目录
一、计算机编码
1.ASCII编码
2. GB2312编码
3.GBK编码
4.UTF-8编码
二、URL转码
1.encodeURI和decodeURI
2.encodeURIComponent 和 decodeURIComponent
三、Base64
一、计算机编码
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则。
常见的编码方式有 :
ASCII编码、GB2312编码、GBK编码、UTF-8编码等。
这些编码方式各有特点,用于处理不同的字符集和数据类型,以满足不同的应用需求。计算机编码的基础在于将字符和数据转换成二进制0和1的序列,以便在计算机内部存储和处理。这种转换过程使得计算机能够理解和处理人类可读的文本信息,同时也允许不同设备和系统之间的数据交换和通信。
主要时间点:

下面介绍几种编码方式:
1.ASCII编码
ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符。
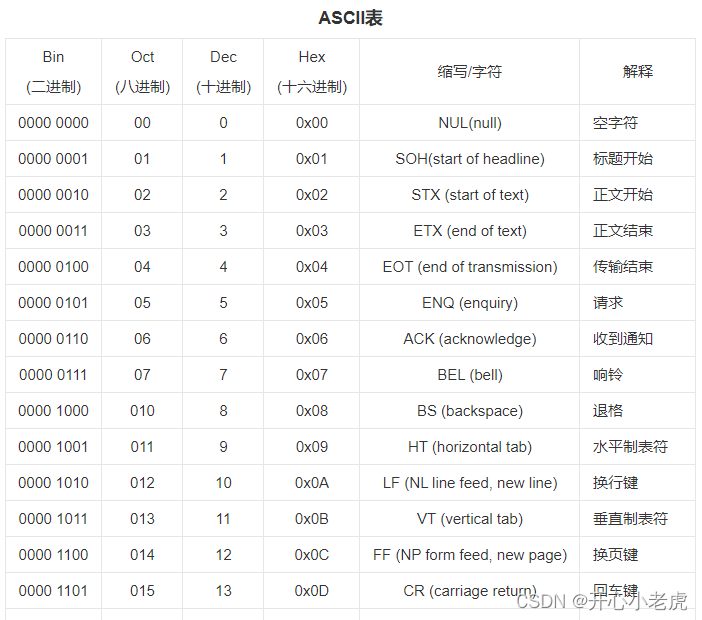
ASCII编码局限性:
在英语中,用128个符号编码便可以表示所有,但是用来表示其他语言,128个符号是不够的。比如汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 2562 = 65536 个符号
2. GB2312编码
1980 年,中国发布了第一个汉字编码标准,也即 GB2312 ,全称 《信息交换用汉字编码字符集·基本集》,通常简称 GB (“国标”汉语拼音首字母)。
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
基本集共收入汉字6763个和非汉字图形字符682个。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。
把换算成十六进制的区位码加上2020H,就得到国标码。国标码加上8080H,就得到常用的计算机机内码。1995年又颁布了《汉字编码扩展规范》(GBK)。GBK与GB/T 2312-1980国家标准所对应的内码标准兼容,同时在字汇一级支持ISO/IEC10646—1和GB 13000—1的全部中、日、韩(CJK)汉字,共计20902字。

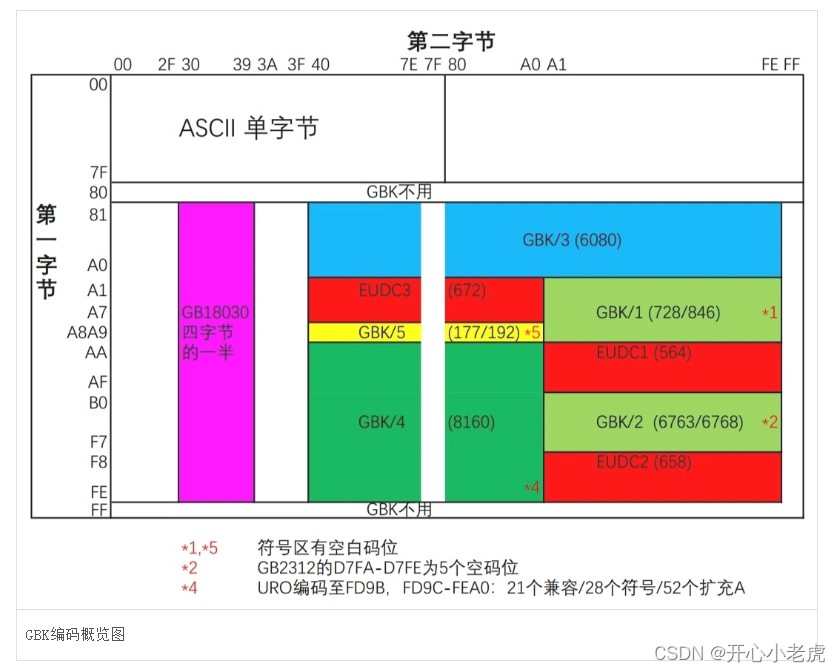
3.GBK编码
GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年10月制定, 1995年12月正式发布,中文版的WIN95、WIN98、WINDOWS NT以及WINDOWS 2000、WINDOWS XP、WIN 7等都支持GBK编码方案。
4.UTF-8编码
UTF-8是一种变长字节表示的Unicode字符编码,它使用1到4个字节来表示Unicode字符。以下是UTF-8编码的一些关键特点:
- 对于基本ASCII字符(码点从U+0000到U+007F),UTF-8编码与ASCII编码兼容,每个字符使用1个字节表示。
- 对于拉丁文、希腊文、等带有变音符号的字符(码点从U+0080到U+07FF),UTF-8编码使用2个字节表示。
- 对于其他语言的字符,包括中日韩文字等(码点超过U+07FF),UTF-8编码使用3个字节表示。
- 对于一些极少使用的语言字符,UTF-8编码使用4个字节表示。
UTF-8编码的规则相对简单,通过查看字节的最高位,可以确定字符的编码长度。例如,如果字节的最高位是0,则该字符使用1个字节;如果最高位是110,则使用2个字节;如果最高位是1110,则使用3个字节;如果最高位是11110,则使用4个字节。这种变长编码方式使得UTF-8能够高效地表示Unicode字符集,同时保持与ASCII编码的兼容性。
Unicode,统一码也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
二、URL转码
URL转码是将字符串转换为适合在URL中传输的形式的过程,它涉及到将某些特殊字符转换为对应的编码形式,以确保URL的正确解析和传输。有些符号在URL中是不能直接传递的,如果要在URL中传递这些特殊符号,那么就要使用他们的编码了。

前端URL转码使用方式:
1.encodeURI和decodeURI
let url = 'http://127.0.0.1:8080/userInfo?age=5000&name=孙悟空';
//转码,进行传输
let currentUrl = encodeURI(url);
console.log(currentUrl);
//解码,获得原链接
let thisUrl = encodeURI(currentUrl)
console.log(thisUrl );encodeURI也是有局限的,它有一些常见的字符还是无法做到有效转码。使用了encodeURI转码,而&这类字符没有有效转码,没有达到我们想要的效果。
2.encodeURIComponent 和 decodeURIComponent
encodeURIComponent ,它可以将; / ? : @ & = + $ , #等这类特殊字符进行转码。所以用这种方式。
let url = 'http://127.0.0.1:8080/userInfo?age=5000&name=孙悟空';
//转码,进行传输
let currentUrl = encodeURIComponent(url);
console.log(currentUrl);
//解码,获得原链接
let thisUrl = decodeURIComponent(currentUrl)
console.log(thisUrl );三、Base64
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法,那么Base64是一种最常见的二进制编码方法。
Base64 常用于表示、传输、存储二进制数据,也可以用于将一些含有特殊字符的文本内容编码,以便传输。
标准 Base64 里的 64 个可打印字符是 A-Za-z0-9+/,分别依次对应索引值 0-63。

编码流程: 先对图片进行 utf-8 编码 生成 二进制,然后 base64 再对 二进制进行编码,生成 base64 字符串。
解码流程: 先对 base64字符串 解码 生成 二进制,然后使用 utf-8 解码生成图片。
前端使用方式:
首先npm下载:
npm i js-base64代码中引入使用:
import { Base64 } from "js-base64";
let url = 'http://127.0.0.1:8080/userInfo?age=5000&name=孙悟空';
//编码
let currentUrl = Base64.encode(url);
console.log(currentUrl)
//解码
let thisUrl = Base64.decode(currentUrl);
console.log(thisUrl)