WALT(Windows-Assist Load Tracing)算法是由Qcom开发, 通过把时间划分为窗口,对
task运行时间和CPU负载进行跟踪计算的方法。为任务调度、迁移、负载均衡及CPU调频
提供输入。
WALT相对PELT算法,更能及时反映负载变化, 更适用于移动设备的交互场景。
1. 不同cpu不同频点的相对runtime
task在不同cpu的不同频点上运行,运行时长是不同的。那么怎么度量task的大小,体现task对CPU的能力需求呢?我们知道task在某个cpu某个频点的绝对runtime时间,此runtime期间这个cpu的能力,和最大capacity cpu在最高频点运行的能力,如果能有对应关系, 就可以把这个绝对runtime时间,归一化到相对最大cpu能力的runtime时间。
WALT中,使用wrq->task_exec_scale表征cpu当前频点的能力。把capacity最大的cpu在最高频点运行的能力定义为1024。task_exec_scale的计算方法如下:
赋值调用路径:walt_update_task_ravg->update_task_rq_cpu_cycles
如果不使用cpu cycles计算负载:
task_exec_scale=
{cpu_cur_freq(cpu)/(wrq->cluster->max_possible_freq)}
*arch_scale_cpu_capacity(cpu)
如果使用cpu cycles计算负载:
task_exec_scale=
{(cycles_delta /time_delta)/(wrq->cluster->max_possible_freq)}
*arch_scale_cpu_capacity(cpu)
wrq->task_exec_scale会在cpu频点发生变化时从新计算更新,此时就可以通过这个归一化后的cpu能力,计算task的相对runtime了。
WALT是通过scale_exec_time函数实现的:
delta * (wrq->task_exec_scale) / 1024
例如,此时task 在cpu0 1G频点对应的task_exec_scale=200运行了10ms,那么task的相对运行时间即为:
10*200/1024=1.953125(ms)
2. scaled runtime
在实际项目中,WALT定义了5个历史窗口,每个窗口长16ms(可根据帧率动态设置为8ms)。在每次对task runtime delta进行更新时,都要转换为相对runtime。
但对调度器默认的单位util,还要做进一步的归一化。WALT中把task 在capacity最大cpu最高频点连续运行一个窗口(16ms)时间,定义为最大uti值1024。所以把相对runtime按一个窗口归一化到1024的util值为:
runtime_scaled = (delta/sched_ravg_window)*1024
实现函数为:
scale_time_to_util(runtime)
一、关键数据结构
1. 变量
sched_ravg_window(EXPORT_SYMBOL())
walt负载统计窗口大小
定义变量时初始化:20000000
walt初始化时:walt_init->walt_tunables->DEFAULT_SCHED_RAVG_WINDOW:
300HZ时对齐刷新率:(3333333*5);其它刷新率16000000
单位:ns
NUM_LOAD_INDICES
#define NUM_LOAD_INDICES 1000
把window size(现在是16ms,不会根据动态window size调整)分为1000份
sched_load_granule
unsigned int __read_mostly sched_load_granule
sched_load_granule = DEFAULT_SCHED_RAVG_WINDOW / NUM_LOAD_INDICES
#define DEFAULT_SCHED_RAVG_WINDOW 16000000
计算得知window size分为1000份之后的单位粒度是16000ns=16us
2. 结构体
walt_task_struct
struct walt_task_struct {
u32 flags;
u64 mark_start;
u64 window_start;
u32 sum, demand;
u32 coloc_demand;
u32 sum_history[RAVG_HIST_SIZE];
u16 sum_history_util[RAVG_HIST_SIZE];
u32 curr_window_cpu[WALT_NR_CPUS];
u32 prev_window_cpu[WALT_NR_CPUS];
u32 curr_window, prev_window;
u8 busy_buckets[NUM_BUSY_BUCKETS];
u16 bucket_bitmask;
u16 demand_scaled;
u16 pred_demand_scaled;
u64 active_time;
u64 last_win_size;
int boost;
bool wake_up_idle;
bool misfit;
bool rtg_high_prio;
u8 low_latency;
u64 boost_period;
u64 boost_expires;
u64 last_sleep_ts;
u32 init_load_pct;
u32 unfilter;
u64 last_wake_ts;
u64 last_enqueued_ts;
struct walt_related_thread_group __rcu *grp;
struct list_head grp_list;
u64 cpu_cycles;
bool iowaited;
int prev_on_rq;
int prev_on_rq_cpu;
struct list_head mvp_list;
u64 sum_exec_snapshot_for_slice;
u64 sum_exec_snapshot_for_total;
u64 total_exec;
int mvp_prio;
int cidx;
int load_boost;
int64_t boosted_task_load;
int prev_cpu;
int new_cpu;
u8 enqueue_after_migration;
u8 hung_detect_status;
int pipeline_cpu;
};
3.mark_start:同步wrq->mark_start
记录task某些event的开始时间, 这些event在walt.h task_event中定义。
4.window_start
标识了per task window。同步于wrq->window_start:
walt_update_task_ravg->update_cpu_busy_time:
/*
* Handle per-task window rollover. We don't care about the
* idle task.
*/
if (new_window) {
if (!is_idle_task(p))
rollover_task_window(p, full_window);
wts->window_start = window_start;
}
新task wts->window_start初始化为0, 在第一次调用walt_update_task_ravg时同步为wrq->window_start

5.wts->sum += scale_exec_time(delta, rq, wts)
计算当前窗口task运行时间总和, 这些时间是实际运行时间delta按cpu当前频率和cpu capacity归一化到最大capacity cpu最高频率的运行时长。比如在最大capacity cpu上以最高频点运行的task,实际运行时间delta和统计到sum的时间是1:1的。
更新路径:
walt_update_task_ravg->update_task_demand->add_to_task_demand->(wts->sum += scale_exec_time(delta, rq, wts))
walt_update_task_ravg->update_task_demand->update_history->(wts->sum = 0), 在event跨窗口时,才会复位为0。
5.wts->demand
历史窗口中统计的相对runtime,通过不同的策略计算出当前采用的相对runtime值
#define WINDOW_STATS_RECENT 0
#define WINDOW_STATS_MAX 1
#define WINDOW_STATS_MAX_RECENT_AVG 2
#define WINDOW_STATS_AVG 3
6.wts->coloc_demand
5个历史窗口task 相对runtime的平均值
wts->coloc_demand = div64_u64((sum += hist[i]), RAVG_HIST_SIZE)
7.wts->sum_history[5]
记录了task 5个历史窗口的相对runtime。相对 runtime,即为task实际running时间归一化到最大capacity cpu最高频点后的相对运行时间, 最大值为16ms。
walt_update_task_ravg()->update_task_demand()->update_history()->
hist[wts->cidx] = runtime
8.wts->sum_history_util[5]
把task在每个历史窗口累加的相对runtime(0ms~16ms), 归一化到(0~1024)的util值, 这里称之为scaled runtime:
walt_update_task_ravg()->update_task_demand()->update_history()->
scale_time_to_util(runtime)=(wts->sum/sched_ravg_window)*1024
9.curr_window_cpu[WALT_NR_CPUS]
统计task在每个cpu上当前窗口中相对runtime
10.prev_window_cpu[WALT_NR_CPUS]
统计task在每个cpu上前一窗口中相对runtime
11.curr_window, prev_window
walt_update_task_ravg()->update_cpu_busy_time()
统计task在当前窗和前一窗中,相对runtime。包含task运行期间的irqtime。
12.参考如何更新wts->bucket_bitmask及busy_buckets[bidx]
13.参考如何更新wts->bucket_bitmask及busy_buckets[bidx]
14.demand_scaled
参考5),把计算出当前的相对runtime值归一化到scaled runtime(0~1024).
walt_update_task_ravg()->update_task_demand()->update_history()->
scale_time_to_util(demand)
16.active_time
is_new_task中判断此值小于100ms就认为是新task,rollover_task_window是唯一调用路径。
28.last_sleep_ts:
记录task被开始sleep的时间, 在__schedule->android_rvh_schedule中, 当prev!=next且!prev->on_rq时, 更新prev task的last_sleep_ts。prev task不再被调度,且不在rq的wait list时, 即表示prev task被schedule out后,进入非running状态。
41.wts->cidx
current idx, 索引hist和hist_util数组中当前窗口, 存储task相对running time和util。在window更新时,在update_history中更新索引值,达到滚动更新历史窗口信息的目的。
task_event
task event标识了task的一组行为,这些行为发生的时间点,是对task demand变化更新的关键时间点。理解walt算法,首先要理解这些event的含义及如何通过这些event更新task demand和cpu 负载。
enum task_event {
PUT_PREV_TASK = 0,
PICK_NEXT_TASK = 1,
TASK_WAKE = 2,
TASK_MIGRATE = 3,
TASK_UPDATE = 4,
IRQ_UPDATE = 5,
};
PUT_PREV_TASK/PICK_NEXT_TASK:
调用路径__schedule->android_rvh_schedule()->
walt_update_task_ravg(prev, rq, PUT_PREV_TASK/PICK_NEXT_TASK, wallclock, 0). CPU上发生任务调度,通过pick_next_task选出cpu上将要运行的next task后,通过hook调用核心函数对prev task和next task的util及cpu的负载进行更新。PUT_PREV_TASK标识prev task从rq上被调度走时对prev task的util和cpu负载进行更新。
TASK_WAKE:
调用路径try_to_wake_up->android_rvh_try_to_wake_up(*p)->
walt_update_task_ravg(p, rq, TASK_WAKE, wallclock, 0)
当wakeup一个task, 对非current(当前cpu)&&非runnalbe(不在run queue wait list中) &&非running(其它cpu)的task p,在select_task_rq选择target cpu之前,通过hook调用核心函数。此时的task_cpu(p)为task最后一次running的cpu。
walt_rq
struct walt_rq {
struct task_struct *push_task;
struct walt_sched_cluster *cluster;
struct cpumask freq_domain_cpumask;
struct walt_sched_stats walt_stats;
u64 window_start;
u32 prev_window_size;
unsigned long walt_flags;
u64 avg_irqload;
u64 last_irq_window;
u64 prev_irq_time;
struct task_struct *ed_task;
u64 task_exec_scale;
u64 old_busy_time;
u64 old_estimated_time;
u64 curr_runnable_sum;
u64 prev_runnable_sum;
u64 nt_curr_runnable_sum;
u64 nt_prev_runnable_sum;
struct group_cpu_time grp_time;
struct load_subtractions load_subs[NUM_TRACKED_WINDOWS];
DECLARE_BITMAP_ARRAY(top_tasks_bitmap,
NUM_TRACKED_WINDOWS, NUM_LOAD_INDICES);
u8 *top_tasks[NUM_TRACKED_WINDOWS];
u8 curr_table;
int prev_top;
int curr_top;
bool notif_pending;
bool high_irqload;
u64 last_cc_update;
u64 cycles;
u64 util;
struct list_head mvp_tasks;
int num_mvp_tasks;
u64 latest_clock;
u32 enqueue_counter;
};
15.task_exec_scale: task所在cpu的当前频点归一化到cpu最大能力1024的值,体现当前频点cpu的能力.
例如在最大cluster中cpu在最高频点运行, task_exec_scale=1024.
赋值调用路径:walt_update_task_ravg->update_task_rq_cpu_cycles
!use_cycle_counter:如果不使用cpu cycles计算负载:task_exec_scale=
{cpu_cur_freq(cpu)/(wrq->cluster->max_possible_freq)}
*arch_scale_cpu_capacity(cpu)
use_cycle_counter:如果使用cpu cycles计算负载:task_exec_scale=
{(cycles_delta /time_delta)/(wrq->cluster->max_possible_freq)}
*arch_scale_cpu_capacity(cpu)
(https://www.kernel.org/doc/Documentation/devicetree/bindings/arm/cpu-capacity.txt)
18.curr_runnable_sum
当前窗口cpu 负载信息
19.prev_runnable_sum
前一窗cpu负载信息
20.nt_curr_runnable_sum
cpu当前窗new task负载信息, wts->active_time小于100ms属于new task
21.nt_prev_runnable_sum
cpu前一窗new task负载信息
24.unsigned long top_tasks_bitmap[2][BITS_TO_LONGS(1000)],
跟踪curr和prev两个窗口。BITS_TO_LONGS(1000)=16, 即为大小为16*64=1024bit
26.u8 *top_tasks[2]
两个指针元素的指针数组, 分别指向大小1000 Byte(u8)类型的mem。记录当前cpu上最近两个窗口curr和prev上, 翻转?
27.curr_table 0?1
使用两个window进行跟踪,标识哪个是curr的,curr和prev构成一个环形数组,不停翻转.
在update_window_start->rollover_top_tasks(rq, full_window)翻转更新:
wrq->curr_table
wrq->prev_top = curr_top
wrq->curr_top = 0
wrq->top_tasks[prev/curr]
wrq->top_tasks_bitmap[prev/curr]
28.prev_top
前窗最大task runtime落在1000个bucket中的index
29.curr_top
是index值,当前窗口的max load_to_index(wts->curr_window), 记录在当前窗口最大task runtime落在的bucket id。如当前窗口运行过task和相对runtime分别为:
A(2ms) B(6ms) C(15ms),
则:wrq->curr_top = load_to_index(15ms)=15*1000/16
34.util
walt gov调频获取cpu util:
waltgov_update_freq->waltgov_get_util(wg_cpu)->cpu_util_freq_walt()->__cpu_util_freq_walt()
wrq->util = scale_time_to_util(freq_policy_load(rq, reason))
37.记录最近一次调用update_window_start的时间戳,但未必满足更新条件(delta \geq sched_ravg_window)对wrq->window_start进行更新
二、核心函数
1. 函数调用关系
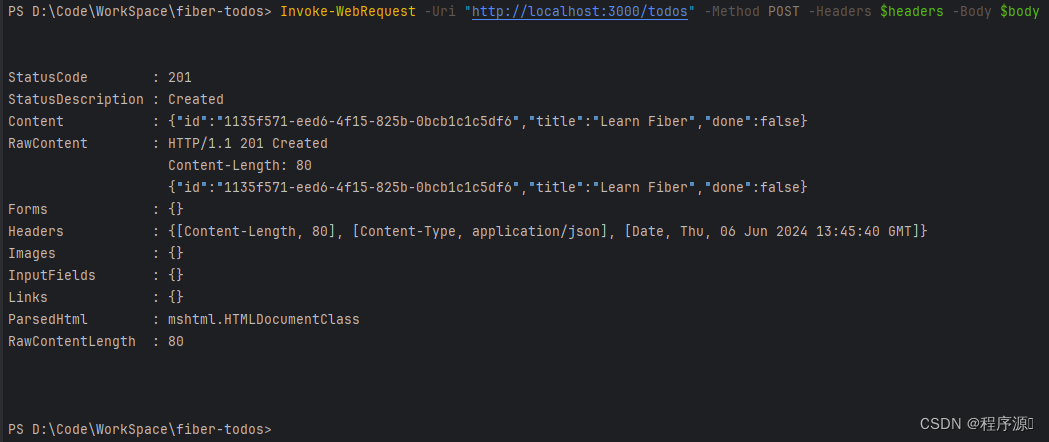
walt_update_task_ravg是WALT算法的入口函数,
主要函数调用关系如下图。主要涉及:
1. 随着时间推移会产生新的window,更新window的
start time
update_window_start
2.计算 wrq->task_exec_scale, task_exec_scale反
映了在当前频点下cpu的能力,参见:
《二、task_runtime 1. 不同cpu不同频点的相对runtim》
update_task_rq_cpu_cycles
3. 对task runtime和历史记录的更新,实现函数为:
update_task_demand
4. 对task 和 rq curr和prev两个window统计信息的更新
update_cpu_busy_time
5. 更新task预测需求
update_task_pred_demand
2. 函数说明

a) update_window_start(rq, wallclock, event)
-
-
- 更新wrq->window_start += (u64)nr_windows * (u64)sched_ravg_window
- 更新wrq->prev_window_size = sched_ravg_window
- 更新wrq的历史窗口统计信息, 初始化新窗口信息:
update_window_start()->rollover_cpu_window(rq, nr_windows > 1)
-
rollover_cpu_window(struct rq *rq, bool full_window)
{
struct walt_rq *wrq = &per_cpu(walt_rq, cpu_of(rq));
u64 curr_sum = wrq->curr_runnable_sum;
u64 nt_curr_sum = wrq->nt_curr_runnable_sum;
u64 grp_curr_sum = wrq->grp_time.curr_runnable_sum;
u64 grp_nt_curr_sum = wrq->grp_time.nt_curr_runnable_sum;
if (unlikely(full_window)) {
curr_sum = 0;
nt_curr_sum = 0;
grp_curr_sum = 0;
grp_nt_curr_sum = 0;
}
wrq->prev_runnable_sum = curr_sum;
wrq->nt_prev_runnable_sum = nt_curr_sum;
wrq->grp_time.prev_runnable_sum = grp_curr_sum;
wrq->grp_time.nt_prev_runnable_sum = grp_nt_curr_sum;
wrq->curr_runnable_sum = 0;
wrq->nt_curr_runnable_sum = 0;
wrq->grp_time.curr_runnable_sum = 0;
wrq->grp_time.nt_curr_runnable_sum = 0;
}
9)~21):
scheduler_tick()->trace_android_rvh_tick_entry(rq)->update_window_start在每个tick(250HZ 4ms)中断处理函数中触发更新wrq->window_start,所以超过一个window_size(8ms/16ms)满足更新条件(delta >=sched_ravg_window)后,在第二个window_size内还没更新wrq->window_start的情况(full_window=2)极少发生:(异常task长时间关中断运行,或tickless的idle cpu(https://docs.kernel.org/timers/no_hz.html))
当这种情况发生时,因为前窗更新window start异常,prev值只参考前窗, 所以(nr_windows > 1)后更新的prev值设置为0.

- 更新
- update_window_start()->rollover_top_tasks(struct rq *rq, bool full_window)
static void rollover_top_tasks(struct rq *rq, bool full_window)
{
struct walt_rq *wrq = &per_cpu(walt_rq, cpu_of(rq));
u8 curr_table = wrq->curr_table;
u8 prev_table = 1 - curr_table;
int curr_top = wrq->curr_top;
clear_top_tasks_table(wrq->top_tasks[prev_table]);
clear_top_tasks_bitmap(wrq->top_tasks_bitmap[prev_table]);
if (full_window) {
curr_top = 0;
clear_top_tasks_table(wrq->top_tasks[curr_table]);
clear_top_tasks_bitmap(wrq->top_tasks_bitmap[curr_table]);
}
wrq->curr_table = prev_table;
wrq->prev_top = curr_top;
wrq->curr_top = 0;
}
b)update_task_rq_cpu_cycles(p, rq, event, wallclock, irqtime)
主要计算 wrq->task_exec_scale, task_exec_scale反映了在当前频点下cpu的能力,参见walt_rq.task_exec_scale说明。
c)u64 update_task_demand(p, rq, event, wallclock)
此函数是WALT算法计算task demand核心函数,把此次event发生时需要更新的task busy time delta,归一化到最大capacity、最高频点的相对时间,即相对runtime,并累加到wts->sum, 并前滚更新task的历史窗口信息。根据5个历史窗口得到最终表示task大小的demand。详细参见《三、算法 1. 如何更新task demnd》
d)update_cpu_busy_time(p, rq, event, wallclock, irqtime)
详细参考《三、算法 2. 如何更新cpu负载信息》
e)update_task_pred_demand(rq, p, event)
static void update_task_pred_demand(struct rq *rq, struct task_struct *p, int event)
{
u16 new_pred_demand_scaled;
struct walt_task_struct *wts = (struct walt_task_struct *) p->android_vendor_data1;
u16 curr_window_scaled;
if (is_idle_task(p))
return;
if (event != PUT_PREV_TASK && event != TASK_UPDATE &&
(!SCHED_FREQ_ACCOUNT_WAIT_TIME ||
(event != TASK_MIGRATE &&
event != PICK_NEXT_TASK)))
return;
/*
* TASK_UPDATE can be called on sleeping task, when its moved between
* related groups
*/
if (event == TASK_UPDATE) {
if (!p->on_rq && !SCHED_FREQ_ACCOUNT_WAIT_TIME)
return;
}
curr_window_scaled = scale_time_to_util(wts->curr_window);
if (wts->pred_demand_scaled >= curr_window_scaled)
return;
new_pred_demand_scaled = get_pred_busy(p, busy_to_bucket(curr_window_scaled),
curr_window_scaled, wts->bucket_bitmask);
if (task_on_rq_queued(p) && (!task_has_dl_policy(p) ||
!p->dl.dl_throttled))
fixup_walt_sched_stats_common(rq, p,
wts->demand_scaled,
new_pred_demand_scaled);
wts->pred_demand_scaled = new_pred_demand_scaled;
}
10~14.只处理PUT_PREV_TASK,TASK_UPDATE,TASK_MIGRATE,PICK_NEXT_TASK四个event,SCHED_FREQ_ACCOUNT_WAIT_TIME=0 (default)
20~22.当sleep task在不同group间迁移时,TASK_UPDATE会被调用。SCHED_FREQ_ACCOUNT_WAIT_TIME=0(default),不对sleep task 更新。
25.(wts->curr_window/sched_ravg_window)*1024, 把wts->curr_window以ns为单位的数值归一化到1024,归一化后的值为util。
29.参考《三、算法 1.如何更新task runtime》
f)run_walt_irq_work_rollover(old_window_start, rq)
三、算法
1. 如何更新task runtime
- WALT(Windows-Assist Load Tracing)算法是由Qcom开发, 通过把时间划分为窗口,对task运行时间和CPU负载进行跟踪计算的方法。为任务调度、迁移、负载均衡及CPU调频提供输入。
- WALT相对PELT算法,更能及时反映负载变化, 更适用于移动设备的交互场景。

不同cpu不同频点的相对runtime
task在不同cpu的不同频点上运行,运行时长是不同的。那么怎么度量task的大小,体现task对CPU的能力需求呢?我们知道task在某个cpu某个频点的绝对runtime时间,此runtime期间这个cpu的能力,和最大capacity cpu在最高频点运行的能力,如果能有对应关系, 就可以把这个绝对runtime时间,归一化到相对最大cpu能力的runtime时间。
WALT中,使用wrq->task_exec_scale表征cpu当前频点的能力。把capacity最大的cpu在最高频点运行一个window定义为1024。task_exec_scale的计算方法如下:
赋值调用路径:walt_update_task_ravg->update_task_rq_cpu_cycles
如果不使用cpu cycles计算负载:
task_exec_scale=
{cpu_cur_freq(cpu)/(wrq->cluster->max_possible_freq)}
*arch_scale_cpu_capacity(cpu)
如果使用cpu cycles计算负载:
task_exec_scale=
{(cycles_delta /time_delta)/(wrq->cluster->max_possible_freq)}
*arch_scale_cpu_capacity(cpu)
wrq->task_exec_scale会在cpu频点发生变化时从新计算更新,此时就可以通过这个归一化后的cpu能力,计算task的相对runtime了。
WALT是通过scale_exec_time函数实现的:
delta * (wrq->task_exec_scale) / 1024
例如,此时task 在cpu0 1G频点对应的task_exec_scale=200运行了10ms,那么task的相对运行时间即为:
10*200/1024=1.953125(ms)
scaled runtime
在实际项目中,WALT定义了5个历史窗口,每个窗口长16ms(可根据帧率动态设置为8ms)。在每次对task runtime delta进行更新时,都要转换为相对runtime。
但对调度器默认的单位util,还要做进一步的归一化。WALT中把task 在capacity最大cpu最高频点连续运行一个窗口(16ms)时间,定义为最大uti值1024。所以把相对runtime按一个窗口归一化到1024的util值为:
runtime_scaled = (delta/sched_ravg_window)*1024
实现函数为:
scale_time_to_util(runtime)
ms: wts->mark_start: event的开始时间
ws: wrq->window_start
wc: wallclock: 当前event时间戳,walt_sched_clock()->sched_clock()
在计算task的demand时分三种情况:
-
- event未跨越窗口
- event跨两个窗口
- event跨多个窗口

update_task_demand
()是WALT算法的核心函数,计算task 相对runtime并更新历史窗口(默认配置记录5个history window)。涉及三个主要函数 :
1) account_busy_for_task_demand(struct rq *rq, struct task_struct *p, int event)
判断task的busy time, 对应event是否应该累加task running time。
static int
account_busy_for_task_demand(struct rq *rq, struct task_struct *p, int event)
{
/*
* No need to bother updating task demand for the idle task.
*/
if (is_idle_task(p))
return 0;
/*
* When a task is waking up it is completing a segment of non-busy
* time. Likewise, if wait time is not treated as busy time, then
* when a task begins to run or is migrated, it is not running and
* is completing a segment of non-busy time.
*/
if (event == TASK_WAKE || (!SCHED_ACCOUNT_WAIT_TIME &&
(event == PICK_NEXT_TASK || event == TASK_MIGRATE)))
return 0;
/*
* The idle exit time is not accounted for the first task _picked_ up to
* run on the idle CPU.
*/
if (event == PICK_NEXT_TASK && rq->curr == rq->idle)
return 0;
/*
* TASK_UPDATE can be called on sleeping task, when its moved between
* related groups
*/
if (event == TASK_UPDATE) {
if (rq->curr == p)
return 1;
return p->on_rq ? SCHED_ACCOUNT_WAIT_TIME : 0;
}
return 1;
}
如何确定event发生时, task在rq上是busy状态, 并应该被累加到task running time中呢?
7.不统计idle task的demand。
16.TASK_WAKE视为非busytime。SCHED_ACCOUNT_WAIT_TIME = flase, PICK_NEXT_TASK, TASK_MIGRATE event视为非busy time,不统计task demand。
24.如果设置了SCHED_ACCOUNT_WAIT_TIME,并且event=PICK_NEXT_TASK,当task被调度到idle cpu运行时,cpu退出idle的时间不能视为task的busy time,不统计。
31.event == TASK_UPDATE 且
-
-
-
- task p正在running,属于busy time。
- task p在等待队列中,可以通过配置 SCHED_ACCOUNT_WAIT_TIME 决定是否把task在等待队列中的时间视为busy time;
非running非runnable不统计。
-
-
38.排除以上情况,默认是需要更新的。
2) update_history(rq, p, runtime, samples, event)
WALT记录了task 5个历史窗口运行时间。在event跨窗口时统计task busy time,因为产生了新的历史窗口, 需要对task历史窗口runtime进行滚动更新。使用wts->cidx作为hist[]数组中current window的索引,通过更新索引值达到滚动更新历史信息。这里的runtime,是task在被更新窗口内的runtime,即wts->sum。当跨越并更新full window时,为window_size(16ms)的相对runtime(大小取决于当前频点计算出的wrq->task_exec_scale)。

static void update_history(struct rq *rq, struct task_struct *p,
u32 runtime, int samples, int event)
{
runtime_scaled = scale_time_to_util(runtime);
/* Push new 'runtime' value onto stack */
for (; samples > 0; samples--) {
hist[wts->cidx] = runtime;
hist_util[wts->cidx] = runtime_scaled;
wts->cidx = ++(wts->cidx) % RAVG_HIST_SIZE;
}
wts->demand的计算策略
| WINDOW_STATS_RECENT | 取上一窗的wts->sum作为demand |
| WINDOW_STATS_MAX | 取5个历史窗口中最大值作为task demand |
| WINDOW_STATS_MAX_RECENT_AVG | 取 max{5个历史窗口的平均值,上一窗的wts->sum},作为task demand |
| WINDOW_STATS_AVG | 取5个窗口的平均值作为task demnad |
如何计算predict task demand?
static inline u16 predict_and_update_buckets(
struct task_struct *p, u16 runtime_scaled) {
int bidx;
u32 pred_demand_scaled;
struct walt_task_struct *wts = (struct walt_task_struct *) p->android_vendor_data1;
bidx = busy_to_bucket(runtime_scaled);
pred_demand_scaled = get_pred_busy(p, bidx, runtime_scaled, wts->bucket_bitmask);
bucket_increase(wts->busy_buckets, &wts->bucket_bitmask, bidx);
return pred_demand_scaled;
}
在调用update_history更新task的历史runtime后,会调用get_pred_busy()预测task的runtime,即未来task对cpu能力的需求。把0~1024的scaled runtime划分为16个buckets,每个buckets对应64 util,把要更新的runtime_scaled通过busy_to_bucket映射到对应的bucket id,作为起始start bucket id,根据wts->bucket_bitmask, 向上寻找第一个置位的bit n, 表示在之前的窗口, task的runtime落到这个bit所对应的busy_buckets[n],这是一个busy bucket。如果hist_util[5]记录的5个最近历史window的task runtime有落在这个busy_buckets[n]范围内的(例如hist_util[m]), 则这个hist_util[m]作为预测的task predict demand返回。

如何更新wts->bucket_bitmask及busy_buckets[bidx]?
#define INC_STEP 8
#define DEC_STEP 2
#define CONSISTENT_THRES 16
#define INC_STEP_BIG 16
static inline void bucket_increase(u8 *buckets, u16 *bucket_bitmask, int idx)
{
int i, step;
for (i = 0; i < NUM_BUSY_BUCKETS; i++) {
if (idx != i) {
if (buckets[i] > DEC_STEP)
buckets[i] -= DEC_STEP;
else {
buckets[i] = 0;
*bucket_bitmask &= ~BIT_MASK(i);
}
} else {
step = buckets[i] >= CONSISTENT_THRES ?
INC_STEP_BIG : INC_STEP;
if (buckets[i] > U8_MAX - step)
buckets[i] = U8_MAX;
else
buckets[i] += step;
*bucket_bitmask |= BIT_MASK(i);
}
}
}

wts->bucket_bitmask的16个bit位对应16个busy_buckets,表示对应的bucket是否还处于busy状态。处于busy状态的bucket会在计算task的predict demand时被选中。当调用update_history更新task的历史负载时,需要更新进历史窗口的task scaled runtime通过busy_to_bucket(runtime_scaled)获取到runtime_scaled所属的bucket id(参数idx),并将bucket_bitmask中的对应的bit置位,表示task在历史窗口的runtime曾经落在这个bucket,表征了task在历史窗口中运行的大小特性。每次调用update_history更新的runtime,runtime落在的bucket,对应的busy_buckets[bidx]值会步进增加,其它busy_buckets则会衰减,当衰减到小于DEC_STEP时,busy_buckets[i]被清零,对应的bit mask被清除。这样busy_buckets[bidx]就反映了近期task runtime特征,值越大表明task在历史窗口的负载越多的落在这个bucket。bucket_bitmask[bit_n]=0表示task的runtime已经很久没有落在这个bucket区间了。目前bucket_bitmask[bidx]的值除了步进或衰减以设置或清除bucket_bitmask ,没有其它用途。
3) add_to_task_demand(struct rq *rq, struct task_struct *p, u64 delta)
static u64 add_to_task_demand(struct rq *rq, struct task_struct *p, u64 delta)
{
struct walt_task_struct *wts = (struct walt_task_struct *) p->android_vendor_data1;
delta = scale_exec_time(delta, rq, wts);
wts->sum += delta;
if (unlikely(wts->sum > sched_ravg_window))
wts->sum = sched_ravg_window;
return delta;
}
当前窗口task busy time统计,把实际运行时间delta按cpu当前频率和capacity归一化到最大capacity cpu上最高频率运行的时长。累加到到wts->sum。wts->sum最大值为sched_ravg_window,即16ms。在event跨窗口时调用update_history归0,从新开始统计新窗口task的相对运行时间。参考wts.sum。
2. 如何更新cpu负载信息
update_cpu_busy_time是cpu负载信息更新核心函数, 将task runningtime或irqtime更新到:
wrq->grp_time->curr/prev_runnable_sum
wrq->grp_time->nt_curr/prev_runnable_sum
wts->curr/prev_window
wts->curr/prev_window_cpu[cpu]
task属于grp时才更grp_time对应的 sum,irq只更新到wrq对应的sum。
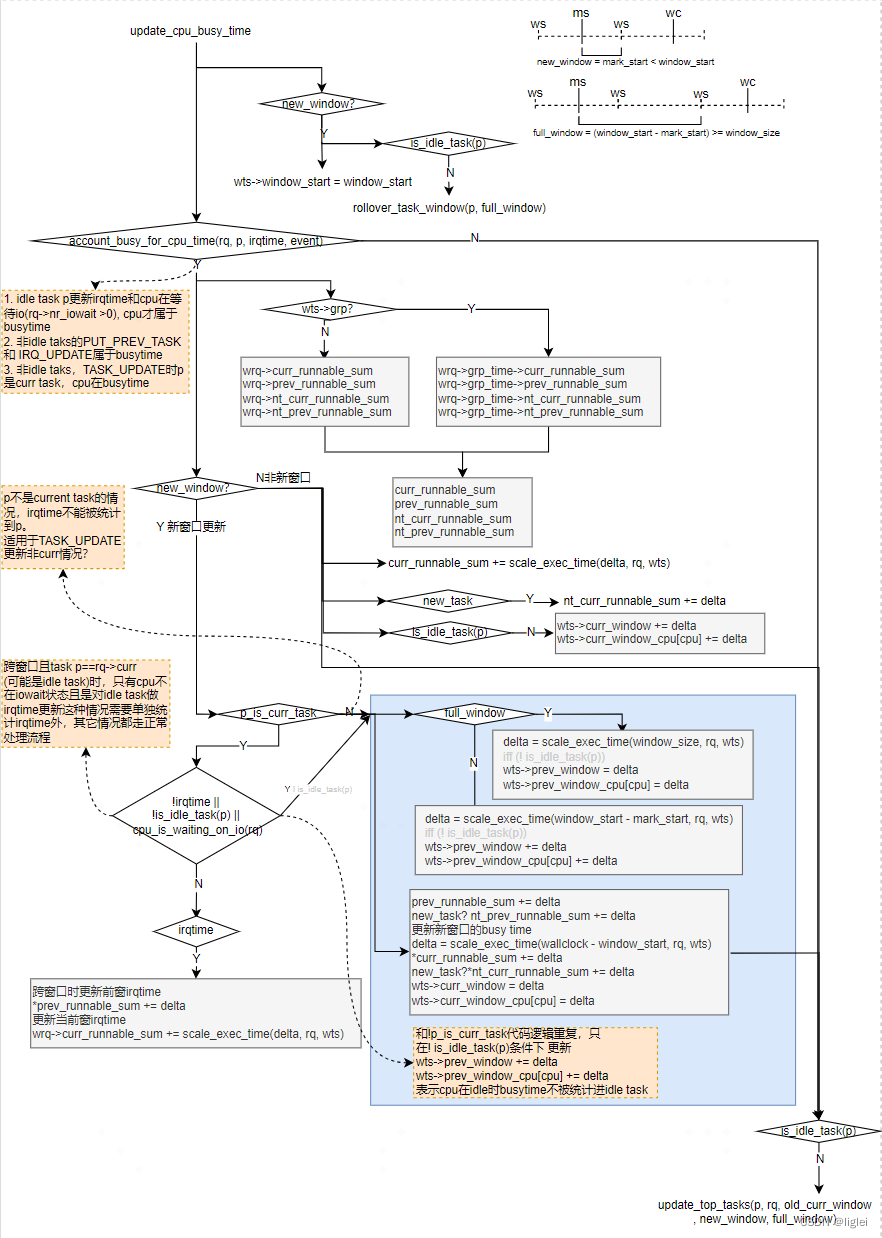
关键函数包括:
1) rollover_task_window(p, full_window)
如果非idle task跨窗口 ,需要将curr_window赋值给prev_window, rollover_task_window task的runtime统计:
wts->curr/prev_window
wts->curr/prev_window_cpu[i]
wts->active_time
static void rollover_task_window(struct task_struct *p, bool full_window)
{
u32 *curr_cpu_windows = empty_windows;
u32 curr_window;
int i;
struct walt_rq *wrq = &per_cpu(walt_rq, cpu_of(task_rq(p)));
struct walt_task_struct *wts = (struct walt_task_struct *) p->android_vendor_data1;
/* Rollover the sum */
curr_window = 0;
if (!full_window) {
curr_window = wts->curr_window;
curr_cpu_windows = wts->curr_window_cpu;
}
wts->prev_window = curr_window;
wts->curr_window = 0;
/* Roll over individual CPU contributions */
for (i = 0; i < nr_cpu_ids; i++) {
wts->prev_window_cpu[i] = curr_cpu_windows[i];
wts->curr_window_cpu[i] = 0;
}
if (is_new_task(p))
wts->active_time += wrq->prev_window_size;
}
3 10 17 22.当经历一个完整窗口,表示可能存在异常,前窗清零:
wts->prev_window=0,
wts->prev_window_cpu[i]=0
13 14 17 22. 当只是跨一个窗口,更新:
wts->prev_window = wts->curr_window
wts->prev_window_cpu[i] = wts->curr_window_cpu[i]
18 23.wts->curr_window和wts->curr_window_cpu[i]在跨窗口时会被重置为0
2) account_busy_for_cpu_time(rq, p, irqtime, event)
walt_update_task_ravg->update_cpu_busy_time->account_busy_for_cpu_time
static int account_busy_for_cpu_time(struct rq *rq, struct task_struct *p,
u64 irqtime, int event)
{
if (is_idle_task(p)) {
/* TASK_WAKE && TASK_MIGRATE is not possible on idle task! */
if (event == PICK_NEXT_TASK)
return 0;
/* PUT_PREV_TASK, TASK_UPDATE && IRQ_UPDATE are left */
return irqtime || cpu_is_waiting_on_io(rq);
}
if (event == TASK_WAKE)
return 0;
if (event == PUT_PREV_TASK || event == IRQ_UPDATE)
return 1;
/*
* TASK_UPDATE can be called on sleeping task, when its moved between
* related groups
*/
if (event == TASK_UPDATE) {
if (rq->curr == p)
return 1;
return p->on_rq ? SCHED_FREQ_ACCOUNT_WAIT_TIME : 0;
}
/* TASK_MIGRATE, PICK_NEXT_TASK left */
return SCHED_FREQ_ACCOUNT_WAIT_TIME;
}
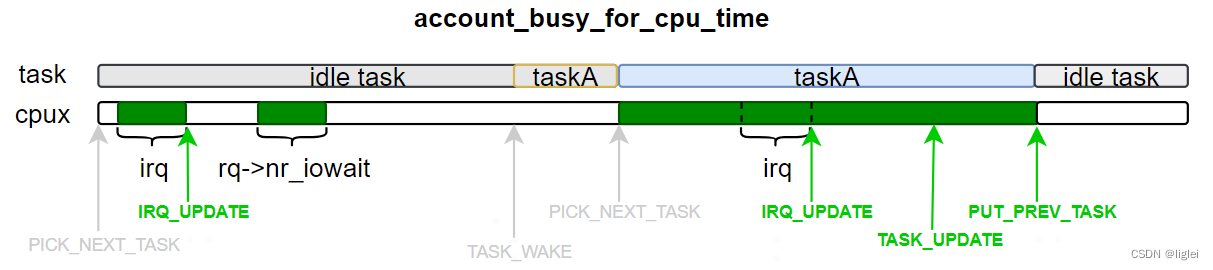
4.先看task是否是idle task。对于非idle task,再根据event具体判断cpu的busy time
10.p是idle task, 此时只有更新irqtime和cpu在等待io(rq->nr_iowait >0), cpu才属于busytime
13.非idle task的TASK_WAKE event发生时,cpu不是busytime
16.非idle taks的PUT_PREV_TASK 和 IRQ_UPDATE属于busytime
23.非idle taks,TASK_UPDATE时
24.p是curr task,cpu在busytime
27.p不是curr task,但是在runqueue的wait list中,取决于是否设置了SCHED_FREQ_ACCOUNT_WAIT_TIME
27.p不是curr task,也不是runnable状态,cpu不在busytime
31.非idle task,TASK_MIGRATE, PICK_NEXT_TASK对cpu来说,取决于是否设置了SCHED_FREQ_ACCOUNT_WAIT_TIME
3) update_top_tasks(p, rq, old_curr_window, new_window, full_window)
调用路径:
walt_update_task_ravg->update_cpu_busy_time->update_top_tasks
这里的old_curr_window是此次更新前的wts->curr_window。此函数作用是在更新
wrq->top_tasks[curr/prev],
wrq->top_tasks_bitmap[curr/prev]
wrq->top_tasks[2]是两个指针的指针数组,分别记录task在curr和prev window的相对runtime。分别指向1000个u8类型的mem, 即把0~16ms分成1000个buckets,每个bucket为16us。task在curr/prev window的相对runtime如果落在某个bucket,对应bucket的值+1,当bucket值等于1时,置位对应的top_tasks_bitmap位,表示此bucket为busy bucket。当bucket值从1变为0时,clear对应的top_tasks_bitmap位,表示此bucket为非busy bucket。
static void update_top_tasks(struct task_struct *p, struct rq *rq,
u32 old_curr_window, int new_window, bool full_window)
{
struct walt_rq *wrq = &per_cpu(walt_rq, cpu_of(rq));
struct walt_task_struct *wts = (struct walt_task_struct *) p->android_vendor_data1;
u8 curr = wrq->curr_table;
u8 prev = 1 - curr;
u8 *curr_table = wrq->top_tasks[curr];
u8 *prev_table = wrq->top_tasks[prev];
int old_index, new_index, update_index;
u32 curr_window = wts->curr_window;
u32 prev_window = wts->prev_window;
bool zero_index_update;
if (old_curr_window == curr_window && !new_window)
return;
old_index = load_to_index(old_curr_window);
new_index = load_to_index(curr_window);
if (!new_window) {
zero_index_update = !old_curr_window && curr_window;
if (old_index != new_index || zero_index_update) {
if (old_curr_window)
curr_table[old_index] -= 1;
if (curr_window)
curr_table[new_index] += 1;
if (new_index > wrq->curr_top)
wrq->curr_top = new_index;
}
if (!curr_table[old_index])
__clear_bit(NUM_LOAD_INDICES - old_index - 1,
wrq->top_tasks_bitmap[curr]);
if (curr_table[new_index] == 1)
__set_bit(NUM_LOAD_INDICES - new_index - 1,
wrq->top_tasks_bitmap[curr]);
return;
}
没跨窗口
21.没跨窗口,更新前的wts->curr_window是0,当前非0,表示task在这个window里第一次被统计
23.如果此次更新task的runtime发生了变化,或者是第一次被统计busy time
25.curr_table指向1000个u8类型的mem, 更新前task runtime所属bucket id即为old_index,因为在同一window中发生了再次更新,原来task runtime落在的curr_table[old_index]减一,当前task runtime落在的curr_table[new_index]加一。
跨一个或多个窗口
/*
* The window has rolled over for this task. By the time we get
* here, curr/prev swaps would has already occurred. So we need
* to use prev_window for the new index.
*/
update_index = load_to_index(prev_window);
if (full_window) {
/*
* Two cases here. Either 'p' ran for the entire window or
* it didn't run at all. In either case there is no entry
* in the prev table. If 'p' ran the entire window, we just
* need to create a new entry in the prev table. In this case
* update_index will be correspond to sched_ravg_window
* so we can unconditionally update the top index.
*/
if (prev_window) {
prev_table[update_index] += 1;
wrq->prev_top = update_index;
}
if (prev_table[update_index] == 1)
__set_bit(NUM_LOAD_INDICES - update_index - 1,
wrq->top_tasks_bitmap[prev]);
} else {
zero_index_update = !old_curr_window && prev_window;
if (old_index != update_index || zero_index_update) {
if (old_curr_window)
prev_table[old_index] -= 1;
prev_table[update_index] += 1;
if (update_index > wrq->prev_top)
wrq->prev_top = update_index;
if (!prev_table[old_index])
__clear_bit(NUM_LOAD_INDICES - old_index - 1,
wrq->top_tasks_bitmap[prev]);
if (prev_table[update_index] == 1)
__set_bit(NUM_LOAD_INDICES - update_index - 1,
8.跨多个窗口
25.跨一个窗口
top task的使用
waltgov_update_freq->waltgov_get_util(wg_cpu)->cpu_util_freq_walt()->__cpu_util_freq_walt()->
util = scale_time_to_util(freq_policy_load(rq, reason))
wrq->util = util->
freq_policy_load(rq, reason)->tt_load = top_task_load(rq)
WALT在调频获取cpu的util时, 会使用top task load:
freq_policy_load->tt_load = top_task_load(rq)
tt_load = (wrq->prev_top + 1) * sched_load_granule
这里的wrq->prev_top表示前窗中,最大相对runtime时长的task,落在1000个bucket中的index值。
551 /*
552 * Special case the last index and provide a fast path for index = 0.
553 * Note that sched_load_granule can change underneath us if we are not
554 * holding any runqueue locks while calling the two functions below.
555 */
556 static u32 top_task_load(struct rq *rq)
557 {
558 struct walt_rq *wrq = &per_cpu(walt_rq, cpu_of(rq));
559 int index = wrq->prev_top;
560 u8 prev = 1 - wrq->curr_table;
561
562 if (!index) {
563 int msb = NUM_LOAD_INDICES - 1;
564
565 if (!test_bit(msb, wrq->top_tasks_bitmap[prev]))
566 return 0;
567 else
568 return sched_load_granule;
569 } else if (index == NUM_LOAD_INDICES - 1) {
570 return sched_ravg_window;
571 } else {
572 return (index + 1) * sched_load_granule;
573 }
574 }
- packing cpu
walt_find_and_choose_cluster_packing_cpu
1068 /* walt_find_and_choose_cluster_packing_cpu - Return a packing_cpu choice common for this cluster.
1069 * @start_cpu: The cpu from the cluster to choose from
1070 *
1071 * If the cluster has a 32bit capable cpu return it regardless
1072 * of whether it is halted or not.
1073 *
1074 * If the cluster does not have a 32 bit capable cpu, find the
1075 * first unhalted, active cpu in this cluster.
1076 *
1077 * Returns -1 if packing_cpu if not found or is unsuitable to be packed on to
1078 * Returns a valid cpu number if packing_cpu is found and is usable
1079 */
1080 static inline int walt_find_and_choose_cluster_packing_cpu(int start_cpu, struct task_struct *p)
1081 {
1082 struct walt_rq *wrq = &per_cpu(walt_rq, start_cpu);
1083 struct walt_sched_cluster *cluster = wrq->cluster;
1084 cpumask_t unhalted_cpus;
1085 int packing_cpu;
1086
1087 /* if idle_enough feature is not enabled */
1088 if (!sysctl_sched_idle_enough)
1089 return -1;
1090 if (!sysctl_sched_cluster_util_thres_pct)
1091 return -1;
1092
1093 /* find all unhalted active cpus */
1094 cpumask_andnot(&unhalted_cpus, cpu_active_mask, cpu_halt_mask);
1095
1096 /* find all unhalted active cpus in this cluster */
1097 cpumask_and(&unhalted_cpus, &unhalted_cpus, &cluster->cpus);
1098
1099 if (is_compat_thread(task_thread_info(p)))
1100 /* try to find a packing cpu within 32 bit subset */
1101 cpumask_and(&unhalted_cpus, &unhalted_cpus, system_32bit_el0_cpumask());
1102
1103 /* return the first found unhalted, active cpu, in this cluster */
1104 packing_cpu = cpumask_first(&unhalted_cpus);
1105
1106 /* packing cpu must be a valid cpu for runqueue lookup */
1107 if (packing_cpu >= nr_cpu_ids)
1108 return -1;
1109
1110 /* if cpu is not allowed for this task */
1111 if (!cpumask_test_cpu(packing_cpu, p->cpus_ptr))
1112 return -1;
1113
1114 /* if cluster util is high */
1115 if (sched_get_cluster_util_pct(cluster) >= sysctl_sched_cluster_util_thres_pct)
1116 return -1;
1117
1118 /* if cpu utilization is high */
1119 if (cpu_util(packing_cpu) >= sysctl_sched_idle_enough)
1120 return -1;
1121
1122 /* don't pack big tasks */
1123 if (task_util(p) >= sysctl_sched_idle_enough)
1124 return -1;
1125
1126 if (task_reject_partialhalt_cpu(p, packing_cpu))
1127 return -1;
1128
1129 /* don't pack if running at a freq higher than 43.9pct of its fmax */
1130 if (arch_scale_freq_capacity(packing_cpu) > 450)
1131 return -1;
1132
1133 /* the packing cpu can be used, so pack! */
1134 return packing_cpu;
1135 }
代码看起来是的,
1. 首先要设置sysctl_sched_idle_enough, 表示让cpu尽可能进入idle状态,packing才会生效;
2. 在start cpu对应的cluster里,考虑cpu_active_mask,cpu_halt_mask,如果是32位进程考虑支持32位进程的cpu mask system_32bit_el0_cpumask, 考虑task的cpu affinity p->cpus_ptr。在符合这些条件的cpu中找packing cpu。
3. 检查cluster的cpu使用率(前一个window)是否大于sysctl_sched_cluster_util_thres_pct(40), 只有cluster负载轻时才packing
4. 检查找到的packing cpu的cpu util是否大于sysctl_sched_idle_enough(30), 只有cpu的util小于30时才能被选座packing cpu。
5. 检查将要packing的task的util是否大于sysctl_sched_idle_enough(30),只有task util小于30的小task才能packing
6. 检查packing cpu是否能是partial halt cpu(加入uifirst和 frameboost检查)
7. 检查packing cpu当前频点的freq_scale是否小于450. 要求packing cpu的当前要处在较低频点。freq_scale=1024*(cpu_curr_freq/cpu_max_freq)