揭秘高效存储模型与数据结构底层实现
- 【专栏简介】
- 【技术大纲】
- 【专栏目标】
- 【目标人群】
- 1. Redis爱好者与社区成员
- 2. 后端开发和系统架构师
- 3. 计算机专业的本科生及研究生
- SDS(简单动态字符串)
- C字符串
- C字符串存在的问题
- 字符串存储局限性
- 不存储字符串长度信息
- 操作C字符串的时间复杂度
- 案例说明
- 引发的性能瓶颈
- 出现缓冲区溢出问题
- strcat拼接引发缓冲区溢出
- SDS的优势特点
- **节省数据内存分配**
- **解决终止符的问题**
- **内存溢出控制**
- sdscat拼接案例分析
- **提升操作效率**
- 原理剖析
- 数据结构
- 分析结构体
- `sdshdr5`(没有使用)
- `sdshdr8`、`sdshdr16`、`sdshdr32`和`sdshdr64`
- 特点分析
- 空字符结尾优点
- 特性对比
- 数据长度分析
- 分析代码
- 计算剩余容量
- sds.h的源码预览
【专栏简介】
随着数据需求的迅猛增长,持久化和数据查询技术的重要性日益凸显。关系型数据库已不再是唯一选择,数据的处理方式正变得日益多样化。在众多新兴的解决方案与工具中,Redis凭借其独特的优势脱颖而出。
【技术大纲】
为何Redis备受瞩目?原因在于其学习曲线平缓,短时间内便能对Redis有初步了解。同时,Redis在处理特定问题时展现出卓越的通用性,专注于其擅长的领域。深入了解Redis后,您将能够明确哪些任务适合由Redis承担,哪些则不适宜。这一经验对开发人员来说是一笔宝贵的财富。

在这个专栏中,我们将专注于Redis的6.2版本进行深入分析和介绍。Redis 6.2不仅是我个人特别偏爱的一个版本,而且在实际应用中也被广泛认为是稳定性和性能表现都相当出色的版本。
【专栏目标】
本专栏深入浅出地传授Redis的基础知识,旨在助力读者掌握其核心概念与技能。深入剖析了Redis的大多数功能以及全部多机功能的实现原理,详细展示了这些功能的核心数据结构和关键算法思想。读者将能够快速且有效地理解Redis的内部构造和运作机制,这些知识将助力读者更好地运用Redis,提升其使用效率。
将聚焦于Redis的五大数据结构,深入剖析各种数据建模方法,并分享关键的管理细节与调试技巧。
【目标人群】
Redis技术进阶之路专栏:目标人群与受众对象,对于希望深入了解Redis实现原理底层细节的人群。
1. Redis爱好者与社区成员
Redis技术有浓厚兴趣,经常参与社区讨论,希望深入研究Redis内部机制、性能优化和扩展性的读者。
2. 后端开发和系统架构师
在日常工作中经常使用Redis作为数据存储和缓存工具,他们在项目中需要利用Redis进行数据存储、缓存、消息队列等操作时,此专栏将为他们提供有力的技术支撑。
3. 计算机专业的本科生及研究生
对于学习计算机科学、软件工程、数据分析等相关专业的在校学生,以及对Redis技术感兴趣的教育工作者,此专栏可以作为他们的学习资料和教学参考。
无论是初学者还是资深专家,无论是从业者还是学生,只要对Redis技术感兴趣并希望深入了解其原理和实践,都是此专栏的目标人群和受众对象。
让我们携手踏上学习Redis的旅程,探索其无尽的可能性!
SDS(简单动态字符串)
Redis没有采纳C语言传统的字符串表示方式,而是选择了一种独特而高效的方法,构建了一个名为简单动态字符串的抽象类型,并将其确立为自己的默认字符串实现。再深入分析SDS核心结构以及原理之前,我们认识一下C语言的字符串,分析一下为什么Redis不采用它?
C字符串
在C语言中,字符串的实现通常依赖于函数的形式。开发者可以使用char*字符数组来表示和操作字符串。为了简化字符串处理任务,C语言标准库提供了string.h头文件,其中定义了一系列字符串操作函数,如字符串连接、比较、查找、复制等。
C字符串存在的问题
字符串存储局限性
C语言使用长度为N+1的字符数组来存储长度为N的字符串。这种设计是为了确保字符串的最后一个元素始终是一个空字符(‘\0’),即ASCII码值为0的字符。它不仅是字符串结束的标记,还确保了字符串操作的安全性,防止了诸如越界访问等潜在问题,如下图所示:

由于C字符串的字符必须遵循特定的编码标准,如ASCII,并且在其内部结构中,除了字符串的自然终止点外,不允许出现空字符。这是因为C字符串的长度是通过遍历字符直至遇到空字符来确定的,如果在字符串中间出现空字符,程序会错误地将其当作字符串的结束,从而截断后续的数据。这一限制使得C字符串只能用来存储纯文本数据,而无法有效地处理二进制数据,如图片、音频、视频或压缩文件等。
不存储字符串长度信息
C语言中的字符串不直接存储其长度信息,要获取一个C字符串的长度,程序必须通过遍历整个字符串来逐一计数其中的字符。这个过程涉及从字符串的起始位置开始,逐个检查每个字符,直到遇到表示字符串终止的空字符(‘\0’)为止。
操作C字符串的时间复杂度
- 使用
char*来操作字符串时,获取字符串长度的操作通常需要遍历整个字符串,因此其时间复杂度为O(N),其中N表示字符串的长度。 - 当需要在字符串末尾追加内容时,也需要遍历整个字符串以找到其末尾位置,这个操作的时间复杂度也是O(N)。
案例说明
我们使用一个案例分析一下计算C字符串长度时的处理过程。传统上,C字符串的长度需要通过遍历整个字符串来逐个字符计数,直到遇到空字符作为字符串结束的标记。
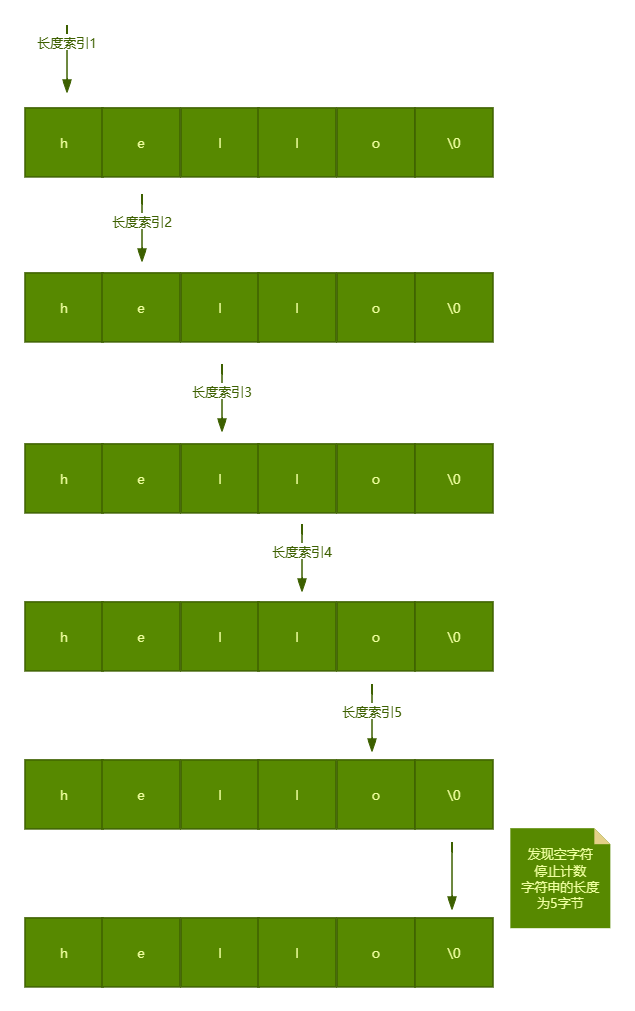
上图展示了C语言程序在计算字符串长度时的处理过程。传统上,C字符串的长度需要通过遍历整个字符串来逐个字符计数。
引发的性能瓶颈
由于每个字符都需要被检查一次,这个操作的复杂度为O(n),其中n是字符串的长度。这意味着,随着字符串长度的增加,计算长度所需的时间也线性增长。因此,对于较长的字符串,这种计算方式可能会成为性能瓶颈,需要开发者在算法设计和性能优化时予以考虑。
出现缓冲区溢出问题
除了其获取字符串长度的复杂度较高之外,C字符串不记录自身长度还带来了一个关键的问题,即容易导致缓冲区溢出(buffer overflow)。缓冲区溢出是一种常见的安全漏洞,它发生在当程序试图将数据写入一个固定大小的缓冲区,而该数据的大小超过了缓冲区所能容纳的界限时。
strcat拼接引发缓冲区溢出
C标准库中的strcat函数为例,该函数用于将src字符串的内容拼接到dest字符串的末尾。如果dest字符串的缓冲区没有足够的空间来容纳src字符串的内容,就会发生缓冲区溢出。这种溢出可能导致程序崩溃,更糟糕的是,它还可能被恶意利用来执行任意代码,从而构成严重的安全威胁。
char *strcat (char dest,const char *src);
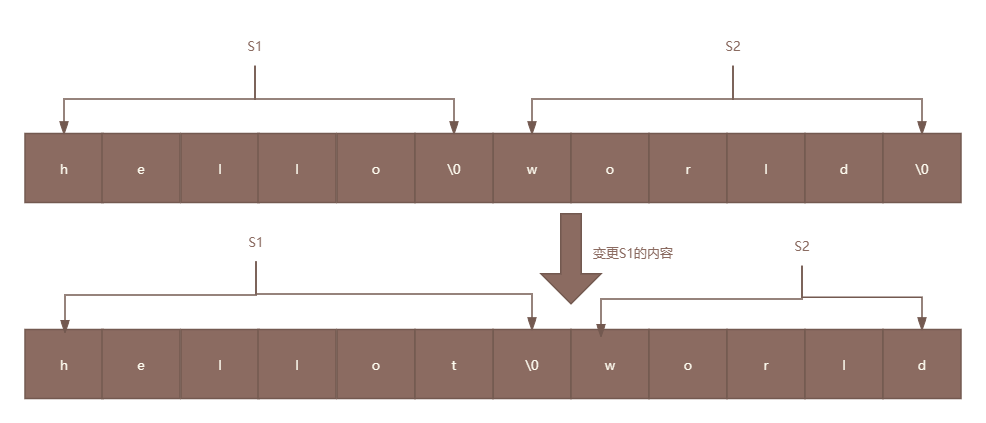
考虑一个场景,在程序中存在两个紧密相邻的C字符串s1和s2,分别存储了字符串"hello"和"world",如下图所示。

在这个例子中,s1和s2在内存中紧密相连,这意味着它们的结束空字符(‘\0’)后直接跟随的是下一个字符串的开始。在这种情况下,如果没有明确的分隔标识(如空字符),程序可能会错误地将s1和s2视为一个连续的字符串,从而导致逻辑错误或意外的行为。
如果一个程序员决定通过执行以下代码:
strcat(s1, "t");
来将字符串 “t” 追加到已存在的 C 字符串 s1 的末尾,那么这里存在几个潜在的问题和风险。
因为strcat 函数不会自动检查 s1 是否有足够的空间来容纳新添加的字符串 “t”。如果 s1 的缓冲区没有足够的空间来容纳原始字符串和追加的字符串,就会发生缓冲区溢出到s2的缓冲空间中,导致s2保存的内容被意外地修改,如下图所示:
SDS的优势特点
节省数据内存分配
SDS的设计,使得Redis在处理字符串时,能够更加灵活和高效。与传统的C字符串相比,SDS提供了动态调整大小的功能,省去了频繁的内存分配和复制操作,从而显著提升了性能。
解决终止符的问题
C语言中字符串是通过char*类型的字符数组来表示的,这些数组以空字符(‘\0’)作为字符串的终止符。如果字符串中间包含空字符,它将被错误地解释为字符串的结束,从而导致字符串无法被正确表示。
#include "stdio.h"
#include "string.h"
int main(void) {
char *t1 = "hello\0world";
char *t2 = "helloworld\0";
printf("%lu\n", strlen(t1));
printf("%lu\n", strlen(t2));
}
输出结果是 5 和 10。
其中底层的字符存储模式如下所示:

为了确保Redis能够灵活适应各种不同的使用场景,SDS被设计为二进制安全的。所有的SDS API在处理存储在buf数组中的数据时,都会以二进制的方式进行处理。程序不会对这些数据施加任何限制、过滤或假设,确保数据在写入时和读取时保持一致。
这也是为什么SDS的buf属性称为字节数组的原因,因为Redis并不是使用这个数组来保存字符,而是用它来保存一系列原始的二进制数据。这种设计使得SDS能够轻松应对各种复杂的数据格式,包括那些使用特殊字符或编码的数据。
内存溢出控制
C语言的字符串是静态分配的,当追加的内容导致字符串长度超过原分配的空间时,就可能发生溢出错误或无法追加的情况。这是因为SDS在内部维护了字符串的长度信息,并且使用了动态内存分配来管理字符串空间。
sdscat拼接案例分析
SDS的sdscat函数为例,该函数旨在将一个C字符串追加到给定SDS所存储的字符串的末尾。然而,与C标准库中的strcat函数不同,sdscat在执行拼接操作之前,会先对给定SDS的可用空间进行详尽的检查。如果SDS的当前空间不足以容纳即将追加的C字符串,sdscat会智能地扩展SDS的空间,确保有足够的容量来容纳拼接后的新字符串。只有当空间扩展完成后,sdscat才会执行实际的拼接操作。
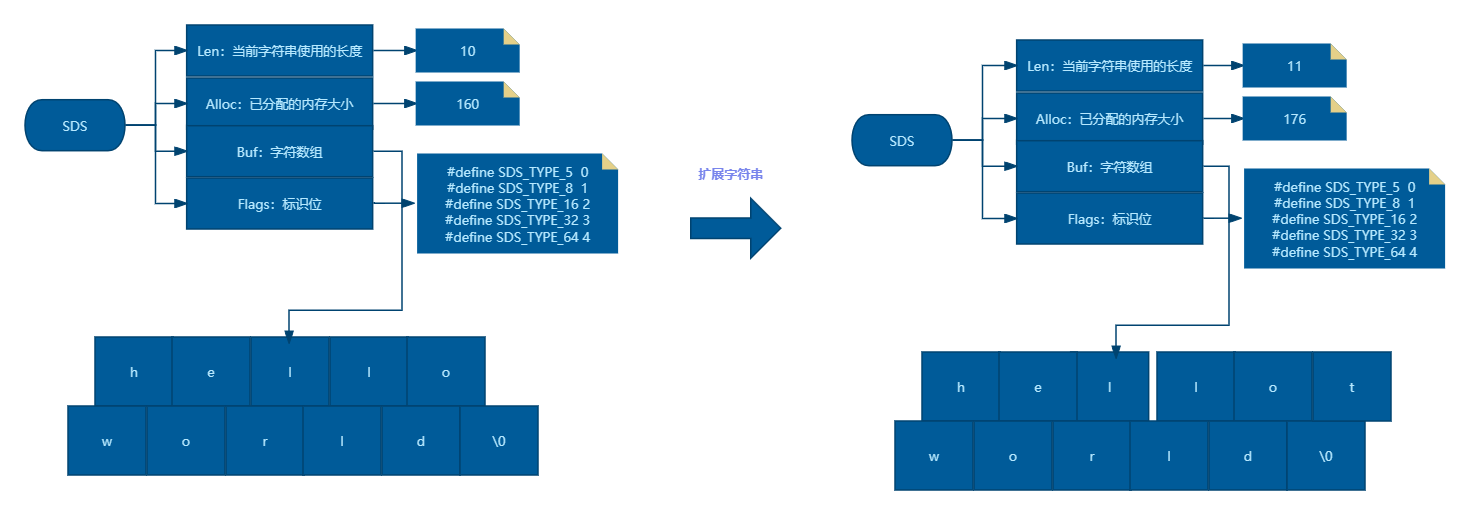
空间分配策略进行了优化,从而彻底消除了缓冲区溢出的风险。当使用SDS API对SDS进行修改时,该API会预先检查SDS当前的空间是否满足修改所需的条件。如果SDS的空间不足以支持所需的修改,API会自动执行空间扩展操作,将SDS的大小调整至足以执行修改所需的大小。只有在确保空间足够后,API才会执行实际的修改操作。
提升操作效率
Redis所采用的简单动态字符串(SDS)则在这些方面进行了优化,SDS不仅能够在O(1)的时间复杂度内获取字符串长度,还能在O(1)的时间复杂度内完成字符串的追加操作。
SDS通过在其内部结构中包含一个len属性来直接记录字符串的长度信息。因此,在SDS中,获取字符串长度的操作不再需要遍历整个字符串,而是直接读取len属性的值,这使得获取SDS长度的复杂度降低到了O(1),即无论SDS的长度如何,获取其长度所需的时间都是恒定的。
因此,可以说SDS是Redis在处理字符串数据时的一项创新举措,它使得Redis能够以更加高效和灵活的方式处理字符串,从而为用户提供了更加稳定和高效的数据存储和访问体验。
原理剖析
简单动态字符串(SDS)是Simple Dynamic String的缩写,它是Redis中用于表示字符串的核心数据结构。在Redis中,几乎所有的键(key)都是通过SDS来实现的,体现了其高效和灵活性。
从源码层面分析,SDS的实现细节主要集中在sds.h和sds.c文件中。其中,sds.h定义了SDS的数据结构和相关操作接口,而sds.c则提供了这些接口的具体实现。此外,sdsalloc.h文件也扮演着重要角色,它负责SDS内存分配和释放的管理,确保SDS在动态扩展和收缩时能够高效、安全地使用内存。
通过深入分析sds.h头文件,我们可以发现Redis源码为char*类型定义了一个别名,如下所示:
#ifndef __SDS_H
#define __SDS_H
#define SDS_MAX_PREALLOC (1024*1024)
extern const char *SDS_NOINIT;
#include <sys/types.h>
#include <stdarg.h>
#include <stdint.h>
typedef char *sds;
这种别名的使用在Redis的源代码中非常普遍,尤其是在处理字符串时。通过将char*重命名为sds,Redis不仅使代码更具可读性,还强调了这些指针实际上是指向动态字符串(SDS)的,而不仅仅是普通的C字符串。
数据结构
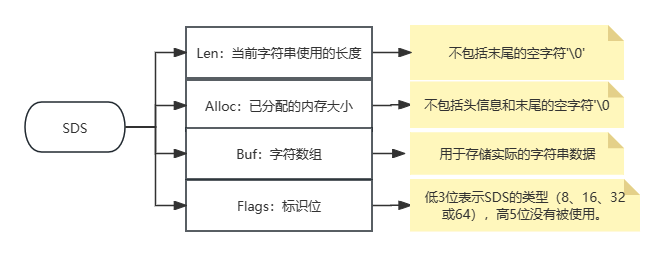
SDS是Redis用来表示字符串的核心数据结构,它提供了一种动态调整字符串长度的方式,同时还包含了一些额外的元数据,如字符串的长度和已分配的内存大小,还有一个名为flags的元数据字段,该字段的最低3位用于标识SDS的类型。
在SDS的设计中,为了节省内存并适应不同大小的字符串,Redis定义了五种不同大小的SDS头结构,分别是sdshdr5、sdshdr8、sdshdr16、sdshdr32和sdshdr64。
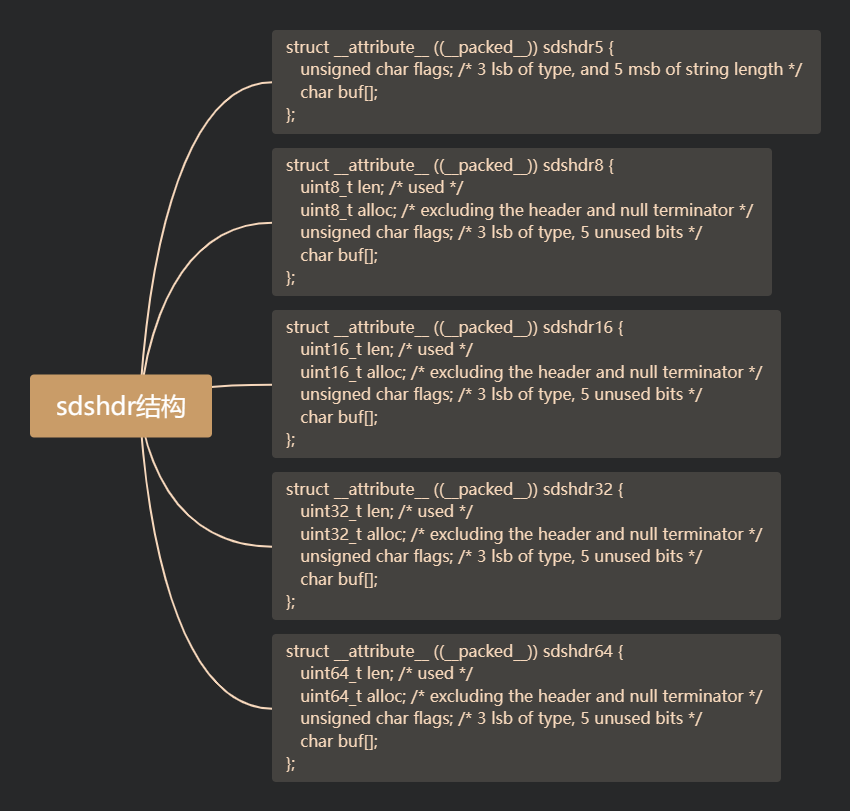
这五种类型的主要区别在于它们如何存储和管理字符数组的两个关键元数据:现有长度(len)和分配空间长度(alloc)。这些元数据的数据类型因SDS类型的不同而有所区别。
以下是sds.h中定义的五种sdshdr结构,它们分别代表了五种不同的SDS数据结构模型:
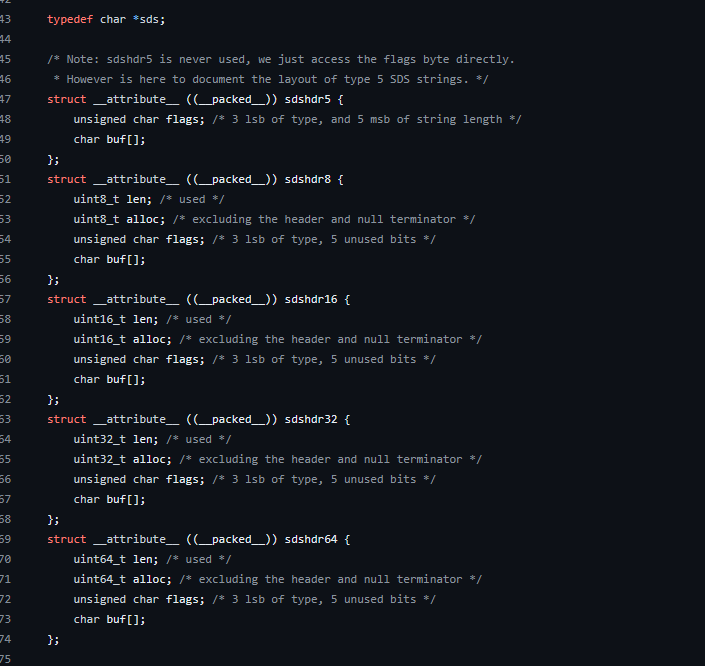
sdshdr8、sdshdr16、sdshdr32和sdshdr64这些头结构的大小分别为5字节、8字节、16字节、32字节和64字节。选择哪种头结构取决于字符串的实际长度和已分配的内存大小。
__attribute__((__packed__))是一个GCC编译器指令,用于确保结构体在内存中的布局是紧凑的,即没有额外的填充字节。这对于嵌入式系统或需要精确控制内存布局的场景非常有用。
分析结构体
接下来,我们将逐一深入剖析这些结构体。在结构模型的设计中,我们主要将其划分为两大类别:sdshdr5与其他类型。那么,为何要进行这样的分类呢?让我们来一探究竟。
sdshdr5(没有使用)
Redis的源码中并没有使用,因为它只包含一个flags字段和一个Buf字段,没有足够的空间来存储字符串的长度信息。
Flags字段的低3位用于表示SDS的类型(在这个情况下是5),而高5位被浪费了,没有使用。Buf字段是字符数组,用于存储实际的字符串数据。
sdshdr8、sdshdr16、sdshdr32和sdshdr64
sdshdr8、sdshdr16、sdshdr32和sdshdr64这些结构体都包含Len、Alloc、Flags和Buf字段。
Len字段表示当前字符串使用的长度(不包括末尾的空字符’\0’)。Alloc字段表示已分配的内存大小(不包括头信息和末尾的空字符’\0’)。Flags字段的低3位用于表示SDS的类型(8、16、32或64),而高5位没有被使用。Buf字段是字符数组,用于存储实际的字符串数据。
注意,
Len和Alloc字段的大小会根据SDS头结构的大小而变化。在sdshdr8中,这两个字段都是uint8_t类型,而在sdshdr64中,这两个字段都是uint64_t类型。这种设计允许Redis根据字符串的实际大小动态地选择最合适的头结构,从而节省内存。
下面是一个底层存储案例,大家应该可以看到对应的存储模型是什么样子的。

特点分析
-
空字符结尾:SDS遵循C字符串的传统做法,即在字符串末尾添加一个空字符(null terminator),以确保字符串的正确终止。这个空字符所占用的1字节空间并不计算在SDS的
len属性中,这意味着对于SDS的使用者来说,这个空字符是完全不可见的。 -
额外的分配:为了确保空字符的存在,SDS会自动为其分配额外的1字节空间,并在需要时在字符串末尾添加空字符。这些操作都是由SDS函数自动完成的,因此用户无需关心。
-
兼容C方法:SDS可以直接使用C标准库中的
<stdio.h>头文件所提供的printf函数来展示其内部保存的字符串内容。录例如,通过执行printf("%s", s->buf);语句,可以方便地打印出SDS结构体中buf指针所指向的字符数组。
空字符结尾优点
- SDS能够直接重用C标准库中的一部分字符串函数,从而提高了代码的复用性和可维护性。
- 空字符的存在也有助于确保字符串的正确性和安全性,防止了越界访问等潜在问题。
特性对比
| 特征 | C字符串 | SDS |
|---|---|---|
| 获取字符串长度的复杂度 | O(n) | O(1) |
| API安全性 | 不安全,可能会造成缓冲区溢出 | 安全,不会造成缓冲区溢出 |
| 内存重分配 | 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 数据类型 | 只能保存文本数据 | 可以保存文本或者二进制数据 |
| 使用的库函数 | 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
数据长度分析
sdslen 函数通过解析 SDS 字符串的标志位和头结构来获取字符串的长度,并根据字符串的类型选择相应的计算方式。这种设计允许 Redis 使用不同大小的头结构来存储不同长度的字符串,从而节省内存空间。
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
这段代码是 Redis 中用于获取 SDS(Simple Dynamic String,简单动态字符串)长度的函数 sdslen 的实现。SDS 是 Redis 用于表示字符串的内部数据结构,它包含了一个长度字段和一个预分配的空间字段,以便在需要时能够快速地扩展或收缩字符串。
分析代码
- 方法参数以及返回值
size_t:这是函数的返回类型,表示字符串的长度。const sds s:这是函数的参数,s是一个指向 SDS 字符串的指针。
- 获取标志位:
unsigned char flags = s[-1];* 这行代码从 SDS 字符串的末尾获取标志位。因为 SDS 字符串的实际数据存储在头结构之后,所以通过s[-1]可以访问到存储标志位的字节。

- 判断 SDS 类型并返回长度:
switch(flags&SDS_TYPE_MASK)*使用了一个位掩码SDS_TYPE_MASK来提取标志位中的 SDS 类型信息。SDS_TYPE_MASK的值通常是一个只有低三位设置为 1 的值(例如0x07),这样可以将标志位中的类型字段提取出来。switch语句根据提取出来的类型字段的值来选择相应的代码分支,每个分支都返回相应类型 SDS 字符串的长度。case SDS_TYPE_5:如果 SDS 类型是 5,则使用SDS_TYPE_5_LEN(Flags)来计算字符串的长度。这个宏通常会从标志位中提取出长度信息。case SDS_TYPE_8、case SDS_TYPE_16、case SDS_TYPE_32、case SDS_TYPE_64:对于其他类型的 SDS 字符串,通过调用SDS_HDR(size, s)宏来获取头结构的指针,然后返回头结构中的len字段的值,即字符串的实际长度。
- 默认返回值:
return 0;* 如果switch语句中没有匹配到任何类型,函数将返回 0。这通常表示输入的s不是一个有效的 SDS 字符串,或者它的类型字段的值不正确。
计算剩余容量
sdsavail 函数用于快速获取 SDS 字符串的剩余容量。该函数的实现基于 SDS 字符串的 alloc(总容量)和 len(已使用长度)字段。通过简单的数学运算 alloc - len,即可得到剩余容量。这种计算方式的时间复杂度为 O(1),意味着无论 SDS 字符串的长度如何,获取剩余容量的操作都是常数时间复杂度的,因此非常高效。
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
简而言之,sdsavail 函数提供了一种快速、简便的方法来查询 SDS 字符串当前剩余的可用空间,这对于需要动态调整字符串大小的应用来说非常有用。
至此,还有还有很多关于SDS源码的其他内容,由于篇幅过长,再次就不过多介绍,本次我们主要是将核心SDS的核心特细和原理以及结构,以及基本的核心方法进行介绍和说明,特别是针对于SDS和C字符串的区别和选择的问题,做了较为深入的介绍和分析。
sds.h的源码预览
文章内容的总体技术分析主要源自于深入研究和探索相关源码的过程。通过仔细剖析源码,我们能够更好地理解技术实现原理、架构设计和性能优化等方面。这种分析不仅有助于我们掌握技术的本质,还能为我们在实际开发过程中提供宝贵的参考和启示。
/* SDSLib 2.0 -- A C dynamic strings library
*
* Copyright (c) 2006-2015, Salvatore Sanfilippo <antirez at gmail dot com>
* Copyright (c) 2015, Oran Agra
* Copyright (c) 2015, Redis Labs, Inc
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* * Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of Redis nor the names of its contributors may be used
* to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
* POSSIBILITY OF SUCH DAMAGE.
*/
#ifndef __SDS_H
#define __SDS_H
#define SDS_MAX_PREALLOC (1024*1024)
extern const char *SDS_NOINIT;
#include <sys/types.h>
#include <stdarg.h>
#include <stdint.h>
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}
static inline void sdssetlen(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1;
*fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS);
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len = newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len = newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len = newlen;
break;
}
}
static inline void sdsinclen(sds s, size_t inc) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1;
unsigned char newlen = SDS_TYPE_5_LEN(flags)+inc;
*fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS);
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len += inc;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len += inc;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len += inc;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len += inc;
break;
}
}
/* sdsalloc() = sdsavail() + sdslen() */
static inline size_t sdsalloc(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->alloc;
case SDS_TYPE_16:
return SDS_HDR(16,s)->alloc;
case SDS_TYPE_32:
return SDS_HDR(32,s)->alloc;
case SDS_TYPE_64:
return SDS_HDR(64,s)->alloc;
}
return 0;
}
static inline void sdssetalloc(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
/* Nothing to do, this type has no total allocation info. */
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->alloc = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->alloc = newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->alloc = newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->alloc = newlen;
break;
}
}
sds sdsnewlen(const void *init, size_t initlen);
sds sdstrynewlen(const void *init, size_t initlen);
sds sdsnew(const char *init);
sds sdsempty(void);
sds sdsdup(const sds s);
void sdsfree(sds s);
sds sdsgrowzero(sds s, size_t len);
sds sdscatlen(sds s, const void *t, size_t len);
sds sdscat(sds s, const char *t);
sds sdscatsds(sds s, const sds t);
sds sdscpylen(sds s, const char *t, size_t len);
sds sdscpy(sds s, const char *t);
sds sdscatvprintf(sds s, const char *fmt, va_list ap);
#ifdef __GNUC__
sds sdscatprintf(sds s, const char *fmt, ...)
__attribute__((format(printf, 2, 3)));
#else
sds sdscatprintf(sds s, const char *fmt, ...);
#endif
sds sdscatfmt(sds s, char const *fmt, ...);
sds sdstrim(sds s, const char *cset);
void sdssubstr(sds s, size_t start, size_t len);
void sdsrange(sds s, ssize_t start, ssize_t end);
void sdsupdatelen(sds s);
void sdsclear(sds s);
int sdscmp(const sds s1, const sds s2);
sds *sdssplitlen(const char *s, ssize_t len, const char *sep, int seplen, int *count);
void sdsfreesplitres(sds *tokens, int count);
void sdstolower(sds s);
void sdstoupper(sds s);
sds sdsfromlonglong(long long value);
sds sdscatrepr(sds s, const char *p, size_t len);
sds *sdssplitargs(const char *line, int *argc);
sds sdsmapchars(sds s, const char *from, const char *to, size_t setlen);
sds sdsjoin(char **argv, int argc, char *sep);
sds sdsjoinsds(sds *argv, int argc, const char *sep, size_t seplen);
int sdsneedsrepr(const sds s);
/* Callback for sdstemplate. The function gets called by sdstemplate
* every time a variable needs to be expanded. The variable name is
* provided as variable, and the callback is expected to return a
* substitution value. Returning a NULL indicates an error.
*/
typedef sds (*sdstemplate_callback_t)(const sds variable, void *arg);
sds sdstemplate(const char *template, sdstemplate_callback_t cb_func, void *cb_arg);
/* Low level functions exposed to the user API */
sds sdsMakeRoomFor(sds s, size_t addlen);
sds sdsMakeRoomForNonGreedy(sds s, size_t addlen);
void sdsIncrLen(sds s, ssize_t incr);
sds sdsRemoveFreeSpace(sds s, int would_regrow);
sds sdsResize(sds s, size_t size, int would_regrow);
size_t sdsAllocSize(sds s);
void *sdsAllocPtr(sds s);
/* Export the allocator used by SDS to the program using SDS.
* Sometimes the program SDS is linked to, may use a different set of
* allocators, but may want to allocate or free things that SDS will
* respectively free or allocate. */
void *sds_malloc(size_t size);
void *sds_realloc(void *ptr, size_t size);
void sds_free(void *ptr);
#ifdef REDIS_TEST
int sdsTest(int argc, char *argv[], int flags);
#endif
#endif
总之,文章内容的技术分析主要基于对源码的深入研究和探索。通过这种方法,我们能够更好地理解技术的本质和性能特点,为实际应用提供有力的支持和指导。