💡 本次解读的文章是 2019 年发表于 SIGIR 的一篇基于图卷积神经网络的用户物品协同过滤推荐算法论文, 论文将用户-物品交互信息建模为二分图,提出了一个基于二分图的推荐框架 Neural Graph Collaborative Filtering(NGCF),有效地将协作信号以显式的方式注入到嵌入过程中,并利用 GNN 捕捉高阶交互信息,以此提高预测的效果。
一、本文贡献
(1)说明了在基于模型 CF 方法的嵌入中显式地利用协作信号的重要性;
(2)提出了一种高阶、显式编码协助信号的图神经网络推荐框架 NGCF;
(3)在 300 万规模的数据集上进行了实证研究,结果证明了 NGCF 的有效性。
二、NGCF 框架
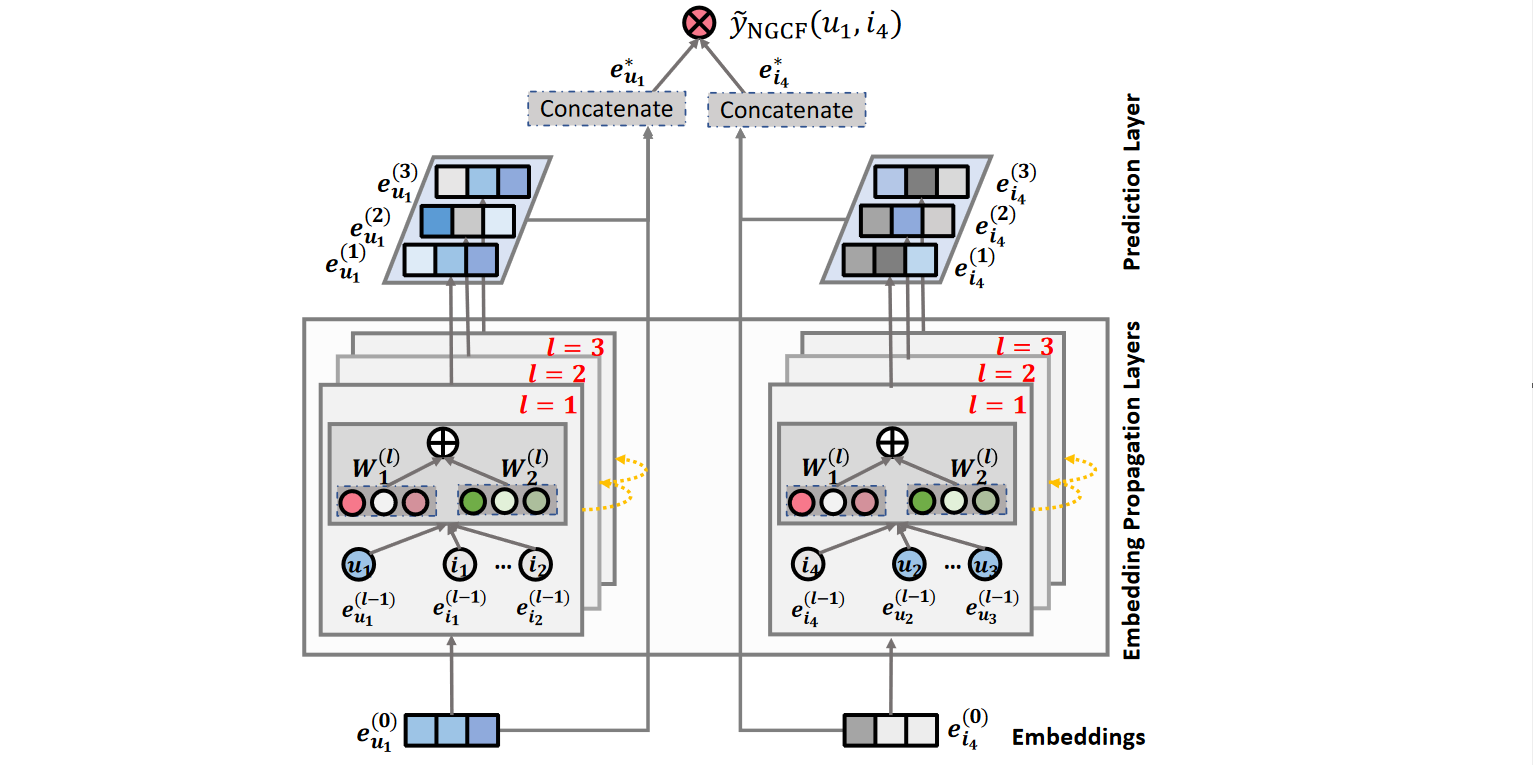
NGCF 框架主要有三个部分组成,分别是嵌入层(Embeddings Layer)、嵌入传播层(Embedding Propagation Layers)以及预测层(Prediction Layer)。
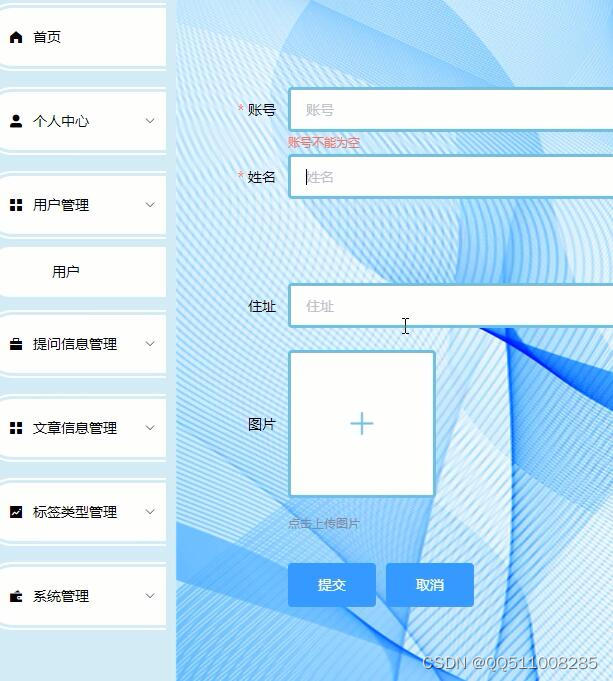
2.1 嵌入层
对于一个用户
u
u
u (或物品
i
i
i),首先利用 one-hot 编码进行向量表示,再利用 embedding 技术获取大小为
d
d
d 的嵌入表示
e
u
∈
R
d
(
e
i
∈
R
d
)
\mathbf{e}_{u} \in \mathbb{R}^{d}(\mathbf{e}_{i} \in \mathbb{R}^{d})
eu∈Rd(ei∈Rd),以此构建出一个作为嵌入查找表的参数矩阵:
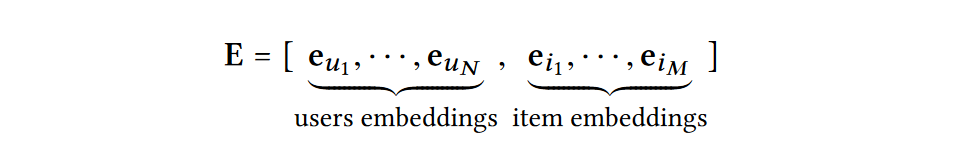
将上述嵌入表作为用户嵌入和物品嵌入的初始状态,并通过后续的图神经网络以端到端方式进行优化,增强嵌入表示中的协同信号。
2.2 嵌入传播层
嵌入传播过程的介绍主要分为一阶传播和高阶传播两个部分。
(1)一阶传播
从直观上看,与用户发生过交互的物品一定程度上反映了用户的偏好,依据协同过滤的思想,与某一物品发生过交互行为的用户可以作为该物品的特征,进一步地,基于此特征衡量两个物品的协同相似度。而这一过程主要通过一阶传播实现,该过程包含两个主要操作:消息构建和消息聚合。
- 消息构建
对于存在交互行为的用户-物品对 ( u , i ) (u,i) (u,i),将从物品 i i i 流向用户 u u u 的消息定义为:
m
u
←
i
=
f
(
e
i
,
e
u
,
p
u
i
)
\mathbf{m}_{u \leftarrow i}=f\left(\mathbf{e}_i, \mathbf{e}_u, p_{u i}\right)
mu←i=f(ei,eu,pui)
其中,
m
u
←
i
\mathbf{m}_{u \leftarrow i}
mu←i 为传播消息的嵌入表示,
f
(
⋅
)
f(\cdot)
f(⋅) 是消息编码函数,它以嵌入
e
i
\mathbf{e}_{i}
ei 和
e
u
\mathbf{e}_{u}
eu 作为输入,利用系数
p
u
i
p_{ui}
pui控制边
(
u
,
i
)
(u,i)
(u,i) 上每次传播的衰减因子。在本文中上述消息定义的具体实现为:
m
u
←
i
=
1
∣
N
u
∥
N
i
∣
(
W
1
e
i
+
W
2
(
e
i
⊙
e
u
)
)
\mathbf{m}_{u \leftarrow i}=\frac{1}{\sqrt{\left|\mathcal{N}_u \| \mathcal{N}_i\right|}}\left(\mathbf{W}_1 \mathbf{e}_i+\mathbf{W}_2\left(\mathbf{e}_i \odot \mathbf{e}_u\right)\right)
mu←i=∣Nu∥Ni∣1(W1ei+W2(ei⊙eu))
其中,
W
1
,
W
1
∈
R
d
′
×
d
\mathbf{W}_{1},\mathbf{W}_{1} \in \mathbb{R}_{d' \times d}
W1,W1∈Rd′×d 是可训练的权重矩阵,用于提取传播中的有用信息,
d
′
d'
d′ 表示变换大小,
⊙
\odot
⊙ 表示逐位乘积,
e
i
⊙
e
u
\mathbf{e}_i \odot \mathbf{e}_u
ei⊙eu 表示物品与用户交互信息的编码。这里用图拉普拉斯范数
1
∣
N
u
∥
N
i
∣
\frac{1}{\sqrt{\left|\mathcal{N}_u \| \mathcal{N}_i\right|}}
∣Nu∥Ni∣1 作为
p
u
i
p_{ui}
pui 的取值,
N
u
\mathcal{N}_{u}
Nu 和
N
i
\mathcal{N}_{i}
Ni 分别表示用户
u
u
u 和物品
i
i
i 的一跳邻居,其反映了历史物品对用户偏好的贡献程度,且传播的消息随路径长度衰减。
- 消息聚合
在获取了消息的表示后,对于用户
u
u
u 需要对邻域传播来的消息进行聚合,以此更新
u
u
u 的嵌入表示。具体地,将聚合函数定义为:
e
u
(
1
)
=
L
e
a
k
y
R
e
L
U
(
m
u
←
u
+
∑
i
∈
N
i
m
u
←
i
)
\mathbf{e}^{(1)}_{u} = LeakyReLU(\mathbf{m}_{u \leftarrow u} + \sum_{i \in \mathcal{N}_{i}}{\mathbf{m}_{u \leftarrow i}})
eu(1)=LeakyReLU(mu←u+i∈Ni∑mu←i)
其中,
e
u
(
1
)
\mathbf{e}^{(1)}_{u}
eu(1) 表示经过第一个嵌入传播层后得到的用户
u
u
u 嵌入表示,
m
u
←
u
\mathbf{m}_{u \leftarrow u}
mu←u 表示用户的自连接,它保留了原始特征的信息。类似地,可以通过从物品
i
i
i 连接的用户传播信息来获得物品
i
i
i 的嵌入表示
e
i
(
1
)
\mathbf{e}^{(1)}_{i}
ei(1)。
(2)高阶传播
在获取了一阶传播表示后,可以通过堆叠更多的图神经网络层,来获取高阶交互信息。通过堆叠
l
l
l 个嵌入传播层,用户和物品能够接收从其
l
l
l 跳邻居传播的消息,在第
l
l
l 步中,用户
u
u
u 的嵌入表示为:
e
u
(
l
)
=
L
e
a
k
y
R
e
L
U
(
m
u
←
u
(
l
)
+
∑
i
∈
N
i
m
u
←
i
(
l
)
)
\mathbf{e}^{(l)}_{u} = LeakyReLU(\mathbf{m}_{u \leftarrow u}^{(l)} + \sum_{i \in \mathcal{N}_{i}}{\mathbf{m}_{u \leftarrow i}^{(l)}})
eu(l)=LeakyReLU(mu←u(l)+i∈Ni∑mu←i(l))
其中,
m
u
←
i
(
l
)
=
p
u
i
(
W
1
(
l
)
e
i
(
l
−
1
)
+
W
2
(
l
)
(
e
i
(
l
−
1
)
⊙
e
u
(
l
−
1
)
)
)
\mathbf{m}_{u \leftarrow i}^{(l)} = p_{ui}(\mathbf{W}_{1}^{(l)}\mathbf{e}_{i}^{(l-1)} + \mathbf{W}_{2}^{(l)}(\mathbf{e}_{i}^{(l-1)} \odot \mathbf{e}_{u}^{(l-1)}))
mu←i(l)=pui(W1(l)ei(l−1)+W2(l)(ei(l−1)⊙eu(l−1))),
m
u
←
u
(
l
)
=
W
1
(
l
)
e
u
(
l
−
1
)
\mathbf{m}_{u \leftarrow u}^{(l)}=\mathbf{W}_{1}^{(l)}\mathbf{e}_{u}^{(l-1)}
mu←u(l)=W1(l)eu(l−1),
W
1
,
W
2
∈
R
d
l
×
d
l
−
1
\mathbf{W}_{1}, \mathbf{W}_{2} \in \mathbb{R}^{d_{l} \times d_{l-1}}
W1,W2∈Rdl×dl−1 表示可训练的变换矩阵。
(3)矩阵表示
基于上述一阶传播和高阶传播的向量化表示,将传播过程以矩阵的形式进行统一表示:
E
(
l
)
=
LeakyReLU
(
(
L
+
I
)
E
(
l
−
1
)
W
1
(
l
)
+
L
E
(
l
−
1
)
⊙
E
(
l
−
1
)
W
2
(
l
)
)
\mathbf{E}^{(l)}=\operatorname{LeakyReLU}\left((\mathcal{L}+\mathbf{I}) \mathbf{E}^{(l-1)} \mathbf{W}_{1}^{(l)}+\mathcal{L} \mathbf{E}^{(l-1)} \odot \mathbf{E}^{(l-1)} \mathbf{W}_{2}^{(l)}\right)
E(l)=LeakyReLU((L+I)E(l−1)W1(l)+LE(l−1)⊙E(l−1)W2(l))
其中,
E
(
l
)
∈
R
(
N
+
M
)
×
d
l
\mathbf{E}^{(l)} \in \mathbb{R}^{(N+M) \times d_{l}}
E(l)∈R(N+M)×dl 是经过
l
l
l 步嵌入传播后得到的用户和物品的表示,
E
(
0
)
\mathbf{E}^{(0)}
E(0) 表示初始嵌入,即
e
u
(
0
)
=
e
u
,
e
i
(
0
)
=
e
i
\mathbf{e}^{(0)}_{u} = \mathbf{e}_{u}, \mathbf{e}^{(0)}_{i} = \mathbf{e}_{i}
eu(0)=eu,ei(0)=ei,
I
\mathbf{I}
I 表示单位矩阵,
L
\mathcal{L}
L 表示用户-物品二分图的拉普拉斯矩阵:
L
=
D
−
1
2
A
D
−
1
2
and
A
=
[
0
R
R
⊤
0
]
\mathcal{L}=\mathrm{D}^{-\frac{1}{2}} \mathrm{AD}^{-\frac{1}{2}} \text { and } \mathrm{A}=\left[\begin{array}{cc} 0 & \mathbf{R} \\ \mathbf{R}^{\top} & 0 \end{array}\right]
L=D−21AD−21 and A=[0R⊤R0]
其中,
R
∈
R
N
×
M
\mathbf{R} \in R^{N \times M}
R∈RN×M 表示用户-物品交互矩阵,
A
\mathbf{A}
A 为邻接矩阵,
D
\mathbf{D}
D 为对角度矩阵(第
t
t
t 个对角元素
D
t
t
=
∣
N
t
∣
D_{tt} = |N_{t}|
Dtt=∣Nt∣,因此,有
L
u
i
=
1
/
∣
N
u
∣
∣
N
i
∣
\mathcal{L}_{u i}=1 / \sqrt{\left|\mathcal{N}_{u}\right|\left|\mathcal{N}_{i}\right|}
Lui=1/∣Nu∣∣Ni∣。这种通过矩阵表示的传播规则,可以丢弃节点采样过程,以相当高效的方式同时更新所有用户和物品的表示,这意味着该方法可以在大规模图上运行。
2.3 预测层
在经过
L
L
L 层嵌入传播层后,可以得到用户
u
u
u 的多个嵌入表示
{
e
u
(
1
)
,
⋯
,
e
u
(
L
)
}
\left\{\mathbf{e}_{u}^{(1)}, \cdots, \mathbf{e}_{u}^{(L)}\right\}
{eu(1),⋯,eu(L)},由于不同层得到的表示强调的是通过不同连接传递的消息,它们在反映用户偏好方面的贡献不同。因此,这里主要利用拼接操作,将它们拼接成最终的嵌入表示:
e
u
∗
=
e
u
(
0
)
∥
⋯
∥
e
u
(
L
)
,
e
i
∗
=
e
i
(
0
)
∥
⋯
∥
e
i
(
L
)
\mathbf{e}_{u}^{*}=\mathbf{e}_{u}^{(0)}\|\cdots\| \mathbf{e}_{u}^{(L)}, \quad \mathbf{e}_{i}^{*}=\mathbf{e}_{i}^{(0)}\|\cdots\| \mathbf{e}_{i}^{(L)}
eu∗=eu(0)∥⋯∥eu(L),ei∗=ei(0)∥⋯∥ei(L)
在分别获取了用户
u
u
u 和物品
i
i
i 的最终嵌入表示后,可以利用内积来估计用户对目标物品的偏好:
y ^ N G C F ( u , i ) = e u ∗ ⊤ e i ∗ \hat{y}_{\mathrm{NGCF}}(u, i)=\mathbf{e}_{u}^{* \top} \mathbf{e}_{i}^{*} y^NGCF(u,i)=eu∗⊤ei∗
三、模型训练
(1)损失函数定义
为了学习模型参数,论文使用了成对 BPR 损失函数,它考虑了观察到的和未观察到的用户-物品交互之间的相对顺序,即 BPR 假设观察到的交互比未观察到的交互更能反映用户的偏好,应该赋予更高的预测值,目标函数如下:
Loss
=
∑
(
u
,
i
,
j
)
∈
O
−
ln
σ
(
y
^
u
i
−
y
^
u
j
)
+
λ
∥
Θ
∥
2
2
\text { Loss }=\sum_{(u, i, j) \in O}-\ln \sigma\left(\hat{y}_{u i}-\hat{y}_{u j}\right)+\lambda\|\Theta\|_{2}^{2}
Loss =(u,i,j)∈O∑−lnσ(y^ui−y^uj)+λ∥Θ∥22
其中,
O
=
{
(
u
,
i
,
j
)
∣
(
u
,
i
)
∈
R
+
,
(
u
,
j
)
∈
R
−
}
O=\left\{(u, i, j) \mid(u, i) \in \mathcal{R}^{+},(u, j) \in \mathcal{R}^{-}\right\}
O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−},训练集中的数据对,
R
+
\mathcal{R}^{+}
R+ 表示观察到的交互,
R
−
\mathcal{R}^{-}
R− 表示未观察到的交互,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅) 表示 sigmoid 函数,
Θ
=
{
E
,
{
W
1
(
l
)
,
W
2
(
l
)
}
l
=
1
L
}
\Theta = \left\{\mathbf{E},\left\{\mathbf{W}_{1}^{(l)}, \mathbf{W}_{2}^{(l)}\right\}_{l=1}^{L}\right\}
Θ={E,{W1(l),W2(l)}l=1L},
λ
\lambda
λ 用于控制 L2 正则化强度,防止过拟合。这里论文采用 mini-batch Adam 优化预测模型并更新模型参数,对于一批随机采样的三元组
(
u
,
i
,
j
)
∈
O
(u, i, j)\in O
(u,i,j)∈O,在传播
L
L
L 步后建立其表示为
[
e
(
0
)
,
⋯
,
e
(
L
)
]
[e^{(0)}, \cdots, e^{(L)}]
[e(0),⋯,e(L)],然后利用损失函数的梯度更新模型参数。
(2)消息和节点的 Dropout
Dropout 操作主要用于缓解模型的过拟合现象,一般只在训练中使用,在测试时禁用。本文的方法在训练时,以概率 p 1 p1 p1 删除传播过程中的消息,即在第 l l l 个传播层中,只有部分消息贡献于嵌入表示。另外,本文的方法还进行了节点丢弃来随机阻塞特定的节点并丢弃其所有的传出消息,即对于第 l l l 个传播层,随机丢弃拉普拉斯矩阵的 ( M + N ) p 2 (M + N)p2 (M+N)p2 个节点,其中 p 2 p2 p2 为丢弃率。