官网参考地址: 官网UDF - Apache Hive
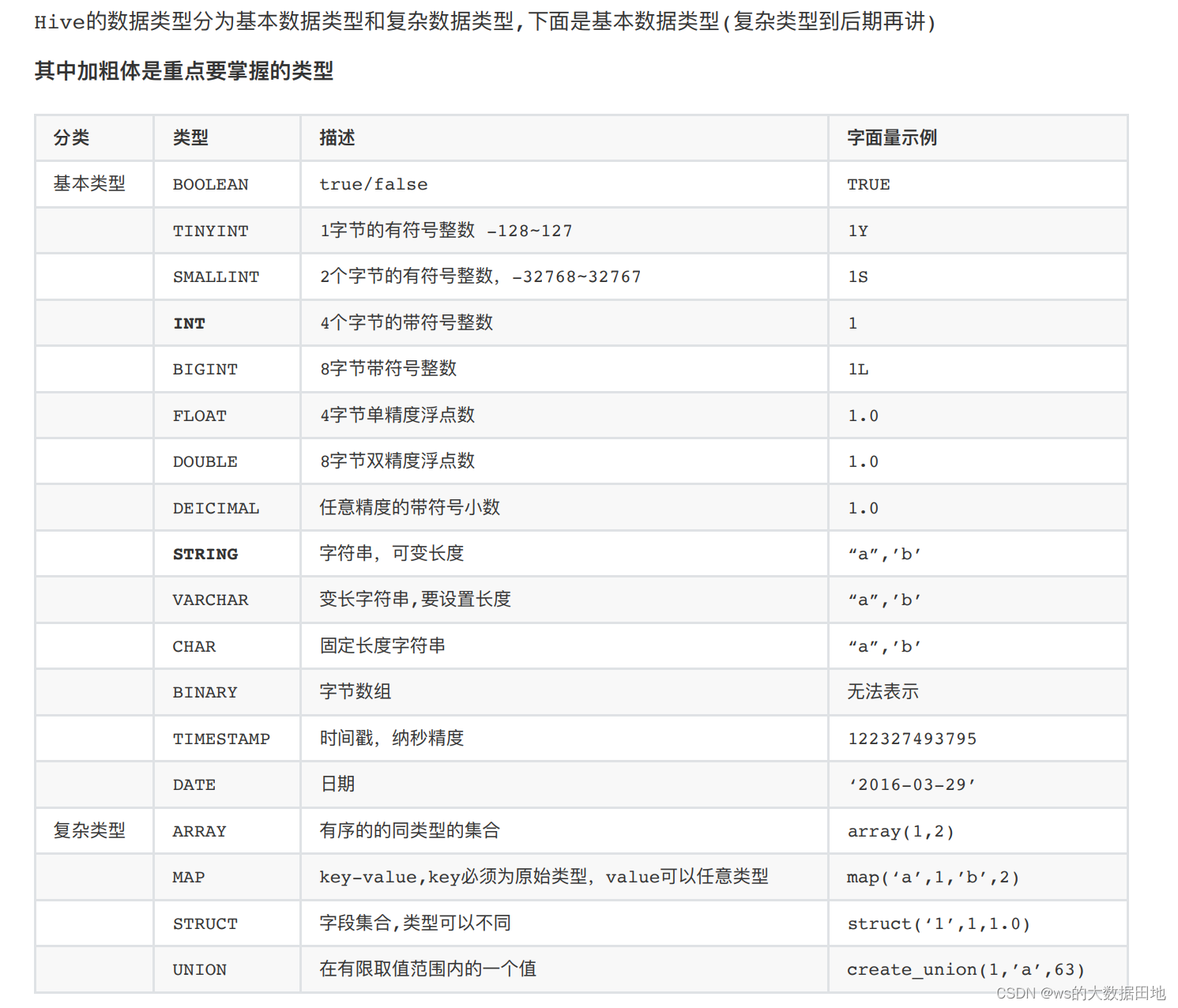
1. 基本数据类型
2. 基础运算符与函数
| SQL | 结果 |
|---|---|
| A IS NULL | 空 |
| A IS NOT NULL | 非空 |
| A LIKE B | 模糊匹配 |
| A RLIKE B | 正则表达式匹配 |
| A REGEXP B | 正则表达式匹配 |
3. 类型转换
cast(expr as <type>)
例如:
cast('1' as BIGINT) 将字符串'1'转化成bigint型
4. 日期函数
| 返回值类型 | 名称 | 描述 |
|---|---|---|
| string | from_unixtime(int unixtime) | 将时间戳(unix epoch秒数)转换为日期时间字符串, 例如from_unixtime(0)="1970-01-01 00:00:00" |
| bigint | unix_timestamp() | 获得当前时间戳 |
| bigint | unix_timestamp(string date) | 获得date表示的时间戳 |
| bigint | to_date(string timestamp) | 返回日期字符串, 例如to_date("1970-01-01 00:00:00") = "1970-01-01" |
| string | year(string date) | 返回年,例如year("1970-01-01 00:00:00") = 1970,year("1970-01-01") = 1970 |
| int | month(string date) | |
| int | day(string date) dayofmonth(date) | |
| int | hour(string date) | |
| int | minute(string date) | |
| int | second(string date) | |
| int | weekofyear(string date) | |
| int | datediff(string enddate, string startdate) | 返回enddate和startdate的天数的差,例如datediff('2009-03-01', '2009-02-27') = 2 |
| int | date_add(string startdate, int days) | 加days天数到startdate: date_add('2008-12-31', 1) = '2009-01-01' |
| int | date_sub(string startdate, int days) | 减days天数到startdate: date_sub('2008-12-31', 1) = '2008-12-30' |
5. 条件函数
| 返回值 | 名称 | 描述 |
|---|---|---|
| - | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 当testCondition为真时返回valueTrue,testCondition为假或NULL时返回valueFalseOrNull |
| - | COALESCE(T v1, T v2, ...) | 返回列表中的第一个非空元素,如果列表元素都为空则返回NULL |
| - | CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | a = b,返回c;a = d,返回e;否则返回f |
| - | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | a 为真,返回b;c为真,返回d;否则e |
例如:
(
case
when category = '1512' then reserve_price > cast(1000 as double)
when category = '1101' then reserve_price > cast(2500 as double)
else reserve_price > cast(10 as double)
end
)
6. 常用字符串函数
| 返回类型 | 函数 | 说明 |
| int | length(string A) | 返回字符串的长度 |
| string | reverse(string A) | 返回倒序字符串 |
| string | concat(string A, string B…) | 连接多个字符串,合并为一个字符串,可以接受任意数量的输入字符串 |
| string | concat_ws(string SEP, string A, string B…) | 链接多个字符串,字符串之间以指定的分隔符分开。 |
| string | substr(string A, int start) substring(string A, int start) | 从文本字符串中指定的起始位置后的字符。 |
| string | substr(string A, int start, int len) substring(string A, int start, int len) | 从文本字符串中指定的位置指定长度的字符。 |
| string | upper(string A) ucase(string A) | 将文本字符串转换成字母全部大写形式 |
| string | lower(string A) lcase(string A) | 将文本字符串转换成字母全部小写形式 |
| string | trim(string A) | 删除字符串两端的空格,字符之间的空格保留 |
| string | ltrim(string A) | 删除字符串左边的空格,其他的空格保留 |
| string | rtrim(string A) | 删除字符串右边的空格,其他的空格保留 |
| string | regexp_replace(string A, string B, string C) | 字符串A中的B字符被C字符替代 |
| string | regexp_extract(string subject, string pattern, int index) | 通过下标返回正则表达式指定的部分。regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) returns ‘bar.’ |
| string | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 返回URL指定的部分。parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1′, ‘HOST’) 返回:’facebook.com’ |
| string | get_json_object(string json_string, string path) | select a.timestamp, get_json_object(a.appevents, ‘$.eventid’), get_json_object(a.appenvets, ‘$.eventname’) from log a; JSON解析 |
| string | space(int n) | 返回指定数量的空格 |
| string | repeat(string str, int n) | 重复N次字符串 |
| int | ascii(string str) | 返回字符串中首字符的数字值 |
| string | lpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从左侧填补。 |
| string | rpad(string str, int len, string pad) | 返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从右侧填补。 |
| array | split(string str, string pat) | 将字符串转换为数组。 |
7. 创建表
CREATE TABLE IF NOT EXISTS table_name
(
--field def
)
PARTITIONED BY (pt string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '...';
注意:如果不是外表部,drop table的时候会将HDFS上文件删除。
8. 创建外部表
CREATE EXTERNAL TABLE dm_all_cpv_assoc (
--field def
)
PARTITIONED BY (pt string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\1' 字段分隔符
LINES TERMINATED BY '\2' 行分隔符
STORED AS TEXTFILE
LOCATION '...';
注意:在删除外部表的时候,不会删除HDFS上的关联文件。
9. 添加分区(二级分区)
ALTER TABLE table_name ADD PARTITION (dt='2008-08-08', country='us')
location '/path/to/us/part080808' PARTITION (dt='2008-08-09', country='us')
location '/path/to/us/part080809';
10. 删除分区(二级分区)
ALTER TABLE table_name DROP PARTITION (dt='2008-08-08', country='us');
11. 导入数据
a. insert overwrite table table_name partition (pt = '20110323000000')
select ... from ...
b. LOAD DATA LOCAL INPATH 'test.dat' OVERWRITE INTO table yahoo_music partition (pt=xxx);
12. 查询数据
SELECT, JOIN, LIMIT
13. 添加UDF
add jar /home/hive/jar/my_udf.jar;
create temporary function sys_date as 'com.taobao.hive.udf.UDFDateSysdate';
14. 设置reducer数量
限制最大reducer数:set hive.exec.reducers.max=15;
设置固定的reducer数:set mapred.reduce.tasks=15;








](https://img-blog.csdnimg.cn/img_convert/76408924b9cd997d72ed328d5b07fe5b.jpeg)