本文是自己的学习笔记。主要参考资料如下:
马士兵
- 4、Redis的五大数据类型
- 1.1、String
- 1.1.1、String 类型的命令
- 1.1.2、存储对象
- 1.2、List
- 1.2.1、List基本命令
- 1.2.2、List高级命令
- 1.3、Set
- 1.3.1、Set基本命令
- 1.4、HashMap
- 1.4.1、HashMap基本命令
- 1.5、ZSet(有序集合)
- 1.5.3、ZSet的指令
- 1.6、BitMap
- 1.6.1、BitMap的数据结构
- 1.6.2、BitMap的命令
- 1.7、HyperLogLog
- 1.7.1、应用场景
- 1.7.2、命令
- 1.7.3、原理
- 1.8、GEO
- 1.8.1、命令
- 2、Redis全局命令
- 2.1、获取数据库大小
- 2.2、设置有效时间
- 2.2.1、设置有效时间需要注意的坑
- 2.1、存储与读取键值对
- 2.1.1、高级的set和get
4、Redis的五大数据类型
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
1.1、String
1.1.1、String 类型的命令
- 对value追加字符串:
append key value。比如说,原有key -> “v”,append key hello,则key -> “vhello”。 - 获取字符串的长度:
strlen key。 - 获取字符串的某一部分:
getrange key start end,start和end都是闭区间。比如"hello’',执行命令getrange key 0 3可以得到"hell"。 - 对替换字符串某个字符替换成指定字符串:
setrange key start value。比如"hello",执行setrange key 1 xx可以得到"hxxllo"。
1.1.2、存储对象
使用json格式存储对象,比如set user1 {name:name1 age:1}。
或者使用多个key存储对象的属性,比如mset user1:name name1 user1:age 1。
后者与其前者相比,省略了取值后解析的逻辑。
1.2、List
redis中没有空链表的概念,如果一个链表的元素被清空,那么这个链表和对应的key也跟着消失。
redis中List的结构是链表不是数组,所以对于表头和表尾操作要比表中间的操作快很多。因为redis提供了链表和链尾的push和pop操作,所以我们可以将其当做栈或者队列使用。
List的命令支持链尾和链头操作,链头的有关命令带有l,比如在链头push一个元素lpush list value;链尾有关的命令带有r,比如链尾push一个元素rpush list value。所以链表的命令有l就多半有r,下面就只介绍其中一种,不重复介绍了。
1.2.1、List基本命令
- 存储:
lpush list value,向list左端中存入value,这里可以一次性存入多个值;rpush list value,向list右端存入value,可以一次性存入多个值。 - 读取链表中的一段:和存储不一样,这个只有从链表左边开始读取的命令
lrange list start end。注意是从链表左边开始读取,我们可以看示例。

- 通过下标获取链表中的某个值:读取第index个元素的值。
lindex list index。 - 获取链表长度:
llen list。 - 移除链表中队尾或队头的元素:移除操作有左右之分,可以移除左边第一个元素,也可以移除右边第一个元素。
lpop和rpop。 - 移除链表中值为value的元素:
lrem list count value,移除链表中值为value的元素,count是移除的个数。移除过程是从左往右移除元素,不是从右往左。下面是示例。

- 裁剪链表:
ltrim list start end只保留链表中start到end中的元素,两者都是闭区间。

-
将一个列表的队尾元素移除,并将该值加入到另一个列表的队头:
rpoplpush source dest。 -
将列表中的下标为index的元素的值替换成value:
lset list index value,如果index越界,或者list不存在该命令报错。 -
判断列表是否存在:
exists list,存在返回1,不存在返回0。redis没有空链表的概念,链表元素被排空了,该链表则是不存在的状态

-
向某个元素的之前/之后插入一个元素:
linsert list before/after pivot value,向值为pivot的元素之前或者之后插入一个置为value的元素。redis会从左往右查找,在第一个值为pivot的元素附件插入。
1.2.2、List高级命令
- 阻塞式pop:
blpop list timeout,对listpop操作,但如果当前列表为空(链表不存在也当它是一个空链表),或者其他的原因导致没有元素pop,那该操作会阻塞线程timeout秒,中途有元素可pop就pop元素提前结束阻塞。timeout设为0则无限阻塞线程。
下面就在一个空链表链表中阻塞式pop,然后开启另一个线程在链表中pop一个元素,最后可以看到阻塞提前终止。



1.3、Set
1.3.1、Set基本命令
- 存储:
sadd set value,可以向一个set中一次存储多个value,操作不具有原子性,可以一些失败一些成功。 - 读取一个set的所有元素:
smembers set。 - 判断set中是否有这个值:
sismember set value,返回1存在,返回0不存在。 - 获取set的大小:
scard set。 - 删除元素:
srem set value,可一次性删除多个值,也不具有原子性。 - 随机从集合中拿出n个元素:
srandmember set n。 - 随机从集合中删除一个元素:
spop set。 - 将集合中的一个元素移动到另一个集合:
smove source dest value,非原子性,只要从souce中取出了元素,哪怕没有dest没有添加成功,也返回1。 - 集合的交集、并集和差集:
sdiff set1 set2,sunion set1 set2,sinter set1 set2,上面三个指令都可以有多个参数 - 将交集、并集和差集存储:上面的命令指示返回计算结果,这个命令是将结果存入指定的key。在以上的命令后加一个
store即可。比如sdiffstore newKey set1 set2。

1.4、HashMap
redis里的HashMap其实Java里面的Map<String, Map<String, String>>。key String类型,但是对应的value是Map类型。
1.4.1、HashMap基本命令
-
存储:
hset map key value。 -
获取:
hget map key。 -
获取或读取多个键值对:
hmset map key value和hmget map key。 -
获取一个map里的所有键值对:
hgetall map -
删除map里的键值对:
hdel map key,可以删除多个key,非原子操作。 -
获取map的长度:
hlen map。 -
判断某个键值对是否存在:
hexists map key -
获取map中所有的key,或者所有的value:
hkeys map或hvals map -
给一个value增加数字:
map key increment。比如有这样一个map,map1 -> key1:1我们可以对key1```的值自增。

-
与setex和setnx功能一样的指令:
hsetex map key value,hsetnx map key value。
1.5、ZSet(有序集合)
有序集合是在集合的一个升级。其他部分和集合一样,但是value部分多加了一个score用于排序。
1.5.3、ZSet的指令
- 存储:
zadd set score key,score是分数,系统根据这个值给key排序。 - 按默认顺序获取多个值:
zrange set start end,闭区间。 - 按默认排序获取score在一定区间的值:
zrangebyscore set min max [withscore],获取set中,score在[min, max]中的元素,默认是闭区间,可以写成(min来代表开区间。我们可以使用-inf和+inf分别代表负无穷大和正无穷大。如果带上后面的参数withscore,那返回结果不止返回key,还返回对应的score。

- 按逆序获取元素:与
zrangebyscore和zrange一样,只要将range换成revrange即可。 - 删除元素:
zrem set key,可以删除多个key,非原子操作。 - 查看长度:
zcard set。 - 查看score在某个区间的值:
zcount set min max,默认闭区间,同样可以使用(min表示开区间。 - 查看
key的score:zscore zset key。 - 查看
key的的名次:查看默认排序下的名次,zrank zset key;查看倒序下的名词,revrank zset key。 - 对
key的score自增或自减:zincrby zset increment key。 - 集合的计算:和
set的交集,并集,差集计算一样,只不过指令由s变成z,比如sunionstore set1 set2对应zunionstore zset1 zset2。
1.6、BitMap
1.6.1、BitMap的数据结构
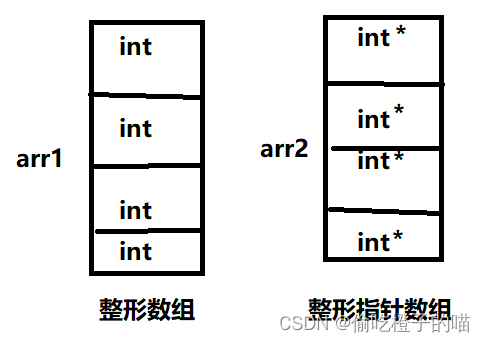
BitMap有些类似于HashMap,但它只能存储某个元素是0还是1,这个数据结构的优点是极大地节省空间。
列举一个应用场景,用一个数据结构记录这节课哪些人到,哪些人没到。
此时对于一个人来说要么到要么不到,不到就可以是0表示,到就是1表示。这种场景就适合BitMap。假设这个班有8个人,那么对应的BitMap就是一个bit[8]的空间。如下图所示。

1.6.2、BitMap的命令
- set:
setbit key offset value,value只能是0或1,其他值会报错。offset相当于是index。 - get:
getbit key offset。 - 统计
value为1的个数:bitcount key start end,start和end是闭区间,忽略start和end则不计范围。这个命令关于范围的参数非常容易让人误解。比如bitcount bitmap 0 2很容易让人以为是统计bitmap[0]到bitmap[2]总计三个比特位上,值为1的个数,但其实这个错误的。
这里的0 2的单位是byte不是bit,一个byte是8个bit,所以这命令的含义是统计bitmap[0]到bitmap[23]总计3个byte位,24bit位上值为1的个数,下面可看例子。
我将0, 1, 8位设为1,bitcount bitmap 0 0统计前8位,即[0-7],所以返回结果为2;
bitcount bitmap 0 1统计前16位,即[0 15],所以返回结果为3。

1.7、HyperLogLog
1.7.1、应用场景
一个大型网站需要统计每天的UV数据(UV,Unique-Visitor),即每天的用户访问量,但是得去重,同一个用户的多次访问只能算成一次。
HyperLogLog就是这种数据量很大,可以去重的数据结构。虽然它的去重有误差,不是百分百的去重,标准误差是0.81%,但这样的精准度已经能满足需求了。比如说实际值是100.81万,而统计值是100W,在百万数量级前,0.81万是可以忽略的。
最重要的一点是,相比于使用set来统计数据,它所需要的空间几乎可以忽略不计。
下面是对比图。

1.7.2、命令
- 添加:
pfadd key element,可以一次性添加多个。 - 计数:
pfcount key。 - 合并集合:
pfmerge destKey sourceKey。
1.7.3、原理
HyperLogLog基于概率论的伯努利实验,并结合极大似然估算方法,并做了分桶优化,所以占用空间才这么小。
1.8、GEO
GEO 3.2以后提供了GEO(地理信息定位)功能,支持存储地理信息用来实现诸如摇一摇附近位置等基于地理信息的功能。
地理信息使用二维的的经纬度表示。经度范围(-180,180),维度范围(-90,90)。
业界比较通用的地理距离计算排序算法是GeoHash算法,redis也是用该算法。
1.8.1、命令
- 添加:
geoadd key longtitude latitude location。在一个key当中添加经度和纬度,然后是地名。比如geoadd map 123.43 39.42 Beijing,geoadd map 132.49 49.29 Hebei。 - 获取位置:
geopos key location,可一次性获取多个location的经纬度。
- 经纬度信息转成hash:
geohash key location,可一次性转换多个。 
2、Redis全局命令
2.1、获取数据库大小
有一个命令是keys *,后面的*可以换成其他的正则表达式。这个命令用来显示符合正则表达式的所有键值对。
但是不推荐使用这个命令,因为键值对很多的时候,这个命令会打印很多数据。比如说有十万条数据,那就要打印十万行数据,这个非常消耗内存。如果想知道数据库大小,可以使用dbsize命令,它是直接读取计数器,时间是O(1)。

2.2、设置有效时间
有下面三种设置有效时间的方式。
给指定key设置过期时间:expire key seconds,seconds秒后指定key失效。也可以指定时间单位是毫秒,pexpire key millionseconds.
另外就是设置key在什么时候失效expireat key timestamp.
查看当前key还剩多少有效时间:ttl key。如果正数,表示还有x秒后就过期;返回-1,表示永远不会过期;返回-2表示已经过期。
2.2.1、设置有效时间需要注意的坑
当对一个键值对设置时间后,不要去修改它的value(可以用rename修改key)。一旦修改后之前设置的过期时间会自动失效。
比如下面就是对一个键值对设置过期时间,然后改变它的value,最后会发现过期时间失效了。

2.1、存储与读取键值对
- 存储和读取:get和set。
- 批量读取和批量设值:mget和mset,比如
mset key1 value key2 value2,这里就是设置了两个键值对,key1 -> value1和key2 -> value2。 - 先读取后写入:
getset key value。该指令返回key原有的值,如果这个key为null或者value为null,那指令会返回null。之后key的value会刷新成新的值。 - 清除指定键值对:
move key - 查询当前数据库是否存有指定的key:
exists key,返回1存在,返回0则不存在。 - 列出当前数据库中的所有key:
key * - 查看当前key的存储的数据类型:
type key - 重命名key:
rename key newKey、需要注意的是,如果新的key是已经存在的,那他会覆盖已经存在的那个key。所以重命名最好使用renamenx key newkey,如果newkey没有被使用,那修改成功返回1;如果newkey已经被使用,修改失败,返回0。
2.1.1、高级的set和get
-
如果key存在(一个键值对过期了也算是不存在)则set(并且可以设置过期时间),不存在就不set:
setex key n value。n是过期时间,单位是秒。 -
如果key不存在才set,存在就set失败:
setnx key n value。 -
批量的
msetex和msetnx:他们是原子性的操作,只要有一个key没设值成功,那所有的key都不会设值成功。 -
自增和自减:
incr key和decr key。key类型可以是字符串。 -
加减n:
incrby key n和decrby key n。 -
先get,然后立刻set新值:
getset key value。 这个效果和set一样,不同的是该命令会返回以前的值。 -
清空当前数据库的所有数据:
flushdb -
清空所有数据库的所有数据:
flushall -
查看当前数据库的大小:
dbsize,这是查看当前数据库,不是查看所有数据库。 -
选择数据库:
select n,选择第几个数据库,从0开始编号,默认选择第0个数据库,总共有16个数据库。