一、深度学习模型训练流程“八股文”
1.1 机器学习的开发应用步骤:
数据搜集——>数据预处理——>特征工程——>划分训练集和测试集——>选择模型——>建立模型(模型+超参数设置)——>设置损失函数——>进行训练以及预测
1.2 深度学习开发应用步骤与机器学习的不同
上面的机器学习应用开发步骤也同样适用于深度学习应用开发,当然也会存在一些不同,具体如下:
(1)深度学习一般所需要的数据样本很大,无法一次性的加载全部数据到模型中,需要设置参数定义每次固定送入的样本数量,通过分批次对模型进行训练;
(2)深度学习模型框架在搭建时都需要我们使用函数去实现,由上往下“逐层”进行搭建,当然也可以分开搭建,最后进行拼接组装;
(3)损失函数反向传播回网络最前面的层,同时使用优化器自动调整相关的网络参数;
(4)机器学习一般是默认在CPU上训练,当然少数除外,然而深度学习,由于计算量的过大,一般在GPU上进行训练。
二、基本配置
2.1 导包
这里导包和机器学习一样,选择需要的包进行导入,常见的有:pandas、numpy、torch、torch.nn、torch.utils.data.Dataset、torch.utils.data.DataLoader、torch.optimizer等等,如下代码所示:
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer2.2 设置一些超参数
在导包完成之后,我们一般开始设置一些在下面需要用到的一些参数,这里的参数比如包含:batch size(每次模型进行训练送入的样本数)、学习率、训练次数、GPU配置、随机数等,(当然有时候也可以使用一个文件来设置参数,将参数保存到yaml文件中,方便对参数进行调整)
batch_size = 16
# 批次的大小
lr = 1e-4
# 优化器的学习率
max_epochs = 100
GPU设置的两种使用方式
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")三、数据读入
3.1 Dataset类重要的三个函数
定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类,其中重要的三个函数的用法很重要,介绍如下表所示。
| 函数 | 介绍 |
| __init__ | 用于向类中传入外部参数,同时定义样本集 |
| __getitem__ | 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据 |
| __len__ | 用于返回数据集的样本数 |
3.2 案例
class MyDataset(Dataset):
def __init__(self, data_dir, info_csv, image_list, transform=None):
"""
Args:
data_dir: path to image directory.
info_csv: path to the csv file containing image indexes
with corresponding labels.
image_list: path to the txt file contains image names to training/validation set
transform: optional transform to be applied on a sample.
"""
label_info = pd.read_csv(info_csv)
image_file = open(image_list).readlines()
self.data_dir = data_dir
self.image_file = image_file
self.label_info = label_info
self.transform = transform
def __getitem__(self, index):
"""
Args:
index: the index of item
Returns:
image and its labels
"""
image_name = self.image_file[index].strip('\n')
raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name]
label = raw_label.iloc[:,0]
image_name = os.path.join(self.data_dir, image_name)
image = Image.open(image_name).convert('RGB')
if self.transform is not None:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.image_file)3.3 数据加载DataLoader
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)其中重要参数介绍
| 参数 | 介绍 |
| batch_size | 样本是按“批”读入的,batch_size就是每次读入的样本数 |
| num_workers | 有多少个进程用于读取数据 |
| shuffle | 是否将读入的数据打乱 |
| drop_last | 对于样本最后一部分没有达到批次数的样本,使其不再参与训练 |
四、模型构建
4.1 PyTorch中神经网络的构造方法
Module 类是 nn 模块里提供的一个模型构造类,是所有神经⽹网络模块的基类。在使用它构造自己的模型框架时,通常是对其类中的init函数和forward函数进行重载。下面以MLP作为例子:
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)init函数中定义我们需要的各个网络层以及进行参数设定
forward函数中定义正向传播
4.2 常见网络层的构造
4.2.1 不含参数的层
即对于init函数中我们不需要进行重载,只需写一个函数调用在那即可,下面以定义一个将输入减掉均值后输出的网络层·为例:
import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean() 4.2.2 含参数的层
将参数传入Parmeter类,Parameter 类其实是 Tensor 的子类。
(1)一个是Parameter的Tensor会自动添加到模型的参数列表中;
(2)ParameterList,将需要设定的参数组合成列表放入其中;
(3)ParameterDict ,将需要设定的参数设置成字典,不同模型层的参数按照对应网络层传入。
ParameterList
class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i])
return x
net = MyListDense()
print(net)ParameterDict
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params = nn.ParameterDict({
'linear1': nn.Parameter(torch.randn(4, 4)),
'linear2': nn.Parameter(torch.randn(4, 1))
})
self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增
def forward(self, x, choice='linear1'):
return torch.mm(x, self.params[choice])
net = MyDictDense()
print(net)在进行实际项目或者比赛的时候,会发现init函数中几乎定义的都是单个不同网络层的输入
4.3 常见的网络层
这里详细展示二维卷积层和池化层的底层代码,一般我们是直接调用nn里面已经写好的网络层。
4.3.1 二维卷积层
import torch
from torch import nn
# 卷积运算(二维互相关)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
# 二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias4.3.2 池化层
import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y4.4 模型示例——LeNet和AlexNet
4.4.1 LeNet
(1)模型架构
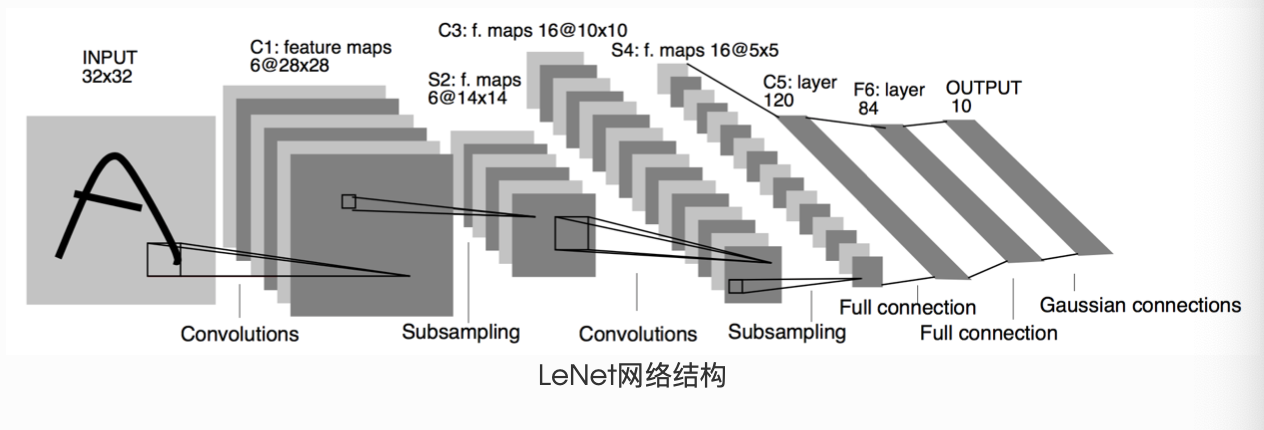
(2)代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的其他所有维度
num_features = 1
for s in size:
num_features *= s
return num_features4.4.2 AlexNet
(1)模型架构
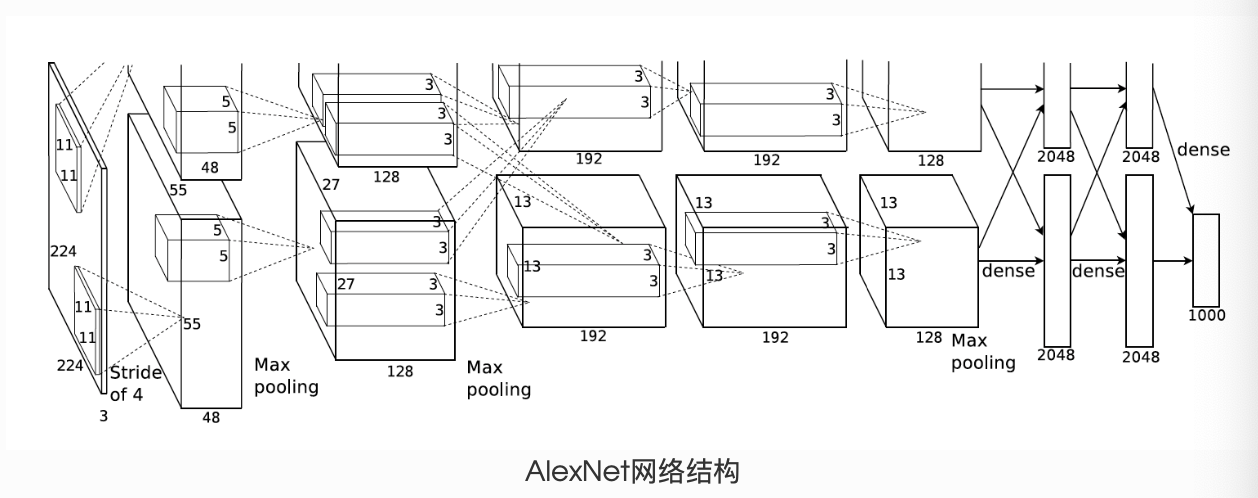
(2) 代码实现
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output五、模型初始化
5.1 torch.nn.init内容
常见的nn中的初始化,主要展示每次初始化的时候应该传入的参数形式
torch.nn.init.uniform_(tensor, a=0.0, b=1.0) |
torch.nn.init.normal_(tensor, mean=0.0, std=1.0) |
torch.nn.init.constant_(tensor, val) |
torch.nn.init.ones_(tensor) |
torch.nn.init.zeros_(tensor) |
torch.nn.init.eye_(tensor) |
torch.nn.init.dirac_(tensor, groups=1) |
torch.nn.init.xavier_uniform_(tensor, gain=1.0) |
torch.nn.init.xavier_normal_(tensor, gain=1.0) |
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan__in', nonlinearity='leaky_relu') |
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu') |
torch.nn.init.orthogonal_(tensor, gain=1) |
torch.nn.init.sparse_(tensor, sparsity, std=0.01) |
torch.nn.init.calculate_gain(nonlinearity, param=None) |
5.2 初始化函数的封装
一般定义为一个initialize_weights()的函数并在模型初始后进行使用
def initialize_weights(self):
for m in self.modules():
# 判断是否属于Conv2d
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
# 判断是否有偏置
if m.bias is not None:
torch.nn.init.constant_(m.bias.data,0.3)
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0.1)
if m.bias is not None:
torch.nn.init.zeros_(m.bias.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zeros_()六、损失函数
将模型训练并进行预测后得到的结果与真实结果之间的“差距”,这个“差距”是不同的,这取决于我们定义的计算方法,也就是我们常说的损失函数。
6.1 二分类交叉熵损失函数
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')6.2 交叉熵损失函数
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')6.3 L1损失函数
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')6.4 MSE损失函数
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')6.5 平滑L1 (Smooth L1)损失函数
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)6.6 目标泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')6.7 KL散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)6.8 MarginRankingLoss
torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')6.9 多标签边界损失函数
torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='mean')6.10 二分类损失函数
torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction='mean')torch.nn.(size_average=None, reduce=None, reduction='mean')6.11 多分类的折页损失
torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction='mean')6.12 三元组损失
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean')6.13 HingEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction='mean')6.14 余弦相似度
torch.nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')6.15 CTC损失函数
torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False)七、训练和评估
训练模型存在两种状态:
(1)训练态:应该参数支持反向传播(主要是对模型参数不断更新,训练出最优的模型)
(2)验证/测试态:不应该修改模型参数(加载上面已经训练好的模型进行预测结果)
7.1 训练
def train(epoch):
# 训练状态
model.train()
# 初始化训练loss为0
train_loss = 0
# 加载训练数据集和标签
for data, label in train_loader:
# 调用cuda将计算放到GPU上
data, label = data.cuda(), label.cuda()
# 因梯度会累加上一次的,因此在每次进行训练的时候,为了放在累加,都要将优化器的梯度置零
optimizer.zero_grad()
# 开始加载模型并传入数据进行模型训练,并得到训练集的预测标签
output = model(data)
# 加载定义好的损失函数进行损失计算
loss = criterion(label, output)
# 通过反向传播传回网络
loss.backward()
# 使用优化器对参数进行更新
optimizer.step()
# 累加loss,方便最后的loss计算
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))7.2 评估
def val(epoch):
# 验证/测试状态
model.eval()
# 定义验证的loss(一般比赛我们是无法知道测试集的loss的)
val_loss = 0
# 不存入梯度计算
with torch.no_grad():
# 加载验证的数据集,并传入验证集标签(还是一样如果是测试集就只有一个训练数据,没有标签
for data, label in val_loader:
# 调用GPU计算
data, label = data.cuda(), label.cuda()
# 加载模型并传入数据,得到预测的结果
output = model(data)
# 将输出定义为我们想要的输出,增加一个输出层(这里输出为二分类)
preds = torch.argmax(output, 1)
# 计算损失
loss = criterion(output, label)
# 验证loss
val_loss += loss.item()*data.size(0)
# 统计和标签相同的
running_accu += torch.sum(preds == label.data)
val_loss = val_loss/len(val_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, val_loss))八、Pytorch优化器
8.1 Pytorch提供的优化器
| torch.optim.ASGD |
| torch.optim.Adadelta |
| torch.optim.Adagrad |
| torch.optim.Adam |
| torch.optim.AdamW |
| torch.optim.Adamax |
| torch.optim.LBFGS |
| torch.optim.RMSprop |
| torch.optim.Rprop |
| torch.optim.SGD |
| torch.optim.SparseAdam |
优化算法继承于Optimizer,其定义如下(把原文中的代码合在了一起放在Optimizer类中)
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
def zero_grad(self, set_to_none: bool = False):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None: #梯度不为空
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
p.grad.zero_()# 梯度设置为0
def step(self, closure):
raise NotImplementedError
def add_param_group(self, param_group):
assert isinstance(param_group, dict), "param group must be a dict"
# 检查类型是否为tensor
params = param_group['params']
if isinstance(params, torch.Tensor):
param_group['params'] = [params]
elif isinstance(params, set):
raise TypeError('optimizer parameters need to be organized in ordered collections, but '
'the ordering of tensors in sets will change between runs. Please use a list instead.')
else:
param_group['params'] = list(params)
for param in param_group['params']:
if not isinstance(param, torch.Tensor):
raise TypeError("optimizer can only optimize Tensors, "
"but one of the params is " + torch.typename(param))
if not param.is_leaf:
raise ValueError("can't optimize a non-leaf Tensor")
for name, default in self.defaults.items():
if default is required and name not in param_group:
raise ValueError("parameter group didn't specify a value of required optimization parameter " +
name)
else:
param_group.setdefault(name, default)
params = param_group['params']
if len(params) != len(set(params)):
warnings.warn("optimizer contains a parameter group with duplicate parameters; "
"in future, this will cause an error; "
"see github.com/pytorch/pytorch/issues/40967 for more information", stacklevel=3)
# 上面好像都在进行一些类的检测,报Warning和Error
param_set = set()
for group in self.param_groups:
param_set.update(set(group['params']))
if not param_set.isdisjoint(set(param_group['params'])):
raise ValueError("some parameters appear in more than one parameter group")
# 添加参数
self.param_groups.append(param_group)
def load_state_dict(self, state_dict):
r"""Loads the optimizer state.
Arguments:
state_dict (dict): optimizer state. Should be an object returned
from a call to :meth:`state_dict`.
"""
# deepcopy, to be consistent with module API
state_dict = deepcopy(state_dict)
# Validate the state_dict
groups = self.param_groups
saved_groups = state_dict['param_groups']
if len(groups) != len(saved_groups):
raise ValueError("loaded state dict has a different number of "
"parameter groups")
param_lens = (len(g['params']) for g in groups)
saved_lens = (len(g['params']) for g in saved_groups)
if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)):
raise ValueError("loaded state dict contains a parameter group "
"that doesn't match the size of optimizer's group")
# Update the state
id_map = {old_id: p for old_id, p in
zip(chain.from_iterable((g['params'] for g in saved_groups)),
chain.from_iterable((g['params'] for g in groups)))}
def cast(param, value):
r"""Make a deep copy of value, casting all tensors to device of param."""
# Copy state assigned to params (and cast tensors to appropriate types).
# State that is not assigned to params is copied as is (needed for
# backward compatibility).
state = defaultdict(dict)
for k, v in state_dict['state'].items():
if k in id_map:
param = id_map[k]
state[param] = cast(param, v)
else:
state[k] = v
# Update parameter groups, setting their 'params' value
def update_group(group, new_group):
...
param_groups = [
update_group(g, ng) for g, ng in zip(groups, saved_groups)]
self.__setstate__({'state': state, 'param_groups': param_groups})
def state_dict(self):
r"""Returns the state of the optimizer as a :class:`dict`.
It contains two entries:
* state - a dict holding current optimization state. Its content
differs between optimizer classes.
* param_groups - a dict containing all parameter groups
"""
# Save order indices instead of Tensors
param_mappings = {}
start_index = 0
def pack_group(group):
param_groups = [pack_group(g) for g in self.param_groups]
# Remap state to use order indices as keys
packed_state = {(param_mappings[id(k)] if isinstance(k, torch.Tensor) else k): v
for k, v in self.state.items()}
return {
'state': packed_state,
'param_groups': param_groups,
}| defaults | 存储的是优化器的超参数 |
| state | 参数的缓存 |
| param_groups | 管理的参数组,是一个list,其中每个元素是一个字典,顺序是params,lr,momentum,dampening,weight_decay,nesterov |
| zero_grad() | 清空所管理参数的梯度,PyTorch的特性是张量的梯度不自动清零,因此每次反向传播后都需要清空梯度。 |
| step() | 执行一步梯度更新,参数更新 |
| add_param_group() | 添加参数组 |
| load_state_dict() | 加载状态参数字典,可以用来进行模型的断点续训练,继续上次的参数进行训练 |
| state_dict() | 获取优化器当前状态信息字典 |
8.2 实际操作
import os
import torch
# 设置权重,服从正态分布 --> 2 x 2
weight = torch.randn((2, 2), requires_grad=True)
# 设置梯度为全1矩阵 --> 2 x 2
weight.grad = torch.ones((2, 2))
# 输出现有的weight和data
print("The data of weight before step:\n{}".format(weight.data))
print("The grad of weight before step:\n{}".format(weight.grad))
# 实例化优化器
optimizer = torch.optim.SGD([weight], lr=0.1, momentum=0.9)
# 进行一步操作
optimizer.step()
# 查看进行一步后的值,梯度
print("The data of weight after step:\n{}".format(weight.data))
print("The grad of weight after step:\n{}".format(weight.grad))
# 权重清零
optimizer.zero_grad()
# 检验权重是否为0
print("The grad of weight after optimizer.zero_grad():\n{}".format(weight.grad))
# 输出参数
print("optimizer.params_group is \n{}".format(optimizer.param_groups))
# 查看参数位置,optimizer和weight的位置一样,我觉得这里可以参考Python是基于值管理
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))
# 添加参数:weight2
weight2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": weight2, 'lr': 0.0001, 'nesterov': True})
# 查看现有的参数
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
# 查看当前状态信息
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)
# 进行5次step操作
for _ in range(50):
optimizer.step()
# 输出现有状态信息
print("state_dict after step:\n", optimizer.state_dict())
# 保存参数信息
torch.save(optimizer.state_dict(),os.path.join(r"D:\pythonProject\Attention_Unet", "optimizer_state_dict.pkl"))
print("----------done-----------")
# 加载参数信息
state_dict = torch.load(r"D:\pythonProject\Attention_Unet\optimizer_state_dict.pkl") # 需要修改为你自己的路径
optimizer.load_state_dict(state_dict)
print("load state_dict successfully\n{}".format(state_dict))
# 输出最后属性信息
print("\n{}".format(optimizer.defaults))
print("\n{}".format(optimizer.state))
print("\n{}".format(optimizer.param_groups))8.3 输出结果
# 进行更新前的数据,梯度
The data of weight before step:
tensor([[-0.3077, -0.1808],
[-0.7462, -1.5556]])
The grad of weight before step:
tensor([[1., 1.],
[1., 1.]])
# 进行更新后的数据,梯度
The data of weight after step:
tensor([[-0.4077, -0.2808],
[-0.8462, -1.6556]])
The grad of weight after step:
tensor([[1., 1.],
[1., 1.]])
# 进行梯度清零的梯度
The grad of weight after optimizer.zero_grad():
tensor([[0., 0.],
[0., 0.]])
# 输出信息
optimizer.params_group is
[{'params': [tensor([[-0.4077, -0.2808],
[-0.8462, -1.6556]], requires_grad=True)], 'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
# 证明了优化器的和weight的储存是在一个地方,Python基于值管理
weight in optimizer:1841923407424
weight in weight:1841923407424
# 输出参数
optimizer.param_groups is
[{'params': [tensor([[-0.4077, -0.2808],
[-0.8462, -1.6556]], requires_grad=True)], 'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}, {'params': [tensor([[ 0.4539, -2.1901, -0.6662],
[ 0.6630, -1.5178, -0.8708],
[-2.0222, 1.4573, 0.8657]], requires_grad=True)], 'lr': 0.0001, 'nesterov': True, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0}]
# 进行更新前的参数查看,用state_dict
state_dict before step:
{'state': {0: {'momentum_buffer': tensor([[1., 1.],
[1., 1.]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [0]}, {'lr': 0.0001, 'nesterov': True, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'params': [1]}]}
# 进行更新后的参数查看,用state_dict
state_dict after step:
{'state': {0: {'momentum_buffer': tensor([[0.0052, 0.0052],
[0.0052, 0.0052]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [0]}, {'lr': 0.0001, 'nesterov': True, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'params': [1]}]}
# 存储信息完毕
----------done-----------
# 加载参数信息成功
load state_dict successfully
# 加载参数信息
{'state': {0: {'momentum_buffer': tensor([[0.0052, 0.0052],
[0.0052, 0.0052]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [0]}, {'lr': 0.0001, 'nesterov': True, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'params': [1]}]}
# defaults的属性输出
{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}
# state属性输出
defaultdict(<class 'dict'>, {tensor([[-1.3031, -1.1761],
[-1.7415, -2.5510]], requires_grad=True): {'momentum_buffer': tensor([[0.0052, 0.0052],
[0.0052, 0.0052]])}})
# param_groups属性输出
[{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [tensor([[-1.3031, -1.1761],
[-1.7415, -2.5510]], requires_grad=True)]}, {'lr': 0.0001, 'nesterov': True, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'params': [tensor([[ 0.4539, -2.1901, -0.6662],
[ 0.6630, -1.5178, -0.8708],
[-2.0222, 1.4573, 0.8657]], requires_grad=True)]}]
8.4 注意
(1)每个优化器都是一个类,我们一定要进行实例化才能使用。
class Net(nn.Moddule):
···
net = Net()
optim = torch.optim.SGD(net.parameters(),lr=lr)
optim.step()(2)optimizer在一个神经网络的epoch中需要实现下面两个步骤:梯度置零、梯度更新。
optimizer = torch.optim.SGD(net.parameters(), lr=1e-5)
for epoch in range(EPOCH):
...
optimizer.zero_grad() #梯度置零
loss = ... #计算loss
loss.backward() #BP反向传播
optimizer.step() #梯度更新(3)给网络不同的层赋予不同的优化器参数。
from torch import optim
from torchvision.models import resnet18
net = resnet18()
optimizer = optim.SGD([
{'params':net.fc.parameters()},#fc的lr使用默认的1e-5
{'params':net.layer4[0].conv1.parameters(),'lr':1e-2}],lr=1e-5)
# 可以使用param_groups查看属性九、基础实战——FashionMNIST时装分类
9.1 导包
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader9.2 配置训练环境和超参数
# 配置GPU,这里有两种方式
## 方案一:使用os.environ
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
## 配置其他超参数,如batch_size, num_workers, learning rate, 以及总的epochs
batch_size = 256
num_workers = 4 # 对于Windows用户,这里应设置为0,否则会出现多线程错误
lr = 1e-4
epochs = 209.3 数据读入和加载
首先设置数据变换
# 首先设置数据变换
from torchvision import transforms
image_size = 28
data_transform = transforms.Compose([
transforms.ToPILImage(),
# 这一步取决于后续的数据读取方式,如果使用内置数据集读取方式则不需要
transforms.Resize(image_size),
transforms.ToTensor()
])两种数据读入方式:
9.3.1 使用代码从网上下载
## 读取方式一:使用torchvision自带数据集,下载可能需要一段时间
from torchvision import datasets
train_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)9.3.2 自行从网站上进行下载,并创建相关的数据文件目录,方便读取。
## 读取方式二:读入csv格式的数据,自行构建Dataset类
# csv数据下载链接:https://www.kaggle.com/zalando-research/fashionmnist
class FMDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
self.images = df.iloc[:,1:].values.astype(np.uint8)
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx].reshape(28,28,1)
label = int(self.labels[idx])
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image/255., dtype=torch.float)
label = torch.tensor(label, dtype=torch.long)
return image, label
train_df = pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df = pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform)数据读入后观察数据并对数据进行可视化
import matplotlib.pyplot as plt
image, label = next(iter(train_loader))
print(image.shape, label.shape)
plt.imshow(image[0][0], cmap="gray")9.4 模型设计
这里搭建的是一个简单的CNN模型架构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3)
)
self.fc = nn.Sequential(
nn.Linear(64*4*4, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 64*4*4)
x = self.fc(x)
# x = nn.functional.normalize(x)
return x
model = Net()
model = model.cuda()
# model = nn.DataParallel(model).cuda() # 多卡训练时的写法,之后的课程中会进一步讲解9.5 设定损失函数
交叉熵损失函数为本次模型训练的损失函数
criterion = nn.CrossEntropyLoss()注意:PyTorch会自动把整数型的label转为one-hot型,用于计算CE loss
9.6 设定优化器
使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)9.7 训练和测试(验证)
9.7.1 训练函数
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))9.7.2 测试(验证)函数
def val(epoch):
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
val_loss = val_loss/len(test_loader.dataset)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels==pred_labels)/len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))注意:本次案例并没有设置测试,上面是验证,一般在使用pytorch进行比赛及论文训练的时候,都会设置验证和测试,这也就是在比赛中我们常听到的线下得分和线上得分。
9.7.3 开始训练
调用上面写到训练和测试的函数,并根据上面设定的epochs进行循环设置。
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)9.8 模型保存
save_path = "./FahionModel.pkl"
torch.save(model, save_path)深入浅出PyTorch:https://github.com/datawhalechina/thorough-pytorch

![[附源码]java毕业设计农家乐点餐系统](https://img-blog.csdnimg.cn/7b71a6f7174b4af59d0e92b57a14948c.png)
![[oeasy]python0017_解码_decode_字节序列_bytes_字符串_str](https://img-blog.csdnimg.cn/img_convert/c1721dd5486725ce6d42e95c374ba52b.png)