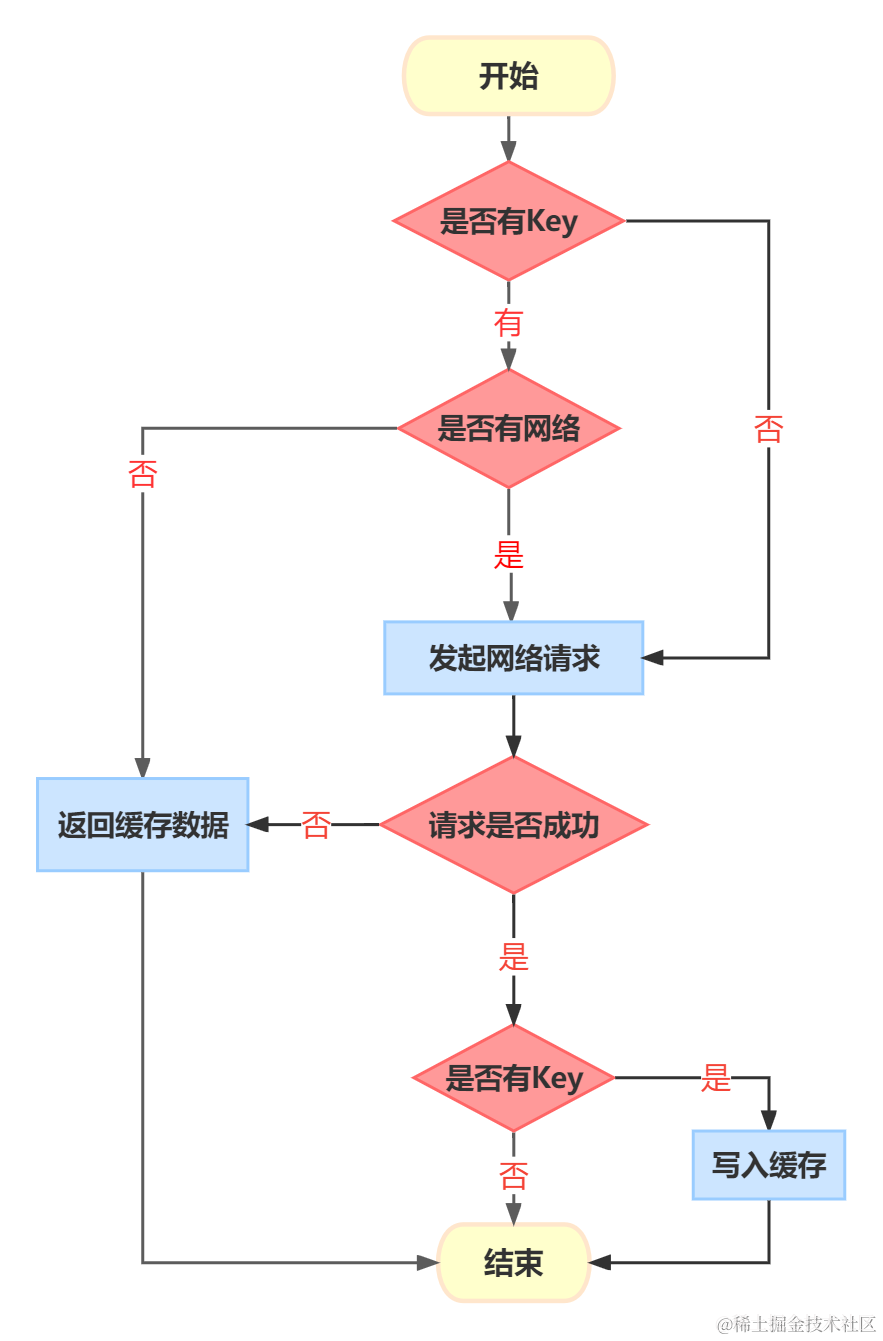
TF-IDF算法
- 一、简介
- 二、TF-IDF算法原理
- 2.1 词频(TF)
- 2.2 逆文档频率(IDF)
- 2.3 TF-IDF的计算
- 三、TF-IDF算法应用
- 3.1 搜索引擎
- 3.2 文本分类
- 3.3 信息提取
- 3.4 文本摘要
- 四、TF-IDF算法的改进
- 4.1、TF-IDF算法的改进
- 4.1.1. 基于词的权重调整
- 4.1.2. 平滑处理
- 4.1.3. 结合词义
- 4.1.4. 文档长度归一化
- 4.1.5. 基于信息论的改进
- 4.1.6. 结合机器学习方法
- 五、总结
一、简介

TF-IDF(Term Frequency-Inverse Document Frequency)算法是文本处理领域中一种常用的信息检索和自然语言处理算法。该算法通过计算文档中词语的重要性来实现文本的特征提取和关键信息抽取,被广泛应用于文本分类、信息检索、关键词抽取等领域。本章将介绍TF-IDF算法的基本思想、原理以及应用场景。
TF-IDF算法最初作为信息检索领域的一种关键技术而被引入,其本质是一种统计方法,能够评估一个词对于一个文档集或者一个语料库中的一个文档的重要性。TF-IDF算法中的TF部分(词频)衡量了一个词在一个文档中出现的频率,而IDF部分(逆文档频率)衡量了一个词在整个语料库中的普遍重要性。通过将这两部分相乘,就可以得到词语在文档中的重要程度。
TF-IDF算法在文本处理领域发挥着重要作用。它可以用于计算文档之间的相似度,从而实现信息检索和相关文档的排序;在文本分类中,TF-IDF算法可以将文档转换成特征向量,进而用于机器学习模型的训练和分类;此外,TF-IDF算法也被广泛应用于关键词抽取,帮助用户快速理解文档的主旨和要点。
随着数据量的不断增大和信息处理的需求不断提升,TF-IDF算法也在不断演进。人们提出了各种改进的方式,比如基于BM25的改进方法、加权TF-IDF算法等,以适应不同的场景和取得更好的效果。
二、TF-IDF算法原理
TF-IDF算法是一种用于信息检索与文本挖掘的常见算法,其基本原理是通过统计词语在文档中的重要性来实现文本特征提取和关键信息抽取。TF-IDF由两部分组成:TF(Term Frequency,词频)和IDF(Inverse Document Frequency,逆文档频率)。
2.1 词频(TF)
TF指的是某个词在文档中出现的频率,计算公式如下:
[
TF(t,d) = \frac{词t在文档d中出现的次数}{文档d中所有词的数量}
]
其中,t代表词语,d代表文档。TF表示了词语在文档中的重要程度,如果一个词在文档中出现的次数越多,那么其重要性也就越大。
2.2 逆文档频率(IDF)
IDF用于衡量一个词对于整个语料库中的文档的重要性,计算公式如下:
[
IDF(t) = \log\left(\frac{语料库中的文档总数}{包含词t的文档数+1}\right)
]
其中,t代表词语。IDF表示了词语在语料库中的普遍重要性,如果一个词在很多文档中出现,那么其重要性就会降低。
2.3 TF-IDF的计算
将词频TF和逆文档频率IDF相乘,即可得到词语在文档中的重要程度:
[
TF-IDF(t, d) = TF(t, d) \times IDF(t)
]
通过TF-IDF算法,可以得到每个词在当前文档中的重要程度,进而实现对文本特征的提取和关键信息的抽取。
三、TF-IDF算法应用
本章讨论TF-IDF算法在文本处理中的应用,包括文本分类、信息检索和关键词抽取等方面。详细说明每个应用场景中如何使用TF-IDF算法进行文本处理和相关的实现细节。
3.1 搜索引擎
TF-IDF算法在搜索引擎中扮演着重要的角色,它用来计算搜索查询词与文档之间的相关性,并根据相关性对搜索结果进行排序。搜索引擎使用TF-IDF算法来解决用户检索时的关键问题:根据查询词来返回最相关的文档。
首先,在用户输入查询词后,搜索引擎会对每个文档中的词计算TF-IDF值。然后,通过计算查询词和文档中词的相似程度(即TF-IDF值的加权总和),搜索引擎可以确定每篇文档的相关性。相关性越高的文档将会排在搜索结果的前面,使用户更容易找到所需的信息。
TF-IDF算法的应用不仅限于文档的相关性排序,它还可以用于建立搜索引擎的索引,帮助搜索引擎快速地定位文档并提高搜索效率。通过计算文档中各个词的TF-IDF值,搜索引擎可以建立索引,从而提高搜索速度和准确性。
总之,TF-IDF算法在搜索引擎中的应用是多方面的,它不仅用于计算文档的相关性并排序搜索结果,还用于构建搜索索引以提高搜索效率。
通过 TF-IDF 算法,搜索引擎能够更好地理解查询词与文档的相关性,从而提高搜索结果的质量和用户体验。
3.2 文本分类
文本分类是将文本按照一定的标准划分到不同的类别中的任务。在文本分类中,TF-IDF算法被广泛用于提取文本的特征,并帮助分类器进行分类决策。
首先,TF-IDF算法可以对文本进行特征提取。对于给定的一篇文本,TF-IDF算法能够计算出文本中每个词的TF-IDF值。这些TF-IDF值构成了文本的特征向量,反映了文本中各个词的重要程度。较高的TF-IDF值意味着某个词对于区分该文本与其他文本的作用更大。
其次,通过特征向量的表示,TF-IDF算法可以为分类器提供输入。分类器可以使用这些特征向量对文本进行分类,并将其归入相应的类别。根据TF-IDF算法提取的特征,分类器可以学习到每个类别的典型特征,从而在遇到新的文本时能够准确地进行分类。
此外,TF-IDF算法还可以结合其他机器学习算法进行文本分类。例如,可以使用支持向量机(Support Vector Machines)或朴素贝叶斯分类器(Naive Bayes Classifier)等算法来构建文本分类模型。TF-IDF算法可以提取文本的特征向量,而分类器可以使用这些特征向量进行训练和预测。
TF-IDF算法在文本分类中的应用不仅仅局限于单个词的特征提取,还可以进行多词组合的特征提取。例如,可以使用n-gram模型来捕捉多个连续单词的信息,从而更好地表示文本的特征。
总结来说,TF-IDF算法在文本分类中的应用是帮助提取文本的重要特征并构建特征向量,从而帮助分类器准确分类文本。它为文本分类任务提供了一种有效的特征提取方法,并在实际应用中取得了良好的效果。
3.3 信息提取
在信息提取领域,TF-IDF算法可以用于抽取文本中的关键词或短语。通过计算每个词项的TF-IDF得分,可以识别出文本中的关键信息,并帮助用户快速获取文档的要点。
3.4 文本摘要
TF-IDF算法也可以应用于自动文本摘要的领域。通过计算文档中各个词项的重要性(TF-IDF得分),可以选择最具代表性的词项作为文档摘要的内容,从而实现自动化的文档摘要生成。
四、TF-IDF算法的改进
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用算法,它衡量了一个词对于一个文档集或语料库中的某一篇文档的重要性。TF-IDF算法的核心思想是:如果一个词在某篇文档中出现频率较高,并且在整个文档集中出现频率较低,那么这个词很可能对这篇文档具有较高的区分能力和重要性。然而,TF-IDF算法也存在一些问题和局限性,因此研究者们提出了许多改进版本来进一步提高其性能和适用性。
4.1、TF-IDF算法的改进
4.1.1. 基于词的权重调整
- 加权词频TF算法:除了简单的词频(Term Frequency)外,一些改进版本考虑了词频的加权因素,比如使用对数加权或词频归一化等方法来调整词的重要性。
- 位置加权算法:考虑词在文档中的位置分布,使得靠近文档开始的词对文档主题的贡献更大,同时也可以减少常见词对于文档主题的影响。
4.1.2. 平滑处理
- 平滑TF-IDF算法:为了避免某些词在文档中未出现而导致TF或IDF为0的情况,一些算法引入了平滑处理,如拉普拉斯平滑或Lidstone平滑等,以提高算法的稳定性和鲁棒性。
4.1.3. 结合词义
- 使用Word2Vec嵌入:将词转换为向量表示,并结合向量相似度来度量词之间的相关性,从而更准确地衡量词的重要性。
- 主题建模算法:结合主题建模方法,如LSA(Latent Semantic Analysis)或LDA(Latent Dirichlet Allocation),来捕捉词语之间的语义关联,进一步优化TF-IDF算法的表现。
4.1.4. 文档长度归一化
- 归一化TF算法:考虑文档长度对TF值的影响,通过将TF值除以文档长度来进行归一化,以避免文档长度对TF值的偏差影响。
4.1.5. 基于信息论的改进
- 基于互信息的算法:利用互信息等信息论方法来衡量词语之间的关联度,从而更精确地计算TF-IDF值。
4.1.6. 结合机器学习方法
- 基于监督学习的模型:结合有监督学习的方法,如逻辑回归、SVM等,通过训练模型来学习词和文档之间的关系,以获得更准确的TF-IDF值。
这些改进版本的TF-IDF算法可以显著提高其在文本挖掘、信息检索等领域的性能和效果,使得其更加适用于实际应用场景,并且在文本特征提取、文本相似度计算等任务中发挥了重要作用。随着对TF-IDF算法的不断改进和优化,相信它将在文本挖掘领域继续发挥重要作用。
五、总结
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取和权重计算方法,用于衡量某个词语对于一个文档集合的重要程度。以下是对TF-IDF算法的总结:
TF-IDF算法的核心思想是将一个词语的重要性权重与它在文档中的出现频率(Term Frequency)和在整个文档集合中的逆文档频率(Inverse Document Frequency)相结合。
首先,计算词语的词频(TF),即一个词语在一个文档中出现的次数。词频是衡量一个词语在单个文档中的重要性的一种方法。如果一个词语在文档中出现频率较高,则可以认为它对于该文档的内容更加重要。
其次,计算逆文档频率(IDF)。逆文档频率是衡量一个词语在整个文档集合中的重要性的一种方法。如果一个词语在整个文档集合中出现频率较低,则可以认为它对于区分和描述该文档集合的特征更加重要。
通过将词频和逆文档频率相乘,可以得到一个词语的TF-IDF权重。TF-IDF权重高的词语在文档中频繁出现,并在整个文档集合中相对较少出现。因此,TF-IDF可以用于提取文本中的关键词和主题,并衡量它们对于文档的重要性。
TF-IDF算法的应用非常广泛。它在信息检索、文本分类、文本聚类、自然语言处理等领域都有重要作用。在信息检索中,通过计算查询词语的TF-IDF权重与文档集合中的文档进行匹配,可以得到相关度较高的文档。在文本分类中,可以利用TF-IDF算法提取特征,训练分类模型。在文本聚类中,可以根据词语的TF-IDF权重进行相似度计算,将相似的文档聚类在一起。在自然语言处理中,TF-IDF算法可以用于文本的关键词提取、文本摘要生成等任务。
总结来说,TF-IDF算法是一种用于计算词语在文本中的重要性的基于统计的方法。通过结合词频和逆文档频率,TF-IDF算法可以有效地提取文本特征并衡量其重要性。它在文本分析和处理任务中有着广泛的应用,帮助我们理解文本内容和挖掘文本中的信息。
您的鼓励是我最大的动力!