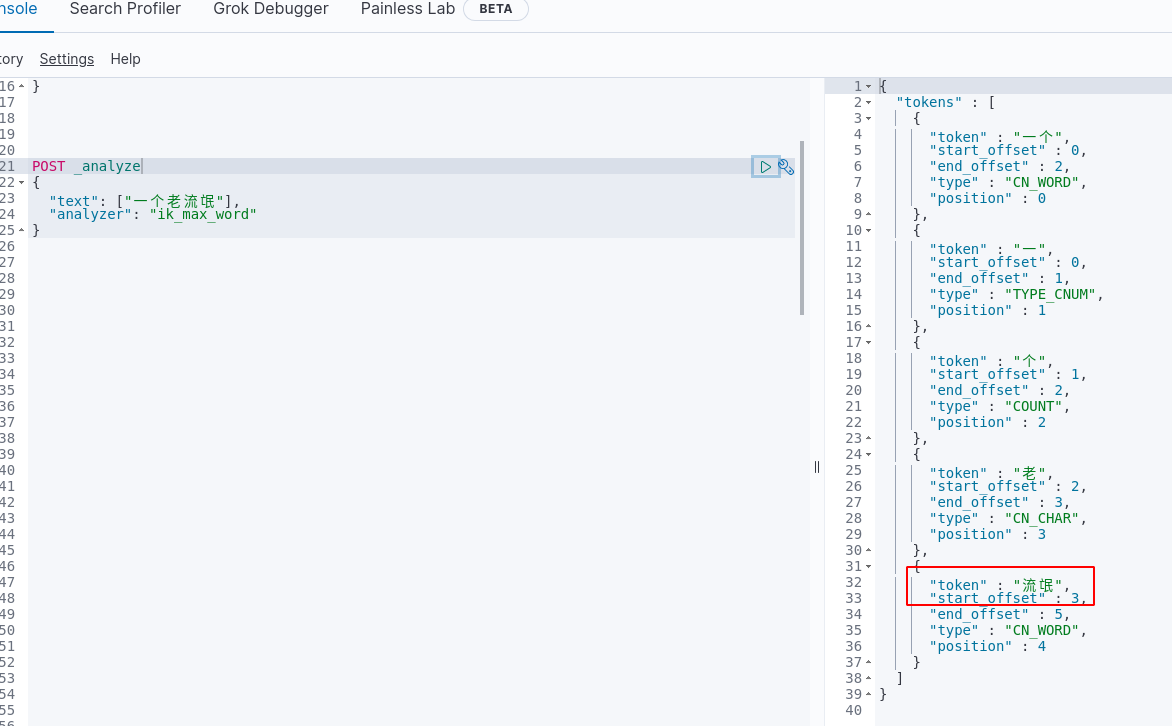
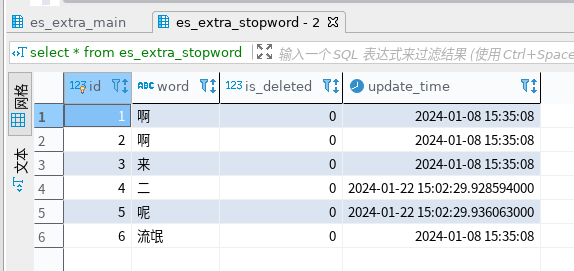
我们发现“流氓”也在其中,对于这种污秽的言辞,我们希望屏蔽它,营造一个良好的网络环境,我们将“流氓”加到停用词库中,再进行测试
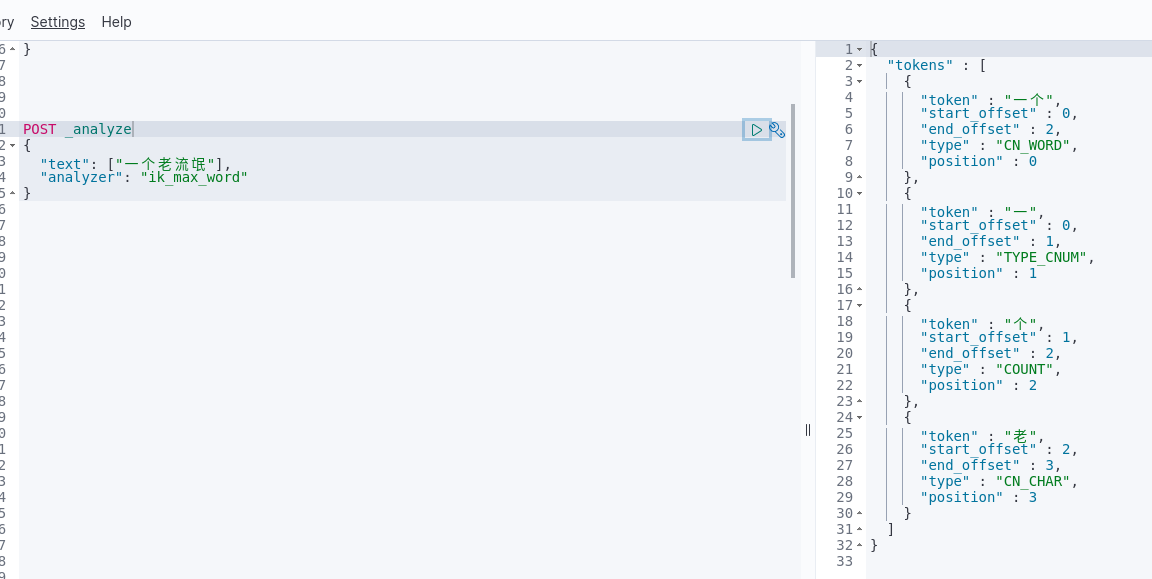
我们再次运行,发现“流氓”已经没了,达到了我们验证的效果
总结
本文主要讲解了什么是ik分词器,如何通过配置化的方式实现自定义词库,配置化方式存在的一些问题,以及如何通过修改ik分词器源码来实现扩展词库以及停用词库热刷新,该实践证明了通过该方案实现的可行性,后续有项目需要基于es分词器实现热刷新,可以借鉴。