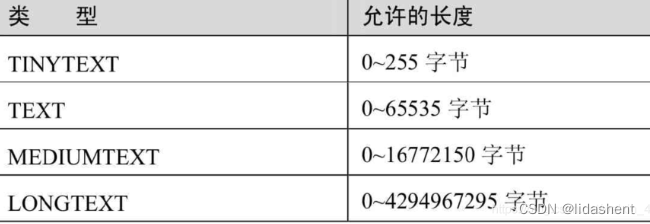
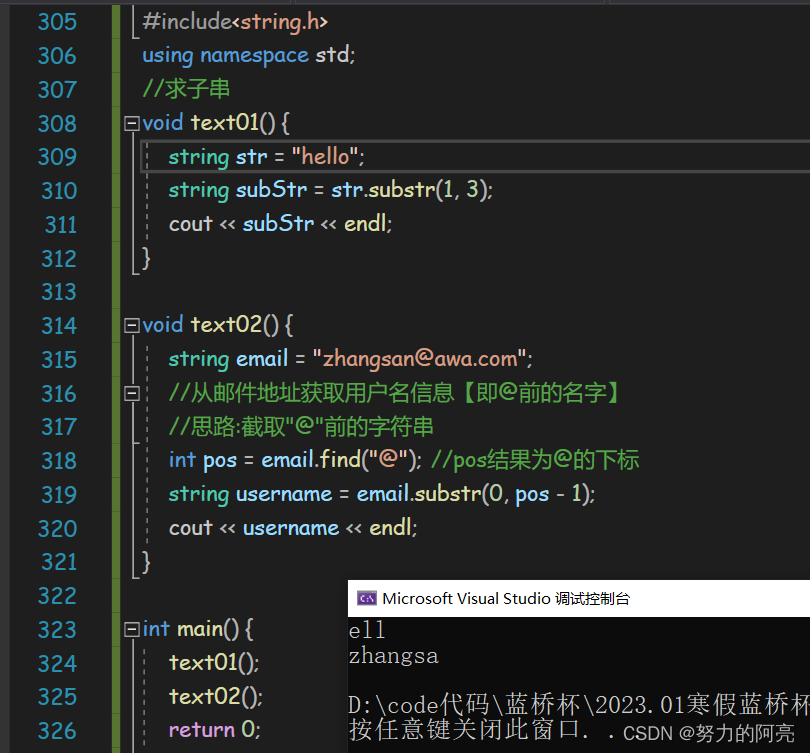
ASCII字符集、GBK字符集、Unicode字符集
这里我直接上总结了,关于这三种字符集的基本介绍大家可以百度一下。
- 在计算机中,任意数据都是以二进制的形式来存储的
- 计算机中最小的存储单元是一个字节
- ASCII字符集中,一个英文占一个字节
- 简体中文版Windows,默认使用GBK字符集
- GBK字符集完全兼容ASCII字符集
一个英文占一个字节,二进制第一位是0
一个中文占两个字节,二进制高位字节的第一位是1 - Unicode字符集的UTF-8编码格式
一个英文占一个字节,二进制第一位是0,转成十进制是正数
一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数
使用字节流读取数据为什么会有乱码?
- 原因一:读取数据时未读完整个汉字
- 原因二:编码和解码时的方式不统一
如何解决?
- 不要用字节流读取文本文件
- 编码解码时使用同一个码表,同一个编码方式
Java中编码的方法

Java中解码的方法

代码演示:
package com.liming.charset;
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
public class CharSetDemo {
public static void main(String[] args) throws UnsupportedEncodingException {
//编码
String str = "ai你呦";
byte[] bytes = str.getBytes();//默认不写UTF-8
System.out.println(Arrays.toString(bytes));
byte[] bytes1 = str.getBytes("GBK");
System.out.println(Arrays.toString(bytes1));
//解码
String str2 = new String(bytes);
System.out.println("默认编码方式:" + str2);
String str3 = new String(bytes1,"GBK");
System.out.println("GBK编码方式:" + str3);
}
}
运行效果图: