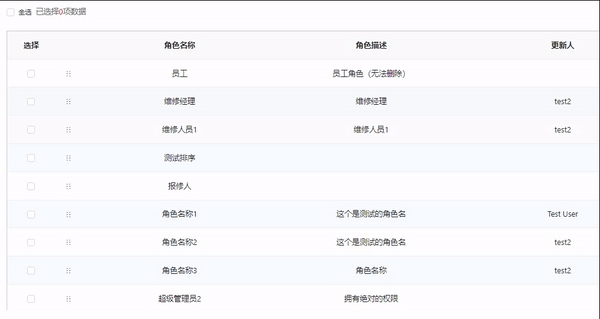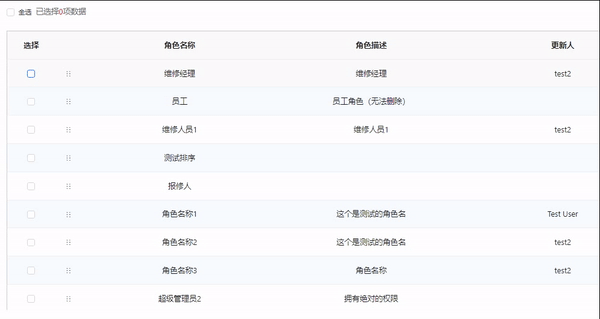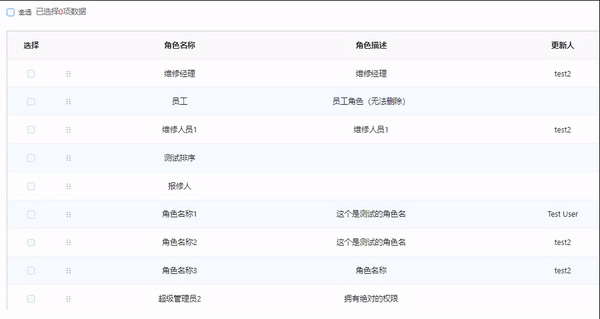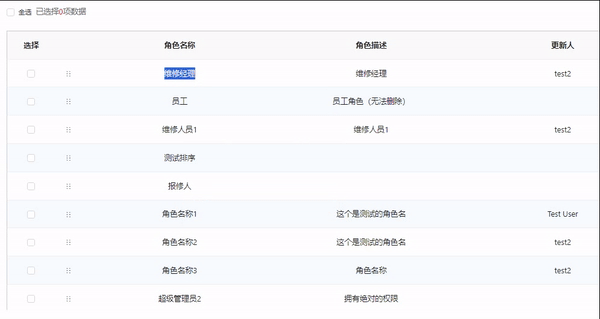
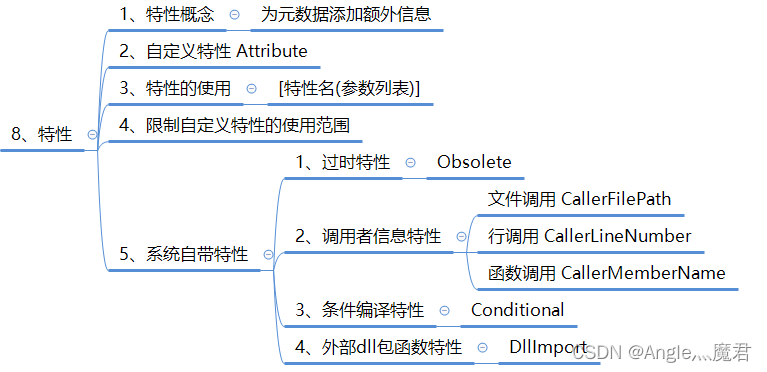
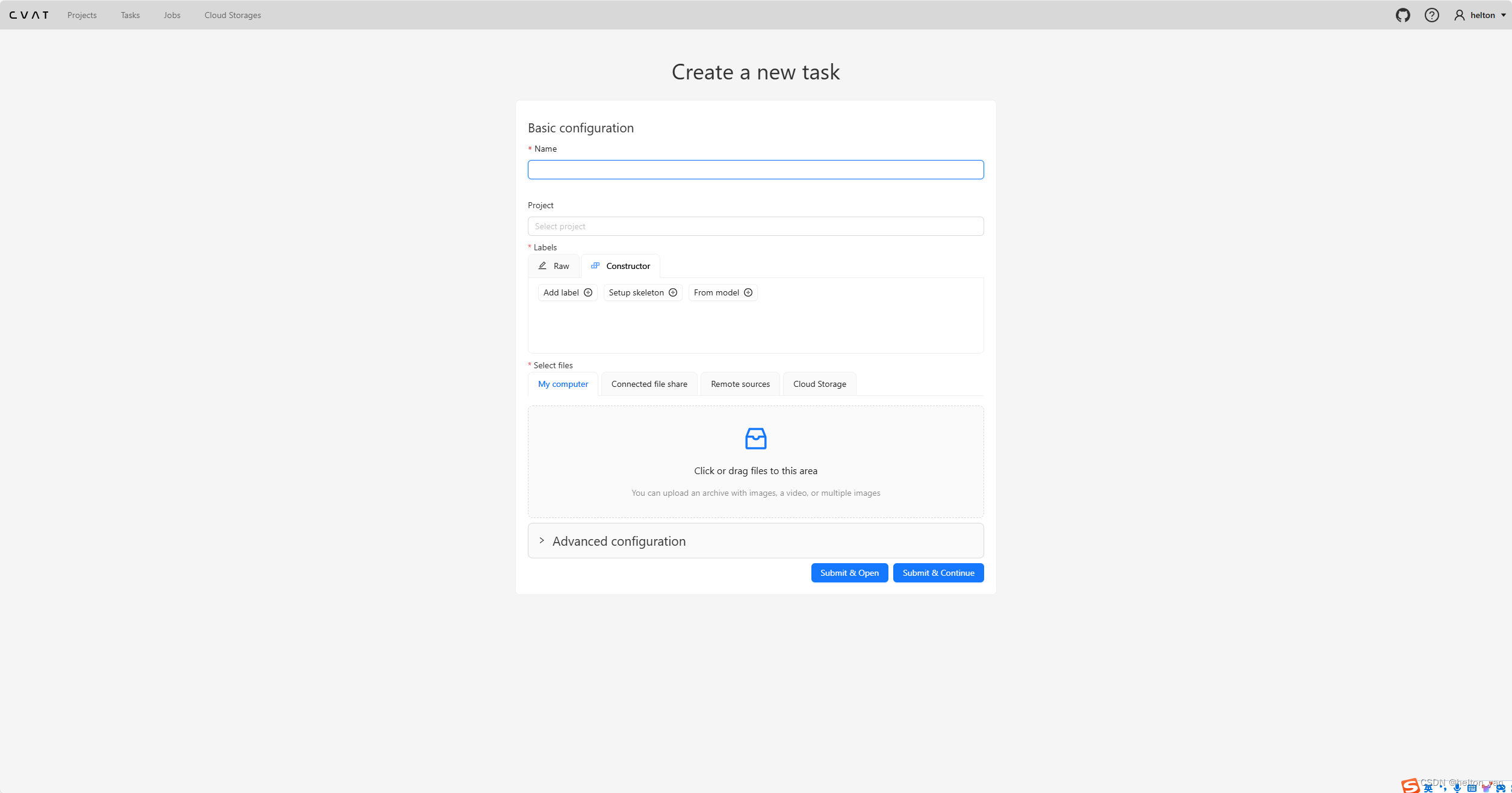
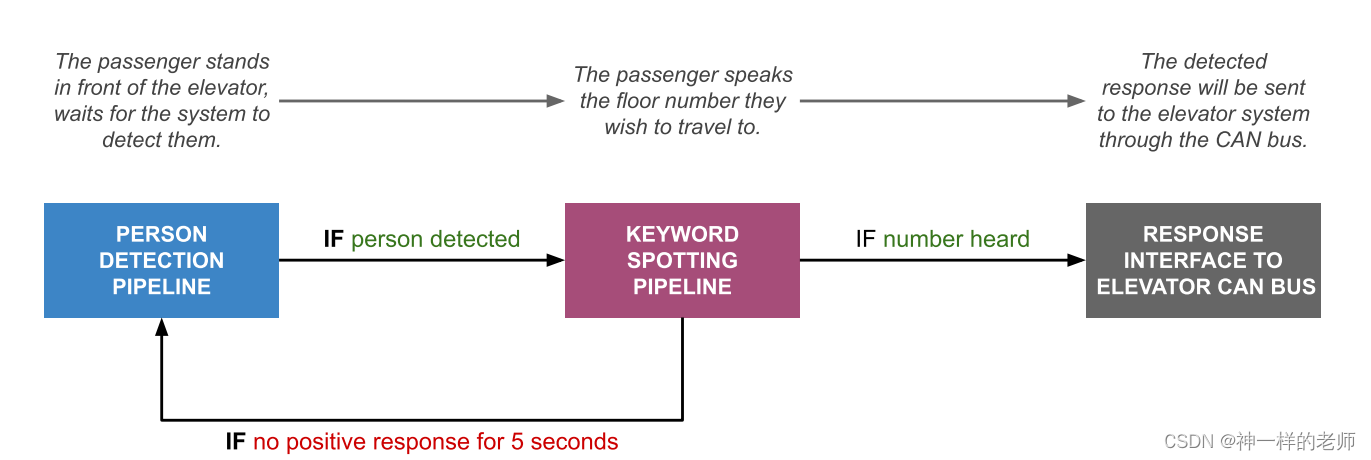
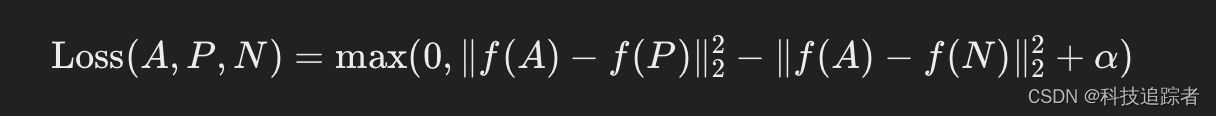最近,想着将pdf的文件进行读取其内容,发现了一个比较好用的依赖pdfbox。目前使用这个依赖,进行实现一个简单实例,如果之后需要使用到更深的了解,会进行更新。这里提醒一下:jdk8尽量采用pdfbox3.x版本。
- 对于文件的读取
File file = new File("E:\\关于pdfbox学习.pdf");
PDDocument document = Loader.loadPDF(file);
//Instantiate PDFTextStripper class
PDFTextStripper pdfStripper = new PDFTextStripper();
//Retrieving text from PDF document
String text = pdfStripper.getText(document);
System.out.println(text);
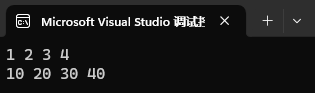
通过这个代码可以读取到相应的pdf文字:

上述是关于文字的读取,如果是获取pdf中的截图,那么进行如下操作:
- 获取pdf中的截图
代码展示:
int pageNum = document.getNumberOfPages();
for (int i = 0; i < pageNum; i++) {
PDPage page = document.getPage(i);
PDResources resources = page.getResources();
Iterable<COSName> xObjectNames = resources.getXObjectNames();
if (xObjectNames != null){
Iterator<COSName> names = xObjectNames.iterator();
while (names.hasNext()){
COSName next = names.next();
if (resources.isImageXObject(next)){
PDImageXObject xObject = (PDImageXObject) resources.getXObject(next);
BufferedImage image = xObject.getImage();
ImageIO.write(image, "png", new File("E:\\" + i + ".png"));
}
}
}
}
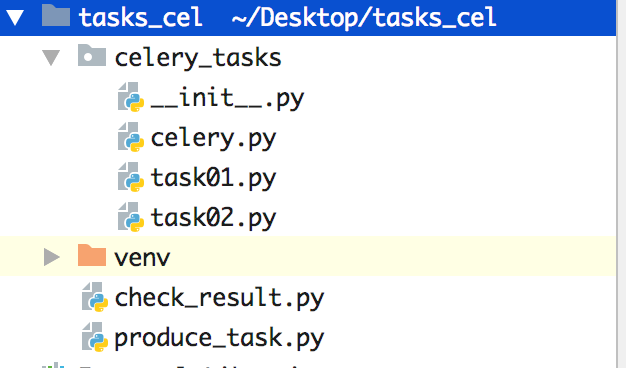
结果如下:
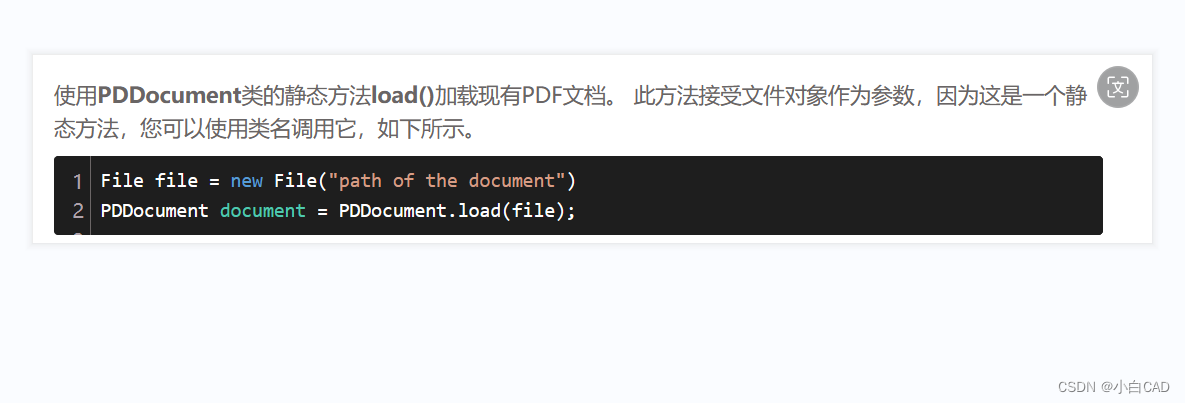
所有代码展示:
package com.example.demo;
import org.apache.pdfbox.Loader;
import org.apache.pdfbox.cos.COSName;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDResources;
import org.apache.pdfbox.pdmodel.graphics.PDXObject;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
import org.apache.pdfbox.text.PDFTextStripper;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
public class FoxApiMain {
public static void main(String[] args) { //
try{
//读取本地文件
File file = new File("E:\\关于pdfbox学习.pdf");
PDDocument document = Loader.loadPDF(file);
//Instantiate PDFTextStripper class
PDFTextStripper pdfStripper = new PDFTextStripper();
//Retrieving text from PDF document
String text = pdfStripper.getText(document);
System.out.println(text);
int pageNum = document.getNumberOfPages();
for (int i = 0; i < pageNum; i++) {
PDPage page = document.getPage(i);
PDResources resources = page.getResources();
Iterable<COSName> xObjectNames = resources.getXObjectNames();
if (xObjectNames != null){
Iterator<COSName> names = xObjectNames.iterator();
while (names.hasNext()){
COSName next = names.next();
if (resources.isImageXObject(next)){
PDImageXObject xObject = (PDImageXObject) resources.getXObject(next);
BufferedImage image = xObject.getImage();
ImageIO.write(image, "png", new File("E:\\" + i + ".png"));
}
}
}
}
document.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}