论文:CodeS: Towards Building Open-source Language Models for Text-to-SQL
⭐⭐⭐⭐
arXiv:2402.16347, SIGMOD 2024
人大
Code: CodeS | GitHub
一、论文速读
本文提出一个开源的专门用于 Text2SQL 任务的 LLM —— CodeS,有多个参数规模的版本(1B ~ 15B),它是基于 StarCdoer 基座模型,使用 Text2SQL 相关的数据集继续训练得到的。同时,论文提出了在训练这个模型和使用这个模型一些方法。
论文提出的一些 challenges 和解决方案:
- C1:如何让小模型具备复杂的 Text2SQL 推理能力?由于现有的 PLM(如 LLaMA-2)的训练数据中,与 SQL 相关的内容只占预料的很小一部分,这种数据偏差可能会阻碍模型的 SQL 生成能力。因此,本文提出一种增量预训练方法,利用与 Text2SQL 任务相关的数据集来训练。
- C2:如何生成一个好的 prompt 来解决 Schema Link 的困难?本文提出了一系列过滤方法,筛选出只与问题有关的 schema 输送给 LLM。
- C3:如何让 LLM 自适应地迁移到新 domain 的 DB 中?这个问题的主要障碍在于缺乏用于微调的 pairs,因此本文提出了一种双向数据增强技术,在少量人工操作下生成足够的微调数据集。
总的来说,为了解决这三个问题,论文一共引入了三个组件来分别解决:Incremental pre-training(下图 a)、Database prompt construction(下图 b)、New Domain Adaption(下图 c):
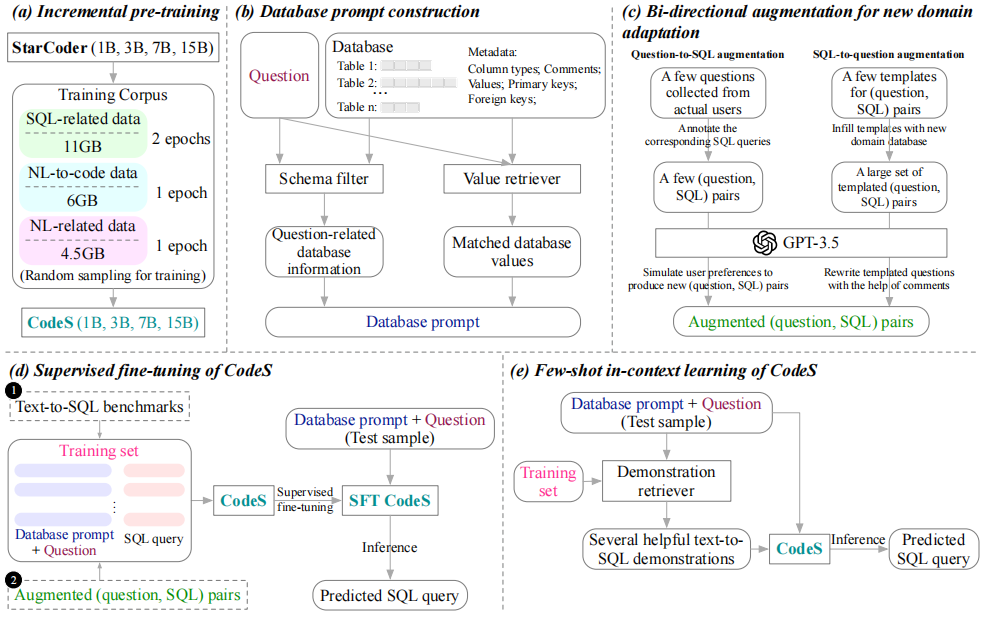
另外,上图的 (d) 和 (e) 展示 CodeS 模型的使用方式。
二、增量预训练(Incremental pre-training)
从 3 个维度来收集用于训练的数据:
- SQL 相关数据:使用了 StarCoder 的与训练语料库种的 SQL 片段
- NL 相关数据:从多个来源收集了 4.5GB 的高质量对话数据
- NL2Code 数据:主要包含如下四类数据:
- CoNaLa、StaQC 包含需要 NL2Python 和 NL2SQL 的 pairs
- CodeAlpaca 包含许多与代码相关的指令遵顼数据
- Jupyter-structured-clean-dedup 是 StarCoder 的预训练语料库的子集
- NL-SQL-458K 是本文精心制作的一个数据集,包含大量的 NL-SQL pairs
使用上面数据,对 StarCoder 进行增量预训练:对 SQL 相关数据做 2 个 epoch 的训练,对 NL 相关和 NL2Code 相关数据做 1 个 epoch 的训练。
训练的思路就是给定一个 sequence,让 LLM 能够最大化整个 sequence 的 likelihood,这可以通过计算每个 token 的条件概率的乘积来实现:
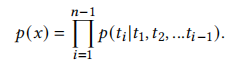
三、Database prompt construction
高质量的 prompt 能够为 LM 提供有价值的见解,从而提高 LLM 的表现。为了构造一个好的 prompt,这里主要采用了两个关键策略:schema filter 和 value retriever。
3.1 Schema Filter
由于 LLM 的 context window 装不下整个 DB 的 schema 信息,因此有必要过滤出有用的 schema。Schema Filter 的作用就是为一个 question 筛选出最相关的 tables 和 columns。
筛选的方法是:计算每个 column 与 question 的相关性分数,然后基于这些分数来选出 Top-K1 的 tables,然后对这些 tables 的每一个选出其中 Top-K2 的 columns。
3.2 Value Retriever
Value retriver 用于从 DB 中检索出与 question 相关的 cell values 并用于执行 schema linking。
这里使用了”由粗到细“的匹配方法:先使用 BM25 索引来快速粗粒度的初始搜索,然后使用 LCS 进行细粒度匹配。这种方式极大减少了 LCS 调用次数,提高了检索速度。
3.3 DB metadata
DB 有 4 类 metadata 也对于构建 prompt 很有用:
- Column Data Types:列的数据类型限制了它允许的操作
- Comments:能够有效解决一些 column 的命名会让人产生歧义的问题
- Representative DB values:每一列中选出一些有代表的 cell values 是很有用的
- Primary and Foreign Keys:在实践中,使用唯一标识符来表示主键,为每个外键表示为
{T1}.{COL1} = {T2}.{COL2}的形式来构建 prompt
3.4 prompt 构建
有了上面的方案,我们可以得到如下用于构建 prompt 的信息:

有了这些信息,就可以构建出一个 prompt 来让 LLM 根据 question 生成 SQL 了。
四、New Domain Adaption
现实场景下,我们会面临各种 domain 的数据库,为了做适应性微调,这里提出了一个双向数据增强技术,以较小的注释成本来自动生成大量可靠且通用的 question-SQL pairs。
4.1 Question -> SQL 增强
这部分 augmentation 是寻找与人类偏好一致的 question-sql pairs。具体来说,就是先从用户那里收集一些真实的、有代表性的 NL question,然后再手动注释对应的 SQL,从而获得一些高质量的 pairs。
上面得到的 pairs 还是不足以微调的。进一步引入了一个 two-stage 的 prompting 方法:
- 先 prompt GPT3.5 来生成潜在的问题,然后从真实问题中吸取灵感、有效捕捉用户意图
- 再让 GPT3.5 为这些问题合成对应的 SQL 查询
4.2 SQL -> Question 增强
使用一组通用 template 来生成通用的 pairs,这里使用的是 Spider 的常见 SQL template,比如 返回 {TABLE} 的最低 {COLUMN},以及对应的 SQL template SELECT {COLUMN} FROM {TABLE} GROUP BY {COLUMN} ORDER BY COUNT(*) ASC LIMIT 1。
这些生成的 question 可能看起来有点死板,因此可以使用 GPT3.5 对它们进行重新表述。
五、CodeS 的使用
有两种使用方式:监督微调 or few-shot ICL。
5.1 监督微调
使用我们在 New Domain Adaption 得到的 domain-specific 数据,利用 DB prompt + question 就可以对 CodeS 做 SFT 了。
微调之后,就可以使用这个 LLM 输入 DB prompt + NL 来输出 SQL 了。
5.2 Few-shot ICL
为了让 ICL 效果更好,这里使用一个 retriever 从 dataset 中检索出有价值的 K 个 demonstrations 来做 ICL。
最基本的方法是,根据 question 的 semantic similarity 来做检索,但这会有一个问题:检索时会过于重视 question 中的 entities。但我们的想法是,demonstrations 应该更偏向翻译问题的 pattern。比如对于问题 ”1949 年出生的歌手中谁唱了最多的歌曲“,retriever 可能会检索出很多关于歌手或者歌曲的数据。
为了避免过度强调 entities,这里掩盖掉 question 中的 entities,使其专注于 question 的核心结构。
具体来说,这里使用 NLTK 工具来删除 question 中识别到的实体,并使用 SimCSE 来评估句子相似度。称这里提出的检索方法为 question-pattern-aware demonstration retriever。
六、实验
6.1 延迟和部署要求
CodeS 可以进行私有化部署,之前的 DIN-SQL + GPT4 在 Spider 数据集上平均每个 sample 花费 60s,但是本文的 1B、3B、7B 和 15B 的版本的 inference 时间分别为 0.6s、0.9s、1.1s 和 1.5s。
另外,CodeS 还很适合实际部署,当以 Float16 精度操作时,这些变体分别需要 10G、13G、20G 和 35G 的 GPU 内存容量。
这样,我们就可以在本地机器上部署 CodeS,而不需要昂贵的 GPT-4 API。
6.2 其他的实验
具体参考原论文。包括微调的评估、ICL 的评估和消融实验。
七、总结
这篇论文开源了一个很不错的 Text2SQL 领域的 LLM,并同时开放了相关的新的数据集,在实际部署时,无论是基于 CodeS 还是另外再微调,这篇论文的思路都值得参考。