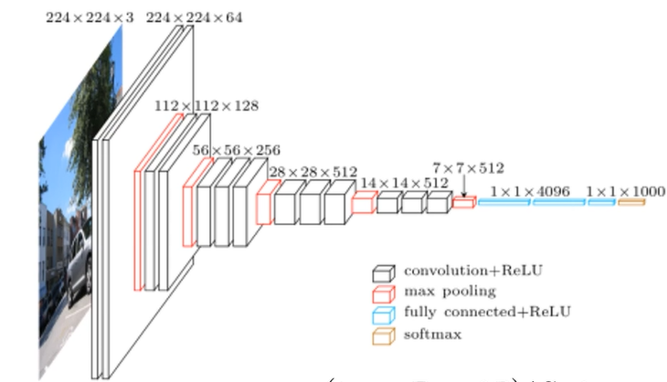
卷积神经网络进阶
b站课程链接碳基生物都能学会的神经网络(跳着看的)
因为我用的是pytorch,而该课程是用tenserflow的,所以主要记了一下理论
为什么要讲不同的网络结构
- 不同的网络结构解决的问题不同
- 不同的网络结构使用的技巧不同
- 不同的神经网络有不同的子手段
- 可以借鉴到其他的神经网络上
- 不同的网络结构应用的场景不同
- 比如在移动端上的要求运行快,服务器端就没有这么多要求
模型的进化
-
更深更宽
- ALexNet->VGGNet
-
不同的模型结构
- VGG->InceptionNet/ResNet
-
优势组合
- Inception+Res=InceptionResNet
-
自我学习
- 强化学习,不是人设计,是模型自学习出结构
- NASNet
-
实用
- MobileNet
ALexNet
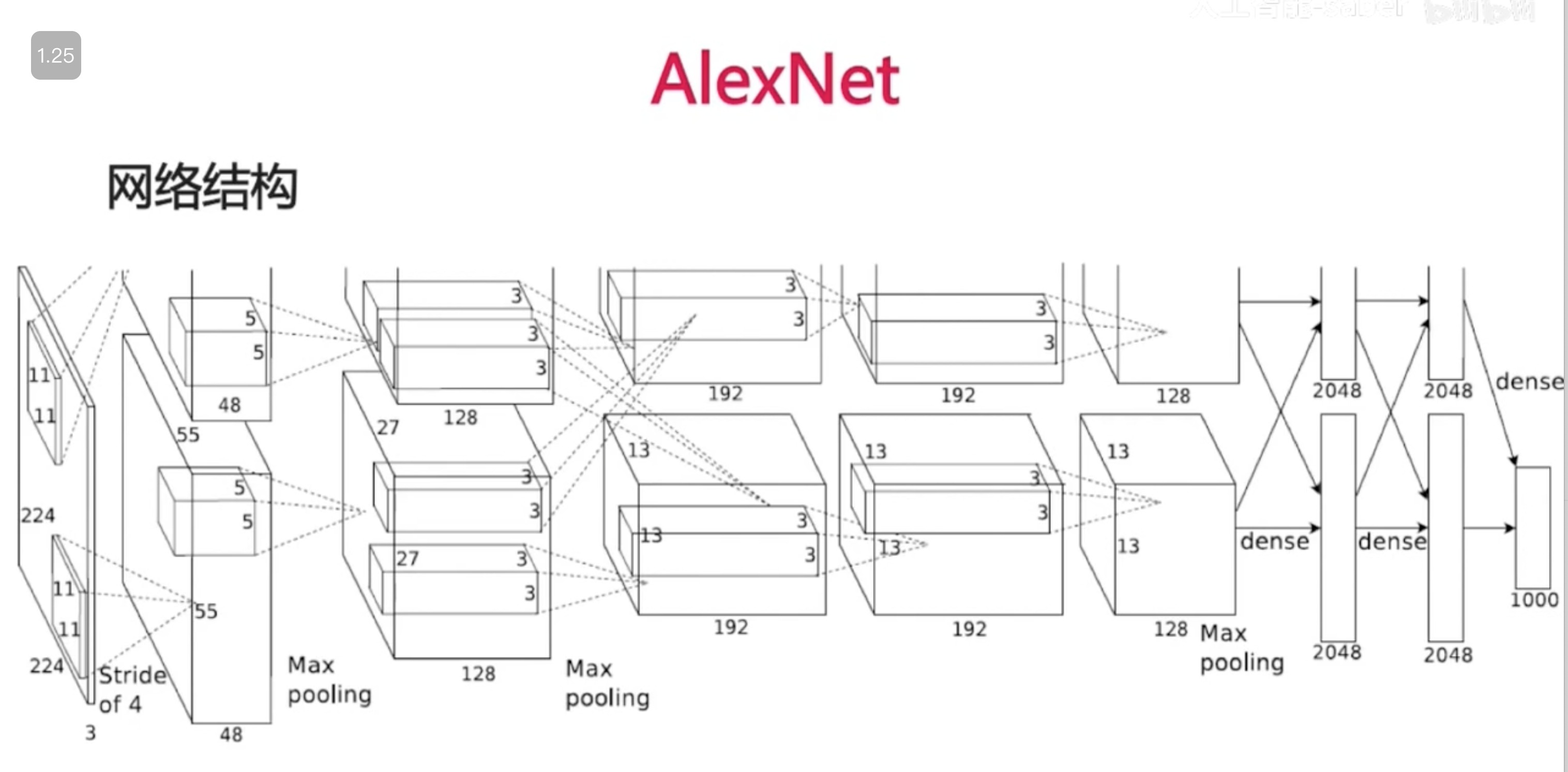
- 5个卷积层 3个全链接层
- 2个GPU使得神经网络更大,且训练的更快

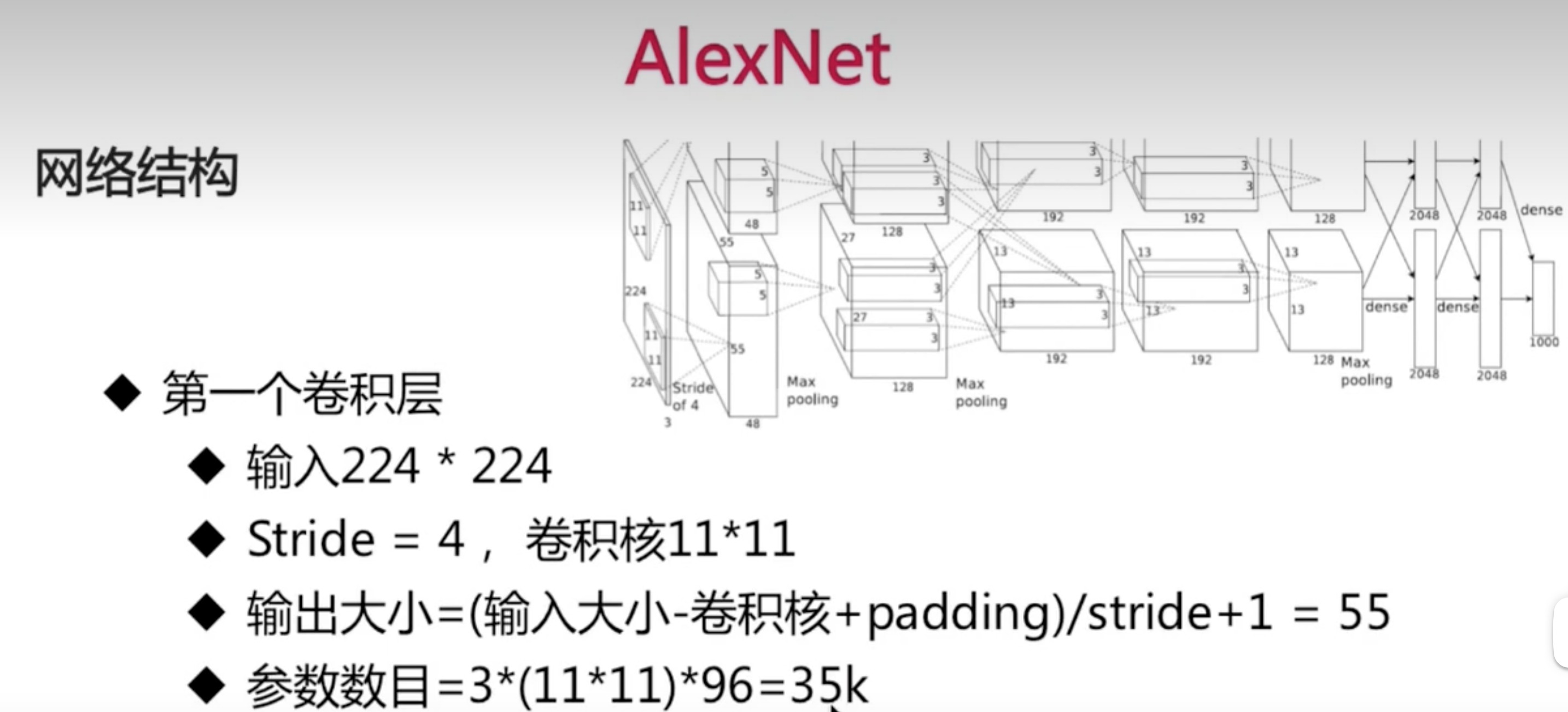
-
padding自行选择添加
-
参数数目就是卷积核的大小*输入通道数*输出通道数
-
其网络结构可以借鉴的东西
- 首次使用Relu:训练的速度非常快
- 2—GPU的并行结构
- 1,2,5卷积层后跟随max-pooling
- 有全链接层的dropout
- 全链接层参数占全部参数数目的大部分,容易过拟合
-
并不一定所有的卷积后面都要加池化层
- 使用了stride也可以做到输出size减小
-
dropout原理解释
- 组合解释
- 每次dropout都相当于训练了一个子网络
- 最后的结果相当于很多子网络组合
- 动机解释
- 消除了神经单元之间的依赖,增强泛化能力
- 数据解释
- 对于dropout后的结果,总能找到一个结果与其对应
- 数据增强
- 组合解释
-
网络结构其他细节
- 数据增强,图片随机采样
- [256,256] 采样 [224,224]
- Dropout=0.5
- Batch size=128
- SGD momentum = 0.9
- Learning rate=0.01 过一定次数降低为1/10
- (训练多个模型做投票)7个CNN做ensemble:18.2%->15.4%
- 数据增强,图片随机采样
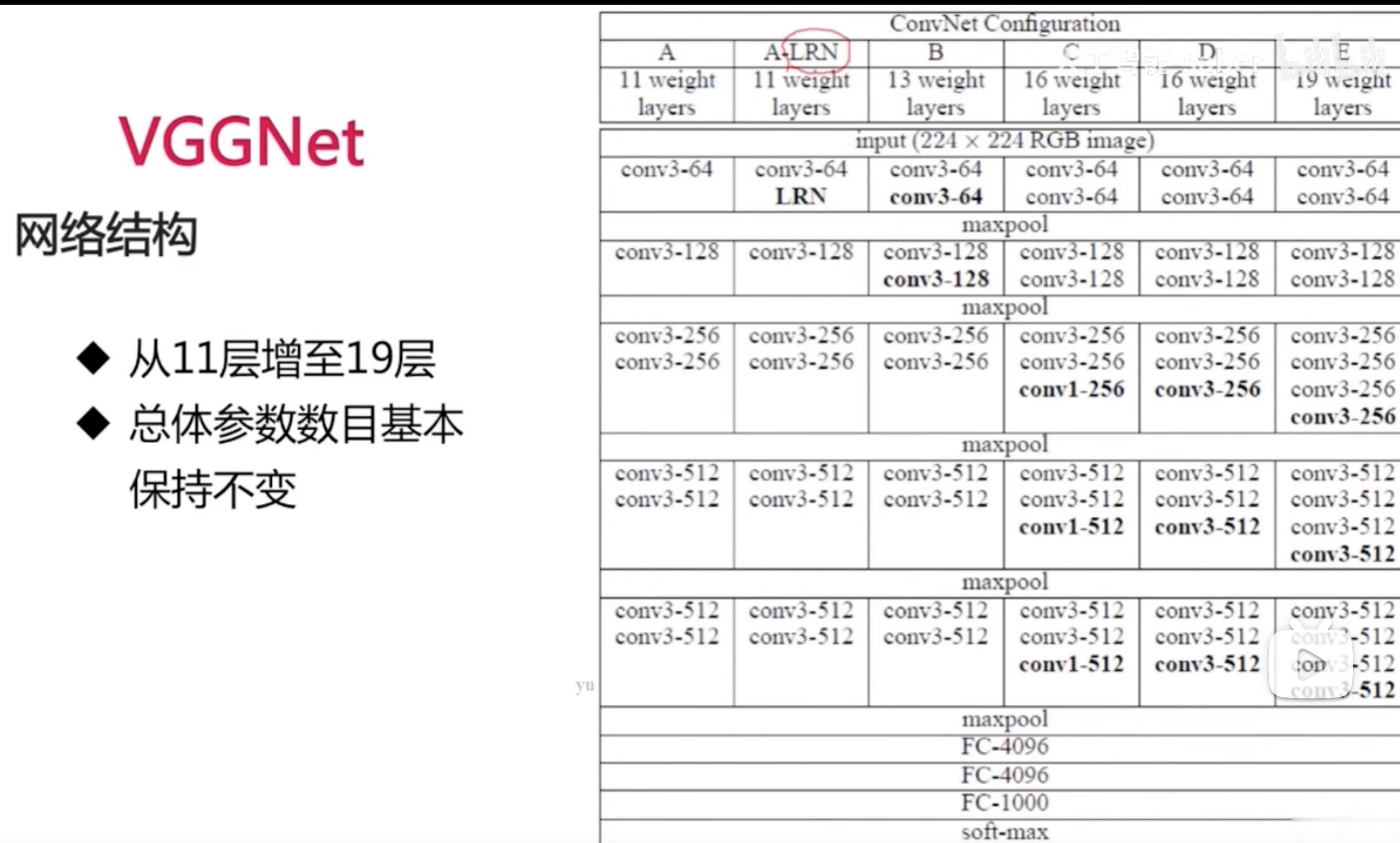
VGGNet
- 网络结构
- 更深
- 多使用3*3的卷积核
- 2个3*3的卷积层可以看作一层5*5的卷积层
- 3个3*3的卷积层可以看作一层7*7的卷积层
- 1*1的卷积层可以看作是非线性变换
- 每经过一个pooling层,通道数目翻倍,因为会丢失特征,所以这样丢失的比较少
- 网络结构——视野域

从下往上看,发现2个3*3的卷积核和1个5*5最后输出都是一样的size。但是多一层激活函数,参数少,效果更好
-
网络结构——1*1
- 多使用1*1的卷积核
- 根据公式,使用1*1的卷积核输入输出size不变,但在通道数上实现了降维,在加多个卷积核的情况下也不损失信息
- 1*1的卷积核相当于一次非线性变换
-
VGGNet
- LRN:局部归一化,比如他和周围五层做归一化
- 在后面神经图比较小的时候再加卷积层,不会增加太多消耗
- 总体参数保持不变,是因为全链接层的参数是比较多的,跟前面的卷积池化不在一个量级上
-
训练技巧
- 先训练浅层网络如A,再去训练深层网络。例如:用VGGNet-A先训练,训练好的参数用到B中,新增的层参数随机,然后再训练
- 多尺度输入
- 不同尺度训练多个分类器,然后做ensemble
- 随机使用不同的尺度缩放然后输入分类器进行训练
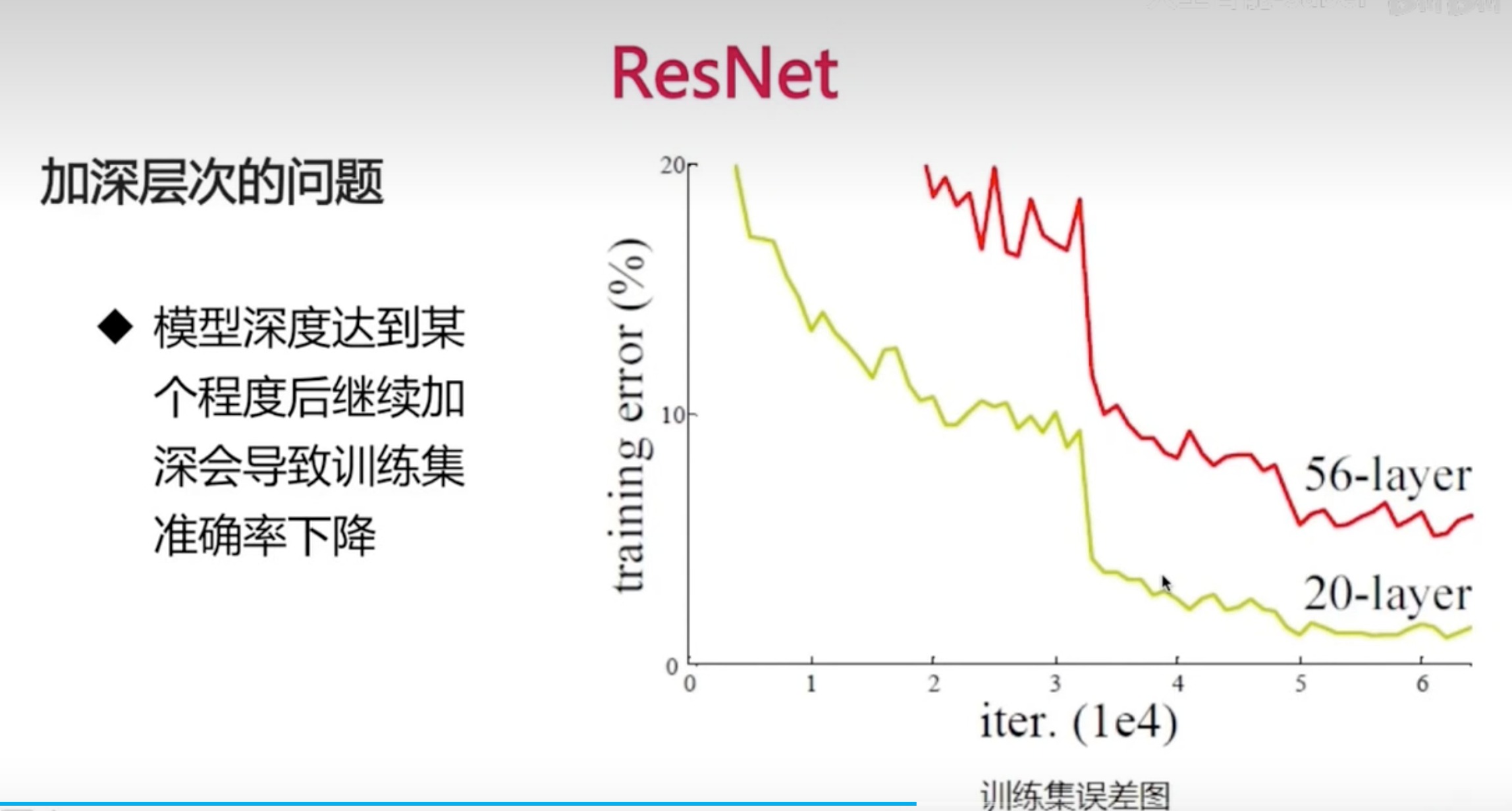
ResNet
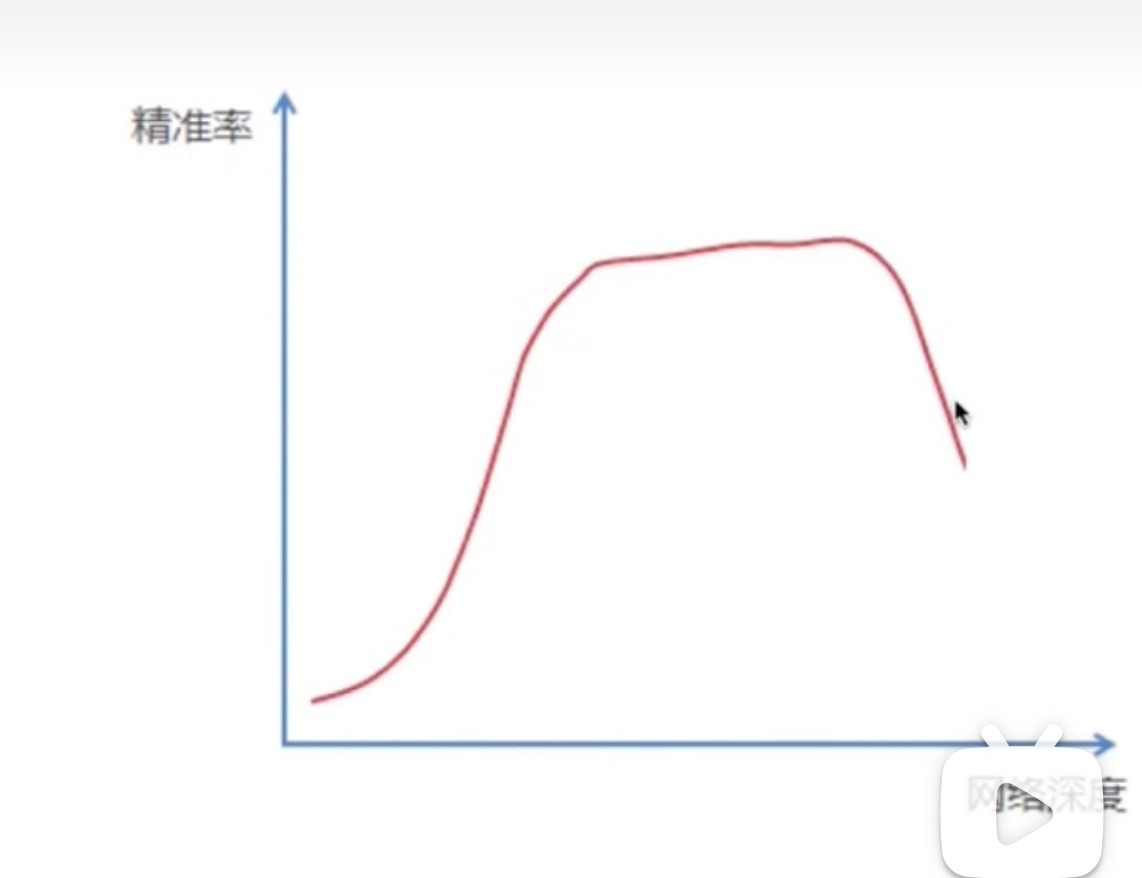
VGGNet已经加深到一定层次,再加深就没有什么效果了
-
加深层次的问题解决
-
假设:深层网络更难优化,而非深层网络学不到东西
- 深层网络至少可以和浅层网络持平
- y=x,虽然增加了深度,但误差不会增加
-
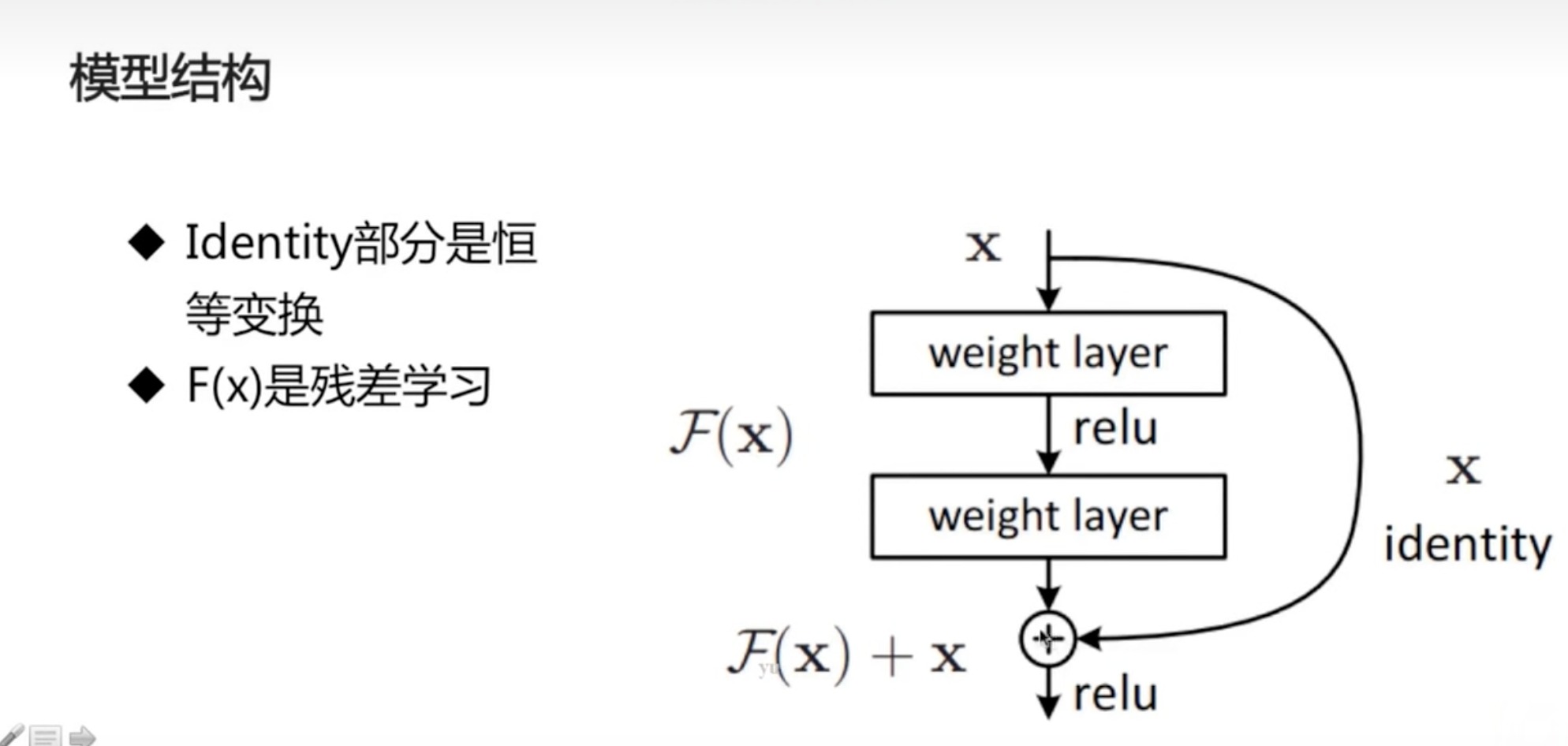
-
F(x)是经过网络后学到的东西,即残差,输出是包括x的恒等变换的,说明及时F(x)为0,至少也跟浅层网络持平,F(x)不为0能学到的话就有效果,且更深
-
-
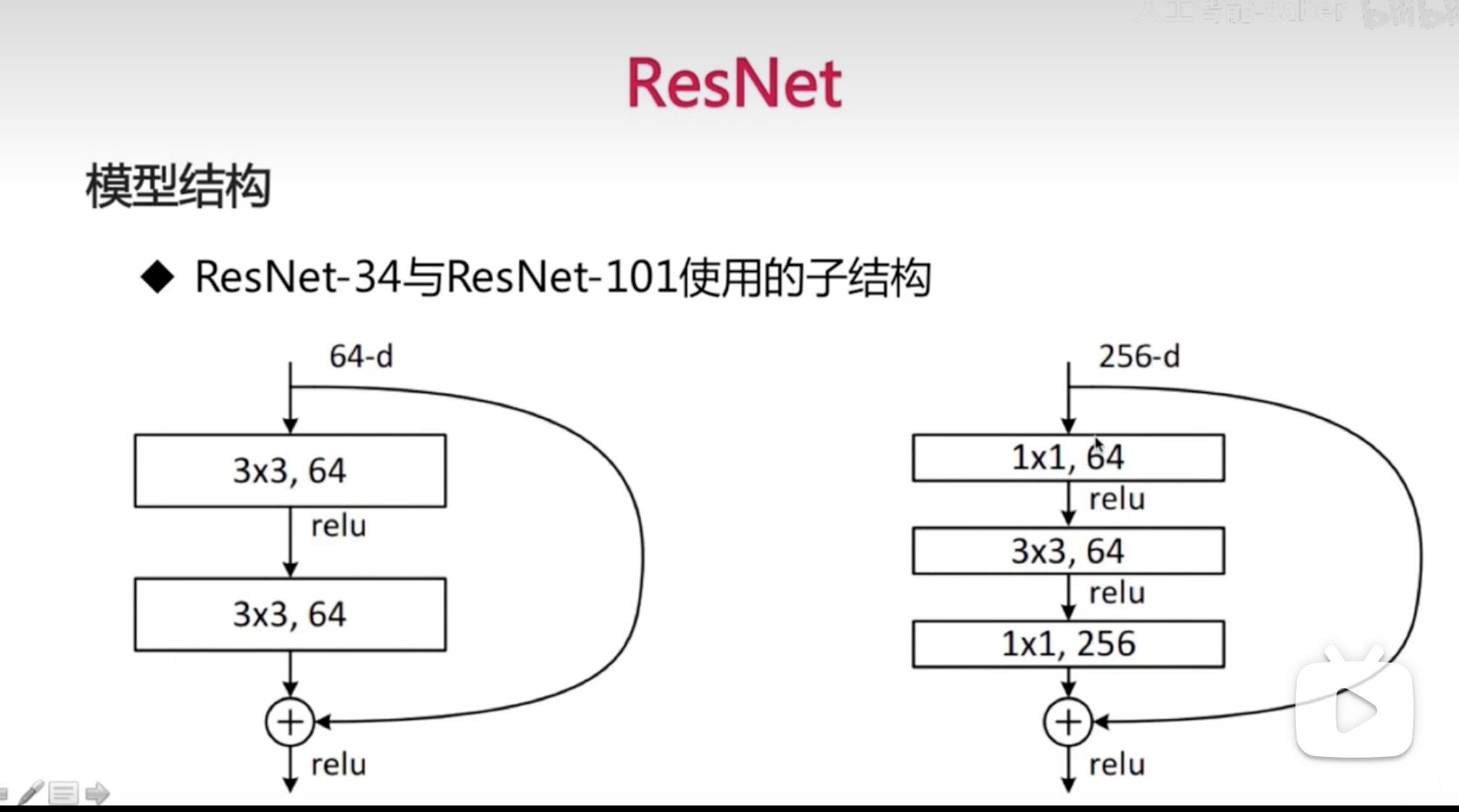
-
括号里的是残差子结构[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2I7FZQxn-1674398359690)(/Users/xuan/Library/Application Support/typora-user-images/image-20230118220913404.png)]
-
参数数目一定程度上能反应模型的容量,太多的容量容易过拟合,所以这里强化了卷积层,就弱化了全链接层
-
残差网络模型结构总结

- 优点
- 残差结构使得网络需要学习的知识更少,容易学习(主要的部分是通过一个恒等式保留下来)
- 残差结构使得每一层的数据分布接近,容易学习(更接近输入的数据分布)
卷积神经网络调参
- 包括:
- 网络的结构、参数个数
- 学习率、参数初始化
- 调参手段
- 更多的优化算法,比如随机梯度下降和动量梯度下降
- 激活函数
- 网络初始化:初始化能让模型在短时间达到好的效果
- 批归一化:适用于更深层次的网络
- 数据增强
- 更多的调参方法
更多的优化算法

学习率很大容易梯度爆炸,导致不收敛
- AdaGrad算法
-
 - 调整学习率 - 学习率随着训练变得越来越小 - 优点: - 前期,regularizer较小,放大梯度 - 后期,regularizer较大,缩小梯度 - 梯度随训练次数降低 - 每个分量有不同的学习率 - 缺点 - 学习率设置太大,导致regularizer影响过于敏感 - 后期,regularizer积累值过大,提前结束
- 调整学习率 - 学习率随着训练变得越来越小 - 优点: - 前期,regularizer较小,放大梯度 - 后期,regularizer较大,缩小梯度 - 梯度随训练次数降低 - 每个分量有不同的学习率 - 缺点 - 学习率设置太大,导致regularizer影响过于敏感 - 后期,regularizer积累值过大,提前结束 - RMSProp

- Adam
- 集众家之长,常用
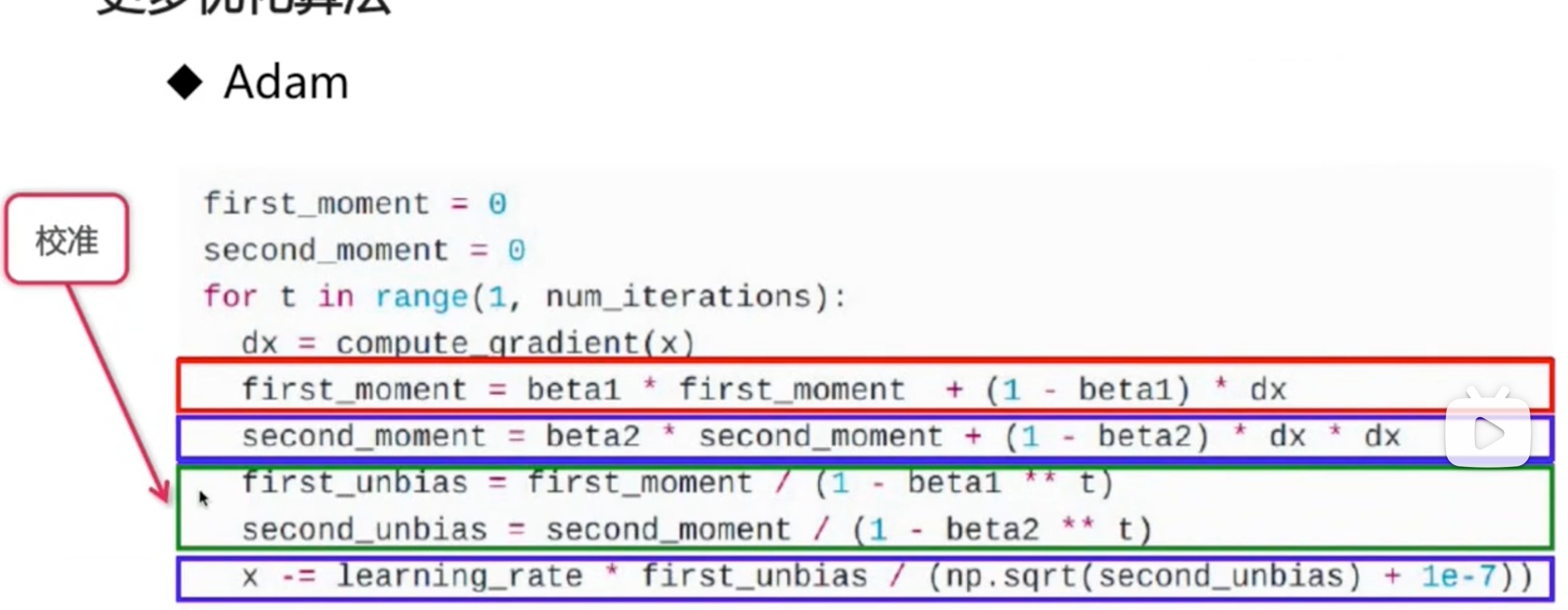
- 学习率自适应
- 让学习率按照某种规则去衰减
- 分不同情况用不同算法
- 稀疏数据,使用学习率自适应方法
- SGD(随机梯度下降)通常训练时间更好,最终效果较好,但需要好的初始化和learning rate
- 需要训练较深较复杂的网络且需要快速收敛时,推荐使用adam
- Adagrad,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多
激活函数
激活函数的不同,会影响训练的速度,以及最后的结果
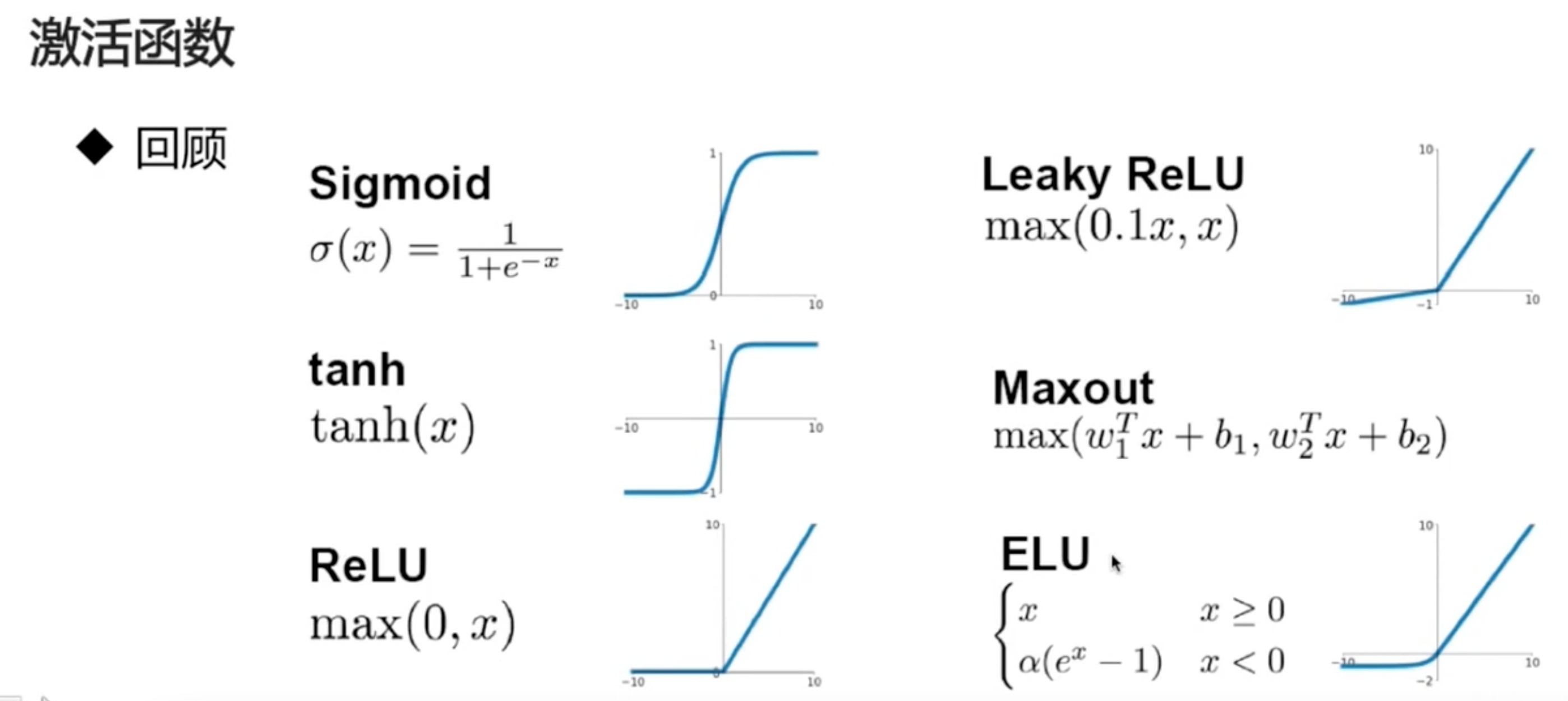
Sigmoid

-
输入非常大或非常小时没有梯度
-
输出均值非0
- 对于神经网络的学习是不友好的
-
Exp计算复杂
- 会导致训练比较慢
-
梯度消失
-
d f ( x ) d x = f ( x ) ( 1 − f ( x ) ) \frac{df(x)}{dx}=f(x)(1-f(x)) dxdf(x)=f(x)(1−f(x))
-
每经过一层都要乘当前梯度,即两个小于1的数,那么对于层次比较深的网络来说,就会造成最后梯度消失
-
Tanh

- 输入非常大或非常小时没有梯度
- 输出均值为0
- 优点
- 计算复杂
ReLU

- 不饱和(梯度不会过小)
- 在>0的时候就是自己
- 计算量小
- 收敛速度快
- 输出均值非0
- 一定>0
- Dead ReLU
- 一个非常大的梯度流过神经元,就不会再对数据有激活现象了
- 负数其梯度一直是0,不更新
- 解决
- Leaky-ReLU

- ELU
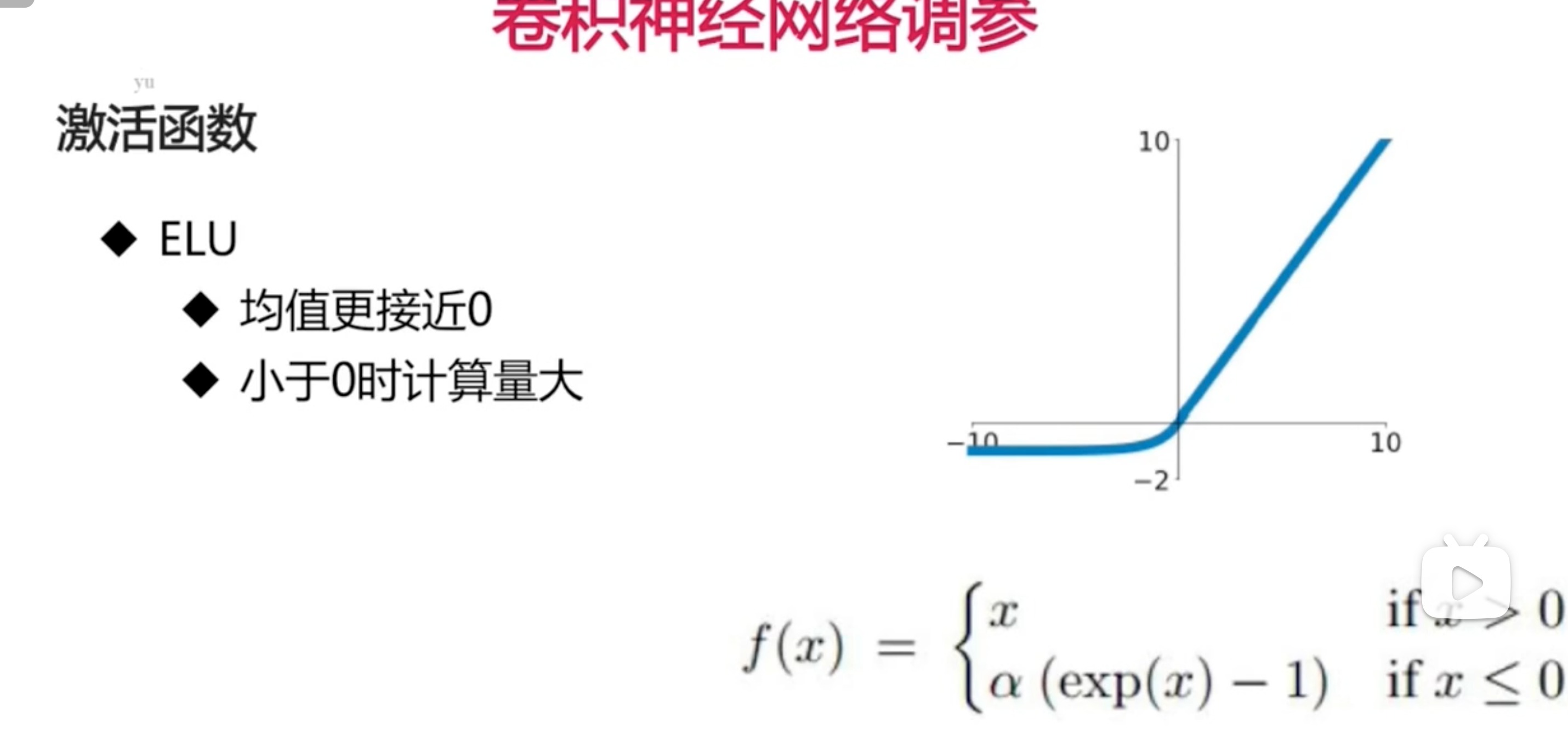
- Maxout

使用技巧
- ReLU
- 小心设置learning rate
- 一般从小的开始
- 不要使用sigmoid
- 使用Leaky Relu、maxout、ELU
- 可以试试tanh,但不要抱太大期望
网络初始化
0初始化
- 全部为0
- 单层网络可以
- 多层网络会使梯度消失
- 链式法则
- 如何查看初始化结果好不好
- 查看初始化后各层的激活值分布
- 是都在0-1之间(好),还是集中在0或者1(不好)
正态分布初始化
-
均值为0,方差为0.02的正态分布初始化
- tanh、ReLU激活函数
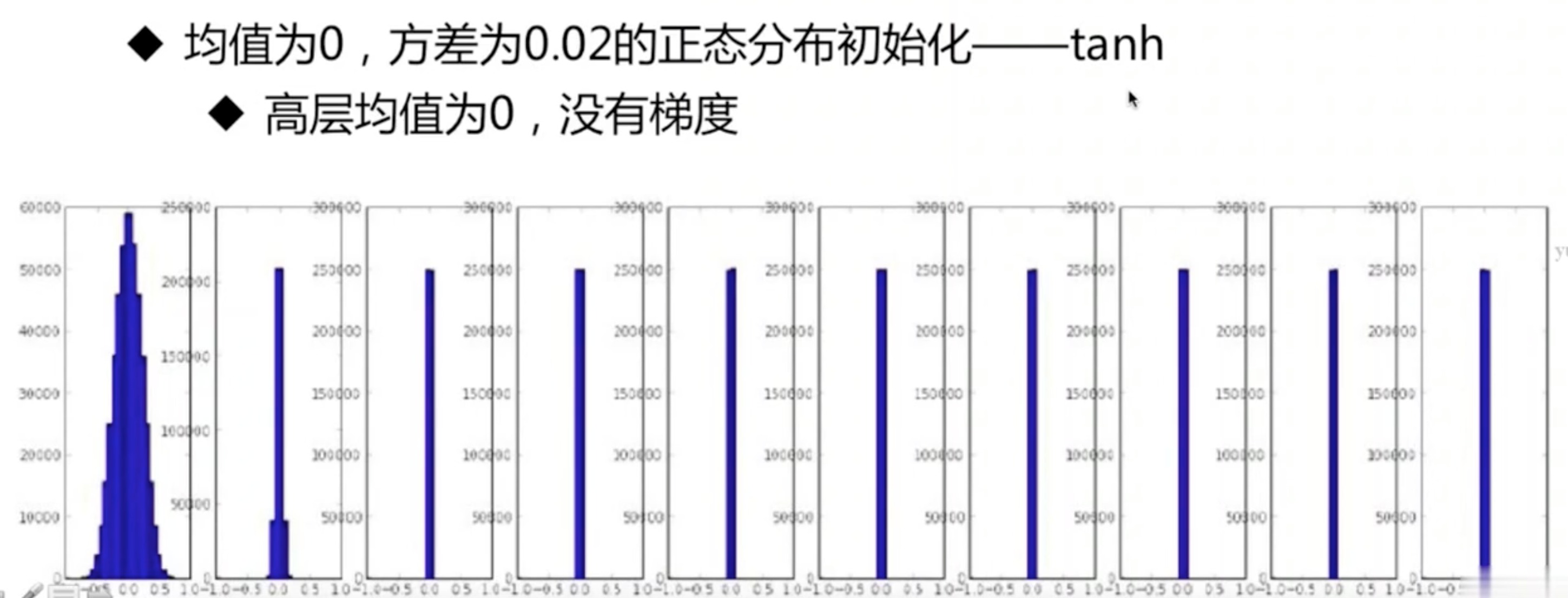
-
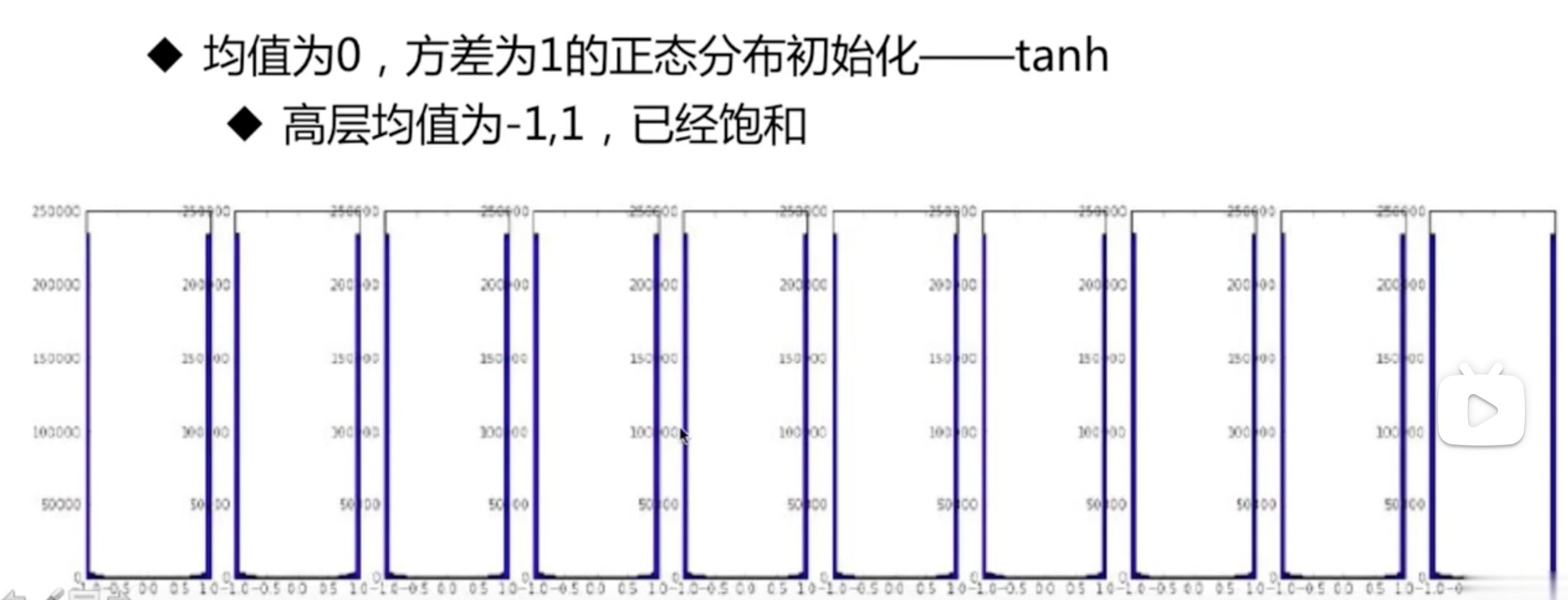
均值为0,方差为1的正态分布初始化
- tanh、ReLU激活函数
-
所以以上两种对于高层网络都不是好的初始化
-
好的方法
-

-
输入通道数和输出通道数取平均值
-
-
批归一化
- 每个batch在每一层上都做归一化
- 让每一层的分布都比较统一,控制在均值为0,方差为1
- 但是会导致一个问题,每个batch的分布不能代表整体,导致已经提取出来的特征被改了
- 所以为了确保归一化能够起到作用,另设两个参数来逆归一化,保证原来提取出来的特征是有效的。
- 如果说归一化后结果是有效的,那么就有效
- 如果说归一化后结果是无效的,那么就通过这两个参数,返回原来不归一化的样子
数据增强
- 归一化
- 图像变换
- 翻转、拉伸、裁剪、变形
- 色彩变换
- 对比度、亮度
- 多尺度裁剪

更多调参技巧
-
做深度学习的话,一定要拿到更多的数据
-
给神经网络添加层次
-
紧跟最新进展,使用新方法
-
增大训练的迭代次数
-
尝试正则化
- 损失函数上加一个正则化项
- 减小过拟合的趋势
-
使用更多的GPU来加速训练
-
可视化工具来检查中间状态
- 损失
- 训练集
- 测试集
- 梯度
- 梯度比较大,那么说明还需要训练
- 准确率
- 对于分类问题用分类正确率
- 对于回归问题用MSE
- 学习率
- 损失
-
不同的可视化结果告诉我们什么
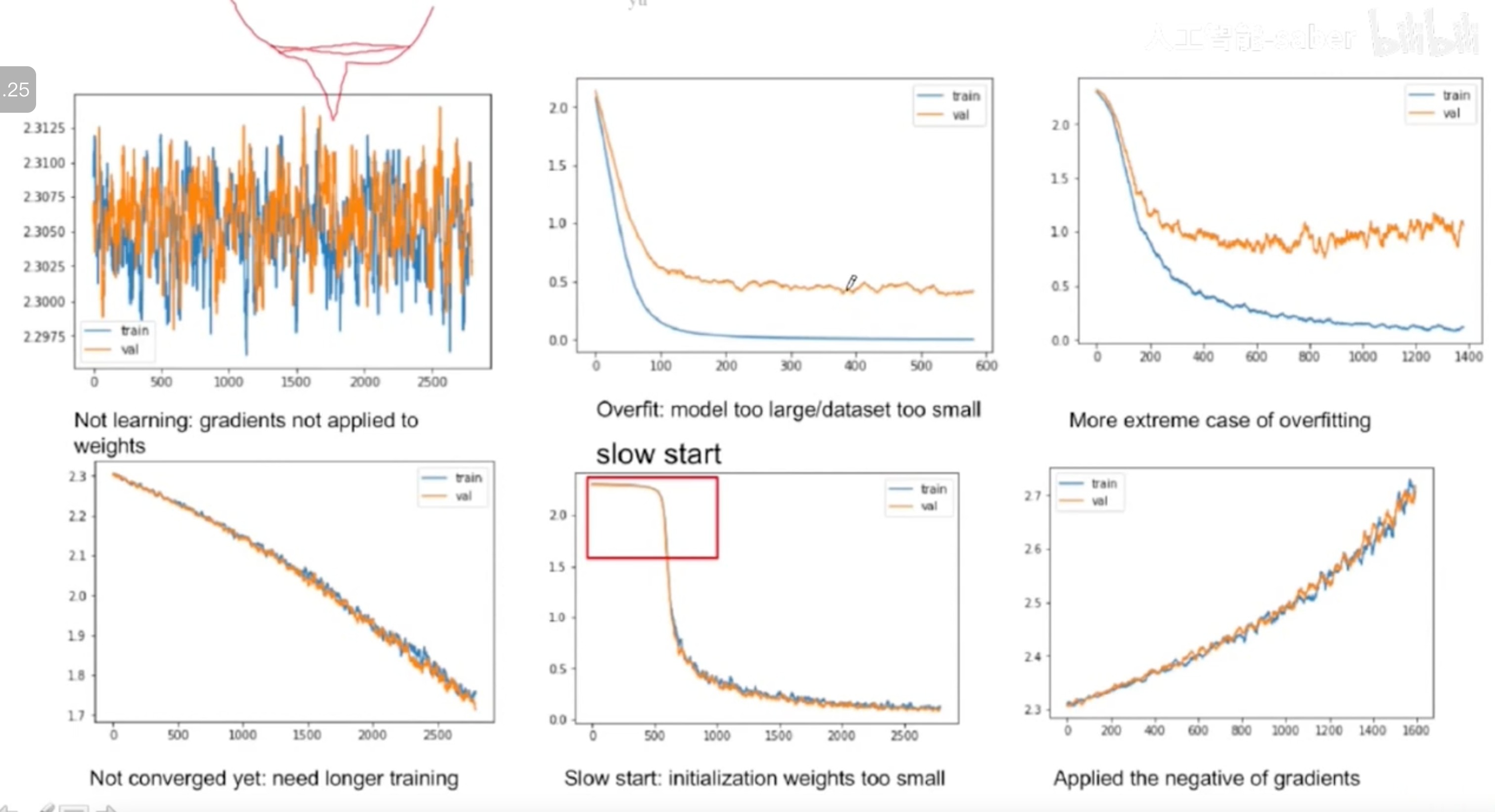
- 在标准数据集上训练,看网络表现怎样
- 在小数据集上测试,过拟合的效果正好是预期所要的
- 在数据集分布平衡,正类负类不平衡
- 使用预调整好的稳定模型结构,使用论文里别人千锤百炼的
- Fine-tuning
- 预训练好的网络结构上进行微调
- 包括训练好的参数等等
- 是最好的方法,在各种比赛中使用的最多
循环神经网络
- 为什么需要循环神经网络
- 循环神经网络
- 多层网络和双向网络
- 循环神经网络相比卷积神经网络的类型少
- 最常用的就是长短时记忆网络LSTM
- 用于文本分类问题
为什么需要循环神经网络
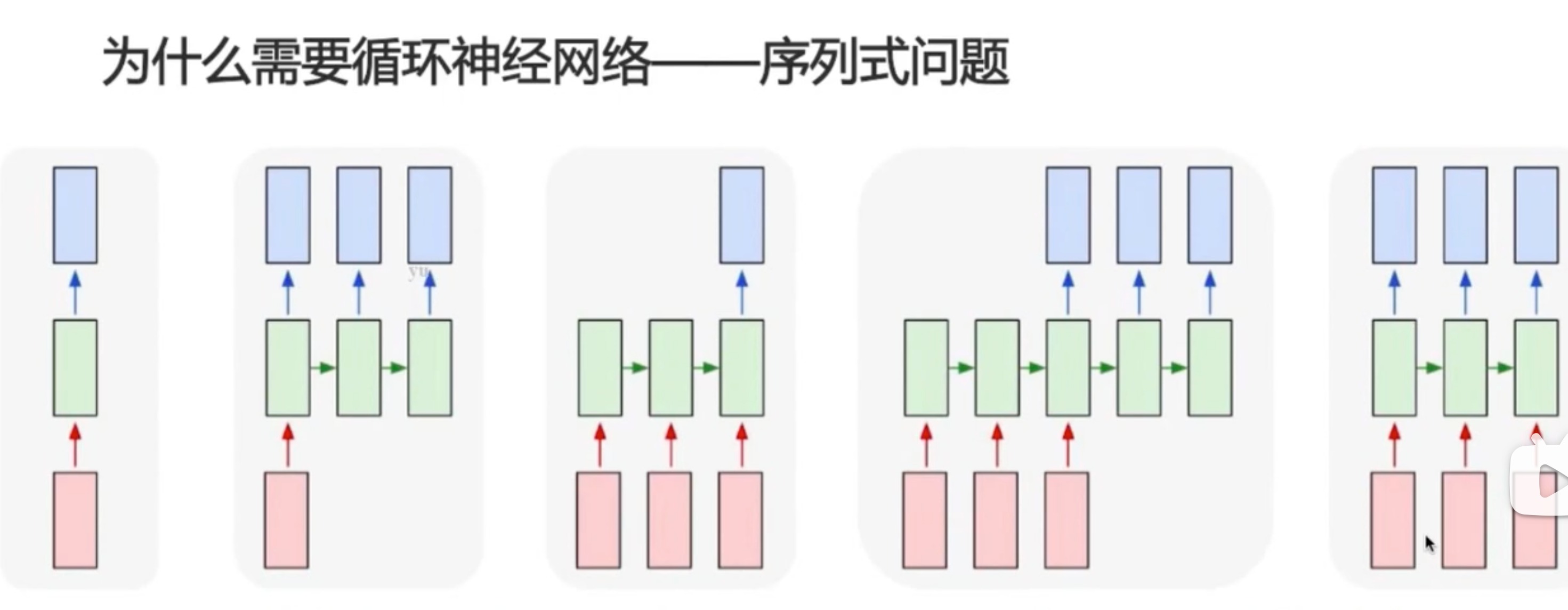
- 1对1,普通神经网络、卷积神经网络可以处理
- 1对多,图片生成描述
- 多对1,文本分类(文本情感分析)
- 多对多:encoding-decoding,机器翻译
- 事实多对多:视频解说





![[前端笔记——CSS] 10.层叠与继承、选择器](https://img-blog.csdnimg.cn/fbbfd08c59d4420d9bb683ae6779cad2.png)