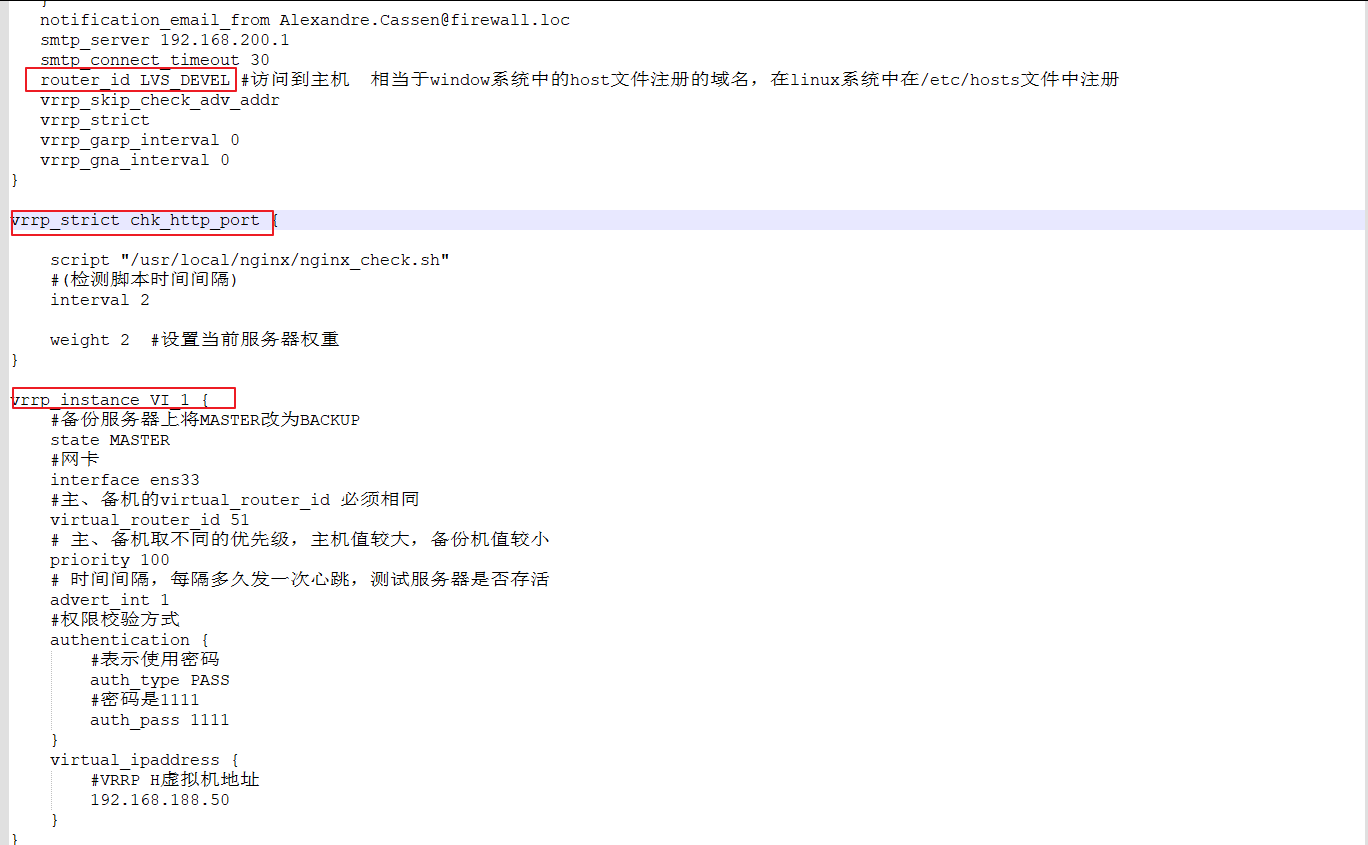
概述
在多线程的情况下有一个典型的模,型生产者消费者模型,该模型主要由生产者、消费者和一个大小固定的队列组成。生产者向队列发送数据,消费者从队列中取出数据并处理。
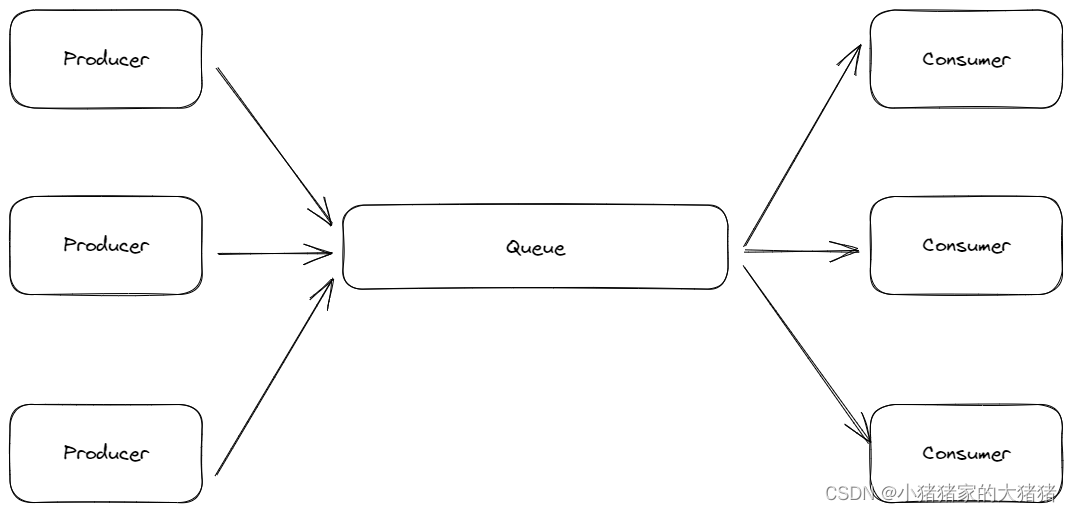
针对上述模型,如果队列属于有限长度,当消费者能力<生产者能力的时候就会出现数据堆积,这样生产者的生产就会停止。现在将这个模型引入Flink算子链中,生产者和消费者的身份是相对的,一个生产者是上游的消费者,一个消费者同样也是下游的生产者。所以一个节点模型中消费者的堵塞将会向上移动,直到源头,这就是反压。
Flink数据通信模型
假如一个Flink任务(Job)中有 TaskA,TaskB,并发度都是 4,即 A1-A4,B1-B4。TaskA 与 TaskB 使用 keyby 连接。将这个 Flink Job 部署到 2 个 TM 中,每个 TM 分配 2 个 slots。那么Flink会将 A 1 , A 2 , B 1 , B 2 A1,A2,B1,B2 A1,A2,B1,B2 放到一个 TM 中, A 3 , A 4 , B 3 , B 4 A3,A4,B3,B4 A3,A4,B3,B4 放到一个 TM 中,具体示例如下图所示:
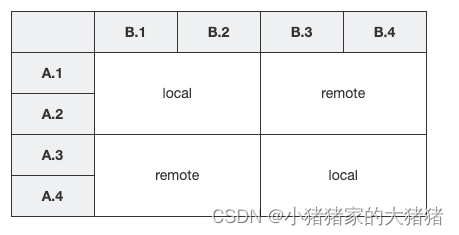
同一个 TM 中的SubTask采用 【local 】方式进行数据传输。位于不同 TM 的 SubTask采用【remote】方式传输。传输示意图如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FDG7JBd6-1674134045215)(E:/Postgraduate/document/ASSESTS/%E3%80%90Flink%E3%80%91%E6%B5%85%E8%B0%88Flink%E8%83%8C%E5%8E%8B%E9%97%AE%E9%A2%98%EF%BC%881%EF%BC%89.assets/Flink-FlinkTM%E9%80%9A%E4%BF%A1%E6%A8%A1%E5%9E%8B%E6%80%BB%E7%BB%93_image_2.png)]](https://img-blog.csdnimg.cn/ca90890553bc4bde8fec73acded4cb95.png)
我们从上图可以看出,以SubTaskA1为例,其数据传输步骤如下:
- TaskA1 先通过 【RecordWriter】对象将数据序列化写到一个 【Output Queue Buffer】 中(下游的并行子任务个数就是队列的个数)。
- 由【 Netty Service 】进行拉取,满足以下任意一个条件都会进行拉取;
- 【Output Queue Buffer】 写满了(默认 32KB);
- 【Output Queue Buffer】 超时了(默认 100ms);
- 遇到特殊结构,例如 Barrier,WaterMark;
- 经过网络传输之后,数据会写到 TaskB3 中的 【Input Queue】 中,然后由 【RecordReader】对象将数据反序列化后进行处理。
也就是说一个 下游TM 中的并行子任务出现消费延迟,就会阻塞 TCP-channel 进而影响整个 TM 的消费,最终向上传递,导致反压。
反压的监控
Web UI
可以直接在 Flink Web 中进行观察,Flink检测会针对任何一个 Task 做反压检测。该机制需要在 Flink Web 上手动触发,触发后TM 使用 Thread.GetStackTrace 来抽样检测 Task Thread 是否在 NetworkBuffer 中,即是否处于等待状态。根据抽样比例,来判断反压状态。Ratio 是代表抽样 n 次(默认100次)中,遇到等待次数的比例。
- OK:ratio≤0.1;
- LOW:0.01≤Ratio≤0.5;
- High:0.5≤Ratio≤1;
从 Sink→Source 进行检查,第一个反压状态处于 High 的 task 大概率是反压的根源。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s6HnrF2y-1674134045216)(E:/Postgraduate/document/ASSESTS/%E3%80%90Flink%E3%80%91%E6%B5%85%E8%B0%88Flink%E8%83%8C%E5%8E%8B%E9%97%AE%E9%A2%98%EF%BC%881%EF%BC%89.assets/Pasted%20image%2020220825113135.png)]](https://img-blog.csdnimg.cn/d04e99a9137c49e19d330f3a9e1e980c.png)
该方法有一定的缺陷:
- 由于他是抽样,无法观察到历史数据;
- 影响作业流程;
- 高并发场景下,需要等待很久才能检测成功;
Flink Network Metric
在上文提到过,TM之间的通信都会使用到 InputQueue 和 OutputQueue,我们可以通过使用【InputQueueUsage】 和 【OutputQueueUsage】这两个指标来判断出现反压的位置。
| Task Status | OutputQueueUsage < 1.0 | OutputQueueUsage == 1.0 |
|---|---|---|
| InputQueueUsage < 1.0 | 正常 | 处于反压,其根本原因可能是该 Task 下游处理能力不足导致,持续下去,该 Task 将会向上游传递反压 |
| InputQueueUsage == 1.0 | 处于反压,持续下去,该 Task 会向上游传递反压,而且该 Task 可能是反压的源头 | 处于反压,原因可能是被下游阻塞 |
现在看一个实际的例子
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9yh1MbN5-1674134045216)(E:/Postgraduate/document/ASSESTS/%E3%80%90Flink%E3%80%91%E6%B5%85%E8%B0%88Flink%E8%83%8C%E5%8E%8B%E9%97%AE%E9%A2%98%EF%BC%881%EF%BC%89.assets/Pasted%20image%2020220825114331.png)]](https://img-blog.csdnimg.cn/7a27178778e0421a9c51705302c0de42.png)
从指标监控界面可以看出 FlatMap→Reduce 出现了阻塞,再看 reduce 任务的 inpoolusage 和 outpoolusage 指标,得出结论reduce任务就是反压的源头。
往期回顾
- 【分布式】浅谈CAP、BASE理论(1)
我将在下一期详细介绍反压形成的原因以及处理办法,敬请期待!!








![[疑难杂症2023-002]不就是Move一个文件吗,怎么会有这么多坑呢?](https://img-blog.csdnimg.cn/9b9b6d94ad06489cad0dfb769f0b7922.png)

![[oeasy]python0054_三引号_原样显示字符串_triple_quoted](https://img-blog.csdnimg.cn/img_convert/2d22c3f18467ce499d910464429003a0.png)